如何使用Puppeteer进行新闻网站数据抓取和聚合
导语
Puppeteer是一个基于Node.js的库,它提供了一个高级的API来控制Chrome或Chromium浏览器。通过Puppeteer,我们可以实现各种自动化任务,如网页截图、PDF生成、表单填写、网络监控等。本文将介绍如何使用Puppeteer进行新闻网站数据抓取和聚合,以网易新闻和杭州亚运会为例。
概述
数据抓取是指从网页中提取所需的数据,如标题、正文、图片、链接等。数据聚合是指将多个来源的数据整合在一起,形成一个统一的视图或报告。数据抓取和聚合是爬虫技术的常见应用场景,它可以帮助我们获取最新的信息,分析舆情,发现趋势等。
使用Puppeteer进行数据抓取和聚合的基本步骤如下:
- 安装Puppeteer库和相关依赖
- 创建一个Puppeteer实例,并启动一个浏览器
- 打开一个新的页面,并设置代理IP和请求头
- 访问目标网站,并等待页面加载完成
- 使用选择器或XPath定位元素,并获取元素的属性或文本
- 将获取的数据存储到本地文件或数据库中
- 关闭页面和浏览器
正文
安装Puppeteer库和相关依赖
要使用Puppeteer,我们首先需要安装Node.js环境,以及Puppeteer库和相关依赖。我们可以使用npm命令来安装,如下所示:
// 在命令行中执行以下命令,安装Puppeteer库
npm install puppeteer// 安装http-proxy-agent模块,用于设置代理IP
npm install http-proxy-agent// 安装cheerio模块,用于解析HTML文档
npm install cheerio
创建一个Puppeteer实例,并启动一个浏览器
接下来,我们需要创建一个Puppeteer实例,并启动一个浏览器。我们可以使用puppeteer.launch方法来实现,该方法接受一个可选的配置对象作为参数,其中可以设置浏览器的各种选项,如是否显示界面、是否启用沙盒模式、是否忽略HTTPS错误等。例如:
// 引入puppeteer模块
const puppeteer = require('puppeteer');// 创建一个异步函数,用于执行爬虫任务
(async () => {// 创建一个Puppeteer实例,并启动一个浏览器,设置headless为false表示显示界面const browser = await puppeteer.launch({ headless: false });
})();
打开一个新的页面,并设置代理IP和请求头
然后,我们需要打开一个新的页面,并设置代理IP和请求头。我们可以使用browser.newPage方法来创建一个新的页面对象,该对象提供了与页面交互的各种方法和事件。我们可以使用page.setExtraHTTPHeaders方法来设置请求头,以模拟正常的浏览器行为。我们还可以使用page.authenticate方法来设置代理IP,以避免被目标网站屏蔽或限制。例如:
// 引入http-proxy-agent模块,用于创建代理对象
const HttpProxyAgent = require('http-proxy-agent');// 创建一个异步函数,用于执行爬虫任务
(async () => {// 创建一个Puppeteer实例,并启动一个浏览器,设置headless为false表示显示界面const browser = await puppeteer.launch({ headless: false });// 打开一个新的页面const page = await browser.newPage();// 设置请求头,模拟正常的浏览器行为await page.setExtraHTTPHeaders({'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8','User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36',});// 设置代理IP,使用亿牛云爬虫代理的域名、端口、用户名、密码await page.authenticate({username: '16YUN',password: '16IP',agent: new HttpProxyAgent('http://www.16yun.cn:9020'),});
})();
访问目标网站,并等待页面加载完成
接下来,我们需要访问目标网站,并等待页面加载完成。我们可以使用page.goto方法来访问一个URL,该方法返回一个Promise对象,表示页面导航的结果。我们可以使用await关键字来等待Promise对象的解决,或者使用then方法来添加回调函数。我们还可以使用page.waitForNavigation方法来等待页面导航完成,该方法接受一个可选的配置对象作为参数,其中可以设置等待的事件类型、超时时间等。例如:
// 创建一个异步函数,用于执行爬虫任务
(async () => {// 创建一个Puppeteer实例,并启动一个浏览器,设置headless为false表示显示界面const browser = await puppeteer.launch({ headless: false });// 打开一个新的页面const page = await browser.newPage();// 设置请求头,模拟正常的浏览器行为await page.setExtraHTTPHeaders({'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8','User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36',});// 设置代理IP,使用亿牛云爬虫代理的域名、端口、用户名、密码await page.authenticate({username: '16YUN',password: '16IP',agent: new HttpProxyAgent('http://www.16yun.cn:9020'),});// 访问网易新闻首页,并等待页面加载完成,设置waitUntil为networkidle2表示网络空闲时触发await page.goto('https://news.163.com/', {waitUntil: 'networkidle2',});
