k8s--基本概念理解
必填字段
在要创建的 Kubernetes 对象的文件中.yaml,您需要设置以下字段的值:
apiVersion- 您使用哪个版本的 Kubernetes API 创建此对象
kind- 你想创建什么样的对象
metadata- 有助于唯一标识对象的数据,包括name字符串、UID和可选namespace
spec- 您希望对象处于什么状态
对象的spec(规格)和对象的status(状态)
在Kubernetes中,几乎每个对象都包含两个嵌套对象字段,用于管理对象的配置:对象的spec(规格)和对象的status(状态)。
对于具有spec的对象,在创建对象时必须设置它,以提供关于您希望资源具有的特性的描述:它的期望状态。
status描述了对象的当前状态,由Kubernetes系统及其组件提供和更新。Kubernetes控制平面持续主动管理每个对象的实际状态,以使其与您提供的期望状态匹配。
例如:在Kubernetes中,Deployment是一个能够表示在集群上运行的应用程序的对象。当您创建Deployment时,可以设置Deployment的spec,以指定您希望运行三个应用程序副本。Kubernetes系统读取Deployment的spec并启动三个所需应用程序的实例,同时更新status以匹配您的spec。如果其中任何一个实例失败(状态发生变化),Kubernetes系统会通过进行更正来响应spec和status之间的差异,例如启动一个替代实例。
有关对象的spec、status和metadata的更多信息,请参阅Kubernetes API Conventions。
对象名称和 ID
这个意思是,Kubernetes集群中的每个对象都有一个针对该资源类型唯一的名称(Name)。此外,每个Kubernetes对象还有一个在整个集群中唯一的UID。
名称在同一资源的所有API 版本中必须是唯一的。
对于非唯一的用户自定义属性,Kubernetes提供了标签(labels)和注解(annotations)的机制来进行区分和归类。标签用于标识和选择对象,而注解提供了关于对象的附加信息。这些标签和注解可以帮助你更有效地组织和管理你的Kubernetes资源。
UID
Kubernetes 系统生成的字符串,用于唯一标识对象。
在 Kubernetes 集群的整个生命周期中创建的每个对象都有一个不同的 UID。它的目的是区分历史上发生的类似实体。
官网文档
标签和选择器
Labels(标签)
Labels(标签)是附加到诸如Pod等对象的键值对。标签被用于指定对象的识别属性,这些属性对用户来说具有意义且相关,但不直接给核心系统提供语义。标签可以用于组织和选择对象的子集。标签可以在创建对象时附加,并随后在任何时候添加和修改。每个对象可以定义一组键值标签。给定对象的每个键必须是唯一的。
标签可实现高效查询和监视,非常适合在 UI 和 CLI 中使用。非识别信息应使用 注释来记录。
在Kubernetes中,标签是一种强大的元数据机制,用于管理和操作集群中的对象。它们提供了一种灵活的方式来对对象进行分类、分组和选择。标签适用于各种用例,包括部署、服务发现、负载均衡、网络路由等。
通过使用标签和选择器(Selectors),你可以执行以下操作:
-
组织对象:使用标签对对象进行逻辑分类和组织。例如,你可以给一组Pod打上相同的标签,这样你就可以根据这些标签来查找并操作这些Pod。
-
选择对象:使用选择器根据标签来选择一组对象。选择器是一个标签选择表达式,用于指定对象必须具有哪些标签、标签的值等。选择器可以用于部署、扩展、更新或删除对象。
-
路由流量:你可以使用标签和选择器来定义网络流量的路由策略,以便将流量发送到特定的对象或对象组。
标签选择器(Label Selectors)
目前,API支持两种类型的选择器:
基于相等性(equality-based)的选择器和基于集合(set-based)的选择器。
一个标签选择器可以由多个条件组成,条件之间用逗号分隔。对于多个条件,所有条件必须满足,逗号分隔符充当逻辑AND(&&)运算符。
对于空的或未指定的选择器,其语义取决于上下文,使用选择器的API类型应该记录其有效性和含义。
注意:对于某些API类型(例如ReplicaSets),两个实例的标签选择器在同一个命名空间中不得重叠,否则控制器可能会将其视为冲突的指令,并无法确定应该存在多少个副本。
注意:对于基于相等性和基于集合的条件,没有逻辑OR(||)运算符。请确保您的筛选语句按照相应的结构进行构建。
基于相等性的要求
基于相等性或不等性的要求允许按照标签键和值进行过滤。匹配的对象必须满足所有指定的标签约束,尽管它们可能还有其他标签。
允许使用三种运算符=、==和!=。前两种表示相等(是同义词),而最后一种表示不等。例如:
environment = production
tier != frontend
前者选择所有标签键等于environment且值等于production的资源。后者选择所有标签键等于tier且值不等于frontend的资源,以及所有没有带有tier键的标签的资源。可以使用逗号运算符来过滤掉在production环境中的前端资源:environment=production,tier!=frontend
基于相等性的标签要求的一个使用场景是Pods指定节点选择条件。例如,下面的示例Pod选择具有标签"accelerator=nvidia-tesla-p100"的节点。
apiVersion: v1
kind: Pod
metadata:name: cuda-test
spec:containers:- name: cuda-testimage: "registry.k8s.io/cuda-vector-add:v0.1"resources:limits:nvidia.com/gpu: 1nodeSelector:accelerator: nvidia-tesla-p100
这是一个Pod的示例,它通过使用基于相等性的标签要求来指定节点选择条件。
在Pod的规范(spec)中,使用了nodeSelector字段来指定节点选择条件。在这个示例中,节点选择条件是accelerator等于nvidia-tesla-p100。这意味着只有具有标签"accelerator=nvidia-tesla-p100"的节点才会被选择来运行这个Pod。
基于集合的标签要求
支持三种类型的运算符:in、notin和exists(仅标识键)。例如:
environment in (production, qa)
tier notin (frontend, backend)
partition
!partition
第一个示例选择所有标签键等于environment且值等于production或qa的资源。
第二个示例选择所有标签键等于tier且值不等于frontend和backend的资源,以及所有没有带有tier键的标签的资源。
第三个示例选择所有包含具有partition键的标签的资源,不检查值。
第四个示例选择所有不带有partition键的标签的资源,不检查值。
类似地,逗号分隔符充当逻辑AND运算符。因此,可以使用partition,environment notin (qa)这样的条件来过滤具有partition键的资源(无论其值为何)且envrionment不等于qa。基于集合的标签选择器是相等性的一般形式,因为environment=production等效于environment in (production);!=和notin也是如此。
基于集合的要求可以与基于相等性的要求混合使用。例如:partition in (customerA, customerB),environment!=qa。
命名空间
Kubernetes的四个初始命名空间:
-
default:
Kubernetes包含这个命名空间,以便您可以在不创建命名空间的情况下开始使用新集群。 -
kube-node-lease:
