MySQL 基本操作1
目录
Create
insert
插入跟新 1
插入跟新 2
Retrive
select
where 子句查询
1.查找数学成绩小于 80 的同学。
2.查询数学成绩等于90分的同学。
3.查询总分大于240 的学生
4.查询空值或者非空值
5.查询语文成绩在70~80之间的同学
6.查询英语成绩是99 和 93 和 19 和 30
7.模糊匹配
排序
LIMIT
mysql 的基本操作就是:CURD
-
Create(创建)
-
Retrive(读取)
-
Update(跟新)
-
Delete(删除)
Create
insert
这里就对应的是表数据的操作,而不是表结构的操作,这里的 create 也表示的是插入也就是 insert
insert [into]
table_name [(column, ...)]
values(value_list), [(value_list)], ...
value_list: value, [value, ][... ,]上面就是插入的语法,还是直接看一下插入示例:
mysql> create table exam_result(-> id int primary key auto_increment,-> name varchar(12) not null,-> chinese tinyint unsigned,-> math tinyint unsigned,-> engilsh tinyint unsigned-> );
Query OK, 0 rows affected (0.01 sec)
mysql> desc exam_result;
+---------+---------------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+---------+---------------------+------+-----+---------+----------------+
| id | int(11) | NO | PRI | NULL | auto_increment |
| name | varchar(12) | NO | | NULL | |
| chinese | tinyint(3) unsigned | YES | | NULL | |
| math | tinyint(3) unsigned | YES | | NULL | |
| engilsh | tinyint(3) unsigned | YES | | NULL | |
+---------+---------------------+------+-----+---------+----------------+
5 rows in set (0.00 sec)上面是创建一张表,考试成绩表,下面插入数据:
首先介绍一下语法:
-
into 是可以有也可以没有,但是为了语法的完整性,还是带上比较好。
-
表名后面跟的是想要插入的列名,如果没有写表示全列插入。
-
values 后面表示要插入的值,插入值的顺序要和表明后面的顺序相同,如果没有写,那么就要按照表里面的值的顺序来插入。
-
插入不仅可以插入一行记录,也可以插入多行记录,插入插入多行数据的话要用逗号隔开。
mysql> insert into exam_result (id, name, chinese, math, english) values (1, '林黛玉', 98, 90, 99);
Query OK, 1 row affected (0.00 sec)
mysql> select * from exam_result;
+----+-----------+---------+------+---------+
| id | name | chinese | math | english |
+----+-----------+---------+------+---------+
| 1 | 林黛玉 | 98 | 90 | 99 |
+----+-----------+---------+------+---------+
1 row in set (0.00 sec)上面没有省略,插入成功,下面我们省略表明后面的列名,全列插入:
mysql> insert into exam_result values (2, '沙和尚', 77, 87, 72);
Query OK, 1 row affected (0.00 sec)
mysql> select * from exam_result;
+----+-----------+---------+------+---------+
| id | name | chinese | math | english |
+----+-----------+---------+------+---------+
| 1 | 林黛玉 | 98 | 90 | 99 |
| 2 | 沙和尚 | 77 | 87 | 72 |
+----+-----------+---------+------+---------+
2 rows in set (0.00 sec)全列插入就不能省略,这个也插入成功了,下面试一下全列插入:
mysql> insert into exam_result(name, chinese, math, english) values ('薛宝钗', 88, 90, 88), ('赵姨娘', 79, 90, 93), ('唐三藏', 72, 60, 56);
Query OK, 3 rows affected (0.00 sec)
Records: 3 Duplicates: 0 Warnings: 0
mysql> select * from exam_result;
+----+-----------+---------+------+---------+
| id | name | chinese | math | english |
+----+-----------+---------+------+---------+
| 1 | 林黛玉 | 98 | 90 | 99 |
| 2 | 沙和尚 | 77 | 87 | 72 |
| 3 | 薛宝钗 | 88 | 90 | 88 |
| 4 | 赵姨娘 | 79 | 90 | 93 |
| 5 | 唐三藏 | 72 | 60 | 56 |
+----+-----------+---------+------+---------+
5 rows in set (0.00 sec)上面就插入完成了。
插入跟新 1
insert ... on duplicate key update 列名 = value, ...再插入了之后有可能会插入失败,也就是里面的唯一键或者主键有重复等情况所以如果有重复插入失败的话就跟新里面的值。
mysql> insert into exam_result values (2, '沙和尚', 77, 87, 72) on duplicate key update id = 6, name = '沙悟净', chinese = 77, math = 87, english = 72;
Query OK, 2 rows affected (0.00 sec)
mysql> select * from exam_result;
+----+-----------+---------+------+---------+
| id | name | chinese | math | english |
+----+-----------+---------+------+---------+
| 1 | 林黛玉 | 98 | 90 | 99 |
| 3 | 薛宝钗 | 88 | 90 | 88 |
| 4 | 赵姨娘 | 79 | 90 | 93 |
| 5 | 唐三藏 | 72 | 60 | 56 |
| 6 | 沙悟净 | 77 | 87 | 72 |
+----+-----------+---------+------+---------+
5 rows in set (0.00 sec)而跟新后的值也是自己设定的。
插入跟新 2
mysql> replace into exam_result (id, name, chinese, math, english) values(7, '白龙马', 90, 46, 50);
Query OK, 1 row affected (0.00 sec)
mysql> select * from exam_result;
+----+-----------+---------+------+---------+
| id | name | chinese | math | english |
+----+-----------+---------+------+---------+
| 1 | 林黛玉 | 98 | 90 | 99 |
| 3 | 薛宝钗 | 88 | 90 | 88 |
| 4 | 赵姨娘 | 79 | 90 | 93 |
| 5 | 唐三藏 | 72 | 60 | 56 |
| 6 | 沙悟净 | 77 | 87 | 72 |
| 7 | 白龙马 | 90 | 46 | 50 |
+----+-----------+---------+------+---------+
6 rows in set (0.00 sec)这个语法就是如果没有重复那么就是插入,如果有重复就讲重复替换。
下面看一下重复后替换:
mysql> replace into exam_result (id, name, chinese, math, english) values(7, '小白龙', 99, 20, 19);
Query OK, 2 rows affected (0.00 sec)mysql> select * from exam_result;
+----+-----------+---------+------+---------+
| id | name | chinese | math | english |
+----+-----------+---------+------+---------+
| 1 | 林黛玉 | 98 | 90 | 99 |
| 3 | 薛宝钗 | 88 | 90 | 88 |
| 4 | 赵姨娘 | 79 | 90 | 93 |
| 5 | 唐三藏 | 72 | 60 | 56 |
| 6 | 沙悟净 | 77 | 87 | 72 |
| 7 | 小白龙 | 99 | 20 | 19 |
+----+-----------+---------+------+---------+
6 rows in set (0.00 sec)下面就是重复后替换。
Retrive
select
select 是mysql 里面最常用的一个,下面看一下查询。
查询全部数据:
select [表达式][列名] from table_name;简单查询的语法下面看一下:
mysql> select * from exam_result;
+----+-----------+---------+------+---------+
| id | name | chinese | math | english |
+----+-----------+---------+------+---------+
| 1 | 林黛玉 | 98 | 90 | 99 |
| 3 | 薛宝钗 | 88 | 90 | 88 |
| 4 | 赵姨娘 | 79 | 90 | 93 |
| 5 | 唐三藏 | 72 | 60 | 56 |
| 6 | 沙悟净 | 77 | 87 | 72 |
| 7 | 小白龙 | 99 | 20 | 19 |
+----+-----------+---------+------+---------+
6 rows in set (0.00 sec)想要查询所有的数据就是 select * ,但是如果数据库里面数据量太大的话, select * 传输的数据太大,所以不适合 select * 查询,但是如果在自己的数据库里面,那么就是无所谓的。
select 不光能查询表里面的数据,还可以在后面输入表达式:
mysql> select 1 + 1;
+-------+
| 1 + 1 |
+-------+
| 2 |
+-------+
1 row in set (0.00 sec)mysql> select NULL;
+------+
| NULL |
+------+
| NULL |
+------+
1 row in set (0.00 sec)mysql> select database();
+------------+
| database() |
+------------+
| CURD |
+------------+
1 row in set (0.00 sec)select 后面还可以跟函数。
下面看一下select 查询表里面的数据:
mysql> select id, name, chinese, math, english from exam_result;
+----+-----------+---------+------+---------+
| id | name | chinese | math | english |
+----+-----------+---------+------+---------+
| 1 | 林黛玉 | 98 | 90 | 99 |
| 3 | 薛宝钗 | 88 | 90 | 88 |
| 4 | 赵姨娘 | 79 | 90 | 93 |
| 5 | 唐三藏 | 72 | 60 | 56 |
| 6 | 沙悟净 | 77 | 87 | 72 |
| 7 | 小白龙 | 99 | 20 | 19 |
+----+-----------+---------+------+---------+
6 rows in set (0.00 sec)也可以这样查询表里面的数据,也可以改变查询的内容:
mysql> select name, id from exam_result;
+-----------+----+
| name | id |
+-----------+----+
| 林黛玉 | 1 |
| 薛宝钗 | 3 |
| 赵姨娘 | 4 |
| 唐三藏 | 5 |
| 沙悟净 | 6 |
| 小白龙 | 7 |
+-----------+----+
6 rows in set (0.01 sec)既然 select 后面可以计算,那么也可以计算,下面可以算一下他们的总分:
mysql> select name, chinese, math, english, chinese+math+english from exam_result;
+-----------+---------+------+---------+----------------------+
| name | chinese | math | english | chinese+math+english |
+-----------+---------+------+---------+----------------------+
| 林黛玉 | 98 | 90 | 99 | 287 |
| 薛宝钗 | 88 | 90 | 88 | 266 |
| 赵姨娘 | 79 | 90 | 93 | 262 |
| 唐三藏 | 72 | 60 | 56 | 188 |
| 沙悟净 | 77 | 87 | 72 | 236 |
| 小白龙 | 99 | 20 | 19 | 138 |
+-----------+---------+------+---------+----------------------+
6 rows in set (0.00 sec)但是这里看到输出出来的数据不好看,其实 myslq 也可以重命名的:
... as new_namemysql> select name, chinese, math, english, chinese+math+english as 总分 from exam_result;
+-----------+---------+------+---------+--------+
| name | chinese | math | english | 总分 |
+-----------+---------+------+---------+--------+
| 林黛玉 | 98 | 90 | 99 | 287 |
| 薛宝钗 | 88 | 90 | 88 | 266 |
| 赵姨娘 | 79 | 90 | 93 | 262 |
| 唐三藏 | 72 | 60 | 56 | 188 |
| 沙悟净 | 77 | 87 | 72 | 236 |
| 小白龙 | 99 | 20 | 19 | 138 |
+-----------+---------+------+---------+--------+
6 rows in set (0.00 sec)除了上面的 as 重命名,其实也可以不带 as 直接空格也可以:
mysql> select name, chinese, math, english, chinese+math+english 总分 from exam_result;
+-----------+---------+------+---------+--------+
| name | chinese | math | english | 总分 |
+-----------+---------+------+---------+--------+
| 林黛玉 | 98 | 90 | 99 | 287 |
| 薛宝钗 | 88 | 90 | 88 | 266 |
| 赵姨娘 | 79 | 90 | 93 | 262 |
| 唐三藏 | 72 | 60 | 56 | 188 |
| 沙悟净 | 77 | 87 | 72 | 236 |
| 小白龙 | 99 | 20 | 19 | 138 |
+-----------+---------+------+---------+--------+
6 rows in set (0.00 sec)where 子句查询
select 查询除了可以查询表里面的数据,还可以筛选,而 where 就可以筛选。
where 既然可以筛选,那么也可以有判断,下面看一下 where 后面跟些判断的内容。
| 运算符 | 说明 |
|---|---|
| >, >=, <, <= | 大于,大于等于,小于,小于等于 |
| = | 等于,NULL 不安全,例如 NULL = NULL 的结果是 NULL |
| <=> | 等于,NULL 安全,例如 NULL <=> NULL 的结果是 TRUE(1) |
| !=, <> | 不等于 |
| BETWEEN a and b | 范围匹配,[a0,a1],如果 a0 <= value <= a1,返回 TRUE(1) |
| IN (option) | 如果是 option 中的任意一个,返回 TRUE(1) |
| IS NULL | 是 NULL |
| IS NOT NULL | 不是 NULL |
| LIKE | 模糊匹配。% 表示任意多个 (包括 0 个) 任意字符,_表示任意一个字符 |
| 运算符 | 说明 |
|---|---|
| AND | 多个条件必须都为 TRUE()1结果才是 TRUE(1) |
| OR | 任意一个条件为 TRUE1), 结果为 TRUE(1) |
| NOT | 条件为 TRUE(1),结果为 FALSE(0) |
上面就是 where 后面可以跟的运算符。
根据下面的表来看一下运算符:
+----+-----------+---------+------+---------+
| id | name | chinese | math | english |
+----+-----------+---------+------+---------+
| 1 | 林黛玉 | 98 | 90 | 99 |
| 3 | 薛宝钗 | 88 | 90 | 88 |
| 4 | 赵姨娘 | 79 | 90 | 93 |
| 5 | 唐三藏 | 72 | 60 | 56 |
| 6 | 沙悟净 | 77 | 87 | 72 |
| 7 | 小白龙 | 99 | 20 | 19 |
+----+-----------+---------+------+---------+1.查找数学成绩小于 80 的同学。
mysql> select name, math from exam_result where math<90;
+-----------+------+
| name | math |
+-----------+------+
| 唐三藏 | 60 |
| 沙悟净 | 87 |
| 小白龙 | 20 |
+-----------+------+
3 rows in set (0.00 sec)上面就查询到了数学小于90分的同学。
2.查询数学成绩等于90分的同学。
mysql> select name, math from exam_result where math=90;
+-----------+------+
| name | math |
+-----------+------+
| 林黛玉 | 90 |
| 薛宝钗 | 90 |
| 赵姨娘 | 90 |
+-----------+------+
3 rows in set (0.00 sec)上面看到 = 显示 NULL 不安全,= 不能查询 NULL,下面看一下:
3.查询总分大于240 的学生
mysql> select name, chinese+english+math from exam_result where chinese+english+math > 240;
+-----------+----------------------+
| name | chinese+english+math |
+-----------+----------------------+
| 林黛玉 | 287 |
| 薛宝钗 | 266 |
| 赵姨娘 | 262 |
+-----------+----------------------+
3 rows in set (0.00 sec)虽然查询出来了,但是上面的写法太难看了,我们可以使用重命名:
mysql> select name, chinese+english+math 总分 from exam_result where chinese+english+math > 240;
+-----------+--------+
| name | 总分 |
+-----------+--------+
| 林黛玉 | 287 |
| 薛宝钗 | 266 |
| 赵姨娘 | 262 |
+-----------+--------+
3 rows in set (0.00 sec)这样写就好多了,但是后面 where 这样写也有点长骂我们可不可以用 重命名:
mysql> select name, chinese+english+math 总分 from exam_result where 总分 > 240;
ERROR 1054 (42S22): Unknown column '总分' in 'where clause'这里显示不认识 “总分”为什么?
这里其实是因为mysql 的执行是有顺序的,如果我们想要查询得到的数据,书不是先要有数据,也就是有表,有了表之后我们还要对数据进行筛选也就是 where 等筛选之后才可以讲数据得到然后在显示出来,所以说 where 一定在显示重命名之前,所以数据还没有重命名然后就被拿来当筛选,那么当然是不认识的,那么我们能不能在 where 处之间重命名然后在前面使用?
mysql> select name, 总分 from exam_result where chinese+english+math 总分 > 240;
ERROR 1064 (42000): You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near '总分 > 240' at line 1这样也是不可以的,因为与发出规定 where 后面不能重命名。
所以我们在写 sql 语句的时候一定要注意其执行顺序,否则就是一条错误的 sql 语句。
4.查询空值或者非空值
下面重新创建一个表插入一些空值:
mysql> create table test_null(-> id int,-> name varchar(12));
Query OK, 0 rows affected (0.01 sec)mysql> desc test_null;
+-------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------+------+-----+---------+-------+
| id | int(11) | YES | | NULL | |
| name | varchar(12) | YES | | NULL | |
+-------+-------------+------+-----+---------+-------+
2 rows in set (0.01 sec)下面插入数据,插入部分空值:
mysql> insert into test_null(id, name) values(1, '张三');
Query OK, 1 row affected (0.00 sec)mysql> insert into test_null(id, name) values(null, '李四');
Query OK, 1 row affected (0.00 sec)mysql> insert into test_null(id, name) values(3, null);
Query OK, 1 row affected (0.00 sec)mysql> select * from test_null;
+------+--------+
| id | name |
+------+--------+
| 1 | 张三 |
| NULL | 李四 |
| 3 | NULL |
+------+--------+
3 rows in set (0.00 sec)下面测试 = NULL:
mysql> select * from test_null where name=NULL;
Empty set (0.00 sec)mysql> select * from test_null where id=null;
Empty set (0.00 sec)上面两个查询都没有查询到结果,想要查询的NULL 的话可以使用 <=>
mysql> select * from test_null where id<=>null;
+------+--------+
| id | name |
+------+--------+
| NULL | 李四 |
+------+--------+
1 row in set (0.00 sec)mysql> select * from test_null where name<=>null;
+------+------+
| id | name |
+------+------+
| 3 | NULL |
+------+------+
1 row in set (0.00 sec)这样就查询到了,下面要是查询不为空的呢?能不能用 !=(不等于):
mysql> select * from test_null where name != null;
Empty set (0.00 sec)mysql> select * from test_null where id != null;
Empty set (0.00 sec)上面都没有查询到,其实查询不为空的话可以使用 <>:
但是其实查询 null 或者不为 null 还是喜欢用 is null 或者是 is not null:
mysql> select * from test_null where name is null;
+------+------+
| id | name |
+------+------+
| 3 | NULL |
+------+------+
1 row in set (0.00 sec)mysql> select * from test_null where name is not null;
+------+--------+
| id | name |
+------+--------+
| 1 | 张三 |
| NULL | 李四 |
+------+--------+
2 rows in set (0.00 sec)5.查询语文成绩在70~80之间的同学
mysql> select name, chinese from exam_result where chinese between 70 and 80;
+-----------+---------+
| name | chinese |
+-----------+---------+
| 赵姨娘 | 79 |
| 唐三藏 | 72 |
| 沙悟净 | 77 |
+-----------+---------+
3 rows in set (0.00 sec)6.查询英语成绩是99 和 93 和 19 和 30
mysql> select name, english from exam_result where english=99 or english=93 or english=19 or english=30;
+-----------+---------+
| name | english |
+-----------+---------+
| 林黛玉 | 99 |
| 赵姨娘 | 93 |
| 小白龙 | 19 |
+-----------+---------+
3 rows in set (0.00 sec)除了上面的方法还有一种方法:
mysql> select name, english from exam_result where english in (99, 93, 19, 30);
+-----------+---------+
| name | english |
+-----------+---------+
| 林黛玉 | 99 |
| 赵姨娘 | 93 |
| 小白龙 | 19 |
+-----------+---------+
3 rows in set (0.00 sec)下面的这个看起更好一点。
7.模糊匹配
%可以表示任意一个或者多个字符,_表示任意一个字符。
查询名字叫黛玉的:
mysql> select id, name from exam_result where name like '_黛玉';
+----+-----------+
| id | name |
+----+-----------+
| 1 | 林黛玉 |
+----+-----------+
1 row in set (0.00 sec)上面就是匹配任意一个字符,下面看一下匹配任意字符。
查询名字里面有“三” 的:
mysql> select id, name from exam_result where name like '%三%';
+----+-----------+
| id | name |
+----+-----------+
| 5 | 唐三藏 |
+----+-----------+
1 row in set (0.00 sec)排序
有时候我们需要对查询出来的数据进行排序,我们现在查询一下总分的排序:
mysql> select *, chinese+math+english from exam_result order by chinese+english+math;
+----+-----------+---------+------+---------+----------------------+
| id | name | chinese | math | english | chinese+math+english |
+----+-----------+---------+------+---------+----------------------+
| 7 | 小白龙 | 99 | 20 | 19 | 138 |
| 5 | 唐三藏 | 72 | 60 | 56 | 188 |
| 6 | 沙悟净 | 77 | 87 | 72 | 236 |
| 4 | 赵姨娘 | 79 | 90 | 93 | 262 |
| 3 | 薛宝钗 | 88 | 90 | 88 | 266 |
| 1 | 林黛玉 | 98 | 90 | 99 | 287 |
+----+-----------+---------+------+---------+----------------------+
6 rows in set (0.00 sec)我们上面这样写太繁琐了,我们可不可以使用重命名?
mysql> select *, chinese+math+english 总分 from exam_result order by 总分;
+----+-----------+---------+------+---------+--------+
| id | name | chinese | math | english | 总分 |
+----+-----------+---------+------+---------+--------+
| 7 | 小白龙 | 99 | 20 | 19 | 138 |
| 5 | 唐三藏 | 72 | 60 | 56 | 188 |
| 6 | 沙悟净 | 77 | 87 | 72 | 236 |
| 4 | 赵姨娘 | 79 | 90 | 93 | 262 |
| 3 | 薛宝钗 | 88 | 90 | 88 | 266 |
| 1 | 林黛玉 | 98 | 90 | 99 | 287 |
+----+-----------+---------+------+---------+--------+
6 rows in set (0.00 sec)这里又可以使用总分了,但是前面 where 不可以使用总分,为什么?
还是执行顺序的问题,首先我们要排序是不是要前面的数据都准备好了才进行排序,也就是说排序在重命名的后面,所以既然已经又重命名了所以排序就可以使用重命名。
我们看到上面的排序都是降序那么怎样可以让其升序呢?
order by 列名 ASC 降序 默认desc 升序下面可以试一下:
mysql> select *, chinese+math+english 总分 from exam_result order by 总分 ASC;
+----+-----------+---------+------+---------+--------+
| id | name | chinese | math | english | 总分 |
+----+-----------+---------+------+---------+--------+
| 7 | 小白龙 | 99 | 20 | 19 | 138 |
| 5 | 唐三藏 | 72 | 60 | 56 | 188 |
| 6 | 沙悟净 | 77 | 87 | 72 | 236 |
| 4 | 赵姨娘 | 79 | 90 | 93 | 262 |
| 3 | 薛宝钗 | 88 | 90 | 88 | 266 |
| 1 | 林黛玉 | 98 | 90 | 99 | 287 |
+----+-----------+---------+------+---------+--------+
6 rows in set (0.00 sec)mysql> select *, chinese+math+english 总分 from exam_result order by 总分 DESC;
+----+-----------+---------+------+---------+--------+
| id | name | chinese | math | english | 总分 |
+----+-----------+---------+------+---------+--------+
| 1 | 林黛玉 | 98 | 90 | 99 | 287 |
| 3 | 薛宝钗 | 88 | 90 | 88 | 266 |
| 4 | 赵姨娘 | 79 | 90 | 93 | 262 |
| 6 | 沙悟净 | 77 | 87 | 72 | 236 |
| 5 | 唐三藏 | 72 | 60 | 56 | 188 |
| 7 | 小白龙 | 99 | 20 | 19 | 138 |
+----+-----------+---------+------+---------+--------+
6 rows in set (0.00 sec)LIMIT
在 mysql 查询的时候其实防止一次性查出来的数据太多还有一个 limit 可以让数据可以分多次打印。
下面看一下 limit 的使用:
mysql> select * from exam_result limit 1;
+----+-----------+---------+------+---------+
| id | name | chinese | math | english |
+----+-----------+---------+------+---------+
| 1 | 林黛玉 | 98 | 90 | 99 |
+----+-----------+---------+------+---------+
1 row in set (0.00 sec)mysql> select * from exam_result limit 3;
+----+-----------+---------+------+---------+
| id | name | chinese | math | english |
+----+-----------+---------+------+---------+
| 1 | 林黛玉 | 98 | 90 | 99 |
| 3 | 薛宝钗 | 88 | 90 | 88 |
| 4 | 赵姨娘 | 79 | 90 | 93 |
+----+-----------+---------+------+---------+
3 rows in set (0.00 sec)其实 limit 还可以打印中间的内容:
mysql> select * from exam_result limit 0,3;
+----+-----------+---------+------+---------+
| id | name | chinese | math | english |
+----+-----------+---------+------+---------+
| 1 | 林黛玉 | 98 | 90 | 99 |
| 3 | 薛宝钗 | 88 | 90 | 88 |
| 4 | 赵姨娘 | 79 | 90 | 93 |
+----+-----------+---------+------+---------+
3 rows in set (0.00 sec)mysql> select * from exam_result limit 3,3;
+----+-----------+---------+------+---------+
| id | name | chinese | math | english |
+----+-----------+---------+------+---------+
| 5 | 唐三藏 | 72 | 60 | 56 |
| 6 | 沙悟净 | 77 | 87 | 72 |
| 7 | 小白龙 | 99 | 20 | 19 |
+----+-----------+---------+------+---------+
3 rows in set (0.00 sec)还可以给两个数字,前面的表示从第一个数字的下一行开始打印,第二个数字表示打印几行。
limit 还可以结合 offset 使用:
mysql> select * from exam_result limit 3 offset 0;
+----+-----------+---------+------+---------+
| id | name | chinese | math | english |
+----+-----------+---------+------+---------+
| 1 | 林黛玉 | 98 | 90 | 99 |
| 3 | 薛宝钗 | 88 | 90 | 88 |
| 4 | 赵姨娘 | 79 | 90 | 93 |
+----+-----------+---------+------+---------+
3 rows in set (0.00 sec)mysql> select * from exam_result limit 3 offset 1;
+----+-----------+---------+------+---------+
| id | name | chinese | math | english |
+----+-----------+---------+------+---------+
| 3 | 薛宝钗 | 88 | 90 | 88 |
| 4 | 赵姨娘 | 79 | 90 | 93 |
| 5 | 唐三藏 | 72 | 60 | 56 |
+----+-----------+---------+------+---------+
3 rows in set (0.00 sec)也可以让 limit 后面跟一个数字,然后加 offset 后面跟一个数字,其中 limit 后面的数字代表打印几行, offset 后面的数字代表从第几行开始打印。
相关文章:

MySQL 基本操作1
目录 Create insert 插入跟新 1 插入跟新 2 Retrive select where 子句查询 1.查找数学成绩小于 80 的同学。 2.查询数学成绩等于90分的同学。 3.查询总分大于240 的学生 4.查询空值或者非空值 5.查询语文成绩在70~80之间的同学 6.查询英语成绩是99 和 93 和 19 和…...
linux内网yum源服务器搭建
1.nginx: location / {root /usr/local/Kylin-Server-V10-SP3-General-Release-2303-X86_64;autoindex on;autoindex_localtime on;autoindex_exact_size off; } 注:指定到镜像的包名 2.修改yum源地址 cd /etc/yum.repos.d/vim kylin_x86_64.repo 注: --enabled设置为1 3.重…...
机器学习与数据分析
【数据清洗】 异常检测 孤立森林(Isolation Forest)从原理到实践 效果评估:F-score 【1】 保护隐私的时间序列异常检测架构 概率后缀树 PST – (异常检测) 【1】 UEBA架构设计之路5: 概率后缀树模型 【…...
项目总结知识点记录-文件上传下载(三)
(1)文件上传 代码: RequestMapping(value "doUpload", method RequestMethod.POST)public String doUpload(ModelAttribute BookHelper bookHelper, Model model, HttpSession session) throws IllegalStateException, IOExcepti…...

