MySQL数据备份与恢复
备份的主要目的:
备份的主要目的是:灾难恢复,备份还可以测试应用、回滚数据修改、查询历史数据、审计等。
日志:
MySQL 的日志默认保存位置为:
/usr/local/mysql/data
##配置文件
vim /etc/my.cnf
[mysqld]
##错误日志,用来记录当MySQL启动、停止或运行时发生的错误信息,默认已开启
log-error=/usr/local/mysql/data/mysql_error.log #指定日志的保存位置和文件名
##通用查询日志,用来记录MySQL的所有连接和语句,默认是关闭的
general_log=ON
general_log_file=/usr/local/mysql/data/mysql_general.log
##二进制日志(binlog),用来记录所有更新了数据或者已经潜在更新了数据的语句,记录了数据的更改,可用于数据恢复,默认已开启
log-bin=mysql-bin
或
log_bin=mysql-bin
##中继日志
一般情况下它在Mysql主从同步(复制)、读写分离集群的从节点开启。主节点一般不需要这个日志
##慢查询日志,用来记录所有执行时间超过long_query_time秒的语句,可以找到哪些查询语句执行时间长,以便提醒优化,默认是关闭的
s1ow_query_log=ON
slow_query_log_file=/usr/local/mysql/data/mysql_slow_query.log
long_query_time=5 #设置超过5秒执行的语句被记录,缺省时为10秒
##复制段
log-error=/usr/local/mysql/data/mysql_error.log
general_log=ON
general_log_file=/usr/local/mysql/data/mysql_general.log
log-bin=mysql-bin
slow_query_log=ON
slow_query_log_file=/usr/local/mysql/data/mysql_slow_query.log
long_query_time=5
systemctl restart mysqld
mysql -u root -p
show variables like 'general%'; #查看通用查询日志是否开启
show variables like 'log_bin%'; #查看二进制日志是否开启
show variables like '%slow%'; #查看慢查询日功能是否开启
show variables like 'long_query_time'; #查看慢查询时间设置
set global slow_query_log=ON; #在数据库中设置开启慢查询的方法PS:variables 表示变量 like 表示模糊查询#xxx(字段)
xxx% 以xxx为开头的字段
%xxx 以xxx为结尾的字段
%xxx% 只要出现xxx字段的都会显示出来
xxx 精准查询#二进制日志开启后,重启mysql 会在目录中查看到二进制日志
cd /usr/local/mysql/data
ls
mysql-bin.000001 #开启二进制日志时会产生一个索引文件及一个索引列表索引文件:记录更新语句
索引文件刷新方式:
1、重启mysql的时候会更新索引文件,用于记录新的更新语句
2、刷新二进制日志mysql-bin.index:
二进制日志文件的索引
二、数据备份的重要性:
在企业中,数据的价值至关重要,数据保障了企业业务的正常运行。因此,数据的安全性及数据的可靠性是运维的重中之重,任何数据的丢失都可能对企业产生严重的后果。
1、备份的主要目的是灾难恢复
2、在生产环境中,数据的安全性至关重要
3、任何数据的丢失都可能产生严重的后果
4、造成数据丢失的原因
通常情况下,造成数据丢失的原因通常有以下几种:
①程序错误
②人为操作错误
③运算错误
④磁盘故障
⑤灾难(火灾、地震)and 盗窃(黑客攻击)
三、备份类型
数据备份的分类:
从物理与逻辑的角度分类可以分为:逻辑备份、物理备份。
1.物理备份:对数据库操作系统的物理文件(如数据文件、日志文件等)的备份
物理备份方法:
①.冷备份(脱机备份):是在关闭数据库的时候进行的。
②热备份(联机备份):数据库处于运行状态,依赖于数据库的日志文件。
③温备份:数据库锁定表格(不可写入但可读)的状态下进行备份操作。
2.逻辑备份:对数据库逻辑组件(如:表等数据库对象)的备份。表示为逻辑数据库结构
这种类型的备份适用于可以编辑数据值或表结构 。
从数据库的备份策略角度,备份分类可以分为:完全备份、差异备份、增量备份。
完全备份: 每次对数据进行完整的备份,即对整个数据库、数据库结构和文件结构的备份,保存的是备份完成时刻的数据库,是差异备份与增量备份的基础。完全备份的备份与恢复操作都非常简单方便,但是数据存在大量的重复,并且会占用大量的磁盘空间,备份的时间也很长。

