【Kafka】Kafka Stream简单使用
一、实时流式计算
1. 概念
一般流式计算会与批量计算相比较。在流式计算模型中,输入是持续的,可以认为在时间上是无界的,也就意味着,永远拿不到全量数据去做计算。同时,计算结果是持续输出的,也即计算结果在时间上也是无界的。流式计算一般对实时性要求较高,同时一般是先定义目标计算,然后数据到来之后将计算逻辑应用于数据。同时为了提高计算效率,往往尽可能采用增量计算代替全量计算
流式计算就相当于上图的右侧扶梯,是可以源源不断的产生数据,源源不断的接收数据,没有边界。

2. 应用场景
- 日志分析: 网站的用户访问日志进行实时的分析,计算访问量,用户画像,留存率等等,实时的进行数据分析,帮助企业进行决策
- 大屏看板统计: 可以实时的查看网站注册数量,订单数量,购买数量,金额等。
- 公交实时数据: 可以随时更新公交车方位,计算多久到达站牌等
- 实时文章分值计算
比如应用较广的 头条类文章的分值计算,通过用户的行为实时文章的分值,分值越高就越被推荐。
3. Kafka Stream
近些年来,开源流处理领域涌现出了很多优秀框架。光是在 Apache 基金会孵化的项目,关于流处理的大数据框架就有十几个之多,比如早期的
Apache Samza、Apache Storm,以及这些年火爆的Spark以及Flink等。
3.1 Kafka Streams的特点
Kafka Stream提供了一个非常简单而轻量的Library,它可以非常方便地嵌入任意Java应用中,也可以任意方式打包和部署- 除了
Kafka外,无任何外部依赖 - 充分利用
Kafka分区机制实现水平扩展和顺序性保证 - 通过可容错的
state store实现高效的状态操作(如windowed join和aggregation) - 支持正好一次处理语义
- 提供记录级的处理能力,从而实现
毫秒级的低延迟 - 支持基于事件时间的窗口操作,并且可处理晚到的数据(late arrival of records)
- 同时提供底层的处理原语
Processor(类似于Storm的spout和bolt),以及高层抽象的DSL(类似于Spark的map/group/reduce)

3.2 关键概念
一个最简单的Streaming的结构如下图所示:
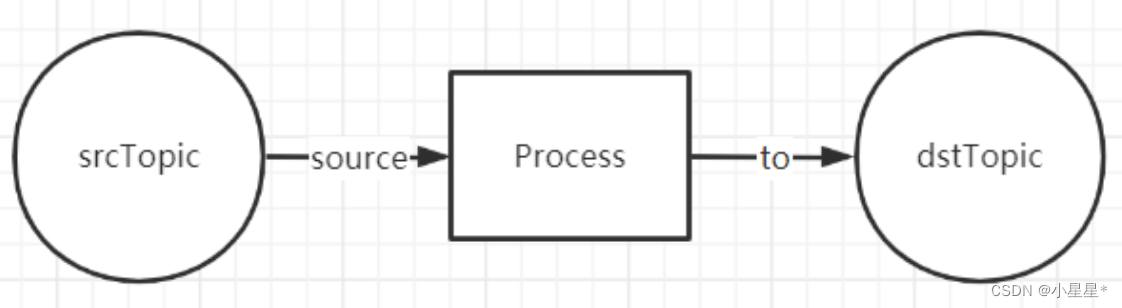
从一个Topic中读取到数据,经过一些处理操作之后,写入到另一个Topic中,这就是一个最简单的Streaming流式计算。其中,Source Topic中的数据会源源不断的产生新数据。
那么,我们再在上面的结构之上扩展一下,假设定义了多个Source Topic及Destination Topic,那就构成如下图所示的较为复杂的拓扑结构:
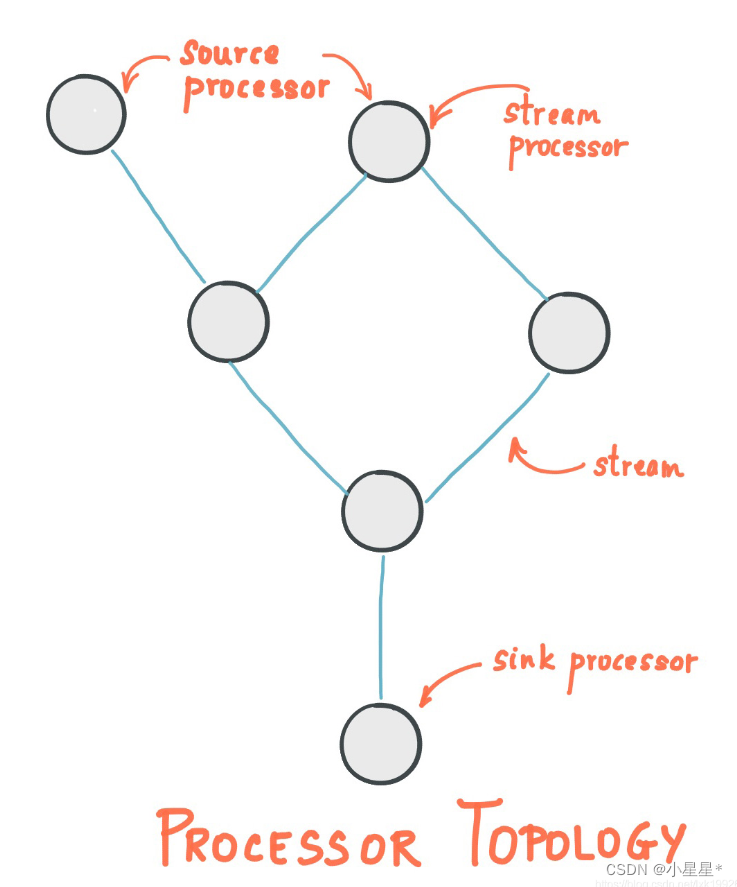
- 源处理器(Source Processor):源处理器是一个没有任何上游处理器的特殊类型的流处理器。它从一个或多个
kafka主题生成输入流。通过消费这些主题的消息并将它们转发到下游处理器。 - Sink处理器:sink处理器是一个没有下游流处理器的特殊类型的流处理器。它接收上游流处理器的消息发送到一个指定的Kafka主题。
Kafka Streams被认为是开发实时应用程序的最简单方法。它是一个Kafka的客户端API库,编写简单的java就可以实现流式处理。
3.3 KStream
KStream:数据结构类似于map,如下图,key-value键值对

