NLP(六十六)使用HuggingFace中的Trainer进行BERT模型微调
以往,我们在使用HuggingFace在训练BERT模型时,代码写得比较复杂,涉及到数据处理、token编码、模型编码、模型训练等步骤,从事NLP领域的人都有这种切身感受。事实上,HugggingFace中提供了datasets模块(数据处理)和Trainer函数,使得我们的模型训练较为方便。关于datasets模块,可参考文章NLP(六十二)HuggingFace中的Datasets使用。
本文将会介绍如何使用HuggingFace中的Trainer对BERT模型微调。
Trainer
Trainer是HuggingFace中的模型训练函数,其网址为:https://huggingface.co/docs/transformers/main_classes/trainer 。
Trainer的传入参数如下:
model: typing.Union[transformers.modeling_utils.PreTrainedModel, torch.nn.modules.module.Module] = None
args: TrainingArguments = None
data_collator: typing.Optional[DataCollator] = None
train_dataset: typing.Optional[torch.utils.data.dataset.Dataset] = None
eval_dataset: typing.Union[torch.utils.data.dataset.Dataset, typing.Dict[str, torch.utils.data.dataset.Dataset], NoneType] = None
tokenizer: typing.Optional[transformers.tokenization_utils_base.PreTrainedTokenizerBase] = None
model_init: typing.Union[typing.Callable[[], transformers.modeling_utils.PreTrainedModel], NoneType] = None
compute_metrics: typing.Union[typing.Callable[[transformers.trainer_utils.EvalPrediction], typing.Dict], NoneType] = None
callbacks: typing.Optional[typing.List[transformers.trainer_callback.TrainerCallback]] = None
optimizers: typing.Tuple[torch.optim.optimizer.Optimizer, torch.optim.lr_scheduler.LambdaLR] = (None, None)
preprocess_logits_for_metrics: typing.Union[typing.Callable[[torch.Tensor, torch.Tensor], torch.Tensor], NoneType] = None )
参数解释:
model为预训练模型args为TrainingArguments(训练参数)类data_collator会将数据集中的元素组成一个batch,默认使用default_data_collator(),如果tokenizer没有提供,则使用DataCollatorWithPaddingtrain_dataset,eval_dataset为训练集,验证集tokenizer为模型训练使用的tokenizermodel_init为模型初始化compute_metrics为验证集的评估指标计算函数callbacks为训练过程中的callback列表optimizers为模型训练中的优化器preprocess_logits_for_metrics为模型评估阶段前对logits的预处理
TrainingArguments为训练参数类,其网址为:https://huggingface.co/docs/transformers/main_classes/trainer#transformers.TrainingArguments,传入参数非常多(transformers版本4.32.1中有98个参数!),我们在这里只介绍几个常见的:
output_dir: stroverwrite_output_dir: bool = False
evaluation_strategy: typing.Union[transformers.trainer_utils.IntervalStrategy, str] = 'no'
per_gpu_train_batch_size: typing.Optional[int] = None
per_gpu_eval_batch_size: typing.Optional[int] = None
learning_rate: float = 5e-05
num_train_epochs: float = 3.0
logging_dir: typing.Optional[str] = None
logging_strategy: typing.Union[transformers.trainer_utils.IntervalStrategy, str] = 'steps'
save_strategy: typing.Union[transformers.trainer_utils.IntervalStrategy, str] = 'steps'save_steps: float = 500
report_to: typing.Optional[typing.List[str]] = None
参数解释:
output_dir为模型输出目录evaluation_strategy为模型评估策略
- “no": 不做模型评估
- “steps”: 按训练步数(steps)进行评估,需指定步数
- “epoch”: 每个epoch训练完后进行评估
per_gpu_train_batch_size,per_gpu_eval_batch_size为每个GPU上训练集和测试集的batch size,也有CPU上的对应参数learning_rate为学习率logging_dir为日志输出目录logging_strategy为日志输出策略,同样有no, steps, epoch三种,意义同上save_strategy为模型保存策略,同样有no, steps, epoch三种,意义同上report_to为模型训练、评估中的重要指标(如loss, accurace)输出之处,可选择azure_ml, clearml, codecarbon, comet_ml, dagshub, flyte, mlflow, neptune, tensorboard, wandb,使用all会输出到所有的地方,使用no则不会输出。
下面我们使用Trainer进行BERT模型微调,给出英语、中文数据集上文本分类的示例代码。
BERT微调
使用datasets模块导入imdb数据集(英语影评数据集,常用于文本分类),加载预训练模型bert-base-cased的tokenizer。
