8月28日上课内容 第四章 MySQL备份与恢复
本章结构

前言:日志⭐⭐
MySQL 的日志默认保存位置为 /usr/local/mysql/data
##配置文件
vim /etc/my.cnf
[mysqld]
##错误日志,用来记录当MySQL启动、停止或运行时发生的错误信息,默认已开启
log-error=/usr/local/mysql/data/mysql_error.log #指定日志的保存位置和文件名
##通用查询日志,用来记录MySQL的所有连接和语句,默认是关闭的
general_log=ON
general_log_file=/usr/local/mysql/data/mysql_general.log
##二进制日志(binlog),用来记录所有更新了数据或者已经潜在更新了数据的语句,记录了数据的更改,可用于数据恢复,默认已开启
log-bin=mysql-bin
或
log_bin=mysql-bin
##中继日志
一般情况下它在Mysql主从同步(复制)、读写分离集群的从节点开启。主节点一般不需要这个日志
##慢查询日志,用来记录所有执行时间超过long_query_time秒的语句,可以找到哪些查询语句执行时间长,以便提醒优化,默认是关闭的
s1ow_query_log=ON
slow_query_log_file=/usr/local/mysql/data/mysql_slow_query.log
long_query_time=5 #设置超过5秒执行的语句被记录,缺省时为10秒
##复制段
log-error=/usr/local/mysql/data/mysql_error.log
general_log=ON
general_log_file=/usr/local/mysql/data/mysql_general.log
log-bin=mysql-bin
slow_query_log=ON
slow_query_log_file=/usr/local/mysql/data/mysql_slow_query.log
long_query_time=5
systemctl restart mysqld
mysql -u root -P
show variables like 'general%'; #查看通用查询日志是否开启
show variables like 'log_bin%'; #查看二进制日志是否开启
show variables like '%slow%'; #查看慢查询日功能是否开启
show variables like 'long_query_time'; #查看慢查询时间设置
set global slow_query_log=ON; #在数据库中设置开启慢查询的方法
PS:variables 表示变量 like 表示模糊查询
#xxx(字段)
xxx% 以xxx为开头的字段
%xxx 以xxx为结尾的字段
%xxx% 只要出现xxx字段的都会显示出来
xxx 精准查询
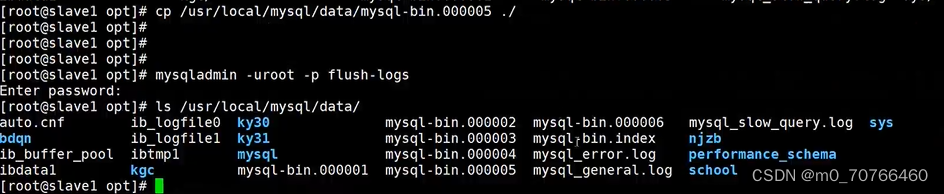
#二进制日志开启后,重启mysql 会在目录中查看到二进制日志
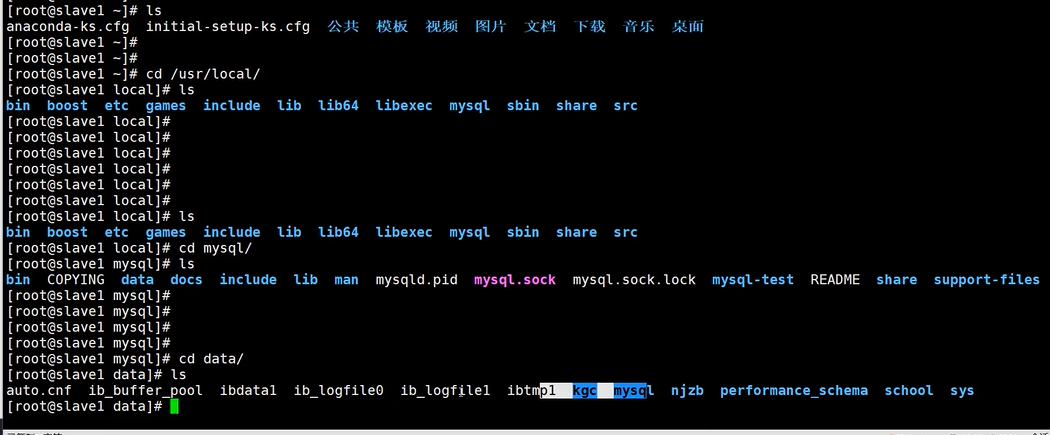
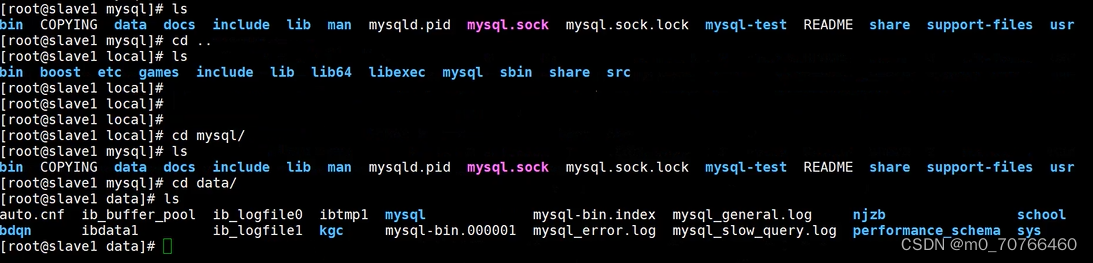
cd /usr/local/mysql/data
ls
mysql-bin.000001 #开启二进制日志时会产生一个索引文件及一个索引列表
索引文件:记录更新语句
索引文件刷新方式:
1、重启mysql的时候会更新索引文件,用于记录新的更新语句
2、刷新二进制日志
mysql-bin.index:
二进制日志文件的索引
数据备份的重要性

在生产环境中,数据的安全性至关重要
任何数据的丢失都可能产生严重的后果
造成数据丢失的原因
程序错误
人为操作错误
运算错误
磁盘故障
灾难 (如火灾、地震)和盗窃
备份的目的:防止故障和灾难造成的数据丢失
数据库备份的分类