KStream数据流(data stream),是一段顺序的,可以无限长,不断更新的数据集。
数据流中比较常记录的是事件,这些事件可以是一次鼠标点击(click),一次交易,或是传感器记录的位置数据。
KStream负责抽象的,就是数据流。与Kafka自身topic中的数据一样,类似日志,每一次操作都是向其中插入(insert)新数据。
二、测试kafkaStream
先看下简单的kafkaStream的KStream测试
需求分析:求单词个数(word count)
1. pom.xml引入依赖:
<!-- kafka --><dependency><groupId>org.springframework.kafka</groupId><artifactId>spring-kafka</artifactId><exclusions><exclusion><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId></exclusion></exclusions></dependency><dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId></dependency><dependency><groupId>com.alibaba</groupId><artifactId>fastjson</artifactId></dependency><dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-streams</artifactId><exclusions><exclusion><artifactId>connect-json</artifactId><groupId>org.apache.kafka</groupId></exclusion><exclusion><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId></exclusion></exclusions></dependency>
2. 配置文件
server:port: 9991
spring:application:name: kafka-demokafka:bootstrap-servers: 192.168.200.130:9092producer:retries: 10key-serializer: org.apache.kafka.common.serialization.StringSerializervalue-serializer: org.apache.kafka.common.serialization.StringSerializercompression-type: lz4consumer:group-id: ${spring.application.name}-testkey-deserializer: org.apache.kafka.common.serialization.StringDeserializervalue-deserializer: org.apache.kafka.common.serialization.StringDeserializer
3. 编写生产者
ProducerQuickStart.java
package com.kafka.sample;import lombok.extern.slf4j.Slf4j;
import org.apache.kafka.clients.producer.*;import java.util.Properties;@Slf4j
public class ProducerQuickStart {public static void main(String[] args) {//1. kafka的配置信息Properties prop = new Properties();//kafka的链接信息prop.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.200.130:9092");//配置重试次数prop.put(ProducerConfig.RETRIES_CONFIG, 5);//数据压缩prop.put(ProducerConfig.COMPRESSION_TYPE_CONFIG,"lz4");//ack配置 消息确认机制 默认ack=1,即只要集群首领节点收到消息,生产者就会收到一个来自服务器的成功响应
// prop.put(ProducerConfig.ACKS_CONFIG,"all");消息key的序列化器prop.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");//消息value的序列化器prop.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");//2. 生产者对象KafkaProducer<String, String> producer = new KafkaProducer<String, String>(prop);//封装发送的消息ProducerRecord<String, String> producerRecord = new ProducerRecord<String, String>("itcast-topic-input", "key_001", "hello kafka");//3. 发送消息for (int i = 0; i < 5; i++) {producer.send(producerRecord);}//4. 关闭消息通道 必须关闭,否则消息发不出去producer.close();}
}
4 编写kafkaStream流式处理
KafkaStreamQuickStart.java
package com.kafka.sample;import org.apache.kafka.common.serialization.Serdes;
import org.apache.kafka.streams.KafkaStreams;
import org.apache.kafka.streams.KeyValue;
import org.apache.kafka.streams.StreamsBuilder;
import org.apache.kafka.streams.StreamsConfig;
import org.apache.kafka.streams.kstream.KStream;
import org.apache.kafka.streams.kstream.TimeWindows;
import org.apache.kafka.streams.kstream.ValueMapper;import java.time.Duration;
import java.util.Arrays;
import java.util.Properties;/*** 流式处理*/
public class KafkaStreamQuickStart {public static void main(String[] args) {//kafka的配置信心Properties prop = new Properties();prop.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.200.130:9092");prop.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());prop.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());prop.put(StreamsConfig.APPLICATION_ID_CONFIG,"streams-quickstart");//stream 构建器StreamsBuilder streamsBuilder = new StreamsBuilder();//流式计算streamProcessor(streamsBuilder);//创建kafkaStream对象KafkaStreams kafkaStreams = new KafkaStreams(streamsBuilder.build(),prop);//开启流式计算kafkaStreams.start();}/*** 流式计算* 消息的内容:hello kafka hello itcast* @param streamsBuilder*/private static void streamProcessor(StreamsBuilder streamsBuilder) {//创建kstream对象,同时指定从那个topic中接收消息KStream<String, String> stream = streamsBuilder.stream("itcast-topic-input");/*** 处理消息的value*/stream.flatMapValues(new ValueMapper<String, Iterable<String>>() {@Overridepublic Iterable<String> apply(String value) {return Arrays.asList(value.split(" "));}})//按照value进行聚合处理.groupBy((key,value)->value)//时间窗口.windowedBy(TimeWindows.of(Duration.ofSeconds(10)))//统计单词的个数.count()//转换为kStream.toStream().map((key,value)->{System.out.println("key:"+key+",vlaue:"+value);return new KeyValue<>(key.key().toString(),value.toString());})//发送消息.to("itcast-topic-out");}
}
5. 编写消费者
ConsumerQuickStart.java
package com.kafka.sample;import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;import java.time.Duration;
import java.util.Collections;
