[C++]构造与毁灭:深入探讨C++中四种构造函数与析构函数
- 个人主页:北·海
- 🎐CSDN新晋作者
- 🎉欢迎 👍点赞✍评论⭐收藏
- ✨收录专栏:C/C++
- 🤝希望作者的文章能对你有所帮助,有不足的地方请在评论区留言指正,大家一起学习交流!🤗
目录
构造函数有什么作用?
构造函数有什么特点
构造函数的种类
一.默认构造函数
1.什么是默认构造函数
2.默认构造函数的应用
使用情况一:类内初始值
使用情况二:创建对象数组
使用情况三:在派生类中
自定义的默认构造函数
二.自定义的重载构造函数
1.构造函数的作用
三.拷贝构造函数
1.浅拷贝
2.深拷贝
3.什么时候用到深拷贝/浅拷贝
4.什么时候会调用拷贝构造函数
四.赋值构造函数
1.赋值构造函数可以怎么样定义
2.赋值构造函数在什么时候会调用?
2.赋值构造函数与拷贝构造函数的区别
五.析构函数
1.析构函数的基本概念
2.容易将调用析构函数与delete释放内存混淆
概要:
"构造与毁灭,是C++中对象生命周期的两个重要阶段。构造函数用于初始化对象的状态和数据成员,为对象提供合适的初始值;而析构函数则在对象销毁时执行清理工作,释放资源,确保对象的安全结束。通过合理设计构造函数和析构函数,我们能够在对象的创建和销毁过程中维护良好的程序行为和资源管理。
构造函数有什么作用?
在创建一个新的对象时,自动调用的函数,用来进行“初始化”工作:对这个对象内部的数据成员进行初始化
构造函数有什么特点
- 自动调用(在创建新对象时,自动调用)
- 构造函数的函数名,和类名相同
- 构造函数没有返回类型
- 可以有多个构造函数(即函数重载形式)
构造函数的种类
1. 默认构造函数
2. 自定义的构造函数
3.拷贝构造函数
4.赋值构造函数
一.默认构造函数
1.什么是默认构造函数
1.没有参数的构造函数成为默认构造函数
2.没有手动定义默认构造函数时,编译器自动为这个类定义一个构造函数。
3. 如果数据成员使用了“类内初始值”,就使用这个值来初始化数据成员。否则,就使用默认初始化(实际上,不做任何初始化)只有C++11可以使用类内初始值】
2.默认构造函数的应用
使用情况一:类内初始值
以上是当全部成员变量有"类内初始值"时,可以使用默认构造函数
使用情况二:创建对象数组
由此报错可以看出,对象数组的创建,必须使用默认的构造函数,在上面87行写了自定义的构造函数之后,程序就不会默认生成默认构造函数了,要想在有自定义构造函数的情况下,创建对象数组,就必须再重载一个不含参数的默认构造函数
使用情况三:在派生类中
当派生类没有显式定义构造函数时,它将继承基类的默认构造函数。这使得在创建派生类对象时,基类的成员变量可以正确地初始化。
#include <iostream> using namespace std;// 基类 class Base { public:int baseValue;// 默认构造函数Base() {baseValue = 0;cout << "Base 默认构造函数被调用" << endl;} };// 派生类 class Derived : public Base { public:int derivedValue;void printValues() {cout << "Base 值: " << baseValue << endl;cout << "Derived 值: " << derivedValue << endl;} };int main() {Derived derivedObj;derivedObj.derivedValue = 10;derivedObj.printValues();return 0; }输出: Base 默认构造函数被调用 Base 值: 0 Derived 值: 10可以看到,派生类的对象
derivedObj在创建时成功继承了基类Base的默认构造函数,并正确地初始化了基类的成员变量baseValue。这证实了在派生类中没有显式定义构造函数时,它将继承基类的默认构造函数,并能够正确初始化基类的成员变量。注意:
只要手动定义了任何一个构造函数,编译器就不会生成“默认构造函数”
一般情况下,都应该定义自己的构造函数,不要使用“默认构造函数”
【仅当数据成员全部使用了“类内初始值”,才宜使用“合成的默认构造函数”】
自定义的默认构造函数
如果既有类内初始值,在默认构造函数里面又有初始化,则以默认构造函数里的为准
说明:如果某数据成员使用类内初始值,同时又在构造函数中进行了初始化,那么以构造函数中的初始化为准。相当于构造函数中的初始化,会覆盖对应的类内初始值。