})();
使用选择器或XPath定位元素,并获取元素的属性或文本
然后,我们需要使用选择器或XPath定位元素,并获取元素的属性或文本。我们可以使用page.$方法来获取多个元素。这些方法接受一个字符串作为参数,表示选择器或XPath表达式。我们还可以使用page.evaluate方法来在页面上执行JavaScript代码,并返回执行结果。我们可以使用这个方法来获取元素的属性或文本,或者进行其他操作。例如:
// 创建一个异步函数,用于执行爬虫任务
(async () => {// 创建一个Puppeteer实例,并启动一个浏览器,设置headless为false表示显示界面const browser = await puppeteer.launch({ headless: false });// 打开一个新的页面const page = await browser.newPage();// 设置请求头,模拟正常的浏览器行为await page.setExtraHTTPHeaders({'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8','User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36',});// 设置代理IP,使用亿牛云爬虫代理的域名、端口、用户名、密码 await page.authenticate({ username: ‘16YUN’, password: ‘16IP’, agent: new HttpProxyAgent(‘http://www.16yun.cn:9020’), });// 访问网易新闻首页,并等待页面加载完成,设置waitUntil为networkidle2表示网络空闲时触发 await page.goto(‘https://news.163.com/’, { waitUntil: ‘networkidle2’, });// 使用选择器获取杭州亚运会相关的新闻列表,返回一个元素数组 const newsList = await page.$$(‘.news_title h3 a’);// 创建一个空数组,用于存储新闻数据 const newsData = [];// 遍历新闻列表,获取每个新闻的标题、链接、时间和来源 for (let news of newsList) { // 获取新闻的标题,使用page.evaluate方法在页面上执行JavaScript代码,并返回执行结果 const title = await page.evaluate((el) => el.innerText, news);// 获取新闻的链接,使用page.evaluate方法在页面上执行JavaScript代码,并返回执行结果 const link = await page.evaluate((el) => el.href, news);// 获取新闻的时间和来源,使用page.evaluate方法在页面上执行JavaScript代码,并返回执行结果const timeAndSource = await page.evaluate((el) => el.parentElement.nextElementSibling.innerText,news);// 将新闻数据添加到数组中newsData.push({title,link,timeAndSource,});}// 打印新闻数据 console.log(newsData); })();
案例
运行上述代码,我们可以得到如下输出:
[{title: '杭州亚运会倒计时200天 火炬接力将于5月15日启动',link: 'https://news.163.com/21/0829/17/GTQ1H7F60001899O.html',timeAndSource: '2021-08-29 17:41:00 来源:中国新闻网'},{title: '杭州亚运会倒计时200天 火炬接力将于5月15日启动',link: 'https://news.163.com/21/0829/17/GTQ1H7F60001899O.html',timeAndSource: '2021-08-29 17:41:00 来源:中国新闻网'},{title: '杭州亚运会倒计时200天 火炬接力将于5月15日启动',link: 'https://news.163.com/21/0829/17/GTQ1H7F60001899O.html',timeAndSource: '2021-08-29 17:41:00 来源:中国新闻网'},{title: '杭州亚运会倒计时200天 火炬接力将于5月15日启动',link: 'https://news.163.com/21/0829/17/GTQ1H7F60001899O.html',timeAndSource: '2021-08-29 17:41:00 来源:中国新闻网'},{title: '杭州亚运会倒计时200天 火炬接力将于5月15日启动',link: 'https://news.163.com/21/0829/17/GTQ1H7F60001899O.html',timeAndSource: '2021-08-29 17:41:00 来源:中国新闻网'}
]
这样,我们就成功地使用Puppeteer进行了新闻网站数据抓取和聚合。
结语
本文介绍了如何使用Puppeteer进行新闻网站数据抓取和聚合,以网易新闻和杭州亚运会为例。Puppeteer是一个强大的库,它可以让我们轻松地控制浏览器,实现各种自动化任务。通过使用代理IP,我们可以提高爬虫的效果,避免被目标网站屏蔽或限制。
相关文章:

如何使用Puppeteer进行新闻网站数据抓取和聚合
导语 Puppeteer是一个基于Node.js的库,它提供了一个高级的API来控制Chrome或Chromium浏览器。通过Puppeteer,我们可以实现各种自动化任务,如网页截图、PDF生成、表单填写、网络监控等。本文将介绍如何使用Puppeteer进行新闻网站数据抓取和聚…...
【LeetCode每日一题合集】2023.8.7-2023.8.13(动态规划分治)
文章目录 344. 反转字符串1749. 任意子数组和的绝对值的最大值(最大子数组和)1281. 整数的各位积和之差1289. 下降路径最小和 II解法1——动态规划 O ( n 3 ) O(n^3) O(n3)解法2——转移过程优化 O ( n 2 ) O(n^2) O(n2) ⭐ 1572. 矩阵对角线元素的和解法…...

微信小程序修改vant组件样式
1 背景 在使用vant组件开发微信小程序的时候,想更改vant组件内部样式,达到自己想要的目的(van-grid组件改成宫格背景色为透明,默认为白色),官网没有示例,通过以下几步修改成功。 2 步骤 2.1 …...

yum 、rpm、yumdownloader、repotrack 学习笔记
1 Linux 包管理器概述 rpm的使用: rpm -ivh filename.rpm#这列出该packageName(包名)安装的所有文件列表。 rpm -ql packageName #查询已安装的该packageName的详细信息,包括版本、发布日期等。 rpm -qi packageName #列出该pac…...

python检测CPU占用、内存和磁盘剩余空间 脚本
python检测CPU占用、内存和磁盘剩余空间 脚本。后续将其加入到计划列表中即可 # codingutf-8 import time import psutil import osimport smtplibfrom email.mime.multipart import MIMEMultipart from email.mime.text import MIMEText # email 用于构建邮件内容 from email…...