import java.util.Properties;public class ConsumerQuickStart {public static void main(String[] args) {//1. 添加kafka的配置信息Properties properties = new Properties();// 配置链接信息properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.200.130:9092");//配置消费者组properties.put(ConsumerConfig.GROUP_ID_CONFIG, "group-2");//配置消息的反序列化器properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");//2. 消费者对象KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(properties);//3. 订阅主题consumer.subscribe(Collections.singletonList("itcast-topic-out"));//当前线程一直监听消息while(true){//4. 消费者拉取消息: 每秒拉取一次ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000));for (ConsumerRecord<String, String> record : records) {System.out.println(record.key());System.out.println(record.value());}}}
}
启动项目:
- 在远端(
192.168.200.130:9092)启动docker中的kafka容器- 启动消费者
ConsumerQuickStart的main函数- 启动
kafkastream的mian函数- 启动生产者
ProducerQuickStart的main函数
5. 控制台打印结果:
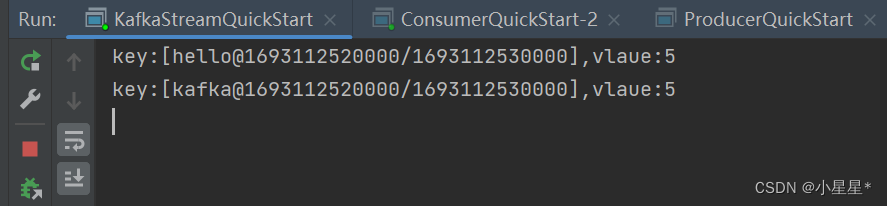
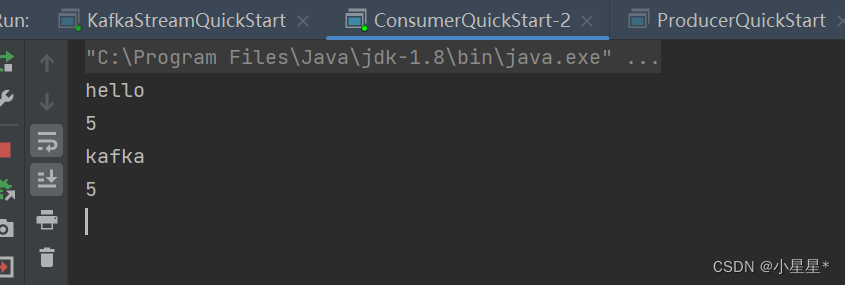
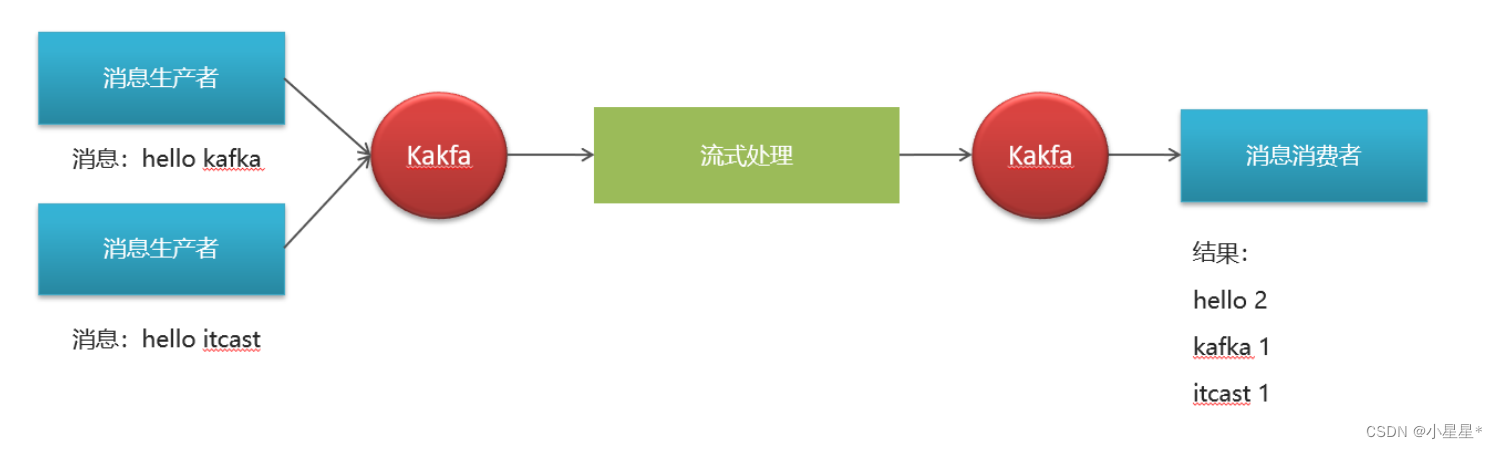
整个过程:
生产者向kafka中发送了5条“hello kafka”消息,topic均为itcast-topic-input。kafkastream监听这个topic,每10秒进行一次流式处理,将“hello kakfa”字符串分割,并统计每个单词出现的次数。然后转为kstream,发送消息到kafka中的topic=itcast-topic-out”。消费者监听“itcast-topic-out”的topic,消费消息。
三、Springboot整合kafkaStream
1. 配置文件新增
application.yml
server:port: 9991
spring:application:name: kafka-demokafka:bootstrap-servers: 192.168.200.130:9092producer:retries: 10key-serializer: org.apache.kafka.common.serialization.StringSerializervalue-serializer: org.apache.kafka.common.serialization.StringSerializercompression-type: lz4consumer:group-id: ${spring.application.name}-testkey-deserializer: org.apache.kafka.common.serialization.StringDeserializervalue-deserializer: org.apache.kafka.common.serialization.StringDeserializer
# kafkaStream新增以下配置
kafka:hosts: 192.168.200.130:9092group: ${spring.application.name}
2. 在微服务中新增配置类
KafkaStreamConfig.java
package com.kafka.config;import lombok.Getter;
import lombok.Setter;
import org.apache.kafka.common.serialization.Serdes;
import org.apache.kafka.streams.StreamsConfig;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.kafka.annotation.EnableKafkaStreams;
import org.springframework.kafka.annotation.KafkaStreamsDefaultConfiguration;
import org.springframework.kafka.config.KafkaStreamsConfiguration;import java.util.HashMap;
import java.util.Map;/*** 通过重新注册KafkaStreamsConfiguration对象,设置自定配置参数*/@Setter
@Getter
@Configuration
@EnableKafkaStreams
@ConfigurationProperties(prefix="kafka")
public class KafkaStreamConfig {private static final int MAX_MESSAGE_SIZE = 16* 1024 * 1024;private String hosts;private String group;@Bean(name = KafkaStreamsDefaultConfiguration.DEFAULT_STREAMS_CONFIG_BEAN_NAME)public KafkaStreamsConfiguration defaultKafkaStreamsConfig() {Map<String, Object> props = new HashMap<>();props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, hosts);props.put(StreamsConfig.APPLICATION_ID_CONFIG, this.getGroup()+"_stream_aid");props.put(StreamsConfig.CLIENT_ID_CONFIG, this.getGroup()+"_stream_cid");props.put(StreamsConfig.RETRIES_CONFIG, 10);props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());return new KafkaStreamsConfiguration(props);}
}
3. 使用kafkaStream监听消息
KafkaStreamHelloListener.java
package com.kafka.stream;import lombok.extern.slf4j.Slf4j;
import org.apache.kafka.streams.KeyValue;
import org.apache.kafka.streams.StreamsBuilder;
import org.apache.kafka.streams.kstream.KStream;
import org.apache.kafka.streams.kstream.TimeWindows;
import org.apache.kafka.streams.kstream.ValueMapper;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;import java.time.Duration;
import java.util.Arrays;@Configuration
@Slf4j
public class KafkaStreamHelloListener {@Beanpublic KStream<String,String> kStream(StreamsBuilder streamsBuilder){//创建kstream对象,同时指定从那个topic中接收消息KStream<String, String> stream = streamsBuilder.stream("itcast-topic-input");stream.flatMapValues(new ValueMapper<String, Iterable<String>>() {@Overridepublic Iterable<String> apply(String value) {return Arrays.asList(value.split(" "));}})//根据value进行聚合分组.groupBy((key,value)->value)//聚合计算时间间隔.windowedBy(TimeWindows.of(Duration.ofSeconds(10)))//求单词的个数.count().toStream()//处理后的结果转换为string字符串.map((key,value)->{System.out.println("key:"+key+",value:"+value);return new KeyValue<>(key.key().toString(),value.toString());})//发送消息.to("itcast-topic-out");return stream;}
}
测试:
启动springboot应用程序,运行之前的ProducerQuickStart来生产消息,约10秒后,看到kafkaStream消息的处理结果
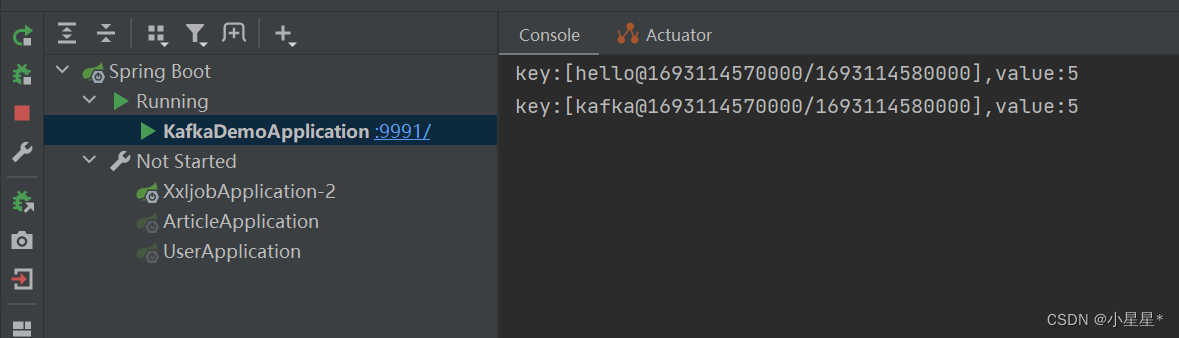
说明kafkaStream接收到消息并将多条消息进行了统一处理。
参考(推荐阅读):
- https://cloud.tencent.com/developer/article/2100664
- https://www.cnblogs.com/tree1123/p/11457851.html
相关文章:
【Kafka】Kafka Stream简单使用
一、实时流式计算 1. 概念 一般流式计算会与批量计算相比较。在流式计算模型中,输入是持续的,可以认为在时间上是无界的,也就意味着,永远拿不到全量数据去做计算。同时,计算结果是持续输出的,也即计算结果…...

