浙大数据结构之09-排序1 排序
题目详情:
给定N个(长整型范围内的)整数,要求输出从小到大排序后的结果。
本题旨在测试各种不同的排序算法在各种数据情况下的表现。各组测试数据特点如下:
- 数据1:只有1个元素;
- 数据2:11个不相同的整数,测试基本正确性;
- 数据3:103个随机整数;
- 数据4:104个随机整数;
- 数据5:105个随机整数;
- 数据6:105个顺序整数;
- 数据7:105个逆序整数;
- 数据8:105个基本有序的整数;
- 数据9:105个随机正整数,每个数字不超过1000。
输入格式:
输入第一行给出正整数N(≤105),随后一行给出N个(长整型范围内的)整数,其间以空格分隔。
输出格式:
在一行中输出从小到大排序后的结果,数字间以1个空格分隔,行末不得有多余空格。
输入样例:
11 4 981 10 -17 0 -20 29 50 8 43 -5输出样例:
-20 -17 -5 0 4 8 10 29 43 50 981
主要思路:
把所有提到的排序都尝试复现一遍(才发现自己啥也不会)
(一)选择排序:
(1)简单选择排序:
在未排序序列中选出最小元素和序列首位元素交换,剩下来的序列以此类推
#include <stdio.h>
#include <stdlib.h>
#define MAX_NUM 100005
int Data[MAX_NUM];
void Swap(int* data1, int* data2) {int temp = *data1;*data1 = *data2;*data2 = temp;return;
}
void SimpleSelectionSort(int num, int data[]) {int minIndex;for(int i = 0; i < num - 1; i++) {minIndex = i;for(int j = i + 1; j < num; j++) {if(data[j] < data[minIndex]) {minIndex = j;} }Swap(&data[i], &data[minIndex]);}return;
}
int main() {int num;scanf("%d", &num);for(int i = 0; i < num; i++) {scanf("%d", &Data[i]);}SimpleSelectionSort(num, Data);for(int i = 0; i < num; i++) {printf("%d", Data[i]);if(i != num - 1) printf(" ");}return 0;
}(2)堆排序
首先将一个无序的序列生成最大堆,从树的倒数第二排最右边开始,下标是节点总数/2-1,然后依次递减1,不断将以当前下标为根节点的子树调整为最大堆
调整过程为下滤
接着不需要将堆顶元素输出,而是将堆顶元素与当前堆的最后一个元素交换位置,交换完位置后再将大小减1的堆重新调整成最大堆,重复上述过程,原来保存最大堆的数组就转换为一个从小到大的序列
/*堆排序建立堆的时候,
相对于之前建立堆是插入,
这个是在一堆无序的数字上建立
*/
#include <stdio.h>
#include <stdlib.h>
#define MAX_NUM 100005
int Data[MAX_NUM];
void Swap(int* a, int* b) {int tmp = *a;*a = *b;*b = tmp;return;
}
void PercDown(int data[], int root, int num) { //建立最大堆和从最大堆中弹出最大值,核心部分都是下滤//相对与之前的最大堆算法,本题特殊之处在于用于存储最大堆的数组不是从下标1开始,0做哨兵,而就是从0开始int parent, child;int tmp = data[root];//从root开始,遍历数组,比较当前值和左右子节点,若当前值大于左右子节点,则交换当前值和左右子节点的值,并重新调整最大堆for(parent = root; parent * 2 + 1 < num; parent = child) {child = parent * 2 + 1;if((child!= num - 1) && (data[child] < data[child + 1])) {child++;}if(tmp >= data[child]) {break;}else {data[parent] = data[child];}}data[parent] = tmp;return;
}
void HeapSort(int data[], int num) {//建立最大堆for(int i = num / 2 - 1; i >= 0; i--) {PercDown(data, i, num);}//删除最大堆顶for(int i = num - 1; i > 0; i--) {Swap(&data[0], &data[i]);PercDown(data, 0, i);}
}
int main() {int num;scanf("%d", &num);for(int i = 0; i < num; i++) {scanf("%d", &Data[i]);}HeapSort(Data, num);for(int i = 0; i < num; i++) {printf("%d", Data[i]);if(i != num - 1) {printf(" ");}}return 0;
}(二)插入排序
(1)简单插入排序
将序列分为已排和未排,每次从未排中取一个与已排比较直到合适位置后插入,重复上述过程,直到没有未排序列
#include <stdio.h>
#include <stdlib.h>
#define MAX_NUM 100005
int Data[MAX_NUM];
void SimpleInsertSort(int data[], int num) {for(int i = 1; i < num; i++) {int tmp = data[i]; //取出未排序列中第一个元素int j = i;for(; j > 0 && data[j - 1] > tmp; j--) { //依次与已排序列从末尾往前比data[j] = data[j - 1]; }data[j] = tmp; //将未排序列第一个元素插入到已排序列合适位置}return;
}
int main() {int num;scanf("%d", &num);for(int i = 0; i < num; i++) {scanf("%d", &Data[i]);}SimpleInsertSort(Data, num);for(int i = 0; i < num; i++) {printf("%d", Data[i]);if(i != num - 1) {printf(" ");}}return 0;
}(2)希尔排序
通过将待排序的一组元素按一定间隔分为若干个序列,分别进行插入排序;最终间隔是1
往往用Sedgewick作为增量序列