从物理与逻辑的角度,备份可分为
物理备份:对数据库操作系统的物理文件(如数据文件日志文件等)的备份
物理备份方法
冷备份 (脱机备份)是在关闭数据库的时候进行的
热备份 (联机备份) :数据库处于运行状态,依赖于数据库的日志文件
温备份:数据库锁定表格(不可写入但可读)的状态下进行备份操作
逻辑备份:对数据库逻辑组件(如:表等数据库对象)的备份,这种类型的备份适用于可以编辑数据值或表结构

从数据库的备份策略角度,备份可分为
完全备份:每次对数据库进行完整的备份
差异备份:备份自从上次完全备份之后被修改过的文件
增量备份:只有在上次完全备份或者增量备份后被修改的文件才会被备份
图解:

详解:
① 完全备份
每次对数据进行完整备份,即对整个数据库、数据库结构和文件结构的备份,保存的是备份完成时刻的数据库,是差异备份与增量备份的基础完全备份的备份与恢复操作都非常简单方便,但是数据存在大量的重复并且会占用大量的磁盘空间,备份的时间也很长
每次都进行完全备份,会导致备份文件占用空间巨大,并且有大量的重复数据,恢复时,直接使用完全备份的文件即可
② 差异备份
备份那些自从上次完全备份之后被修改过的所有文件,备份的时间节点是从上次完整备份起,备份数据量会越来越大。恢复数据时只需要恢复上次的完全备份与最佳的一次差异备份
每次差异备份,都会备份上一次完全备份之后的数据,可能会出现重复数据。恢复时,先恢复完全备份的数据,再恢复差异备份的数据
③ 增量备份
只有那些在上次完全备份或者增量备份后被修改的文件才会被备份以上次完整备份或上次增量备份的时间为时间点,仅备份期间内的数据变化,因而备份的数据量小,占用空间小,备份速度快。但恢复时,需要从上一次的完整备份开始到最后一次增量备份之间的所有增量依次恢复,如中间某次的备份数据损坏,将导致数据的丢失
每次增量备份都是在备份在上一次完成全备份
每次增量备份都是备份在上一次完全备份或者增量备份之后的数据,不会出现重复数据的情况,也不会占用额外的磁盘空间
恢复数据,需要按照次序恢复完全备份和增量备份的数据
备份方式比较(掌握)
备份方式 完全备份 差异备份 增量备份
完全备份时的状态 表1、表2 表1、表2 表1、表2
第1次添加内容 创建表3 创建表3 创建表3
备份内容 表1、表2、表3 表3 表3
第2次添加内容 创建表4 创建表4 创建表4
备份内容 表1、表2、表3、表4 表3、表4 表4
逻辑备份的策略(增、全、差异)
如何选择逻辑备份策略(频率)
合理值区间⭐⭐⭐
一周一次的全备,全备的时间需要在不提供业务的时间区间进行 PM 10点 AM 5:00之间进行全备
增量:3天/2天/1天一次增量备份
差异:选择特定的场景进行备份
一个处理(NFS)提供额外空间给与mysql 服务器用
常见的备份方法

物理冷备
备份时数据库处于关闭状态,直接打包数据库文件
备份速度快,恢复时也是最简单的
专用备份工具mydump或mysqlhotcopy
mysqldump常用的逻辑备份工具。
mysglhotcopy仅拥有备份MyISAM和ARCHIVE表
启用二进制日志进行增量备份
进行增量备份,需要刷新二进制日志
MySQL支持增量备份,进行增量备份时必须启用二进制日志。二进制日志文件为用户提供复制,对执行备份点后进行的数据库更改所需的信息进行恢复。如果进行增量备份(包含自上次完全备份或增量备份以来发生的数据修改),需要刷新二进制日志。
第三方工具备份
免费的MySQL热备份软件Percona XtraBackup
MySQL完全备份

是对整个数据库、数据库结构和文件结构的备份
保存的是备份完成时刻的数据库
是差异备份与增量备份的基础
完全备份的优缺点

优点
备份与恢复操作简单方便
缺点
数据存在大量的重复
占用大量的备份空间
备份与恢复时间长
数据库完全备份分类

物理冷备份与恢复
关闭MySQL数据库
使用tar命令直接打包数据库文件夹
直接替换现有MySQL目录即可
mysqldump备份与恢复
MySQL自带的备份工具,可方便实现对MySQL的备份。
可以将指定的库、表导出为SQL脚本
使用命令mysql导入备份的数据