import numpy as np
from transformers import AutoTokenizer, DataCollatorWithPadding
import datasetscheckpoint = 'bert-base-cased'
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
raw_datasets = datasets.load_dataset('imdb')
查看数据集,有train(训练集)、test(测试集)、unsupervised(非监督)三部分,我们这里使用训练集和测试集,各自有25000个样本。
raw_datasets
DatasetDict({train: Dataset({features: ['text', 'label'],num_rows: 25000})test: Dataset({features: ['text', 'label'],num_rows: 25000})unsupervised: Dataset({features: ['text', 'label'],num_rows: 50000})
})
创建数据tokenize函数,对文本进行tokenize,最大长度设置为300,同时使用data_collector为DataCollatorWithPadding。
def tokenize_function(sample):return tokenizer(sample['text'], max_length=300, truncation=True)
tokenized_datasets = raw_datasets.map(tokenize_function, batched=True)data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
加载分类模型,输出类别为2.
from transformers import AutoModelForSequenceClassification
model = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=2)
设置compute_metrics函数,在评估过程中输出accuracy, f1, precision, recall四个指标。设置训练参数TrainingArguments类,设置Trainer。
from transformers import Trainer, TrainingArguments
from sklearn.metrics import accuracy_score, precision_recall_fscore_supportdef compute_metrics(pred):labels = pred.label_idspreds = pred.predictions.argmax(-1)precision, recall, f1, _ = precision_recall_fscore_support(labels, preds, average='weighted')acc = accuracy_score(labels, preds)return {'accuracy': acc,'f1': f1,'precision': precision,'recall': recall}training_args = TrainingArguments(output_dir='imdb_test_trainer', # 指定输出文件夹,没有会自动创建evaluation_strategy="epoch",per_device_train_batch_size=32,per_device_eval_batch_size=32,learning_rate=5e-5,num_train_epochs=3,warmup_ratio=0.2,logging_dir='./imdb_train_logs',logging_strategy="epoch",save_strategy="epoch",report_to="tensorboard") trainer = Trainer(model,training_args,train_dataset=tokenized_datasets["train"],eval_dataset=tokenized_datasets["test"],data_collator=data_collator, # 在定义了tokenizer之后,其实这里的data_collator就不用再写了,会自动根据tokenizer创建tokenizer=tokenizer,compute_metrics=compute_metrics
)
开启模型训练。
trainer.train()
| Epoch | Training Loss | Validation Loss | Accuracy | F1 | Precision | Recall |
|---|---|---|---|---|---|---|
| 1 | 0.364300 | 0.223223 | 0.910600 | 0.910509 | 0.912276 | 0.910600 |
| 2 | 0.164800 | 0.204420 | 0.923960 | 0.923941 | 0.924375 | 0.923960 |
| 3 | 0.071000 | 0.241350 | 0.925520 | 0.925510 | 0.925759 | 0.925520 |
TrainOutput(global_step=588, training_loss=0.20003824169132986, metrics={'train_runtime': 1539.8692, 'train_samples_per_second': 48.705, 'train_steps_per_second': 0.382, 'total_flos': 1.156249755e+16, 'train_loss': 0.20003824169132986, 'epoch': 3.0})
以上为英语数据集的文本分类模型微调。
中文数据集使用sougou-mini数据集(训练集4000个样本,测试集495个样本,共5个输出类别),预训练模型采用bert-base-chinese。代码基本与英语数据集差不多,只要修改 预训练模型,数据集加载 和 最大长度为128,输出类别。以下是不同的代码之处:
import numpy as np
from transformers import AutoTokenizer, DataCollatorWithPadding
import datasetscheckpoint = 'bert-base-chinese'
tokenizer = AutoTokenizer.from_pretrained(checkpoint)data_files = {"train": "./data/sougou/train.csv", "test": "./data/sougou/test.csv"}
raw_datasets = datasets.load_dataset("csv", data_files=data_files, delimiter=",")
...
model = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=5)
...
输出结果如下:
| Epoch | Training Loss | Validation Loss | Accuracy | F1 | Precision | Recall |
|---|---|---|---|---|---|---|
| 1 | 0.849200 | 0.115189 | 0.969697 | 0.969449 | 0.970073 | 0.969697 |
| 2 | 0.106900 | 0.093987 | 0.973737 | 0.973770 | 0.975372 | 0.973737 |
| 3 | 0.047800 | 0.078861 | 0.973737 | 0.973740 | 0.974117 | 0.973737 |
模型评估
在上述模型评估过程中,已经有了模型评估的各项指标。
本文也给出单独做模型评估的代码,方便后续对模型做量化时(后续介绍BERT模型的动态量化)获取量化前后模型推理的各项指标。
中文数据集文本分类模型评估代码如下:
import torch
from transformers import AutoModelForSequenceClassificationMAX_LENGTH = 128
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
checkpoint = f"./sougou_test_trainer_{MAX_LENGTH}/checkpoint-96"
model = AutoModelForSequenceClassification.from_pretrained(checkpoint).to(device)from transformers import AutoTokenizer, DataCollatorWithPaddingtokenizer = AutoTokenizer.from_pretrained(checkpoint)import pandas as pdtest_df = pd.read_csv("./data/sougou/test.csv")
test_df.head()
| text | label | |
|---|---|---|
| 0 | 届数比赛时间比赛地点参加国家和地区冠军亚军决赛成绩第一届1956-1957英国11美国丹麦6... | 0 |
| 1 | 商品属性材质软橡胶带加浮雕工艺+合金彩色队徽吊牌规格162mm数量这一系列产品不限量发行图案... | 0 |
| 2 | 今天下午,沈阳金德和长春亚泰队将在五里河相遇。在这两支球队中沈阳籍球员居多,因此这场比赛实际... | 0 |
| 3 | 本报讯中国足协准备好了与特鲁西埃谈判的合同文本,也在北京给他预订好了房间,但特鲁西埃爽约了!... | 0 |
| 4 | 网友点击发表评论祝贺中国队夺得五连冠搜狐体育讯北京时间5月6日,2006年尤伯杯羽毛球赛在日... | 0 |
import numpy as np
import times_time = time.time()
true_labels, pred_labels = [], []
for i, row in test_df.iterrows():row_s_time = time.time()true_labels.append(row["label"])encoded_text = tokenizer(row['text'], max_length=MAX_LENGTH, truncation=True, padding=True, return_tensors='pt').to(device)# print(encoded_text)logits = model(**encoded_text)label_id = np.argmax(logits[0].detach().cpu().numpy(), axis=1)[0]pred_labels.append(label_id)if i % 100 == 0:print(i, (time.time() - row_s_time)*1000, label_id)print("avg time: ", (time.time() - s_time) * 1000 / test_df.shape[0])
0 229.3872833251953 0
100 362.0314598083496 1
200 311.16747856140137 2
300 324.13792610168457 3
400 406.9099426269531 4
avg time: 352.44047810332944
true_labels[:10]
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
pred_labels[:10]
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
from sklearn.metrics import classification_reportprint(classification_report(true_labels, pred_labels, digits=4))
precision recall f1-score support0 0.9900 1.0000 0.9950 991 0.9691 0.9495 0.9592 992 0.9900 1.0000 0.9950 993 0.9320 0.9697 0.9505 994 0.9895 0.9495 0.9691 99accuracy 0.9737 495macro avg 0.9741 0.9737 0.9737 495
weighted avg 0.9741 0.9737 0.9737 495
总结
本文介绍了如何使用HuggingFace中的Trainer对BERT模型微调。可以看到,使用Trainer进行模型微调,代码较为简洁,且支持功能丰富,是理想的模型训练方式。
本文项目代码已开源至Github,网址为:https://github.com/percent4/PyTorch_Learning/tree/master/huggingface_learning 。
本人已开通个人博客网站,网址为:https://percent4.github.io/ ,欢迎大家访问~
相关文章:
使用HuggingFace中的Trainer进行BERT模型微调)
NLP(六十六)使用HuggingFace中的Trainer进行BERT模型微调
以往,我们在使用HuggingFace在训练BERT模型时,代码写得比较复杂,涉及到数据处理、token编码、模型编码、模型训练等步骤,从事NLP领域的人都有这种切身感受。事实上,HugggingFace中提供了datasets模块(数据处…...
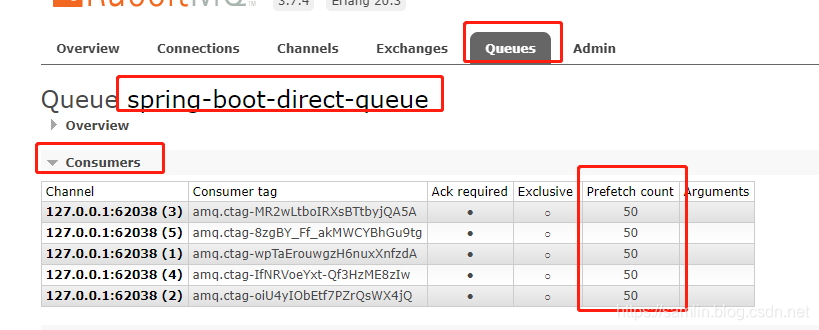
Rabbitmq消息积压问题如何解决以及如何进行限流
一、增加处理能力 优化系统架构、增加服务器资源、采用负载均衡等手段,以提高系统的处理能力和并发处理能力。通过增加服务器数量或者优化代码,确保系统能够及时处理所有的消息。 二、异步处理 将消息的处理过程设计为异步执行,即接收到消息…...