void ShellSort(int data[], int num) {//定义一个增量数组int i;int sedgewick[] = {929, 505, 209, 109, 41, 19, 5, 1, 0};//在sedgewick序列中找到比num小的增量,因为初始的增量sedgewick[i]不能超过待排序列长度for(i = 0; sedgewick[i] >= num; i++) //在sedgewick序列中找到比num小的增量,因为初始的增量sedgewick[i]不能超过待排序列长度;for(int interval = sedgewick[i]; interval > 0; interval = sedgewick[++i]) {//插入排序//比较难以理解,首先从一个intervel以后开始选择,因为下标0~intervel-1是分别intervel的第一个(第一个又是已排序列)for(int j = interval; j < num; j++) { int tmp = data[j]; //取出未排序列中第一个元素int k = j;//依次将其已排序元素进行比较for(; k >= interval && data[k - interval] > tmp; k -= interval) { //依次与已排序列从末尾往前比data[k] = data[k - interval];}data[k] = tmp; //将未排序列的第一个元素插入到已排序列中合适位置}}
}
(三)交换排序
(1)冒泡排序
外层循环从待排序列最后一位往前依次确定,内层循环从前往后扫描两两比较取最大
减少循环的一个方法是每层循环设置一个flag,如果从头至尾扫描循环都没有交换,说明当前序列已经有序,可以break了
#include <stdio.h>
#define MAX_NUM 100005
#define bool int
#define TRUE 1
#define FALSE 0
int Data[MAX_NUM];
void Swap(int* a, int* b) {int tmp = *a;*a = *b;*b = tmp;return;
}
void BubbleSort(int data[], int num) {for(int i = num - 1; i >= 0; i--) { //依次从下标num - 1开始往前定位bool flag = FALSE; //标记该次循环中是否发生交换,若无,说明该序列已经有序for(int j = 0; j < i; j++) {if(data[j] > data[j + 1]) {Swap(&data[j], &data[j + 1]);flag = TRUE;}}if(flag == FALSE) {break;}}return;
}
int main() {int num;scanf("%d", &num);for(int i = 0; i < num; i++) {scanf("%d", &Data[i]);}BubbleSort(Data, num);for(int i = 0; i < num; i++) {printf("%d", Data[i]);if(i != num - 1) {printf(" ");}}return 0;
}(2)快速排序
快速排序的思路是通过分治法,首先取一个pivot基准值,将大于pivot的都移到右边,小于它的都移到左边,将一个序列分成两个序列,然后将这两个序列分别重复上述操作
具体实现:
首先为了减少时间复杂度,要考究选择的pivot,方法是将最左边,最右边和中间(left + right)/2按最左边<=中间<=最右边,因为这样排序后最左边必定比中间小,最右边必定比中间大,将中间的值移动到最右边倒数第二个后,比较范围只用从最左边下标+1到最右边下标-2
另一个优化是因为递归针对较大数据还好,但对于较小数据就很慢,所以临设一个cutoff变量,当前序列大小比这个大就用快排,如果小就直接用简单插入排序
但发现这个cutoff最小必须设为2,再小就报错了,目前还没想出来是为什么
#include <stdio.h>
#define TRUE 1
#define FALSE 0
#define MAX_NUM 100005
typedef int bool;
int Data[MAX_NUM];
int Cutoff = 3;
void Swap(int* a, int* b) {int tmp = *a;*a = *b;*b = tmp;return;
}
/*实现简单插入排序*/
void SimpleInsertSort(int data[], int left, int right) {for(int i = left + 1; i <= right; i++) {int tmp = data[i];int j = i;for(; j > left && data[j - 1] > tmp; j--) {data[j] = data[j - 1];}data[j] = tmp;}return;
}
/*下面函数作用是确定快排中主元,将最左边、最右边、中间元素调整为
最左边 <= 中间 <= 最右边,此时最左边一定小于中间,最右边一定大于等于中间,这两个所以就不用考虑了
将中间的主元放到右边倒数第二个位置,下面就只用比较左边第二个到右边倒数第三个位置的范围就行*/
int CompareThreeNums(int data[], int left, int right) {int mid = (left + right) / 2;int max = data[left];if(data[left] > data[mid]) {Swap(&data[left], &data[mid]);}if(data[left] > data[right]) {Swap(&data[left], &data[right]);}if(data[mid] > data[right]) {Swap(&data[mid], &data[right]);}Swap(&data[mid], &data[right - 1]);return data[right - 1];
}
void QuickSortCore(int data[], int left, int right) {if(Cutoff <= right - left) {int pivot = CompareThreeNums(data, left, right);int low = left;int high = right - 1;while(TRUE) {while(data[++low] < pivot) ;while(data[--high] > pivot) ;if(low < high) {Swap(&data[low], &data[high]);}else {break;}}Swap(&data[low], &data[right - 1]); //将基准换到正确位置QuickSortCore(data, left, low - 1); //对基准左边序列递归QuickSortCore(data, low + 1, right); //对基准右边序列递归}else {SimpleInsertSort(data, left, right); //对序列进行简单插入排序}return;
}
void QuickSort(int data[], int num) {QuickSortCore(data, 0, num - 1);return;
}
int main() {int num;scanf("%d", &num);for(int i = 0; i < num; i++) {scanf("%d", &Data[i]);}QuickSort(Data, num);for(int i = 0; i < num; i++) {printf("%d", Data[i]);if(i != num - 1) {printf(" ");}}return 0;
