在 Amazon 搭建无代码可视化的数据分析和建模平台
现代企业常常会有利用数据分析和机器学习帮助解决业务痛点的需求。如制造业中,利用设备采集上来的数据做预测性维护,质量控制;在零售业中,利用客户端端采集的数据做渠道转化率分析,个性化推荐等。
| 亚马逊云科技开发者社区为开发者们提供全球的开发技术资源。这里有技术文档、开发案例、技术专栏、培训视频、活动与竞赛等。帮助中国开发者对接世界最前沿技术,观点,和项目,并将中国优秀开发者或技术推荐给全球云社区。如果你还没有关注/收藏,看到这里请一定不要匆匆划过,点这里让它成为你的技术宝库! |
通常业务部门需要提需求给技术团队,技术团队将业务需求转换为技术需求,调动数据工程师,数据科学家,机器学习工程师等,做数据处理、分析以及建模,整个流程较长,需要比较高的跨团队沟通成本,且对企业人才储备技能有要求。 客户业务部门普遍期望降低使用机器学习解决业务问题的门槛和学习成本,使得业务分析人员可以较少借助数据科学家和数据工程师,快速解决特定领域的业务数据洞察。
本文以汽车行业的故障分析为例,演示如何在亚马逊云科技上构建一套无代码数据分析平台,业务人员不需要有编程能力、 SQL 或任何机器学习的先验知识,即可自行根据业务场景和具体需求,自助式的上传导入数据做出分析,从而帮助业务人员以最短的时间,最方便的使用数据。
场景和痛点
