面试系列 - JVM内存模型和调优详解
目录
一、JVM内存模型
1. 程序计数器(Program Counter Register):
2.Java虚拟机栈(Java Virtual Machine Stacks):
3. 本地方法栈(Native Method Stack):
5. 方法区(Method Area):
6. 运行时常量池(Runtime Constant Pool):
7. 直接内存(Direct Memory):
二、垃圾回收期CMS和G1区别
1. 工作原理:
2. 停顿时间:
3. 内存碎片:
4. 适用场景:
三、jvm调优工具使用
1. VisualVM:
2. jconsole:
3. jvisualvm:
4. jmap:
5. jhat:
6. MAT(Memory Analyzer Tool):
7. YourKit:
8. JProfiler:
四、jvm 调优方案
1.调整堆内存大小:
2.选择合适的垃圾收集器:
3.调整新生代和老年代比例:
4.合理配置垃圾收集器参数:
5.监控和分析GC日志:
6.线程管理:
7.使用合适的数据结构和算法:
8.内存泄漏检测:
9. 代码优化:
10.使用性能分析工具:
五、jvm在项目中调优的示例
步骤1:分析性能问题
步骤2:调整堆内存
步骤3:选择合适的垃圾收集器
步骤4:监控和分析GC日志
步骤5:线程管理
步骤6:代码优化
步骤7:内存泄漏检测
步骤8:测试和监视
JVM(Java Virtual Machine)内存模型定义了Java应用程序在运行时如何管理内存,包括如何分配、回收和使用内存。
一、JVM内存模型
1. 程序计数器(Program Counter Register):
- 每个线程都有一个程序计数器,它是一个指针,指向当前线程正在执行的字节码指令的位置。
- 在多线程环境中,程序计数器用于线程切换时的恢复现场。
2.Java虚拟机栈(Java Virtual Machine Stacks):
- 每个线程都有一个Java虚拟机栈,用于存储局部变量和方法调用的信息。
- 栈帧包括局部变量表、操作数栈、方法引用等。
- 当一个方法被调用时,会创建一个栈帧,方法的参数和局部变量被存储在栈帧的局部变量表中。
3. 本地方法栈(Native Method Stack):
- 本地方法栈类似于Java虚拟机栈,但是用于执行本地方法,即由本地库(通常是用C/C++编写的)提供的方法。
- 本地方法栈也包含了栈帧,但它用于执行非Java代码。
4. 堆(Heap):
- 堆是Java虚拟机管理的最大的一块内存区域,用于存储对象实例。
- 所有线程共享堆,但线程之间不直接访问堆。
- 堆中的对象由垃圾回收器管理,主要包括新生代和老年代,以及永久代/元空间(Java 8及之前)或元空间(Java 8之后)。
5. 方法区(Method Area):
- 方法区用于存储类的信息,包括类的结构信息、字段信息、方法信息、静态变量、常量池等。
- 在Java 8之前,方法区包括永久代,而在Java 8之后,使用元空间代替永久代。
- 方法区在运行时是只读的,不允许动态创建类或修改类的结构。
6. 运行时常量池(Runtime Constant Pool):
- 运行时常量池是方法区的一部分,用于存储编译期生成的各种字面量和符号引用。
- 运行时常量池支持在运行时动态生成新的常量。
7. 直接内存(Direct Memory):
- 直接内存不是JVM规范中的一部分,但它在Java NIO中被广泛使用,通过ByteBuffer等类来进行操作。
- 直接内存是通过操作系统的本地I/O来分配和释放的,而不是通过Java虚拟机内存管理。
二、垃圾回收期CMS和G1区别
1. 工作原理:
- CMS:
- CMS使用“标记-清除”算法,它分为四个主要阶段:初始标记、并发标记、重新标记和并发清除。
- 初始标记和重新标记需要停止应用程序的运行,因为它们需要标记根对象和标记已经发生变化的对象。
- 并发标记和并发清除阶段尽可能并发执行,以最小化停顿时间。
- G1:
- G1使用“分代标记整理”算法,它将堆内存划分为多个大小相等或不等的区域,每个区域可以是幸存区、老年区或Humongous区。
- G1的目标是减少停顿时间,它通过选择具有最多垃圾的区域来进行回收(Garbage First),而不是整个堆。
- G1使用并发标记来标记存活对象,并使用并发清理来回收垃圾对象,从而减少停顿时间。
2. 停顿时间:
- CMS:
- CMS的目标是减少老年代的Full GC停顿时间,因此它通常能够提供较低的Full GC停顿时间。
- 但CMS在并发标记和清除阶段可能会产生一些较小的停顿。
