从零开始的Hadoop学习(五)| HDFS概述、shell操作、API操作
1. HDFS 概述
1.1 HDFS 产出背景及定义
1)HDFS 产生背景
随着数据量越来越大,在一个操作系统存不下所有的数据,那么就分配到更多的操作系统管理的磁盘中,但是不方便管理和维护,迫切 需要一种系统来管理多台机器上的文件,这就是分布式文件管理系统。 HDFS只是分布式文件管理系统中的一种。
2)HDFS定义
HDFS(Hadoop Distributed File System),它是一个文件系统,用于存储文件,通过目录树来定位文件: 其次,它是分布式的,由很多服务器联合起来实现其功能,集群中的服务器有各自的角色。
HDFS 的使用场景:适合一次写入,多次读出的场景。 一个文件经过创建写入和关闭之后就不需要改变。
1.2 HDFS 优缺点
HDFS优点
1)高容错性
- 数据自动保存多个副本。它通过增加副本的形式,提高容错性。
- 某一个副本丢失以后,它可以自动恢复。
2)适合处理大数据
- 数据规模:能够处理数据规模达到GB、TB、甚至BP级别的数据;
- 文件规模:能够处理百万规模以上的文件数量,数量相当之大。
3)可构建在廉价机器上,通过多副本机制,提高可靠性。
HDFS缺点
1)不适合低延时数据访问,比如毫秒级的存储数据,是做不到的。
2)无法高效的对大量小文件进行存储。
- 存储大量小文件的话,它会占用NameNode大量的内存来存储文件目录和块信息。这样是不可取的,因为NameNode的内存总是有限的;
- 小文件存储的寻址时间会超过读取时间,它违反了 HDFS 的设计目标。
3)不支持并发写入,文件随机修改。
- 一个文件只能有一个写,不允许多个线程同时写。
- 仅支持append(追加),不支持文件的随机修改。
1.3 HDFS 组成架构

1)NameNode(nn):就是Master,它是一个主管、管理者。
- (1)管理HDFS的名称空间;
- (2)配置副本策略;
- (3)管理数据块(Block)隐射信息;
- (4)处理客户端读写请求。
2)DataNode:就是Slave。NameNode下达命令,DataNode执行实际的操作。
- (1)存储实际的数据块;
- (2)执行数据块的读/写操作。
3)Client:就是客户端。
- (1)文件切分。文件上传HDFS的时候,Clinet将文件切分成一个一个的Block,然后进行上传;
- (2)与NameNode交互,获取文件的位置信息;
- (3)与DataNode交互,读取或者写入数据;
- (4)Client提供一些命令来管理HDFS,不如NameNode格式化;
- (5)Client可以通过一些命令来访问HDFS,比如对HDFS增删改操作;
4)Secondary NameNode:并非NameNode的热备。当NameNode挂掉的时候,它并不能马上替换NameNode并提供服务。
- (1)辅助NameNode,分组其工作量,比如定期合并Fsimage和Edits,并推送给NameNode;
- (2)在紧急情况下,可辅助恢复NameNode。
1.4 HDFS 文件块大小(面试重点)
HDFS中的文件在物理上是分块存储(Block),块的大小可以通过配置参数(dis.blocksize)来规定, 默认大小在Hadoop2.x/3.x版本中是128M,1.x版本中是64M。