车辆的异常故障率通常受多个因素影响,比如生产批次问题,使用年限,经销商维保等。
在过去,质保部门被动的接受零散客户的问题上报和维修请求,当某车型或某批次的问题积攒到一定程度乃至爆发后,才能定位这部分车辆的问题统一进行召回。突然的故障爆发使得相关部门没办法提前预算出维修经费,没法提前准备备件,没法提前做管控措施,也影响车主的体验。
因此,对车辆质保数据做数据分析,对故障发生情况做基于时序的分析或者聚类分析,并根据现有数据对故障趋势进行预测,可以帮助业务部门实现质量预警,质量改善的目标,有助于企业和部门提前做预算,提前采取相应措施降低整体维修费用。
技术目标
基于实销车辆数据,以及车辆维修数据 ( 两个 Schema 如下表所示),基于车型,绘制出可以描述故障发生情况的曲线, 对曲线进行分类,归纳出相似的故障曲线,筛选出异常的故障曲线,以达到对异常故障进行预测,提前预警的目的。
- 车型故障曲线 :如根据时间、行驶里程数、车龄等维度的车辆故障数增长曲线。 本文以车龄这个维度为示例,其他条件类似,只是聚合条件发生变化。
- 归纳相似形状,筛选异常故障曲线
- 根据现有数据预测趋势
Sampling Schema
- Repair data
- Sales data
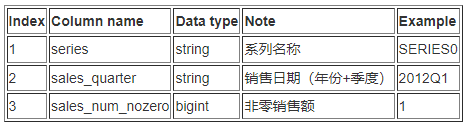
架构
