实训笔记8.28
实训笔记8.28
- 8.28笔记
- 一、大数据计算场景主要分为两种
- 1.1 离线计算场景
- 1.2 实时计算场景
- 二、一般情况下大数据项目的开发流程
- 2.1 数据采集存储阶段
- 2.2 数据清洗预处理阶段
- 2.3 数据统计分析阶段
- 2.4 数据挖掘预测阶段
- 2.5 数据迁移阶段
- 2.6 数据可视化阶段
- 三、纯大数据离线计算项目
- 3.1 预备知识
- 3.1.1 电商网站的概念
- 3.1.2 什么是用户的行为日志数据以及用户的行为数据是怎么产生的
- 3.1.3 用户行为日志数据的组成(记录哪些数据)
- 3.2 项目的开发背景和意义
- 3.3 项目的数据格式和数据来源问题
- 3.3.1 我们项目记录的用户行为格式如下
- 3.4 项目的开发流程和技术选项
- 3.5 项目的统计分析的指标
- 3.5.1 从终端纬度
- 3.5.2 从用户纬度
- 3.5.3 从地理纬度
- 3.5.4 从时间纬度
- 3.5.5 从来源纬度
- 3.6 项目的前置阶段--数据的来源和产生问题
8.28笔记
一、大数据计算场景主要分为两种
1.1 离线计算场景
数据产生之后,不是立马处理数据,而是先把数据存放起来,积攒到一定的程度之后统一的进行计算处理操作
适用于我们的数据或者需求对时间要求不高的场景下,要求一个小时、一天、一周、一个月…出一次结果
Hadoop技术、Spark Core、Spark SQL技术
1.2 实时计算场景
数据产生之后,需要立马处理数据,不能等待
适用于我们业务需求对时间要求很高的场景,要求几毫秒或者几百毫秒之间立马算出结果
Spark Streaming、Flink、Storm技术
Hadoop计算因为它的架构设计,因此只能做离线计算;Spark基于内存进行运算的,因此Spark技术既可以胜任离线计算,也可以去做实时计算(不精);Flink/storm技术专门为实时计算设计的
图计算、算法预测等等…
【注】再去进行大数据项目开发时,不是只使用一个技术完成的,而是使用一系列技术完成项目的开发 大数据项目当中,使用一系列技术完成项目开发,技术和技术之间我们是有版本对应问题的,大数据技术主要有两种发行版本: Apache版本:开源免费,如果整合多个技术,需要自己整合(版本的对应关系、技术的配置等等) CDH版本:收费的,把常用的技术的版本关系全部给配置好了,技术配置要比apache简单。
二、一般情况下大数据项目的开发流程
2.1 数据采集存储阶段
【注意】数据得有一个产生的过程,数据产生一般不属于大数据环节
将需要使用大数据处理的数据,先使用数据采集技术将数据采集到大数据环境下进行持久化、海量化的保存。
2.2 数据清洗预处理阶段
采集存储的数据并不是都是有价值的数据(价值密度低),可能存在很多的错误的、缺失的、异常的数据,数据需要清洗预处理,清洗的目的是把无用的数据过滤掉,预处理的目的是为了将数据的格式统一起来,便于我们后期的统计分析。
2.3 数据统计分析阶段
从清洗预处理完成的时候基础上对数据进行聚合汇总,统计一些数据中隐含的一些价值信息
2.4 数据挖掘预测阶段
在统计分析的结果之上,可以预测或者继续深入挖掘数据中的更深层次的含义 一般使用到大数据算法(算法工程师需要做的事情 大数据开发有区别的)
2.5 数据迁移阶段
将统计分析的结果迁移到非大数据环境,为后期的操作做准备
2.6 数据可视化阶段
将统计分析完成的结果指标以可视化图表(柱状图、折线图)的形式进行展示。严格意义上来说数据可视化也不是大数据工程师需要做的事情。
三、纯大数据离线计算项目
电商网站用户行为日志分析平台,电信用户通话数据分析平台
电商网站用户行为日志分析平台项目主要是对电商网站产生的用户行为日志数据进行采集存储、清洗预处理、统计分析、数据可视化展示的。
3.1 预备知识
3.1.1 电商网站的概念
专门用来进行网站购物的平台,大数据最开始使用最广泛、最成熟的就是电商网站。项目主要针对的白龙马电商购物网站–公司的子公司
3.1.2 什么是用户的行为日志数据以及用户的行为数据是怎么产生的
用户行为数据不管什么网站都会有用户的行为数据记录,行为数据指的是用户在网站当中进行的一系列动作,背后都会触发一些程序记录用户的行为数据。用户行为数据我们会通过程序一般都记录到日志文件当中
用户行为数据基本都是源源不断的产生的(7*24小时不停止的产生)
网站的用户行为数据记录不是大数据开发工程师的事,而是软件开发人员的工作(前端、后端工作人员) 无非就是产生数据的时候需要和大数据开发人员沟通记录用户的哪些数据而已
3.1.3 用户行为日志数据的组成(记录哪些数据)
-
用户的系统属性信息:用户使用的浏览器信息、用户使用的操作系统、用户的IP地址等等
-
用户的访问信息:用户触发的行为之后访问的网站信息\
-
用户的来源信息:用户行为触发之后访问的网站信息是从哪个网站过来的
-
点击的产品信息:点击的商品或者连接对应的产品的详细信息可以记录的 点击产品的时候,可以从数据库查询商品的详细信息
-
用户的个人信息:点击网站某一个连接的时候,如果你登录了的话,前端请求的时候,会把用户的标识带上,后端可以根据用户标识去查询你在网站注册的信息(用户的性别、出生年月、用户的昵称、手机号、实名认证信息等等)
-
【补充】网站或者软件的组成
-
前端(界面)
- 作用
负责和用户进行交互的-
技术
-
web网站
html/css/js vue/recat/angular
-
微信小程序
wxml/wxss/js/json
-
手机app软件
uniapp、c语言的网站制作技术,Object-C
-
PC端软件
Java GUI、python、C语言等等界面制作框架
-
-
后端
- 作用
- 负责和前端之间进行交互(接受前端请求、响应前端数据)
- 处理前端所需的业务逻辑(需要连接数据库)
- 技术
- 比较简单的后端技术:nodejs、php(web全栈开发工程师)
- 比较成熟的后端技术:JavaEE(Servelt/JSP、SSM框架、SpringBoot)、Python(不常用)、C/C++
- 作用
-
数据库
-
作用
负责进行数据的保存的
-
技术
- 存储结构化数据的数据库:MySQL oracle、SQL Server
- 存储临时性缓存数据的数据库:Redis
- 存储非结构化或者文档数据:mongodb
-
-
3.2 项目的开发背景和意义
背景:对于一个电商网站而言,大数据统计分析是非常有必要的,通过大数据的统计分析,我们可以得到很多和网站运营发展有关的指标信息。
用户行为数据(可以从不同的纬度进行统计分析)
3.3 项目的数据格式和数据来源问题
《白龙马电商用户行为日志分析平台》数据来源于网站记录的用户行为日志数据,日志数据我们是通过电商网站内嵌的埋点程序以及后端程序记录的。(埋点程序就是指的是网站的一些”暗箱“操作) 来源问题一般我们知道即可,不需要我们自己去完成,来源一般都是软件开发人员完成的。 项目的数据必然是7*24小时不间断产生的
3.3.1 我们项目记录的用户行为格式如下
149.74.183.133 - - 2018-09-24 19:38:17 "GET https://www.bailongma.com/register HTTP/1.0" 300 72815 https://www.bailongma.com/item/a Windows Internet Explorer Tridentwindows 广西 22.48 108.19 39
上面就是我们网站触发了某些行为(点击、浏览等等),记录的一条完整的用户行为数据(每一个字段之间以空格分割的):
149.74.183.133 用户的IP地址(ip可以统计网站的访客数量)
-- 个字段 两个字段一个代表用户的邮箱,一个代表用户的标识 (都是-- 代表的是没有记录)
2018-09-24 19:38:17 两个字段 一个代表日期 一个代表时间 用户行为触发时间 "
GET https://www.bailongma.com/register HTTP/1.0" 三个字段代表用户行为触发之后访问的网站,请求方法 请求URL 请求的协议
300 请求网站给的响应状态码 1xx 2xx(请求成功) 3xx(重定向,请求成功) 4xx(请求失败 404 前端的问题) 5xx(请求失败 后端代码的问题)
72815 请求网站给我们的响应字节数
https://www.bailongma.com/item/a 请求网站对应来源网站
Windows Internet Explorer Tridentwindows n个字段组成的(不确定)代表的是浏览器和操作系统信息
广西 用户请求地址
22.48 用户请求网站时所处的纬度
108.19 用户请求网站时所处的经度
39 用户的年龄信息
用户的系统属性信息、用户信息、访问信息、来源信息
3.4 项目的开发流程和技术选项
本次我们项目主要分为五个阶段开完成:数据采集存储阶段、数据清洗预处理阶段、数据统计分析阶段、数据迁移导出阶段、数据可视化阶段、任务调度阶段。

