MySQL一行记录是如何存储的?
目录
MySQL的数据存放在哪个文件?
表空间文件的结构是怎么样的?
1、行(row)
2、页(page)
3、区(extent)
4、段(segment)
InnoDB 行格式有哪些?
COMPACT行格式长什么样?
记录的额外信息
1、变长字段长度列表
2、NULL值列表
3、记录头信息
记录的真实信息
varchar(n) 中 n 最大取值为多少?
单字段的情况
多字段的情况
行溢出后,MySQL是怎么处理的?
总结
MySQL的数据存放在哪个文件?
MySQL存储的行为由存储引擎实现的,MySQL 支持多种存储引擎,不同的存储引擎保存的文件也不同。
InnoDB是我们常用的存储引擎,也是 MySQL 默认的存储引擎。所以本文主要围绕 InnoDB 存储引擎展开。
查询MySQL数据库的文件存放在哪个目录:
mysql> SHOW VARIABLES LIKE 'datadir';
+---------------+-----------------+
| Variable_name | Value |
+---------------+-----------------+
| datadir | /var/lib/mysql/ |
+---------------+-----------------+
1 row in set (0.00 sec)我们每创建一个 database (数据库)都会在 datadir 目录里创建一个以 database 为名的目录,然后保存表结构和表数据的文件都会存放在这个目录里。
比如,这里有一个名为 my_test 的 database ,该 database 里有一张名为 t_order 数据库表。

然后,我们进入 /var/lib/mysql/my_test 目录,看看有什么文件?
[root@xiaolin ~]#ls /var/lib/mysql/my_test
db.opt
t_order.frm
t_order.ibd可以看到,公有三个文件,这三个文件分别代表着:
- db.opt,用来存储当前数据库的默认字符集和字符校验规则
- t_order.frm,t_order 的表结构会保存在这个文件。在MySQL中建立一张表都会生成一个 .frm 文件,该文件是用来保存每个表的元数据信息的,主要包含表结构定义。
- t_order.ibd,t_order 的表数据会保存在这个文件。表数据既可以存在共享表空间文件(文件名:ibdata1)里,也可以存放在独占表空间文件(文件名:表名字.ibd)。这个行为是由参数 innodb_file_per_table 控制的,若设置了参数 innodb_file_per_table 为 1 ,则会将存储的数据、索引等信息单独存储在一个独占表空间,从 MySQL 5.6.6 版本开始,它的默认值就是 1 了,因此从这个版本之后, MySQL 中每一张表的数据都存放在一个独立的 .ibd 文件。
总结:每创建一张表都会生成.opt,.frm,.ibd三个文件,其中 .opt 存储字符集和字符校验规则; .frm 存储表结构定义;.ibd 存储每张表的数据。
表空间文件的结构是怎么样的?
表空间由 段(segment)、区(extent)、页(page)、行(row)组成,InnoDB存储引擎的逻辑结构大致如下图:
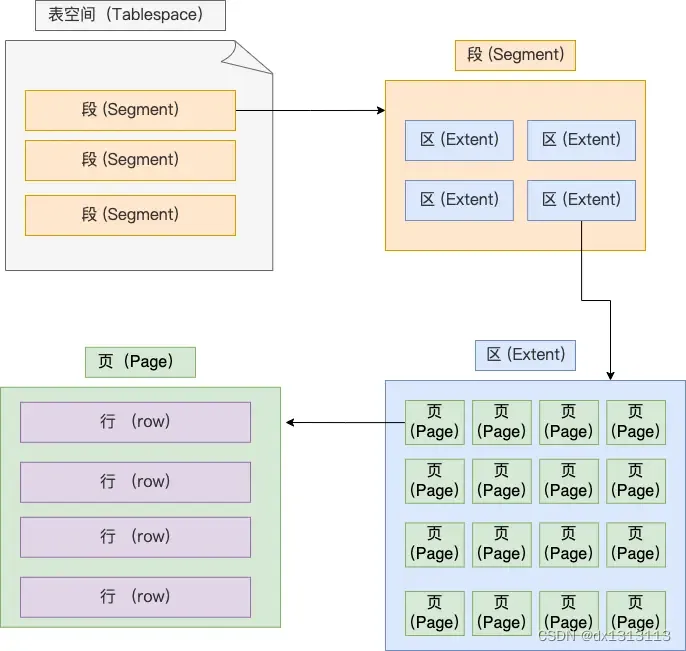
1、行(row)
数据表中的记录都是按行(row)进行存放的,每个记录根据不同的行格式,有不同的存储结构。
2、页(page)
记录是按照行来存储的,但是数据库的读取并不以 [行] 为单位,否则一次读取(也就是一次 I/O操作)只能处理一行数据,效率会非常低。
因此 InnoDB的数据是按 [页] 为单位读写的,也就是说,当需要读取一条记录的时候,并不是将这个记录从磁盘读出来,而是以页为单位,将其整体读入内存。
默认每个页的大小为 16 KB ,也就是最多能保证 16 KB 的连续存储空间。
页是 InnoDB 存储引擎磁盘管理的最小单元,意味着数据库每次读写都是以 16KB 为单位的,一次最少从磁盘中读取 16K 的内容到内存中,一次最少把内存中的 16 K 内容刷新到磁盘中。
页的类型很多,常见的有数据页、undo 日志页、溢出页等等。数据表中的页式用 [数据页] 来管理的。
3、区(extent)
InnoDB存储引擎是用 B+ 树来组织数据的。
B+ 树中每一层都是通过双向链表连接起来的,如果是以页为单位来分配存储空间,那么链表中相邻的两个页之间的物理位置并不是连续的,可能离得非常远,那么磁盘查询时就会有大量的随机I/O,随机 I/O 是非常慢的。
解决这个问题也很简单,就是让链表中相邻的页的物理位置也相邻,这样就可以使用顺序 I/O 了,那么在范围查询(扫描叶子结点)的时候性能就会很高。
解决办法:
在表中数据量大的时候,为某个索引分配空间的时候就不再按照页为单位分配了,而是按照区(extent)为单位分配。每个区的大小为 1MB ,对于 16KB 的页来说,连续的 64 个页会被划分为一个区,这样就使得链表中相邻的页的物理位置也相邻,就能使用顺序 I/O 了。
4、段(segment)
表空间是由各个段(segment)组成的,段是由多个区(extent)组成的。段一般分为数据段、索引段和回滚段等。
- 索引段:存放 B+ 树的非叶子节点的区的集合
- 数据段:存放 B+ 树的叶子节点的集合
- 回滚段:存放的是回滚数据的区的集合
InnoDB 行格式有哪些?
行格式(row_format),就是一条记录的存储结构。
InnoDB 提供了 4 种行格式,分别是Redundant 、Compact、Dynamic和Compressed行格式。
- Redundant 是很古老的行格式了,MySQL 5.0 版本之前用的行格式,现在基本没人用了
- 由于Redundant不是一种紧凑的行格式,所以 MySQL 5.0 之后引入了 Compact 行记录存储方式,Compact是一种紧凑的行格式,设计的初衷就是为了让一个数据页中可以存放更多的行记录,从 MySQL 5.1 版本后,行格式默认设置成 Compact
- Dynamic 和 Compressed 两个都是紧凑的行格式,它们的行格式都和Compact差不多,因为都是基于Compact改进一点东西。从 MySQL5.7版本后,默认使用Dynamic 行格式。
COMPACT行格式长什么样?