- 选择 Glue Databrew 作为主要数据处理的工具。 Amazon Glue Databrew 提供一个可视化的工具,可以帮助数据分析师和数据科学家对数据做数据清洗和转换,从而方便后续将数据应用到分析和机器学习的场景。Glue Databrew 提供多达 250 种预构建转换中的操作,都可通过 UI 自动执行,不需要任何代码。比如,筛选异常数据、将数据转换为标准格式以及纠正无效值等等。
- 利用 Glue 做数据格式(Schema)的爬取,通过 Athena 作为 connector,最终用 QuickSight 作为 BI 展示工具,做 dashboard 展示
- 利用 Databrew 处理后的数据作为模型输入,利用 Sagemaker Canvas 生成预测模型。Amazon SageMaker Canvas 通过为业务分析师提供可视化、点击式的界面来扩展对机器学习 (ML) 的访问,利用AutoML 技术,根据您的独特用例自动创建 ML 模型,而无需任何机器学习经验或编写任何代码。 同时SageMaker Canvas 与 Amazon SageMaker Studio 集成,使业务分析师可以更轻松地与数据科学家共享模型和数据集,以便他们验证和进一步优化 ML 模型。
前提条件
- Glue Databrew 在大多数区域已经支持(包括北京和宁夏区),可在控制台切换至目标区域。 SageMaker Canvas 目前在部分区域推出,具体 region 请参考此 FAQ 文档。本文使用 Ohio (us-east-2) 为例。