Lambda方法引用
1、体验方法引用 在使用Lambda表达式的时候,我们实际上传递进去的代码就是一种解决方案:拿参数做操作那么考虑一种情况:如果我们在Lanbda中所指定的操作方案,已经有地方存在相同方案,那是否还有必要再重复逻辑呢&#…...
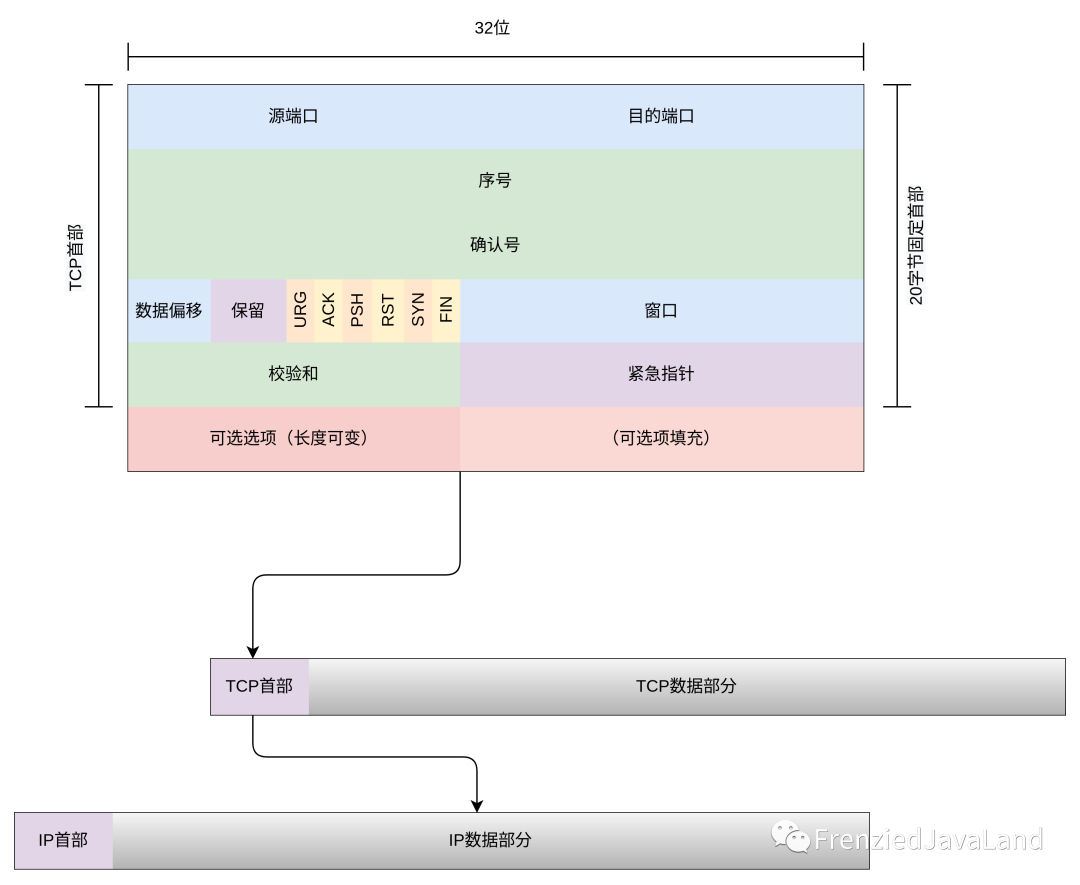
TCP协议报文
前言 TCP/IP协议簇——打开虚拟世界大门中,已经给大家大致介绍了TCP/IP协议簇的分层。 TCP (Transmission Control Protocol)传输控制协议,在TCP/IP协议簇中,处于传输层。是为了在不可靠的互联网络(IP协议)中&#x…...
C# 如何将使用的Dll嵌入到.exe应用程序中?
文章目录 前言详细实操简要步骤 前言 有没有想自己开发的exe保留一点神秘,不想让他人知道软件使用了哪些dll; 又或许是客户觉得一个软件里面的dll文件太多了,能不能简单一点,直接双击.exe就可以直接运行了,别搞那么多乱七八糟的。…...
【LeetCode】剑指 Offer Ⅱ 第5章:哈希表(6道题) -- Java Version
题库链接:https://leetcode.cn/problem-list/e8X3pBZi/ 类型题目解决方案哈希表的设计剑指 Offer II 030. 插入、删除和随机访问都是O(1) 的容器HashMap ArrayList ⭐剑指 Offer II 031. LRU 缓存HashMap 双向链表 ⭐哈希表的应用剑指 Offer II 032. 有效的变位…...
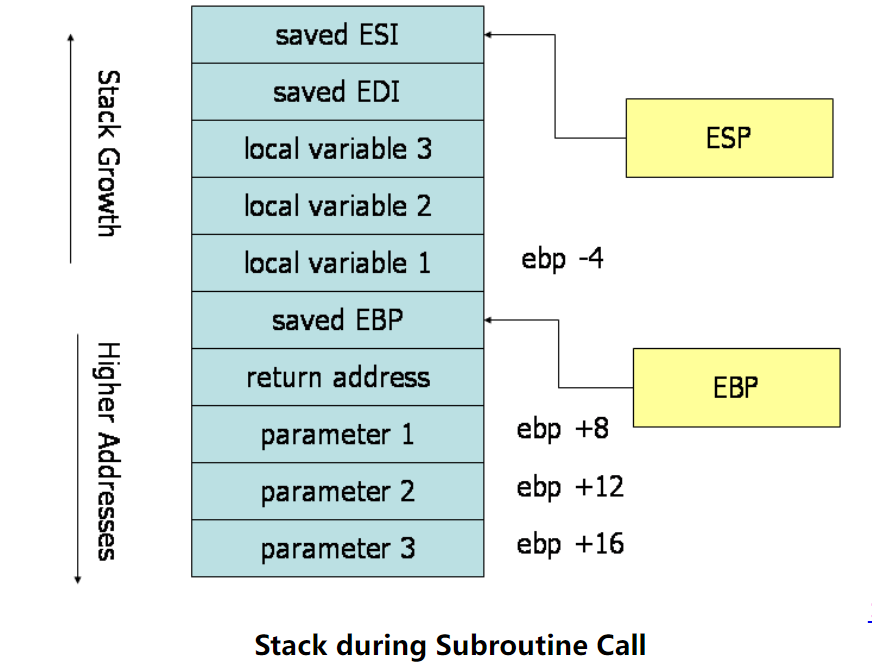
x86 汇编手册快速入门
本文翻译自:Guide to x86 Assembly 在阅读 Linux 源码之前,我们需要有一些 x86 汇编知识。本指南描述了 32 位 x86 汇编语言编程的基础知识,包括寄存器结构,数据表示,基本的操作指令(包括数据传送指令、逻…...