可以看到,一条完整的记录分为 [记录的额外信息] 和 [记录的真实数据] 两个部分。
记录的额外信息
记录的额外信息包含三个部分:变长字段长度列表、NULL值列表、记录头信息。
1、变长字段长度列表
varchar(n) 和 char(n) 的区别:char是定长的,varchar 是变长的,变长字段实际存储数据的长度(大小)不固定。
所以,在存储数据的时候,也要把数据占用的大小存起来,存到 [变长字段长度列表] 里面,读取数据的时候才能根据这个 [变长字段长度列表] 去读取对应长度的数据。其他 TEXT、BLOB等变长字段也是这么实现的。
为了展示 [变长字段长度列表] 具体是怎么保存 [变长字段的真实数据占用的字节数],我们先创建这样的一张表,字符集是 ascii (所以每一个字符占用的是 1 字节),行格式是 Compact ,t_user 表中 name 和 phone 字段都是变长字段:
CREATE TABLE `t_user` (`id` int(11) NOT NULL,`name` VARCHAR(20) DEFAULT NULL,`phone` VARCHAR(20) DEFAULT NULL,`age` int(11) DEFAULT NULL,PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB DEFAULT CHARACTER SET = ascii ROW_FORMAT = COMPACT;现在 t_user 表里有三条记录:
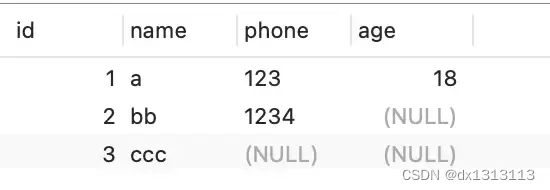
接下来我们看看这三条记录的行格式中的 [变长字段长度列表] 是怎么存储的?
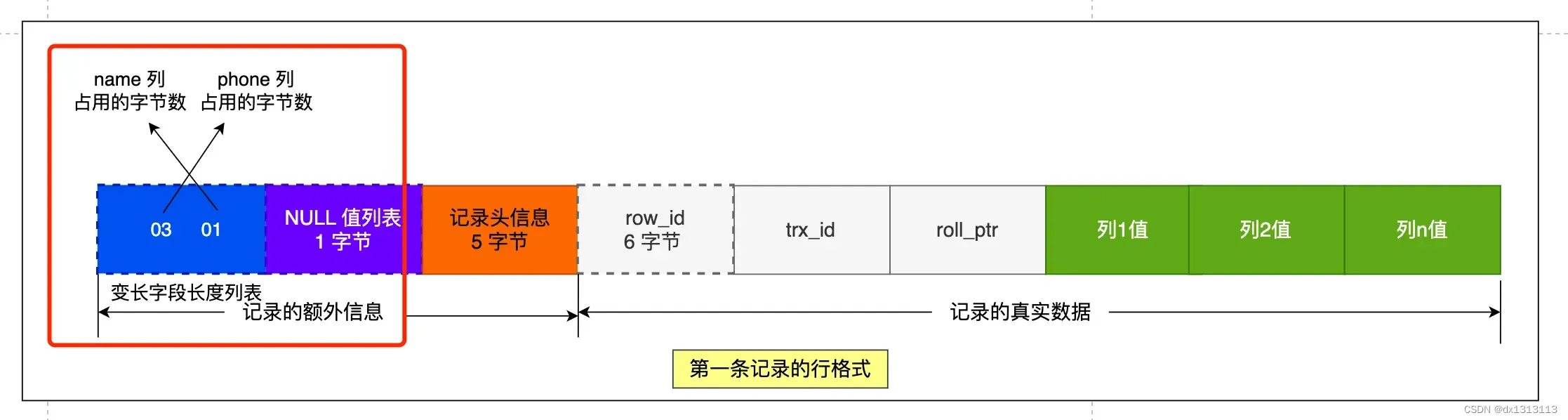
第一条记录:
- name 列的值为 a ,真实数据占用的字节数是 1 字节,十六进制 0x01;
- phone 列的值 为 123,真实数据占用的字节数是 3 字节,十六进制 0x03;
- age 列和 id 列是不变长字段,所以这里不用管
这些变长字段的真实数据占用的字节数会按照列的顺序逆序存放,所以 [变长字段长度列表] 里的内容是 [03 01],而不是 [01 03]。
同样,可以得出第二条记录的行格式中,[变长字段长度列表] 里的内容是 [04 02] ,如下图:

第三条记录中的 phone 的 列值为 NULL ,NULL 是不会存放在行格式中记录的真实数据部分里的,所以 [变长字段长度列表] 里不需要保存值为 NULL 的变长字段的长度。
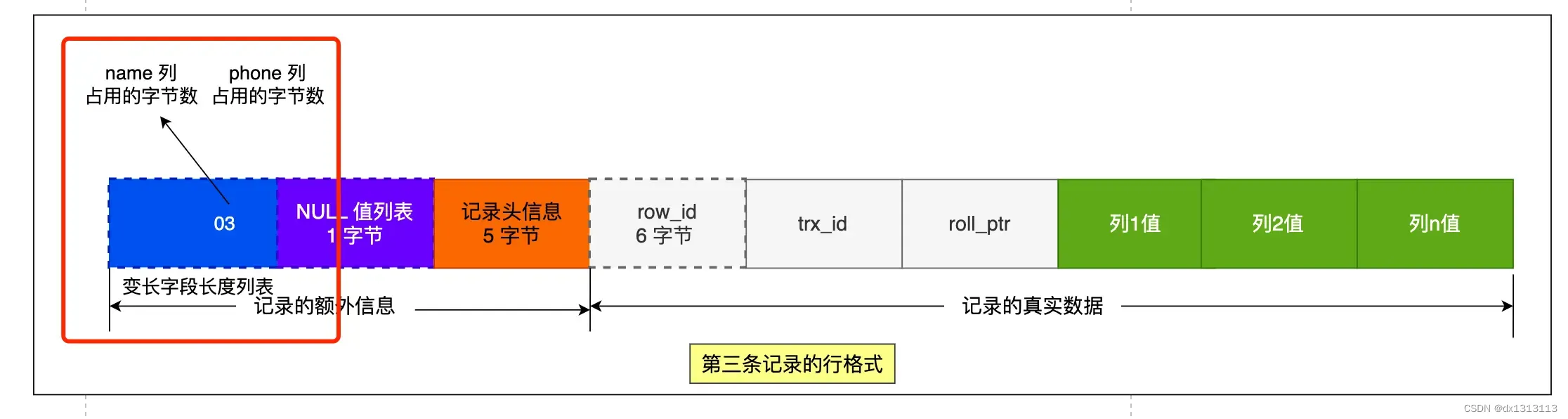
为什么 [变长字段长度列表] 的信息要按照逆序存放?
主要是因为 [ 记录头信息] 中指向下一个记录的指针,指向的是下一条记录的 [记录头信息] 和 [真实数据] 之间的位置,这样的好处就是向左读就是记录头信息,向右读就是真实数据,比较方便。
[变长字段长度列表] 中的信息之所以要逆序存放,是因为这样可以使得位置靠前的记录的真实数据和数据对应的字段长度信息可以同时在一个 CPU Cache Line 中,这样就可以提高 CPU Cache 的命中率。
同样的道理,NULL值列表的信息也需要逆序存放。
每个数据库表的行格式都有 [变长字段字节数列表] 吗?
变长字段字节数列表不是必须的。
当数据表没有变长字段的时候,比如全部都是 int 类型的字段,这时候表里的行格式就不会有 [变长字段长度列表] 了,因为没必要,不如去掉可以节省空间。
所以 [变长字段长度列表] 只出现在数据表中有变长字段的时候。
2、NULL值列表
表中的某些列可能会存储 NULL值,如果把这些 NULL 值都放在记录的真实数据中会比较浪费空间,所以Compact 行格式把这些值为 NULL的列存储到 NULL 值列表中。
如果存在允许 NULL 值的列,则每一个列对应一个二进制位(bit),二进制位按照列的顺序逆序排列。
- 二进制位的值为 1 时,代表该列的值为 NULL
- 二进制位的值为 0 时,代表该列的值不为 NULL
另外,NULL的值列表必须用整数个字节的位表示(1字节8位),如果使用的二进制位个数不足整数个字节,则在字节的高位补 0.
还是以 t_user 表的这三条记录作为例子:

接下来,看看这三条记录的行格式中的 NULL 值列表是怎样存储的:
先看第一条记录,第一条记录所有列都有值,不存在 NULL 值,所以用二进制来表示是这样子的:
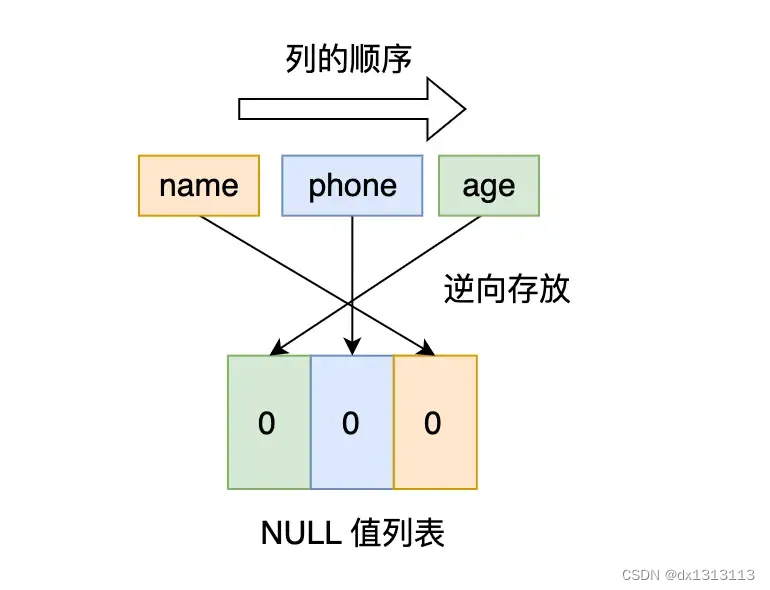
但是 InnoDB 是用整数字节的二进制来表示NULL值列表的,现在不足 8 位 ,所以要在高位补 0 ,最终用二进制来表示是这样子的:

所以,对于第一条数据, NULL值列表用十六进制表示是 0x00.
第二条记录:第二条记录age列是NULL值,所以,对于第二条数据,NULL值列表用十六进制表示是0x04.
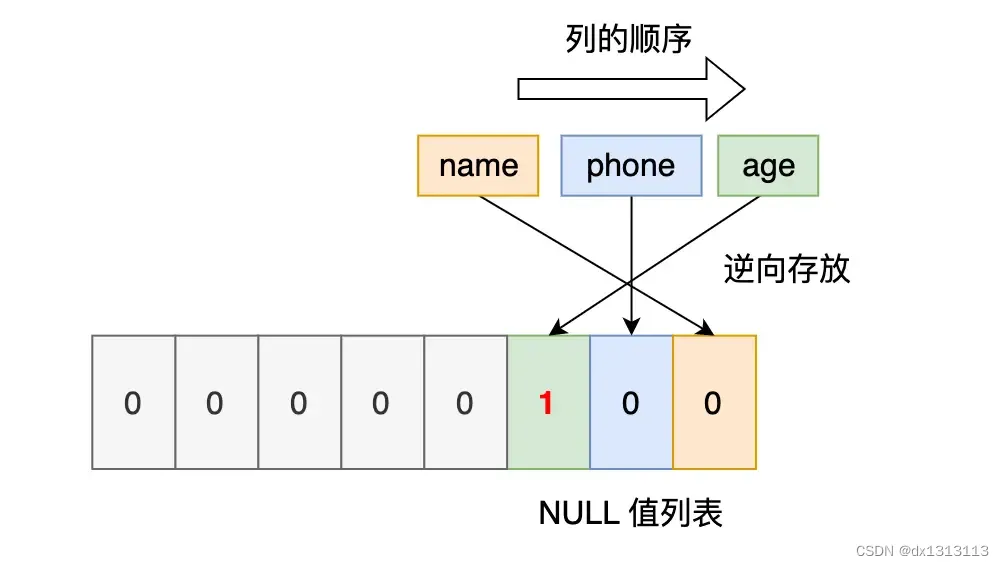
第三条记录:第三条记录 phone 列和 age 列是 NULL值,所以,对于第三条数据,NULL值列表用十六进制表示是0x06。
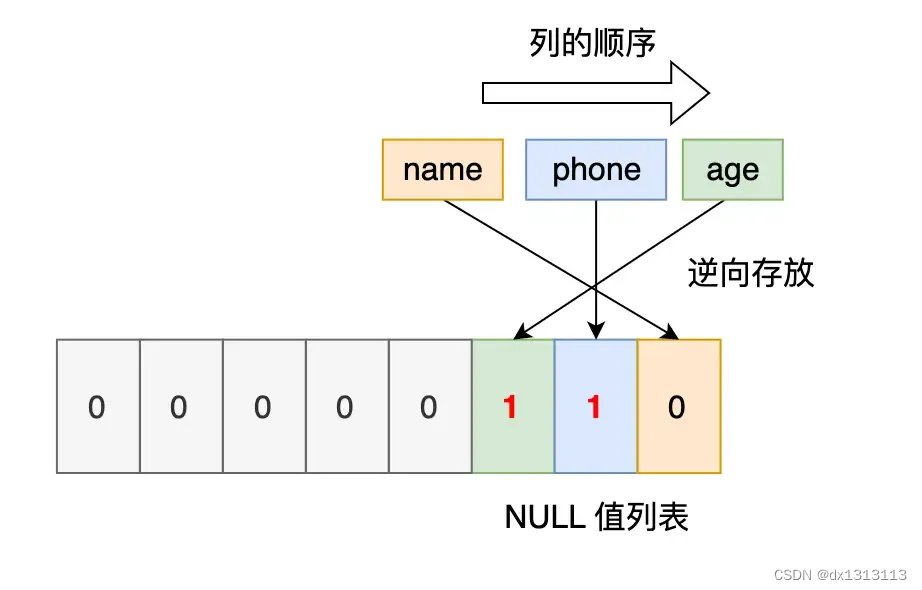
把三条记录的NULL值列表都填充完毕后,它们的行格式是这样的:

每个数据库表行格式都有 [NULL值列表] 吗?
NULL值列表也不是必须的。
当数据库的字段都定义成 NOT NULL 的时候,这时候表里的行格式就不会有 NULL值列表了。
所以在设计数据库表的时候,通常都是建议将字段设置为 NOT NULL ,这样可以至少节省 1 字节的空间(NULL值列表至少占用 1 字节空间)。
[NULL 值列表] 是固定 1 字节吗?如果是这样的话,一条记录有九个字段值都是 NULL ,这时候怎么表示?
[NULL值列表] 的空间不是固定 1 字节的。
当一条记录有 9 个字段值都是 NULL ,那么就会创建 2 字节空间的 [NULL 值列表],以此类推。
3、记录头信息
记录头信息包含的内容很多,这里例举几个比较重要的:
- delete_mask:标识此条数据是否被删除。从这里可以知道,我们执行 delete 删除记录的时候,并不会真正的删除记录,只是将这个记录的 delete_mask 标记为 1。
- next_record:下一条记录的位置。从这里可以知道,记录与记录之间是通过链表组织的。在前面提到过,指向的是下一条记录的 [记录头信息] 和 [真实数据] 之间的位置
- record_type:表示当前记录的类型, 0 表示 普通记录, 1 表示 B+树非叶子节点记录, 2 则表示最小记录, 3 表示最大记录。
记录的真实信息
记录的真实数据部分除了我们定义的字段,还有三个隐藏字段,分别为 row_id、trx_id、roll_pointer。

- row_id:如果建表的时候指定了主键或者唯一约束列,那么就没有 row_id隐藏字段了。如果既没有指定主键,又没有唯一约束,那么InnoDB就会记录添加 row_id 隐藏字段。row_id 不是必需的,占用 6 个字节
- trx_id:事务id,表示这个数据是由哪个事务生成的。trx_id是必需的,占用 6 个字节。
- roll_pointer:这条记录上一个版本的指针。roll_pointer是必需的,占用 7 个字节。
varchar(n) 中 n 最大取值为多少?
MySQL规定除了 TEXT、BLOBs 这种大对象类型之外,其他所有的列(步包括隐藏列和记录头信息)占用的字节长度加起来不能超过 65535 个字节。
也就是说,一行记录除了TEXT、BLOBs 类型的列,限制最大为 65535 字节,注意是一行的总长度不是一列。
PS: varchar(n) 字段类型的 n 代表的是最多存储的字符数量,并不是字节大小。
要算varchar(n)最大能允许存储的字节数,还需要看数据库表的字符集,因为字符集代表着,1个字符占用多少字节,比如ascii字符集,1 个字符占用 1 字节,那么 varchar(100)意味着最大能允许存储 100 字节的数据。如果是utf-8字符集,一个中文字符占用 3 字节,英文占用 1 字节。
单字段的情况
前面,我们知道了一行记录最大只能存储 65535 字节的数据
假设数据库表只有一个 varchar(n)类型的列且字符集是 ascii ,在这种情况下,varchar(n)中 n 取最大值是 65535 吗?
我们定义一个 varchar(65535)类型的字段,字符集为 ascii 的数据库表
CREATE TABLE test (
`name` VARCHAR(65535) NULL
) ENGINE = InnoDB DEFAULT CHARACTER SET = ascii ROW_FORMAT = COMPACT;看看能不能成功创建一张表:

可以看到,创建失败了
从报错信息可以知道:一行数据的最大字节数是 65535 (不包含 TEXT、BLOBs 这种大对象类型),其中包含了storage overhead.
storage overhead 其实就是 [变长字段长度列表] 和 [NULL值列表],也就是说一行数据的最大字节数 65535 ,实际上是包含 [变长字段长度列表] 和 [NULL 值列表] 所占用的字节数。所以在计算varchar(n) 中 n 最大值时,需要减去 storage overhead 占用的字节数。
这是因为我们存储字段类型为 varchar(n) 的数据时,其实分成了三个部分来存储:
- 真实数据
- 真实数据占用的字节数
- NULL标识,如果不允许为NULL,这部分不需要
本例中, [NULL值列表] 所占用的字节数是多少?
我们创建表时,字段允许为NULL的,而且行字段数不超过8,所以会用 1 字节来表示 [NULL值列表]。
本例中,[变长字段长度列表] 所占用的字节数是多少?
[变长字段长度列表] 所占用的字节数 = 所有 [变长字段长度] 占用的字节数之和。
所以,我们要先知道每个变长字段的 [变长字段长度] 需要用多少字节表示?具体情况分为:
- 条件一:如果变长字段允许存储的最大字节数小于等于 255 字节,就会用 1 字节表示 [变长字段长度]
- 条件二:如果变长字段允许存储的最大字节数大于 255 字节,就会用 2 字节表示 [变长字段长度] ;
因为我们这个案例是只有 1 个变长字段,所以「变长字段长度列表」= 1 个「变长字段长度」占用的字节数,也就是 2 字节。
因为在算 varchar(n) 中 n 最大值时,需要减去 「变长字段长度列表」和 「NULL 值列表」所占用的字节数的。所以,在数据库表只有一个 varchar(n) 字段且字符集是 ascii 的情况下,varchar(n) 中 n 最大值 = 65535 - 2 - 1 = 65532。