基于LinuxC语言实现的TCP多线程/进程服务器
多进程并发服务器 设计流程 框架一(使用信号回收僵尸进程) void handler(int sig) {while(waitpid(-1, NULL, WNOHANG) > 0); }int main() {//回收僵尸进程siganl(17, handler);//创建服务器监听套接字 serverserver socket();//给服务器地址信息…...

浅谈JVM垃圾回收机制
一、HotSpot VM中的GC分为两大类 1.部分收集(Partial GC): 新生代收集(Minor GC/Young GC):只对新生代进行垃圾收集老年代收集(Major GC/Old GC):只队老年代进行垃圾收集混合收集(Mixed GC):对整个新生代和老年代进行垃圾收集 2.整堆收集(Full GC) 收集整个Java堆和方法区 …...
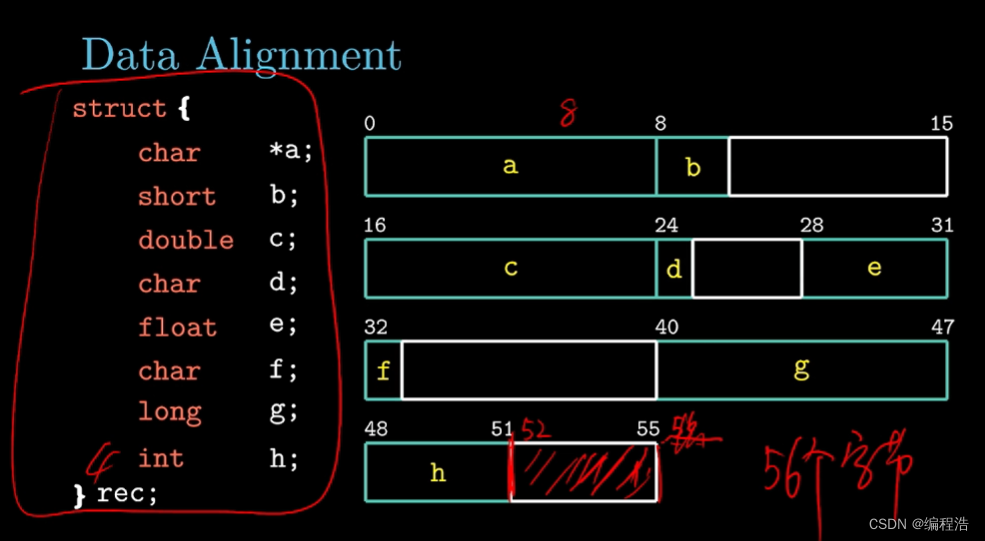
【80天学习完《深入理解计算机系统》】第十二天3.6数组和结构体
专注 效率 记忆 预习 笔记 复习 做题 欢迎观看我的博客,如有问题交流,欢迎评论区留言,一定尽快回复!(大家可以去看我的专栏,是所有文章的目录) 文章字体风格: 红色文字表示&#…...
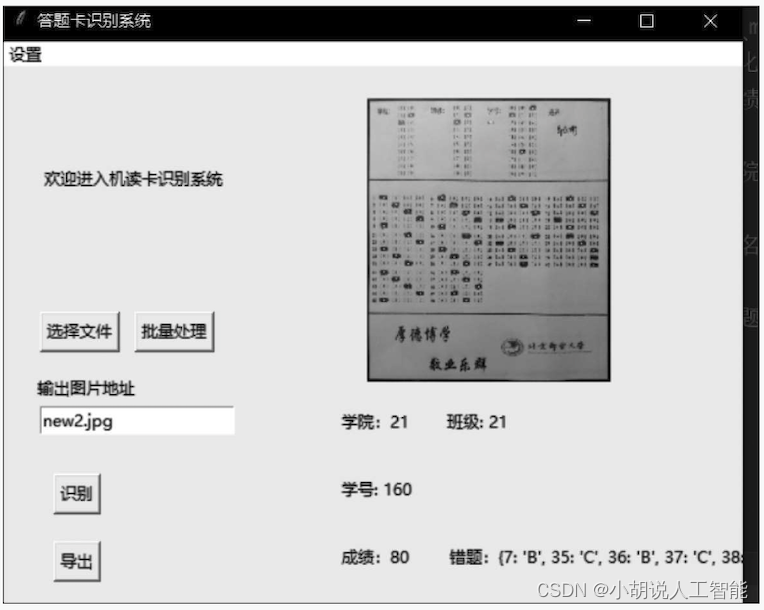
基于Python+OpenCV智能答题卡识别系统——深度学习和图像识别算法应用(含Python全部工程源码)+训练与测试数据集
目录 前言总体设计系统整体结构图系统流程图 运行环境Python 环境PyCharm安装OpenCV环境 模块实现1. 信息识别2. Excel导出模块3. 图形用户界面模块4. 手写识别模块 系统测试1. 系统识别准确率2. 系统识别应用 工程源代码下载其它资料下载 前言 本项目基于Python和OpenCV图像处…...
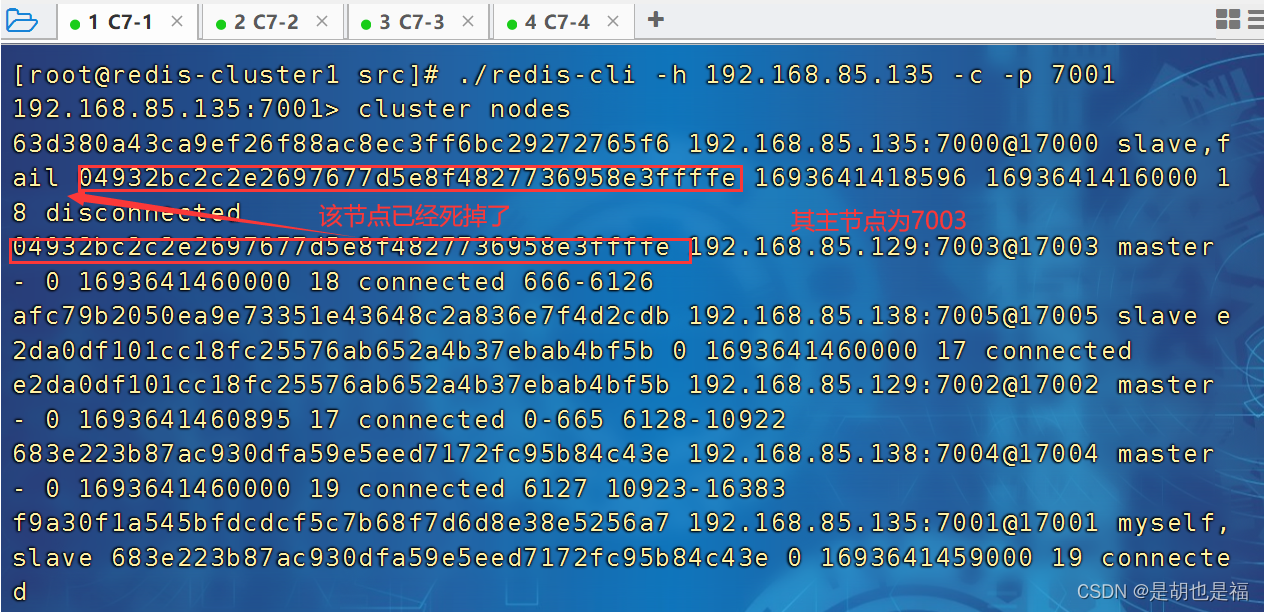
Redis集群操作-----主从互换
一、将节点cluster1的主节点7000端口的redis关掉 [rootredis-cluster1 src]# ps -ef |grep redis 二、查看集群信息:...