在Linux服务器上,查看系统最近的重启记录
在Linux服务器上,您可以查看系统的重启记录以了解系统何时进行了重启。系统的重启记录通常被记录在系统日志文件中。以下是在不同Linux发行版上查看系统重启记录的方法: 1. 使用 last 命令: 打开终端,并输入以下命令来查看系统的…...
Vue2023 面试归纳及复习
1. Vue 3中的Composition API(Hooks)是什么?它与Options API有何不同? 答:Composition API是Vue 3中引入的一种新的API风格, 用于组织和重用组件逻辑。它与Options API相比, 提供了更灵活和可…...
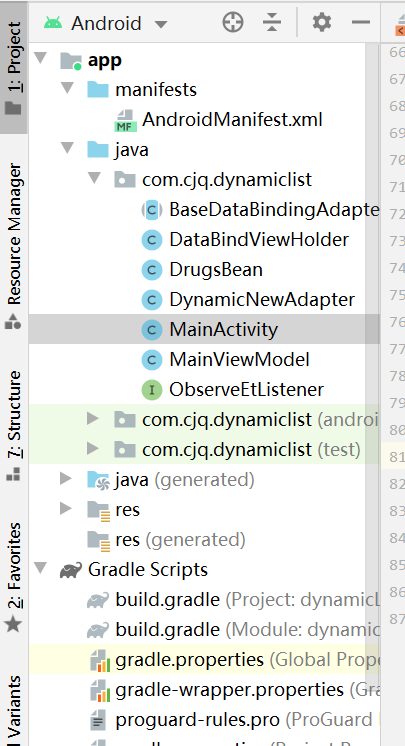
Android动态可编辑长度列表
概述 在界面实现一个列表,用户可以随意给列表新增或者删除项目,在开发中比较常用,但是真正做起来又有点花时间,今天花时间做一个,以便在以后的开发中用到。 详细 运行效果: 二、实现思路: 1…...