WPF C# Binding绑定不上的解决情况
Binding绑定不上的一般解决情况: 1.添加上下文 DataContext d:DataContext"{d:DesignInstance Typelocal:CommSettingView}"2.添加相对位置 RelativeSource Command"{Binding SaveCommand, RelativeSource{RelativeSource AncestorTypeUserContr…...
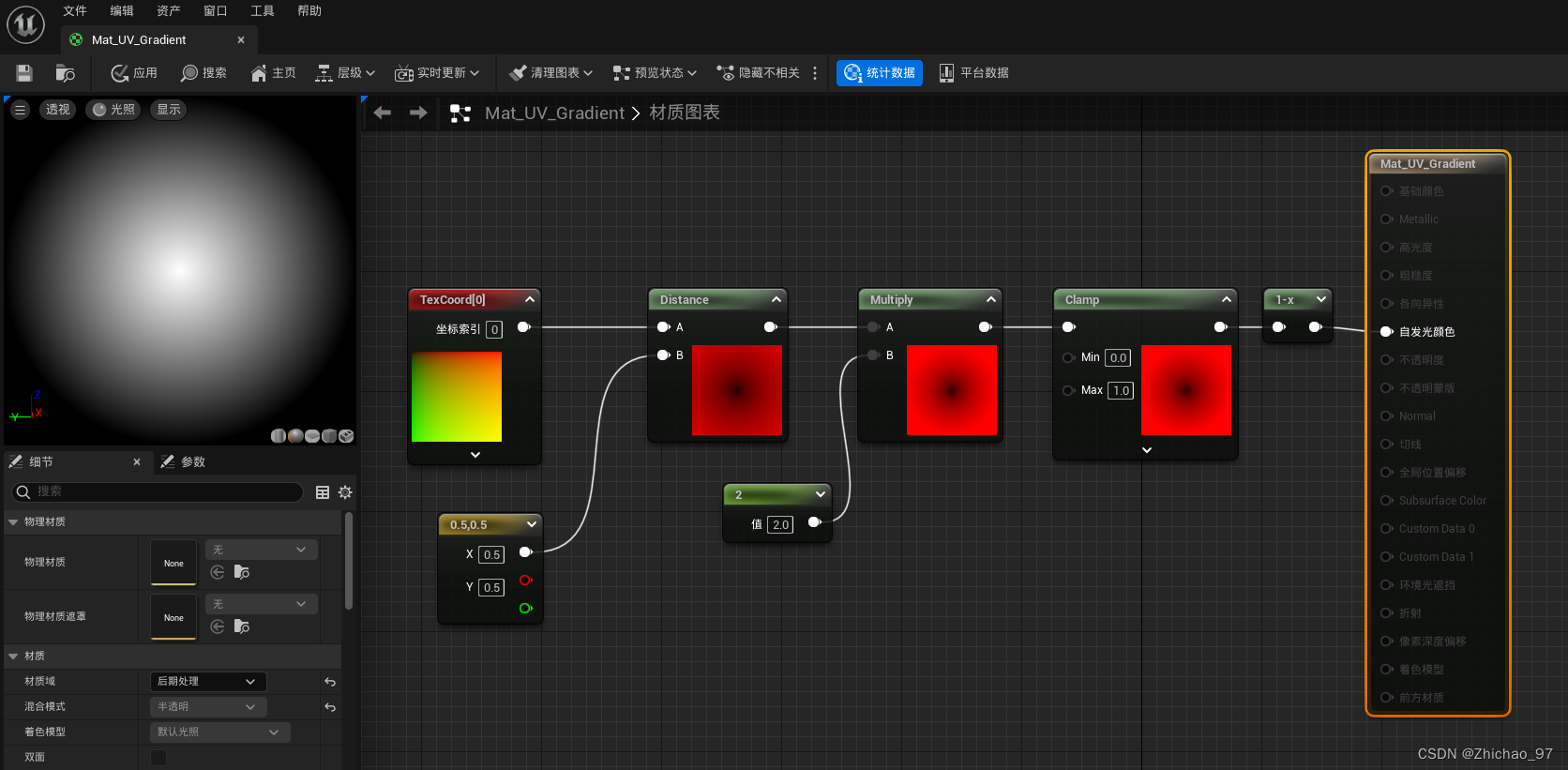
【UE 材质】实现方形渐变、中心渐变材质