- 将样本数据先存储在目标区域的某个 S3 桶中。如您不了解如何上传,请参考此 S3 文档
方案步骤
1. Glue Databrew 进行数据转换
该章节完成如下功能
- 无效数据清理
- 转换车辆维修数据,以适配销售数据
- 车辆维修数据和销售数据的合并
- 按照车型和车龄聚合数据
- 计算故障率
详细步骤
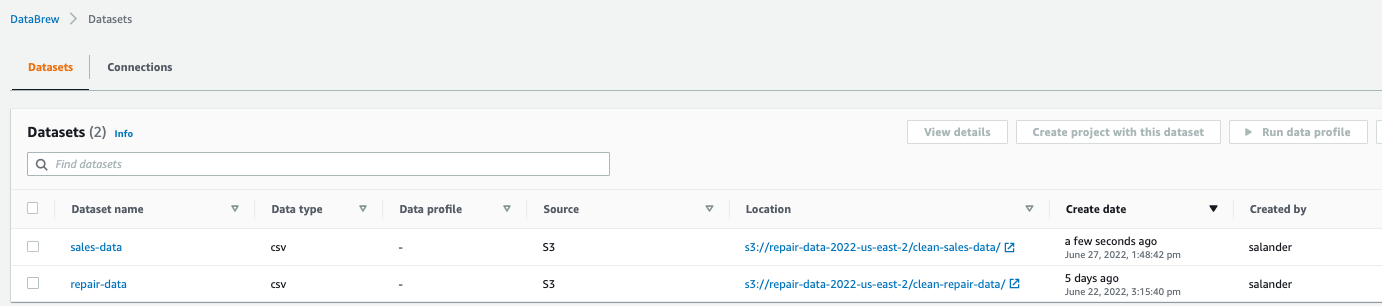
1.打开 Databrew 控制台,点击左侧栏 “数据集 (Datasets)”, 点击 “连接新数据集 (Connect new dataset)” 以创建数据源
2.在为数据集命名 (如 “repair-data”) 并选择 S3 的存储位置,数据格式 csv,采用默认分隔符 “,” ,点击创建数据集。同理,创建命为 sales-data 的数据集,csv 格式,默认分隔符 “,” 创建数据集。
3.选中刚创建好的数据集 repair-data,选择 “使用此数据集创建项目 (create project with dataset)” , 输入项目名称和配方名称,选择现有的或者新创建一个 IAM Role,需确保此 IAM Role 有权连接到所选的数据。点击 创建项目。 等待 DataBrew 界面的加载。