思考:为什么块的大小不能设置太小,也不能设置太大?
- (1)HDFS的块设置太小,会增加寻址时间,程序一直在找块的开始位置;
- (2)如果块设置的太大,从磁盘传输数据的时间会明显大雨定位这个块开始位置所需的时间。导致程序在处理这块数据时,会非常慢。
总结:HDFS块的大小设置主要取决于磁盘传输速度。
2. HDFS的shell操作(开发重点)
2.1 基本语法
hadoop fs 具体命令 OR hdfs dfs具体命令。
2.2 命令大全
[atguigu@hadoop102 hadoop-3.1.3]$ bin/hadoop fs[-appendToFile <localsrc> ... <dst>][-cat [-ignoreCrc] <src> ...][-chgrp [-R] GROUP PATH...][-chmod [-R] <MODE[,MODE]... | OCTALMODE> PATH...][-chown [-R] [OWNER][:[GROUP]] PATH...][-copyFromLocal [-f] [-p] <localsrc> ... <dst>][-copyToLocal [-p] [-ignoreCrc] [-crc] <src> ... <localdst>][-count [-q] <path> ...][-cp [-f] [-p] <src> ... <dst>][-df [-h] [<path> ...]][-du [-s] [-h] <path> ...][-get [-p] [-ignoreCrc] [-crc] <src> ... <localdst>][-getmerge [-nl] <src> <localdst>][-help [cmd ...]][-ls [-d] [-h] [-R] [<path> ...]][-mkdir [-p] <path> ...][-moveFromLocal <localsrc> ... <dst>][-moveToLocal <src> <localdst>][-mv <src> ... <dst>][-put [-f] [-p] <localsrc> ... <dst>][-rm [-f] [-r|-R] [-skipTrash] <src> ...][-rmdir [--ignore-fail-on-non-empty] <dir> ...]
<acl_spec> <path>]][-setrep [-R] [-w] <rep> <path> ...][-stat [format] <path> ...][-tail [-f] <file>][-test -[defsz] <path>][-text [-ignoreCrc] <src> ...]
2.3 常用命令实操
2.3.1 准备工作
1)启动 Hadoop 集群(方便后续的测试)
[atguigu@hadoop102 hadoop-3.1.3]$ sbin/start-dfs.sh
[atguigu@hadoop103 hadoop-3.1.3]$ sbin/start-yarn.sh
2)-help:输出这个命令参数
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -help rm
3)创建/sanguo 文件夹
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -mkdir /sanguo
2.3.2 上传
1)-moveFromLocal:从本地剪切粘贴到 HDFS
[atguigu@hadoop102 hadoop-3.1.3]$ vim shuguo.txt
输入:
shuguo[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -moveFromLocal ./shuguo.txt /sanguo
2)-copyFormLocal:从本地文件系统中拷贝文件到 HDFS 路径去
[atguigu@hadoop102 hadoop-3.1.3]$ vim weiguo.txt
输入:
weiguo[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -copyFromLocal weiguo.txt /sanguo
3)-put:等同于 copyFromLocal,生产环境更习惯用 put
[atguigu@hadoop102 hadoop-3.1.3]$ vim wuguo.txt
输入:
wuguo[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -put ./wuguo.txt /sanguo
4)-appendToFile:追加一个文件到已经存在的文件末尾
[atguigu@hadoop102 hadoop-3.1.3]$ vim liubei.txt
输入:
liubei[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -appendToFile liubei.txt /sanguo/shuguo.txt
2.3.3 下载
1)-copyToLocal:从HDFS 拷贝到本地
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -copyToLocal /sanguo/shuguo.txt ./
2)-get:等同于 copyToLocal,生产环境更习惯用 get
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -get /sanguo/shuguo.txt ./shuguo2.txt
2.3.4 HDFS 直接操作
1)-ls:现实目录信息
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -ls /sanguo
2)-cat:显示文件内容
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -cat /sanguo/shuguo.txt
3)-chgrp、-chmod、-chown:Linux 文件系统中的用法一样,修改文件所属权限
4)-mkdir:创建路径
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -mkdir /jinguo
5)-cp:从HDFS的一个路径拷贝到HDFS的另一个路径
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -cp /sanguo/shuguo.txt /jinguo
6)-mv:在 HDFS 目录中移动文件
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -mv /sanguo/wuguo.txt /jinguo
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -mv /sanguo/weiguo.txt /jinguo
7)-tail:显示一个文件的末尾 1kb 的数据
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -tail /jinguo/shuguo.txt
8)-rm:删除文件或文件夹
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -rm /sanguo/shuguo.txt
9)-rm -r:递归删除目录及目录里面内容
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -rm -r /sanguo
10)-du 统计文件夹的大小信息
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -du -s -h /jinguo
27 81 /jinguo[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -du -h /jinguo
14 42 /jinguo/shuguo.txt
7 21 /jinguo/weiguo.txt
6 18 /jinguo/wuguo.tx
11)-setrep:设置 HDFS 中文件的副本数量
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -setrep 10 /jinguo/shuguo.txt