- G1:
- G1的主要目标是提供可预测的停顿时间,不仅针对老年代,还包括新生代。
- G1通过垃圾回收周期的分布来控制停顿时间,通常在几百毫秒内。
3. 内存碎片:
- CMS:
- 由于CMS使用标记-清除算法,可能会导致内存碎片的问题。当分配大对象时,可能需要进行Full GC来进行整理。
- G1:
- G1使用复制算法来整理内存,通常不会产生明显的内存碎片问题。
4. 适用场景:
- CMS:
- CMS适用于需要短暂停顿时间的应用程序,特别是Web应用等。
- 不建议在内存分配速度非常快或内存碎片严重的情况下使用CMS。
- G1:
- G1适用于需要可预测停顿时间的应用程序,尤其是对于大堆内存。
- G1在应对内存碎片和大堆情况下表现更好。
总的来说,选择CMS还是G1取决于应用程序的性质和需求。CMS适合对短暂停顿时间要求较高的应用,而G1适合需要可预测停顿时间和大堆内存的应用。在选择之前,最好通过性能测试来确定哪个垃圾收集器适合你的应用程序。此外,Java虚拟机的版本和配置也可能影响选择。
三、jvm调优工具使用
JVM调优工具是用于分析、监视和优化Java应用程序性能的工具集。
1. VisualVM:
- VisualVM是一个免费的开发工具,通常随JDK一起提供。
- 用于监视和分析本地和远程Java应用程序的性能,包括内存、线程和CPU使用情况。
- 使用VisualVM时,可以连接到正在运行的Java进程,并监视各种性能指标。
- 可以通过VisualVM执行线程分析、堆转储、垃圾回收分析等操作。
2. jconsole:
- jconsole是JDK提供的Java监视和管理控制台工具。
- 用于监视本地Java进程的性能,包括内存使用、垃圾回收、线程和MBean。
- 在命令行中运行jconsole,然后选择要监视的Java进程。
3. jvisualvm:
- jvisualvm是JDK提供的Java VisualVM工具,是VisualVM的前身。
- 具有更多的功能,包括内存分析、性能分析、线程分析和堆转储分析。
- 在命令行中运行jvisualvm,然后选择要监视的Java进程。
4. jmap:
- jmap是一个命令行工具,用于生成Java堆转储快照,以供后续分析。
- 可以使用jmap -dump:format=b,file=heapdump.bin <pid>命令生成堆转储文件。
- 生成的堆转储文件可以使用其他工具进行分析,如VisualVM或MAT。
5. jhat:
- jhat是一个命令行工具,用于分析Java堆转储文件(通常由jmap生成)。
- 可以使用jhat <heapdumpfile>命令启动jhat分析。
- jhat提供了一个Web界面,可以用于查看内存分析数据。
6. MAT(Memory Analyzer Tool):
- MAT是一个强大的开源内存分析工具,用于分析Java堆转储文件。
- 支持查找内存泄漏、分析对象引用关系、查看内存使用情况等。
- 通过导入堆转储文件进行分析。
7. YourKit:
- YourKit是一款商业的Java性能分析工具,提供了强大的性能分析和调优功能。
- 支持CPU和内存分析,可以监视线程、内存使用、垃圾回收等。
- 有图形界面和命令行工具。
8. JProfiler:
- JProfiler是另一款商业的Java性能分析工具,提供了全面的性能分析和优化工具。
- 支持CPU、内存、线程、数据库等各种性能分析。
- 具有图形界面和命令行工具。
这些工具中的大多数都可以通过命令行启动或作为独立应用程序使用,用于分析和监视Java应用程序的性能。选择工具时,通常会根据你的需求、技能水平和预算来进行选择。无论使用哪个工具,都可以帮助你识别和解决Java应用程序中的性能问题,进行JVM调优。
四、jvm 调优方案
JVM(Java Virtual Machine)调优是为了提高Java应用程序的性能和稳定性,需要根据应用的性质和工作负载来选择适当的调优方案。以下是一些常见的JVM调优方案,并附有解释:
1.调整堆内存大小:
解释: 堆内存是Java应用程序中存储对象的主要区域。通过调整堆内存的初始大小(-Xms)和最大大小(-Xmx),你可以根据应用程序的内存需求来分配足够的内存。
示例: 如果应用程序的内存需求较大,可以增加-Xms和-Xmx的值以提高性能,但要确保不超过物理内存的限制。
2.选择合适的垃圾收集器:
解释: 不同的垃圾收集器适用于不同的应用场景。例如,SerialGC适用于单线程应用,而G1GC适用于大内存和多核心机器。
示例: 根据应用程序的性能需求和硬件环境,选择合适的垃圾收集器。