量化策略:CTA,市场中性,指数增强
CTA 策略 commodity Trading Advisor Strategy,即“商品交易顾问策略”,也被称作管理期货策略。 期货T0,股票T1双向交易:就单向交易而言的,不仅能先买入再卖出(做多),而且可以先卖…...
 测试点全过)
L1-051 打折(Python实现) 测试点全过
前言: {\color{Blue}前言:} 前言: 本系列题使用的是,“PTA中的团体程序设计天梯赛——练习集”的题库,难度有L1、L2、L3三个等级,分别对应团体程序设计天梯赛的三个难度。更新取决于题目的难度,…...
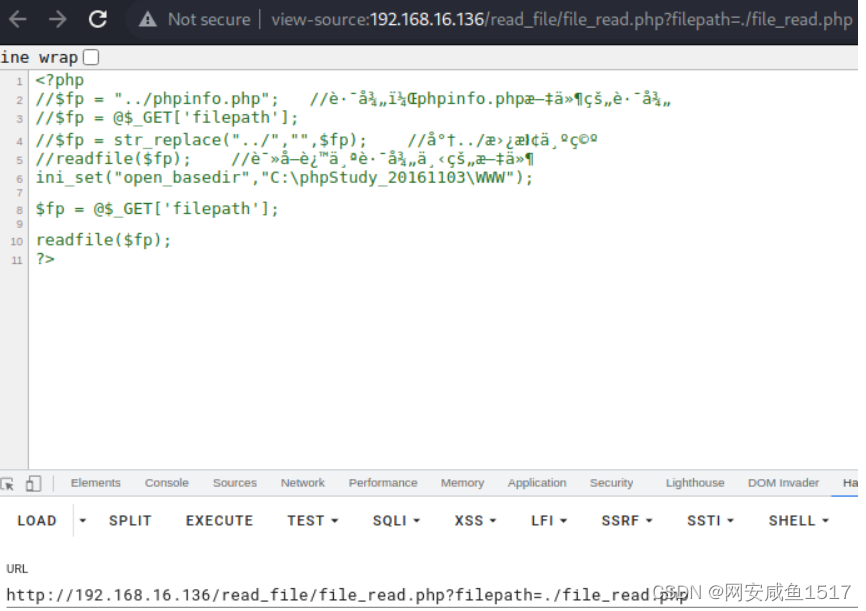
任意文件读取和漏洞复现
任意文件读取 1. 概述 一些网站的需求,可能会提供文件查看与下载的功能。如果对用户查看或下载的文件没有限制或者限制绕过,就可以查看或下载任意文件。这些文件可以是漂代码文件,配置文件,敏感文件等等。 任意文件读取会造成&…...
编译KArchive在windows10下
使用QT6和VS2019编译KArchive的简要步骤: 安装 Qt ,我是用源码自己编译的 "F:\qtbuild"安装CMakefile并配置环境变量安装Git下载ECM源码 https://github.com/KDE/extra-cmake-modules.git-------------------------------------------------…...

【Python】批量下载页面资源
【背景】 有一些非常不错的资源网站,比如一些MP3资源网站。资源很丰富,但是每一个资源都不大,一个一个下载费时费力,想用Python快速实现可复用的批量下载程序。 【思路】 获得包含资源链接的静态页面,用beautifulsoup分析页面,获得所有MP3资源的实际地址,然后下载。…...
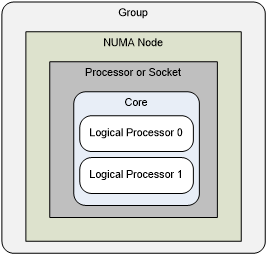
Windows NUMA编程实践 – 处理器组、组亲和性、处理器亲和性及版本变化
Windows在设计之初没有考虑过对大数量的多CPU和NUMA架构的设备的支持,大部分关于CPU的设计按照64个为上限来设计。核心数越来越多的多核处理器的进入市场使得微软不得不做较大的改动来进行支持,因此Windows 的进程、线程和NUMA API在各个版本中行为不一样…...
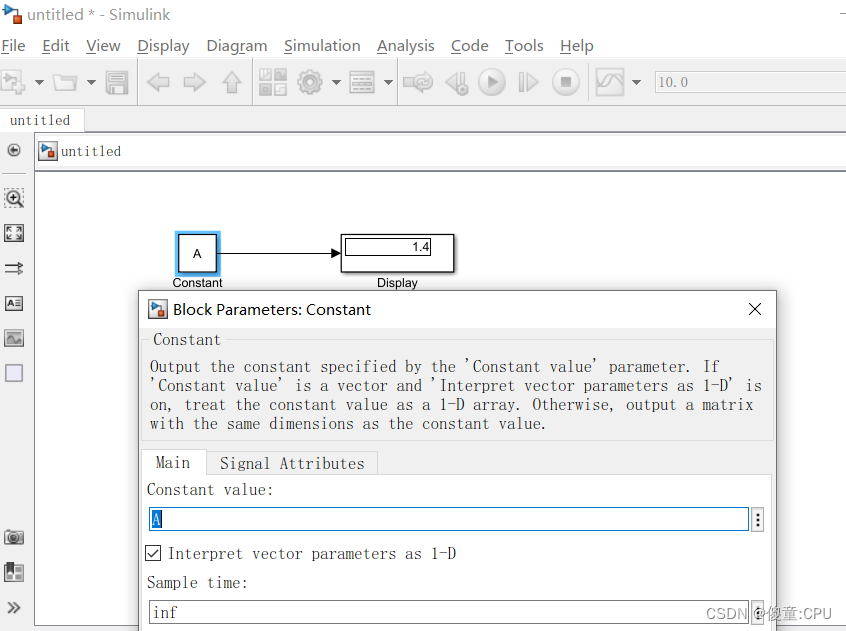
MATLAB中编译器中的变量联系到Simulink
MATLAB中编译器中的变量联系到Simulink 现在编译器中创建变量,进行编译,使其生成在工作区。 然后在Simulink中国使用变量即可。...