这里设置的副本数只是记录在 NameNode 的元数据中,是否真的会有那么多副本,还得看 DataNode 的数量。因为目前只有3台设备,最多也就3个副本,只有节点数增加到10台时,副本数才能达到10。
3. HDFS 的 API操作
3.1 客户端环境准备
1)找到资源包路径下的 Windows 依赖文件夹,拷贝 hadoop-3.1.0 到非中文路径(比如d:\)。
2)配置 HADOOP_HOME 环境变量

3)配置 Path 环境变量。
如果环境变量不起作用,可以重启电脑试试。

验证 Hadoop 环境变量是否正常。双击 winutils.exe,如果报如下错误。说明缺少微软运行库(正版系统往往有这个问题)。在资料包里面有对应的微软运行库安装包双击安装即可。

4)在 IDEA 中创建一个 Maven 工程 HdfsClientDemo,并凹入相应的依赖坐标+日志添加
<dependencies><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>3.1.3</version></dependency><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>4.12</version></dependency><dependency><groupId>org.slf4j</groupId><artifactId>slf4j-log4j12</artifactId><version>1.7.30</version></dependency>
</dependencies>
在项目的 src/main/resources 目录下,新建一个文件,命名为 “log4j.properties”,在文件中填入
log4j.rootLogger=INFO, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/spring.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
5)创建包名:com.atguigu.hdfs
6)创建 HdfsClient 类
package com.atguigu.hdfs;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.junit.Test;import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;/*** @author WangTingWei* @Date 2023/8/31 10:01* @description 客户端代码常用套路* 1、获取一个客户端对象* 2、执行相关的操作命令* 3、关闭资源* HDFS zookeeper*/
public class HdfsClient {@Testpublic void testMkdirs() throws URISyntaxException, IOException, InterruptedException {// 1.获取文件系统Configuration configuration = new Configuration();// 用户String user = "atguigu";FileSystem fs = FileSystem.get(new URI("hdfs://hadoop102:8020"), configuration,user);// 2.创建目录fs.mkdirs(new Path("/xiyou/huaguoshan"));// 3.关闭资源fs.close();}
}
7)执行程序
客户端去操作 HDFS 时,是有一个用户身份的。默认情况下,HDFS 客户端 API 会从采用 Windows 默认用户访问 HDFS,会报权限异常错误。所以在访问 HDFS时,一定要配置用户。
package com.atguigu.hdfs;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;/*** @author WangTingWei* @Date 2023/8/31 10:01* @description 客户端代码常用套路* 1、获取一个客户端对象* 2、执行相关的操作命令* 3、关闭资源* HDFS zookeeper*/
public class HdfsClient {private FileSystem fs;@Beforepublic void init() throws URISyntaxException, IOException, InterruptedException {// 连接的集群nn地址URI uri = new URI("hdfs://hadoop102:8020");Configuration configuration = new Configuration();// 用户String user = "atguigu";fs = FileSystem.get(uri,configuration,user);}@Afterpublic void close() throws IOException {fs.close();}@Testpublic void testMkdirs() throws URISyntaxException, IOException, InterruptedException {fs.mkdirs(new Path("/xiyou/huaguoshan1"));}
}
3.2 HDFS 的API 案例实操
3.2.1 HDFS 文件上传(测试参数优先级)
1)编写源代码
/*** 上传* 参数优先级* 代码里面的配置 > 在项目资源目录下的配置文件 > hdfs-site.xml > hdfs-default.xml * @throws IOException*/@Testpublic void testPut() throws IOException {//参数一:表示删除原数据;参数二:是否允许覆盖;参数三:原数据路径;参数四:目的地路径fs.copyFromLocalFile(true,true,new Path("D:\\sunwukong.txt"),new Path("hdfs://hadoop102/xiyou/huaguoshan"));}