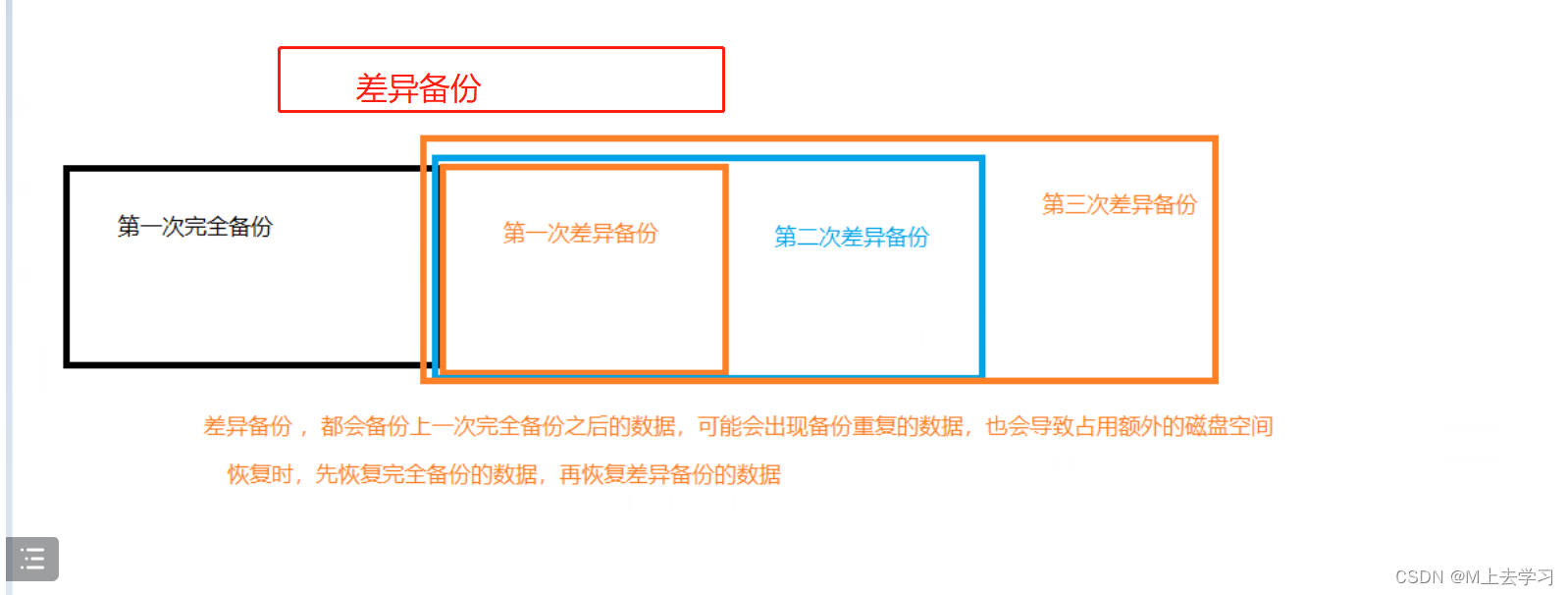
差异备份: 备份那些自从上次完全备份之后被修改过的所有文件,备份的时间节点是从上次完整备份起,备份数据量会越来越大。恢复数据时,只需恢复上次的完全备份与最近的一次差异备份。
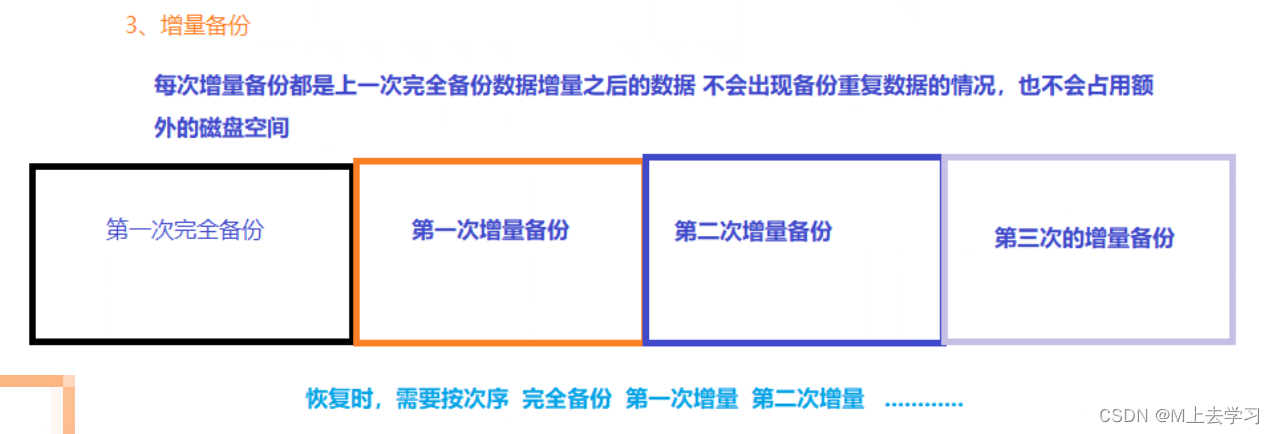
增量备份: 只有在上次完全备份或者增量备份后被修改的文件才会被备份。以上次完整备份或上次增量备份的时间为时间点,仅备份这之间的数据变化,因而备份的数据量小,占用空间小,备份速度快。但恢复时,需要从上一次的完整备份开始到最后一次增量备份之的所有增量依次恢复,如中间某次的备份数据损坏,将导致数据的丢失。
备份方式比较:
备份方式 完全备份 差异备份 增量备份
完全备份时的状态 表1、表2 表1、表2 表1、表2
第1次添加内容 创建表3 创建表3 创建表3
备份内容 表1、表2、表3 表3 表3
第2次添加内容 创建表4 创建表4 创建表4
备份内容 表1、表2、表3、表4 表3、表4 表4
逻辑备份的策略(增、全、差异)
如何选择逻辑备份策略(频率)
合理值区间⭐⭐⭐
一周一次的全备,全备的时间需要在不提供业务的时间区间进行 PM 10点 AM 5:00之间进行全备
增量:3天/2天/1天一次增量备份
差异:选择特定的场景进行备份
一个处理(NFS)提供额外空间给与mysql 服务器用
常见的备份方法:
1、物理冷备
物理冷备份时需要在数据库处于关闭状态下,能够较好地保证数据库的完整性。
物理冷备份一般用于非核心业务,这类业务一般都允许中断。
物理冷备份的特点就是速度快,恢复时也是最为简单的。
通常通过直接打包(tar-cf)数据库文件夹(/usr/local/mysql/data)来实现备份。
2、专用备份工具mydump或者mysqlhotcopy:
①mysqldump程序和mysqlhotcopy都可以做备份。
②mysqldump是客户端常用逻辑备份程序,能够产生一组被执行以后再现原始数据库对象定义和表数据的SQL语句。它可以转储一个到多个MySQL数据库,对其进行备份或传输到远程SQL服务器。mysqldump更为通用,因为它可以备份各种表。
③mysqlhotcopy仅适用于某些存储引擎(MyISAM和ARCHIVE)。
3、启用二进制日志进行增量备份:
①进行增量备份,需要刷新二进制日志
②mysql支持增量备份,进行增量备份时必须启用二进制日志。
二进制日志文件为用户提供复制,对执行备份点后进行的数据库更改所需的信息进行恢复。
如果进行增量备份(包含自上次完全备份或增量备份以来发生的数据修改) ,需要刷新二进制日志
4、通过第三方工具备份:
使用免费的第三方Percona xtraBackup热备份软件,支持在线热备份Innodb和xtraDB,也可以支持MySQL表备份,不过MyISAM表的备份要在表锁的情况下进行。
四、MySQL完全备份
是对整个数据库、数据库结构和文件结构的备份
保存的是备份完成时刻的数据库
是差异备份与增量备份的基础
1、优点:
备份与恢复操作简单方便。
2、缺点:
数据存在大量的重复、占用大量的备份空间,备份与恢复时间长。
数据库完全备份分类:
1、物理冷备份与恢复
关闭MySQL数据库
使用tar命令直接打包数据库文件夹
直接替换现有MySQL目录即可
2、mysqldump备份与恢复
MySQL自带的备份工具,可方便实现对MySQL的备份
可以将指定的库、表导出为SQL 脚本
使用命令mysq|导入备份的数据
五、实验部分
环境准备:
use MY;
create table if not exists info (
id int(4) not null auto_increment,
name varchar(10) not null,
age char(10) not null,
hobby varchar(50),
primary key (id));
#创建一个名为"info"的MySQL表格。表格包含四个列,分别是"id"、"name"、"age"和"hobby"。其中,"id"是一个4位整数,不为空且自动递增;"name"是一个最大长度为10的字符串,不为空;"age"是一个最大长度为10的字符型,不为空;"hobby"是一个最大长度为50的字符串,可以为空。此外,"id"列被指定为主键。insert into info values(1,'user1',20,'running');
insert into info values(2,'user2',30,'singing');
插入两行数据
MySQL完全备份与恢复:
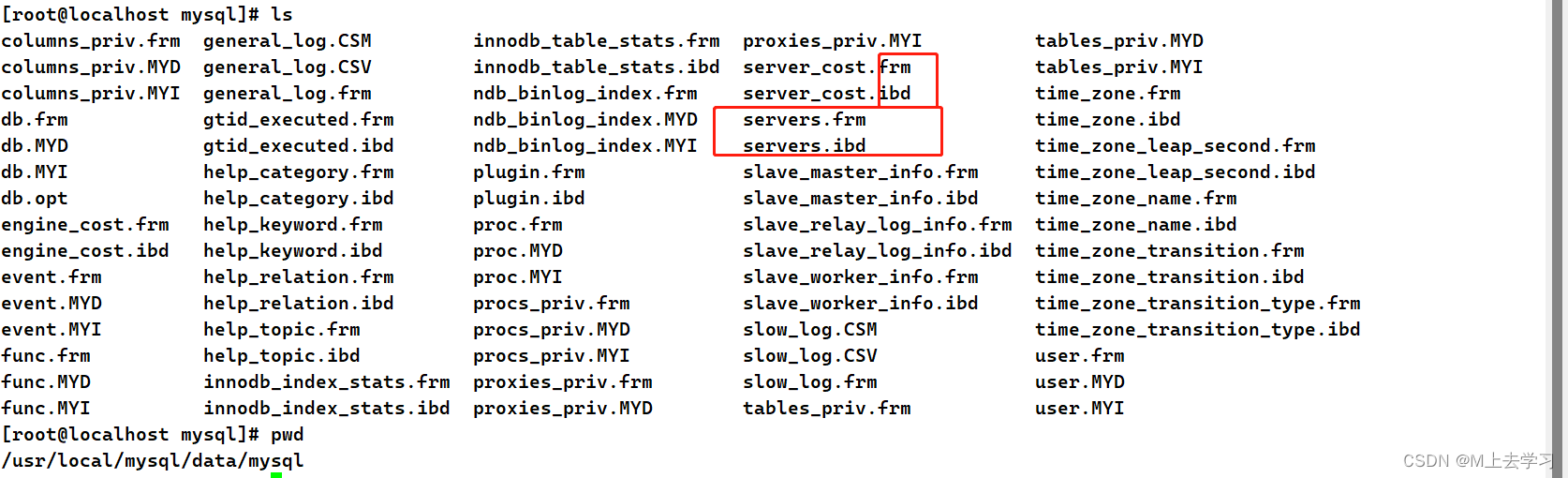
InnoDB 存储引擎的数据库在磁盘上存储成三个文件: db.opt(表属性文件)、表名.frm(表结构文件)、表名.ibd(表数据文件)。
在/usr/local/mysql/data/中
1.物理冷备份与恢复
systemctl stop mysqld #命令来停止 mysqld 进程
yum -y install xz #安装 xz 压缩工具,xz 是一种高效的压缩工具,可以将文件压缩到很小的体积。
压缩备份:
tar -jcvf /opt/mysql_all_$(date +%F).tar.xz /usr/local/mysql/data/
#将 /usr/local/mysql/data/ 目录下的 MySQL 数据库文件打包并压缩为一个 .tar.xz 文件,然后将其保存到 /opt/ 目录下。其中 $(date +%F) 表示将当前日期格式化为 YYYY-MM-DD 的形式,用于在备份文件名中添加日期
mv /usr/local/mysql/data/ /opt/
#将/usr/local/mysql/data/ 目录下的 MySQL 数据库文件移动到 /opt/ 目录下
解压恢复:
tar -jxvf /opt/mysql_all_2023-08-29.tar.xz -C /usr/local/mysql/data/
#解压缩备份文件 /opt/mysql_all_2023-08-29.tar.xz 并将其恢复到 /usr/local/mysql/data/ 目录下
cd /usr/local/mysql/data
mv /usr/local/mysql/data/* ./
#将 /usr/local/mysql/data/ 目录下的所有文件和子目录移动到当前工作目录下。
- mysqldump 备份与恢复(温备份)
数据库还是之前创建的MY库
create table info1 (id int,name char(10),age int,sex char(4));
insert into info1 values(1,'user',11,'性别');
insert into info1 values(2,'user',11,'性别');
1、完全备份一个或多个完整的库 (包括其中所有的表)
mysqldump -u root -p[密码] --databases 库名1 [库名2] ... > /备份路径/备份文件名.sql #导出的就是数据库脚本文件
例:
mysqldump -u root -p --databases MY > /opt/kgc.sql #备份一个MY库
mysqldump -u root -p --databases mysql MY > /opt/mysql-MY.sql #备份mysql与 kgc两个库
2、完全备份 MySQL 服务器中所有的库
mysqldump -u root -p[密码] --all-databases > /备份路径/备份文件名.sql
例:
mysqldump -u root -p --all-databases > /opt/all.sql
3、完全备份指定库中的部分表
mysqldump -u root -p[密码] 库名 [表名1] [表名2] ... > /备份路径/备份文件名.sql
例:
mysqldump -u root -p [-d] kgc info info1 > /opt/MY_info1.sql
#使用“-d”选项,说明只保存数据库的表结构
#不使用“-d"选项,说明表数据也进行备份
#做为一个表结构模板
(4)查看备份文件
grep -v "^--" /opt/MY_info1.sql | grep -v "^/" | grep -v "^$"
Mysql 完全恢复:
恢复数据库:
1.使用mysqldump导出的文件,可使用导入的方法
source命令
mysql命令
1.mysql> use mydatabase;
2.mysql> source /backup/all-data.sql;
2.使用source恢复数据库的步骤
登录到MySQL数据库:mysql -u 用户名 -p 密码
执行source备份sql脚本的路径
mysql> source /backup/all-data.sql;3.source恢复的示例
MySQL [(none)]> source /backup/all-data.sql
#MySQL [(none)]> 是 MySQL 命令行客户端的提示符,表示当前没有选择任何数据库。