该命名空间保存与每个节点相关的租约对象。节点租约允许kubelet发送心跳,以便控制平面可以检测到节点失败。 -
kube-public:
该命名空间可被所有客户端(包括未经身份验证的客户端)读取。该命名空间主要用于集群使用,以防集群内的某些资源应该在整个集群中可见和可读。这个命名空间的公共方面只是一个约定,而不是必需的。 -
kube-system:
这是Kubernetes系统创建的对象所在的命名空间。
Kubernetes中的对象不都位于命名空间中
命名空间资源本身不在命名空间中。而低级别资源(例如节点和持久卷)不属于任何命名空间
在命名空间中的资源
kubectl api-resources --namespaced=true
不在命名空间的资源
kubectl api-resources --namespaced=false
官网文档
控制平面(control plane)
Kubernetes(通常简称为K8s)是一个开源的容器编排和管理平台,用于自动化部署、扩展和管理容器化应用程序。Kubernetes的核心是控制平面(control plane),它是Kubernetes集群的大脑和管理中心。
控制平面由多个组件组成,每个组件负责不同的功能和任务。这些组件包括:
-
kube-apiserver:作为Kubernetes API的前端,负责接收和处理来自客户端的API请求,并管理集群的状态。
-
etcd:分布式键值存储系统,用于持久化保存集群的配置信息、状态和元数据。
-
kube-scheduler:负责根据预定义的策略,将新创建的Pod分配给集群中的节点。
-
kube-controller-manager:包含多个控制器,用于监控集群的状态,并根据所配置的期望状态,进行自动化修复和调整。
-
cloud-controller-manager(可选):用于与公有云提供商集成,管理与云平台相关的资源。
控制平面的主要任务是管理和协调整个集群,包括管理Pod的调度、扩缩容、副本管理、故障检测和自动修复等。它与工作节点(Node)上的kubelet和容器运行时一起工作,确保集群中的容器应用程序正常运行,并根据需要进行动态调整。控制平面为用户和开发人员提供了一个统一的接口,可通过API和命令行工具与集群进行交互,管理和监控应用程序的部署和运行状态。
Controller pattern
在Kubernetes中,Controller模式是一种用于管理资源状态的设计模式。每个Controller跟踪至少一种Kubernetes资源类型。这些资源对象拥有一个spec字段,表示其期望的状态。Controller负责将当前状态逐渐接近期望的状态。
Controller可以自行执行操作,但在Kubernetes中,更常见的做法是将控制器发送的消息传递给API服务器,以产生有用的副作用。下面将展示一些示例。
Control via API server
在Kubernetes中,控制器通过与集群API服务器进行交互来管理状态。Job控制器是Kubernetes中一个内置的控制器示例。
Job是一个Kubernetes资源,它运行一个或多个Pod来执行任务,然后停止。
(一旦被调度,Pod对象就成为kubelet的期望状态的一部分)。
当Job控制器看到一个新的任务时,它会确保集群中的一组节点上的kubelet正在运行正确的Pod数量来完成工作。Job控制器本身不运行任何Pod或容器。相反,Job控制器告诉API服务器创建或删除Pods。控制平面中的其他组件根据新的信息进行操作(有新的Pod需要调度和运行),最终完成工作。
创建新的Job之后,期望的状态是该Job已完成。Job控制器会使该Job的当前状态更接近期望的状态:创建执行该Job所需工作的Pods,使Job更接近完成状态。
控制器还会更新配置它们的对象。例如,一旦Job的工作完成,Job控制器会更新该Job对象,标记为已完成。
(这有点像某些恒温器关掉灯来表示房间已达到您设置的温度的方式)
Direct control
与Job不同,某些控制器需要对集群外的内容进行更改。
例如,如果您使用控制循环来确保集群中有足够的节点,则该控制器需要在需要时从当前集群外部设置新的节点。
与外部状态进行交互的控制器从API服务器获取其期望状态,然后直接与外部系统通信以使当前状态更接近期望状态。
(实际上,有一个控制器可以对集群中的节点进行水平扩展。)
这里的重要一点是,控制器进行一些更改以实现所需的状态,然后向集群的API服务器报告当前状态。其他控制循环可以观察到报告的数据并采取自己的操作。
在恒温器的例子中,如果房间非常冷,则不同的控制器可能还会启动一个防冻加热器。对于Kubernetes集群,控制平面通过扩展Kubernetes来间接地与IP地址管理工具、存储服务、云提供商API和其他服务进行交互。
Desired versus current state
在Kubernetes中,存在着所期望的状态(desired state)和当前状态(current state)之间的区别。
Kubernetes采用云原生的系统观点,并能够应对持续的变化。
您的集群可能在任何时刻都在发生变化,因为任务执行和控制循环会自动修复故障。这意味着,潜在地,您的集群可能永远无法达到一个稳定的状态。
只要集群中的控制器正在运行并能够进行有用的更改,无论整体状态是否稳定并不重要。Kubernetes被设计成不断努力实现控制器定义的期望状态,适应和管理系统的动态性质。控制器负责将当前状态逐渐接近期望的状态,而不一定要达到完全稳定的状态。这种灵活性和自适应性是Kubernetes的核心特点之一。
Design
在设计上,Kubernetes采用了大量的控制器,每个控制器都管理集群状态的特定方面。通常,特定的控制循环(控制器)使用一种资源作为其期望状态,并使用不同类型的资源来管理以实现该期望状态。例如,一个用于Job的控制器会跟踪Job对象(以便发现新的任务)和Pod对象(用于运行Job,然后查看任务何时完成)。在这种情况下,其他组件创建Job,而Job控制器创建Pod。
使用简单的控制器而不是相互关联的庞大控制循环集合是很有用的。控制器可能会出现故障,因此Kubernetes被设计成能够处理这种情况。Kubernetes的设计允许控制器的失效情况,并具备相应的容错和恢复机制。
注意:
可能会有多个控制器创建或更新同一类型的对象。在幕后,Kubernetes控制器确保它们只关注与它们的控制资源相关联的资源。
例如,您可以有Deployments和Jobs,它们都会创建Pods。Job控制器不会删除部署创建的Pods,因为控制器可以使用标签等信息来区分这些Pods。控制器之间通过标识符(如标签)来区分管理的资源,并相应地执行不同的操作,以确保资源的独立性和正确性。这种方式使得不同的控制器可以并行工作,管理各自的资源,而不会相互干扰。
Kubernetes提供了一组内置的控制器,这些控制器在kube-controller-manager中运行。这些内置控制器提供了重要的核心功能。
Deployment控制器和Job控制器是Kubernetes本身提供的一些示例(“内置”控制器)。Kubernetes允许您运行一个弹性的控制平面,因此如果任何一个内置控制器出现故障,控制平面的其他部分将接手工作。
您可以找到在控制平面之外运行的控制器,以扩展Kubernetes的功能。或者,您可以自己编写一个新的控制器。您可以将您自己的控制器作为一组Pods运行,也可以在Kubernetes之外运行。最适合的方式取决于该特定控制器的功能和需求。您可以根据您的具体需求和实现方式来选择最合适的控制器部署方式。
官网文档
k8s组件
当您部署Kubernetes时,您将获得一个集群。
Kubernetes集群由一组称为节点(nodes)的工作机器组成,这些节点运行着容器化的应用程序。每个集群至少有一个工作节点。
工作节点托管作为应用程序工作负载组件的Pods。控制平面管理集群中的工作节点和Pods。在生产环境中,控制平面通常在多台计算机上运行,而集群通常运行多个节点,提供容错性和高可用性。