肖sir __linux命令拓展__05
linux命令拓展 1.追加内容到某文件 echo “i like learn linux” >>quzhi.txt 2.删除指定的空目录: rmdir 目录名 rmdir -p 目录名 (删除指定的空目录及其内子空目录) 3.显示zip包信息 zipinfo 压缩包名 (显示压缩包内的文…...
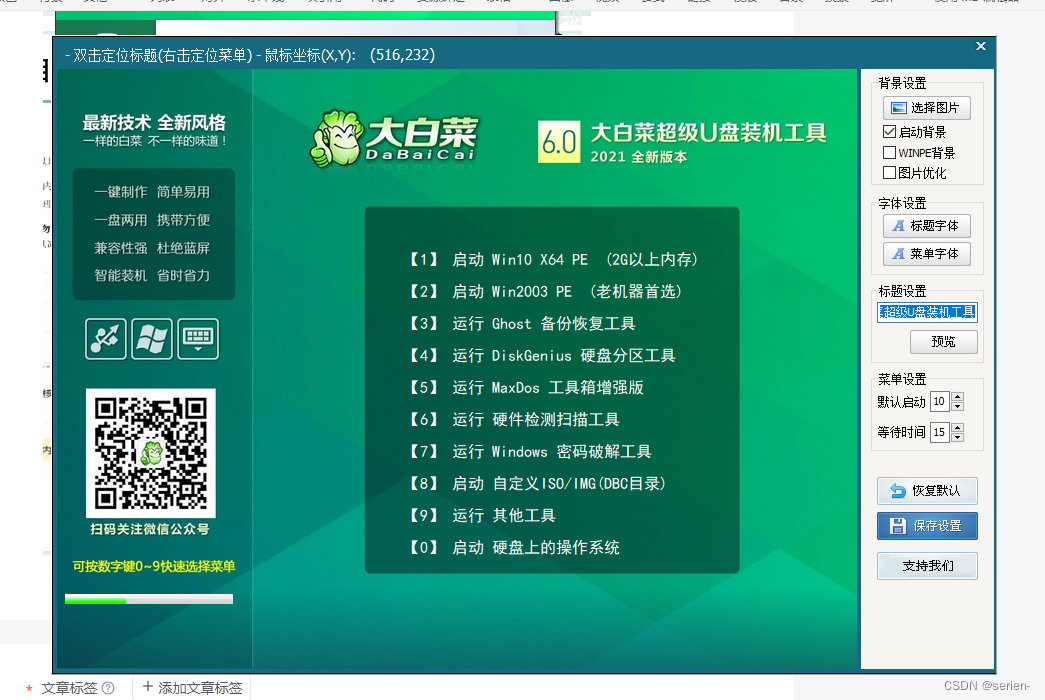
大白菜清理电脑密码教程
首先安装大白菜: 插入u盘一键制作启动盘 制作成功,重启进入u盘启动模式...