可以看到,创建成功了。所以在算 varchar(n) 中 n 最大值时,需要减去 「变长字段长度列表」和 「NULL 值列表」所占用的字节数的。
当然,上面这个例子是针对字符集为 ascii 情况,如果采用的是 UTF-8,varchar(n) 最多能存储的数据计算方式就不一样了:
- 在 UTF-8 字符集下,一个字符最多需要3个字节,varchar(n) 的 n 最大取值就是 65532/3 = 21844。
上面所说的只是针对于一个字段的计算方式。
多字段的情况
如果有多个字段的话,要保证所有字段的长度 + 变长字段字节数列表所占用的字节数 + NULL值列表所占用的字节数 <= 65535
行溢出后,MySQL是怎么处理的?
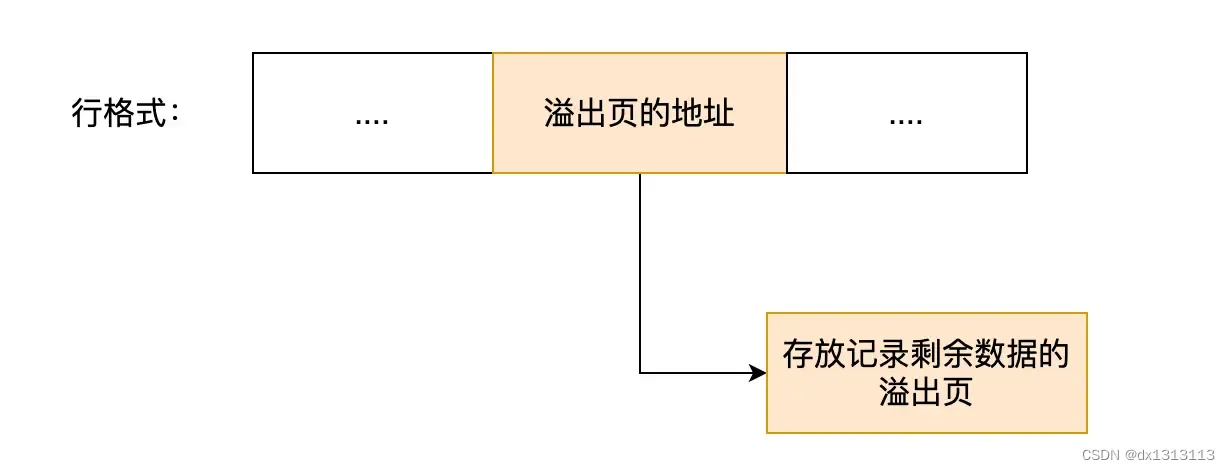
MySQL 中磁盘和内存交互的基本单位是页,一个页的大小一般是 16KB,也就是 16384字节,而一个 varchar(n) 类型的列最多可以存储 65532字节,一些大对象如 TEXT、BLOB 可能存储更多的数据,这时一个页可能就存不了一条记录。这个时候就会发生行溢出,多的数据就会存到另外的「溢出页」中。
如果一个数据页存不了一条记录,InnoDB 存储引擎会自动将溢出的数据存放到「溢出页」中。在一般情况下,InnoDB 的数据都是存放在 「数据页」中。但是当发生行溢出时,溢出的数据会存放到「溢出页」中
当发生行溢出时,在记录的真实数据处只会保存该列的一部分数据,而把剩余的数据放在 [溢出页] 中,然后真实数据处用 20 字节存储指向溢出页的地址,从而可以找到剩余数据所在的页。
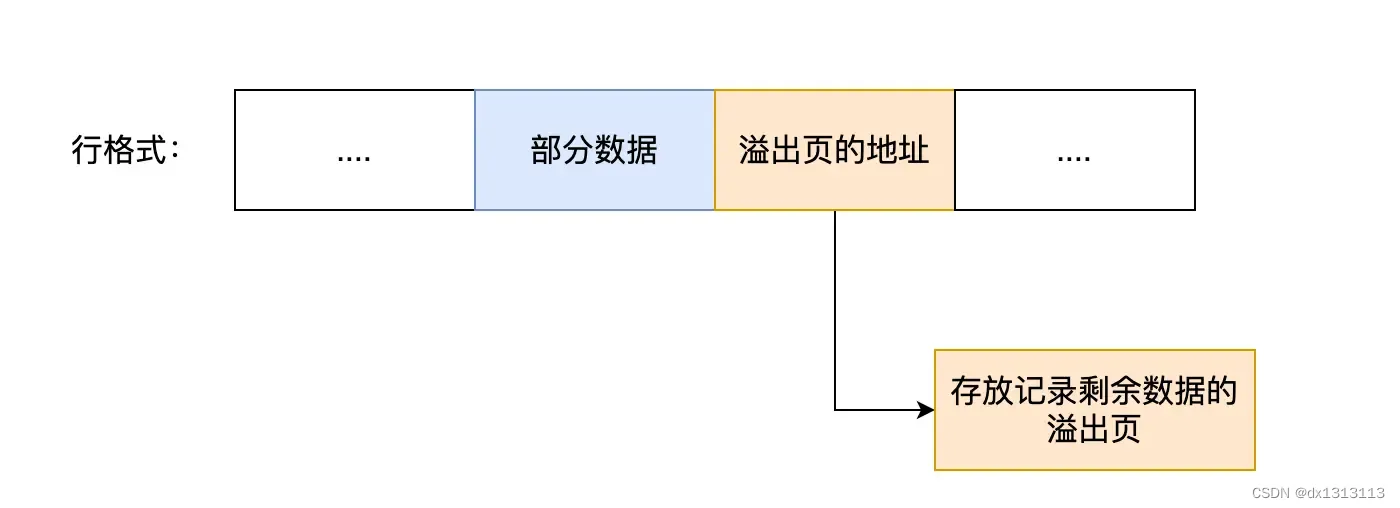
上面这个是 Compact 行格式在发生行溢出后的处理。
Compressed 和 Dynamic 这两个行格式和 Compact 非常类似,主要的区别在于处理行溢出数据时有些区别。
这两种格式采用完全的行溢出方式,记录的真实数据处不会存储该列的一部分数据,只存储 20 个字节的指针来指向溢出页。而实际的数据都存储在溢出页中,看起来就像下面这样
总结
MySQL的NULL值是怎么存放的?
MySQL的Compact行格式中会用 [NULL值列表] 来标记值为 NULL 的列。NULL值并不会存储在行格式中的真实数据部分。
NULL值列表会占用 1 字节空间,当表中所有的字段都定义成 NOT NULL ,行格式中就不会有 NULL 值列表,这样可以节省 1 字节的空间。
MySQL怎么知道varchar(n) 实际占用数据的大小?
MySQL 的 Compact 行格式中会用 [变长字段长度列表] 存储变长字段实际占用的数据大小。
varchar(n)中 n 最大值为多少?
一行记录最大能存储 65535 字节的数据,但是这个是包含「变长字段字节数列表所占用的字节数」和「NULL值列表所占用的字节数」。所以, 我们在算 varchar(n) 中 n 最大值时,需要减去这两个列表所占用的字节数。
如果一张表只有一个 varchar(n) 字段,且允许为 NULL,字符集为 ascii。varchar(n) 中 n 最大取值为 65535(行最大存储) - 2(变长字段长度列表) - 1(NULL值列表) = 65532。
如果有多个字段的话,要保证所有字段的长度 + 变长字段字节数列表所占用的字节数 + NULL值列表所占用的字节数 <= 65535。
ps:在计算的时候需要考虑字符集、NULL值列表 和 变长字段列表 三部分。
行溢出后,MySQL是怎么处理的?
如果一个数据页存不了一条记录 ,InnoDB存储引擎会自动将溢出的数据存放在 [溢出页] 中
Compact 行格式:当发生行溢出时,在记录的真实数据处只会保存该列的一部分数据,而把剩余的数据放在「溢出页」中,然后真实数据处用 20 字节存储指向溢出页的地址,从而可以找到剩余数据所在的页。
Compressed 和 Dynamic 这两种格式采用完全的行溢出方式,记录的真实数据处不会存储该列的一部分数据,只存储 20 个字节的指针来指向溢出页。而实际的数据都存储在溢出页中。
相关文章:
MySQL一行记录是如何存储的?
目录 MySQL的数据存放在哪个文件? 表空间文件的结构是怎么样的? 1、行(row) 2、页(page) 3、区(extent) 4、段(segment) InnoDB 行格式有哪些…...

[element-ui] el-tree全部展开与收回
shrinkTreeNode () {// 改变一个全局变量this.treeStatus !this.treeStatus;// 改变每个节点的状态this.changeTreeNodeStatus(this.$refs.attrList.store.root); },// 改变节点的状态 changeTreeNodeStatus (node) {node.expanded this.treeStatus;for (let i 0; i < no…...

git 统计(命令)
查询某人某个时刻提交了多少代码 added 添加代码 removed 删除代码 total 总代码 git log --author刘俊秦 --since2023-08-01 00:00:00 --until2023-08-23 23:00:00 --prettytformat: --numstat | awk { add $1; subs $2; loc $1 - $2 } END { printf "added lines: %s…...
)
斐波那契1(矩阵快速幂加速递推,斐波那契前n项平方和)
链接:登录—专业IT笔试面试备考平台_牛客网 来源:牛客网 Keven 特别喜欢斐波那契数列,已知 fib11fib_11fib11,fib21fib_21fib21,对于 n>3n>3n>3,fibnfibn−2fibn−1fib_{n}fib_{n-2}fib_{n…...