本文档概述了构建完整可用的Kubernetes集群所需的各个组件。
k8s组件 Control Plane Components
控制平面的组件对集群进行全局决策(例如,调度),并检测和响应集群事件(例如,在部署的副本字段不满足时启动新的Pod)。
控制平面组件可以在集群中的任何一台机器上运行。然而,为了简化起见,设置脚本通常会在同一台机器上启动所有的控制平面组件,并且不在该机器上运行用户容器。请参阅使用kubeadm创建高可用集群的示例控制平面设置,该设置会在多台机器上运行控制平面组件。
创建高可用集群通常涉及将控制平面组件分散在多个机器上,以确保在单个机器故障的情况下仍然能够保持集群的可用性。这种设置需要更复杂的配置和管理,但它提供了更高的容错性和可靠性。
kube-apiserver
kube-apiserver是Kubernetes控制平面的一个组件,它暴露Kubernetes API,作为控制平面的前端。
kube-apiserver是Kubernetes API服务器的主要实现。它的设计理念是水平扩展,也就是通过部署多个实例来进行扩展。你可以运行多个kube-apiserver实例,并在这些实例之间平衡流量。
具体而言,当客户端(例如Kubernetes命令行工具kubectl)想要与Kubernetes集群进行交互时,它会向kube-apiserver发送HTTP请求。kube-apiserver会验证和处理这些请求,执行身份验证和授权检查,然后对集群的状态进行必要的更改。
为了确保可伸缩性和容错性,你可以在负载均衡器后面运行多个kube-apiserver实例。这样可以分发请求负载到各个实例上,避免单点故障。负载均衡确保每个kube-apiserver实例共享流量负载,并提供高可用性。
etcd
etcd是一个一致性和高可用性的键值存储,用作Kubernetes集群中所有数据的后端存储。
如果你的Kubernetes集群使用etcd作为其后端存储,请确保你有针对数据的备份计划。
ETCD官方文档中提供了关于etcd的详细信息,你可以在其中找到更多相关的资料。
kube-scheduler
kube-scheduler是Kubernetes控制平面的一个组件,它负责监视新创建的没有分配节点的Pod,并为它们选择一个节点来运行。
kube-scheduler会根据一系列因素进行调度决策,这些因素包括:单个和集体资源需求、硬件/软件/策略限制、亲和性和反亲和性规范、数据本地性、工作负载之间的干扰以及截止时间。
在进行调度决策时,kube-scheduler会考虑每个Pod的资源需求,例如:
- CPU和内存等资源。
- 还会考虑集群中各个节点的资源利用率和可用性,以便将Pod分配给最合适的节点。
- 如果定义了亲和性和反亲和性规范,kube-scheduler还会将这些规范考虑在内,以满足特定的调度策略。
- 此外,kube-scheduler还会考虑数据本地性,尽可能将需要访问相同数据的Pod调度到同一节点上,以提高性能和效率。
- 还会考虑截止时间,确保Pod在特定时间内得到调度和运行,以满足应用程序的需求。
总之,kube-scheduler负责根据一系列因素和策略,动态选择合适的节点来运行Pod,以优化集群资源的利用和满足应用程序的需求。
kube-controller-manage
kube-controller-manager是Kubernetes控制平面的一个组件,它运行各种控制器进程。
从逻辑上讲,每个控制器都是一个独立的进程,但为了降低复杂性,它们都被编译到单个二进制文件中,并在单个进程中运行。
控制器有许多不同类型。以下是其中一些示例:
- Node controller:负责注意和响应节点宕机的情况。
- Job controller:监视代表一次性任务的Job对象,然后创建Pod来完成这些任务。
- EndpointSlice controller:填充EndpointSlice对象(提供Service和Pod之间的链接)。
- ServiceAccount controller:为新命名空间创建默认的ServiceAccount。
以上仅为部分示例,控制器的类型还有很多,这里没有穷尽所有。
每个控制器的目标是通过监视集群状态的变化,以及根据所定义的期望状态来进行相应的操作。控制器可以执行自动化任务,例如启动和停止Pod、管理副本数量、检测和处理故障等。
kube-controller-manager通过运行不同的控制器进程,帮助确保集群中的各种资源和组件保持预期的状态,并根据需要进行自动修复和调整。
cloud-controller-manager
cloud-controller-manager是Kubernetes控制平面的一个组件,用于嵌入特定于云平台的控制逻辑。通过cloud-controller-manager,您可以将集群与云提供商的API进行连接,将与该云平台交互的组件与仅与集群交互的组件分开。
cloud-controller-manager仅会运行与您的云提供商相关的控制器。如果您在自己的环境中或在个人电脑上的学习环境中运行Kubernetes,那么集群将没有cloud-controller-manager。
与kube-controller-manager类似,cloud-controller-manager将多个逻辑上独立的控制循环合并到一个单独的二进制文件中,并作为单个进程运行。您可以水平扩展(运行多个副本)以提高性能或帮助容忍故障。
以下控制器可能具有云提供商依赖:
- Node controller:检查云提供商以确定节点是否在停止响应后在云中被删除。
- Route controller:用于在底层云基础设施中设置路由。
- Service controller:用于创建、更新和删除云提供商负载均衡器。
以上是一些可能具有云提供商依赖的控制器的示例。
cloud-controller-manager允许将特定于云平台的逻辑与其他控制平面组件分离,使您能够更好地集成和管理与云提供商相关的功能。它提供了一种扩展和定制Kubernetes控制平面的方式,以适应不同的云环境和需求。
节点组件
节点组件是运行在每个节点上的组件,它们负责维护正在运行的Pod并提供Kubernetes运行时环境。
节点组件包括以下几个核心组件:
Kubelet
是在集群中每个节点上运行的代理程序。负责管理该节点上的容器和Pod。它会与控制平面通信,接收到分配给节点的Pod清单,并确保这些Pod在节点上按照预期运行。
kubelet通过各种机制接收一组PodSpecs(Pod规范),并确保这些PodSpecs中描述的容器运行并保持健康状态。
kubelet的任务包括:
- 通过与控制平面通信,接收将在该节点上运行的Pod清单。
- 根据PodSpec中的描述,启动和停止容器。它会监控容器的生命周期,确保容器保持运行状态。
- 通过与kube-proxy和容器运行时交互,设置网络和存储卷等资源的配置。
- 定期向控制平面报告节点的状态和容器的健康状况。
需要注意的是,kubelet只负责管理由Kubernetes创建的容器,而不负责管理其他外部方式创建的容器。它的主要职责是与控制平面保持通信,并在节点上运行和管理Pod中的容器。kubelet是使得Pod能够在集群中正常运行的重要组件之一。
Kube-proxy:
是运行在集群中每个节点上的网络代理和负载均衡。它维护网络规则,使得Pod可以在集群中与其他服务进行通信,并通过负载均衡提供稳定的服务访问。
kube-proxy在节点上维护网络规则。这些网络规则允许集群内外的网络会话与您的Pod进行通信。
如果操作系统中存在并可用,kube-proxy会使用操作系统的数据包过滤层。否则,kube-proxy会自行转发流量。
具体来说,kube-proxy的功能包括:
-
服务代理:kube-proxy通过监听Kubernetes API上的服务配置,将服务的请求转发到相应的Pod。它为服务创建一个虚拟IP,并通过负载均衡将请求转发到后端的Pod实例。
-