2)将 hdfs-site.xml 拷贝到项目的 resource 资源目录下
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?><configuration><property><name>dfs.replication</name><value>1</value></property>
</configuration>
3)参数优先级(从高到低)
- (1)客户端代码中设置的值
- (2)ClassPath下的用户自定义配置文件
- (3)然后是服务器的自定义配置(xxx-site.xml)
- (4)服务器的默认配置(xxx-default.xml)
3.2.2 HDFS 文件下载
/*** 下载*/@Testpublic void testGet() throws IOException {//delSrc 是否将原文件删除;要下载的文件路径;文件下载到的路径;useRawLocalFileSystem 是否开启文件校验fs.copyToLocalFile(true,new Path("hdfs://hadoop102/xiyou/huaguoshan"),new Path("D:\\"),true);}
}3.2.3 HDFS 文件更名和移动
/*** 文件更名和移动*/@Testpublic void testRename() throws IOException {// 原文件路径;目标文件路径// 对文件名称的修改fs.rename(new Path("/output/_SUCCESS"),new Path("/output/SUCCESS"));// 文件的移动和更名fs.rename(new Path("/output/SUCCESS"),new Path("/SU"));}
3.2.4 HDFS 删除文件和目录
/*** 文件删除*/@Testpublic void testRm() throws IOException {// 要删除的路径;是否递归删除fs.delete(new Path("/jinguo"), true);}
3.2.5 HDFS 文件详情查看
查看文件名称、权限、长度、块信息
/*** 获取文件信息详情*/@Testpublic void fileDetail() throws IOException {// 获取所有文件信息RemoteIterator<LocatedFileStatus> listFiles = fs.listFiles(new Path("/"), true);// 遍历文件while (listFiles.hasNext()){LocatedFileStatus fileStatus = listFiles.next();System.out.println("========" + fileStatus.getPath() + "=========");System.out.println(fileStatus.getPermission());System.out.println(fileStatus.getOwner());System.out.println(fileStatus.getGroup());System.out.println(fileStatus.getLen());System.out.println(fileStatus.getModificationTime());System.out.println(fileStatus.getReplication());System.out.println(fileStatus.getBlockSize());System.out.println(fileStatus.getPath().getName());// 获取块信息BlockLocation[] blockLocations = fileStatus.getBlockLocations();System.out.println(Arrays.toString(blockLocations));}}
3.2.6 HDFS 文件和文件夹判断
@Testpublic void testListStatus() throws IOException, InterruptedException, URISyntaxException{// 判断是文件还是文件夹FileStatus[] listStatus = fs.listStatus(new Path("/"));for (FileStatus fileStatus : listStatus) {// 如果是文件if (fileStatus.isFile()) {System.out.println("f:"+fileStatus.getPath().getName());}else {System.out.println("d:"+fileStatus.getPath().getName());}}}
相关文章:
从零开始的Hadoop学习(五)| HDFS概述、shell操作、API操作
1. HDFS 概述 1.1 HDFS 产出背景及定义 1)HDFS 产生背景 随着数据量越来越大,在一个操作系统存不下所有的数据,那么就分配到更多的操作系统管理的磁盘中,但是不方便管理和维护,迫切 需要一种系统来管理多台机器上的…...
【spark】序列化和反序列化,transient关键字的使用
序列化 Spark是基于JVM运行的进行,其序列化必然遵守Java的序列化规则。 序列化就是指将一个对象转化为二进制的byte流(注意,不是bit流),然后以文件的方式进行保存或通过网络传输,等待被反序列化读取出来。…...
)
2.4 Vector<T> 动态数组(随机访问迭代器)
C自学精简教程 目录(必读) 该 Vector 版本特点 这里的版本主要是使用模板实现、支持随机访问迭代器,支持std::sort等所有STL算法。(本文对随机迭代器的支持参考了 复旦大学 大一公共基础课C语言的一次作业) 随机访问迭代器的实现主要是继承std::iterator<std:…...