二.自定义的重载构造函数
1.构造函数的作用
初始化对象:自定义构造函数允许你在创建对象时对其进行初始化。您可以通过构造函数的参数传递初始值,或在构造函数中执行特定的初始化操作,确保对象在创建时处于正确的状态。
参数化构造:自定义构造函数可以接受参数,从而使对象的创建更加灵活和可定制化。通过不同的构造函数形式,可以为不同的使用场景提供不同的对象初始化方式。
代码可读性和维护性:通过显式定义构造函数,可以提高代码的可读性和维护性。构造函数明确地指示了对象的创建方式和初始化过程,使代码更加清晰易懂,并且便于后续修改维护。
// 定义一个“人类” class Human { public: Human();Human(int age, int salary);//自定义构造函数string getName();int getAge();int getSalary();private:string name = "Unknown";int age = 28;int salary; };Human::Human() {name = "无名氏";age = 18;salary = 30000; }Human::Human(int age, int salary) {cout << "调用自定义的构造函数" << endl; this->age = age; //this是一个特殊的指针,指向这个对象本身this->salary = salary;name = "无名"; }string Human::getName() {return name; }int Human::getAge() {return age; }int Human::getSalary() {return salary; }int main(void) {Human h1(25, 35000); // 使用自定义的默认构造函数cout << "姓名:" << h1.getName() << endl;cout << "年龄: " << h1.getAge() << endl; cout << "薪资:" << h1.getSalary() << endl; system("pause");return 0; }由此可以看出,自定义构造函数,只是比默认构造函数多了形参,由于创建的对象都形形色色,所以大多数情况下都会用自定义构造函数,在定义对象时,将参数传递进去给对象赋值
三.拷贝构造函数
1.浅拷贝
浅拷贝是指在对象拷贝过程中,仅简单地复制对象的成员变量值,而不复制成员变量所指向的动态分配的内存。这意味着原对象和拷贝对象将共享同一块内存区域,对其中一个对象的修改会影响到另一个对象。
在进行浅拷贝时,通常会使用默认的拷贝构造函数或赋值运算符重载来完成。这些默认的复制操作只会简单地逐个拷贝对象的成员变量的值。
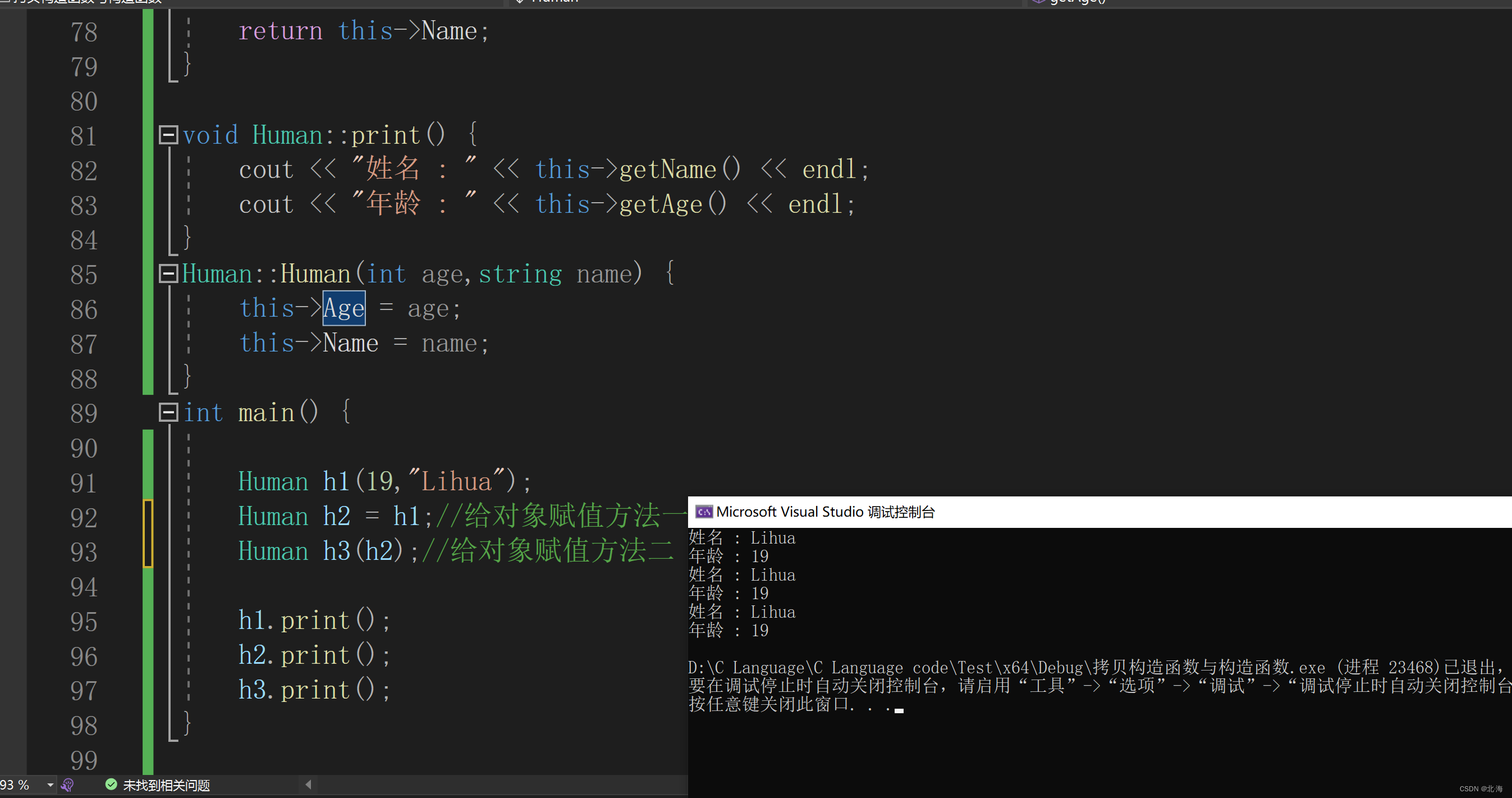
class Human { private:int Age=30;string Name ="LiHua"; public:Human(int age,string name);int getAge();string getName();void print(); };int Human::getAge() {return this->Age; }string Human::getName() {return this->Name; }void Human::print() {cout << "姓名 : " << this->getName() << endl;cout << "年龄 : " << this->getAge() << endl; } Human::Human(int age,string name) {this->Age = age;this->Name = name; } int main() {Human h1(19,"Lihua");Human h2 = h1;//给对象赋值方法一Human h3(h2);//给对象赋值方法二h1.print();h2.print();h3.print(); }
由此可以得出:给对象的赋值方法有两种,这两种方法都会调用拷贝构造函数,由于三个变量用的一块内存,所以说,改其中一个对象的值,其他三个的值都会被改变
上面两张图片中输出的地址是一个地址,改变一个对象的值,另一个对象的值也会改变,这就验证了,浅拷贝的结果是两个对象共用了一个地址