实验部分
环境准备:
use kgc;
create table if not exists info1 (
id int(4) not null auto_increment,
name varchar(10) not null,
age char(10) not null,
hobby varchar(50),
primary key (id));
insert into info1 values(1,'user1',20,'running');
insert into info1 values(2,'user2',30,'singing');
MySQL完全备份与恢复
InnoDB 存储引擎的数据库在磁盘上存储成三个文件: db.opt(表属性文件)、表名.frm(表结构文件)、表名.ibd(表数据文件)。
1.物理冷备份与恢复
systemctl stop mysqld
yum -y install xz
#压缩备份
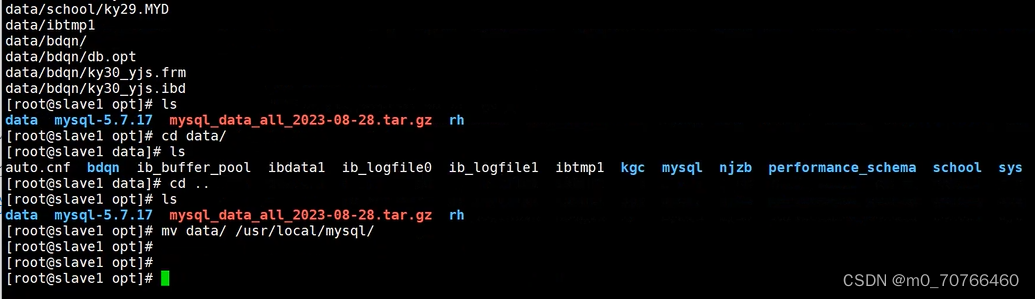
tar Jcvf /opt/mysql_all_$(date +%F).tar.xz /usr/local/mysql/data/
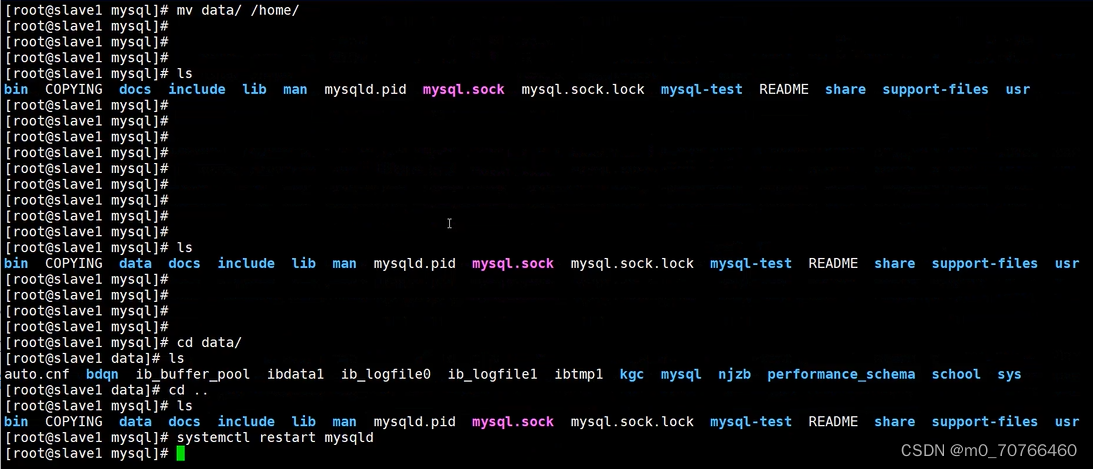
mv /usr/local/mysql/data/ /opt/
#解压恢复
tar Jxvf /opt/mysql_all_2020-11-22.tar.xz -C /usr/local/mysql/data/
cd /usr/local/mysql/data
mv /usr/local/mysql/data/* ./
2. mysqldump 备份与恢复(温备份)
create table info2 (id int,name char(10),age int,sex char(4));
insert into info2 values(1,'user',11,'性别');
insert into info2 values(2,'user',11,'性别');
(1)、完全备份一个或多个完整的库 (包括其中所有的表)
mysqldump -u root -p[密码] --databases 库名1 [库名2] ... > /备份路径/备份文件名.sql #导出的就是数据库脚本文件
例:
mysqldump -u root -p --databases kgc > /opt/kgc.sql #备份一个kgc库
mysqldump -u root -p --databases mysql kgc > /opt/mysql-kgc.sql #备份mysql与 kgc两个库
(2)、完全备份 MySQL 服务器中所有的库
mysqldump -u root -p[密码] --all-databases > /备份路径/备份文件名.sql
例:
mysqldump -u root -p --all-databases > /opt/all.sql
(3)、完全备份指定库中的部分表
mysqldump -u root -p[密码] 库名 [表名1] [表名2] ... > /备份路径/备份文件名.sql
例:
mysqldump -u root -p [-d] kgc info1 info2 > /opt/kgc_info1.sql
#使用“-d”选项,说明只保存数据库的表结构
#不使用“-d"选项,说明表数据也进行备份
#做为一个表结构模板
(4)查看备份文件
grep -v "^--" /opt/kgc_info1.sql | grep -v "^/" | grep -v "^$"
1、









##复制段
log-error=/usr/local/mysql/data/mysql_error.log
general_log=ON
general_log_file=/usr/local/mysql/data/mysql_general.log
log-bin=mysql-bin
slow_query_log=ON
slow_query_log_file=/usr/local/mysql/data/mysql_slow_query.log
long_query_time=5




常见的日志
1、错误日志
2、一般查询日志
3、慢查询日志
4、二进制日志
5、中继日志
6、重做日志
7、回滚日志
2、
(1)、完全备份一个或多个完整的库 (包括其中所有的表)

(2)、也可以两个库一起导



(2)、完全备份 MySQL 服务器中所有的库
mysqldump -u root -p[密码] --all-databases > /备份路径/备份文件名.sql

(3)、完全备份指定库中的部分表
只导结构




全导包括结构和数据,不加-d



(4)查看备份文件
grep -v "^--" /opt/kgc_info1.sql | grep -v "^/" | grep -v "^$"
![]()

Mysql 完全恢复
#恢复数据库
1.使用mysqldump导出的文件,可使用导入的方法
source命令
mysql命令
2.使用source恢复数据库的步骤
登录到MySQL数据库
执行source备份sql脚本的路径
3.source恢复的示例
MySQL [(none)]> source /backup/all-data.sql
使用source命令恢复数据
1.模拟数据库出现问题
[root@server1 backup]# mysql -uroot -pabc123 登录数据库
mysql> show databases; 查看数据库信息
mysql> drop database school; 删除数据库school
mysql> show databases;
2 应用示例:
创建备份(对表进行备份)
[root@server1 ~]# mysqldump -uroot -pabc123 school info > /opt/info.sql
[root@server1 ~]# mysql -uroot -pabc123 登录数据库查看
[root@server1 ~]# mysql -uroot -p123123 -e 'drop table school.info;' #删除数据库的表
恢复数据表
mysq
mysql> select * from info; 查询所有字段
mysql> show tables; 查看表信息
或免交互l> source /opt/info.sql
mysql -uroot -p123123 -e 'show tables from school;
方式二:
[root@mysql abc]# mysql -uroot -p123123 school < /abc/school.info.sql #恢复info表
[root@mysql abc]# mysql -uroot -p123123 -e 'show tables from school;' #查看info表
PS:mysqldump 严格来说属于温备份,会需要对表进行写入的锁定
在全量备份与恢复实验中,假设现有ky13库,ky13库中有一个test表,需要注意的一点为:
① 当备份时加 --databases ,表示针对于ky13库
#备份命令
mysqldump -uroot -p123123 --databases school > /opt/school_01.sql 备份库后
#恢复命令过程为:
mysql -uroot -p123123
drop database ky13;
exit
mysql -uroot -p123123 < /opt/ky13_01.sql
② 当备份时不加 --databases,表示针对ky13库下的所有表
#备份命令
mysqldump -uroot -p123123 ky13 > /opt/ky11_all.sql
#恢复过程:
mysql -uroot -p123123
drop database ky13;
create database ky13;
exit
mysql -uroot -p123123 ky13 < /opt/ky11_02.sql
#查看ky13_01.sql 和ky13_02.sql
主要原因在于两种方式的备份(前者会从"create databases"开始,而后者则全是针对表格进行操作)




