Spring Boot 整合 分布式搜索引擎 Elastic Search 实现 数据聚合
文章目录
- ⛄引言
- 一、数据聚合
- ⛅简介
- ⚡聚合的分类
- 二、DSL实现数据聚合
- ⏰Bucket聚合
- ⚡Metric聚合
- 三、RestAPI实现数据聚合
- ⌚业务需求
- ⏰业务代码实现
- ✅效果图
- ⛵小结
⛄引言
本文参考黑马 分布式Elastic search
Elasticsearch是一款非常强大的开源搜索引擎,具备非常多强大功能,可以帮助我们从海量数据中快速找到需要的内容
本篇文章将讲解 Elastic Search 如何实现数据聚合,以及 在项目实战中如何通过数据聚合实现业务需求并完成功能。
一、数据聚合
⛅简介
以下为官方 解释:
聚合可以进行各种组合以构建复杂的数据汇总。
可以看作是在一组文档上建立分析信息的工作单元,统计一些文档集。聚合可以将一些独立的功能单元可以被混合在一起来满足你的需求,是一种单独的语法。
kibana的可视化看板就是非常经典的聚合功能的体现。
简单的来说:
聚合 可以让我们极其方便的实现对数据的统计、分析、运算。例如:
- 什么品牌的手机最受欢迎?
- 这些手机的平均价格、最高价格、最低价格?
- 这些手机每月的销售情况如何?
实现这些统计功能的比数据库的sql要方便的多,而且查询速度非常快,可以实现实时搜索效果。
聚合就是类似于垃圾分类,干湿分离,每个桶中装不同的数据。
⚡聚合的分类
聚合主要分为三大类:
- 桶(Bucket) 聚合:用来对文档做分组
- TermAggregation:按照文档字段值分组,例如按照品牌值分组、按照国家分组
- Date Histogram:按照日期阶梯分组,例如一周为一组,或者一月为一组
- 度量(Metric) 聚合:用以计算一些值,比如:最大值、最小值、平均值等
- Avg:求平均值
- Max:求最大值
- Min:求最小值
- Stats:同时求max、min、avg、sum等
- 管道(pipeline) 聚合:其它聚合的结果为基础做聚合
注意: 参加聚合的字段必须是keyword、日期、数值、布尔类型
二、DSL实现数据聚合
例如:要统计所有数据中的酒店品牌有几种,其实就是按照品牌对数据分组。此时可以根据酒店品牌的名称做聚合,也就是Bucket聚合。
⏰Bucket聚合
语法如下:
GET /hotel/_search
{"size": 0, // 设置size为0,结果中不包含文档,只包含聚合结果"aggs": { // 定义聚合"brandAgg": { //给聚合起个名字"terms": { // 聚合的类型,按照品牌值聚合,所以选择term"field": "brand", // 参与聚合的字段"size": 20 // 希望获取的聚合结果数量}}}
}
结果如图:

聚合结果进行数据排序
默认情况下,Bucket聚合会统计Bucket内的文档数量,记为 count,并且按照 _count降序排序。
我们可以指定 order属性,自定义聚合的排序方式:
GET /hotel/_search
{"size": 0, "aggs": {"brandAgg": {"terms": {"field": "brand","order": {"_count": "asc" // 按照_count升序排列},"size": 20}}}
}

限定聚合范围
默认情况下,Bucket聚合是对索引库的所有文档做聚合,但真实场景下,用户会输入搜索条件,因此聚合必须是对搜索结果聚合。那么聚合必须添加限定条件。
我们可以限定要聚合的文档范围,只要添加query条件即可:
GET /hotel/_search
{"query": {"range": {"price": {"lte": 200 // 只对200元以下的文档聚合}}}, "size": 0, "aggs": {"brandAgg": {"terms": {"field": "brand","size": 20}}}
}