说明 : 默认的拷贝构造函数的缺点: 使用“浅拷贝”
2.深拷贝
根据上面浅拷贝中的例子,其中有个地址,如果h1想要改addr,但是h2却不想改他的addr,这种情况就需要用到深拷贝了,深拷贝就必须得写自定义的拷贝构造函数,例子如下:
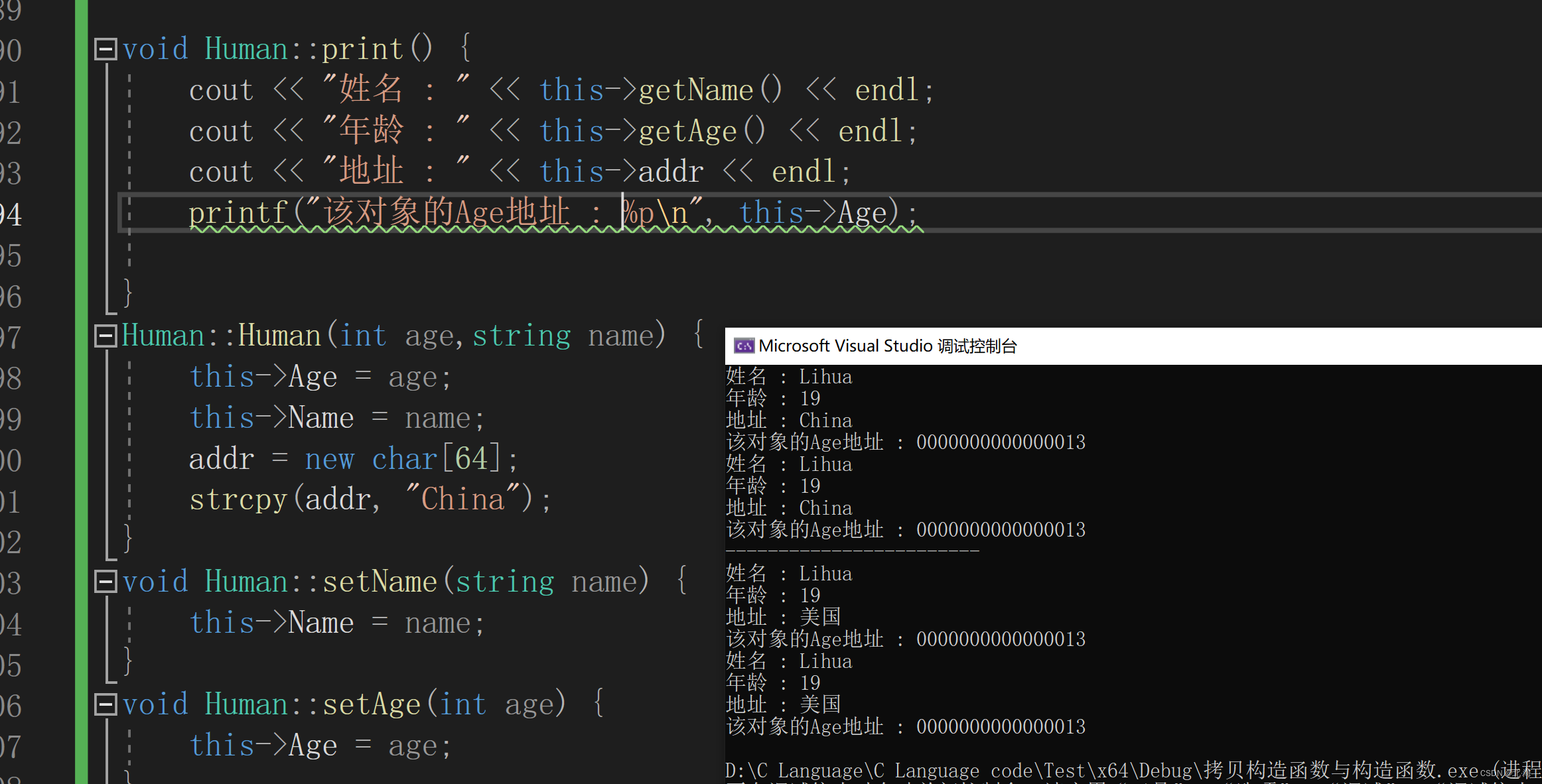
class Human { private:int Age=30;string Name ="LiHua";char* addr; public:Human(int age,string name);Human(const Human& the);~Human();//析构函数int getAge();string getName();void setAge(int age);void setName(string name);void setAddr(const char* addr);void print();}; int Human::getAge() {return this->Age; }string Human::getName() {return this->Name; }Human::~Human(){delete addr; }void Human::print() {cout << "姓名 : " << this->getName() << endl;cout << "年龄 : " << this->getAge() << endl;cout << "地址 : " << this->addr << endl;printf("该对象的addr地址 : %p\n", this->addr); } Human::Human(int age,string name) {this->Age = age;this->Name = name;addr = new char[64];strcpy(addr, "China"); } void Human::setName(string name) {this->Name = name; } void Human::setAge(int age) {this->Age = age; } void Human::setAddr(const char* addr) {if (!addr) {return;}strcpy(this->addr, addr); } Human::Human(const Human& the) {this->Age = the.Age;this->Name = the.Name;//给拷贝对象的addr重新分配内存,存储该地址this->addr = new char[64];strcpy(this->addr, the.addr); } int main() {Human h1(19,"Lihua");Human h2(h1);//给对象赋值方法一//Human h3=h1;//给对象赋值方法二h1.print();h2.print();//addr是char*类型h2.setAddr("美国");cout << "------------------------" << endl;h1.print();h2.print(); }
可以看到,此时通过深拷贝,两个对象的addr地址已经改变了
3.什么时候用到深拷贝/浅拷贝
对象拥有动态分配的资源:如果对象包含了动态分配的内存(如使用
new或malloc创建的内存),在进行拷贝时需要进行深拷贝。这是因为默认的浅拷贝(shallow copy)只会复制指针,而不会为新对象分配独立的内存空间,这可能会导致多个对象指向同一内存,造成资源释放问题或不可预测的行为。修改的独立性要求:如果你需要在拷贝对象后对其进行修改,而不希望修改影响到原始对象,那么深拷贝是必需的。深拷贝会创建一个完全独立的副本,修改副本不会影响原始对象。
对象包含指向其他对象的引用:当一个对象包含指向其他对象的引用或指针时,进行拷贝时可能需要进行深拷贝。这样可以确保每个对象都有自己的引用,而不是共享同一个引用。
需要注意的是,并非所有情况都需要进行深拷贝。有时候浅拷贝已经足够满足需求,尤其是当拷贝的对象是只读的或者没有包含指向动态分配资源的指针时。
在 C++ 中,可以通过自定义拷贝构造函数和赋值运算符重载来实现深拷贝
4.什么时候会调用拷贝构造函数
1.调用函数时,实参是对象,形参不是引用类型
2.函数的返回类型是类.而且不是引用类型
3.对象数组的初始化列表中,使用对象