}(四)归并排序
归并排序的思路类似于快排,不过归并是通过将待排序列不断分割到每个序列只剩两个数字时排序,然后再两两合并实现排序
①递归版本
#include <stdio.h>
#include <stdlib.h>
#define MAX_NUM 100005
int DataToSort[MAX_NUM];
void Merge(int data[], int tmpData[], int leftStart, int rightEnd, int rightStart) {int leftEnd = rightStart - 1;int tmpStart = leftStart;int num = rightEnd - leftStart + 1;while(leftStart <= leftEnd && rightStart <= rightEnd) {if(data[leftStart] <= data[rightStart]) {tmpData[tmpStart++] = data[leftStart++];}else {tmpData[tmpStart++] = data[rightStart++];}} while(leftStart <= leftEnd) {tmpData[tmpStart++] = data[leftStart++];}while(rightStart <= rightEnd) {tmpData[tmpStart++] = data[rightStart++];}for(int i = 0; i < num; i++, rightEnd--) {data[rightEnd] = tmpData[rightEnd];}return;
}
void MergeSortRecursiveVersionCore(int data[], int tmpData[],int leftStart, int rightEnd) {if(leftStart >= rightEnd) {return;}int mid = (leftStart + rightEnd) / 2;MergeSortRecursiveVersionCore(data, tmpData, leftStart, mid);MergeSortRecursiveVersionCore(data, tmpData, mid + 1, rightEnd);Merge(data, tmpData, leftStart, rightEnd, mid + 1);return;
}
void MergeSort(int data[], int num) {int* tmpData = (int*)malloc(sizeof(int) * num);MergeSortRecursiveVersionCore(data, tmpData, 0, num - 1);free(tmpData);return;
}
int main() {int num;scanf("%d", &num);for(int i = 0; i < num; i++) {scanf("%d", &DataToSort[i]);}MergeSort(DataToSort, num);for(int i = 0; i < num; i++) {printf("%d", DataToSort[i]);if(i != num - 1) {printf(" ");}}return 0;
}②循环版本
#include <stdio.h>
#include <stdlib.h>
#define MAX_NUM 100005
int DataToSort[MAX_NUM];
void Merge(int data[], int tmpData[], int leftStart, int rightStart, int rightEnd) {int leftEnd = rightStart - 1;int tmpStart = leftStart;int numElements = rightEnd - leftStart + 1;while(leftStart <= leftEnd && rightStart <= rightEnd) {if(data[leftStart] <= data[rightStart]) {tmpData[tmpStart++] = data[leftStart++];}else {tmpData[tmpStart++] = data[rightStart++];}}while(leftStart <= leftEnd) {tmpData[tmpStart++] = data[leftStart++];}while(rightStart <= rightEnd) {tmpData[tmpStart++] = data[rightStart++];}for(int i = 0; i < numElements; i++, rightEnd--) {data[rightEnd] = tmpData[rightEnd];}return;
}
/*length表示当前有序序列*/
void MergeCirculationSortCore(int data[], int tmpData[], int length, int totalNum) {/*i表示当前序列中左开头*//*下面代码中传i, i + length, i + 2 * length - 1等都是坐标*/int i;for(i = 0; i <= totalNum - 2 * length; i += 2 * length) { Merge(data, tmpData, i, i + length, i + 2 * length - 1);}/*如果剩余的序列已经小于等于两个length但依然比一个length长*/if(i + length < totalNum) {Merge(data, tmpData, i, i + length, totalNum - 1);}/*如果剩余的序列已经不足一个length*/else {for(int j = i; j < totalNum; j++) {tmpData[j] = data[j];}}return;
}
void MergeCirculationSort(int data[], int num) {int length = 1;while(length < num) {int* tmpData = (int*)malloc(sizeof(int) * num);/*第一次先对按length长度的序列排序*/MergeCirculationSortCore(DataToSort, tmpData, length, num);length *= 2;/*第二次对之前length长度的2倍的序列归*/MergeCirculationSortCore(tmpData, data, length, num);length *= 2; free(tmpData); }return;
}
int main() {int num;scanf("%d", &num);for(int i = 0; i < num; i++) {scanf("%d", &DataToSort[i]);}MergeCirculationSort(DataToSort, num);for(int i = 0; i < num; i++) {printf("%d", DataToSort[i]);if(i != num - 1) {printf(" ");}} return 0;
}相关文章:

浙大数据结构之09-排序1 排序
题目详情: 给定N个(长整型范围内的)整数,要求输出从小到大排序后的结果。 本题旨在测试各种不同的排序算法在各种数据情况下的表现。各组测试数据特点如下: 数据1:只有1个元素;数据2…...

Pydantic 学习随笔
这里是零散的记录一些学习过程中随机的理解,因此这里的记录不成体系。如果是想学习 Pydantic 建议看官方文档,写的很详细并且成体系。如果有问题需要交流,欢迎私信或者评论。 siwa 报 500 Pydantic 可以和 siwa 结合使用,这样既…...
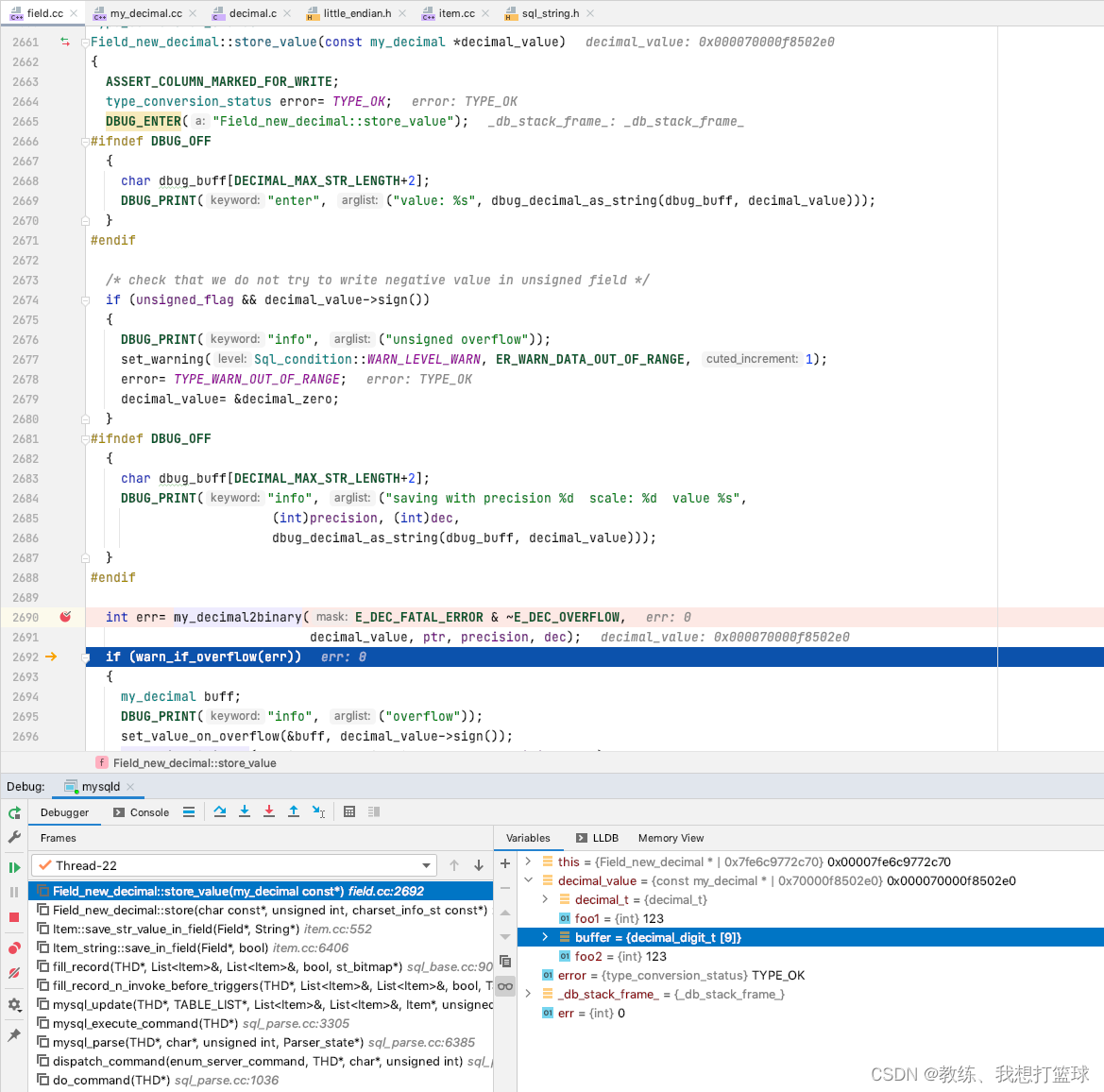
11 mysql float/double/decimal 的数据存储
前言 这里主要是 由于之前的一个 datetime 存储的时间 导致的问题的衍生出来的探究 探究的主要内容为 int 类类型的存储, 浮点类类型的存储, char 类类型的存储, blob 类类型的存储, enum/json/set/bit 类类型的存储 本文主要 的相关内容是 float, decimal 类类型的相关数据…...