4.第一步, 无效数据的清理。
(1)选择 CarAgeDay 这一列(代表按天计算的车龄),点击 filter,并选择仅保留大于0的数据(或者根据需求,自定义此值)。如图所属,编辑完 Greater than 0 的条件后,点击 add to recipe,此时会在右侧生成浏览,请点击 APPLY 以生效
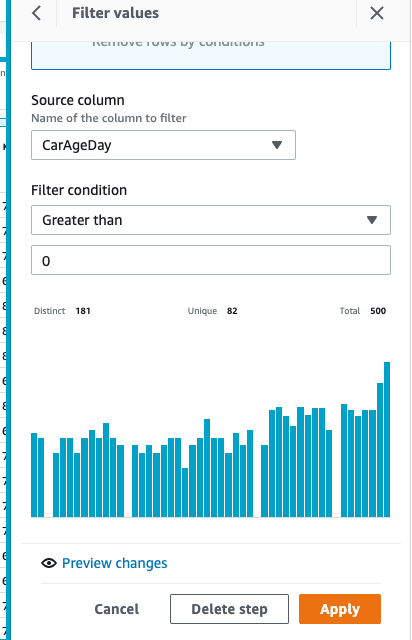
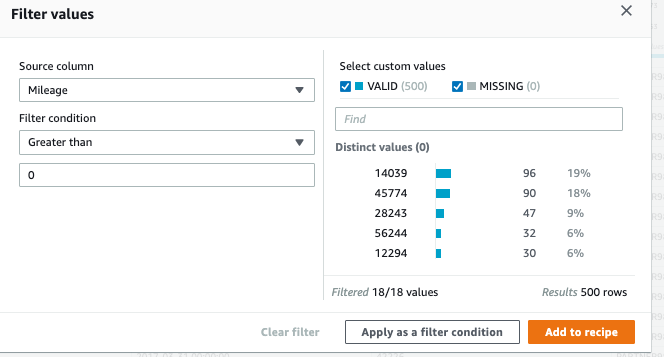
(2)将 mileage 进行 filter,只保留大于0的有效数据。同样点击 add to recipe 然后点击 apply 以生效。
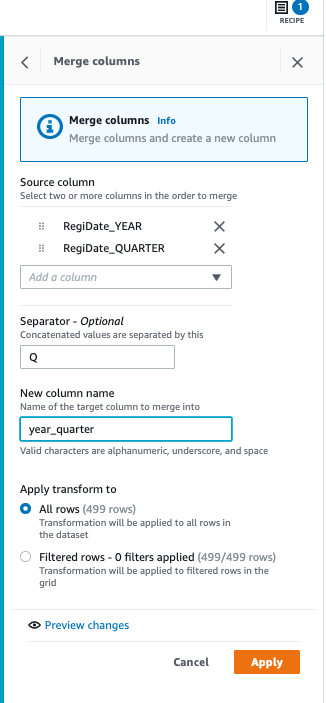
5.第二步,将车辆维修数据的销售年份和销售季度合并为一个字段适配销售数据:点击右侧 recipe,add step,并选择 merge 操作 (Concatenate Columns),将 RegiDate_Year 和 RegiDate_Quarter 合并, 以 “ Q ” 作为连接符,target column name “year_quarter”
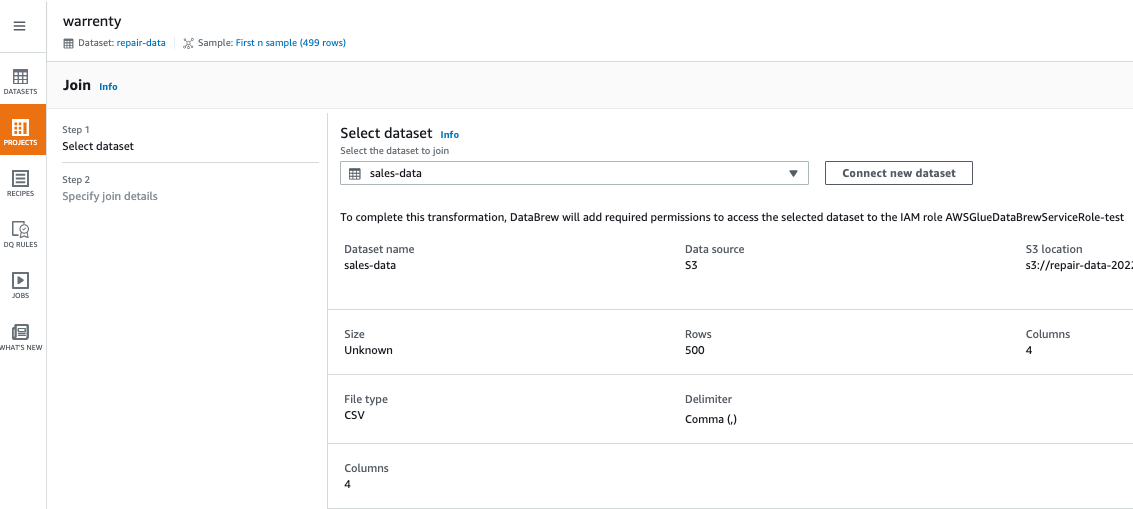