3.调整新生代和老年代比例:
解释: 默认情况下,新生代和老年代的比例为1:2。根据应用程序的内存访问模式,你可以调整这个比例。
示例: 如果应用程序生成的临时对象较多,可以增加新生代的大小,减少新生代垃圾收集的频率。
4.合理配置垃圾收集器参数:
解释: 垃圾收集器有许多参数可以调整,如堆大小、线程数、停顿时间等。根据应用程序的需求,可以微调这些参数以优化性能。
示例: 使用参数如-XX:MaxGCPauseMillis来控制垃圾回收的停顿时间,或使用-XX:ParallelGCThreads来配置垃圾回收线程数。
5.监控和分析GC日志:
解释: 启用GC日志并分析它可以帮助你了解垃圾收集的行为,识别潜在的性能问题。
示例: 使用参数-XX:+PrintGC和-XX:+PrintGCDetails启用GC日志,然后使用工具如VisualVM或GCViewer来分析日志。
6.线程管理:
解释: 管理线程池的大小,确保不会过度创建线程,以避免线程竞争和资源浪费。
示例: 根据应用程序的负载和硬件配置,调整线程池的大小,避免过多的线程竞争。
7.使用合适的数据结构和算法:
解释: 使用适当的数据结构和算法可以减少内存和CPU消耗,提高性能。
示例: 选择合适的集合类型,避免不必要的复杂度。
8.内存泄漏检测:
解释: 使用工具如MAT或YourKit来检测和解决内存泄漏问题。
示例: 分析堆转储文件以查找未释放的对象引用。
9. 代码优化:
解释: 优化代码以减少对象创建、避免过度同步、减少循环次数等,以提高性能。
示例: 使用连接池、缓存、懒加载等技术来减少资源浪费。
10.使用性能分析工具:
解释: 使用性能分析工具如YourKit、JProfiler等,可以帮助识别瓶颈和性能问题。
示例: 使用工具来分析CPU、内存和线程性能,并识别性能瓶颈。
JVM调优是一个复杂的过程,需要根据具体的应用程序和硬件环境来进行调整。最佳的调优方案取决于应用程序的性质和需求。建议在进行调优前对应用程序进行性能分析,以了解问题的根本原因,然后根据实际情况采取相应的措施。不同的应用程序可能需要不同的调优策略。
五、jvm在项目中调优的示例
JVM调优的示例通常基于具体项目的需求和性能特征。以下是一个示例,演示了如何在一个Java应用程序中进行JVM调优。
示例背景: 假设你有一个Spring Boot Web应用程序,该应用程序处理大量HTTP请求,但在高负载下性能不佳。你想通过JVM调优来提高应用程序的性能和稳定性。
步骤1:分析性能问题
首先,使用性能分析工具(如VisualVM、YourKit等)或监控工具(如Prometheus和Grafana)来分析应用程序的性能问题。识别性能瓶颈,确定是否存在内存泄漏、频繁的垃圾回收、高CPU使用率等问题。
步骤2:调整堆内存
假设分析显示内存使用过多,并且垃圾回收频繁。你可以尝试调整堆内存大小,增加初始堆大小(-Xms)和最大堆大小(-Xmx),以减少垃圾回收的频率。在Spring Boot项目的application.properties或application.yml中添加以下配置:
# 增加堆内存大小,示例中设置为2GB
java:
options: -Xms2g -Xmx2g
步骤3:选择合适的垃圾收集器
如果应用程序的性能问题与垃圾回收有关,可以考虑更改垃圾收集器。例如,使用G1垃圾收集器可以提供更可预测的停顿时间。在启动应用程序时,添加以下参数:
-Dspring.profiles.active=production -XX:+UseG1GC
步骤4:监控和分析GC日志
启用GC日志,并使用工具(如VisualVM、GCViewer)分析GC日志,以确保垃圾回收的行为是你预期的。你可以使用以下参数启用GC日志:
-XX:+PrintGC -XX:+PrintGCDetails -Xloggc:/path/to/gc.log
步骤5:线程管理
分析应用程序的线程使用情况,确保没有线程泄漏或过度创建线程。根据需要调整线程池的大小。
步骤6:代码优化
检查应用程序的代码,查找可能导致性能问题的部分。优化代码以减少对象创建、避免过度同步、减少循环次数等。
步骤7:内存泄漏检测
使用内存分析工具(如MAT、YourKit)检测内存泄漏问题。分析堆转储文件以查找未释放的对象引用。
步骤8:测试和监视
对应用程序进行全面的性能测试,模拟不同负载情况,确保性能改进是有效的。使用监视工具持续监控应用程序的性能,并根据需要进一步调整。
总之,JVM调优是一个迭代的过程,需要不断分析、测试和调整。在具体项目中,需要根据应用程序的性质和需求来选择和实施调优策略,以确保应用程序在高负载下能够稳定运行并具有良好的性能。
相关文章:

面试系列 - JVM内存模型和调优详解
目录 一、JVM内存模型 1. 程序计数器(Program Counter Register): 2.Java虚拟机栈(Java Virtual Machine Stacks): 3. 本地方法栈(Native Method Stack): 5. 方法区…...

JavaScript -【第一周】
文章来源于网上收集和自己原创,若侵害到您的权利,请您及时联系并删除~~~ JavaScript 介绍 变量、常量、数据类型、运算符等基础概念 能够实现数据类型的转换,结合四则运算体会如何编程。 体会现实世界中的事物与计算机的关系理解什么是数据并…...

高性能缓存 Caffeine 原理及实战
Caffeine 是基于Java 8 开发的、提供了近乎最佳命中率的高性能本地缓存组件,Spring5 开始不再支持 Guava Cache,改为使用 Caffeine。 1 算法原理 对于 Java 进程内缓存我们可以通过 HashMap 来实现。不过,Java 进程内存是有限的,…...

【算法】leetcode 105 从前序与中序遍历序列构造二叉树
题目 输入某二叉树的前序遍历和中序遍历的结果,请构建该二叉树并返回其根节点。 假设输入的前序遍历和中序遍历的结果中都不含重复的数字。 示例 1: Input: preorder [3,9,20,15,7], inorder [9,3,15,20,7] Output: [3,9,20,null,null,15,7]示例 2: Input: pr…...

11 | Spark计算数据文件中每行数值的平均值
需求:计算数据文件中的数值的平均值 背景: 你有一个数据文件,其中包含一系列数值,每行一个数值,数值之间用逗号分隔。你想使用Apache Spark分布式计算框架来读取数据文件中的数值并计算它们的平均值。功能要求: 通过Spark配置和上下文初始化Spark应用程序。从数据文件中…...