3.5 项目的统计分析的指标
3.5.1 从终端纬度
不同浏览器的用户使用量
3.5.2 从用户纬度
不同年龄段用户访问量
网站的独立访客数
网站的新老用户数量
3.5.3 从地理纬度
不同省份用户的访问量
3.5.4 从时间纬度
每一年用户的访问量
每一月用户的访问量
每天/每小时用户的访问量
不同季度的用户访问量
3.5.5 从来源纬度
网站站内和站外流量的对比
3.6 项目的前置阶段–数据的来源和产生问题
严格意义上来说不属于大数据环节的一部分,但是如果没有这个阶段,那么大数据就无从谈起
《白龙马电商用户行为日志分析平台》数据来源于我们网站的埋点程序,当用户在白龙马电商网站的界面上触发了某种动作(浏览、点击、鼠标的移入等等),网站的后端会把本次用户的行为以数据的形式记录到一个日志文件中。 149.74.183.133 - - 2018-09-24 19:38:17 “GET https://www.bailongma.com/register HTTP/1.0” 300 72815 https://www.bailongma.com/item/a Windows Internet Explorer Tridentwindows 广西 22.48 108.19 39
只要电商网站不关闭,那么数据源源不断的产生到日志文件当中。意味着网站的用户行为数据是7*24小时源源不断的会记录的。
【问题】白龙马电商网站是公司的内部产品,只有公司人员能使用,大家无法使用。如果我们要做这个项目,因为我们没有产生的数据的网站。
虽然我们没有网站,但是我们有网站以前产生的脱敏数据,因此我们就可以基于以前产生的脱敏数据,模拟数据产生的过程 只需要按照数据的格式产生一批和脱敏数据格式一致的数据即可。产生的时候增加一点随机性(每分钟产生100条或者每隔10秒产生20条数据)。
package com.sxuek;import java.io.*;
import java.text.SimpleDateFormat;
import java.util.*;/*** 专门用来产生用户行为数据的 而且通过这个类模拟白龙马用户行为数据产生过程* 120.191.181.178 - - 2018-02-18 20:24:39 "POST https://www.bailongma.com/item/b HTTP/1.1" 203 69172 https://www.bailongma.com/register UCBrowser Webkit X3android 8.0 海南 20.02 110.20 36* ip地址 两个中划线 日期 时间 用户的请求网站(三个字段组成的) 请求网站的响应码 请求的响应字节数 来源网站 浏览器信息(n个字段) 省份 纬度 经度 年龄** 模拟数据的时候--数据的真实性,IP地址随机生成 时间生成-数据产生的时间 来源网站和请求网址可以从脱敏数据中获取回来* 浏览器信息(从文件读取)*/
public class DataGenerator {//1、定义一个存储IP地址的集合 一会产生模拟数据的时候,模拟数据当中ip地址从集合中随机获取一个private static List<String> ipList = new ArrayList<>();//2、定义一个集合,集合存放请求的白龙马的网址 模拟数据当中请求网址时从集合中随机获取一个即可private static List<String> requestList = new ArrayList<>();//3、定义一个集合,集合存放来源网站信息,模拟数据的来源网站时候我们可以从集合中随机获取一个即可private static List<String> refererList = new ArrayList<>();//4、定义一个集合 存放请求的响应状态码private static List<String> codeList = new ArrayList<>();//5、定义一个集合 存放浏览器信息 一会模拟产生数据时,浏览器信息从集合中随机获取private static List<String> userAgentList = new ArrayList<>();//6、定义一个集合,集合存放地理位置信息private static List<String> addressList = new ArrayList<>();/*** 初始化方法,初始化方法主要是给我们上面定义的集合先填充一点数据*/private static void init(){/*** 1、填充状态码集合 一会随机从集合获取一条数据,默认情况下每一条数据的获取概率都是一样* 如果你想让某一个值获取概率大一点那么可以将这个值在集合多添加几次*/codeList.addAll(Arrays.asList("200","203","300","301","200","203","300","301","200","203","300","301","200","203","300","301","400","401","403","500","503"));/*** 2、填充浏览器信息集合*/userAgentList.add("Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; Win64; x64; Trident/4.0)");userAgentList.add("Mozilla/5.0 (Windows; U; Windows NT 5.2) Gecko/2008070208 Firefox/3.0.1");userAgentList.add("Mozilla/5.0 (Macintosh; PPC Mac OS X; U; en) Opera 8.0");userAgentList.add("Mozilla/5.0 (Windows; U; Windows NT 5.2) AppleWebKit/525.13 (KHTML, like Gecko) Version/3.1 Safari/525.13");userAgentList.add("Mozilla/5.0 (Windows; U; Windows NT 5.2) AppleWebKit/525.13 (KHTML, like Gecko) Chrome/0.2.149.27 Safari/525.13");userAgentList.add("Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.11 TaoBrowser/2.0 Safari/536.11");userAgentList.add("Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; QQBrowser/7.0.3698.400) ");userAgentList.add("Mozilla/5.0 (Windows NT 5.1) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.84 Safari/535.11 SE 2.X MetaSr 1.0");userAgentList.add("Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.11 TaoBrowser/2.0 Safari/536.11");/*** 填充ip地址 请求网站 来源网站 省份地理位置信息 四个集合* 四个集合的填充不能随便瞎写 集合从脱敏数据文件中读取对应的值填充进来*/BufferedReader bufferedReader = null;try {bufferedReader = new BufferedReader(new FileReader("a.log"));String line = null;//这个数据是我们给大家发送的脱敏数据 脱敏数据大数据没法使用 原因是因为是旧数据while((line = bufferedReader.readLine()) != null){String[] array = line.split(" ");//脱敏数据中的IP地址放到ipList集合中ipList.add(array[0]);//需要把请求方式 请求网站 