合并对象在 Typescript 中的实现与应用
合并对象在 Typescript 中的实现与应用 文章目录 合并对象在 Typescript 中的实现与应用一、简介二、实现1、函数实现2、参数说明3、返回值 三、使用示例四、实际应用场景五、拓展:使用 lodash-es 的 assign 函数进行对象合并1、简介2、安装与导入3、基础用法4、注意…...

antd upload组件beforeUpload返回promise之后,获取的文件不是file类型导致上传失败
之前的beforeUpload直接返回一个false值 ,文件是可以正常与服务端进行传输的 beforeUpload: (file) > {return false},但是这样并不能阻止文件上传,看了官方文档后,改用返回promise对象上传 beforeUpload: (file) > {console.log(-befo…...
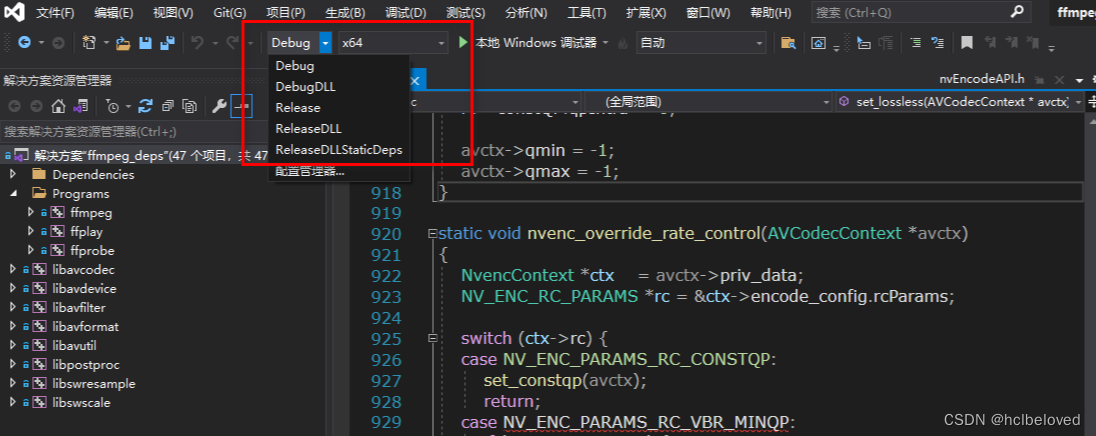
创建ffmpeg vs2019工程
0 写在前面 本文主要参考链接:https://www.cnblogs.com/suiyek/p/15669562.html 感谢作者的付出; 1 目录结构 2 下载yasm和nasm 如果自己在安装VS2019等IDE的时候已经安装了它们,则不用再单独进行安装,比如我这边已经安装了&a…...