#/backup/all-data.sql 是 SQL 脚本文件的路径。执行这个命令后,MySQL 将会读取并执行 /backup/all-data.sql 文件中的 SQL 语句,从而将其中的数据导入到 MySQL 数据库中
使用source命令恢复数据
1.模拟数据库出现问题:
mysql -uroot -pabc123 登录数据库
mysql> show databases; 查看数据库信息
mysql> drop database school; 删除数据库school
mysql> show databases;
2 应用示例:
创建备份(对表进行备份)
mysqldump -uroot -123 MY info > /opt/info.sql
将MY数据库中的info表进行删除数据库:mysql -uroot -p123 登录数据库show tables;drop table MY.info;或者直接执行下面的语句直接删除:
mysql -uroot -p123 -e 'drop table MY.info;' #删除数据库的表
恢复数据表:
mysql -uroot -p123select * from info; 查询所有字段
show tables; 查看表信息
或免交互l> source /opt/info.sql
mysql -uroot -p123123 -e 'show tables from school;'
方式二:
mysql -uroot -p123 MY < /opt/MY.info.sql #恢复info表mysql -uroot -p123 -e 'show tables from MY;' #查看info表
PS:mysqldump 严格来说属于温备份,会需要对表进行写入的锁定
在全量备份与恢复实验中,假设现有MY库,MY库中有一个info1表,需要注意的一点为:
① 当备份时加 --databases ,表示针对于MY库
#备份命令:
mysqldump -uroot -p123 --databases MY > /opt/MY_01.sql 备份库后
#恢复过程为:
mysql -uroot -p123
drop database ;
exit
mysql -uroot -p123 < /opt/MY_01.sql
② 当备份时不加 --databases,表示针对MY库下的所有表
#备份命令
mysqldump -uroot -p123 > /opt/MY_all.sql
#恢复过程:
mysql -uroot -p123
drop database MY;
create database MY;
exit
mysql -uroot -p123 MY < /opt/MY_02.sql 查看MY_01.sql 和MY_02.sql 主要原因在于两种方式的备份(前者会从"create databases"开始,而后者则全是针对表格进行操作) 4.在生产环境中,可以使用Shell脚本自动实现定时备份(时间频率需要确认)
0 1 * * 6 /usr/local/mysql/bin/mysqldump -uroot -p123 MY info1 > ./MY_info1_$(date +%Y%m%d).sql ;/usr/local/mysql/bin/mysqladmin -u root -p flush-logs
# 0 1 * * 6 表示在每周的第六天(即星期六)的凌晨 1 点执行备份任务。
/usr/local/mysql/bin/mysqldump -uroot -p123 MY info1 > ./MY_info1_$(date +%Y%m%d).sql 表示执行备份操作,使用 mysqldump 工具备份 MySQL 数据库中的 MY 数据库中的 info1 表,并将备份结果输出到当前目录下以日期命名的备份文件中,例如 ./MY_info1_20220101.sql。
;/usr/local/mysql/bin/mysqladmin -u root -p flush-logs 表示执行刷新 MySQL 日志文件的操作,使用 mysqladmin 工具刷新 MySQL 的日志文件
MySQL 增量备份与恢复:
MySQL数据库增量恢复
1.一般恢复
将所有备份的二进制日志内容全部恢复
2.基于位置恢复
数据库在某一时间点可能既有错误的操作也有正确的操作
可以基于精准的位置跳过错误的操作
发生错误节点之前的一个节点,上一次正确操作的位置点停止
3.基于时间点恢复
跳过某个发生错误的时间点实现数据恢复
在错误时间点停止,在下一个正确时间点开始
----------MySQL 增量备份------------
一、增备实验
1.开启二进制日志功能
vim /etc/my.cnf
[mysqld]
log-bin=mysql-bin
binlog_format = MIXED #可选,指定二进制日志(binlog)的记录格式为MIXED(混合输入)
server-id = 1 #可加可不加该命令
二进制日志(binlog)有3种不同的记录格式: STATEMENT (基于SQL语句)、ROW(基于行)、MIXED(混合模式),默认格式是STATEMENT
① STATEMENT(基于SQL语句):
每一条涉及到被修改的sql 都会记录在binlog中
缺点:日志量过大,如sleep()函数,last_insert_id()>,以及user-defined fuctions(udf)、主从复制等架构记录日志时会出现问题
总结:增删改查通过sql语句来实现记录,如果用高并发可能会出错,可能时间差异或者延迟,可能不是我们想想的恢复可能你先删除或者在修改,可能会倒过来。准确率底
② ROW(基于行)
只记录变动的记录,不记录sql的上下文环境
缺点:如果遇到update…set…where true 那么binlog的数据量会越来越大
总结:update、delete以多行数据起作用,来用行记录下来,
只记录变动的记录,不记录sql的上下文环境,
比如sql语句记录一行,但是ROW就可能记录10行,但是准确性高,高并发的时候由于操作量,性能变低 比较大所以记录都记下来,
③ MIXED 推荐使用
一般的语句使用statement,函数使用ROW方式存储。
systemctl restart mysqld
查看二进制日志文件的内容
cp /usr/local/mysql/data/mysql-bin.000002 /opt/① mysqlbinlog --no-defaults /opt/mysql-bin.000002mysqlbinlog --no-defaults --base64-output=decode-rows -v /opt/mysql-bin.000002#--base64-output=decode-rows:使用64位编码机制去解码(decode)并按行读取(rows)
#-v: 显示详细内容
#--no-defaults : 默认字符集(不加会报UTF-8的错误)
PS: 可以将解码后的文件导出为txt格式,方便查阅
mysqlbinlog --no-defaults --base64-output=decode-rows -v /opt/mysql-bin.000002 > /opt/mysql-bin.000002
二进制日志中需要关注的部分:
1、at :开始的位置点
2、end_log_pos:结束的位置
3、时间戳: 23082910:30:30
4、SQL语句
2.进行完全备份(增量备份时基于完全备份的,所以我们直接完全备份数据库)
mysqldump -uroot -p MY info > /opt/MY_info1_$(date +%F).sql#使用了 mysqldump 工具,用于备份 MySQL 数据库中的 MY 数据库中的 info 表。其中 -uroot 表示使用 root 用户登录,-p 表示需要输入密码,MY 表示要备份的数据库名,info 表示要备份的数据表名。> 表示将备份结果输出到指定的文件中,/opt/MY_info1_$(date +%F).sql 表示备份文件的路径和文件名,其中 $(date +%F) 表示当前日期,mysqldump -uroot -p MY > /opt/MY_all_$(date +%F).sql#用 mysqldump 工具备份 MySQL 数据库中的 MY 数据库中的所有数据表。其中 -uroot 表示使用 root 用户登录,-p 表示需要输入密码,MY 表示要备份的数据库名。> 表示将备份结果输出到指定的文件中,/opt/MY_all_$(date +%F).sql 表示备份文件的路径和文件名,其中 $(date +%F)3.可每天进行增量备份操作,生成新的二进制日志文件(例如:mysql-bin.000002)
mysqladmin -u root -p flush-logs
4.插入新数据,以模拟数据的增加或变更
PS:在第一次完全备份之后刷新二进制文件,在第二个二进制文件中记载着"增量备份的数据"
mysql> create database MY;
Query OK, 1 row affected (0.00 sec)mysql> use MY;
Database changed
mysql> create table info1 (id int(4),name varchar(4));