AI与游戏创新:深度学习的起跑枪声
《AI与游戏创新:深度学习的起跑枪声》 目录 引言AIGC定义与重要性AI在游戏中的应用AI推动游戏创新的可能途径AIGC的挑战与解决方案结论:AI是游戏行业的下一站 引言 AI(人工智能)正在全球范围内改变各个行业,游戏行…...
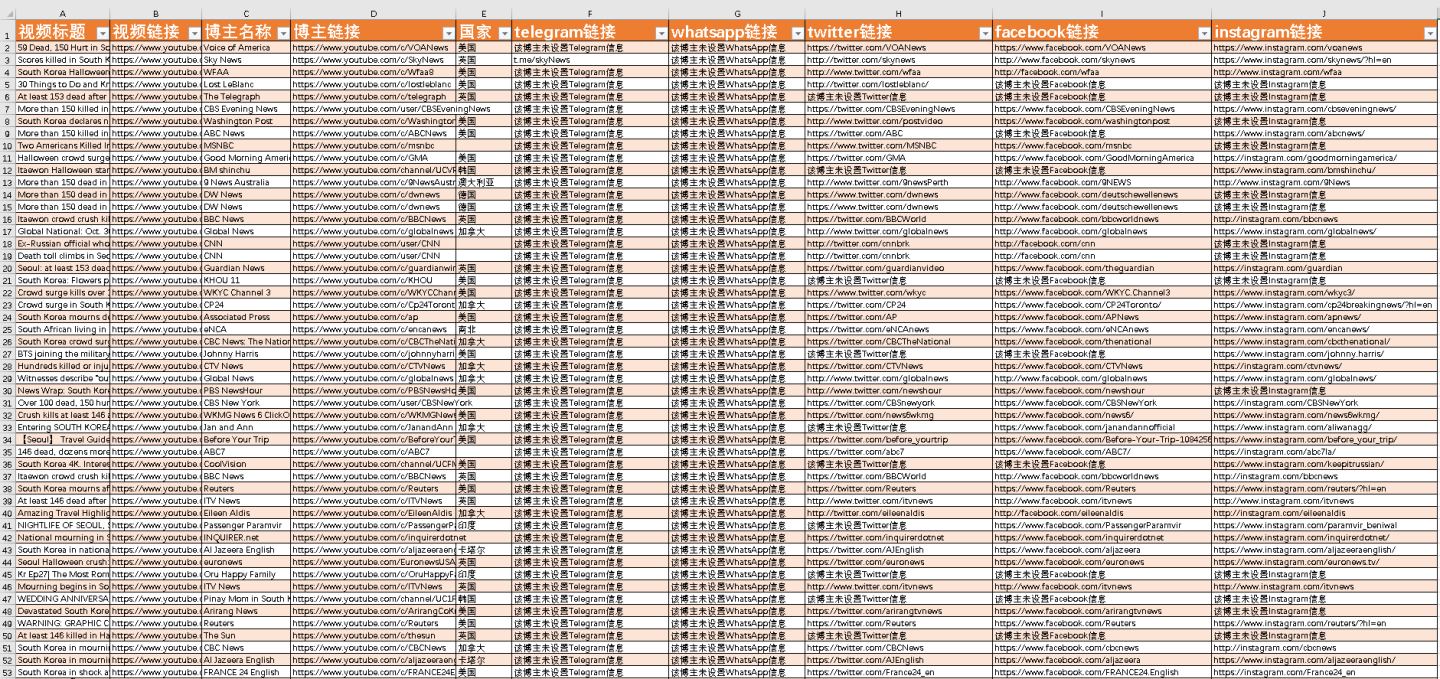
【GUI开发】用python爬YouTube博主信息,并开发成exe软件
文章目录 一、背景介绍二、代码讲解2.1 爬虫2.2 tkinter界面2.3 存日志 三、软件演示视频四、说明 一、背景介绍 你好,我是马哥python说,一名10年程序猿。 最近我用python开发了一个GUI桌面软件,目的是爬取相关YouTube博主的各种信息&#…...