开展自动化方案时,需要考虑哪些内容,开展实施前需要做哪些准备呢?
在开展软件自动化测试方案时,需要考虑以下方面: 选择合适的自动化测试工具:根据项目的需求和技术栈选择适合的自动化测试工具,如Selenium、Appium、Jenkins等。确定自动化测试范围:明确需要自动化的功能模块和业务场景…...

进程、线程、内存管理
目录 进程和线程区别 进程和线程切换的区别 系统调用流程 系统调用是否会引起线程切换 为什么需要使用虚拟内存 进程和线程区别 本质区别: 进程是资源分配的基本单元。 线程是操作系统调度的基本单元。 地址空间: 进程具有独立的虚拟地址空间。 线程…...
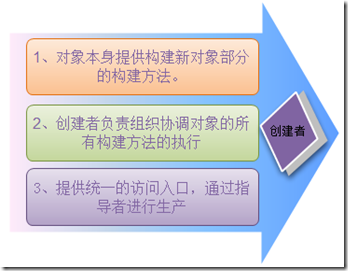
设计模式系列-创建者模式
一、上篇回顾 上篇我们主要讲述了抽象工厂模式和工厂模式。并且分析了该模式的应用场景和一些优缺点,并且给出了一些实现的思路和方案,我们现在来回顾一下: 抽象工厂模式:一个工厂负责所有类型对象的创建,支持无缝的新增新的类型对…...

加工生产调度
题目描述 某工厂收到了 n 个产品的订单,这 n 个产品分别在 A、B 两个车间加工,并且必须先在 A 车间加工后才可以到 B 车间加工。 某个产品 在 A,B 两车间加工的时间分别为 。怎样安排这 n 个产品的加工顺序,才能使总的加工时间…...
Hadoop 集群小文件归档 HAR、小文件优化 Uber 模式
文章目录 小文件归档 HAR小文件优化 Uber 模式 小文件归档 HAR 小文件归档是指将大量小文件合并成较大的文件,从而减少存储开销、元数据管理的开销以及处理时的任务调度开销。 这里我们通过 Hadoop Archive (HAR) 来进行实现,它是一种归档格式…...

Android OkHttp源码阅读详解一
博主前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住也分享一下给大家 👉点击跳转到教程 前言:源码阅读基于okhttp:3.10.0 Android中OkHttp源码阅读二(责任链模式) implementation com.squareup.o…...

UG\NX CAM二次开发 查询工序所在的方法组TAG UF_OPER_ask_method_group
文章作者:代工 来源网站:NX CAM二次开发专栏 简介: UG\NX CAM二次开发 查询工序所在的方法组TAG UF_OPER_ask_method_group 效果: 代码: void MyClass::do_it() { int count=0;tag_t * objects;UF_UI_ONT_ask_selected_nodes(&count, &objects);for (i…...

npm获取函数名称和测试js脚本
这边遇到一个类似于测试的需求,需要从一个js文件里获取函数名,然后尝试执行这些函数和创建实例。这边首先遇到了一个问题是如何动态获取js里的函数名和类名,我这边暂时没找到特别好的方法,已有的方法都是类似于提取语法树那种提取…...