四.赋值构造函数
1.赋值构造函数可以怎么样定义
使用重载运算符 " = "进行实现
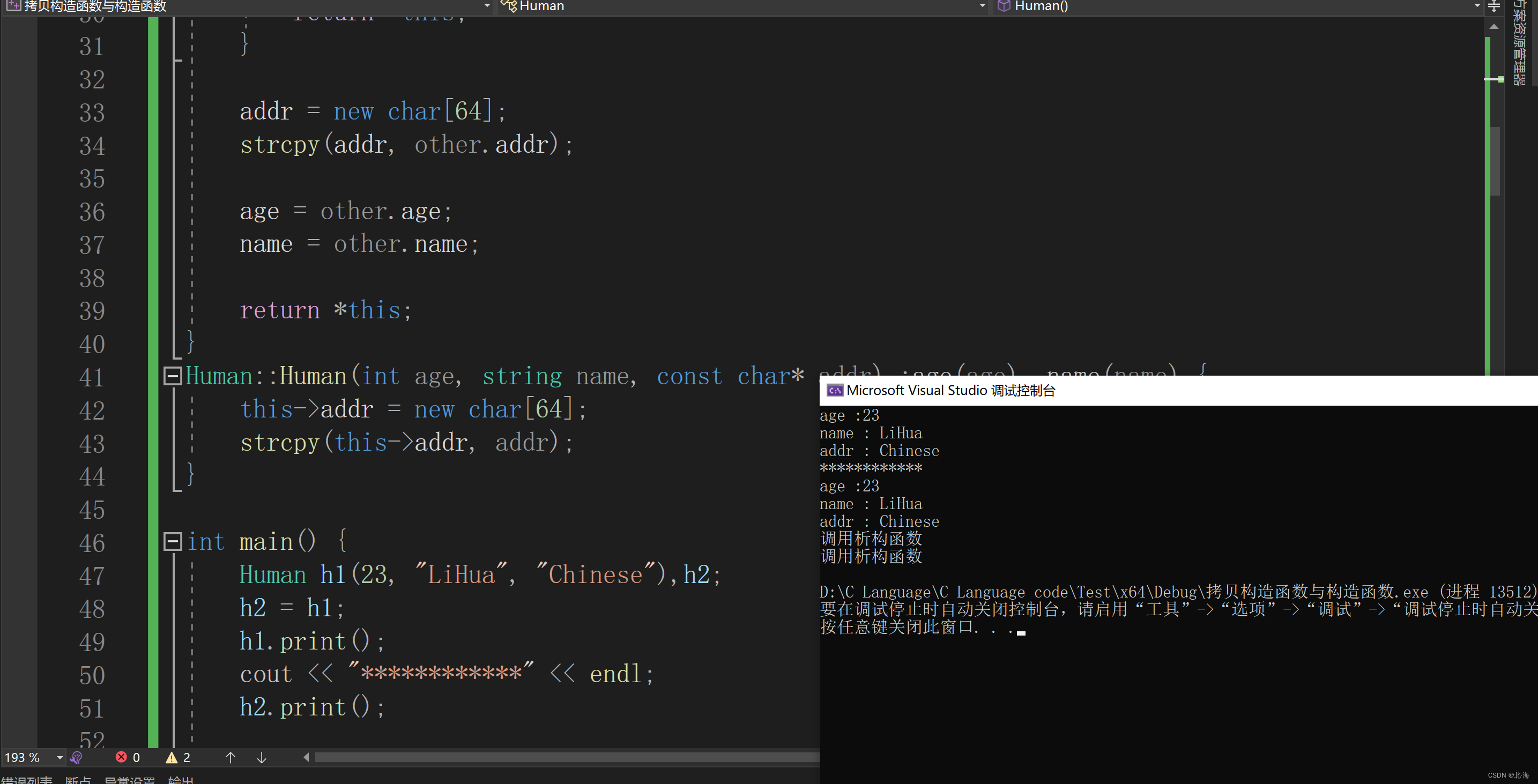
class Human { private:int age;string name;char* addr;public://通过重载 " = "实现Human& operator=(const Human& other);Human(int age, string name,const char*addr);Human(){}~Human() {cout << "调用析构函数" << endl;delete addr;}void print() {cout << "age :" << age << endl;cout << "name : " << name << endl;cout << "addr : " << addr << endl;} };Human& Human::operator=(const Human& other) {if (this == &other) {return *this;}addr = new char[64];strcpy(addr, other.addr);age = other.age;name = other.name;return *this; } Human::Human(int age, string name, const char* addr) :age(age), name(name) {this->addr = new char[64];strcpy(this->addr, addr); }int main() {Human h1(23, "LiHua", "Chinese"),h2;h2 = h1;h1.print();cout << "************" << endl;h2.print();}
2.赋值构造函数在什么时候会调用?
当用一个对象给另一个对象进行赋值时候会被调用,定义加赋值的话调用拷贝构造函数,例如:
int main(){Test p1(20); Test p2 = p1; 此时会调用拷贝构造函数 }class Test{..... public:Test(int n){ this.age =20; } Test test(Test & man){ //内联函数 return man;//返回对象 }};int main(){Test p1(20),p2; p2 = p1;//此时会调用赋值构造函数Test p3 = h1;//此时创建对象p3同时初始化,会调用的是拷贝构造函数 p2 = test(p1);//此时会调用赋值构造函数Test p4 =test(p1);//此时会调用拷贝构造函数}2.赋值构造函数与拷贝构造函数的区别
触发时机:拷贝构造函数在创建一个新对象并初始化时被调用,而赋值构造函数在已存在的对象进行赋值操作时被调用。
参数类型:拷贝构造函数使用被拷贝对象的引用作为参数,通常是常量引用,用于初始化新对象;而赋值构造函数使用所需赋值的对象的引用作为参数,用于将已存在的对象赋值给另一个已存在的对象。
功能:拷贝构造函数的主要目的是创建一个新对象,并将其初始化为与被拷贝对象相同的值。它通常用于深拷贝,确保新对象与原对象是独立的。赋值构造函数的主要目的是将一个已经存在的对象的值赋给另一个已经存在的对象。
默认实现:如果没有显式定义拷贝构造函数和赋值构造函数,C++ 编译器会为类生成默认的拷贝构造函数和默认的赋值构造函数。默认的拷贝构造函数会执行浅拷贝,简单地将成员变量的值复制给新对象。默认的赋值构造函数也执行浅拷贝,将每个成员变量的值从一个对象复制到另一个对象。
需要明确的是,拷贝构造函数和赋值构造函数在语法上是不同的,它们具有不同的函数形参和使用方式。在设计类时,根据对象的需求,需要选择正确的构造函数来满足对象的初始化和赋值操作。
五.析构函数
1.析构函数的基本概念
作用:
对象销毁前,做清理工作。
具体的清理工作,一般和构造函数对应
比如:如果在构造函数中,使用new分配了内存,就需在析构函数中用delete释放。
如果构造函数中没有申请资源(主要是内存资源),
那么很少使用析构函数。
函数名:
~类型
没有返回值,没有参数,最多只能有一个析构函数
访问权限:
一般都使用public
使用方法:
不能主动调用。
对象销毁时,自动调用。
如果不定义,编译器会自动生成一个析构函数(什么也不做)
2.容易将调用析构函数与delete释放内存混淆
在我接触析构函数的时候,一直懂得就是在对象被销毁的时候才会调用析构函数,但是每次在类的成员函数中遇到new出来的空间时,就会以为将delete写在该成员函数中,然后delete执行了就会去调用析构函数,这个从逻辑上都是说不过去的
现在懂得概念很明确,只有在对象销毁的时候调用,在类的成员函数或者构造函数中遇到new出来的空间时候,就应该给析构函数里面写delete释放该空间,等到对象被销毁的时候,就会去调用析构函数,就会执行delete语句将内存释放
现在来看这么一个简单的例子,输出的顺序,就明白,只有对象被销毁的时候才会调用析构函数,遇见了new,就应该在析构函数里面写delete
class Human { private:int age;string name;char* addr;public:Human() {cout << "调用构造函数" << endl;addr = new char[64];}~Human() {cout << "调用析构函数" << endl;delete[]this->addr;}void print() {cout << "调用print函数" << endl;strcpy(addr, "China");cout << addr << endl;} };int main() {Human p1;p1.print(); }