IPVS或iptables规则管理:kube-proxy使用IPVS(IP Virtual Server)或iptables规则来实现服务的负载均衡和网络转发。它在节点上管理网络规则,将请求路由到正确的Pod。
-
会话跟踪:kube-proxy跟踪网络会话,并确保会话中的所有数据包都被路由到同一个Pod。
-
高可用性:kube-proxy支持多个代理实例,并使用选举机制来确保高可用性。如果当前运行的代理实例发生故障,将自动选择新的主实例来接管代理任务。
总的来说,kube-proxy是实现Kubernetes服务代理和负载均衡的关键组件之一。它通过维护网络规则和转发流量,使得集群内外的用户能够访问到您的Pod。
kube-proxy
Container runtime
容器运行时(Container runtime)是负责运行容器的软件。
Kubernetes支持多种Container runtime,如containerd、CRI-O以及符合Kubernetes CRI(Container Runtime Interface)规范的其他实现。
容器运行时负责以下任务:
-
容器生命周期管理:Container runtime负责创建、启动、停止和销毁容器。它提供了对容器的生命周期管理的接口和功能。
-
资源隔离:Container runtime通过使用Linux内核的命名空间和cgroup等机制,实现对容器之间的资源隔离,包括文件系统、进程、网络和设备等资源。
-
容器镜像管理:Container runtime管理容器镜像的下载、存储和加载。它负责根据镜像定义创建容器的文件系统,并提供镜像的描述和共享。
-
容器网络:Container runtime管理容器的网络连接和配置。它为容器分配IP地址,并提供网络功能,如网络插件的支持和容器间的通信。
Kubernetes的CRI是定义Kubernetes控制平面与Container runtime之间交互的接口规范。通过实现符合CRI规范的Container runtime,可以与Kubernetes紧密集成,并提供统一的容器管理体验。
综上所述,Container runtime是负责运行和管理容器的关键组件。它使得Kubernetes能够在不同的运行环境中使用各种容器运行时,并提供一致的容器操作和管理能力。
Addons
Addons是使用Kubernetes资源(如DaemonSet、Deployment等)来实现集群功能的扩展功能。由于这些功能是提供集群级别的功能,因此属于kube-system命名空间下的命名空间资源。
下面描述了一些被选中的Addons;如果需要了解更多可用的Addons,请参考Addons文档。
这些节点组件共同工作,提供了运行和维护Pod的环境。Kubelet负责与控制平面通信,接收Pod清单并启动/停止容器,Kube-proxy负责网络代理和负载均衡,而容器运行时则负责实际的容器管理。节点组件是Kubernetes集群中至关重要的一部分,确保Pod能够运行和访问所需资源。
DNS
在Kubernetes中,集群DNS是一个重要的Addon。
集群DNS是在您的环境中的其他DNS服务器之外的一个DNS服务器,为Kubernetes服务提供DNS记录。
在Kubernetes中启动的容器会自动将这个DNS服务器加入到它们的DNS搜索中,这意味着在容器内部的应用程序中可以直接使用服务名称来进行网络通信。
简单来说,Kubernetes集群中的每个节点上都会运行一个DNS服务器,它提供了Kubernetes服务名称到IP地址的解析。这使得在容器中使用服务名称来进行通信更加简单和方便,无需关心服务的具体IP地址和端口号。
所有的Kubernetes集群应该都要有集群DNS,因为很多示例和应用都依赖于它来进行服务发现和通信。
Web UI(仪表盘)
仪表盘
是Kubernetes集群的一个通用的基于Web的用户界面。它允许用户管理和排查运行在集群中的应用程序,以及集群本身的状态和配置。
容器资源监控(Container Resource Monitoring)记录关于容器的通用时间序列指标,并将其存储在一个中央数据库中,并提供一个用户界面来浏览这些数据。
容器资源监控
在Kubernetes集群中,容器资源监控可以跟踪和记录容器的各种资源使用情况和性能指标,包括CPU使用率、内存使用量、网络流量、磁盘IO等。
通过容器资源监控,您可以:
-
了解容器的资源使用情况:监控指标可以显示每个容器的资源消耗情况,使您能够查看容器的CPU、内存和其他资源的使用率和限制。
-
性能分析和诊断:利用监控指标,可以分析容器的性能瓶颈和问题,并进行诊断和排查。例如,您可以检查容器的CPU使用情况是否在预期范围内,或者是否存在内存泄漏等问题。
-
容器自动扩缩容:容器资源监控可以提供资源使用情况的历史数据,通过分析历史数据和设置的规则,可以实现自动地调整容器的副本数来适应负载的变化。
容器资源监控还提供了一个用户界面(UI),使您可以浏览和查看记录的监控数据。通过UI,您可以进行实时监控和历史数据的分析,从而更好地了解和管理您的容器资源。
集群级别的日志记录机制
集群级别的日志记录机制指的是将容器日志保存到一个中央日志存储并提供搜索/浏览接口的功能。
在Kubernetes集群中,有多个容器在各个节点上运行,并且这些容器产生的日志需要进行收集、存储和分析。集群级别的日志记录机制就是用来管理和处理这些容器日志的。
集群级别的日志记录机制通常具备以下功能:
-
日志收集:该机制能够自动地从集群中的各个节点上收集容器生成的日志。日志可以是标准输出、标准错误输出,以及容器内应用程序的日志文件等。
-
日志存储:收集到的容器日志会被保存到一个集中的日志存储系统中,例如Elasticsearch、Logstash、Fluentd等。这些日志存储系统通常具备高可用性和数据冗余功能,以确保日志数据的安全性和可靠性。
-
搜索和浏览:日志存储系统提供搜索和浏览接口,用户可以通过关键字搜索感兴趣的日志事件,也可以根据时间、容器、节点等条件进行筛选和浏览。
集群级别的日志记录机制可以帮助用户更好地管理和分析容器生成的日志,实现以下目标:
- 集中化日志:将容器日志集中到一个存储系统中,方便后续查询和分析。
- 故障排查:通过搜索和浏览接口,用户可以快速地定位和排查容器和应用程序的故障和问题。
- 安全审计:集群级别的日志记录机制可以提供对集群中发生的事件和活动进行审计和追踪的能力。
网络插件(Network Plugins)
网络插件(Network Plugins)是实现容器网络接口(CNI)规范的软件组件。它们负责为Pod分配IP地址,并使它们能够在集群内部相互通信。
在Kubernetes集群中,网络插件是实现容器网络的关键组件之一。它们提供了一种机制来为Kubernetes中的Pod分配IP地址,并建立Pod之间的网络连接,以便它们可以相互通信。
网络插件的工作原理如下:
-
CNI规范:CNI是一个Kubernetes定义的标准接口规范,用于定义容器运行时和网络插件之间的通信协议和数据格式。
-
IP地址分配:网络插件负责为每个Pod分配唯一的IP地址。它们可以使用不同的机制来管理和分配IP地址,例如通过DHCP服务器、使用预定义的IP池、使用子网划分等。
-
网络连接:网络插件建立Pod之间的网络连接,使它们可以通过IP地址进行通信。这包括在节点上创建虚拟网络设备、配置网络路由和防火墙规则等操作。
-
网络策略:某些网络插件还可以提供网络策略功能,用于定义和控制Pod之间的网络通信规则,例如允许或禁止特定的流量传输。
-
插件可扩展性:Kubernetes允许使用不同的网络插件来满足不同的网络需求。用户可以根据自己的需求选择和配置适合的网络插件,例如flannel、Calico、Weave等。
通过网络插件,Kubernetes的Pod可以获得唯一的IP地址,并能够在集群内部进行网络通信。网络插件的选择和配置对于容器的网络性能、安全性和可靠性都具有重要影响。因此,根据集群的需求,选择适当的网络插件是一个重要的决策。
官网文档
相关文章:

k8s--基本概念理解
必填字段 在要创建的 Kubernetes 对象的文件中.yaml,您需要设置以下字段的值: apiVersion- 您使用哪个版本的 Kubernetes API 创建此对象 kind- 你想创建什么样的对象 metadata- 有助于唯一标识对象的数据,包括name字符串、UID和可选namesp…...

流媒体开发千问【持续更新】
H.264中IDR帧和I帧区别 H.264/AVC编码标准中,IDR帧和I帧都是关键帧,即它们都不依赖于其他帧进行解码。但是,它们之间存在明确的区别: 定义与功能: I帧(Intra-frame):I帧是一个内部编…...

全球各国官方语言大盘点,英语不得不学哇。。。
因国家和地区范围界定不同,官方语言只是个相对概念。具体而言是一个国家通用的正式语言或认定的正式语言。它是为适应管理国家事务的需要,在国家机关、正式文件、法律裁决及国际交往等官方场合中规定一种或几种语言为有效语言的现象。官方语言也是一个国…...
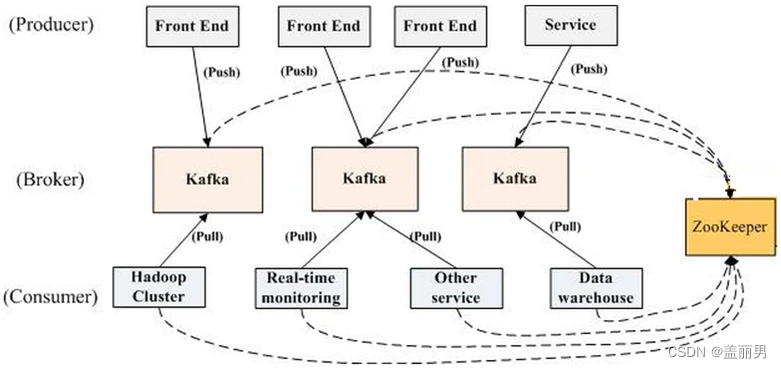
【mq】如何保证消息可靠性
文章目录 mq由哪几部分组成rocketmqkafka 为什么需要这几部分nameserver/zookeeper可靠性 broker可靠性 生产者消费者 mq由哪几部分组成 rocketmq kafka 这里先不讨论Kafka Raft模式 比较一下,kafka的结构和rocketmq的机构基本上一样,都需要一个注册…...
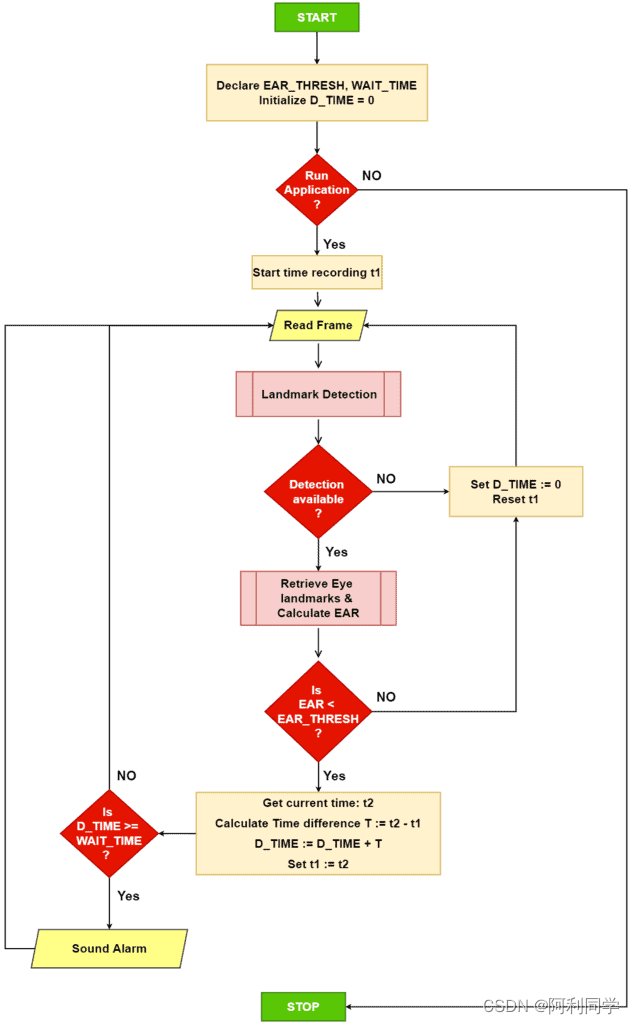
疲劳检测-闭眼检测(详细代码教程)
简介 瞌睡经常发生在汽车行驶的过程中,该行为害人害己,如果有一套能识别瞌睡的系统,那么无疑该系统意义重大! 实现步骤 思路:疲劳驾驶的司机大部分都有打瞌睡的情形,所以我们根据驾驶员眼睛闭合的频率和…...