无涯教程-机器学习 - Jupyter Notebook函数
Jupyter笔记本基本上为开发基于Python的数据科学应用程序提供了一个交互式计算环境。它们以前称为ipython笔记本。以下是Jupyter笔记本的一些功能,使其成为Python ML生态系统的最佳组件之一- Jupyter笔记本可以逐步排列代码,图像,文本,输出等内容,从而逐步说明分析过程。 它有…...

ubuntu安装单机的Consul
文章目录 场景解决启动方式 场景 公司使用Consul做注册发现中心以及管理配置,之前没有用过consul, 现在记录下ubuntu部署的过程 解决 apt 安装 wget -O- https://apt.releases.hashicorp.com/gpg | sudo gpg --dearmor -o /usr/share/keyrings/hashicorp-archive-…...

聊聊mybatis-plus的sql加载顺序
序 本文主要研究一下如果mybatis mapper定义了多个同名方法会不会有问题 MybatisConfiguration com/baomidou/mybatisplus/core/MybatisConfiguration.java /*** MybatisPlus 加载 SQL 顺序:* <p> 1、加载 XML中的 SQL </p>* <p> 2、加载 SqlP…...
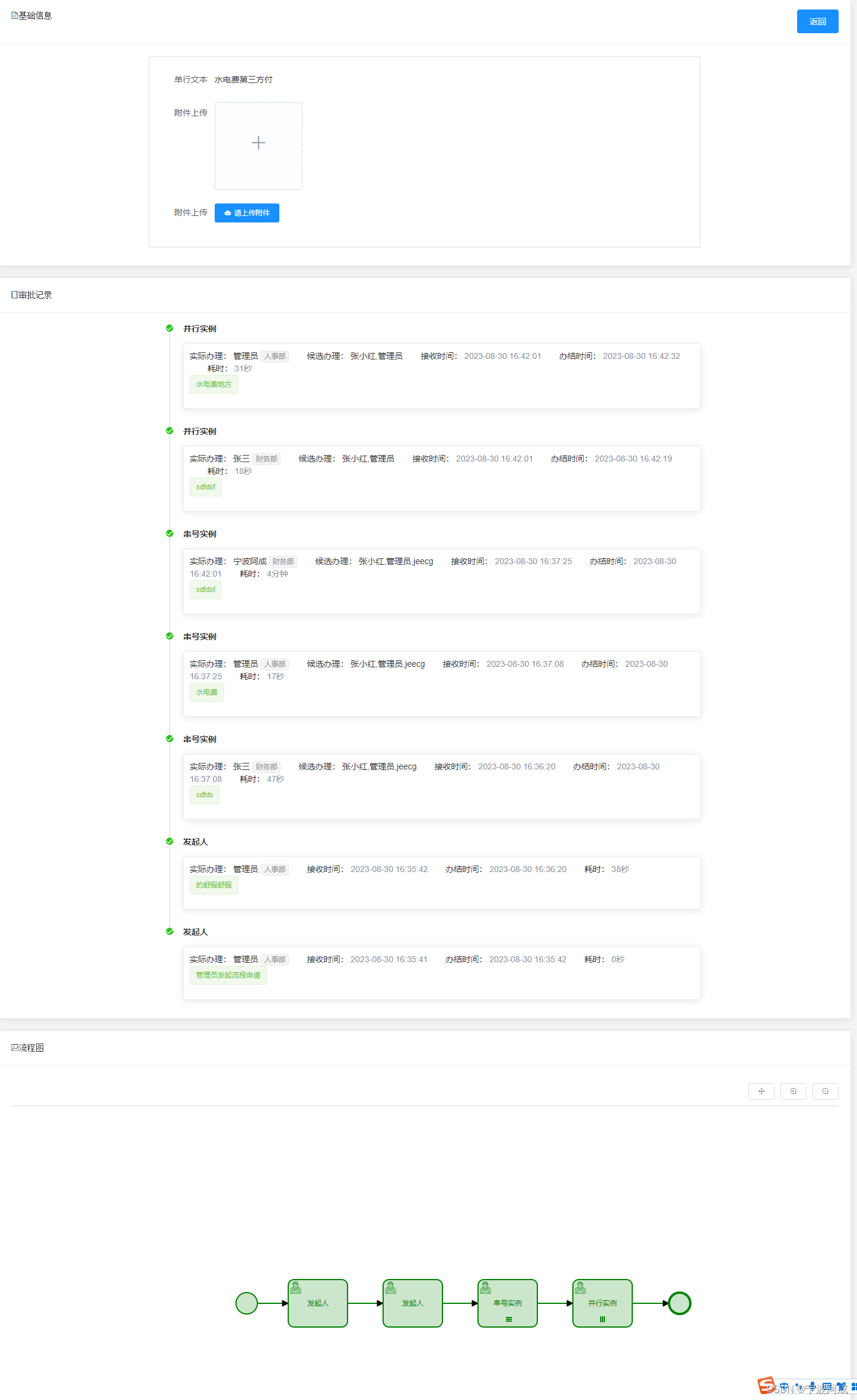
基于jeecg-boot的flowable流程审批时增加下一个审批人设置
更多nbcio-boot功能请看演示系统 gitee源代码地址 后端代码: https://gitee.com/nbacheng/nbcio-boot 前端代码:https://gitee.com/nbacheng/nbcio-vue.git 在线演示(包括H5) : http://122.227.135.243:9888 因为有时…...

HTML 与 CSS 有什么区别?
HTML(超文本标记语言)和 CSS(层叠样式表)是构建网页的两个核心技术。HTML负责定义网页的结构和内容,而CSS则用于控制网页的样式和布局。虽然它们在构建网页时密切相关,但它们在功能和用途上有明显的区别。 …...