步骤 一、实现方形渐变 1. 新建一个材质,材质域选择“后期处理” 2. 通过“Mask”节点单独获取R、G通道,可以看到R通道是从左到右0~1之间的变化,对应U平铺 可以看到G通道是从上到下0~1之间的变化,对应V平铺 3. 完善如下节点 二、…...
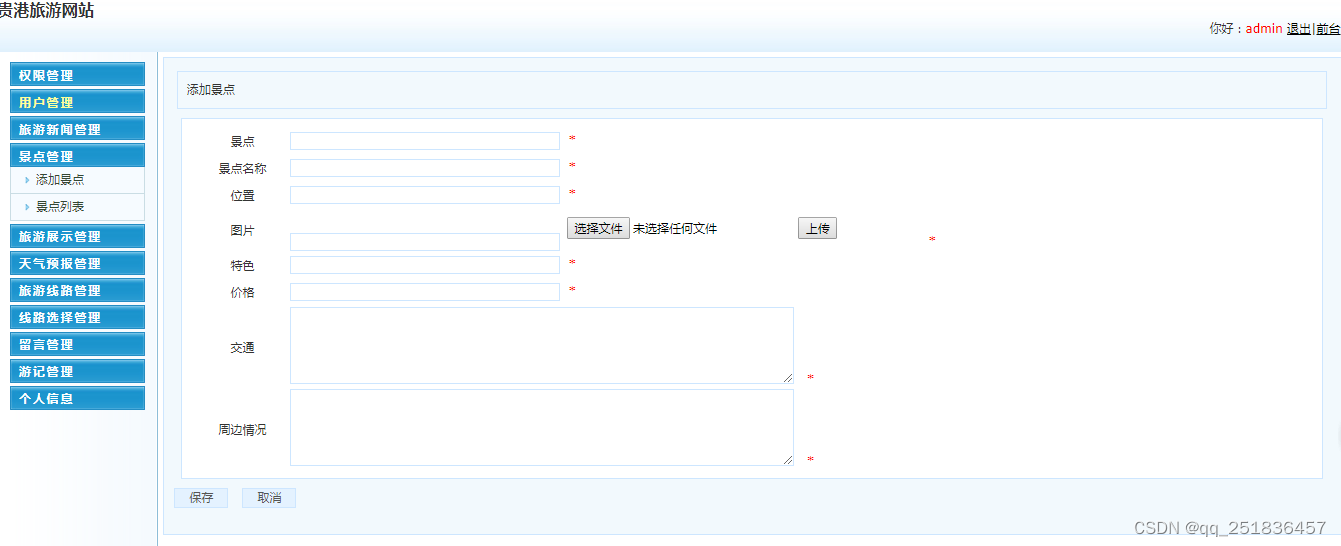
PHP旅游管理系统Dreamweaver开发mysql数据库web结构php编程计算机网页
一、源码特点 PHP 旅游管理系统是一套完善的web设计系统,对理解php编程开发语言有帮助,系统具有完整的源代码和数据库,系统主要采用B/S模式开发。 PHP 旅游管理系统 源码下载地址: https://download.csdn.net/download/qq_41…...