【高效数据结构——位图bitmap】
初识位图bitmap 位图(Bitmap)是一种用于表示和操作位(bit)的数据结构。它是由一系列二进制位(0 或 1)组成的序列,每个位都可以单独访问和操作。 位图常用于以下情况: 压缩存储&…...

ArrayList LinkedList
ArrayList 和 LinkedList 区别 ArrayList和LinkedList都是Java集合框架中的实现类,用于存储和操作数据。它们在底层实现和性能特点上有一些区别。 数据结构:ArrayList底层使用数组实现,而LinkedList底层使用双向链表实现。这导致它们在内存结…...
iOS砸壳系列之三:Frida介绍和使用
当涉及从App Store下载应用程序时,它们都是已安装的iOS应用(IPA)存储在设备上。这些应用程序通常带有保护的代码和资源,以限制用户对其进行修改或者逆向工程。 然而,有时候,为了进行调试、制作插件或者学习…...
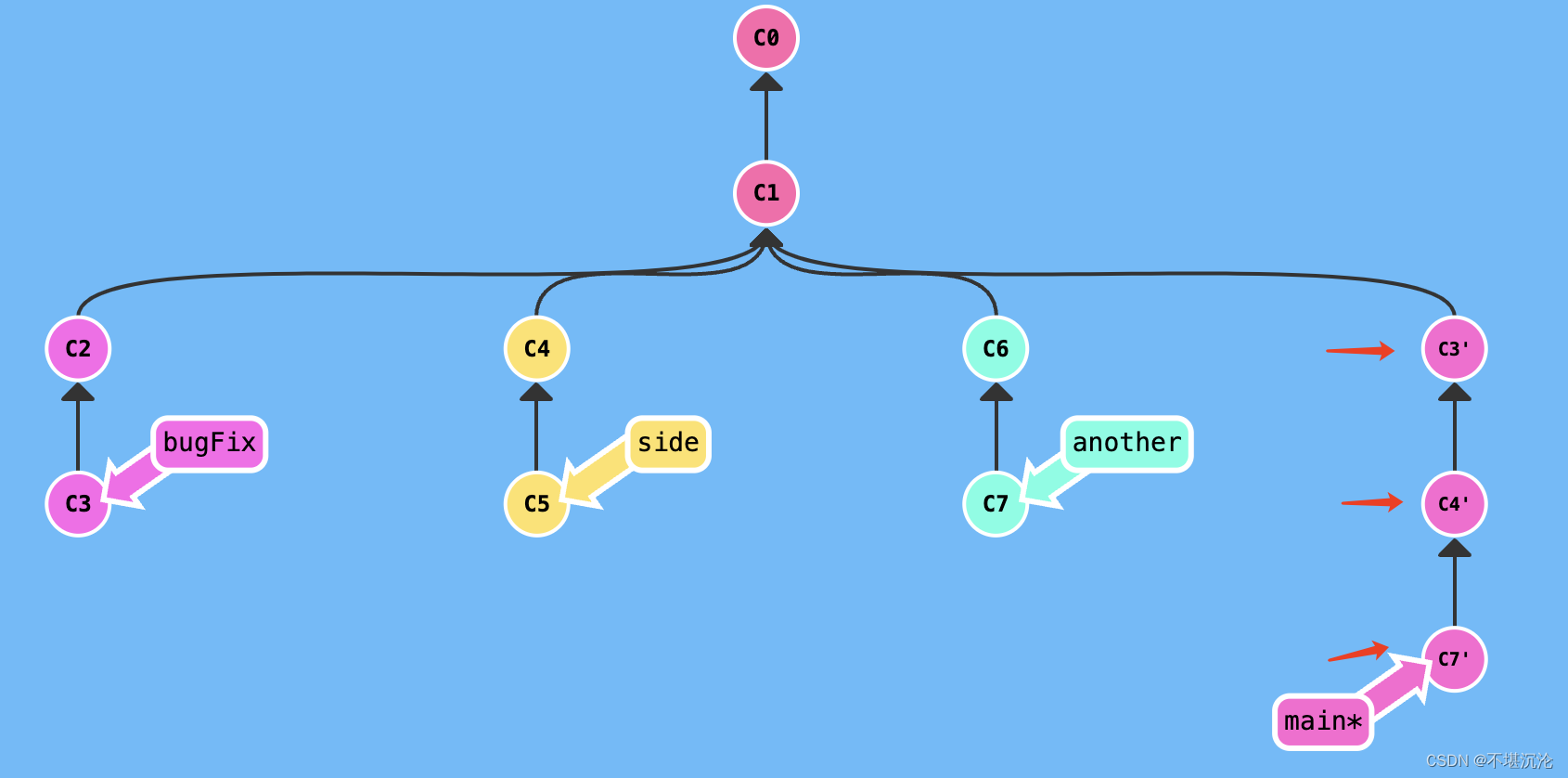
Git学习——细节补充
Git学习——细节补充 1. git diff2. git log3. git reset4. git reflog5. 提交撤销5.1 当你改乱了工作区某个文件的内容,想直接丢弃工作区的修改时5.2 当提交到了stage区后,想要退回 6. git remote7. git pull origin master --no-rebase8. 分支管理9. g…...