[libglog][FFmpeg] 如何把 ffmpeg 的库日志输出到 libglog里
ffmpeg 提供了自己的 log 模块 av_log,会默认把输出打印到 stderr 上,因此无法方便地跟踪日志。但是 ffmpeg 提供了一个接口 av_log_set_callback 以供外界自定义自己的日志输出。 libglog 提供的是c 形式的日志输出样式,因此需要将二者关联起…...
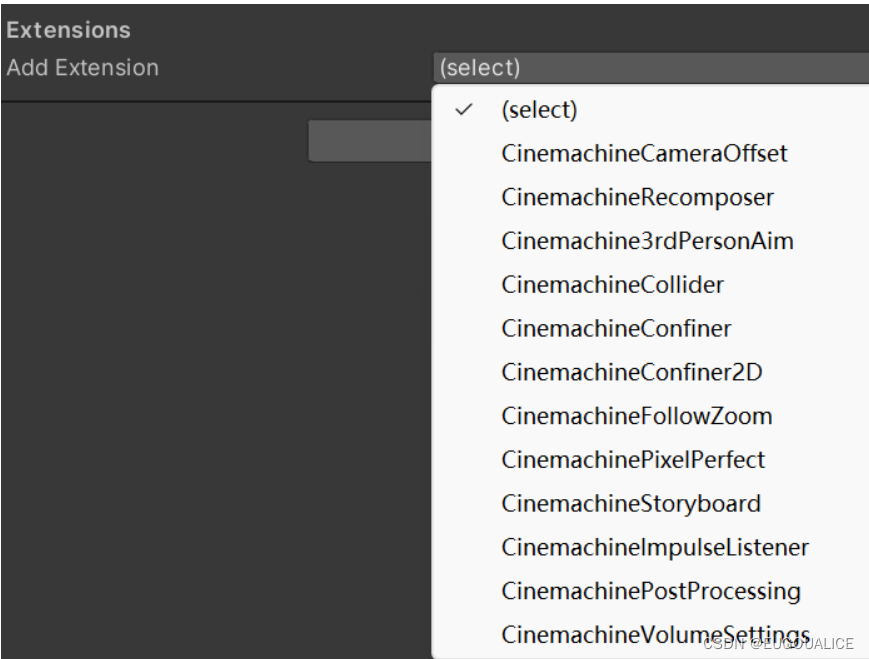
【Unity-Cinemachine相机】虚拟相机(Virtual Camera)的本质与基本属性
我们可以在游戏进行时修改各个属性,但在概念上,最好将Virtual Camera 当作一种相机行为的“配置文件”,而不是一个组件。 我们的相机有几种行为就为它准备几种虚拟相机,比如角色移动就为它第三人称相机,瞄准就准备一个…...