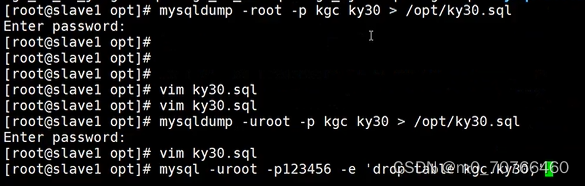

恢复:
![]()
查看是否恢复成功


方法二:

mysqldump注意点示例:
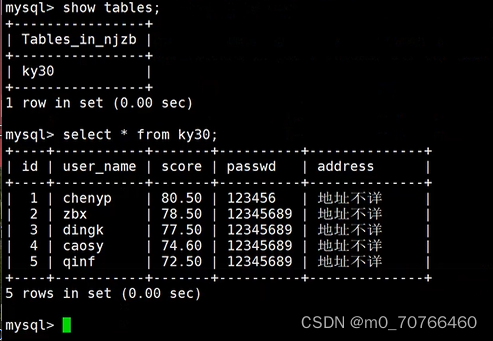

![]()



删除库后再导入
需要再创建库之后才能导入






![]()
4.在生产环境中,可以使用Shell脚本自动实现定时备份(时间频率需要确认)
0 1 * * 6 /usr/local/mysql/bin/mysqldump -uroot -pabc123 kgc info1 > ./kgc_infol_$(date +%Y%m%d).sql ;/usr/local/mysql/bin/mysqladmin -u root -p flush-logs
小结:

MySQL 增量备份与恢复
MySQL数据库增量恢复
1.一般恢复
将所有备份的二进制日志内容全部恢复
2.基于位置恢复
数据库在某一时间点可能既有错误的操作也有正确的操作
可以基于精准的位置跳过错误的操作
发生错误节点之前的一个节点,上一次正确操作的位置点停止
3.基于时间点恢复
跳过某个发生错误的时间点实现数据恢复
在错误时间点停止,在下一个正确时间点开始
MySQL 增量备份
一、增备实验
1.开启二进制日志功能
vim /etc/my.cnf
[mysqld]
log-bin=mysql-bin
binlog_format = MIXED #可选,指定二进制日志(binlog)的记录格式为MIXED(混合输入)
server-id = 1 #可加可不加该命令
#二进制日志(binlog)有3种不同的记录格式: STATEMENT (基于SQL语句)、ROW(基于行)、MIXED(混合模式),默认格式是STATEMENT
① STATEMENT(基于SQL语句):
每一条涉及到被修改的sql 都会记录在binlog中
缺点:日志量过大,如sleep()函数,last_insert_id()>,以及user-defined fuctions(udf)、主从复制等架构记录日志时会出现问题
总结:增删改查通过sql语句来实现记录,如果用高并发可能会出错,可能时间差异或者延迟,可能不是我们想想的恢复可能你先删除或者在修改,可能会倒过来。准确率底
② ROW(基于行)
只记录变动的记录,不记录sql的上下文环境
缺点:如果遇到update......set....where true 那么binlog的数据量会越来越大
总结:update、delete以多行数据起作用,来用行记录下来,
只记录变动的记录,不记录sql的上下文环境,
比如sql语句记录一行,但是ROW就可能记录10行,但是准确性高,高并发的时候由于操作量,性能变低 比较大所以记录都记下来,
③ MIXED 推荐使用
一般的语句使用statement,函数使用ROW方式存储。
systemctl restart mysqld
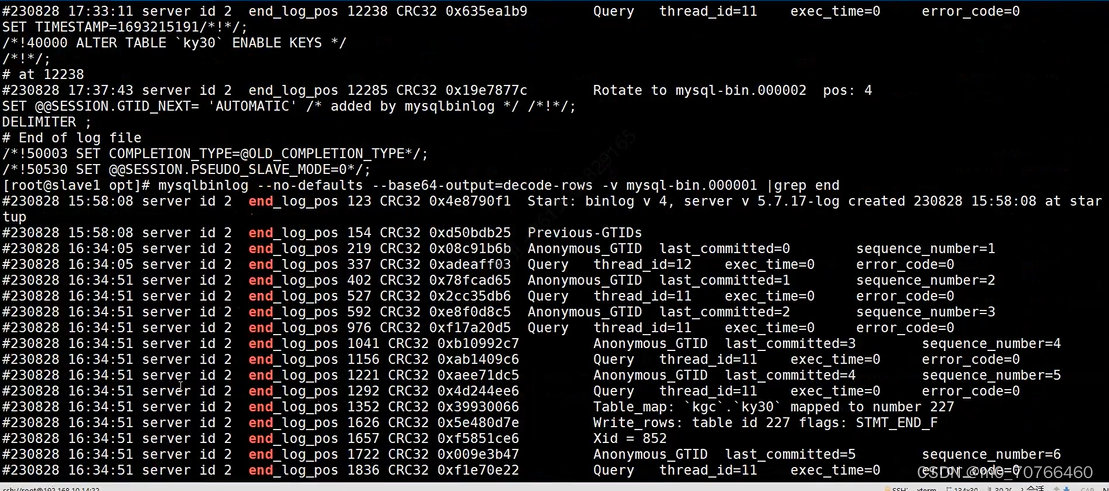
查看二进制日志文件的内容
cp /usr/local/mysql/data/mysql-bin.000002 /opt/
① mysqlbinlog --no-defaults /opt/mysql-bin.000002
mysqlbinlog --no-defaults --base64-output=decode-rows -v /opt/mysql-bin.000002
#--base64-output=decode-rows:使用64位编码机制去解码(decode)并按行读取(rows)
#-v: 显示详细内容
#--no-defaults : 默认字符集(不加会报UTF-8的错误)
PS: 可以将解码后的文件导出为txt格式,方便查阅
mysqlbinlog --no-defaults --base64-output=decode-rows -v /opt/mysql-bin.000002 > /opt/mysql-bin.000002
查看示例:


![]()

二进制日志中需要关注的部分
1、at :开始的位置点
2、end_log_pos:结束的位置
3、时间戳: 210712 11:50:30
4、SQL语句
2.进行完全备份(增量备份时基于完全备份的,所以我们直接完全备份数据库)
[root@mysql data]# mysqldump -uroot -p school info > /opt/kgc_info1_$(date +%F).sql
[root@mysql data]# mysqldump -uroot -p123123 school > /opt/school_all_$(date +%F).sql
3.可每天进行增量备份操作,生成新的二进制日志文件(例如:mysql-bin.000002)
mysqladmin -u root -p flush-logs
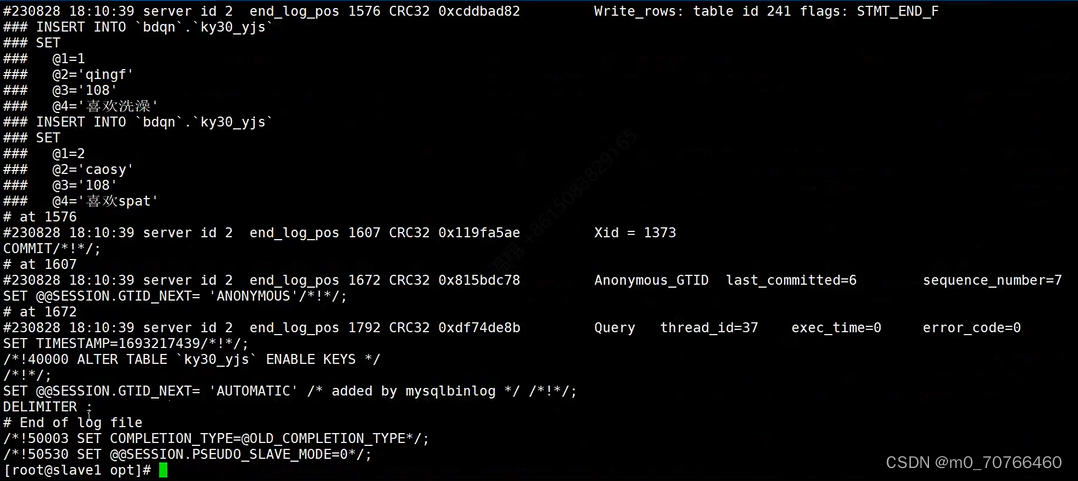
实验示例
导出一个库恢复:

导出全部库,也是按时间进行恢复:

![]()


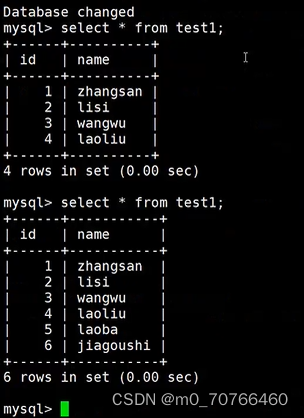
查看一下01和02表:(02表由于没有插入新的数据,因此不会有变化)