请求协议三个字段以空格组合放到requestList集合中requestList.add(array[5]+" "+array[6]+" "+array[7]);//来源信息把它加到来源列表当中refererList.add(array[10]);refererList.add("https://www.baidu.com/search");refererList.add("https://www.baidu.com/search");refererList.add("https://www.baidu.com/search");refererList.add("https://www.sougou.com/search");refererList.add("https://www.google.com/search");//把省份 维度 经度 加到地理位置数据中addressList.add(array[array.length-4]+" "+array[array.length-3]+" "+array[array.length-2]);}} catch (FileNotFoundException e) {throw new RuntimeException(e);} catch (IOException e) {throw new RuntimeException(e);} finally {if (bufferedReader != null){try {bufferedReader.close();} catch (IOException e) {throw new RuntimeException(e);}}}}/*** 程序执行入口* @param args*/public static void main(String[] args) throws IOException, InterruptedException {//1、填充模拟数据集合init();/*** 2、模拟数据的目的是为了模拟真实的数据产生逻辑,* 真实场景下 数据是源源不断的产生的。所以我们模拟程序也是源源不断的产生的,不会停止的 除非你手动停止* 产生数据的时候,数据得有一个存放的一个文件路径 文件中通过IO流写入数据*/Scanner scanner = new Scanner(System.in);System.out.println("请输入网站产生的用户行为日志数据文件的路径");String path = scanner.next();//定义IO输出流 用于模拟一会数据产生之后输出到日志文件的的过程BufferedWriter bufferedWriter = new BufferedWriter(new FileWriter(path));//随机类 用于产生随机数的Random random = new Random();//定义时间格式类 用于格式化时间的SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");while (true){/*** 真实情况下 虽然数据是7*24小时产生的,但是并不是每时每刻都在产生数据,* 而是会间断性的产生的 比如每隔1-10s 产生10-50条数据* 尤其是在凌晨12:00 -6:00的时候 数据产生的非常缓慢*///1、先获取数据产生的一个时间Calendar calendar = Calendar.getInstance();boolean judgeNight = isJudgeNight(calendar);// num代表一次产生num条数据int num = 0;// time代表产生一次数据 休息多长时间int time = 0;if (judgeNight){//代表是凌晨的时间num = random.nextInt(10);time = 30000+random.nextInt(60001);}else{//代表的是非凌晨的时间num = random.nextInt(50);time = 1000+ random.nextInt(20001);}/*** for循环代表产生num条数据*/for (int i = 0; i < num; i++) {/*** 获取数据对应的值 然后拼接 输出即可*///1、获取ip地址 [0,ipList.size()-1]String ip = ipList.get(random.nextInt(ipList.size()));//2、获取数据的生成时间Date date = new Date();//2023-08-28 18:00:00String dataGenTime = sdf.format(date);//3、随机获取请求的网址--行为触发之后请求的网址String request = requestList.get(random.nextInt(requestList.size()));//4、随机获取一个状态码String code = codeList.get(random.nextInt(codeList.size()));//5、随机产生一个响应字节数int bytes = random.nextInt(100000);//6、随机获取一个来源网站String referer = refererList.get(random.nextInt(refererList.size()));//7、随机获取一个浏览器信息String userAgent = userAgentList.get(random.nextInt(userAgentList.size()));//8、随机获取一个地理位置信息String address = addressList.get(random.nextInt(addressList.size()));//9、随机产生一个年龄int age = 18+ random.nextInt(71);//组装数据 可以使用StringBuffer完成 数据和数据之间一定要以空格分割String data = ip+" - - "+dataGenTime+" "+request+" "+code+" "+bytes+" "+referer+" "+userAgent+" "+address+" "+age;//将数据输出bufferedWriter.write(data);//写出一个换行符 保证一条用户行为数据独占一行bufferedWriter.newLine();//bufferWriter是处理流 输出数据必须加flushbufferedWriter.flush();}//生成num条数据之后 间隔time时间之后再继续生成Thread.sleep(time);System.out.println("间隔了"+time+"秒之后生成了"+num+"条数据");}}/*** 方法是用来判断是否为凌晨的时间* @param cal* @return*/public static boolean isJudgeNight(Calendar cal){//先获取当前的时间Date currentTime = cal.getTime();//先获取当前日期下的凌晨时间段 两个时间 一个是开始的时间 一个是结束的时间//开始的时间是当天的00:00:00 结束时间 06:00:00cal.set(Calendar.HOUR_OF_DAY,0);cal.set(Calendar.MINUTE,0);cal.set(Calendar.SECOND,0);//获取当前时间对应的凌晨的开始时间Date startTime = cal.getTime();cal.set(Calendar.HOUR_OF_DAY,6);cal.set(Calendar.MINUTE,0);cal.set(Calendar.SECOND,0);//获取当前时间对应的结束时间Date endTime = cal.getTime();if (currentTime.after(startTime) && currentTime.before(endTime)){return true;}else{return false;}}
}相关文章:
实训笔记8.28
实训笔记8.28 8.28笔记一、大数据计算场景主要分为两种1.1 离线计算场景1.2 实时计算场景 二、一般情况下大数据项目的开发流程2.1 数据采集存储阶段2.2 数据清洗预处理阶段2.3 数据统计分析阶段2.4 数据挖掘预测阶段2.5 数据迁移阶段2.6 数据可视化阶段 三、纯大数据离线计算项…...