【设计模式】Head First 设计模式——装饰者模式 C++实现
设计模式最大的作用就是在变化和稳定中间寻找隔离点,然后分离它们,从而管理变化。将变化像小兔子一样关到笼子里,让它在笼子里随便跳,而不至于跳出来把你整个房间给污染掉。 设计思想 动态地将责任附加到对象上,若要扩…...
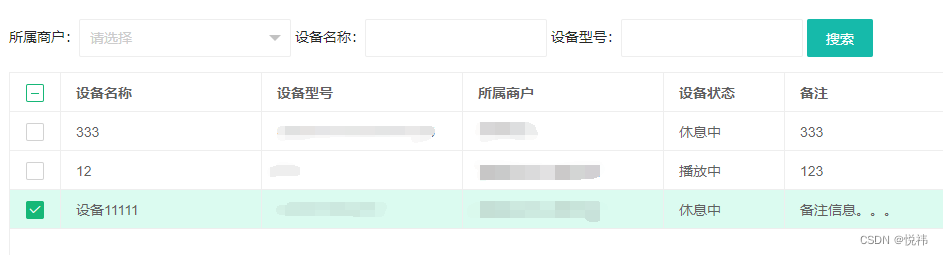
layui实现数据列表的复选框回显
layui版本2.8以上 实现效果如图: <input type"hidden" name"id" id"id" value"{:g_val( id,0)}"> <div id"tableDiv"><table class"layui-hide" id"table_list" lay-filter…...
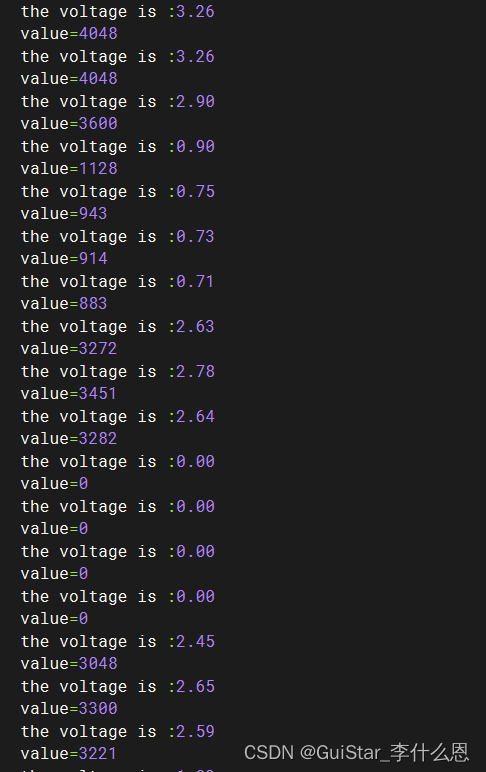
关于使用RT-Thread系统读取stm32的adc无法连续转换的问题解决
关于使用RT-Thread系统读取stm32的adc无法连续转换的问题解决 今天发现rt系统的adc有一个缺陷(也可能是我移植的方法有问题,这就不得而知了!),就是只能单次转换,事情是这样的: 我在stm32的RT-T…...
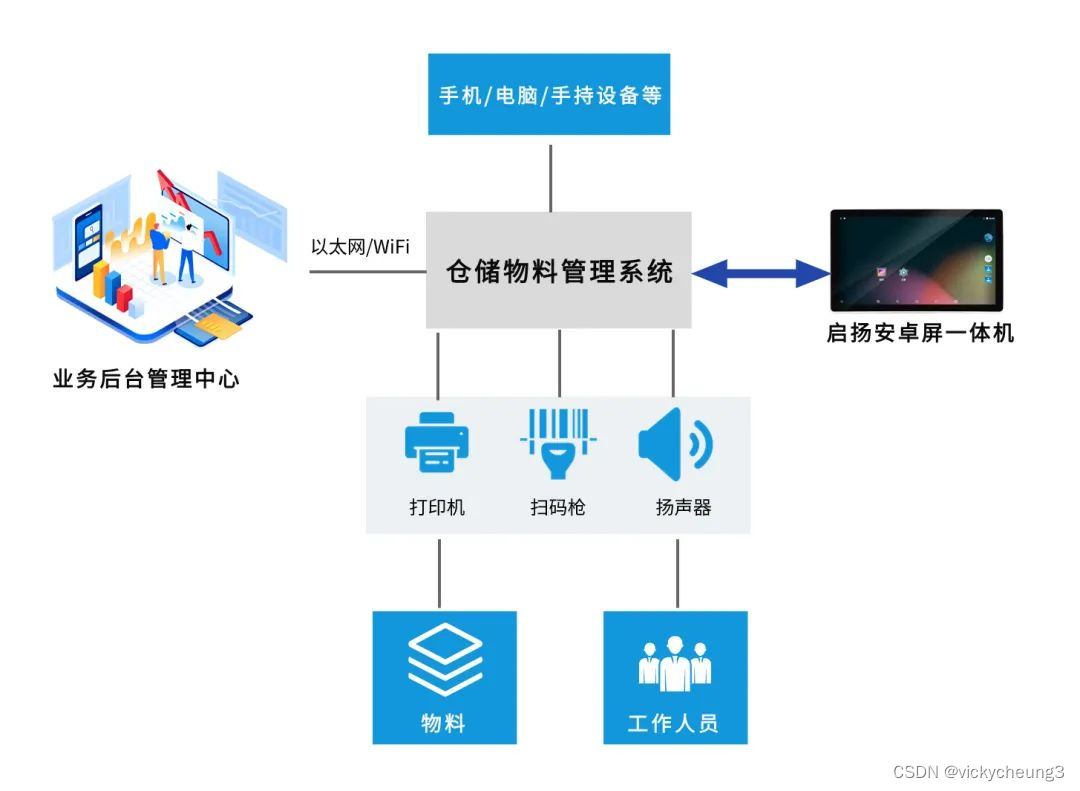
【启扬方案】启扬多尺寸安卓屏一体机,助力仓储物料管理系统智能化管理
随着企业供应链管理的不断发展,对仓储物料管理的要求日益提高。企业需要实时追踪和管理物料的流动,提高物流效率、降低库存成本和减少库存的风险。因此,仓储物料管理系统的实现成为必要的手段。 仓储物料管理系统一体机作为一种新型的物料管理…...

Android Glide使用姿势与原理分析
作者: 午后一小憩 简介 Android Glide是一款强大的图片加载库,提供了丰富的功能和灵活的使用方式。本文将深入分析Glide的工作原理,并介绍一些使用姿势,助你更好地运用这个优秀的库。 原理分析 Glide的原理复杂而高效。它首先基…...

管理类联考——逻辑——汇总篇——知识点突破——形式逻辑——联言选言——真假
角度——真值表 以上考点均是已知命题的真假情况做出的推理,还存在一种情况是已知肢判断P、Q的真假,断定干判断的真假,这种判断过程就是运用真值表。 P ∧ Q的真值 ①如何证明P ∧ Q为假? 由于P ∧ Q的本质是P、Q同时成立,所以只要P、Q有一个为假,整个命题就为假。 ②如…...
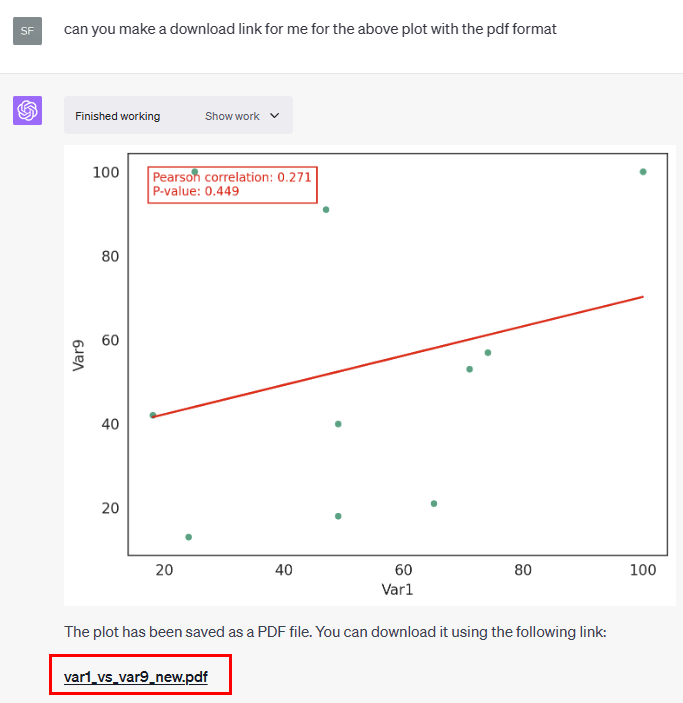
ChatGPT数据分析及作图插件推荐-Code Interpreter
今天打开chatGPT时发现一个重磅更新!code interpreter插件可以使用了。 去查看openai官网,发现从2023.7.6号(前天)开始,code interpreter插件已经面向所有chatGPT plus用户开放了。 为什么说code interpreter插件是一…...