大数据日常运维命令
1、HDFS NameNode /usr/local/fqlhadoop/hadoop/sbin/hadoop-daemon.sh start namenode /usr/local/fqlhadoop/hadoop/sbin/hadoop-daemon.sh stop namenode bin/hdfs haadmin -DFSHAAdmin -getServiceState n1 2、HDFS DataNode /usr/local/fqlhadoop/hadoop/sbin/hadoop-…...

解锁安全高效办公——私有化部署的WorkPlus即时通讯软件
在当今信息时代,高效的沟通与协作对于企业的成功至关重要。然而,随着信息技术的发展,保护敏感信息和数据安全也变得越来越重要。为了满足企业对于安全沟通和高效办公的需求,我们隆重推出私有化部署的WorkPlus即时通讯软件…...
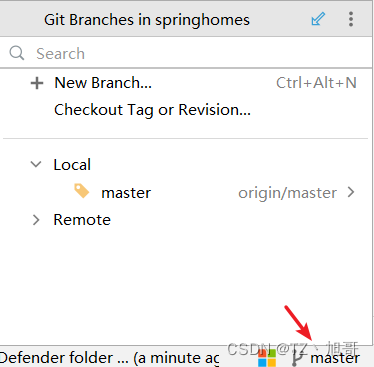
IDEA使用git
文章目录 给所有文件配置git初始化本地仓库创建.gitignore文件添加远程仓库分支操作 给所有文件配置git 初始化本地仓库 创建.gitignore文件 添加远程仓库 分支操作 新建分支 newbranch 切换分支 checkout 推送分支 push 合并分支 merge...
)
【跟小嘉学 Rust 编程】十八、模式匹配(Patterns and Matching)
系列文章目录 【跟小嘉学 Rust 编程】一、Rust 编程基础 【跟小嘉学 Rust 编程】二、Rust 包管理工具使用 【跟小嘉学 Rust 编程】三、Rust 的基本程序概念 【跟小嘉学 Rust 编程】四、理解 Rust 的所有权概念 【跟小嘉学 Rust 编程】五、使用结构体关联结构化数据 【跟小嘉学…...
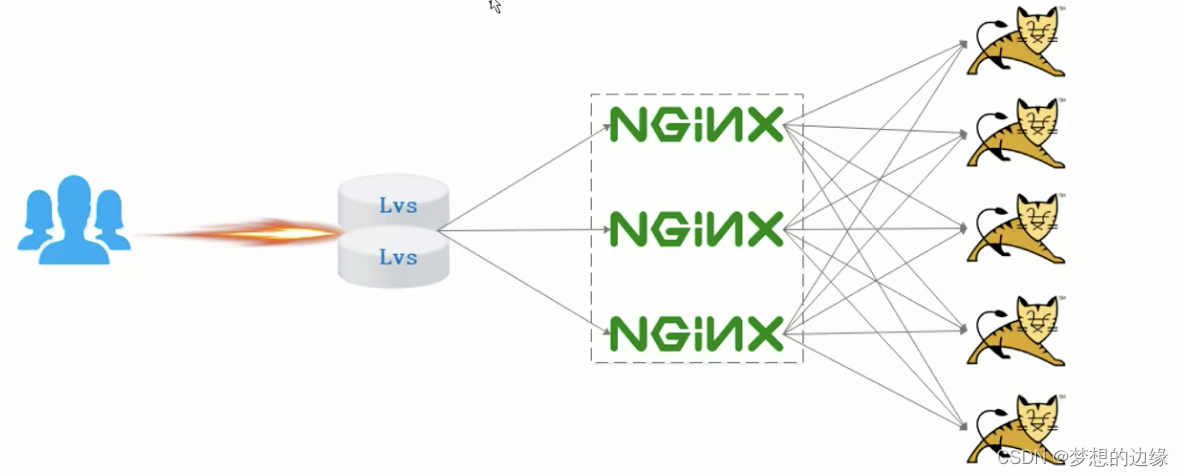
keepalived+lvs+nginx高并发集群
keepalivedlvsnginx高并发集群 简介: keepalivedlvsnginx高并发集群,是通过LVS将请求流量均匀分发给nginx集群,而当单机nginx出现状态异常或宕机时,keepalived会主动切换并将不健康nginx下线,维持集群稳定高可用 1.L…...