7.6 函数的递归调用
直接调用: ### 1. 直接递归调用 直接递归调用是指一个函数直接调用自己。例如,计算阶乘的函数,可以使用递归方法: int factorial(int n) {if (n < 1) {return 1;}return n * factorial(n - 1); } 在这个例子中,f…...
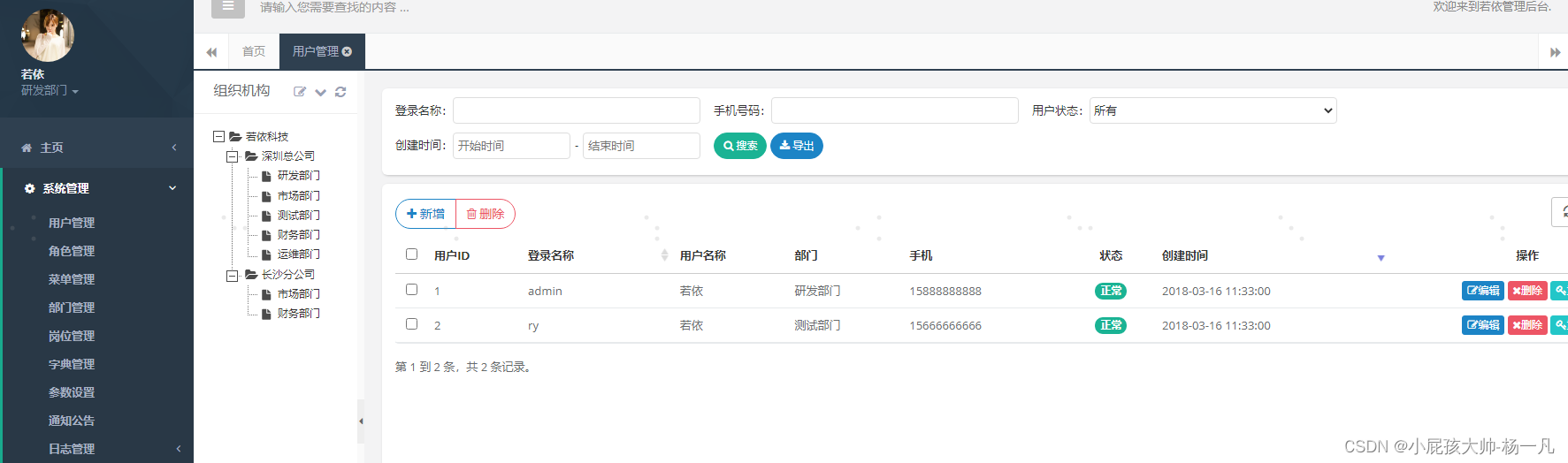
本地开机启动jar
1:首先有个可运行的jar包 本地以ruiyi代码为例打包 2:编写bat命令---命名为.bat即可 echo off java -jar D:\everyDay\test\RuoYi\target\RuoYi.jar 3:设置为开机自启动启动 快捷键winr----输入shell:startup---打开启动文档夹 把bat文件复…...
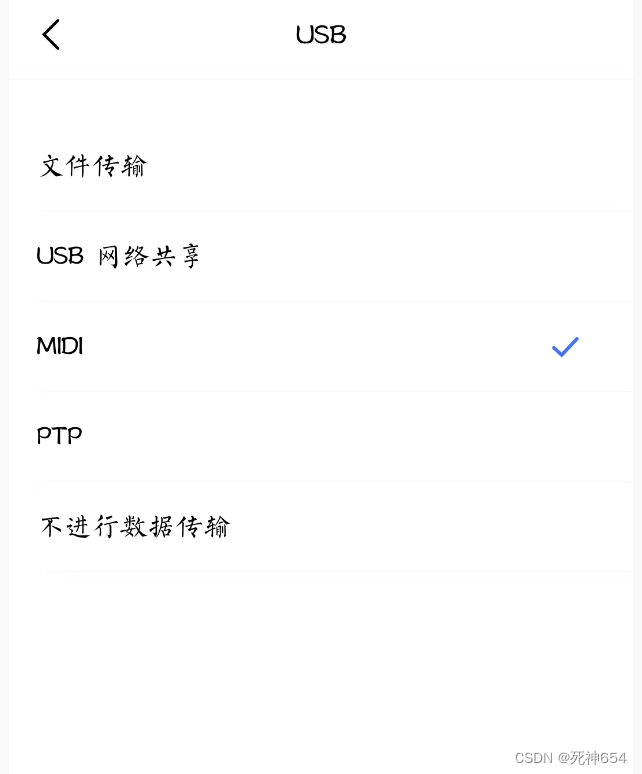
解决uniapp手机真机调试时找不到手机问题
1、检查 USB 调试是否开启 2、检查是否有选择 文件 传输 选项 3、如果上述都做了还找不到,可以看看开发者选项中的【USB设置】,把模式改为 MIDI 模式...

HarmonyOS应用开发者-----高级认证试题及答案
HarmonyOS应用开发者高级认证试题及答案 试题会不定时刷新,本试题仅供大家学习参考 【判断题】 2/2 HarmonyOS应用可以兼容OpenHarmony生态 正确(True)【判断题】 2/2 所有使用@Component修饰的自定义组件都支持onPageShow,onBackPress和onPageHide生命周期函数。 正确(True…...