⚡Metric聚合
我们对酒店按照品牌分组,形成了一个个桶。现在我们需要对桶内的酒店做运算,获取每个品牌的用户评分的min、max、avg等值。
这就要用到Metric聚合了,例如stat聚合:就可以获取min、max、avg等结果。
语法如下:
GET /hotel/_search
{"size": 0, "aggs": {"brandAgg": { "terms": { "field": "brand", "size": 20},"aggs": { // 是brands聚合的子聚合,也就是分组后对每组分别计算"score_stats": { // 聚合名称"stats": { // 聚合类型,这里stats可以计算min、max、avg等"field": "score" // 聚合字段,这里是score}}}}}
}
这次的score_stats聚合是在 brandAgg 的聚合内部嵌套的子聚合。因为我们需要在每个桶分别计算。
另外,我们还可以给聚合结果做个排序,例如按照每个桶的酒店平均分做排序:

聚合小结
aggs代表聚合,与query同级,此时query的作用是
- 限定聚合的的文档范围
聚合必须的三要素:
- 聚合名称
- 聚合类型
- 聚合字段
聚合可配置属性有:
- size:指定聚合结果数量
- order:指定聚合结果排序方式
- field:指定聚合字段
三、RestAPI实现数据聚合
API语法
聚合条件与query条件同级别,因此需要使用request.source()来指定聚合条件。
聚合条件的语法:

聚合的结果也与查询结果不同,API也比较特殊。不过同样是JSON逐层解析:

⌚业务需求
需求:在搜索页面的品牌、城市等信息不应该是在页面写死,而是通过聚合索引库中的酒店数据得来的:

需求分析:
目前,页面的城市列表、星级列表、品牌列表都是写死的,并不会随着搜索结果的变化而变化。但是用户搜索条件改变时,搜索结果会跟着变化。
例如:用户搜索“天安门”,那搜索的酒店肯定是在虹桥附近,因此,城市只能是上海,此时城市列表中就不应该显示其他城市信息了。
也就是说,搜索结果中包含哪些城市,页面就应该列出哪些城市;搜索结果中包含哪些品牌,页面就应该列出哪些品牌。
如何得知搜索结果中包含哪些品牌?如何得知搜索结果中包含哪些城市?
使用聚合功能,利用Bucket聚合,对搜索结果中的文档基于品牌分组、基于城市分组,就能得知包含哪些品牌、哪些城市了。
因为是对搜索结果聚合,因此聚合是限定范围的聚合,也就是说聚合的限定条件跟搜索文档的条件一致。
查看浏览器可以发现,前端其实已经发出了这样的一个请求:

因此,返回的类型应该是以下

结果是一个Map结构:
- key是字符串,城市、星级、品牌、价格
- value是集合,例如多个城市的名称
⏰业务代码实现
在HotelController中添加一个方法,遵循下面的要求:
- 请求方式:
POST - 请求路径:
/hotel/filters - 请求参数:
RequestParams,与搜索文档的参数一致 - 返回值类型:
Map<String, List<String>>
代码:
@PostMapping("filters")public Map<String, List<String>> getFilters(@RequestBody RequestParams params){return hotelService.getFilters(params);}
这里调用了IHotelService中的getFilters方法,尚未实现。
在IHotelService中定义新方法:
Map<String, List<String>> filters(RequestParams params);
在HotelService中实现该方法:
@Override
public Map<String, List<String>> filters(RequestParams params) {try {// 1.准备RequestSearchRequest request = new SearchRequest("hotel");// 2.准备DSL// 2.1.querybuildBasicQuery(params, request);// 2.2.设置sizerequest.source().size(0);// 2.3.聚合buildAggregation(request);// 3.发出请求SearchResponse response = client.search(request, RequestOptions.DEFAULT);// 4.解析结果Map<String, List<String>> result = new HashMap<>();Aggregations aggregations = response.getAggregations();// 4.1.根据品牌名称,获取品牌结果List<String> brandList = getAggByName(aggregations, "brandAgg");result.put("品牌", brandList);// 4.2.根据品牌名称,获取品牌结果List<String> cityList = getAggByName(aggregations, "cityAgg");result.put("城市", cityList);// 4.3.根据品牌名称,获取品牌结果List<String> starList = getAggByName(aggregations, "starAgg");result.put("星级", starList);return result;} catch (IOException e) {throw new RuntimeException(e);}
}private void buildAggregation(SearchRequest request) {request.source().aggregation(AggregationBuilders.terms("brandAgg").field("brand").size(100));request.source().aggregation(AggregationBuilders.terms("cityAgg").field("city").size(100));request.source().aggregation(AggregationBuilders.terms("starAgg").field("starName").size(100));
}private List<String> getAggByName(Aggregations aggregations, String aggName) {// 4.1.根据聚合名称获取聚合结果Terms brandTerms = aggregations.get(aggName);// 4.2.获取bucketsList<? extends Terms.Bucket> buckets = brandTerms.getBuckets();// 4.3.遍历List<String> brandList = new ArrayList<>();for (Terms.Bucket bucket : buckets) {// 4.4.获取keyString key = bucket.getKeyAsString();brandList.add(key);}return brandList;
}
✅效果图

