LLM学习《Prompt Engineering for Developer》
Prompt
如何构造好的Prompt
- 分割符:分隔符就像是 Prompt 中的墙,将不同的指令、上下文、输入隔开,避免意外的混淆。你可以选择用 ```,“”",< >, ,: 等做分隔符,只要能明确起到隔断作用即可。
from tool import get_completiontext = f"""
您应该提供尽可能清晰、具体的指示,以表达您希望模型执行的任务。\
这将引导模型朝向所需的输出,并降低收到无关或不正确响应的可能性。\
不要将写清晰的提示词与写简短的提示词混淆。\
在许多情况下,更长的提示词可以为模型提供更多的清晰度和上下文信息,从而导致更详细和相关的输出。
"""
# 需要总结的文本内容
prompt = f"""
把用三个反引号括起来的文本总结成一句话。
```{text}```
"""
# 指令内容,使用 ```来分隔指令和待总结的内容
response = get_completion(prompt)
print(response)- 寻求结构化的输出。按照某种格式组织的内容,例如JSON、HTML等。这种输出非常适合在代码中进一步解析和处理。例如,您可以在 Python 中将其读入字典或列表中。
- 在以下示例中,我们要求 GPT 生成三本书的标题、作者和类别,并要求 GPT 以 JSON 的格式返回给我们,为便于解析,我们指定了 Json 的键。
prompt = f"""
请生成包括书名、作者和类别的三本虚构的、非真实存在的中文书籍清单,\
并以 JSON 格式提供,其中包含以下键:book_id、title、author、genre。
"""
response = get_completion(prompt)
print(response)- 返回值
{"books": [{"book_id": 1,"title": "迷失的时光","author": "张三","genre": "科幻"},{"book_id": 2,"title": "幻境之门","author": "李四","genre": "奇幻"},{"book_id": 3,"title": "虚拟现实","author": "王五","genre": "科幻"}]
}- 要求模型检查是否满足条件
# 满足条件的输入(text中提供了步骤)
text_1 = f"""
泡一杯茶很容易。首先,需要把水烧开。\
在等待期间,拿一个杯子并把茶包放进去。\
一旦水足够热,就把它倒在茶包上。\
等待一会儿,让茶叶浸泡。几分钟后,取出茶包。\
如果您愿意,可以加一些糖或牛奶调味。\
就这样,您可以享受一杯美味的茶了。
"""
prompt = f"""
您将获得由三个引号括起来的文本。\
如果它包含一系列的指令,则需要按照以下格式重新编写这些指令:第一步 - ...
第二步 - …
…
第N步 - …如果文本中不包含一系列的指令,则直接写“未提供步骤”。"
\"\"\"{text_1}\"\"\"
"""
response = get_completion(prompt)
print("Text 1 的总结:")
print(response)Text 1 的总结:
第一步 - 把水烧开。
第二步 - 拿一个杯子并把茶包放进去。
第三步 - 把烧开的水倒在茶包上。
第四步 - 等待几分钟,让茶叶浸泡。
第五步 - 取出茶包。
第六步 - 如果需要,加入糖或牛奶调味。
第七步 - 就这样,您可以享受一杯美味的茶了。- 提供少量示例。“Few-shot” prompting,即在要求模型执行实际任务之前,给模型一两个已完成的样例,让模型了解我们的要求和期望的输出样式。
prompt = f"""
您的任务是以一致的风格回答问题。<孩子>: 请教我何为耐心。<祖父母>: 挖出最深峡谷的河流源于一处不起眼的泉眼;最宏伟的交响乐从单一的音符开始;最复杂的挂毯以一根孤独的线开始编织。<孩子>: 请教我何为韧性。
"""
response = get_completion(prompt)
print(response)- 指定回答的步骤和格式。
prompt_2 = f"""
1-用一句话概括下面用<>括起来的文本。
2-将摘要翻译成英语。
3-在英语摘要中列出每个名称。
4-输出一个 JSON 对象,其中包含以下键:English_summary,num_names。请使用以下格式:
文本:<要总结的文本>
摘要:<摘要>
翻译:<摘要的翻译>
名称:<英语摘要中的名称列表>
输出 JSON:<带有 English_summary 和 num_names 的 JSON>Text: <{text}>
"""
response = get_completion(prompt_2)
print("\nprompt 2:")
print(response)幻觉问题
- 虚假知识:模型偶尔会生成一些看似真实实则编造的知识
- 在开发与应用语言模型时,需要注意它们可能生成虚假信息的风险。尽管模型经过大规模预训练,掌握了丰富知识,但它实际上并没有完全记住所见的信息,难以准确判断自己的知识边界,可能做出错误推断。若让语言模型描述一个不存在的产品,它可能会自行构造出似是而非的细节。这被称为
“幻觉”(Hallucination),是语言模型的一大缺陷。
如何解决幻觉问题?
- Prompt中加入限制词
- 外挂知识库
迭代优化
Prompt 开发也采用类似循环迭代的方式,逐步逼近最优。具体来说,有了任务想法后,可以先编写初版 Prompt,注意清晰明确并给模型充足思考时间。运行后检查结果,如果不理想,则分析 Prompt 不够清楚或思考时间不够等原因,做出改进,再次运行。如此循环多次,终将找到适合应用的 Prompt。
-
优化提示:直接加入长度限制词,
使用最多50个词- 当在 Prompt 中设置长度限制要求时,语言模型生成的输出长度不总能精确符合要求,但基本能控制在可接受的误差范围内。比如要求生成50词的文本,语言模型有时会生成60词左右的输出,但总体接近预定长度。
- 这是因为语言模型在计算和判断文本长度时依赖于分词器,而分词器在字符统计方面不具备完美精度。目前存在多种方法可以尝试控制语言模型生成输出的长度,比如指定语句数、词数、汉字数等。
-
根据回复,不断的增加限制词。
-
可以让模型返回表格。
文本摘要
多条文本:放在一个list里面,然后for遍历
reviews = [review_1, review_2, review_3, review_4]for i in range(len(reviews)):prompt = f"""你的任务是从电子商务网站上的产品评论中提取相关信息。请对三个反引号之间的评论文本进行概括,最多20个词汇。评论文本: ```{reviews[i]}```"""response = get_completion(prompt)print(f"评论{i+1}: ", response, "\n")文本转换