01表有许多数据


4.插入新数据,以模拟数据的增加或变更
PS:在第一次完全备份之后刷新二进制文件,在第二个二进制文件中记载着"增量备份的数据"
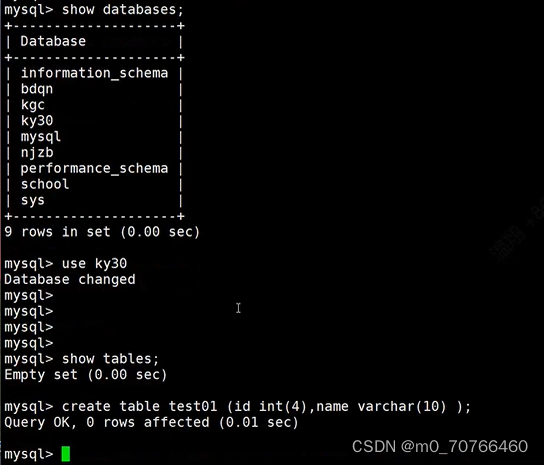
mysql> create database ky13;
Query OK, 1 row affected (0.00 sec)
mysql> use ky13;
Database changed
mysql> create table test1 (id int(4),name varchar(4));
Query OK, 0 rows affected (0.00 sec)
mysql> insert into test1 values(1,'one');
Query OK, 1 row affected (0.00 sec)
mysql> insert into test1 values(2,'two');
Query OK, 1 row affected (0.00 sec)
mysql> select * from test1;
+------+------+
| id | name |
+------+------+
| 1 | one |
| 2 | two |
+------+------+
2 rows in set (0.00 sec)
5.再次生成新的二进制日志文件(例如:mysql-bin.000003)
mysqladmin -u root -p flush-logs
#之前的步骤4的数据库操作会保存到mysql-bin.000002文件中,之后我们测试删除ky13库的操作会保存在mysql-bin.000003文件中 (以免当我们基于mysql-bin.000002日志进行恢复时,依然会删除库)
MySQL增量恢复--------
1.一般恢复
(1)、模拟丢失更改的数据的恢复步骤(直接使用恢复即可)
① 备份ky11库中test1表
mysqldump -uroot -p123123 ky13 test1 > /opt/ky13_test13.sql
② 删除ky13库中test1表
drop table ky13.test1;
③ 恢复test1表
mysql -uroot -p ky13 < info-2020-08-31.sql
#查看日志文件
[root@mysql data]# mysqlbinlog --no-defaults --base64-output=decode-rows -v mysql-bin.000002
(2)、模拟丢失所有数据的恢复步骤
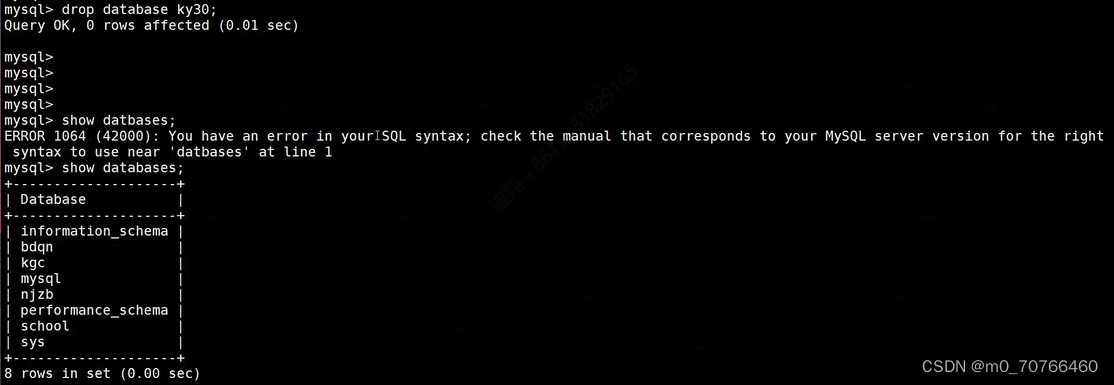
① 模拟丢失所有数据
[root@mysql data]# mysql -uroot -p123123
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| ky13 |
| mysql |
| performance_schema |
| school |
| sys |
| test |
+--------------------+
7 rows in set (0.00 sec)
mysql> drop database ky13;
Query OK, 1 row affected (0.00 sec)
mysql> exit
② 基于mysql-bin.000002恢复
mysqlbinlog --no-defaults /opt/mysql-bin.000002 | mysql -u root -p
实验演示:
![]()


备份

定义时间:

(2)







一般恢复(整个恢复):


方法二恢复:
![]()


删除整个库和表,也可以恢复


2.断点恢复
mysqlbinlog --no-defaults --base64-output=decode-rows -v /opt/mysql-bin.000002
例:
# at 302
#201122 16:41:16
插入了"user3"的用户数据
# at 623
#201122 16:41:24
插入了"user4"的用户数据
(1)、基于位置恢复
① 插入三条数据
mysql> use ky13;
mysql> select * from test1;
+------+------+
| id | name |
+------+------+
| 1 | one |
| 2 | two |
+------+------+
2 rows in set (0.00 sec)
mysql> insert into test1 values(3,'true');
Query OK, 1 row affected (0.00 sec)
mysql> insert into test1 values(4,'f');
Query OK, 1 row affected (0.00 sec)
mysql> insert into test1 values(5,'t');
Query OK, 1 row affected (0.00 sec)
mysql> select * from test1;
+------+------+
| id | name |
+------+------+
| 1 | one |
| 2 | two |
| 3 | true |
| 4 | f |
| 5 | t |
+------+------+
5 rows in set (0.00 sec)
#需求:以上id =4的数据操作失误,需要跳过
② 确认位置点,刷新二进制日志并删除test1表
mysqlbinlog --no-defaults --base64-output=decode-rows -v /opt/mysql-bin.000003
960 停止
1066 开始
#刷新日志
mysqladmin -uroot -p123123 flush-logs
mysql> use ky13;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
mysql> show tables;
+----------------+
| Tables_in_ky13 |
+----------------+
| test1 |
+----------------+
1 row in set (0.00 sec)
mysql> drop table ky13.test1;
Query OK, 0 rows affected (0.00 sec)
③ 基于位置点恢复
#仅恢复到操作 ID 为“623"之前的数据,即不恢复"user4"的数据
mysqlbinlog --no-defaults --stop-position='623' /opt/mysql-bin.000002 | mysql -uroot -p
#仅恢复"user4"的数据,跳过"user3"的数据恢复
mysqlbinlog --no-defaults --start-position='623' /opt/mysql-bin.000002 | mysql -uroot -p
mysqlbinlog --no-defaults --start-position='400' --stop-position='623' /opt/mysql-bin.000002 | mysql -uroot -p #恢复从位置为400开始到位置为623为止
示例:
![]()




删除:

查看:
![]()


恢复一段数据(恢复到4):
注:中间不能出现重复的数据,否则恢复不了,用起始到结束恢复


(2)、基于时间点恢复
mysqlbinlog [--no-defaults] --start-datetime='年-月-日 小时:分钟:秒' --stop-datetime='年-月-日小时:分钟:秒' 二进制日志 | mysql -u 用户名 -p 密码
#仅恢复到16:41:24 之前的数据,即不恢复"user4"的数据
mysqlbinlog --no-defaults --stop-datetime='2020-11-22 16:41:24' /opt/mysql-bin.000002 | mysql -uroot -p
#仅恢复"user4"的数据,跳过"user3"的数据恢复
mysqlbinlog --no-defaults --start-datetime='2020-11-22 16:41:24' /opt/mysql-bin.000002 | mysql -uroot -p
如果恢复某条SQL语之前的所有数据,就stop在这个语句的位置节点或者时间点
如果恢复某条SQL语句以及之后的所有数据,就从这个语句的位置节点或者时间点start
恢复到某个时间段之前


之后:

相关文章:
8月28日上课内容 第四章 MySQL备份与恢复
本章结构 前言:日志⭐⭐ MySQL 的日志默认保存位置为 /usr/local/mysql/data ##配置文件 vim /etc/my.cnf [mysqld] ##错误日志,用来记录当MySQL启动、停止或运行时发生的错误信息,默认已开启 log-error/usr/local/mysql/data/mysql_error.l…...

es字段查询加keyword和不加keyword的区别
在ES(Elasticsearch)中,查询字段名后面加上"keyword"和不加"keyword"有着不同的含义和用途。 当字段名后面加上"keyword"时,表示该字段是一个keyword类型的字段。Keyword类型的字段会将文本作为一…...