总结:
"在C++中,构造函数和析构函数是类的特殊成员函数,它们扮演着至关重要的角色。通过构造函数,我们可以初始化对象的状态,确保对象在被创建时处于合适的状态。而析构函数则负责在对象生命周期结束时进行善后工作,释放动态分配的资源,保证对象的安全销毁。深入理解和合理设计构造函数和析构函数,可以帮助我们编写更可靠、高效的C++程序,有效地管理资源,避免内存泄漏和访问冲突。构造与毁灭是C++编程中的关键概念,它们共同构成了面向对象编程中的基石,为我们提供了强大而灵活的工具,让我们能够更好地利用和管理对象的生命周期。"
相关文章:

[C++]构造与毁灭:深入探讨C++中四种构造函数与析构函数
个人主页:北海 🎐CSDN新晋作者 🎉欢迎 👍点赞✍评论⭐收藏✨收录专栏:C/C🤝希望作者的文章能对你有所帮助,有不足的地方请在评论区留言指正,大家一起学习交流!ǹ…...

【跟小嘉学 Rust 编程】二十一、网络编程
系列文章目录 【跟小嘉学 Rust 编程】一、Rust 编程基础 【跟小嘉学 Rust 编程】二、Rust 包管理工具使用 【跟小嘉学 Rust 编程】三、Rust 的基本程序概念 【跟小嘉学 Rust 编程】四、理解 Rust 的所有权概念 【跟小嘉学 Rust 编程】五、使用结构体关联结构化数据 【跟小嘉学…...
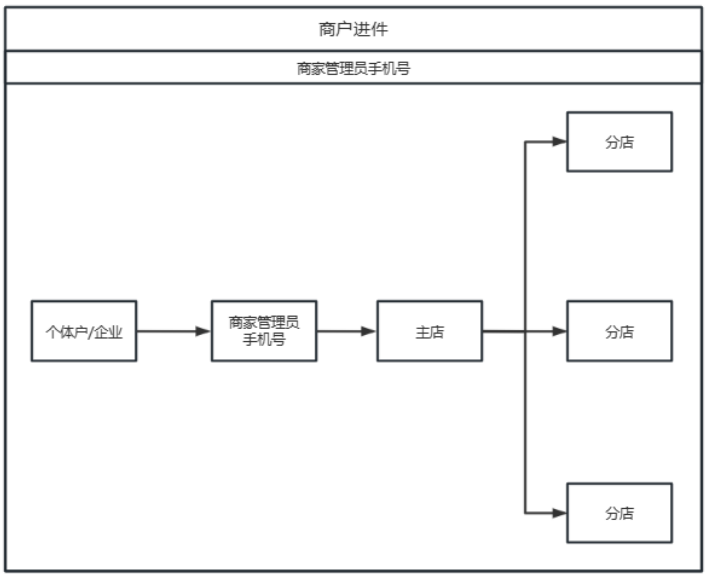
一文了解聚合支付
第四方支付是相对于第三方支付而提出的概念,又被称为“聚合支付”是指通过聚合第三方支付平台、合作银行、等多种支付工具进行的综合支付服务。 简言而之,把支付接口聚合到一个平台上面,来给商家或者个人来提供支付服务。 第四方支付集中了各…...
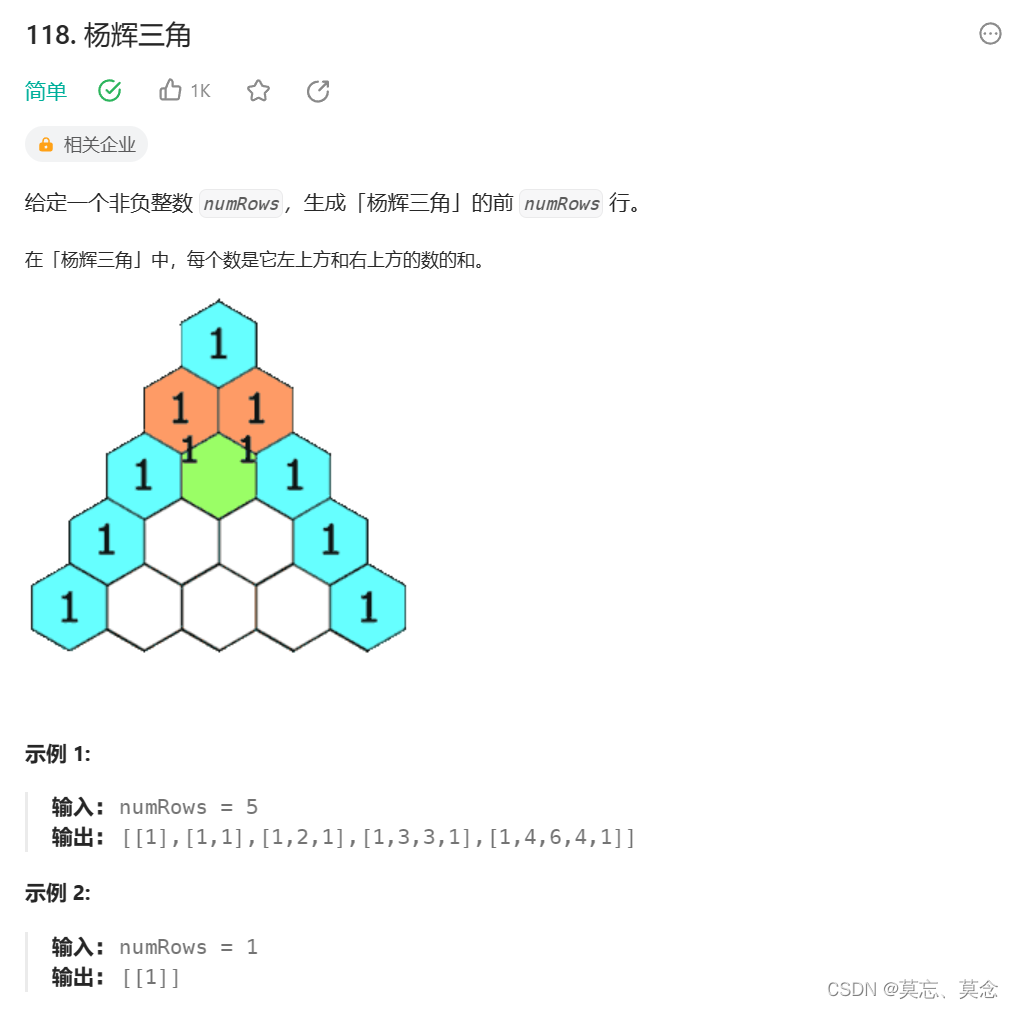
118.杨辉三角
一、题目 118. 杨辉三角 - 力扣(LeetCode) 二、代码 class Solution { public:vector<vector<int>> generate(int numRows) {vector<vector<int>>data(numRows);for(int i0;i<numRows;i){data[i].resize(i1);//扩容data[i]…...
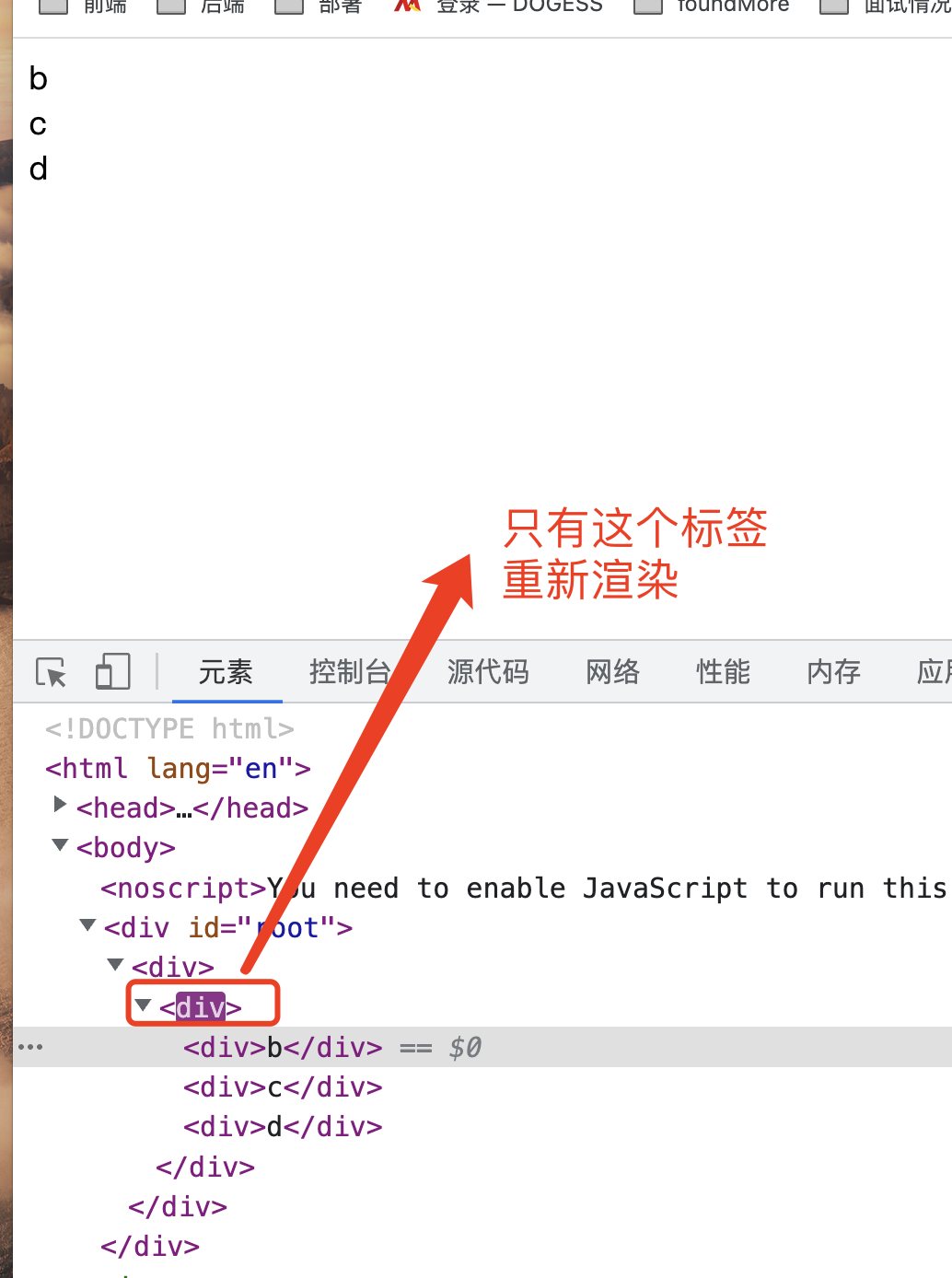
第7节——渲染列表+Key作用
一、列表渲染 我们再react中如果渲染列表,一般使用map方法进行渲染 import React from "react";export default class LearnJSX2 extends React.Component {state {infos: [{name: "张三",age: 18,},{name: "李四",age: 20,},{nam…...