⛵小结
以上就是【Bug 终结者】对 Spring Boot 整合 分布式搜索引擎 Elastic Search 实现 搜索、分页与结果过滤 的简单介绍,ES搜索引擎无疑是最优秀的分布式搜索引擎,使用它,可大大提高项目的灵活、高效性! 技术改变世界!!!
如果这篇【文章】有帮助到你,希望可以给【Bug 终结者】点个赞👍,创作不易,如果有对【后端技术】、【前端领域】感兴趣的小可爱,也欢迎关注❤️❤️❤️ 【Bug 终结者】❤️❤️❤️,我将会给你带来巨大的【收获与惊喜】💝💝💝!
相关文章:
Spring Boot 整合 分布式搜索引擎 Elastic Search 实现 数据聚合
文章目录 ⛄引言一、数据聚合⛅简介⚡聚合的分类 二、DSL实现数据聚合⏰Bucket聚合⚡Metric聚合 三、RestAPI实现数据聚合⌚业务需求⏰业务代码实现 ✅效果图⛵小结 ⛄引言 本文参考黑马 分布式Elastic search Elasticsearch是一款非常强大的开源搜索引擎,具备非常…...

深入探讨代理技术:保障网络安全与爬虫效率
在当今数字化时代,代理技术在网络安全与爬虫领域扮演着重要角色。从Socks5代理、IP代理,到网络安全和爬虫应用,本文将深入探讨这些关键概念,揭示它们如何相互关联以提高网络安全性和爬虫效率。 1. 代理技术简介 代理技术是一种允…...
【云原生】Docker私有仓库 RegistryHabor
目录 1.Docker私有仓库(Registry) 1.1 Registry的介绍 1.2 Registry的部署 步骤一:拉取相关的镜像 步骤二:进行 Registry的相关yml文件配置(docker-compose) 步骤三:镜像的推送 2. Regist…...

二叉树先序遍历的两种思路
二叉树先序遍历的两种思路 遍历思路 遍历二叉树首先判断一个节点应该做什么然后遍历左子树 遍历右子树 /*** Definition for a binary tree node.* public class TreeNode {* int val;* TreeNode left;* TreeNode right;* TreeNode() {}* TreeNode(int …...
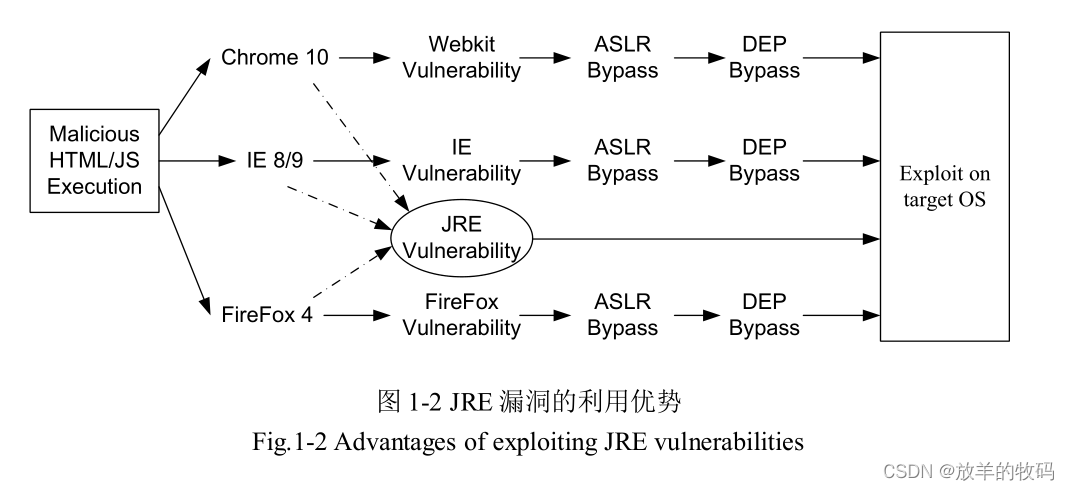
小研究 - JVM 逃逸技术与 JRE 漏洞挖掘研究(一)
Java语言是最为流行的面向对象编程语言之一, Java运行时环境(JRE)拥有着非常大的用户群,其安全问题十分重要。近年来,由JRE漏洞引发的JVM逃逸攻击事件不断增多,对个人计算机安全造成了极大的威胁。研究JRE安…...
好用的可视化大屏适配方案
1、scale方案 优点:使用scale适配是最快且有效的(等比缩放) 缺点: 等比缩放时,项目的上下或者左右是肯定会有留白的 实现步骤 <div className"screen-wrapper"><div className"screen"…...