R语言随机波动模型SV:马尔可夫蒙特卡罗法MCMC、正则化广义矩估计和准最大似然估计上证指数收益时间序列...
全文链接:http://tecdat.cn/?p31162 最近我们被客户要求撰写关于SV模型的研究报告,包括一些图形和统计输出(点击文末“阅读原文”获取完整代码数据)。 相关视频 本文做SV模型,选取马尔可夫蒙特卡罗法(MCMC)、正则化广…...
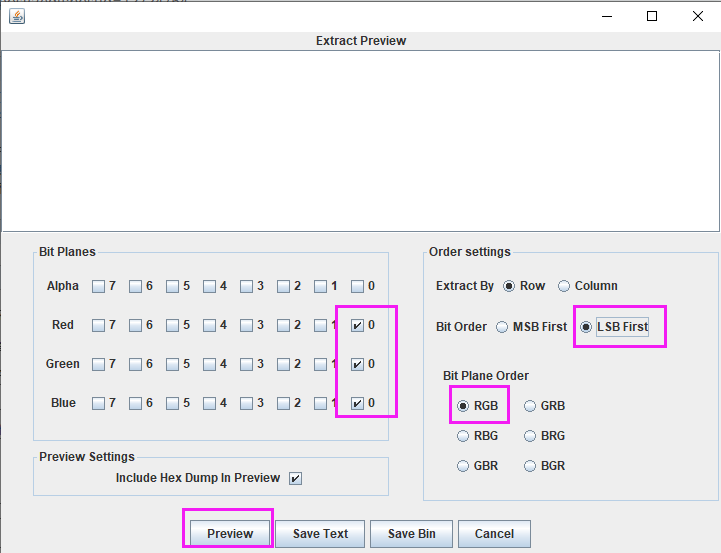
详细教程:Stegsolve的下载,jdk的下载、安装以及环境的配置
最近在学习隐写术,下载stegsolve 以及使用stegsolve倒腾了很久,避免朋友们和我一样倒腾了很久,希望此文可以帮到刚在学习隐写的朋友们(win7下使用stegsolve) 文章目录 一、下载stegsolve链接二、jdk的下载三、jdk的安装四、配置环境变量五、检…...
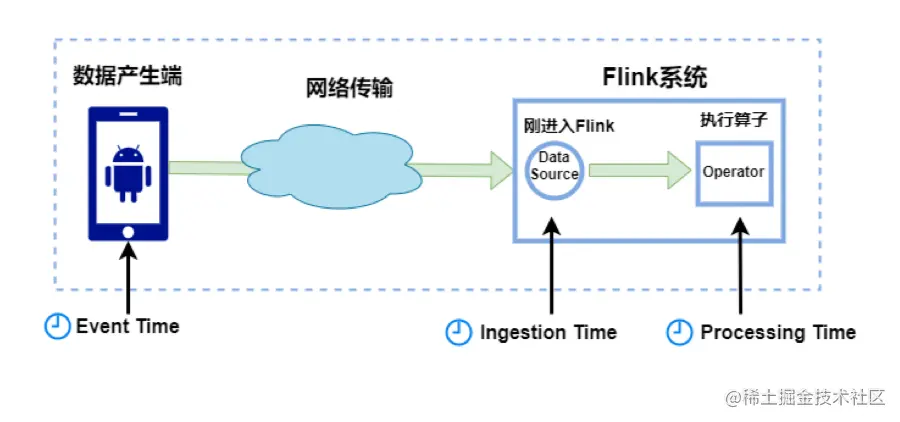
Watermark 是怎么生成和传递的?
分析&回答 Watermark 介绍 Watermark 本质是时间戳,与业务数据一样无差别地传递下去,目的是衡量事件时间的进度(通知 Flink 触发事件时间相关的操作,例如窗口)。 Watermark 是一个时间戳, 它表示小于该时间戳的…...

深度学习论文分享(八)Learning Event-Driven Video Deblurring and Interpolation
深度学习论文分享(八)Learning Event-Driven Video Deblurring and Interpolation 前言Abstract1 Introduction2 Motivation2.1 Physical Model of Event-based Video Reconstruction2.2 Spatially Variant Triggering Threshold 3 Proposed Methods3.1 …...

UI设计开发原则
一、一致性原则 坚持以用户体验为中心设计原则,界面直观、简洁,操作方便快捷,用户接触软件后对界面上对应的功能一目了然、不需要太多培训就可以方便使用本应用系统。 1、字体 保持字体及颜色一致,避免一套主题出现多个字体&am…...

Mac 如何判断下载Mac with Intel Chip 还是 Mac with Apple Chip
如下图,当我们在 Mac系统 下载客户端时,有两种选择:Mac with Intel Chip 、 Mac with Apple Chip 如何判断要下载哪一种? 需要判断本机Mac是在Inter芯片还是Apple芯片上运行的。方法如下: 点击屏幕左上角Apple标志&a…...

windows笔记本远程连接如何打开任务管理器?
参考素材: https://jingyan.baidu.com/article/8275fc86a97f5207a03cf6cd.html https://www.anyviewer.cn/how-to/ctrl-alt-delete-remote-desktop-6540.html 网上查了很多方法,都说ctrlaltend可以解决这个问题。 但是笔记本键盘上没有end键。 继续查了一…...
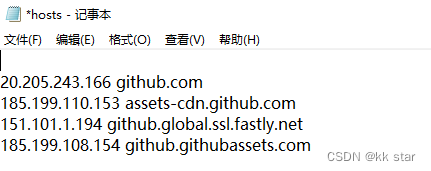
GitHub打不开解决方法——授人以渔
打不开GitHub的原因之一,DNS地址解析到了无法访问的ip。(为什么无法访问?) 1、打开GitHub看是哪个域名无法访问,F12一下 2、DNS解析看对应的域名目前哪个IP可以访问 DNS解析的网址: (1&#x…...