NTP服务器时间配置
简介 ntp服务器是一个同步时间都服务器。 开启ntpd 1.查看状态(可以看到状态为:inactive,也就是没有启动ntp服务) [rootlocalhost]$ systemctl status ntpd ● ntpd.service - Network Time ServiceLoaded: loaded (/usr/lib/…...
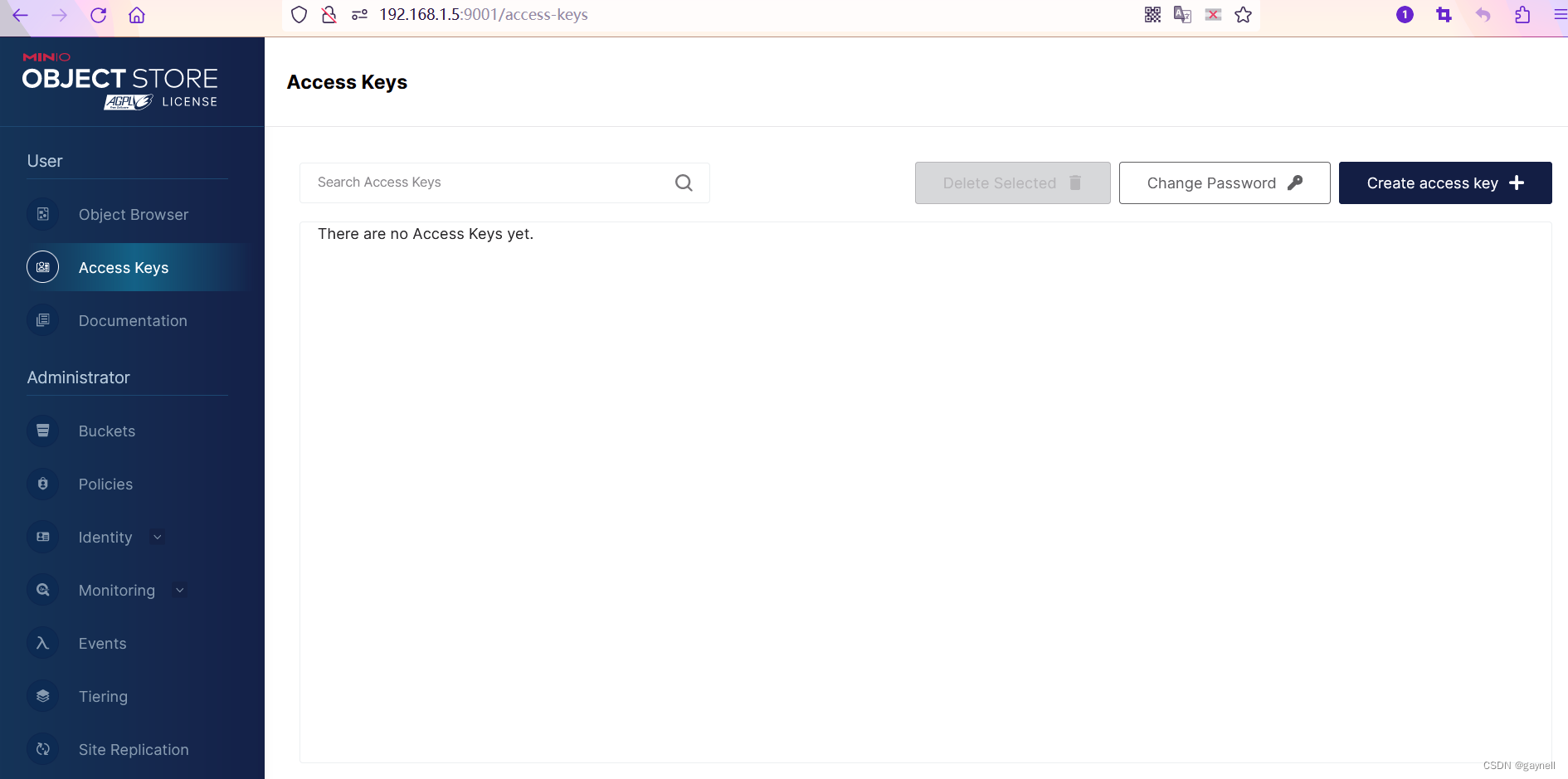
vulhub之MinIO信息泄露漏洞(CVE-2023-28432)
文章目录 0x01 前言0x02 漏洞描述0x03 影响范围0x04 漏洞复现1.启动环境2.查看端口3.构造POC 0x05 修复建议 0x01 前言 本次测试仅供学习使用,如若非法他用,与本文作者无关,需自行负责!!! 0x02 漏洞描述 …...

C语言:递归思想及实例详解
简介:在计算机科学中是指一种通过重复将问题分解为同类的子问题而解决问题的方法。通过函数的自调用化繁为简。 递归可以说是编程中最神奇的一种算法。因为我们有时候可能不能完全明晰代码的运行过程,但是我们却知道代码可以跑出正确的结果。而当我们使…...

好题分享0
P2141 [NOIP2014 普及组] 珠心算测验 原题链接 : [NOIP2014 普及组] 珠心算测验 - 洛谷 思路 : 用哈希表来存出现过的两数之和,最后ans即可 代码 : #include<bits/stdc.h> #define IOS ios::sync_with_stdio(0);cin.tie(0);cout.tie(0); #define end…...
python的asyncio事件循环
一、介绍 asyncio是Python标准库中的一个异步编程框架,它提供了一个事件循环(event loop),用于协调异步任务的执行和结果的返回。在asyncio中,事件循环是一个非常重要的概念,它是异步编程的核心。 事件循…...

QT day1登录界面设计
要设计如下图片: 代码如下: main.cpp widget.h widget.cpp 运行效果: 2,思维导图...
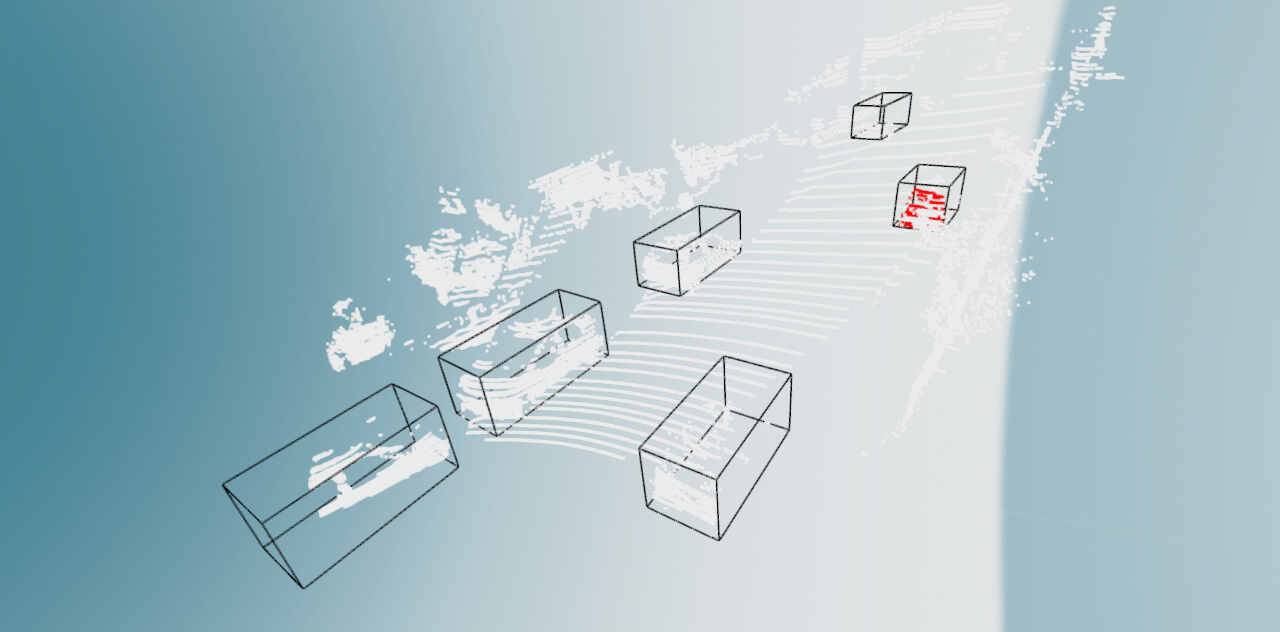
(一)KITTI数据集用于3D目标检测
KITTI数据集介绍 数据基本情况 KITTI是德国卡尔斯鲁厄科技学院和丰田芝加哥研究院开源的数据集,最早发布于2012年03月20号。 对应的论文Are we ready for Autonomous Driving? The KITTI Vision Benchmark Suite发表在CVPR2012上。 KITTI数据集搜集自德国卡尔斯鲁厄市&…...