下面是一个示例,展示了如何使用一个Prompt,同时对一段文本进行翻译、拼写纠正、语气调整和格式转换等操作。
prompt = f"""
针对以下三个反引号之间的英文评论文本,
首先进行拼写及语法纠错,
然后将其转化成中文,
再将其转化成优质淘宝评论的风格,从各种角度出发,分别说明产品的优点与缺点,并进行总结。
润色一下描述,使评论更具有吸引力。
输出结果格式为:
【优点】xxx
【缺点】xxx
【总结】xxx
注意,只需填写xxx部分,并分段输出。
将结果输出成Markdown格式。
```{text}```
"""
response = get_completion(prompt)
display(Markdown(response))温度系数
- 大语言模型中的 “温度”(temperature) 参数可以控制生成文本的随机性和多样性。temperature 的值越大,语言模型输出的多样性越大;temperature 的值越小,输出越倾向高概率的文本。
# 第一次运行
prompt = f"""
你是一名客户服务的AI助手。
你的任务是给一位重要的客户发送邮件回复。
根据通过“```”分隔的客户电子邮件生成回复,以感谢客户的评价。
如果情感是积极的或中性的,感谢他们的评价。
如果情感是消极的,道歉并建议他们联系客户服务。
请确保使用评论中的具体细节。
以简明和专业的语气写信。
以“AI客户代理”的名义签署电子邮件。
客户评价:```{review}```
评论情感:{sentiment}
"""
response = get_completion(prompt, temperature=0.7)
print(response)聊天机器人
大型语言模型带给我们的激动人心的一种可能性是,我们可以通过它构建定制的聊天机器人(Chatbot),而且只需很少的工作量。在这一章节的探索中,我们将带你了解如何利用会话形式,与具有个性化特性(或专门为特定任务或行为设计)的聊天机器人进行深度对话。
- 单轮对话:即 get_completion ,其适用于单轮对话。我们将 Prompt 放入某种类似用户消息的对话框中
- get_completion_from_messages ,传入一个消息列表。这些消息可以来自大量不同的角色 (roles) ,我们会描述一下这些角色。
import openai# 下文第一个函数即tool工具包中的同名函数,此处展示出来以便于读者对比
def get_completion(prompt, model="gpt-3.5-turbo"):messages = [{"role": "user", "content": prompt}]response = openai.ChatCompletion.create(model=model,messages=messages,temperature=0, # 控制模型输出的随机程度)return response.choices[0].message["content"]def get_completion_from_messages(messages, model="gpt-3.5-turbo", temperature=0):response = openai.ChatCompletion.create(model=model,messages=messages,temperature=temperature, # 控制模型输出的随机程度)
# print(str(response.choices[0].message))return response.choices[0].message["content"]- 问答
# 中文
messages = [
{'role':'system', 'content':'你是一个像莎士比亚一样说话的助手。'},
{'role':'user', 'content':'给我讲个笑话'},
{'role':'assistant', 'content':'鸡为什么过马路'},
{'role':'user', 'content':'我不知道'} ]response = get_completion_from_messages(messages, temperature=1)
print(response)- 上下文提示
# 中文
messages = [
{'role':'system', 'content':'你是个友好的聊天机器人。'},
{'role':'user', 'content':'Hi, 我是Isa'},
{'role':'assistant', 'content': "Hi Isa! 很高兴认识你。今天有什么可以帮到你的吗?"},
{'role':'user', 'content':'是的,你可以提醒我, 我的名字是什么?'} ]
response = get_completion_from_messages(messages, temperature=1)
print(response)订餐机器人
- 这个机器人将被设计为自动收集用户信息,并接收来自比萨饼店的订单
def collect_messages(_):# panels 就是记录上下文对话,pn.Row()prompt = inp.value_inputinp.value = ''context.append({'role':'user', 'content':f"{prompt}"})response = get_completion_from_messages(context) context.append({'role':'assistant', 'content':f"{response}"})panels.append(pn.Row('User:', pn.pane.Markdown(prompt, width=600)))panels.append(pn.Row('Assistant:', pn.pane.Markdown(response, width=600, style={'background-color': '#F6F6F6'})))return pn.Column(*panels)这个函数将收集我们的用户消息,以便我们可以避免像刚才一样手动输入。这个函数将从我们下面构建的用户界面中收集 Prompt ,然后将其附加到一个名为上下文( context )的列表中,并在每次调用模型时使用该上下文。模型的响应也会添加到上下文中,所以用户消息和模型消息都被添加到上下文中,上下文逐渐变长。这样,模型就有了需要的信息来确定下一步要做什么。
相关文章:

LLM学习《Prompt Engineering for Developer》
Prompt 如何构造好的Prompt 分割符:分隔符就像是 Prompt 中的墙,将不同的指令、上下文、输入隔开,避免意外的混淆。你可以选择用 ,“”",< >, ,: 等做分隔符,只要能明确…...

nginx-获取客户端IP地址
上有服务器与客户端中间是有nginx代理服务器的,上游服务器如何获取客户端真实ip地址? nginx代理服务器设置X-Forwarded-For的header参数,代理服务器通过remote_addr获取客户端ip地址,将ip地址写入nginx代理服务器的X-Forwarded-Fo…...

Redis 高可用之集群搭建和数据分片
Redis 高可用之集群搭建和数据分片 一、简介1. Redis 集群:2. 集群搭建: 二、Redis 集群搭建1. 单机 Redis 升级为 Redis Clustera. 搭建方法b. 搭建方式说明 2. 环境准备3. 配置修改4. 启动集群 三、Redis数据分片的实现Redis数据分片概念说明数据分片的…...

兄弟,王者荣耀的段位排行榜是通过Redis实现的?
目录 一、排行榜设计方案1、数据库直接排序2、王者荣耀好友排行 二、Redis实现计数器1、什么是计数器功能?2、Redis实现计数器的原理(1)使用INCR命令实现计数器(2)使用INCRBY命令实现计数器 三、通过Redis实现“王者荣…...