gRPC之数据压缩Snappy、zstd
文章目录 gRPC之数据压缩Snappy一、背景二、什么是snappy1. Snappy适合场景 三、demo: Go代码实现了一个snappy压缩格式的压缩器for grpc1. 这段代码怎么保证并发安全的? 四、什么是zstd五、 zstd和snappy有什么区别,如何选择?六、demo: Go代码实现了一个zstd压缩格…...

Linux链表操作全解析
Linux C语言链表深度解析与实战技巧 一、链表基础概念与内核链表优势1.1 为什么使用链表?1.2 Linux 内核链表与用户态链表的区别 二、内核链表结构与宏解析常用宏/函数 三、内核链表的优点四、用户态链表示例五、双向循环链表在内核中的实现优势5.1 插入效率5.2 安全…...

Swift 协议扩展精进之路:解决 CoreData 托管实体子类的类型不匹配问题(下)
概述 在 Swift 开发语言中,各位秃头小码农们可以充分利用语法本身所带来的便利去劈荆斩棘。我们还可以恣意利用泛型、协议关联类型和协议扩展来进一步简化和优化我们复杂的代码需求。 不过,在涉及到多个子类派生于基类进行多态模拟的场景下,…...

大语言模型如何处理长文本?常用文本分割技术详解
为什么需要文本分割? 引言:为什么需要文本分割?一、基础文本分割方法1. 按段落分割(Paragraph Splitting)2. 按句子分割(Sentence Splitting)二、高级文本分割策略3. 重叠分割(Sliding Window)4. 递归分割(Recursive Splitting)三、生产级工具推荐5. 使用LangChain的…...

DBAPI如何优雅的获取单条数据
API如何优雅的获取单条数据 案例一 对于查询类API,查询的是单条数据,比如根据主键ID查询用户信息,sql如下: select id, name, age from user where id #{id}API默认返回的数据格式是多条的,如下: {&qu…...

今日科技热点速览
🔥 今日科技热点速览 🎮 任天堂Switch 2 正式发售 任天堂新一代游戏主机 Switch 2 今日正式上线发售,主打更强图形性能与沉浸式体验,支持多模态交互,受到全球玩家热捧 。 🤖 人工智能持续突破 DeepSeek-R1&…...

k8s业务程序联调工具-KtConnect
概述 原理 工具作用是建立了一个从本地到集群的单向VPN,根据VPN原理,打通两个内网必然需要借助一个公共中继节点,ktconnect工具巧妙的利用k8s原生的portforward能力,简化了建立连接的过程,apiserver间接起到了中继节…...

SpringCloudGateway 自定义局部过滤器
场景: 将所有请求转化为同一路径请求(方便穿网配置)在请求头内标识原来路径,然后在将请求分发给不同服务 AllToOneGatewayFilterFactory import lombok.Getter; import lombok.Setter; import lombok.extern.slf4j.Slf4j; impor…...

Map相关知识
数据结构 二叉树 二叉树,顾名思义,每个节点最多有两个“叉”,也就是两个子节点,分别是左子 节点和右子节点。不过,二叉树并不要求每个节点都有两个子节点,有的节点只 有左子节点,有的节点只有…...

鸿蒙DevEco Studio HarmonyOS 5跑酷小游戏实现指南
1. 项目概述 本跑酷小游戏基于鸿蒙HarmonyOS 5开发,使用DevEco Studio作为开发工具,采用Java语言实现,包含角色控制、障碍物生成和分数计算系统。 2. 项目结构 /src/main/java/com/example/runner/├── MainAbilitySlice.java // 主界…...

关键领域软件测试的突围之路:如何破解安全与效率的平衡难题
在数字化浪潮席卷全球的今天,软件系统已成为国家关键领域的核心战斗力。不同于普通商业软件,这些承载着国家安全使命的软件系统面临着前所未有的质量挑战——如何在确保绝对安全的前提下,实现高效测试与快速迭代?这一命题正考验着…...