前端JavaScript将数据转换成JSON字符串以及将JSON字符串转换成对象的两个API
在前端 JavaScript 中,你可以使用 JSON.stringify() 方法将 JavaScript 数据转换成 JSON 字符串,以及使用 JSON.parse() 方法将 JSON 字符串转换成 JavaScript 对象。下面是这两个 API 的详细说明和示例: JSON.stringify(): 用于…...
Spring——Spring Boot基础
文章目录 第一个helloword项目新建 Spring Boot 项目Spring Boot 项目结构分析SpringBootApplication 注解分析新建一个 Controller大功告成,运行项目 简而言之,从本质上来说,Spring Boot 就是 Spring,它做了那些没有它你自己也会去做的 Spri…...

Python基础之基础语法(二)
Python基础之基础语法(二) 语言类型 静态语言 如:C C Java ina a 100 a 100 a abc # 不可以静态语言需要指定声明标识符的类型,之后不可以改变类型赋值。静态语言变异的时候要检查类型,编写源代码,编译时检查错误。 动态语…...
docker常见面试问题详解
在面试的时候,面试官常常会问一些问题: docker是什么,能做什么?docker和虚拟机的区别是什么呢?docker是用什么做隔离的?docke的网络类型?docker数据之间是如何通信的?docker的数据保…...

Auto-GPT 学习笔记
Auto-GPT 学习笔记 Auto-GPT 简介 Auto-GPT 是一个基于 GPT-4 的自主智能体实验项目。它展示了大规模语言模型的规划、记忆和工具使用能力。Auto-GPT 的目标是实现一个完全自主的 AI 代理。GitHub 仓库 Auto-GPT 核心模块 规划(Planning) 使用强化学习策略进行多跳思考。通…...

代码随想录 - Day30 - 修剪二叉树,转换二叉树 + 二叉树总结
代码随想录 - Day30 - 修剪二叉树,转换二叉树 二叉树总结 669. 修剪二叉搜索树 有点像是删除二叉搜索树的变形,改变了删除条件而已。 递归法: class Solution:def trimBST(self, root: Optional[TreeNode], low: int, high: int) -> O…...

[音视频] sdl 渲染到外部创建的窗口上
API SDL_CreateWindowFrom # 在外部窗口上创建窗口 其他 api 调用,按照之前的 代码 ui.setupUi(this); sdl_width ui.label->width(); sdl_height ui.label->height(); SDL_Init(SDL_INIT_VIDEO); sdl_win SDL_CreateWindowFrom((void*)ui.label->wi…...

MongoDB之索引
大数据量使用全集合查询,这是非常影响性能的,而索引可以加快查询效率,提高性能,所以这方面的知识也是必不可少的。 查询分析 explain()可以帮助我们分析查询语句性能。 语法 db.collection.find(...).explain()案例及结果 案…...

Redis的介绍
Redis的架构介绍如下: 1. 概述 Redis是一个基于内存的高性能NoSQL键值数据库,支持网络访问和持久化特性。 2. 功能架构 Redis提供字符串、哈希、列表、集合、有序集合、位数组等多种数据结构,支持事务、Lua脚本、发布订阅、流水线等功能。 3. 技术架构 Redis使用单线程的…...

一文了解Docker的用法
一、什么是Docker Docker 是一个开源的应用容器引擎,基于 Go 语言 并遵从 Apache2.0 协议开源。 Docker 可以让开发者打包他们的应用以及依赖包到一个轻量级、可移植的容器中,然后发布到任何流行的 Linux 机器上,也可以实现虚拟化。 容器是…...

netcat的使用
目录 netcat简介 nc的使用场景 nc实现通信 创建一个服务端 创建一个客户端 具体案例 环境 win10在具体路径下执行命令 win7在具体路径下执行命令 netcat文件传输 nc文件传输的利用 服务器等待接收文件 客户端向服务器发送文件 服务器向连接的客户端发送文件 客户…...

深度学习推荐系统(二)Deep Crossing及其在Criteo数据集上的应用
深度学习推荐系统(二)Deep Crossing及其在Criteo数据集上的应用 在2016年, 随着微软的Deep Crossing, 谷歌的Wide&Deep以及FNN、PNN等一大批优秀的深度学习模型被提出, 推荐系统全面进入了深度学习时代, 时至今日,…...

前端常用 Vue3 项目组件大全
Vue.js 是一种流行的 JavaScript 前端框架,它简化了构建交互式的用户界面的过程。Vue3 是 Vue.js 的最新版本,引入了许多新的特性和改进。在 Vue3 中,组件是构建应用程序的核心部分,它们可以重用、组合和嵌套。下面是一些前端开发…...
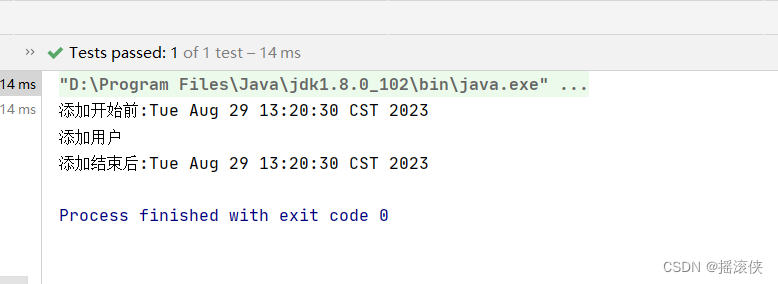
javaee spring 静态代理
静态代理 package com.test.staticProxy;public interface IUsersService {public void insert(); }package com.test.staticProxy;//目标类 public class UsersService implements IUsersService {Overridepublic void insert() {System.out.println("添加用户");…...