minikube mac 启动
系统信息如下 最开始使用的minikube是1.22.0版本,按照如下命令启动: minikube start --memory7851 --cpus4 --image-mirror-countrycn遇到了下面一些问题: 1、拉取coredns:v1.8.0镜像失败 Error response from daemon: manifest for regis…...
从零开始学习 Java:简单易懂的入门指南之查找算法及排序算法(二十)
查找算法及排序算法 常见的七种查找算法:1. 基本查找2. 二分查找3. 插值查找4. 斐波那契查找5. 分块查找6. 哈希查找7. 树表查找 四种排序算法:1. 冒泡排序1.1 算法步骤1.2 动图演示1.3 代码示例 2. 选择排序2.1 算法步骤2.2 动图演示 3. 插入排序3.1 算…...

非煤矿山风险监测预警算法 yolov8
非煤矿山风险监测预警算法通过yolov8网络模型深度学习算法框架,非煤矿山风险监测预警算法在煤矿关键地点安装摄像机等设备利用智能化视频识别技术,能够实时分析人员出入井口的情况,人数变化并检测作业状态。YOLO的结构非常简单,就…...
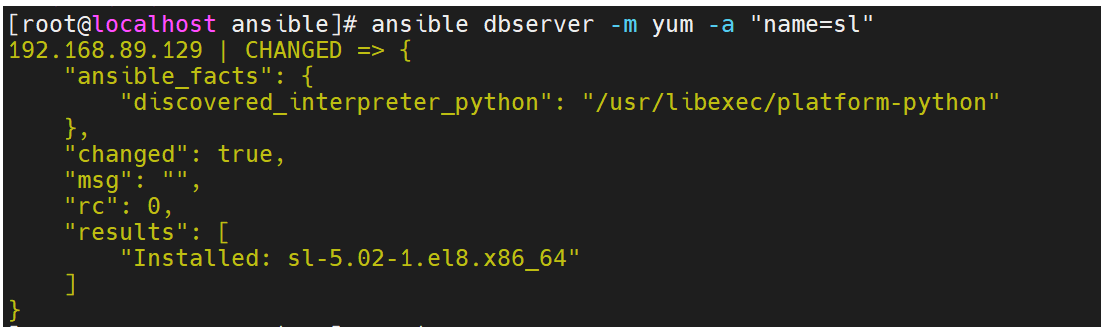
Ansible学习笔记(一)
1.什么是Ansible 官方网站:https://docs.ansible.com/ansible/latest/installation_guide/intro_installation.html Ansible是一个配置管理和配置工具,类似于Chef,Puppet或Salt。这是一款很简单也很容易入门的部署工具,它使用SS…...

2024毕业设计选题指南【附选题大全】
title: 毕业设计选题指南 - 如何选择合适的毕业设计题目 date: 2023-08-29 categories: 毕业设计 tags: 选题指南, 毕业设计, 毕业论文, 毕业项目 - 如何选择合适的毕业设计题目 当我们站在大学生活的十字路口,毕业设计便成了我们面临的一项重要使命。这不仅是对我们…...
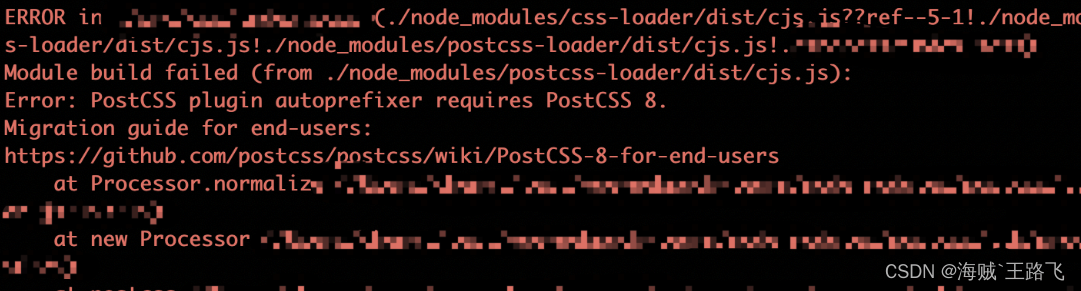
Error: PostCSS plugin autoprefixer requires PostCSS 8 问题解决办法
报错:Error: PostCSS plugin autoprefixer requires PostCSS 8 原因:autoprefixer版本过高 解决方案: 降低autoprefixer版本 执行:npm i postcss-loader autoprefixer8.0.0...
)
pymongo通过oplog获取数据(mongodb)
使用 MongoDB 的 oplog(操作日志)进行数据同步是高级的用法,主要用于复制和故障恢复。需要确保源 MongoDB 实例是副本集的一部分,因为只有副本集才会维护 oplog。 以下是简化的步骤,描述如何使用 oplog 进行数据同步&…...
MySQL数据备份与恢复
备份的主要目的: 备份的主要目的是:灾难恢复,备份还可以测试应用、回滚数据修改、查询历史数据、审计等。 日志: MySQL 的日志默认保存位置为: /usr/local/mysql/data##配置文件 vim /etc/my.cnf [mysqld] ##错误日志…...
基于ssm+vue汽车售票网站源码和论文
基于ssmvue汽车售票网站源码和论文088 开发工具:idea 数据库mysql5.7 数据库链接工具:navcat,小海豚等 技术:ssm 摘 要 互联网发展至今,无论是其理论还是技术都已经成熟,而且它广泛参与在社会中的方方面面。它让…...
)
【List】List集合有序测试案例:ArrayList,LinkedList,Vector(123)
List是有序、可重复的容器。 有序: List中每个元素都有索引标记。可以根据元素的索引标记(在List中的位置)访问 元素,从而精确控制这些元素。 可重复: List允许加入重复的元素。更确切地讲,List通常允许满足 e1.equals(e2) 的元素…...
【javaweb】学习日记Day6 - Mysql 数据库 DDL DML
之前学习过的SQL语句笔记总结戳这里→【数据库原理与应用 - 第六章】T-SQL 在SQL Server的使用_Roye_ack的博客-CSDN博客 目录 一、概述 1、如何安装及配置路径Mysql? 2、SQL分类 二、DDL 数据定义 1、数据库操作 2、IDEA内置数据库使用 (1&…...