6.第三步,合并车辆维修数据和销售数据: 点击 JOIN 操作,选择 sales-data 作为要 join 的数据集,选择 LEFT JOIN, 并将 year_quarter 以及 Sales_Quarter 作为 join key,浏览后点击finish
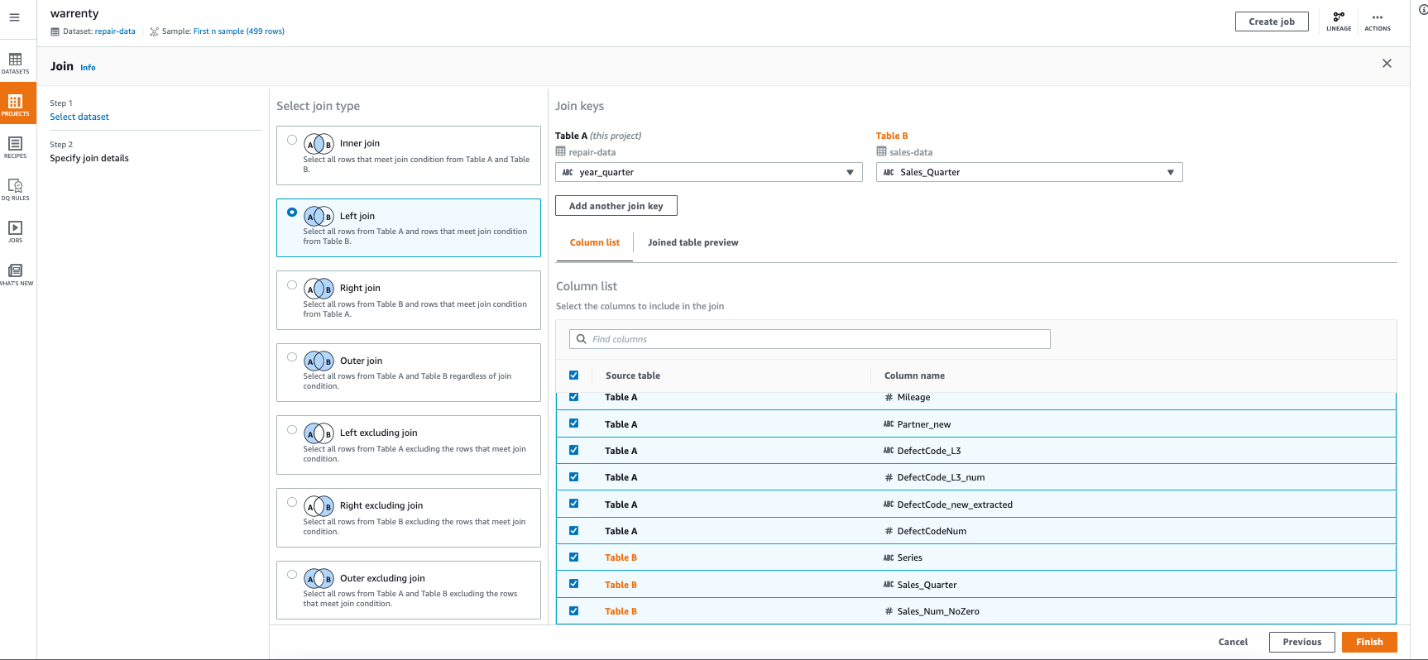
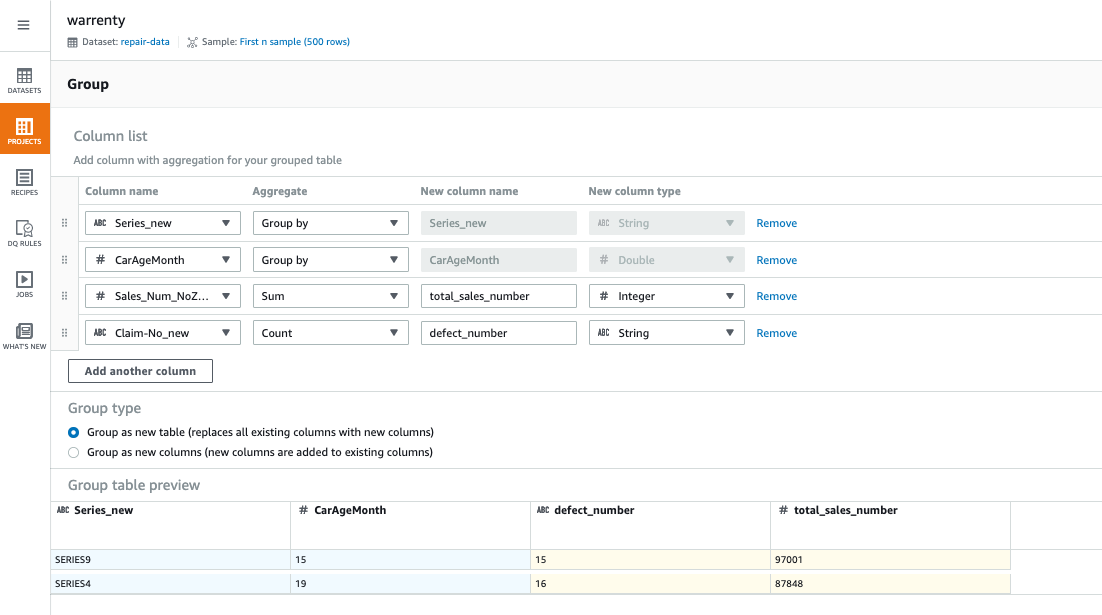
7.第四步,按照车型和车龄聚合数据: 如下图所示,按照 Series_new 和 CarAgeMonth 做聚合 Group by,生成故障数和销售数。
8.第五步,计算故障率
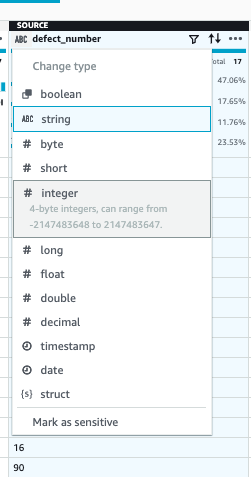
(1)为了做除法,先将 defect number 改为 INT 数据类型
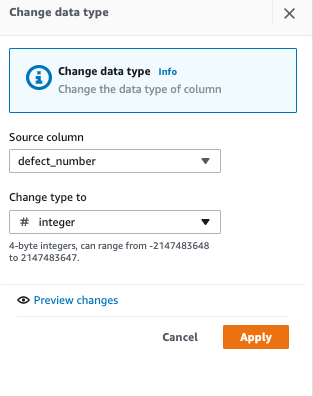
(2)为了计算故障率,我们选择DIVIDE方法,第一列选择 defect_number, 第二列选择 total_sales_number,目标列命名为 defect_rate
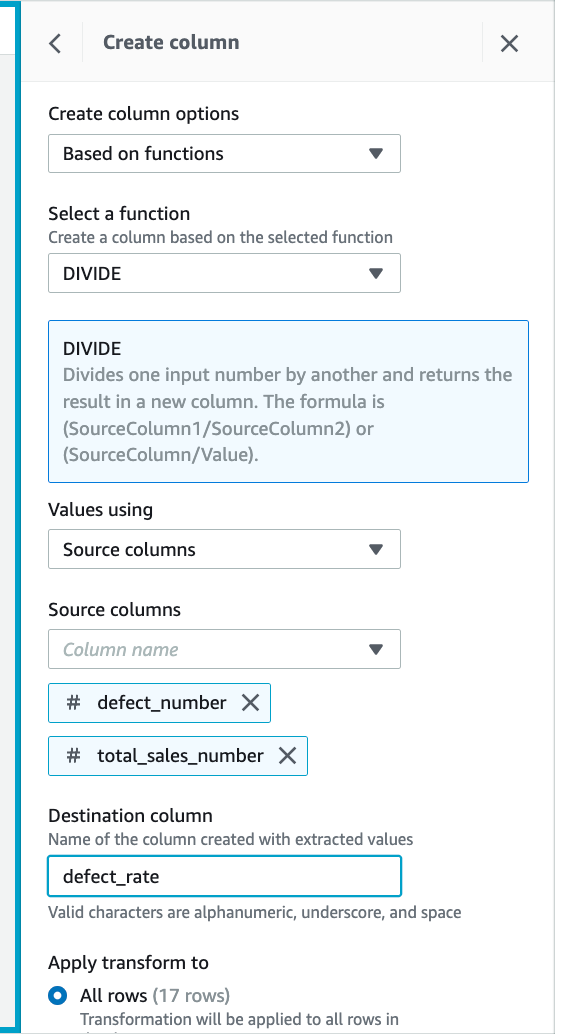
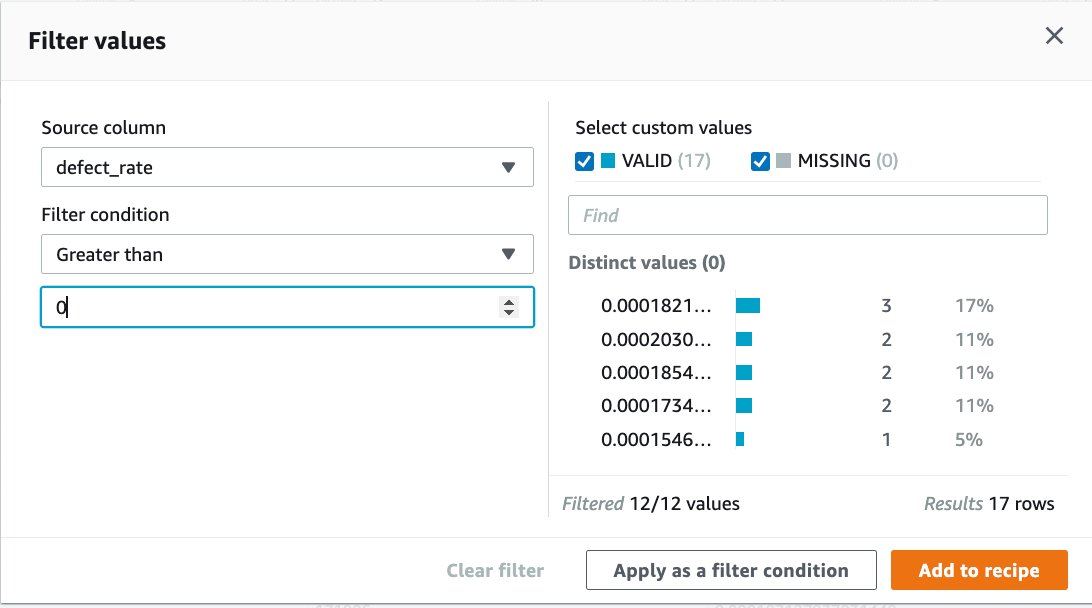