java内存模型讨论及案例分析
常用内存选项 -Xmx: 最大堆大小 -Xms:最小堆大小 -Xss :线程堆栈大小,默认1M 生产环境最好保持 Xms Xmx java内存研究 内存布局 可见: 堆大小 新生代 老年代,新生代EFrom SurvivorTo Survivor。新…...

对战ChatGPT,创邻科技的Graph+AI会更胜一筹吗?
大模型(大规模语言模型,即Large Language Model)的应用已经成为千行百业发展的必然。特定领域或行业中经过训练和优化的企业级垂直大模型则成为大模型走下神坛、真正深入场景的关键之路。 但是,企业级垂直大模型在正式落地应用前…...

9月2日,每日信息差
1、墨迹天气发布全球雷达融合降水服务产品。据介绍,该产品基于机器学习技术,对全球气象雷达观测图片进行智能识别去噪和外推,并融合全球气象模式、卫星等数据,提供全球范围公里级、分钟级降水预报,可围绕降水灾害的不同…...

uni-app之android项目云打包
1,项目根目录,找到mainfest.json,如果appid是空的,需要生成一个appid 2,点击重新获取appid,这个时候需要登录,那就输入账号密码登录下 3,登陆后可以看到获取appid成功 4,…...

C++的智能指针和可变参数模板详解
智能指针 1. 垃圾回收 垃圾回收机制已经大行其道,得到了诸多编程语言的支持,例如Java、Python、 C#、PHP等。而C虽然从来没有公开得支持过垃圾回收机制,但C98/03标准中,支持使用auto_ptr智能指针来实现堆内存的自动回收; C11新标…...

Docker及常用数据库安装
Docker安装常用数据库 1、Docker安装2、Mysql安装3、Redis安装4、DM安装5、Oracle安装1、Docker安装 1、确保 yum 包更新到最新yum update2、卸载旧版本(如果安装过旧版本的话)yum remove docker docker-common docker-selinux docker-engine3、安装需要的软件包, yum-util 提…...

前端使用 JavaScript 检测用户是否在线的6种方法
要检测用户是否在线,可以使用以下几种方法: 1. 使用navigator.onLine属性: navigator.onLine是一个布尔值,表示用户是否与互联网连接。当用户在线时,该属性的值为true,当用户离线时,该属性的值…...