机器学习笔记之最优化理论与方法(五)凸优化问题(上)
机器学习笔记之最优化理论与方法——凸优化问题[上] 引言凸优化问题的基本定义凸优化定义:示例 凸优化与非凸优化问题的区分局部最优解即全局最优解凸优化问题的最优性条件几种特殊凸问题的最优性条件无约束凸优化等式约束凸优化非负约束凸优化 引言 本节将介绍凸优…...
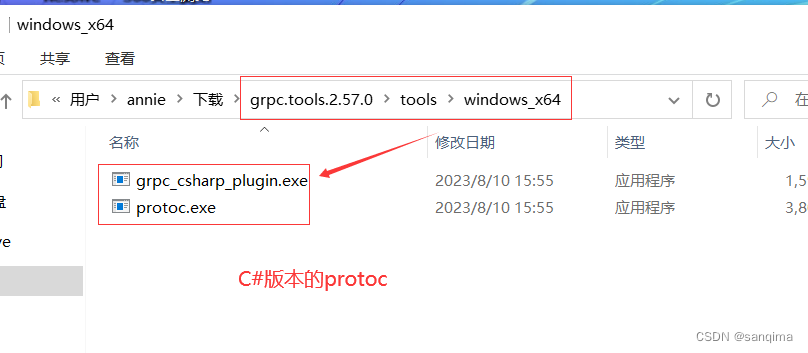
在Windows10上编译grpc工程,得到protoc.exe和grpc_cpp_plugin.exe
grpc是google于2015年发布的一款跨进程、跨语言、开源的RPC(远程过程调用)技术。使用C/S模式,在客户端、服务端共享一个protobuf二进制数据。在点对点通信、微服务、跨语言通信等领域应用很广,下面介绍grpc在windows10上编译,这里以编译grpc …...