Linux系统编程--文件编程--打开创建文件
创建文件需要包含以下3个头文件 #include <sys/types.h> #include <sys/stat.h> #include <fcntl.h> 打开、创建文件有以下3个API open的返回值——文件描述符(索引作用),是一个小的非负整数 int open(const char*pathn…...
http协议与apache
http概念: 互联网:是网络的网络,是所有类型网络的母集 因特网:世界上最大的互联网网络。即因特网概念从属于互联网概念 万维网:万维网并非某种特殊的计算机网络,是一个大规模的、联机式的信息贮藏库&…...
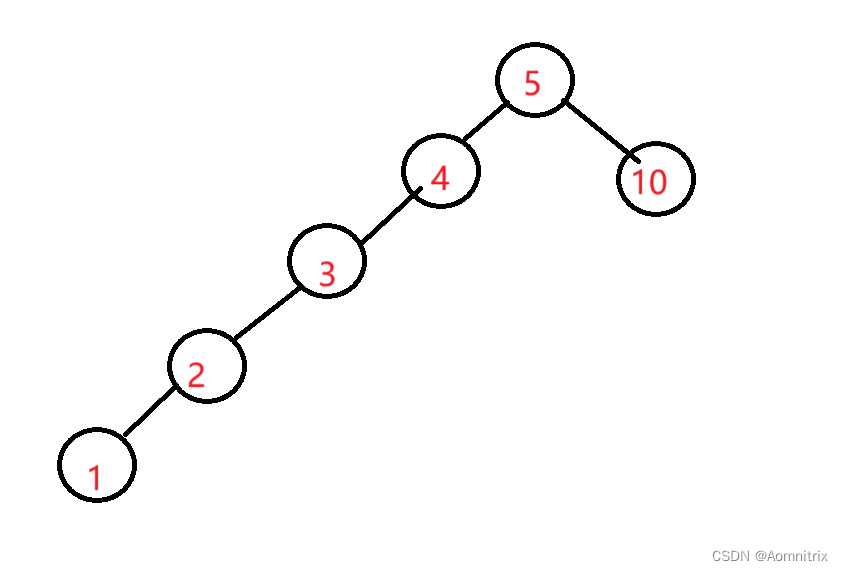
搜索二叉树的算法解析与实例演示
目录 一.搜索二叉树的特性与实现1.特点2.实现二.搜索二叉树的性能 一.搜索二叉树的特性与实现 1.特点 二叉搜索树是特殊的二叉树,它有着更严格的数据结构特点: (1)非空左子树的所有键值小于其根结点的键值。 (2&…...

研磨设计模式day13组合模式
目录 场景 不用模式实现 代码实现 有何问题 解决方案 代码改造 组合模式优缺点 思考 何时选用 场景 不用模式实现 代码实现 叶子对象 package day14组合模式;/*** 叶子对象*/ public class Leaf {/*** 叶子对象的名字*/private String name "";/**…...
之zip)
Linux命令(73)之zip
linux命令之zip 1.zip介绍 linux命令zip是用来压缩文件及解压缩文件名称后缀为".zip"的文件 2.zip用法 zip [参数] filename[.zip] zip常用参数 参数说明-r压缩递归处理-d从压缩文件内删除指定的文件-T检查备份文件是否正确无误-u更换较新的文件到压缩文件内-q不…...

深入理解Reactor模型的原理与应用
1、什么是Reactor模型 Reactor意思是“反应堆”,是一种事件驱动机制。 和普通函数调用的不同之处在于:应用程序不是主动的调用某个 API 完成处理,而是恰恰相反,Reactor逆置了事件处理流程,应用程序需要提供相应的接口并…...

微信小程序开发的投票评选系统设计与实现
摘要 越来越多信息化融入到我们生活当中的同时,也在改变着我们的生活和学习方式,当然,变化最明显的除了我们普通民众之外,要数高校学生的生活方式以及校园信息化的变革。智慧是改变生活和生产的一种来源,那么智慧的体…...

【校招VIP】算法考点之堆排
考点介绍: 排序算法属于数据结构和算法的基础内容,并且也是大厂笔试中的高频考点。 堆排序是使用一棵树存储序列这个课树只保证跟节点是这棵树中的最小值,但并不保证其他节点是按顺序的。因此他的排序是每次从堆中取得堆顶,取得 n…...
关于yarn安装时报“node“ is incompatible with this module的解决办法
前提: 在用vue写一个h5页面时,当在用yarn安装时,提示如下错误: The engine “node” is incompatible with this module. Expected version "^14.18.0 || ^16.14.0 || >18. 解决办法 我是使用命令忽略错误:…...

开源利器推荐:美团动态线程池框架的接入分享及效果展示
前言 蛮早前有些过关于线程池的使用及参数的一些参考配置,有兴趣的可以翻看以前的博文,但终究无法解决线程池的动态监控和实时修改。 以前读过美团早期发布的动态线程池框架的思路相关文章,但想要独自实现不是一件容易的事。 去年,…...