言有三新书出版,《深度学习之图像识别(全彩版)》上市发行,配套超详细的原理讲解与丰富的实战案例!...
各位同学,今天有三来发布新书了,名为《深度学习之图像识别:核心算法与实战案例(全彩版)》,本次书籍为我写作并出版的第6本书籍。 前言 2019年5月份我写作了《深度学习之图像识别:核心技术与案例…...

英特尔开始加码封装领域 | 百能云芯
在积极推进先进制程研发的同时,英特尔正在加大先进封装领域的投入。在这个背景下,该公司正在马来西亚槟城兴建一座全新的封装厂,以加强其在2.5D/3D封装布局领域的实力。据了解,英特尔计划到2025年前,将其最先进的3D Fo…...

基于大数据+django+mysql的学习资源推送系统的设计与实现(含报告+源码+指导)
本系统为了数据库结构的灵活性所以打算采用MySQL来设计数据库,而Python技术, B/S架构则保证了较高的平台适应性。文中主要是讲解了该系统的开发环境、要实现的基本功能和开发步骤,并主要讲述了系统设计方案的关键点、设计思想。 由于篇幅限制…...

CCF HPC China2023 | 盛大开幕,邀您关注澎峰科技
2023年8月24日,以“算力互联智领未来”为主题的第十九届全国高性能计算学术年会(CCF HPC China 2023)在青岛红岛国际会议展览中心拉开帷幕。特邀嘉宾涵盖行业大咖,主持阵容同样是“重量级”——来自国家并行计算机工程技术研究中心…...