一些测试知识
希望能起到帮助,博主主页: https://blog.csdn.net/qq_57785602/category_12023254.html?spm1001.2014.3001.5482 软件测试理论 测试的依据: 需求,规格说明,模型,用户需求等 什么是软件测试 描述一种来…...

Socket交互的基本流程?
TCP socket通信过程图 什么是网络编程,网络编程就是编写程序使两台连联网的计算机相互交换数据。怎么交换数据呢?操作系统提供了“套接字”(socket)的组件我们基于这个组件进行网络通信开发。tcp套接字工作流程都以“打电话”来生…...

css 分割线中间带文字
效果图 代码块(自适应) <div class"line"><span class"text">我是文字</span></div>.line{height:0;border-top:1px solid #000;text-align:center;}.text{position:relative;top:-14px;background-color:#…...

会不会激发对modern c++的新兴趣
可变参数好像很厉害的样子,会节省很多手写代码,让编译器自动帮我们生成代码 template<typename Fun, typename...Args> void invoke(Fun&& fun, Args&&...args) { fun(std::forward<Args>(args)...); } 任意函数包装器…...

Nginx服务器如何配合Java开发项目
Nginx服务器如何才能配合好相关的编程语言进行服务器搭建呢?下面我们就来看看有关的技术如何融合。希望大家有所收获。 在进行Nginx服务器建设的时候有很多语言的应用,其中Java 开发的web项目就是很常见的。下面我们就看看Nginx服务器如何才能与Java编程…...
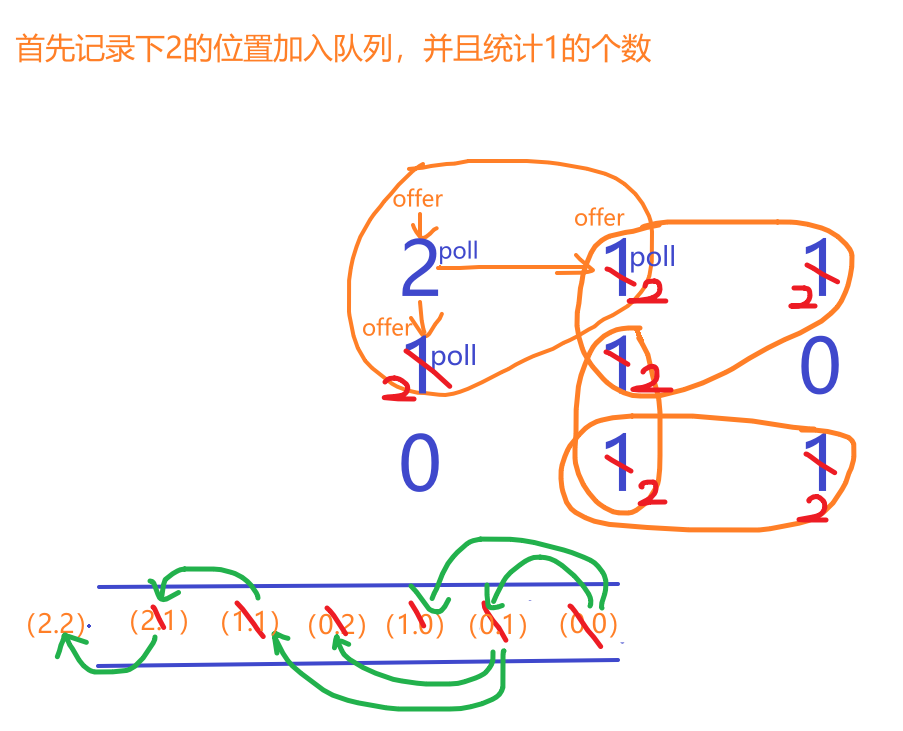
【LeetCode-中等题】994. 腐烂的橘子
文章目录 题目方法一:bfs层序遍历 题目 该题值推荐用bfs,因为是一层一层的感染,而不是一条线走到底的那种,所以深度优先搜索不适合 方法一:bfs层序遍历 广度优先搜索,就是从起点出发,每次都尝…...