服务器数据恢复-vmware ESXI虚拟机数据恢复案例
服务器数据恢复环境: 从物理机迁移一台虚拟机到ESXI,迁移后做了一个快照。该虚拟机上部署了一个SQLServer数据库,存放了5年左右的数据。ESXI上有数十台虚拟机,EXSI连接了一台EVA存储,所有的虚拟机都在EVA存储上。 服务…...
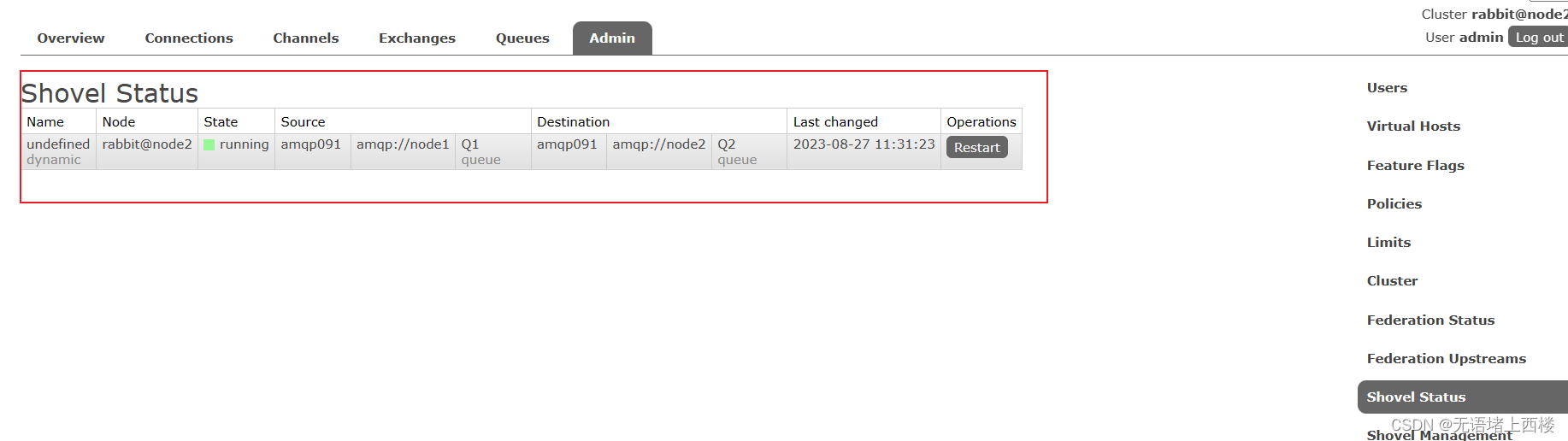
Rabbitmq的Shovel
Federation 具备的数据转发功能类似, Shovel 够可靠、持续地从一个 Broker 中的队列 ( 作为源端,即source)拉取数据并转发至另一个 Broker 中的交换器 ( 作为目的端,即 destination) 。作为源端的队列和作为目的端的交换器可以同时位于…...
华为手机实用功能介绍
一、内置app介绍 分四块介绍,包括出门款、规划款、工作款和生活款。 出门款:红色框框部分,照镜子化妆/看天气 规划款:黄色框框部分,日程表/计划表/番茄时间/计时 工作款:蓝色框框部分,便笺/录…...

算法题打卡day50-动态规划 | 123.买卖股票的最佳时机III、188.买卖股票的最佳时机IV
123. 买卖股票的最佳时机 III - 力扣(LeetCode) 状态:查看索引含义和初始化思路后AC。 增加了两次的限制,相应的就是需要考虑的状态改变,具体的索引含义在代码中: class Solution { public:int maxProfit(…...

jvm与锁
今天是《面霸的自我修养》的第二弹,内容是Java并发编程中关于Java内存模型(Java Memory Model)和锁的基础理论相关的问题。这两块内容的八股文倒是不多,但是难度较大,接下来我们就一起一探究竟吧。 数据来源ÿ…...
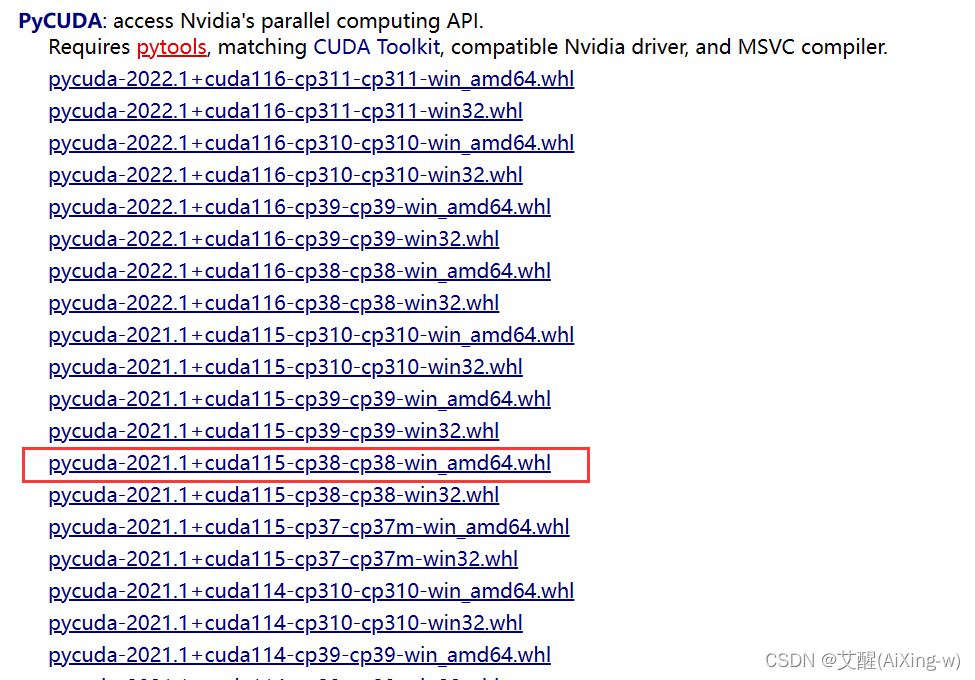
零基础安装pycuda
零基础安装pycuda 前言安装Visual Studio安装C/C环境添加环境变量 安装pycuda查看系统位数查看python版本下载whl文件 前言 最近开始学习基于python的cuda编程,记录一下pycuda的安装。 在安装pycuda之前,首先需要有NVIDIA的独立显卡并且要安装CUDA和CUD…...