LeetCode:718. 最长重复子数组 - Python
718. 最长重复子数组 问题描述: 给两个整数数组 nums1 和 nums2 ,返回 两个数组中 公共的 、长度最长 的 子数组 的 长度 。 示例 1: 输入:nums1 [1,2,3,2,1], nums2 [3,2,1,4,7] 输出:3 解释:长度最长…...

【面试题精讲】Redis如何实现分布式锁
首发博客地址 系列文章地址 Redis 可以使用分布式锁来实现多个进程或多个线程之间的并发控制,以确保在给定时间内只有一个进程或线程可以访问临界资源。以下是一种使用 Redis 实现分布式锁的常见方法: 获取锁: 客户端尝试使用 SETNX命令在 Re…...

list【2】模拟实现(含迭代器实现超详解哦)
模拟实现list 引言(实现概述)list迭代器实现默认成员函数operator* 与 operator->operator 与 operator--operator 与 operator!迭代器实现概览 list主要接口实现默认成员函数构造函数析构函数赋值重载 迭代器容量元素访问数据修改inserterasepush_ba…...
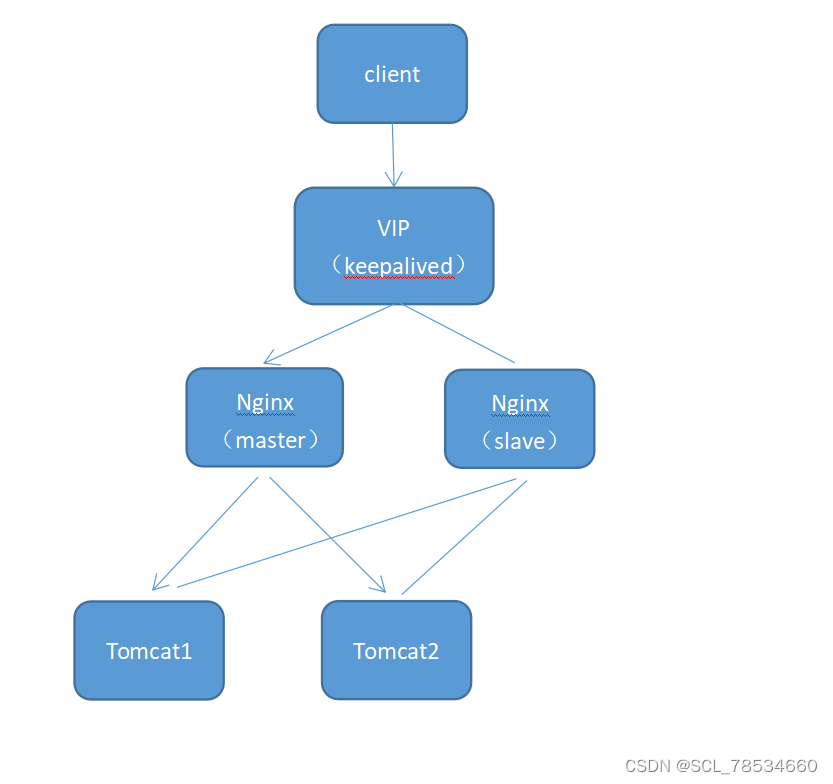
Nginx+Tomcat的动静分离与负载均衡
目录 前言 一、案例 二、Nginx的高级用法 三、tomcat部署 四、Nginx部署 五、测试 总结 前言 通常情况下,一个 Tomcat 站点由于可能出现单点故障及无法应付过多客户复杂多样的请求等情况,不能单独应用于生产环境下,所以我们需要一套更…...

【设计模式】Head First 设计模式——策略模式 C++实现
设计模式最大的作用就是在变化和稳定中间寻找隔离点,然后分离它们,从而管理变化。将变化像小兔子一样关到笼子里,让它在笼子里随便跳,而不至于跳出来把你整个房间给污染掉。 设计思想 将行为想象为一族算法,定义算法族…...

c#object类中方法的使用
C#中的Object类是所有类的基类,它定义了一些通用的方法和属性,可以在任何对象上使用。以下是Object类中常用的方法和属性的使用: 1.ToString():将对象转换为字符串表示形式。 string str obj.ToString();2.Equals():…...

三种常用盒子布局的方法
在Vue中,可以使用各种CSS布局属性和技巧来设置盒子的布局。以下是一些常用的方法: 1.使用Flexbox布局:在包含盒子的父元素上设置display: flex,然后可以使用flex-direction、justify-content和align-items 等属性来控制盒子的布局…...

【Python】 -- 趣味代码 - 小恐龙游戏
文章目录 文章目录 00 小恐龙游戏程序设计框架代码结构和功能游戏流程总结01 小恐龙游戏程序设计02 百度网盘地址00 小恐龙游戏程序设计框架 这段代码是一个基于 Pygame 的简易跑酷游戏的完整实现,玩家控制一个角色(龙)躲避障碍物(仙人掌和乌鸦)。以下是代码的详细介绍:…...

Vue记事本应用实现教程
文章目录 1. 项目介绍2. 开发环境准备3. 设计应用界面4. 创建Vue实例和数据模型5. 实现记事本功能5.1 添加新记事项5.2 删除记事项5.3 清空所有记事 6. 添加样式7. 功能扩展:显示创建时间8. 功能扩展:记事项搜索9. 完整代码10. Vue知识点解析10.1 数据绑…...

如何将联系人从 iPhone 转移到 Android
从 iPhone 换到 Android 手机时,你可能需要保留重要的数据,例如通讯录。好在,将通讯录从 iPhone 转移到 Android 手机非常简单,你可以从本文中学习 6 种可靠的方法,确保随时保持连接,不错过任何信息。 第 1…...

初学 pytest 记录
安装 pip install pytest用例可以是函数也可以是类中的方法 def test_func():print()class TestAdd: # def __init__(self): 在 pytest 中不可以使用__init__方法 # self.cc 12345 pytest.mark.api def test_str(self):res add(1, 2)assert res 12def test_int(self):r…...

代码规范和架构【立芯理论一】(2025.06.08)
1、代码规范的目标 代码简洁精炼、美观,可持续性好高效率高复用,可移植性好高内聚,低耦合没有冗余规范性,代码有规可循,可以看出自己当时的思考过程特殊排版,特殊语法,特殊指令,必须…...

Golang——9、反射和文件操作
反射和文件操作 1、反射1.1、reflect.TypeOf()获取任意值的类型对象1.2、reflect.ValueOf()1.3、结构体反射 2、文件操作2.1、os.Open()打开文件2.2、方式一:使用Read()读取文件2.3、方式二:bufio读取文件2.4、方式三:os.ReadFile读取2.5、写…...

基于Java+VUE+MariaDB实现(Web)仿小米商城
仿小米商城 环境安装 nodejs maven JDK11 运行 mvn clean install -DskipTestscd adminmvn spring-boot:runcd ../webmvn spring-boot:runcd ../xiaomi-store-admin-vuenpm installnpm run servecd ../xiaomi-store-vuenpm installnpm run serve 注意:运行前…...
)
安卓基础(Java 和 Gradle 版本)
1. 设置项目的 JDK 版本 方法1:通过 Project Structure File → Project Structure... (或按 CtrlAltShiftS) 左侧选择 SDK Location 在 Gradle Settings 部分,设置 Gradle JDK 方法2:通过 Settings File → Settings... (或 CtrlAltS)…...

在树莓派上添加音频输入设备的几种方法
在树莓派上添加音频输入设备可以通过以下步骤完成,具体方法取决于设备类型(如USB麦克风、3.5mm接口麦克风或HDMI音频输入)。以下是详细指南: 1. 连接音频输入设备 USB麦克风/声卡:直接插入树莓派的USB接口。3.5mm麦克…...

【SpringBoot自动化部署】
SpringBoot自动化部署方法 使用Jenkins进行持续集成与部署 Jenkins是最常用的自动化部署工具之一,能够实现代码拉取、构建、测试和部署的全流程自动化。 配置Jenkins任务时,需要添加Git仓库地址和凭证,设置构建触发器(如GitHub…...