使用 PyTorch C ++前端
使用 PyTorch C 前端 PyTorch C 前端是 PyTorch 机器学习框架的纯 C 接口。 虽然 PyTorch 的主要接口自然是 Python,但此 Python API 建立于大量的 C 代码库之上,提供基本的数据结构和功能,例如张量和自动微分。 C 前端公开了纯 C 11 API&a…...

6、NoSQL的四大分类
6、NoSQL的四大分类 kv键值对 不同公司不同的实现 新浪:Redis美团:RedisTair阿里、百度:Redismemcache 文档型数据库(bson格式和json一样) MongoDB MongoDB是一个基于分布式文件存储的数据库,一般用于存储…...
(动态规划) 剑指 Offer 60. n个骰子的点数 ——【Leetcode每日一题】
❓ 剑指 Offer 60. n个骰子的点数 难度:中等 把 n 个骰子扔在地上,所有骰子朝上一面的点数之和为 s 。输入 n,打印出s的所有可能的值出现的概率。 你需要用一个浮点数数组返回答案,其中第 i 个元素代表这 n 个骰子所能掷出的点…...
ArrayList与顺序表
文章目录 一. 顺序表是什么二. ArrayList是什么三. ArrayList的构造方法四. ArrayList的常见方法4.1 add()4.2 size()4.3 remove()4.4 get()4.5 set()4.6 contains()4.7 lastIndexOf()和 indexOf()4.8 subList()4.9 clear() 以上就是ArrayList的常见方法!…...

【【萌新的STM32-22中断概念的简单补充】】
萌新的STM32学习22-中断概念的简单补充 我们需要注意的是这句话 从上面可以看出,STM32F1 供给 IO 口使用的中断线只有 16 个,但是 STM32F1 的 IO 口却远远不止 16 个,所以 STM32 把 GPIO 管脚 GPIOx.0~GPIOx.15(xA,B,C,D,E,F,G)分别对应中断…...

PHP Intelephense项目结构解析:多工作区、虚拟工作区与远程开发
PHP Intelephense项目结构解析:多工作区、虚拟工作区与远程开发 【免费下载链接】vscode-intelephense PHP intellisense for Visual Studio Code 项目地址: https://gitcode.com/gh_mirrors/vs/vscode-intelephense PHP Intelephense是一款为Visual Studio …...

No!! MeiryoUI终极指南:3步恢复Windows界面字体自定义功能
No!! MeiryoUI终极指南:3步恢复Windows界面字体自定义功能 【免费下载链接】noMeiryoUI No!! MeiryoUI is Windows system font setting tool on Windows 8.1/10/11. 项目地址: https://gitcode.com/gh_mirrors/no/noMeiryoUI 你是否曾经为Windows 8.1/10/11…...

【巴洛克AI生成合规白皮书】:基于梵蒂冈档案馆高清藏品训练的192个版权安全Prompt模板
更多请点击: https://codechina.net 第一章:巴洛克AI生成合规白皮书导论 巴洛克AI生成合规白皮书旨在为组织在部署和运营生成式人工智能系统时,提供一套可落地、可审计、可演进的合规治理框架。该白皮书聚焦于中国《生成式人工智能服务管理暂…...

为什么你的蓝晒图总像“褪色老照片”?3个被忽略的--stylize权重陷阱,今晚失效前速查
更多请点击: https://kaifayun.com 第一章:蓝晒法的光学本质与数字转译悖论 蓝晒法(Cyanotype)作为一种1842年诞生的古典摄影工艺,其核心依赖于铁盐在紫外光照射下发生的光还原反应:柠檬酸铁铵与铁氰化钾…...

【技术干货】微小间距、热敏感区域焊接难?激光锡球焊接在芯片封装中的高精零飞溅解决方案
随着智能穿戴设备、5G通信、电子娱乐影音等产品的普及,智能电子产品已深度融入现代人生活的方方面面,从衣食住行到尖端科技领域,无处不在。人们在享受便利的同时,不禁好奇:这些设备究竟如何实现“智能化”?…...

泥沙自动监测仪:从“估算”到“实测”,水保验收不再凭感觉
泥沙自动监测仪搭载一体化智能监测架构,聚焦水保监测核心指标,可全天候无人值守自动采集关键数据,精准监测径流量、实时径流含沙量、阶段性径流总量三大核心参数,全面覆盖水土保持监测刚需指标。区别于人工定时取样的片面性&#…...

告别环境报错:用Docker 10分钟在本地/服务器部署YOLOv8完整开发环境
告别环境报错:用Docker 10分钟在本地/服务器部署YOLOv8完整开发环境 在计算机视觉领域,YOLOv8作为当前最先进的目标检测模型之一,其强大的性能和易用性吸引了大量开发者和研究者。然而,传统的手动搭建开发环境过程往往令人望而生畏…...

ZYNQ启动全解析:从BootROM到你的App,SD卡与QSPI Flash烧录究竟差在哪?
ZYNQ启动全解析:从BootROM到你的App,SD卡与QSPI Flash烧录究竟差在哪? 当一块ZYNQ开发板静静躺在桌面上,按下电源键的瞬间,芯片内部究竟发生了什么?为什么有的工程师选择SD卡启动,而另一些则坚…...

ARM SVE存储指令ST1D与ST1H深度解析与优化
1. ARM SVE存储指令深度解析在ARMv8架构的可扩展向量扩展(SVE)指令集中,ST1D和ST1H指令扮演着关键角色。这些指令专为高效的内存存储操作设计,特别适合处理大规模数据集的场景。与传统的标量存储指令相比,它们能同时处理多个数据元素…...

为你的AI Agent项目选择并接入Taotoken多模型聚合平台
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为你的AI Agent项目选择并接入Taotoken多模型聚合平台 当你着手构建一个智能Agent应用时,很快会面临一个现实问题&…...