Ubuntu下运行QEMU模拟riscv64跑Debian
1.安装QEMU 下载地址: https://www.qemu.org/download/ 建议选择稳定版本,下载后解压,然后make wget https://download.qemu.org/qemu-8.0.3.tar.xz tar xjvf qemu-8.0.3.tar.xz cd qemu-8.0.3 ./configure --enable-kvm --enable-virtfs …...

移动基站ip的工作原理
原理介绍 Basic Principle 先说一下概念,大家在不使用 WIFI 网络的时候,使用手机通过运营商提供的网络进行上网的时候,目前都是在用户端使用私有IP,然后对外做 NAT 转换,这样的情况就导致大家统一使用一些 IP 段进行访…...

Kubernetes技术--使用kubeadm搭建高可用的K8s集群(贴近实际环境)
1.高可用k8s集群架构(多master) 2.安装硬件要求 一台或多台机器,操作系统 CentOS7.x-86_x64 硬件配置:2GB或更多RAM,2个CPU或更多CPU,硬盘30GB或更多 注: 这里属于教学环境,所以使用三台虚拟机模拟实现。 3.部署规划 4.部署前准备 (1).关闭防火墙 systemctl stop fi…...

【Linux】文件
Linux 文件 什么叫文件C语言视角下文件的操作文件的打开与关闭文件的写操作文件的读操作 & cat命令模拟实现 文件操作的系统接口open & closewriteread 文件描述符进程与文件的关系重定向问题Linux下一切皆文件的认识文件缓冲区缓冲区的刷新策略 stuout & stderr 什…...

Android OTA 相关工具(六) 使用 lpmake 打包生成 super.img
我在 《Android 动态分区详解(二) 核心模块和相关工具介绍》 介绍过 lpmake 工具,这款工具用于将多个分区镜像打包生成一个 Android 专用的动态分区镜像,一般称为 super.img。Android 编译时,系统会自动调用 lpmake 并传入相关参数来生成 sup…...

信创环境 Phytium S2500 虚拟机最大内存规格测试
在 ARM 架构中,"IPA" 通常指的是 "Instruction Set Architecture"(指令集架构),arm环境的虚拟机支持的最大内存规格与母机上内存多少无关,由arm本身的ipa size决定,ipa size 可以理解为虚拟机的物理地址空间,kernel5.4.32中ipa默认是44bits(16T si…...

新建工程——第一个S32DS工程
之前的"测试开发板"章节 测试开发板——第一个AutoSAR程序,使用了一个 demo 工程,不管是裸机程序还是 AutoSAR 程序,那都是别人已经创建好的工程。本节来介绍如何来创建自己的工程,本节介绍如何创建一个 S32DS 的工程,点亮开发板上的 LED 我们从官方提供的例程…...