剑指Offer65.不用加减乘除做加法 C++
1、题目描述 写一个函数,求两个整数之和,要求在函数体内不得使用 “”、“-”、“*”、“/” 四则运算符号。 示例: 输入: a 1, b 1 输出: 2 2、VS2019上运行 使用位运算的方法 #include <iostream>class Solution { public:/*** 计算两个整…...

【linux命令讲解大全】004.探索Linux命令行中的chmod和chown工具
文章目录 chmod概要主要用途参数选项返回值例子 chown补充说明语法选项参数实例 从零学 python chmod 用来变更文件或目录的权限 概要 chmod [OPTION]... MODE[,MODE]... FILE... chmod [OPTION]... OCTAL-MODE FILE... chmod [OPTION]... --referenceRFILE FILE...主要用途…...
nginx会话保持
ip_hash:通过IP保持会话 作用: nginx通过后端服务器地址将请求定向的转发到服务器上。 将客户端的IP地址通过哈希算法加密成一个数值 如果后端有多个服务器,第一次请求到服务器A, 并在务器登录成功,那么再登录B服务器就要重新…...
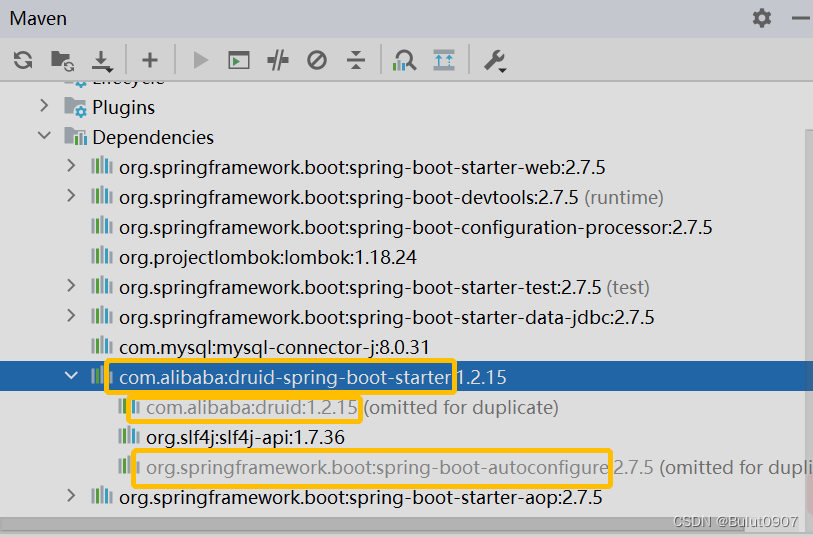
SpringBoot使用Druid连接池 + 配置监控页面(自定义版 + starter版)
目录 1. Druid连接池的功能2. 自定义版2.1 pom.xml添加依赖2.2 MyDataSourceConfig实现2.3 application.properties配置编写Controller进行测试2.4 druid监控页面查看 3. starter版3.1 pom.xml添加依赖3.2 自动配置分析3.3 使用application.properties对druid进行配置3.4 druid…...