Linux目录结构与文件管理 (02)(四)
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 目录 前言 一、查看文件内容 二、创建文件 三、删除文件 四、 移动文件 五、复制文件 六、编辑文件内容 总结 前言 今天是在昨天的基础上继续学习,主要…...
对1GHz脉冲多普勒雷达进行快速和慢速处理生成5个移动目标的距离多普勒图研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

uni.uploadFile上传 PHP接收不到
开始这样,后端$file $request->file(file);接收不到 数据跑到param中去了 去掉Content-Type,就能接收到了 param只剩下...

2023年高教社杯 国赛数学建模思路 - 复盘:光照强度计算的优化模型
文章目录 0 赛题思路1 问题要求2 假设约定3 符号约定4 建立模型5 模型求解6 实现代码 建模资料 0 赛题思路 (赛题出来以后第一时间在CSDN分享) https://blog.csdn.net/dc_sinor?typeblog 1 问题要求 现在已知一个教室长为15米,宽为12米&…...
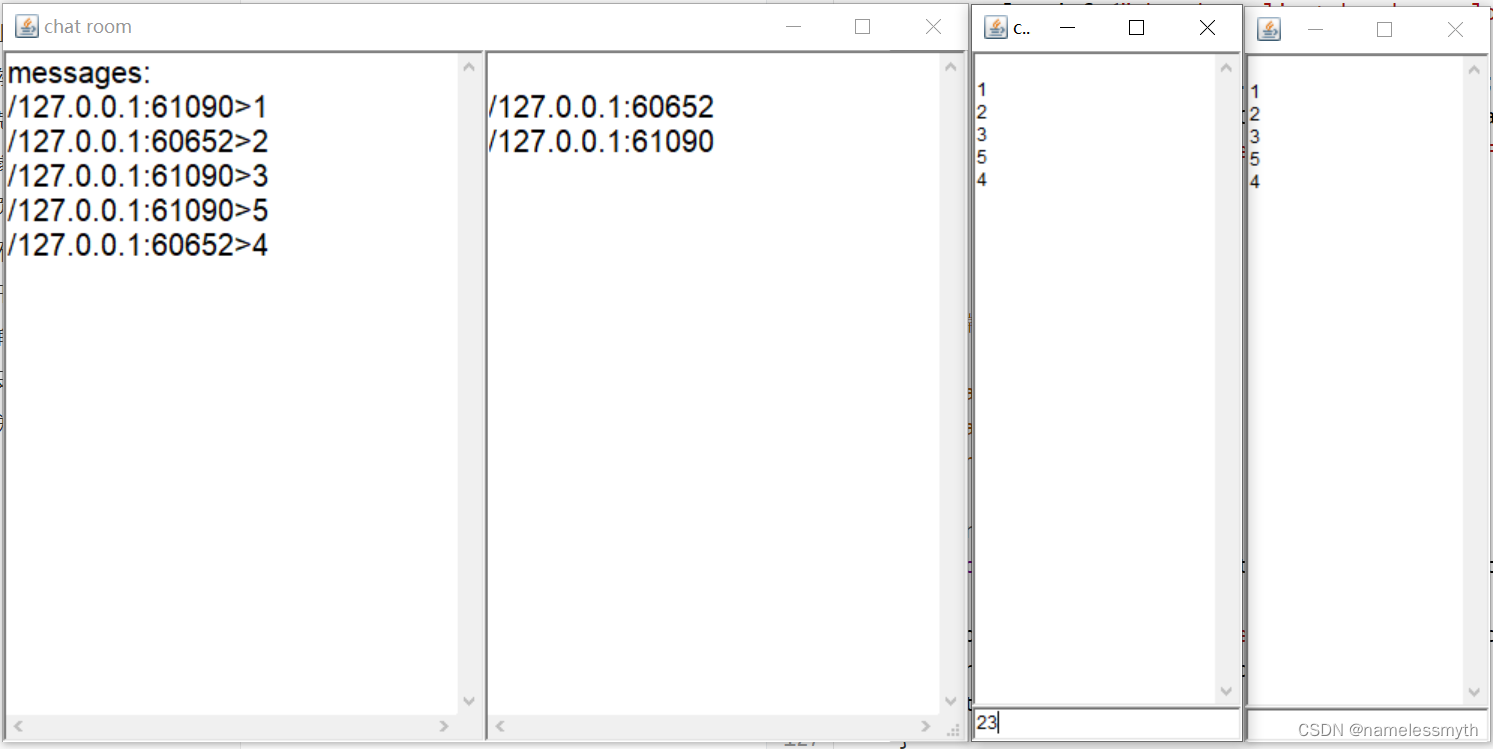
Netty简易聊天室
文章目录 本文目的参考说明环境说明maven依赖日志配置单元测试 功能介绍开发步骤 本文目的 通过一个简易的聊天室案例,讲述Netty的基本使用。同时分享案例代码。项目中用到了log4j2,junit5,同时分享这些基础组件的使用。项目中用到了awt&…...
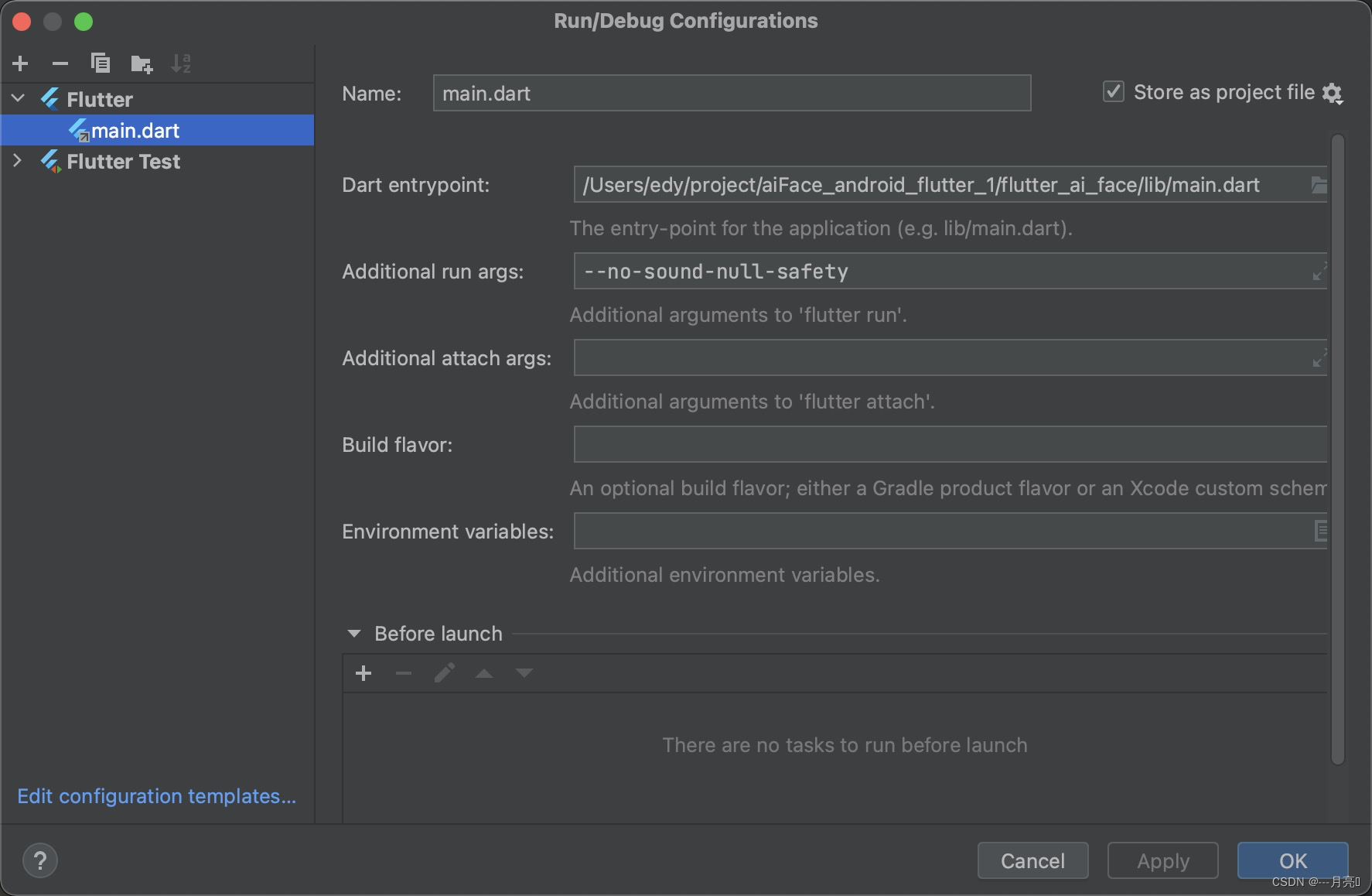
Flutter Cannot run with sound null safety, because the following dependencies
flutter sdk 版本升级到2.0或者更高的版本后,运行之前的代码会报错 Error: Cannot run with sound null safety, because the following dependencies dont support null safety:- package:flutter_swiper- package:flutter_page_indicator- package:transformer_p…...