9.第五步,计算故障率:对 defect_rate 做过滤,去除小于0的那些无效值
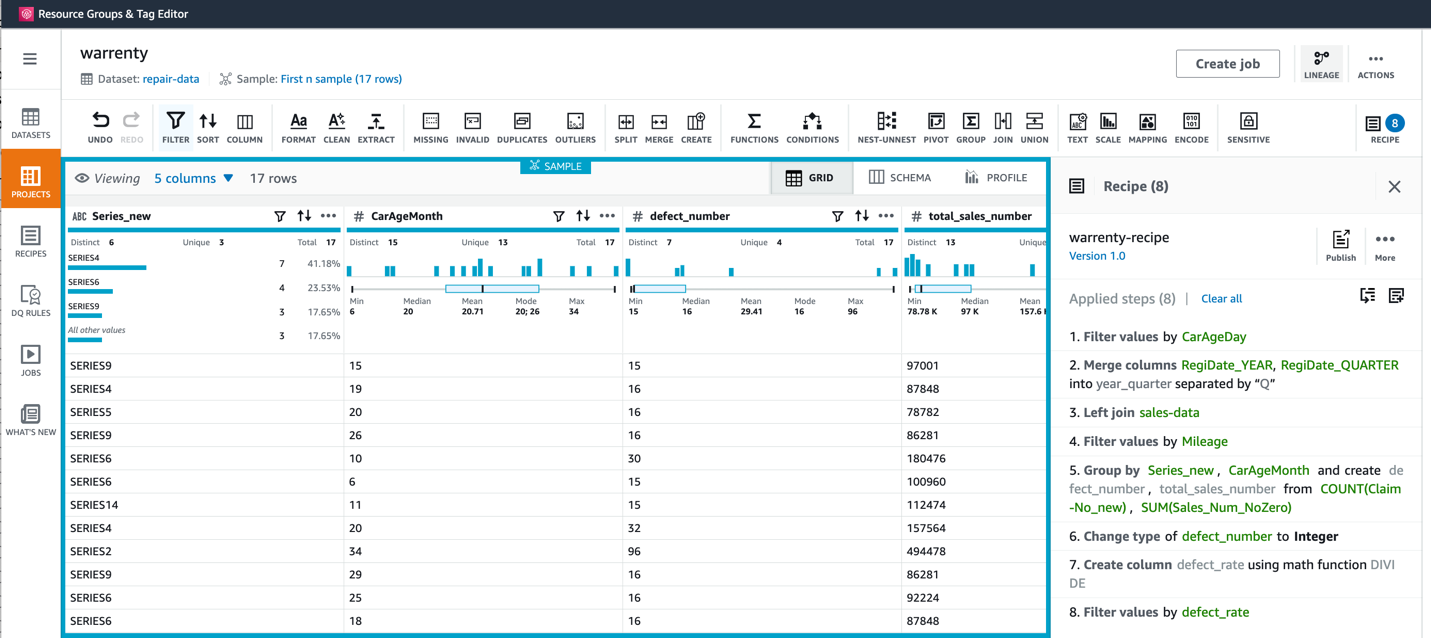
10.最终数据和配方如图所示, 基于每种车型做聚合,我们可以追踪出针对不同车龄的故障率。当然您也可以根据需求自行对数据做更多处理和转换。
11.点击右上方 Create job,以将此配方用于整个数据集。 定义job名称,文件输出地址(S3 location),选择 IAM role (此 Role 需要有 S3 对应位置的读写权限)后,点击最下方 create and run job, 大概会在 2min 完成数据的处理。
12.当 final 后,可以选择将 recipe publish 以保存配方。此配方在下一次可以直接用于应用于其他样本集。
2. 利用 QuickSight 进行数据展示
该章节完成如下功能
- Glue 爬取 Databrew 输出的 Schema,作为数据目录
- 利用 Athena 作为 Connector,连接至 BI 工具 QuickSight
- 在 QuickSight 中自定义 Widget 和 Dashboard
详细步骤
1.到 Glue Crawler (爬网程序) 中,点击添加爬网程序 (add crawler ),定义 S3 数据所在位置,也就是刚才 Databrew 的输出位置 。定义完成后,记得点击 run crawler 以启动此运行任务。 当job 完成后,请到左侧 Table (表)这一栏中检查 data schema 。