Java 包装类和Arrays类(详细解释)
目录 包装类 作用介绍 包装类的特有功能 Arrays类 Arrays.fill() Arrays.toString() Arrays.sort() 升序排序 降序排序 Arrays.equals() Arrays.copyOf() Arrays.binarySearch() 包装类 作用介绍 包装类其实就是8种基本数据类型对应的引用类型。 基本数据类型引用…...
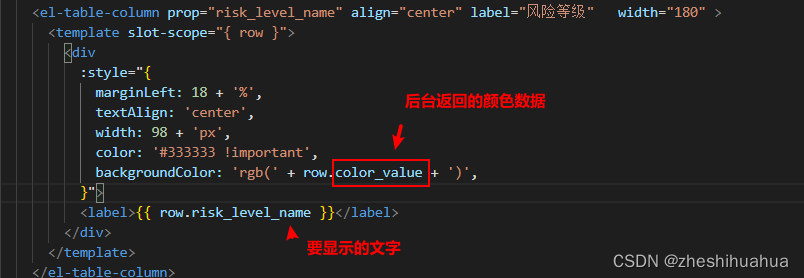
elementUi中的el-table表格的内容根据后端返回的数据用不同的颜色展示
效果图如下: 首先 首先:需要在表格行加入 <template slot-scope"{ row }"> </template>标签 <el-table-column prop"usable" align"center" label"状态" width"180" ><templ…...

在访问一个网页时弹出的浏览器窗口,如何用selenium 网页自动化解决?
相信大家在使用selenium做网页自动化时,会遇到如下这样的一个场景: 在你使用get访问某一个网址时,会在页面中弹出如上图所示的弹出框。 首先想到是利用Alert类来处理它。 然而,很不幸,Alert类处理的结果就是没有结果…...

python 基于http方式与基于redis方式传输摄像头图片数据的实现和对比
目录 0. 需求1. 基于http方式传递图片数据1.1 发送图片数据1.2 接收图片数据并可视化1.3 测试 2. 基于redis方式传递图片数据2.1 发送图片数据2.2 接收图片数据并可视化2.3 测试 3. 对比 0. 需求 在不同进程或者不同语言间传递摄像头图片数据,比如从java实现的代码…...

使用docker在3台服务器上搭建基于redis 6.x的一主两从三台均是哨兵模式
一、环境及版本说明 如果服务器已经安装了docker,则忽略此步骤,如果没有安装,则可以按照一下方式安装: 1. 在线安装(有互联网环境): 请看我这篇文章 传送阵>> 点我查看 2. 离线安装(内网环境):请看我这篇文章 传送阵>> 点我查看 说明:假设每台服务器已…...

从零实现富文本编辑器#5-编辑器选区模型的状态结构表达
先前我们总结了浏览器选区模型的交互策略,并且实现了基本的选区操作,还调研了自绘选区的实现。那么相对的,我们还需要设计编辑器的选区表达,也可以称为模型选区。编辑器中应用变更时的操作范围,就是以模型选区为基准来…...

为什么需要建设工程项目管理?工程项目管理有哪些亮点功能?
在建筑行业,项目管理的重要性不言而喻。随着工程规模的扩大、技术复杂度的提升,传统的管理模式已经难以满足现代工程的需求。过去,许多企业依赖手工记录、口头沟通和分散的信息管理,导致效率低下、成本失控、风险频发。例如&#…...

江苏艾立泰跨国资源接力:废料变黄金的绿色供应链革命
在华东塑料包装行业面临限塑令深度调整的背景下,江苏艾立泰以一场跨国资源接力的创新实践,重新定义了绿色供应链的边界。 跨国回收网络:废料变黄金的全球棋局 艾立泰在欧洲、东南亚建立再生塑料回收点,将海外废弃包装箱通过标准…...

AspectJ 在 Android 中的完整使用指南
一、环境配置(Gradle 7.0 适配) 1. 项目级 build.gradle // 注意:沪江插件已停更,推荐官方兼容方案 buildscript {dependencies {classpath org.aspectj:aspectjtools:1.9.9.1 // AspectJ 工具} } 2. 模块级 build.gradle plu…...

USB Over IP专用硬件的5个特点
USB over IP技术通过将USB协议数据封装在标准TCP/IP网络数据包中,从根本上改变了USB连接。这允许客户端通过局域网或广域网远程访问和控制物理连接到服务器的USB设备(如专用硬件设备),从而消除了直接物理连接的需要。USB over IP的…...

Mysql中select查询语句的执行过程
目录 1、介绍 1.1、组件介绍 1.2、Sql执行顺序 2、执行流程 2.1. 连接与认证 2.2. 查询缓存 2.3. 语法解析(Parser) 2.4、执行sql 1. 预处理(Preprocessor) 2. 查询优化器(Optimizer) 3. 执行器…...

GitFlow 工作模式(详解)
今天再学项目的过程中遇到使用gitflow模式管理代码,因此进行学习并且发布关于gitflow的一些思考 Git与GitFlow模式 我们在写代码的时候通常会进行网上保存,无论是github还是gittee,都是一种基于git去保存代码的形式,这样保存代码…...

【学习笔记】erase 删除顺序迭代器后迭代器失效的解决方案
目录 使用 erase 返回值继续迭代使用索引进行遍历 我们知道类似 vector 的顺序迭代器被删除后,迭代器会失效,因为顺序迭代器在内存中是连续存储的,元素删除后,后续元素会前移。 但一些场景中,我们又需要在执行删除操作…...

[USACO23FEB] Bakery S
题目描述 Bessie 开了一家面包店! 在她的面包店里,Bessie 有一个烤箱,可以在 t C t_C tC 的时间内生产一块饼干或在 t M t_M tM 单位时间内生产一块松糕。 ( 1 ≤ t C , t M ≤ 10 9 ) (1 \le t_C,t_M \le 10^9) (1≤tC,tM≤109)。由于空间…...