Streamlit 讲解专栏(十一):数据可视化-图表绘制详解(中)
文章目录 1 前言2 绘制交互式散点图3 定制图表主题4 增强数据可视化的交互性与注释步骤1步骤二 5 结语 1 前言 在上一篇博文《 Streamlit 讲解专栏(十):数据可视化-图表绘制详解(上)》中,我们学习了一些关…...

d3dx9_35.dll丢失怎么解决
今天,我将为大家介绍关于电脑d3dx9_35.dll丢失的4种详细修复方法。希望通过这次分享,能够帮助大家解决在日常工作和生活中遇到的一些问题。 首先,让我们来了解一下d3dx9_35.dll是什么? d3dx9_35.dll是一个非常重要的动态链接库文…...

树莓派超全系列教程文档--(61)树莓派摄像头高级使用方法
树莓派摄像头高级使用方法 配置通过调谐文件来调整相机行为 使用多个摄像头安装 libcam 和 rpicam-apps依赖关系开发包 文章来源: http://raspberry.dns8844.cn/documentation 原文网址 配置 大多数用例自动工作,无需更改相机配置。但是,一…...

MySQL中【正则表达式】用法
MySQL 中正则表达式通过 REGEXP 或 RLIKE 操作符实现(两者等价),用于在 WHERE 子句中进行复杂的字符串模式匹配。以下是核心用法和示例: 一、基础语法 SELECT column_name FROM table_name WHERE column_name REGEXP pattern; …...

初学 pytest 记录
安装 pip install pytest用例可以是函数也可以是类中的方法 def test_func():print()class TestAdd: # def __init__(self): 在 pytest 中不可以使用__init__方法 # self.cc 12345 pytest.mark.api def test_str(self):res add(1, 2)assert res 12def test_int(self):r…...

Vue ③-生命周期 || 脚手架
生命周期 思考:什么时候可以发送初始化渲染请求?(越早越好) 什么时候可以开始操作dom?(至少dom得渲染出来) Vue生命周期: 一个Vue实例从 创建 到 销毁 的整个过程。 生命周期四个…...

Linux 下 DMA 内存映射浅析
序 系统 I/O 设备驱动程序通常调用其特定子系统的接口为 DMA 分配内存,但最终会调到 DMA 子系统的dma_alloc_coherent()/dma_alloc_attrs() 等接口。 关于 dma_alloc_coherent 接口详细的代码讲解、调用流程,可以参考这篇文章,我觉得写的非常…...
QT开发技术【ffmpeg + QAudioOutput】音乐播放器
一、 介绍 使用ffmpeg 4.2.2 在数字化浪潮席卷全球的当下,音视频内容犹如璀璨繁星,点亮了人们的生活与工作。从短视频平台上令人捧腹的搞笑视频,到在线课堂中知识渊博的专家授课,再到影视平台上扣人心弦的高清大片,音…...

JS红宝书笔记 - 3.3 变量
要定义变量,可以使用var操作符,后跟变量名 ES实现变量初始化,因此可以同时定义变量并设置它的值 使用var操作符定义的变量会成为包含它的函数的局部变量。 在函数内定义变量时省略var操作符,可以创建一个全局变量 如果需要定义…...

2025年低延迟业务DDoS防护全攻略:高可用架构与实战方案
一、延迟敏感行业面临的DDoS攻击新挑战 2025年,金融交易、实时竞技游戏、工业物联网等低延迟业务成为DDoS攻击的首要目标。攻击呈现三大特征: AI驱动的自适应攻击:攻击流量模拟真实用户行为,差异率低至0.5%,传统规则引…...

C++ 类基础:封装、继承、多态与多线程模板实现
前言 C 是一门强大的面向对象编程语言,而类(Class)作为其核心特性之一,是理解和使用 C 的关键。本文将深入探讨 C 类的基本特性,包括封装、继承和多态,同时讨论类中的权限控制,并展示如何使用类…...

HTML中各种标签的作用
一、HTML文件主要标签结构及说明 1. <!DOCTYPE html> 作用:声明文档类型,告知浏览器这是 HTML5 文档。 必须:是。 2. <html lang“zh”>. </html> 作用:包裹整个网页内容,lang"z…...