Query OK, 0 rows affected (0.00 sec)mysql> insert into info1 values(1,'one');
Query OK, 1 row affected (0.00 sec)mysql> insert into info1 values(2,'two');
Query OK, 1 row affected (0.00 sec)mysql> select * from info;
+------+------+
| id | name |
+------+------+
| 1 | one |
| 2 | two |
+------+------+
2 rows in set (0.00 sec)
5.再次生成新的二进制日志文件(例如:mysql-bin.000003)
mysqladmin -u root -p flush-logs
#之前的步骤4的数据库操作会保存到mysql-bin.000002文件中,之后我们测试删除MY库的操作会保存在mysql-bin.000003文件中 (以免当我们基于mysql-bin.000002日志进行恢复时,依然会删除库)
MySQL增量恢复:
1.一般恢复(直接使用二进制文件恢复)
(1)、模拟丢失更改的数据的恢复步骤
① 备份MY库中test1表
mysqldump -uroot -p123123 MY test1 > /opt/MY_test13.sql
② 删除MY库中test1表
drop table MY.test1;
③ 恢复test1表
mysql -uroot -p ky13 < info-2023-08-29.sql
#查看日志文件
mysqlbinlog --no-defaults --base64-output=decode-rows -v mysql-bin.000002
2、模拟丢失所有数据的恢复步骤
① 模拟丢失所有数据
mysql -uroot -p123
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| MY |
| mysql |
| performance_schema |
| school |
| sys |
| test |
+--------------------+
7 rows in set (0.00 sec)
mysql> drop database MY;
Query OK, 1 row affected (0.00 sec)mysql> exit
② 基于mysql-bin.000002恢复
mysqlbinlog --no-defaults /opt/mysql-bin.000002 | mysql -u root -p
2.断点恢复
基于位置点恢复
mysqlbinlog --no-defaults --base64-output=decode-rows -v /opt/mysql-bin.000002
例:
at 302
#230830 15:21:16
插入了"user3"的用户数据
#at 623
#230830 15:21:20
插入了"user4"的用户数据
(1)、基于位置恢复
① 插入三条数据
mysql> use MY;mysql> select * from test1;
+------+------+
| id | name |
+------+------+
| 1 | one |
| 2 | two |
+------+------+
2 rows in set (0.00 sec)mysql> insert into test1 values(3,'true');
Query OK, 1 row affected (0.00 sec)mysql> insert into test1 values(4,'f');
Query OK, 1 row affected (0.00 sec)mysql> insert into test1 values(5,'t');
Query OK, 1 row affected (0.00 sec)mysql> select * from test1;
+------+------+
| id | name |
+------+------+
| 1 | one |
| 2 | two |
| 3 | true |
| 4 | f |
| 5 | t |
+------+------+
5 rows in set (0.00 sec)#需求:以上id =4的数据操作失误,需要跳过
② 确认位置点,刷新二进制日志并删除test1表
mysqlbinlog --no-defaults --base64-output=decode-rows -v /opt/mysql-bin.000003
960 停止
1066 开始#刷新日志
mysqladmin -uroot -p123 flush-logsmysql> use MY;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -ADatabase changed
mysql> show tables;
+----------------+
| Tables_in_MY |
+----------------+
| test1 |
+----------------+
1 row in set (0.00 sec)mysql> drop table MY.test1;
Query OK, 0 rows affected (0.00 sec)
③ 基于位置点恢复
--stop-position #之前所有的数据进行恢复。
#仅恢复到操作 ID 为“623"之前的数据,即不恢复"user4"的数据
mysqlbinlog --no-defaults --stop-position='623' /opt/mysql-bin.000002 | mysql -uroot -p
–start-position #之后的所有数据进行恢复。
#仅恢复"user4"的数据,跳过"user3"的数据恢复
mysqlbinlog --no-defaults --start-position='623' /opt/mysql-bin.000002 | mysql -uroot -p
#恢复从位置为400开始到位置为623为止
mysqlbinlog --no-defaults --start-position='400' --stop-position='623' /opt/mysql-bin.000002 | mysql -uroot -p
3、基于时间点恢复
mysqlbinlog [--no-defaults] --start-datetime='年-月-日 小时:分钟:秒' --stop-datetime='年-月-日小时:分钟:秒' 二进制日志 | mysql -u 用户名 -p 密码
#仅恢复到15:21:20 之前的数据,即不恢复"user4"的数据
mysqlbinlog --no-defaults --stop-datetime='2023-8-30 15:21:20' /opt/mysql-bin.000002 | mysql -uroot -p
#仅恢复"user4"的数据,跳过"user3"的数据恢复
mysqlbinlog --no-defaults --start-datetime='2023-8-30 15:21:20' /opt/mysql-bin.000002 | mysql -uroot -p
注意:
如果恢复某条SQL语之前的所有数据,就stop在这个语句的位置节点或者时间点。
如果恢复某条SQL语句以及之后的所有数据,就从这个语句的位置节点或者时间点start。
相关文章:
MySQL数据备份与恢复
备份的主要目的: 备份的主要目的是:灾难恢复,备份还可以测试应用、回滚数据修改、查询历史数据、审计等。 日志: MySQL 的日志默认保存位置为: /usr/local/mysql/data##配置文件 vim /etc/my.cnf [mysqld] ##错误日志…...
基于ssm+vue汽车售票网站源码和论文
基于ssmvue汽车售票网站源码和论文088 开发工具:idea 数据库mysql5.7 数据库链接工具:navcat,小海豚等 技术:ssm 摘 要 互联网发展至今,无论是其理论还是技术都已经成熟,而且它广泛参与在社会中的方方面面。它让…...
)
【List】List集合有序测试案例:ArrayList,LinkedList,Vector(123)
List是有序、可重复的容器。 有序: List中每个元素都有索引标记。可以根据元素的索引标记(在List中的位置)访问 元素,从而精确控制这些元素。 可重复: List允许加入重复的元素。更确切地讲,List通常允许满足 e1.equals(e2) 的元素…...
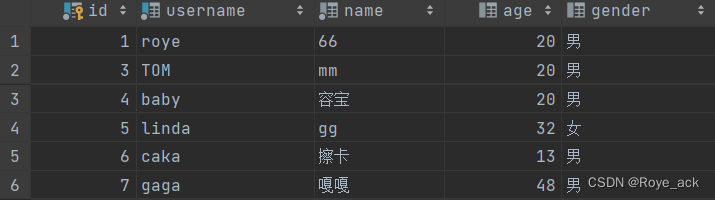
【javaweb】学习日记Day6 - Mysql 数据库 DDL DML
之前学习过的SQL语句笔记总结戳这里→【数据库原理与应用 - 第六章】T-SQL 在SQL Server的使用_Roye_ack的博客-CSDN博客 目录 一、概述 1、如何安装及配置路径Mysql? 2、SQL分类 二、DDL 数据定义 1、数据库操作 2、IDEA内置数据库使用 (1&…...