【git进阶使用】 告别只会git clone 学会版本控制 ignore筛选 merge冲突等进阶操作
git使用大全 基本介绍git 快速上手一 环境安装(默认已安装)二 远程仓库克隆到本地1 进入rep文件夹目录2 复制远程仓库地址3 git clone克隆仓库内容到本地4 修改后版本控制4.1 修改文件4.2 git status查看版本库文件状态4.3 git add将文件加入版本库暂存区…...
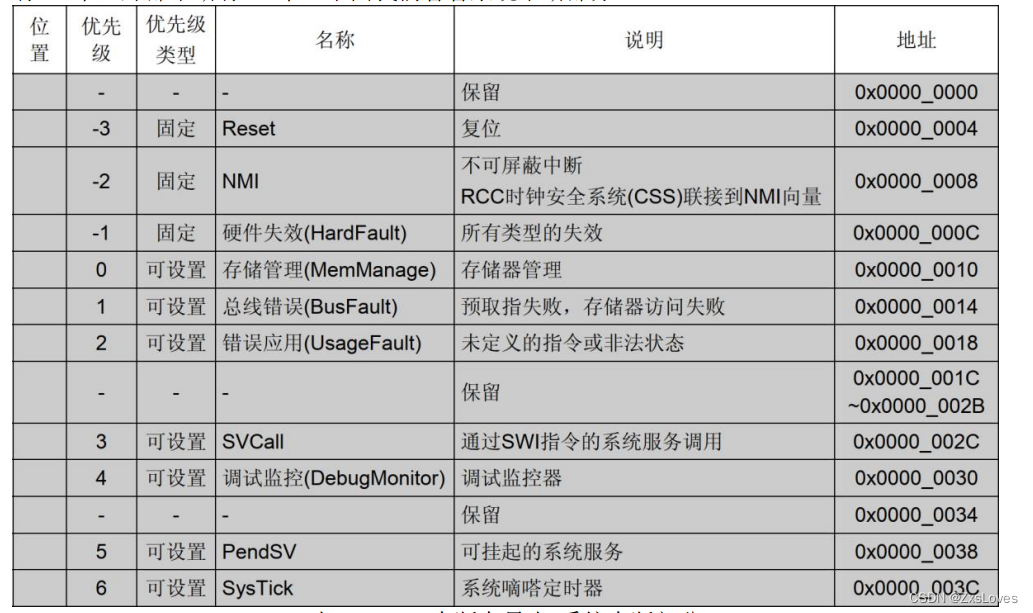
【【萌新的STM32学习-16中断的基本介绍1】】
萌新的STM32学习-16中断的基本介绍1 中断 什么是中断 中断是打断CPU执行正常的程序,转而处理紧急程序,然后返回原暂停的程序继续执行,就叫中断 中断的作用 实时控制 : 就像对温度进行控制 故障控制 : 第一时间对突发情…...
ctfshow-红包题第二弹
0x00 前言 CTF 加解密合集CTF Web合集 0x01 题目 0x02 Write Up 同样,先看一下有没有注释的内容,可以看到有一个cmd的入参 执行之后可以看到文件代码,可以看到也是eval,但是中间对大部分的字符串都进行了过滤,留下了…...

C# winform中无标题栏窗口如何实现鼠标拖动?
文章目录 在C#中,可以通过重写窗体的鼠标事件来实现无标题栏窗体的拖动。 具体步骤如下: 禁用窗体的默认标题栏:在窗体属性中设置FormBorderStyle为None。 重写鼠标事件:在窗体类中重写MouseDown、MouseMove和MouseUp事件。 定义变量存储鼠标点击时的坐标。 在MouseDown事…...

【操作系统】各平台定时器粒度
文章目录 WindowsLinux Windows 在 Windows 操作系统中,定时器的精度取决于系统时钟的精度。通常情况下,Windows 系统时钟的精度为 15.6 毫秒(即每秒钟约 64 次时钟中断),因此定时器的最小精度也是 15.6 毫秒。但是&a…...

抽象又有点垃圾的JavaScript
常数的排序 let x 10;let y 20;let z;if (x < y) {z x;x y;y z;}console.log(x, y);//x 20 ,y 10 通过一个媒介来继承x的初始值,然后将y的值赋值给x,再把媒介z的值赋值给y,达到排序 一个可重复使用的排序程序 第一种 function s…...
【Spring Boot】使用Spring Boot进行transformer的部署与开发
Transformer是一个用于数据转换和处理的平台,使用Spring Boot可以方便地进行Transformer的部署与开发。 以下是使用Spring Boot进行Transformer部署与开发的步骤: 创建Spring Boot项目 可以使用Spring Initializr创建一个简单的Spring Boot项目。在创…...
Qt应用开发(基础篇)——富文本浏览器 QTextBrowser
一、前言 QTextBrowser类继承于QTextEdit,是一个具有超文本导航的富文本浏览器。 框架类 QFramehttps://blog.csdn.net/u014491932/article/details/132188655 滚屏区域基类 QAbstractScrollAreahttps://blog.csdn.net/u014491932/article/details/132245486 文…...

JDBC:更新数据库
JDBC:更新数据库 更新记录删除记录 为了更新数据库,您需要使用语句。但是,您不是调用executeQuery()方法,而是调用executeUpdate()方法。 可以对数据库执行两种类型的更新: 更新记录值删除记录 executeUpdate()方…...
如何自定义iview树形下拉内的内容
1.使用render函数给第一层父级定义 2. 使用树形结构中的render函数来定义子组件 renderContent(h, {root, node, data}) {return data.children.length0? h(span, {style: {display: inline-block,width: 400px,lineHeight: 32px}}, [h(span, [h(Icon, {type: ios-paper-outli…...