手写Promise完整介绍
Promise是一种用于处理异步操作的机制,它可以将异步操作的结果以同步的方式进行处理和返回。在JavaScript中,Promise是一种内置对象,但我们也可以手动实现一个Promise类来更好地理解其原理和工作方式。 Promise的特性 首先,让我…...
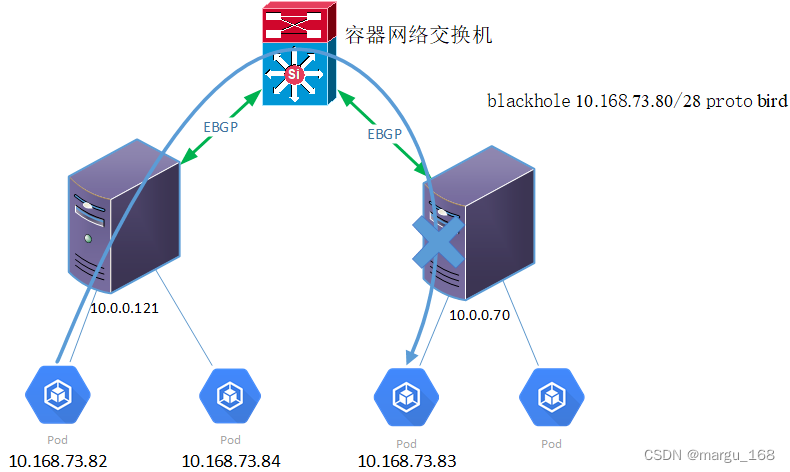
【kubernetes系列】Calico原理及配置
概述 Calico是针对容器,虚拟机和基于主机的本机工作负载的开源网络和网络安全解决方案。 Calico支持广泛的平台,包括Kubernetes,OpenShift,Docker EE,OpenStack和裸机服务。 Calico在每个计算节点都利用Linux Kernel实…...
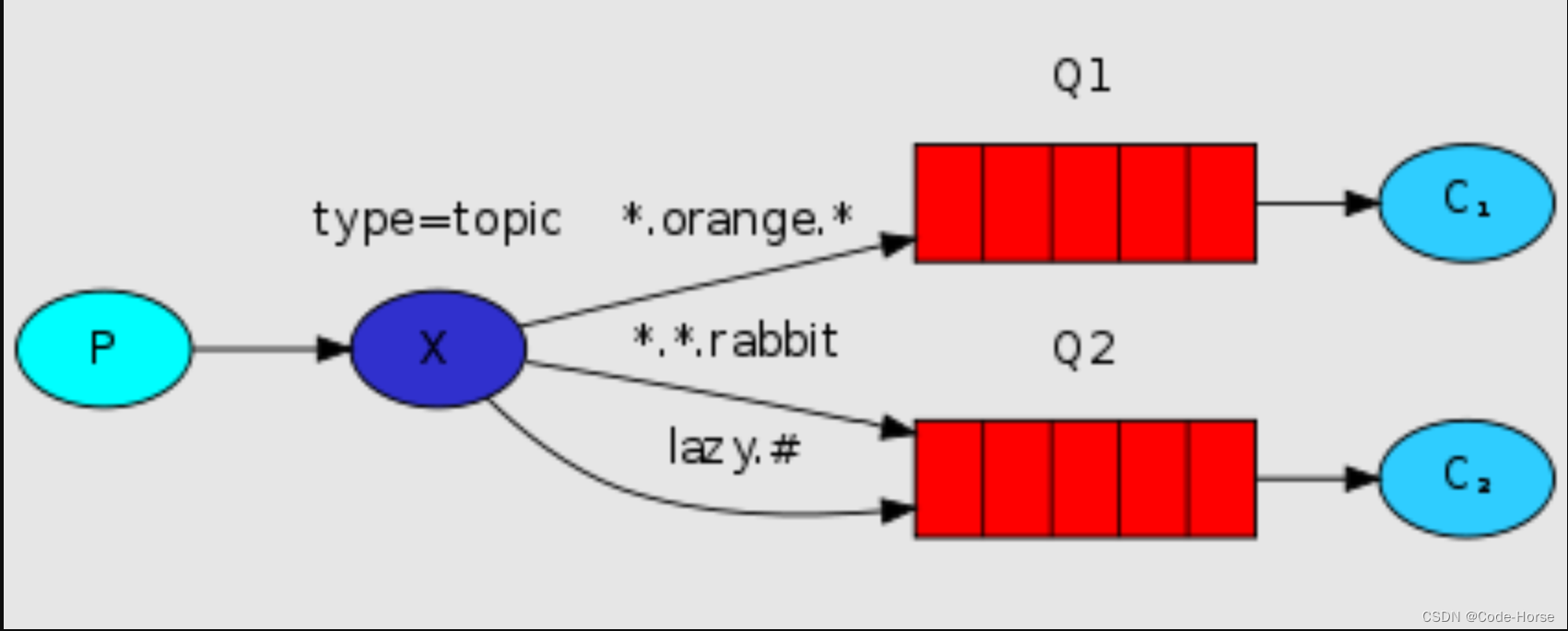
RabbitMQ 的快速使用
docker部署rabbitmq # management才有管理页面 docker pull rabbitmq:management# 新建容器并运行 docker run \-e RABBITMQ_DEFAULT_USERadmin \ -e RABBITMQ_DEFAULT_PASSadmin \ -v mq-plugins:/plugins \--name mq \--hostname mq \-p 15672:15672 \-p 5672:5672 \-itd \ra…...