Windows下Redis的安装
文章目录 一,Redis介绍二,Redis下载三,Redis安装-解压四,Redis配置五,Redis启动和关闭(通过terminal操作)六,Redis连接七,Redis使用 一,Redis介绍 远程字典服务,一个开源的,键值对形式的在线服务框架,值支持多数据结构,本文介绍windows下Redis的安装,配置相关,官网默认下载的是…...

SpringBoot第45讲:SpringBoot定时任务 - Timer实现方式
SpringBoot第45讲:SpringBoot定时任务 - Timer实现方式 定时任务在实际开发中有着广泛的用途,本文是SpringBoot第45讲,主要帮助你构建定时任务的知识体系,同时展示Timer 的schedule和scheduleAtFixedRate例子;后续的文章中我们将逐一介绍其它常见的定时任务,并与SpringBo…...
)
01背包(换汤不换药)
链接:登录—专业IT笔试面试备考平台_牛客网 来源:牛客网 有一个箱子容量为V(正整数,0 ≤ V ≤ 20000),同时有n个物品(0<n ≤ 30),每个物品有一个体积…...

【kafka】Golang实现分布式Masscan任务调度系统
要求: 输出两个程序,一个命令行程序(命令行参数用flag)和一个服务端程序。 命令行程序支持通过命令行参数配置下发IP或IP段、端口、扫描带宽,然后将消息推送到kafka里面。 服务端程序: 从kafka消费者接收…...

ES6从入门到精通:前言
ES6简介 ES6(ECMAScript 2015)是JavaScript语言的重大更新,引入了许多新特性,包括语法糖、新数据类型、模块化支持等,显著提升了开发效率和代码可维护性。 核心知识点概览 变量声明 let 和 const 取代 var…...

黑马Mybatis
Mybatis 表现层:页面展示 业务层:逻辑处理 持久层:持久数据化保存 在这里插入图片描述 Mybatis快速入门 
基于Uniapp开发HarmonyOS 5.0旅游应用技术实践
一、技术选型背景 1.跨平台优势 Uniapp采用Vue.js框架,支持"一次开发,多端部署",可同步生成HarmonyOS、iOS、Android等多平台应用。 2.鸿蒙特性融合 HarmonyOS 5.0的分布式能力与原子化服务,为旅游应用带来…...

逻辑回归暴力训练预测金融欺诈
简述 「使用逻辑回归暴力预测金融欺诈,并不断增加特征维度持续测试」的做法,体现了一种逐步建模与迭代验证的实验思路,在金融欺诈检测中非常有价值,本文作为一篇回顾性记录了早年间公司给某行做反欺诈预测用到的技术和思路。百度…...

uniapp 实现腾讯云IM群文件上传下载功能
UniApp 集成腾讯云IM实现群文件上传下载功能全攻略 一、功能背景与技术选型 在团队协作场景中,群文件共享是核心需求之一。本文将介绍如何基于腾讯云IMCOS,在uniapp中实现: 群内文件上传/下载文件元数据管理下载进度追踪跨平台文件预览 二…...

[特殊字符] 手撸 Redis 互斥锁那些坑
📖 手撸 Redis 互斥锁那些坑 最近搞业务遇到高并发下同一个 key 的互斥操作,想实现分布式环境下的互斥锁。于是私下顺手手撸了个基于 Redis 的简单互斥锁,也顺便跟 Redisson 的 RLock 机制对比了下,记录一波,别踩我踩过…...

C++--string的模拟实现
一,引言 string的模拟实现是只对string对象中给的主要功能经行模拟实现,其目的是加强对string的底层了解,以便于在以后的学习或者工作中更加熟练的使用string。本文中的代码仅供参考并不唯一。 二,默认成员函数 string主要有三个成员变量,…...
 ----- Python的类与对象)
Python学习(8) ----- Python的类与对象
Python 中的类(Class)与对象(Object)是面向对象编程(OOP)的核心。我们可以通过“类是模板,对象是实例”来理解它们的关系。 🧱 一句话理解: 类就像“图纸”,对…...
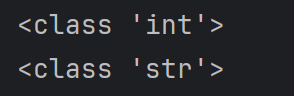
python基础语法Ⅰ
python基础语法Ⅰ 常量和表达式变量是什么变量的语法1.定义变量使用变量 变量的类型1.整数2.浮点数(小数)3.字符串4.布尔5.其他 动态类型特征注释注释是什么注释的语法1.行注释2.文档字符串 注释的规范 常量和表达式 我们可以把python当作一个计算器,来进行一些算术…...