基于Open3D的点云处理16-特征点匹配
点云配准 将点云数据统一到一个世界坐标系的过程称之为点云配准或者点云拼接。(registration/align) 点云配准的过程其实就是找到同名点对;即找到在点云中处在真实世界同一位置的点。 常见的点云配准算法: ICP、Color ICP、Trimed-ICP 算法…...
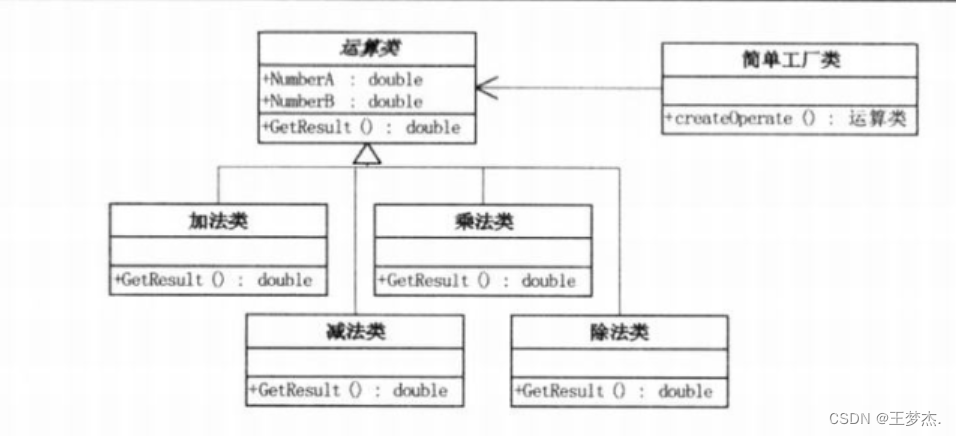
设计模式—简单工厂
目录 一、前言 二、简单工厂模式 1、计算器例子 2、优化后版本 3、结合面向对象进行优化(封装) 3.1、Operation运算类 3.2、客户端 4、利用面向对象三大特性(继承和多态) 4.1、Operation类 4.2、加法类 4.3、减法类 4…...
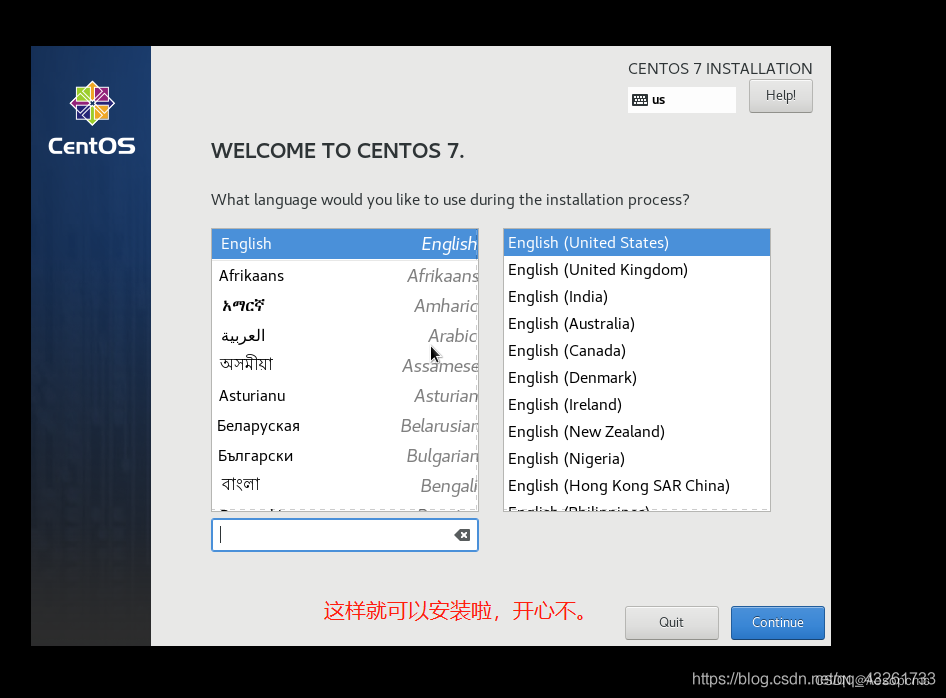
真机安装Linux Centos7
准备工具: 8G左右U盘最新版UltraISOCentOS7光盘镜像 操作步骤 下载镜像 地址:http://isoredirect.centos.org/centos/7/isos/x86_64/ 安装刻录工具UltraISO,刻录镜像到U盘 ① 选择ISO镜像文件 ② 写入磁盘镜像,在这里选择你的U盘…...
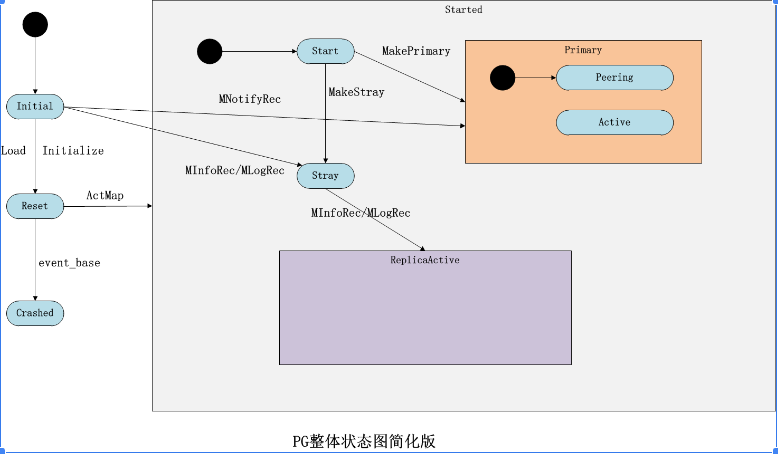
ceph peering机制-状态机
本章介绍ceph中比较复杂的模块: Peering机制。该过程保障PG内各个副本之间数据的一致性,并实现PG的各种状态的维护和转换。本章首先介绍boost库的statechart状态机基本知识,Ceph使用它来管理PG的状态转换。其次介绍PG的创建过程以及相应的状…...