UPF实战指南:解锁芯片低功耗设计的自动化与验证核心
1. UPF:芯片低功耗设计的自动化基石 当你面对一个包含7个电压域、300多万个逻辑单元的芯片设计时,手动插入电源开关和电平转换器就像用绣花针建造摩天大楼——不仅效率低下,而且错误百出。这正是UPF(统一功耗格式)的价…...

ROS2与OpenCV多线程优化:高效抓取RTSP视频流的实践指南
1. 为什么需要多线程优化RTSP视频流处理 最近在做一个机器人视觉项目时,我发现直接用ROS2订阅RTSP视频流会出现严重的丢帧问题。当时的情况是这样的:每当机器人移动时,视频流就会变得卡顿,有时甚至会丢失关键帧。经过排查…...

Flutter + OpenHarmony 性能调优实战:从内存泄漏排查到功耗控制,构建高效鸿蒙应用
1. 为什么性能优化是鸿蒙应用的生命线? 在OpenHarmony生态中,用户对卡顿的容忍度正在急剧下降。我实测过一组数据:当应用启动时间超过1.5秒时,智能手表用户的放弃率会飙升到62%;当列表滚动出现明显掉帧时,超…...

渗透率超50%!AI家电告别噱头,中国家电业的变革与隐忧
前言:AI不再是营销噱头,家电业真的变天了最近,AWE2026在上海开幕,一组数据彻底打破了我的固有认知:2025年中国人工智能家电渗透率已超过50%,彩电AI渗透率更是高达70%以上。这意味着,现在走进电器…...

语音标注新范式:Qwen3-ForcedAligner-0.6B在Python数据分析中的应用
语音标注新范式:Qwen3-ForcedAligner-0.6B在Python数据分析中的应用 1. 引言 语音数据处理一直是数据分析领域的难点,特别是如何将音频内容与文本准确对齐,获取精确的时间戳信息。传统方法往往需要复杂的音素标注和专业的语言学知识&#x…...

Lychee-Rerank参数调优实战:针对特定领域数据的微调策略
Lychee-Rerank参数调优实战:针对特定领域数据的微调策略 你是不是也遇到过这种情况?用一个通用的文本排序模型来处理自己行业的数据,比如医疗报告、金融合同或者法律条文,总觉得效果差那么点意思。模型好像能理解,但又…...

元脉网络旗舰级本土芯片交换机S12700 打造数智化园区新引擎
在数字经济与产业变革深度融合的时代背景下,园区作为经济发展与科技创新的核心载体之一,正迎来全方位的数智化变革浪潮。近日,元脉网络推出基于本土芯片设计的旗舰级园区核心交换机——S12700系列,兼具无阻塞转发、多维可靠、全栈…...

用Selenium操控寺庙:香火钱自动分账系统
一、系统架构与测试挑战寺庙香火分账系统采用“支付-清算-分账”三层架构:前端支付层:多殿堂独立收款码(微信/支付宝/云闪付)及现金通道,需兼容老年香客的无感支付流程规则引擎层:预设阶梯分账比例…...

TypeScript+React 全栈生态实战:从架构选型到工程落地,告别开发踩坑
目录 前言 为什么说这套技术栈是全栈开发的最优解? 1、TypeScript:全栈开发的"类型安全护城河" 2、ReactNext.js:前端工程化的"效率利器" 3、MongoDBMongoose:非关系型数据库的"实战指南" 4、…...

稳转细胞株构建全攻略:从理论到实践的生物制药核心技术解析
为何稳转细胞株成为生物制药领域的“兵家必争之地”?稳转细胞株被称为“药物研发的基石”,是单克隆抗体、双抗、疫苗、ADC等生物制品规模化生产的核心环节,还是药物生产成本、效率和质量的关键决定因素。一株高产稳定的细胞株有可能直接缩短药…...