K8s部署单机mysql
文章目录 一、K8s部署单机mysql1.1 说明1.2 不足 二、部署三、检查 一、K8s部署单机mysql 1.1 说明 定制配置数据存放在configMapmysql数据放在/opt/mysql目录下(/opt/mysql目录需要事先创建)root账号密码使用环境变量env服务暴露方式为nodePort,端口30336 1.2 不…...
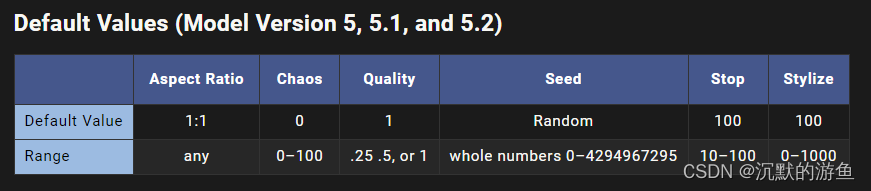
Midjourney学习(二)参数的基础
prompt的组成 prompt 可以由三部分组成, 第一部分是垫图部分,也就是一张网络图片 第二部分是文本描述内容 第三部分则是参数 参数列表 --aspect <value> 或者 --ar <value> 控制画面的比例,横竖比例 --version <value> -…...

Ubuntu安装Protobuf,指定版本
参考:https://github.com/protocolbuffers/protobuf#readme https://github.com/protocolbuffers/protobuf/blob/v3.20.3/src/README.md 其实官网的readme给的步骤很详细。 1.安装相关依赖 sudo apt-get install autoconf automake libtool curl make g unzip …...
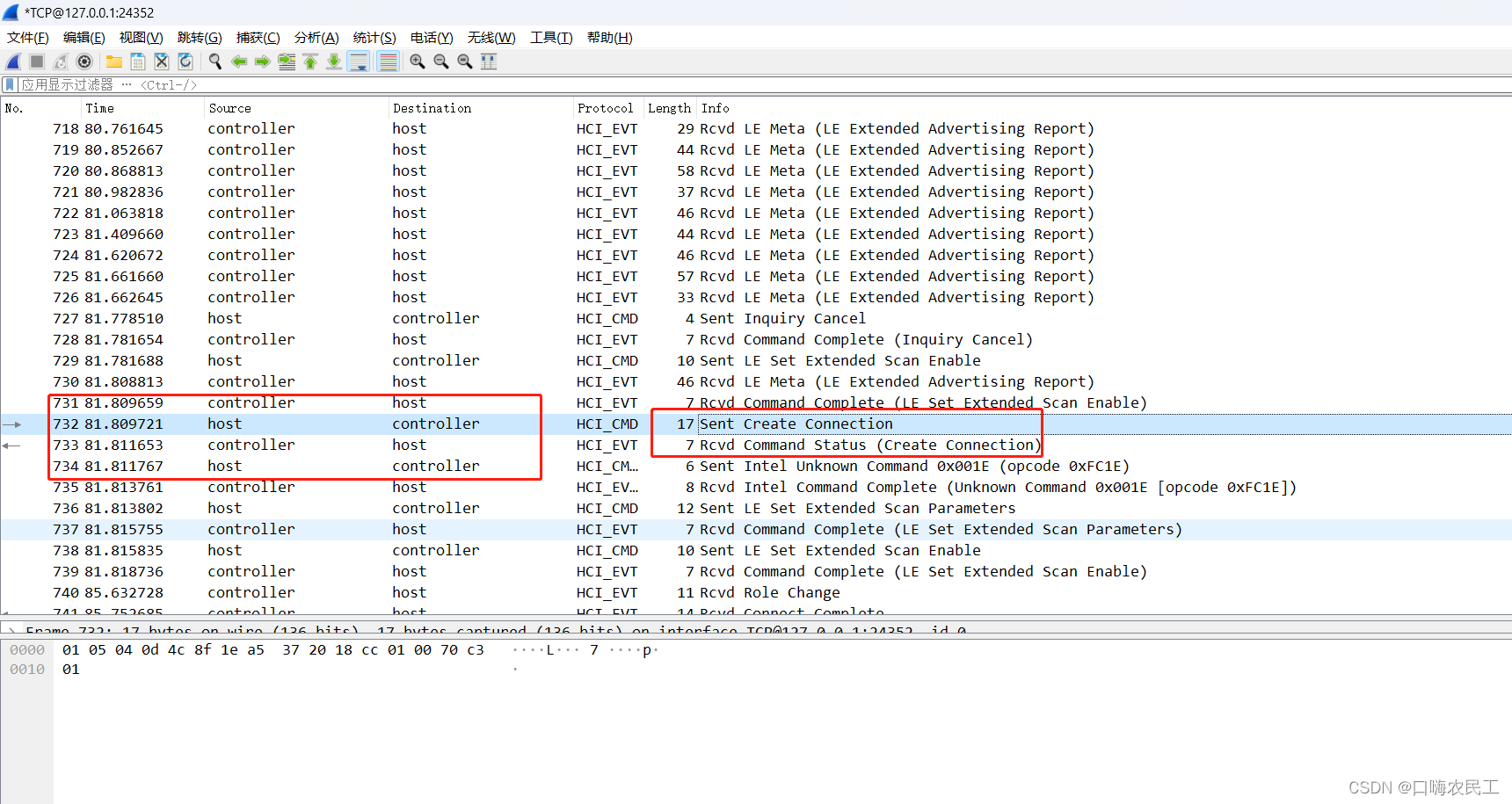
没有使用sniffer dongle在windows抓包蓝牙方法分享
网上很多文章都是介绍买一个sniffer dongle来抓蓝牙数据,嫌麻烦又费钱,目前找到一个好方法,不需要sniffer就可以抓蓝牙数据过程,现分享如下: (1)在我资源附件找到相关安装包或者查看如下链接 https://learn.microsoft.com/zh-cn/windows-hardware/drivers/bluetooth/testing-bt…...