Java | File类
目录: File类File类中常用的方法:boolean exists( ) :判断此 文件/目录 是否存在boolean createNewFile( ) :创建一个文件boolean mkdir( ) :创建 “单层” 目录/文件夹boolean mkdirs( ) :创建 “多层” 目…...

数学建模之灰色预测
灰色预测(Grey Forecasting)是一种用于时间序列数据分析和预测的方法,通常用于处理具有较少历史数据的情况或者数据不够充分的情况。它是一种非常简单但有效的方法,基于灰色系统理论,用来估计未来的趋势。 以下是灰色…...

03_nodejd_npm install报错
npm install报错 npm ERR! code ERESOLVE npm ERR! ERESOLVE unable to resolve dependency tree npm ERR! npm ERR! While resolving: 5kcrm11.0.0 npm ERR! Found: vue2.5.17 npm ERR! node_modules/vue npm ERR! vue"2.5.17" from the root project npm ERR! np…...

three.js(二):webpack + three.js + ts
用webpackts 开发 three.js 项目 webpack 依旧是主流的模块打包工具;ts和three.js 是绝配,three.js本身就是用ts写的,ts可以为three 项目提前做好规则约束,使项目的开发更加顺畅。 1.创建一个目录,初始化 npm mkdir demo cd de…...
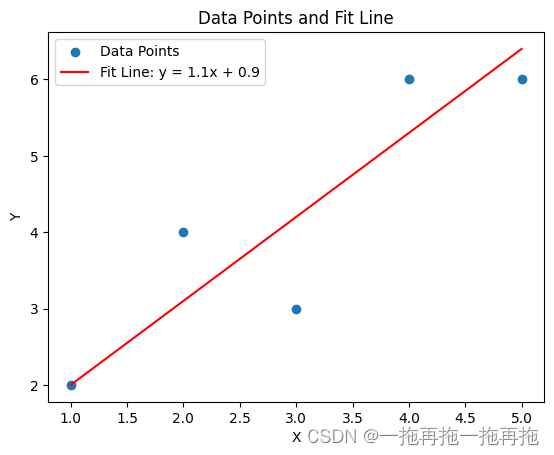
最小二乘法处理线性回归
最小二乘法是一种数学优化技术,用于查找最适合一组数据点的函数。 该方法主要用于线性回归分析,当然,也可用于非线性问题。 开始之前,我们先理解一下什么是回归。 回归:回归是一种监督学习算法,用于建模和…...