idea大量爆红问题解决
问题描述 在学习和工作中,idea是程序员不可缺少的一个工具,但是突然在有些时候就会出现大量爆红的问题,发现无法跳转,无论是关机重启或者是替换root都无法解决 就是如上所展示的问题,但是程序依然可以启动。 问题解决…...

uni-app学习笔记二十二---使用vite.config.js全局导入常用依赖
在前面的练习中,每个页面需要使用ref,onShow等生命周期钩子函数时都需要像下面这样导入 import {onMounted, ref} from "vue" 如果不想每个页面都导入,需要使用node.js命令npm安装unplugin-auto-import npm install unplugin-au…...

《从零掌握MIPI CSI-2: 协议精解与FPGA摄像头开发实战》-- CSI-2 协议详细解析 (一)
CSI-2 协议详细解析 (一) 1. CSI-2层定义(CSI-2 Layer Definitions) 分层结构 :CSI-2协议分为6层: 物理层(PHY Layer) : 定义电气特性、时钟机制和传输介质(导线&#…...

Linux相关概念和易错知识点(42)(TCP的连接管理、可靠性、面临复杂网络的处理)
目录 1.TCP的连接管理机制(1)三次握手①握手过程②对握手过程的理解 (2)四次挥手(3)握手和挥手的触发(4)状态切换①挥手过程中状态的切换②握手过程中状态的切换 2.TCP的可靠性&…...

vue3 字体颜色设置的多种方式
在Vue 3中设置字体颜色可以通过多种方式实现,这取决于你是想在组件内部直接设置,还是在CSS/SCSS/LESS等样式文件中定义。以下是几种常见的方法: 1. 内联样式 你可以直接在模板中使用style绑定来设置字体颜色。 <template><div :s…...

相机从app启动流程
一、流程框架图 二、具体流程分析 1、得到cameralist和对应的静态信息 目录如下: 重点代码分析: 启动相机前,先要通过getCameraIdList获取camera的个数以及id,然后可以通过getCameraCharacteristics获取对应id camera的capabilities(静态信息)进行一些openCamera前的…...
详解:相对定位 绝对定位 固定定位)
css的定位(position)详解:相对定位 绝对定位 固定定位
在 CSS 中,元素的定位通过 position 属性控制,共有 5 种定位模式:static(静态定位)、relative(相对定位)、absolute(绝对定位)、fixed(固定定位)和…...

BCS 2025|百度副总裁陈洋:智能体在安全领域的应用实践
6月5日,2025全球数字经济大会数字安全主论坛暨北京网络安全大会在国家会议中心隆重开幕。百度副总裁陈洋受邀出席,并作《智能体在安全领域的应用实践》主题演讲,分享了在智能体在安全领域的突破性实践。他指出,百度通过将安全能力…...

UR 协作机器人「三剑客」:精密轻量担当(UR7e)、全能协作主力(UR12e)、重型任务专家(UR15)
UR协作机器人正以其卓越性能在现代制造业自动化中扮演重要角色。UR7e、UR12e和UR15通过创新技术和精准设计满足了不同行业的多样化需求。其中,UR15以其速度、精度及人工智能准备能力成为自动化领域的重要突破。UR7e和UR12e则在负载规格和市场定位上不断优化…...

自然语言处理——循环神经网络
自然语言处理——循环神经网络 循环神经网络应用到基于机器学习的自然语言处理任务序列到类别同步的序列到序列模式异步的序列到序列模式 参数学习和长程依赖问题基于门控的循环神经网络门控循环单元(GRU)长短期记忆神经网络(LSTM)…...