解决Debian系统通过cifs挂载smb后,中文目录乱码问题
解决Debian系统通过cifs挂载smb后,中文目录乱码问题 //$smb_server/share /mnt/nas_share cifs credentials/root/.smbcredentials,iocharsetutf8 0 0默认通过以上命令挂载smb,但是在查看文件目录时,中文乱码 解决问题方式: de…...

springboot整合jquery实现前后端数据交互
一 实施逻辑 1.1 前端 <!doctype html> <html lang"en"><head><meta charset"UTF-8"><meta name"Generator" content"EditPlus"><meta name"Author" content""><meta n…...

TypeScript 中的类型检查实用函数
TypeScript 中的类型检查实用函数 文章目录 TypeScript 中的类型检查实用函数一、概述二、代码实现 一、概述 在前端开发中,我们经常需要判断变量的类型以进行相应的操作或处理。TypeScript 提供了基础的类型检查,但有时我们需要更复杂或更灵活的类型检…...

JavaScript中的事件委托(event delegation)
聚沙成塔每天进步一点点 ⭐ 专栏简介⭐ JavaScript事件委托⭐ 事件冒泡(Event Bubbling)⭐ 事件委托的优点⭐ 如何使用事件委托⭐ 写在最后 ⭐ 专栏简介 前端入门之旅:探索Web开发的奇妙世界 记得点击上方或者右侧链接订阅本专栏哦 几何带你启…...

ubuntu OCR 脚本
1. 百度 PaddleOCR 介绍 2. 环境安装 pip install paddlepaddle -i https://pypi.tuna.tsinghua.edu.cn/simple # 进入 https://github.com/PaddlePaddle/PaddleOCR # 这里有个 requirements.txt pip install paddleocr -i https://mirror.baidu.com/pypi/simple pip instal…...
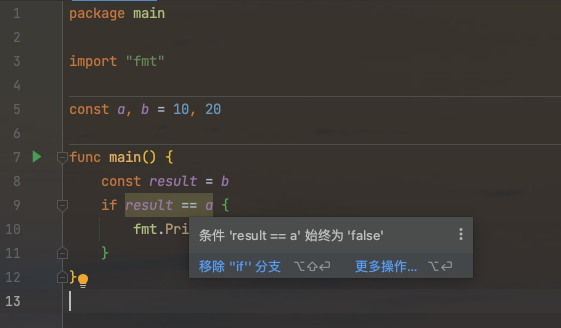
Go死码消除
概念: 死码消除(dead code elimination, DCE) 是一种编译器优化技术, 作用是在编译阶段去掉对程序运行结果没有任何影响的代码 和 逃逸分析[1],内联优化[2]并称为 Go编译器执行的三个重要优化 效果: 对于 const.go代码如下: package mainimport "fmt"func max(a, b i…...
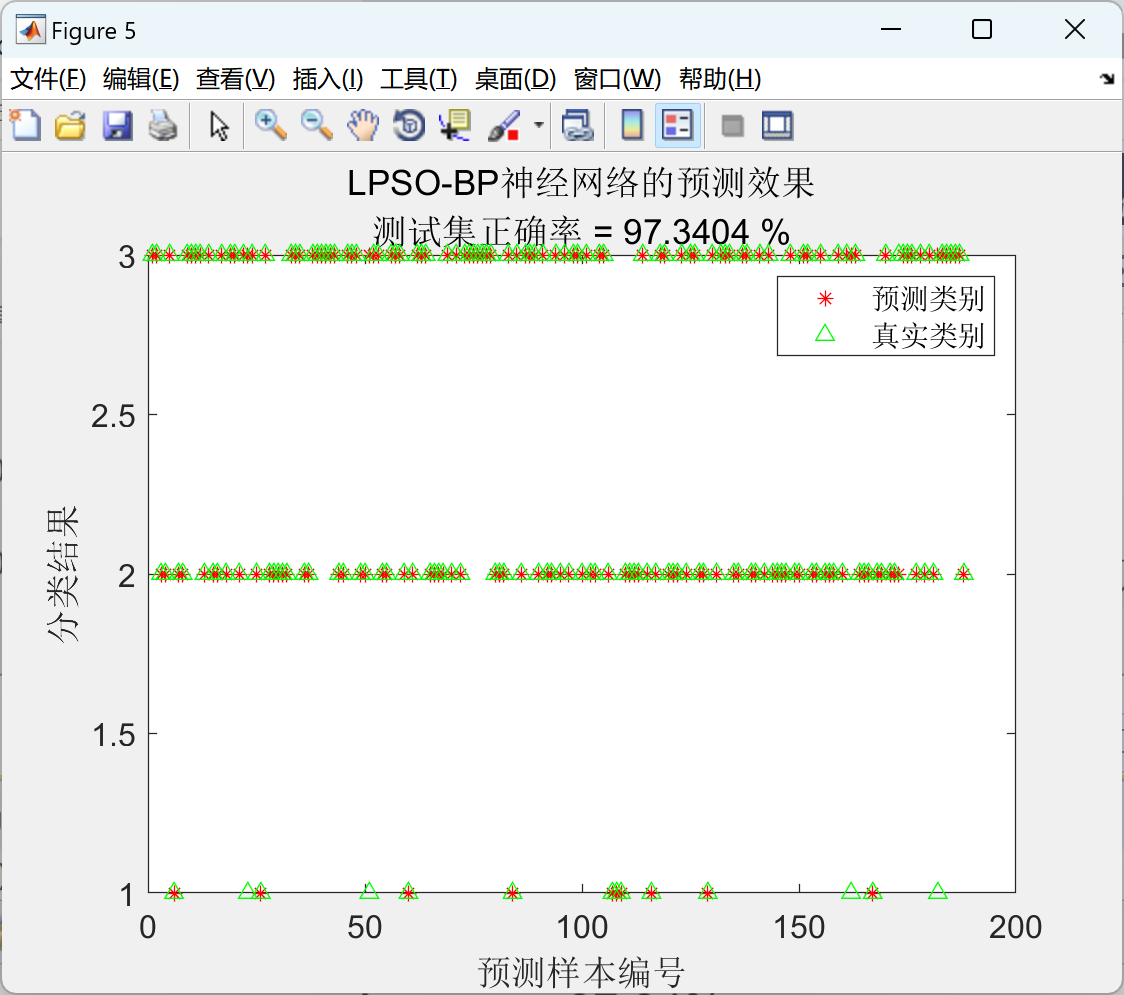
基于改进莱维飞行和混沌映射的粒子群优化BP神经网络分类研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