VUE3添加全局变量
全局变量的添加 在vue3.0中注入全局方法不是在prototype上挂载了,而是添加在config.globalProperties属性上。 //main.js import { createApp } from "vue"; import App from "./App.vue";const app createApp(App); app.config.globalPrope…...
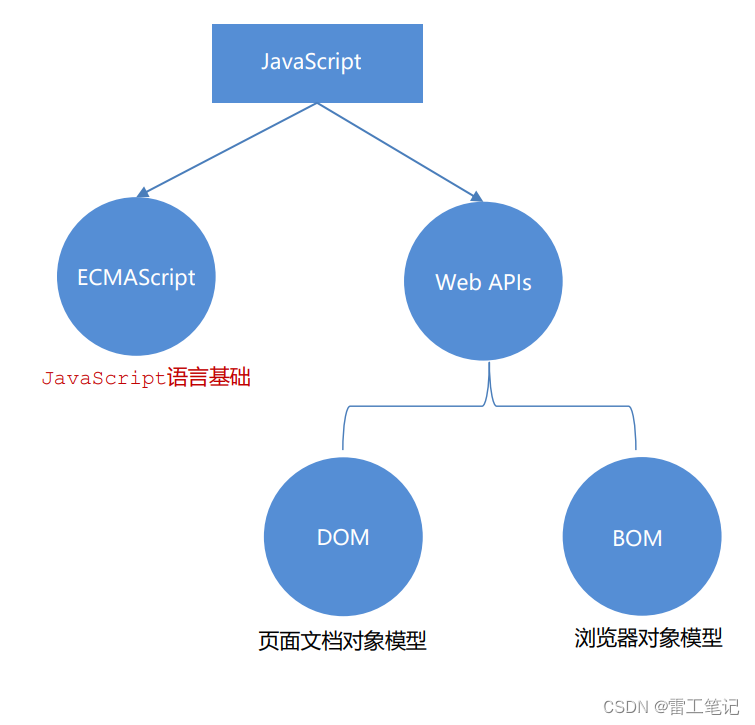
JavaScript基础语法01——初识JavaScript
哈喽,大家好,我是雷工! 最近有项目用到KingFusion软件,由于KingFusion是B/S架构的客户端组态软件,因此在学习KingFusion产品时会涉及许多前端的知识。 像JavaScript语言就是需要用的,俗话说:活到…...
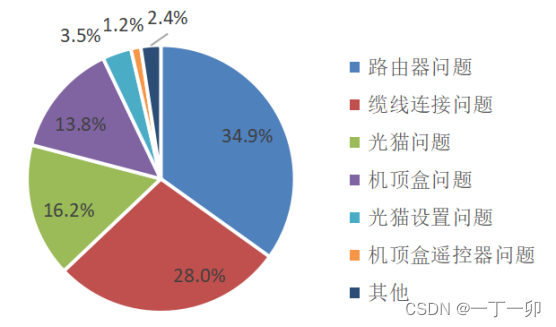
家宽用户家庭网的主要质量问题是什么?原因有哪些
1 引言 截至2020年底,我国家庭宽带(以下简称“家宽”)普及率已达到96%。经过一年多的发展,当前,家庭宽带的市场空间已经饱和。运营商在家宽市场的竞争也随之从新增用户数的竞争转移到家宽品质的竞争。 早期运营商的家…...
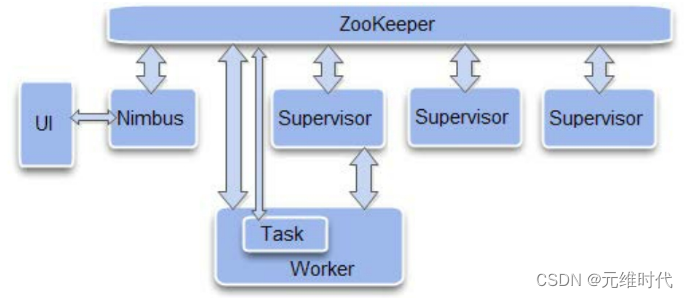
ZooKeeper的典型应用场景及实现
文章目录 1、典型应用场景及实现1.1、 数据发布/订阅1.1.1、配置管理案列 1.2、负载均衡1.3、命名服务1.4、分布式协调/通知1.4.1、一种通用的分布式系统机器间通信方式 1.5、集群管理1.6、Master选举1.7、分布式锁1.7.1、排他锁1.7.2、共享锁 1.8、分布式队列 2、ZooKeeper在大…...

智能安全帽~生命体征检测与危险气体检测一体化集成设计还是蓝牙无线外挂式方式好?
生命体征(心率、血氧等)检测&上报平台,危险气体采集&上报平台,是智能安全帽产品中常见的两种选配件,它们的实现有两种典型的模式: 1)将传感器集成到主板上,做成一体化的智能…...

VB.net复制Ntag213卡写入UID
本示例使用的发卡器:https://item.taobao.com/item.htm?ftt&id615391857885 一、读取旧Ntag卡的UID和数据 Private Sub Button15_Click(sender As Object, e As EventArgs) Handles Button15.Click轻松读卡技术支持:网站:Dim i, j As IntegerDim cardidhex, …...

【入坑系列】TiDB 强制索引在不同库下不生效问题
文章目录 背景SQL 优化情况线上SQL运行情况分析怀疑1:执行计划绑定问题?尝试:SHOW WARNINGS 查看警告探索 TiDB 的 USE_INDEX 写法Hint 不生效问题排查解决参考背景 项目中使用 TiDB 数据库,并对 SQL 进行优化了,添加了强制索引。 UAT 环境已经生效,但 PROD 环境强制索…...
)
IGP(Interior Gateway Protocol,内部网关协议)
IGP(Interior Gateway Protocol,内部网关协议) 是一种用于在一个自治系统(AS)内部传递路由信息的路由协议,主要用于在一个组织或机构的内部网络中决定数据包的最佳路径。与用于自治系统之间通信的 EGP&…...

渗透实战PortSwigger靶场-XSS Lab 14:大多数标签和属性被阻止
<script>标签被拦截 我们需要把全部可用的 tag 和 event 进行暴力破解 XSS cheat sheet: https://portswigger.net/web-security/cross-site-scripting/cheat-sheet 通过爆破发现body可以用 再把全部 events 放进去爆破 这些 event 全部可用 <body onres…...

Linux简单的操作
ls ls 查看当前目录 ll 查看详细内容 ls -a 查看所有的内容 ls --help 查看方法文档 pwd pwd 查看当前路径 cd cd 转路径 cd .. 转上一级路径 cd 名 转换路径 …...

Vue2 第一节_Vue2上手_插值表达式{{}}_访问数据和修改数据_Vue开发者工具
文章目录 1.Vue2上手-如何创建一个Vue实例,进行初始化渲染2. 插值表达式{{}}3. 访问数据和修改数据4. vue响应式5. Vue开发者工具--方便调试 1.Vue2上手-如何创建一个Vue实例,进行初始化渲染 准备容器引包创建Vue实例 new Vue()指定配置项 ->渲染数据 准备一个容器,例如: …...

学习STC51单片机31(芯片为STC89C52RCRC)OLED显示屏1
每日一言 生活的美好,总是藏在那些你咬牙坚持的日子里。 硬件:OLED 以后要用到OLED的时候找到这个文件 OLED的设备地址 SSD1306"SSD" 是品牌缩写,"1306" 是产品编号。 驱动 OLED 屏幕的 IIC 总线数据传输格式 示意图 …...

【Oracle】分区表
个人主页:Guiat 归属专栏:Oracle 文章目录 1. 分区表基础概述1.1 分区表的概念与优势1.2 分区类型概览1.3 分区表的工作原理 2. 范围分区 (RANGE Partitioning)2.1 基础范围分区2.1.1 按日期范围分区2.1.2 按数值范围分区 2.2 间隔分区 (INTERVAL Partit…...

sipsak:SIP瑞士军刀!全参数详细教程!Kali Linux教程!
简介 sipsak 是一个面向会话初始协议 (SIP) 应用程序开发人员和管理员的小型命令行工具。它可以用于对 SIP 应用程序和设备进行一些简单的测试。 sipsak 是一款 SIP 压力和诊断实用程序。它通过 sip-uri 向服务器发送 SIP 请求,并检查收到的响应。它以以下模式之一…...

安宝特案例丨Vuzix AR智能眼镜集成专业软件,助力卢森堡医院药房转型,赢得辉瑞创新奖
在Vuzix M400 AR智能眼镜的助力下,卢森堡罗伯特舒曼医院(the Robert Schuman Hospitals, HRS)凭借在无菌制剂生产流程中引入增强现实技术(AR)创新项目,荣获了2024年6月7日由卢森堡医院药剂师协会࿰…...