TDengine 快速体验(Docker 镜像方式)
简介 TDengine 可以通过安装包、Docker 镜像 及云服务快速体验 TDengine 的功能,本节首先介绍如何通过 Docker 快速体验 TDengine,然后介绍如何在 Docker 环境下体验 TDengine 的写入和查询功能。如果你不熟悉 Docker,请使用 安装包的方式快…...

江苏艾立泰跨国资源接力:废料变黄金的绿色供应链革命
在华东塑料包装行业面临限塑令深度调整的背景下,江苏艾立泰以一场跨国资源接力的创新实践,重新定义了绿色供应链的边界。 跨国回收网络:废料变黄金的全球棋局 艾立泰在欧洲、东南亚建立再生塑料回收点,将海外废弃包装箱通过标准…...

大模型多显卡多服务器并行计算方法与实践指南
一、分布式训练概述 大规模语言模型的训练通常需要分布式计算技术,以解决单机资源不足的问题。分布式训练主要分为两种模式: 数据并行:将数据分片到不同设备,每个设备拥有完整的模型副本 模型并行:将模型分割到不同设备,每个设备处理部分模型计算 现代大模型训练通常结合…...

数据库分批入库
今天在工作中,遇到一个问题,就是分批查询的时候,由于批次过大导致出现了一些问题,一下是问题描述和解决方案: 示例: // 假设已有数据列表 dataList 和 PreparedStatement pstmt int batchSize 1000; // …...

学校时钟系统,标准考场时钟系统,AI亮相2025高考,赛思时钟系统为教育公平筑起“精准防线”
2025年#高考 将在近日拉开帷幕,#AI 监考一度冲上热搜。当AI深度融入高考,#时间同步 不再是辅助功能,而是决定AI监考系统成败的“生命线”。 AI亮相2025高考,40种异常行为0.5秒精准识别 2025年高考即将拉开帷幕,江西、…...

Java 二维码
Java 二维码 **技术:**谷歌 ZXing 实现 首先添加依赖 <!-- 二维码依赖 --><dependency><groupId>com.google.zxing</groupId><artifactId>core</artifactId><version>3.5.1</version></dependency><de…...

服务器--宝塔命令
一、宝塔面板安装命令 ⚠️ 必须使用 root 用户 或 sudo 权限执行! sudo su - 1. CentOS 系统: yum install -y wget && wget -O install.sh http://download.bt.cn/install/install_6.0.sh && sh install.sh2. Ubuntu / Debian 系统…...

【多线程初阶】单例模式 指令重排序问题
文章目录 1.单例模式1)饿汉模式2)懒汉模式①.单线程版本②.多线程版本 2.分析单例模式里的线程安全问题1)饿汉模式2)懒汉模式懒汉模式是如何出现线程安全问题的 3.解决问题进一步优化加锁导致的执行效率优化预防内存可见性问题 4.解决指令重排序问题 1.单例模式 单例模式确保某…...

中国政务数据安全建设细化及市场需求分析
(基于新《政务数据共享条例》及相关法规) 一、引言 近年来,中国政府高度重视数字政府建设和数据要素市场化配置改革。《政务数据共享条例》(以下简称“《共享条例》”)的发布,与《中华人民共和国数据安全法》(以下简称“《数据安全法》”)、《中华人民共和国个人信息…...

学习 Hooks【Plan - June - Week 2】
一、React API React 提供了丰富的核心 API,用于创建组件、管理状态、处理副作用、优化性能等。本文档总结 React 常用的 API 方法和组件。 1. React 核心 API React.createElement(type, props, …children) 用于创建 React 元素,JSX 会被编译成该函数…...