说说FLINK细粒度滑动窗口如何处理
分析&回答 Flink的窗口机制是其底层核心之一,也是高效流处理的关键。Flink窗口分配的基类是WindowAssigner抽象类,下面的类图示出了Flink能够提供的所有窗口类型。 Flink窗口分为滚动(tumbling)、滑动(sliding&am…...
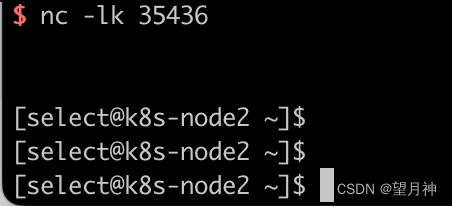
记一次反弹shell的操作【非常简单】
#什么是反弹shell 通常我们对一个开启了80端口的服务器进行访问时,就会建立起与服务器Web服务链接,从而获取到服务器相应的Web服务。而反弹shell是我们开启一个端口进行监听,转而让服务器主动反弹一个shell来连接我们的主机,我们再…...

如何排查 Flink Checkpoint 失败问题?
分析&回答 这是 Flink 相关工作中最常出现的问题,值得大家搞明白。 1. 先找到超时的subtask序号 图有点问题,因为都是成功没失败的,尴尬了。 借图: 2. 找到对应的机器和任务 方法很多,这里看自己习惯和公司提供…...
和c语言读日志文件筛选保存为新文件)
lazarus(pascal)和c语言读日志文件筛选保存为新文件
lazarus(pascal)和c语言读日志文件筛选保存为新文件,源于看日志每次从一个很多内容文件里查找不方便,写个代码输入时分秒参数,然后按行读取比较日志时间,当前秒和上一秒的输出保存为新文件,只保存2秒钟文件小多了&…...

学习JAVA打卡第四十九天
Random类 尽管可以使用math类调用static方法random()返回一个0~1之间的随机数。(包括0.0但不包括0.1),即随机数的取值范围是[0.0,1.0]的左闭右开区间。 例如,下列代码得到1~100之间…...
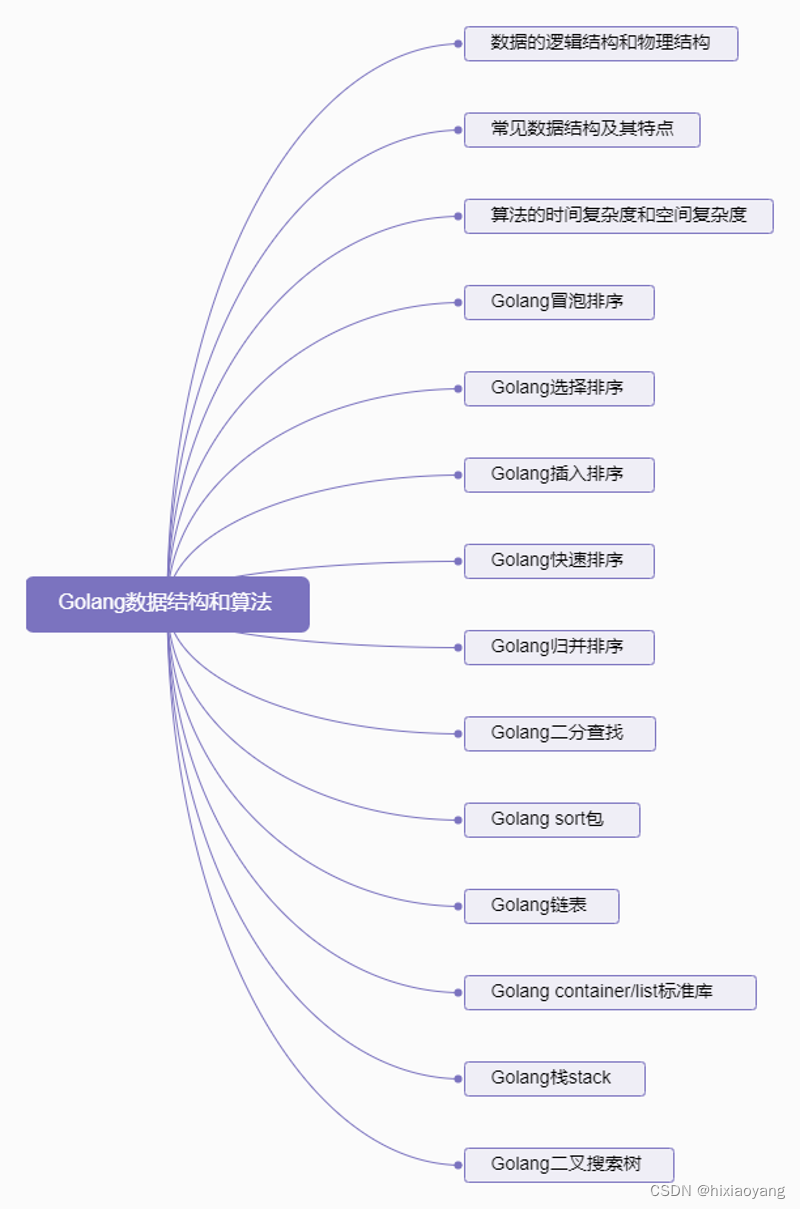
Golang数据结构和算法
Golang数据结构和算法 数据的逻辑结构和物理结构常见数据结构及其特点算法的时间复杂度和空间复杂度Golang冒泡排序Golang选择排序Golang插入排序Golang快速排序Golang归并排序Golang二分查找Golang sort包Golang链表Golang container/list标准库Golang栈stackGolang二叉搜索树…...