【业务功能篇77】微服务-OSS对象存储-上传下载图片
3. 图片管理 文件存储的几种方式 单体架构可以直接把图片存储在服务器中 但是在分布式环境下面直接存储在WEB服务器中的方式就不可取了,这时我们需要搭建独立的文件存储服务器。 3.1 开通阿里云服务 针对本系统中的相关的文件,图片,文本等…...

【CSS 常用加载动画效果】
常用加载效果 呼吸灯效果波浪光效果转圈加载 呼吸灯效果 <!DOCTYPE html> <html><head><meta charset"utf-8"><title></title></head><body><div id"ti"></div></body><style>b…...

python 模块requests 发送 HTTP 请求
一、简介 requests 模块是 python 基于 urllib,采用 Apache2 Licensed 开源协议的 HTTP 库。它比 urllib 更加方便,可以节约我们大量的工作 二、安装 pip install requestsimport requests三、方法 requsts.requst(method, url,headers,cookies,prox…...

关于 Camera 预览和录像画质不一样的问题分析
1、问题背景 基于之前安卓平台的一个项目,客户有反馈过一个 Camera app 预览的效果,和录像效果不一致的问题。 这里的预览是指打开 Camera app 后直接出图的效果;录像的效果则是指打开 Camera app 开启录像功能,录制一段视频&…...

【音视频】 视频的播放和暂停,当播放到末尾时触发 ended 事件,循环播放,播放速度
video 也可以 播放 MP3 音频,当不想让 视频显示出来的话,可以 给 video 设置宽和高 1rpx ,不可以隐藏 <template><view class"form2box"><u-navbar leftClick"leftClick"><view slot"left&q…...

Python数据分析高薪实战第一天 python基础与项目环境搭建
开篇词 数据赋能未来,Python 势不可挡 互联网公司从红利下的爆发期,进入新的精细化发展阶段,亟须深入分析与挖掘业务与数据价值,从而找到新的增长点突破现有增长瓶颈。各行各业的数据分析需求井喷,数据分析人才成为争…...

C++ 与 异步流调度:在 C++ AI 框架中利用多个 CUDA Stream 重叠计算与数据传输的掩盖性能分析
C 与 异步流调度:在 C AI 框架中利用多个 CUDA Stream 重叠计算与数据传输的掩盖性能分析引言在现代人工智能领域,尤其是深度学习的应用中,GPU 已成为不可或缺的计算引擎。然而,即使拥有强大的 GPU 算力,系统整体性能也…...

ThinkBook 16 2024款装Ubuntu 22.04,无线网卡和蓝牙驱动修复保姆级教程
ThinkBook 16 2024款Ubuntu 22.04无线与蓝牙驱动终极解决方案 刚拿到新款ThinkBook 16 2024的开发者们,在享受其强悍性能的同时,可能都会遇到一个共同的烦恼——安装Ubuntu 22.04后无线网卡和蓝牙无法正常工作。这并非硬件故障,而是由于Intel…...

2024年流浪星球比赛
2024年暑假,我去到河北参加流浪星球比赛现场人很多,调试的人排队很长,不过调试很快60分钟的时间13分钟就弄完了。拿了国一比完赛后,我又去北京爬长城,长城的确难爬,道路已有些坑坑洼洼很多人不讲文明在墙上…...

含分布式电源的IEEE33节点配电网的潮流计算程序,程序考虑了风光接入下的潮流计算问题将风光等...
含分布式电源的IEEE33节点配电网的潮流计算程序,程序考虑了风光接入下的潮流计算问题将风光等效为PQV PI等节点处理,采用牛拉法开展潮流计算,而且程序都有注释 –以下内容属于A解读,有可能是一本正经的胡说八道,仅供参…...

Windows Subsystem for Android全流程实战攻略:从环境搭建到场景落地
Windows Subsystem for Android全流程实战攻略:从环境搭建到场景落地 【免费下载链接】WSA Developer-related issues and feature requests for Windows Subsystem for Android 项目地址: https://gitcode.com/gh_mirrors/ws/WSA Windows Subsystem for And…...

文本文件批量转 UTF-8 与「仅检测编码」操作备忘
需要在 Windows 桌面端对一批文本类文件统一编码或先摸清当前编码时,可以用【批量文件编码转换工具】。下文只记界面流程与注意点,不写检测与转换的实现细节。源路径支持拖入文件或文件夹、多次追加,也可用浏览菜单选文件夹、单文件或多文件。…...
)
别再为视频生成发愁了!用ComfyUI+Wan 2.1,保姆级本地部署教程(附工作流文件)
从零到一:ComfyUI与Wan 2.1的本地视频生成实战指南 如果你曾经被AI视频生成工具的复杂配置劝退,或是厌倦了云端服务的漫长等待和隐私顾虑,今天这份指南将彻底改变你的创作体验。我们将深入探索如何利用ComfyUI框架和Wan 2.1模型,…...

终极指南:如何用dlssg-to-fsr3让老款RTX显卡享受帧生成技术
终极指南:如何用dlssg-to-fsr3让老款RTX显卡享受帧生成技术 【免费下载链接】dlssg-to-fsr3 Adds AMD FSR 3 Frame Generation to games by replacing Nvidia DLSS Frame Generation (nvngx_dlssg). 项目地址: https://gitcode.com/gh_mirrors/dl/dlssg-to-fsr3 …...

如何绕过百度网盘限速?这个开源工具让你免费享受会员级下载速度
如何绕过百度网盘限速?这个开源工具让你免费享受会员级下载速度 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 还在为百度网盘的龟速下载而烦恼吗?每天…...

企业级消息保留技术实现:3大核心机制深度解析与完整部署方案
企业级消息保留技术实现:3大核心机制深度解析与完整部署方案 【免费下载链接】RevokeMsgPatcher :trollface: A hex editor for WeChat/QQ/TIM - PC版微信/QQ/TIM防撤回补丁(我已经看到了,撤回也没用了) 项目地址: https://gitc…...