使用 PyTorch C ++前端
使用 PyTorch C 前端 PyTorch C 前端是 PyTorch 机器学习框架的纯 C 接口。 虽然 PyTorch 的主要接口自然是 Python,但此 Python API 建立于大量的 C 代码库之上,提供基本的数据结构和功能,例如张量和自动微分。 C 前端公开了纯 C 11 API&a…...

6、NoSQL的四大分类
6、NoSQL的四大分类 kv键值对 不同公司不同的实现 新浪:Redis美团:RedisTair阿里、百度:Redismemcache 文档型数据库(bson格式和json一样) MongoDB MongoDB是一个基于分布式文件存储的数据库,一般用于存储…...
(动态规划) 剑指 Offer 60. n个骰子的点数 ——【Leetcode每日一题】
❓ 剑指 Offer 60. n个骰子的点数 难度:中等 把 n 个骰子扔在地上,所有骰子朝上一面的点数之和为 s 。输入 n,打印出s的所有可能的值出现的概率。 你需要用一个浮点数数组返回答案,其中第 i 个元素代表这 n 个骰子所能掷出的点…...
ArrayList与顺序表
文章目录 一. 顺序表是什么二. ArrayList是什么三. ArrayList的构造方法四. ArrayList的常见方法4.1 add()4.2 size()4.3 remove()4.4 get()4.5 set()4.6 contains()4.7 lastIndexOf()和 indexOf()4.8 subList()4.9 clear() 以上就是ArrayList的常见方法!…...