华为云AI开发平台ModelArts
华为云ModelArts:重塑AI开发流程的“智能引擎”与“创新加速器”! 在人工智能浪潮席卷全球的2025年,企业拥抱AI的意愿空前高涨,但技术门槛高、流程复杂、资源投入巨大的现实,却让许多创新构想止步于实验室。数据科学家…...

相机Camera日志实例分析之二:相机Camx【专业模式开启直方图拍照】单帧流程日志详解
【关注我,后续持续新增专题博文,谢谢!!!】 上一篇我们讲了: 这一篇我们开始讲: 目录 一、场景操作步骤 二、日志基础关键字分级如下 三、场景日志如下: 一、场景操作步骤 操作步…...

在rocky linux 9.5上在线安装 docker
前面是指南,后面是日志 sudo dnf config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo sudo dnf install docker-ce docker-ce-cli containerd.io -y docker version sudo systemctl start docker sudo systemctl status docker …...

微服务商城-商品微服务
数据表 CREATE TABLE product (id bigint(20) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT 商品id,cateid smallint(6) UNSIGNED NOT NULL DEFAULT 0 COMMENT 类别Id,name varchar(100) NOT NULL DEFAULT COMMENT 商品名称,subtitle varchar(200) NOT NULL DEFAULT COMMENT 商…...

【笔记】WSL 中 Rust 安装与测试完整记录
#工作记录 WSL 中 Rust 安装与测试完整记录 1. 运行环境 系统:Ubuntu 24.04 LTS (WSL2)架构:x86_64 (GNU/Linux)Rust 版本:rustc 1.87.0 (2025-05-09)Cargo 版本:cargo 1.87.0 (2025-05-06) 2. 安装 Rust 2.1 使用 Rust 官方安…...

4. TypeScript 类型推断与类型组合
一、类型推断 (一) 什么是类型推断 TypeScript 的类型推断会根据变量、函数返回值、对象和数组的赋值和使用方式,自动确定它们的类型。 这一特性减少了显式类型注解的需要,在保持类型安全的同时简化了代码。通过分析上下文和初始值,TypeSc…...

深入理解Optional:处理空指针异常
1. 使用Optional处理可能为空的集合 在Java开发中,集合判空是一个常见但容易出错的场景。传统方式虽然可行,但存在一些潜在问题: // 传统判空方式 if (!CollectionUtils.isEmpty(userInfoList)) {for (UserInfo userInfo : userInfoList) {…...
)
Spring Boot 与 Kafka 的深度集成实践(二)
3. 生产者实现 3.1 生产者配置 在 Spring Boot 项目中,配置 Kafka 生产者主要是配置生产者工厂(ProducerFactory)和 KafkaTemplate 。生产者工厂负责创建 Kafka 生产者实例,而 KafkaTemplate 则是用于发送消息的核心组件&#x…...

触发DMA传输错误中断问题排查
在STM32项目中,集成BLE模块后触发DMA传输错误中断(DMA2_Stream1_IRQHandler进入错误流程),但单独运行BLE模块时正常,表明问题可能源于原有线程与BLE模块的交互冲突。以下是逐步排查与解决方案: 一、问题根源…...
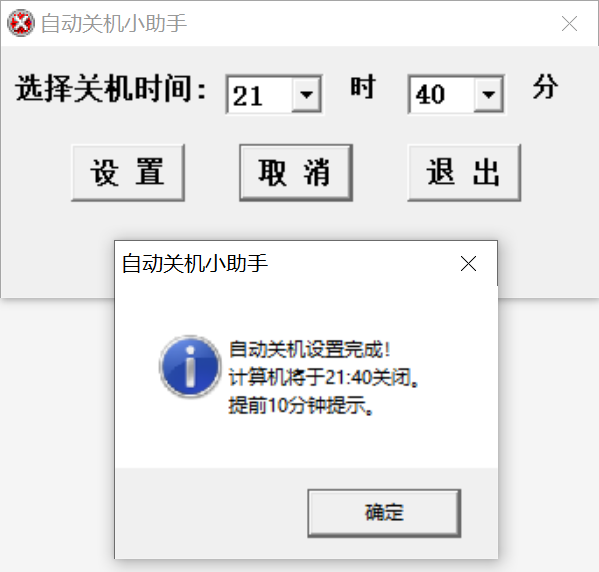
电脑定时关机工具推荐
软件介绍 本文介绍一款轻量级的电脑自动关机工具,无需安装,使用简单,可满足定时关机需求。 工具简介 这款关机助手是一款无需安装的小型软件,文件体积仅60KB,下载后可直接运行,无需复杂配置。 使用…...