ModbusCRC16校验 示例代码
作者: Herman Ye Galbot Auromix 测试环境: Ubuntu20.04 更新日期: 2023/08/30 注1: Auromix 是一个机器人爱好者开源组织。 注2: 本文在更新日期经过测试,确认有效。 笔者出于学习交流目的, 给…...

第19节 Node.js Express 框架
Express 是一个为Node.js设计的web开发框架,它基于nodejs平台。 Express 简介 Express是一个简洁而灵活的node.js Web应用框架, 提供了一系列强大特性帮助你创建各种Web应用,和丰富的HTTP工具。 使用Express可以快速地搭建一个完整功能的网站。 Expre…...

Linux 文件类型,目录与路径,文件与目录管理
文件类型 后面的字符表示文件类型标志 普通文件:-(纯文本文件,二进制文件,数据格式文件) 如文本文件、图片、程序文件等。 目录文件:d(directory) 用来存放其他文件或子目录。 设备…...

dedecms 织梦自定义表单留言增加ajax验证码功能
增加ajax功能模块,用户不点击提交按钮,只要输入框失去焦点,就会提前提示验证码是否正确。 一,模板上增加验证码 <input name"vdcode"id"vdcode" placeholder"请输入验证码" type"text&quo…...

2021-03-15 iview一些问题
1.iview 在使用tree组件时,发现没有set类的方法,只有get,那么要改变tree值,只能遍历treeData,递归修改treeData的checked,发现无法更改,原因在于check模式下,子元素的勾选状态跟父节…...

Mac软件卸载指南,简单易懂!
刚和Adobe分手,它却总在Library里给你写"回忆录"?卸载的Final Cut Pro像电子幽灵般阴魂不散?总是会有残留文件,别慌!这份Mac软件卸载指南,将用最硬核的方式教你"数字分手术"࿰…...

Psychopy音频的使用
Psychopy音频的使用 本文主要解决以下问题: 指定音频引擎与设备;播放音频文件 本文所使用的环境: Python3.10 numpy2.2.6 psychopy2025.1.1 psychtoolbox3.0.19.14 一、音频配置 Psychopy文档链接为Sound - for audio playback — Psy…...

2025盘古石杯决赛【手机取证】
前言 第三届盘古石杯国际电子数据取证大赛决赛 最后一题没有解出来,实在找不到,希望有大佬教一下我。 还有就会议时间,我感觉不是图片时间,因为在电脑看到是其他时间用老会议系统开的会。 手机取证 1、分析鸿蒙手机检材&#x…...

sipsak:SIP瑞士军刀!全参数详细教程!Kali Linux教程!
简介 sipsak 是一个面向会话初始协议 (SIP) 应用程序开发人员和管理员的小型命令行工具。它可以用于对 SIP 应用程序和设备进行一些简单的测试。 sipsak 是一款 SIP 压力和诊断实用程序。它通过 sip-uri 向服务器发送 SIP 请求,并检查收到的响应。它以以下模式之一…...

【笔记】WSL 中 Rust 安装与测试完整记录
#工作记录 WSL 中 Rust 安装与测试完整记录 1. 运行环境 系统:Ubuntu 24.04 LTS (WSL2)架构:x86_64 (GNU/Linux)Rust 版本:rustc 1.87.0 (2025-05-09)Cargo 版本:cargo 1.87.0 (2025-05-06) 2. 安装 Rust 2.1 使用 Rust 官方安…...

Vue 模板语句的数据来源
🧩 Vue 模板语句的数据来源:全方位解析 Vue 模板(<template> 部分)中的表达式、指令绑定(如 v-bind, v-on)和插值({{ }})都在一个特定的作用域内求值。这个作用域由当前 组件…...