【【萌新的STM32-22中断概念的简单补充】】
萌新的STM32学习22-中断概念的简单补充 我们需要注意的是这句话 从上面可以看出,STM32F1 供给 IO 口使用的中断线只有 16 个,但是 STM32F1 的 IO 口却远远不止 16 个,所以 STM32 把 GPIO 管脚 GPIOx.0~GPIOx.15(xA,B,C,D,E,F,G)分别对应中断…...

Java 中数据结构HashMap的用法
Java HashMap HashMap 是一个散列表,它存储的内容是键值对(key-value)映射。 HashMap 实现了 Map 接口,根据键的 HashCode 值存储数据,具有很快的访问速度,最多允许一条记录的键为 null,不支持线程同步。 HashMap 是…...
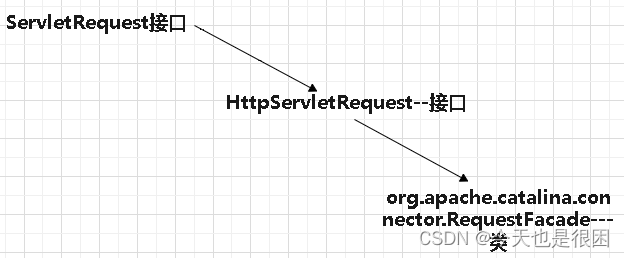
Request对象和response对象
一、概念 request对象和response对象是通过Servlet容器(如Tomcat)自动创建并传递给Servlet的。 Servlet容器负责接收客户端的请求,并将请求信息封装到request对象中,然后将request对象传 递给相应的Servlet进行处理。类似地&…...