Vim 调用外部命令学习笔记
Vim 外部命令集成完全指南 文章目录 Vim 外部命令集成完全指南核心概念理解命令语法解析语法对比 常用外部命令详解文本排序与去重文本筛选与搜索高级 grep 搜索技巧文本替换与编辑字符处理高级文本处理编程语言处理其他实用命令 范围操作示例指定行范围处理复合命令示例 实用技…...

装饰模式(Decorator Pattern)重构java邮件发奖系统实战
前言 现在我们有个如下的需求,设计一个邮件发奖的小系统, 需求 1.数据验证 → 2. 敏感信息加密 → 3. 日志记录 → 4. 实际发送邮件 装饰器模式(Decorator Pattern)允许向一个现有的对象添加新的功能,同时又不改变其…...

Prompt Tuning、P-Tuning、Prefix Tuning的区别
一、Prompt Tuning、P-Tuning、Prefix Tuning的区别 1. Prompt Tuning(提示调优) 核心思想:固定预训练模型参数,仅学习额外的连续提示向量(通常是嵌入层的一部分)。实现方式:在输入文本前添加可训练的连续向量(软提示),模型只更新这些提示参数。优势:参数量少(仅提…...

简易版抽奖活动的设计技术方案
1.前言 本技术方案旨在设计一套完整且可靠的抽奖活动逻辑,确保抽奖活动能够公平、公正、公开地进行,同时满足高并发访问、数据安全存储与高效处理等需求,为用户提供流畅的抽奖体验,助力业务顺利开展。本方案将涵盖抽奖活动的整体架构设计、核心流程逻辑、关键功能实现以及…...

MMaDA: Multimodal Large Diffusion Language Models
CODE : https://github.com/Gen-Verse/MMaDA Abstract 我们介绍了一种新型的多模态扩散基础模型MMaDA,它被设计用于在文本推理、多模态理解和文本到图像生成等不同领域实现卓越的性能。该方法的特点是三个关键创新:(i) MMaDA采用统一的扩散架构…...

华为OD机试-食堂供餐-二分法
import java.util.Arrays; import java.util.Scanner;public class DemoTest3 {public static void main(String[] args) {Scanner in new Scanner(System.in);// 注意 hasNext 和 hasNextLine 的区别while (in.hasNextLine()) { // 注意 while 处理多个 caseint a in.nextIn…...

自然语言处理——Transformer
自然语言处理——Transformer 自注意力机制多头注意力机制Transformer 虽然循环神经网络可以对具有序列特性的数据非常有效,它能挖掘数据中的时序信息以及语义信息,但是它有一个很大的缺陷——很难并行化。 我们可以考虑用CNN来替代RNN,但是…...

AspectJ 在 Android 中的完整使用指南
一、环境配置(Gradle 7.0 适配) 1. 项目级 build.gradle // 注意:沪江插件已停更,推荐官方兼容方案 buildscript {dependencies {classpath org.aspectj:aspectjtools:1.9.9.1 // AspectJ 工具} } 2. 模块级 build.gradle plu…...

A2A JS SDK 完整教程:快速入门指南
目录 什么是 A2A JS SDK?A2A JS 安装与设置A2A JS 核心概念创建你的第一个 A2A JS 代理A2A JS 服务端开发A2A JS 客户端使用A2A JS 高级特性A2A JS 最佳实践A2A JS 故障排除 什么是 A2A JS SDK? A2A JS SDK 是一个专为 JavaScript/TypeScript 开发者设计的强大库ÿ…...
: 一刀斩断视频片头广告)
快刀集(1): 一刀斩断视频片头广告
一刀流:用一个简单脚本,秒杀视频片头广告,还你清爽观影体验。 1. 引子 作为一个爱生活、爱学习、爱收藏高清资源的老码农,平时写代码之余看看电影、补补片,是再正常不过的事。 电影嘛,要沉浸,…...