设计模式之桥接模式
文章目录 一、介绍二、案例1. 组件抽象化2. 桥梁抽象化 一、介绍 桥接模式,属于结构型设计模式。通过提供抽象与实现之间的桥接结构,把抽象化与实现化解耦,使得二者可以独立变化。 《Head First 设计模式》: 将抽象和实现放在两…...
pom.xml配置文件失效,显示已忽略的pom.xml --- 解决方案
现象: 在 Maven 创建模块Moudle时,由于开始没有正确创建好,所以把它删掉了,然后接着又创建了与一个与之前被删除的Moudle同名的Moudle时,出现了 Ignore pom.xml,并且新创建的 Module 的 pom.xml配置文件失效…...

文本编辑器Vim常用操作和技巧
文章目录 1. Vim常用操作1.1 Vim简介1.2 Vim工作模式1.3 插入命令1.4 定位命令1.5 删除命令1.6 复制和剪切命令1.7 替换和取消命令1.8 搜索和搜索替换命令1.9 保存和退出命令 2. Vim使用技巧 1. Vim常用操作 1.1 Vim简介 Vim是一个功能强大的全屏幕文本编辑器,是L…...
【算法系列篇】位运算
文章目录 前言什么是位运算算法1.判断字符是否唯一1.1 题目要求1.2 做题思路1.3 Java代码实现 2. 丢失的数字2.1 题目要求2.2 做题思路2.3 Java代码实现 3. 两数之和3.1 题目要求3.2 做题思路3.3 Java代码实现 4. 只出现一次的数字4.1 题目要求4.2 做题思路4.3 Java代码实现 5.…...

机器学习的测试和验证(Machine Learning 研习之五)
关于 Machine Learning 研习之三、四,可到秋码记录上浏览。 测试和验证 了解模型对新案例的推广效果的唯一方法是在新案例上进行实际尝试。 一种方法是将模型投入生产并监控其性能。 这很有效,但如果你的模型非常糟糕,你的用户会抱怨——这…...

RNN循环神经网络
目录 一、卷积核与循环核 二、循环核 1.循环核引入 2.循环核:循环核按时间步展开。 3.循环计算层:向输出方向生长。 4.TF描述循环计算层 三、TF描述循环计算 四、RNN使用案例 1.数据集准备 2.Sequential中RNN 3.存储模型,acc和lose…...
安防视频监控/视频集中存储/云存储平台EasyCVR无法播放HLS协议该如何解决?
视频云存储/安防监控EasyCVR视频汇聚平台基于云边端智能协同,支持海量视频的轻量化接入与汇聚、转码与处理、全网智能分发、视频集中存储等。音视频流媒体视频平台EasyCVR拓展性强,视频能力丰富,具体可实现视频监控直播、视频轮播、视频录像、…...

Docker技术--Docker的安装
1..Docker的安装方式介绍 Docker官方提供了三种方式可以实现Docker环境的安装。分别为:Script、yum、rpm。在实际的环境中建议使用yum或者是rpm。 2..Docker的yum安装 # 1.下载docker wget https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo -O /etc/yum.re…...
客户案例|MemFire Cloud助推应急管理业务,打造百万级数据可视化大屏
「导语」 硬石科技,成立于2018年,总部位于武汉,是一家专注于应急管理行业和物联感知预警算法模型的技术核心的物联网产品和解决方案提供商。硬石科技作为一家高新技术企业,持有6项发明专利,拥有100余项各类平台认证和资…...

突破不可导策略的训练难题:零阶优化与强化学习的深度嵌合
强化学习(Reinforcement Learning, RL)是工业领域智能控制的重要方法。它的基本原理是将最优控制问题建模为马尔可夫决策过程,然后使用强化学习的Actor-Critic机制(中文译作“知行互动”机制),逐步迭代求解…...

java调用dll出现unsatisfiedLinkError以及JNA和JNI的区别
UnsatisfiedLinkError 在对接硬件设备中,我们会遇到使用 java 调用 dll文件 的情况,此时大概率出现UnsatisfiedLinkError链接错误,原因可能有如下几种 类名错误包名错误方法名参数错误使用 JNI 协议调用,结果 dll 未实现 JNI 协…...

STM32标准库-DMA直接存储器存取
文章目录 一、DMA1.1简介1.2存储器映像1.3DMA框图1.4DMA基本结构1.5DMA请求1.6数据宽度与对齐1.7数据转运DMA1.8ADC扫描模式DMA 二、数据转运DMA2.1接线图2.2代码2.3相关API 一、DMA 1.1简介 DMA(Direct Memory Access)直接存储器存取 DMA可以提供外设…...

最新SpringBoot+SpringCloud+Nacos微服务框架分享
文章目录 前言一、服务规划二、架构核心1.cloud的pom2.gateway的异常handler3.gateway的filter4、admin的pom5、admin的登录核心 三、code-helper分享总结 前言 最近有个活蛮赶的,根据Excel列的需求预估的工时直接打骨折,不要问我为什么,主要…...

MySQL用户和授权
开放MySQL白名单 可以通过iptables-save命令确认对应客户端ip是否可以访问MySQL服务: test: # iptables-save | grep 3306 -A mp_srv_whitelist -s 172.16.14.102/32 -p tcp -m tcp --dport 3306 -j ACCEPT -A mp_srv_whitelist -s 172.16.4.16/32 -p tcp -m tcp -…...

Unity | AmplifyShaderEditor插件基础(第七集:平面波动shader)
目录 一、👋🏻前言 二、😈sinx波动的基本原理 三、😈波动起来 1.sinx节点介绍 2.vertexPosition 3.集成Vector3 a.节点Append b.连起来 4.波动起来 a.波动的原理 b.时间节点 c.sinx的处理 四、🌊波动优化…...

Spring Cloud Gateway 中自定义验证码接口返回 404 的排查与解决
Spring Cloud Gateway 中自定义验证码接口返回 404 的排查与解决 问题背景 在一个基于 Spring Cloud Gateway WebFlux 构建的微服务项目中,新增了一个本地验证码接口 /code,使用函数式路由(RouterFunction)和 Hutool 的 Circle…...

【Java学习笔记】BigInteger 和 BigDecimal 类
BigInteger 和 BigDecimal 类 二者共有的常见方法 方法功能add加subtract减multiply乘divide除 注意点:传参类型必须是类对象 一、BigInteger 1. 作用:适合保存比较大的整型数 2. 使用说明 创建BigInteger对象 传入字符串 3. 代码示例 import j…...

HarmonyOS运动开发:如何用mpchart绘制运动配速图表
##鸿蒙核心技术##运动开发##Sensor Service Kit(传感器服务)# 前言 在运动类应用中,运动数据的可视化是提升用户体验的重要环节。通过直观的图表展示运动过程中的关键数据,如配速、距离、卡路里消耗等,用户可以更清晰…...

【无标题】路径问题的革命性重构:基于二维拓扑收缩色动力学模型的零点隧穿理论
路径问题的革命性重构:基于二维拓扑收缩色动力学模型的零点隧穿理论 一、传统路径模型的根本缺陷 在经典正方形路径问题中(图1): mermaid graph LR A((A)) --- B((B)) B --- C((C)) C --- D((D)) D --- A A -.- C[无直接路径] B -…...