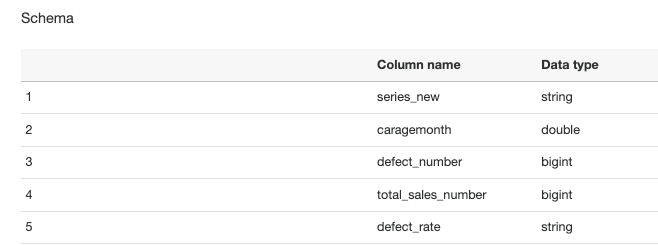
2.因 Athena 使用的是 Glue 的数据目录,因此点击来到 Athena,可以看到刚才我们爬网过的 defect-rate 的 table,本文也用 Glue 也爬过其他的两张原始表,显示如下。
3.控制台到 QuickSight ,添加数据集 (dataset), 选择 Athena 作为数据源。根据提示,选择目标表,将数据加载到 QuickSight 当中。

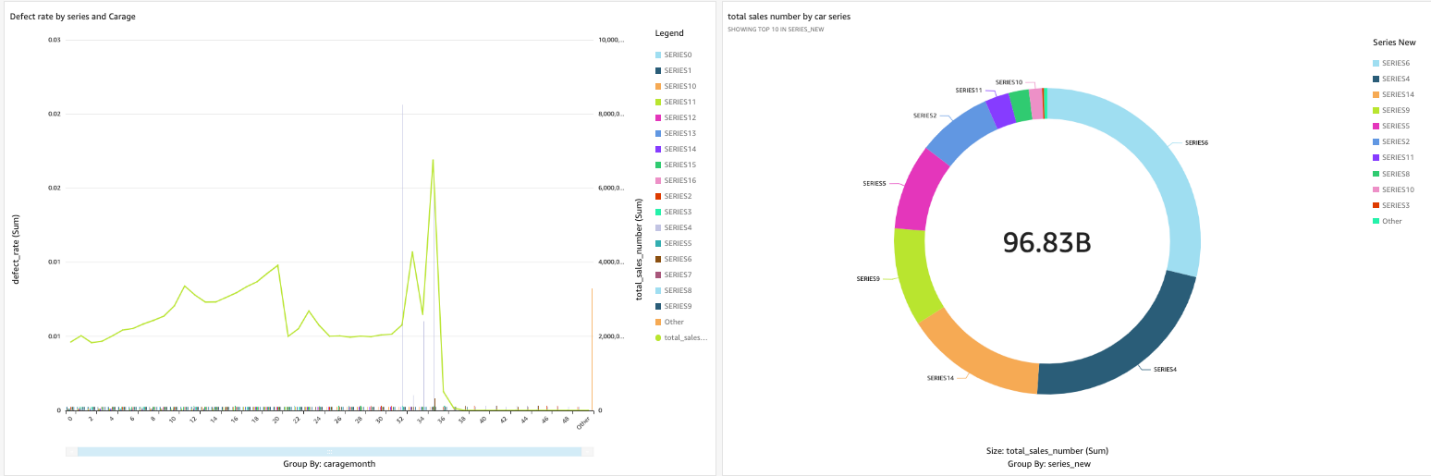
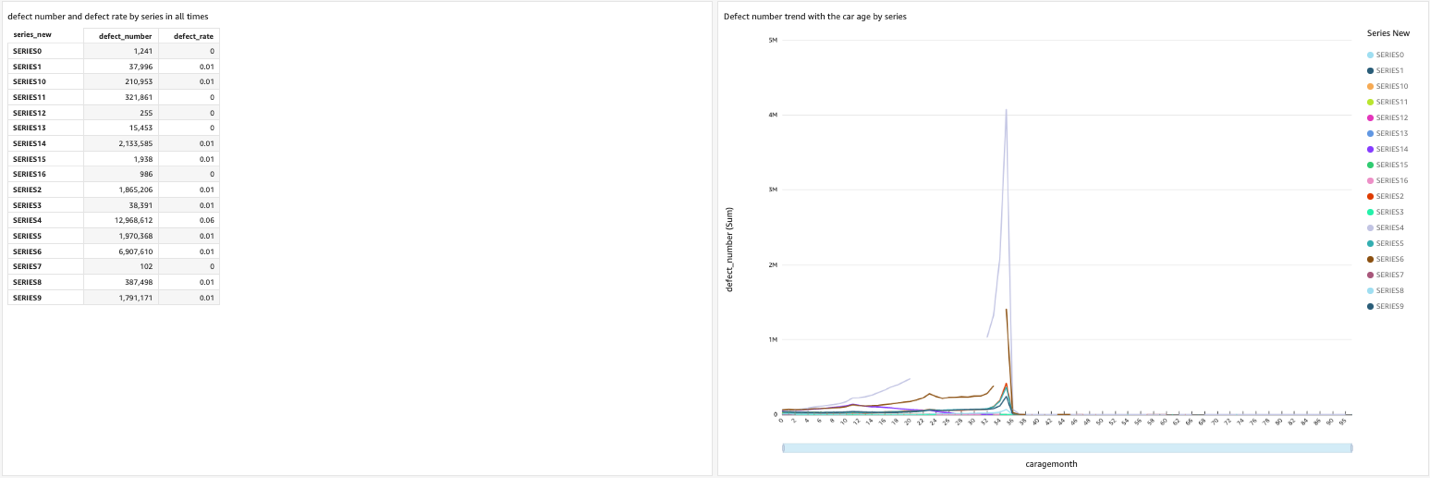
4.导入成功后,添加 New analysis , 在这里可以利用数据的不同维度,以及不同的图表形式,进行自定义的数据探索和展示。本文以不同车型的 defect rate,销量为例,可以看出,SERIES4 为比较畅销的一款车型,此车故障率较高,且故障率基本高频发生在车龄三年左右的时候,我们可以根据此规律提前做客户关怀和车检。 因此文重点不在于 Quicksight 的使用,因此不再展开,如对 QuickSight 使用不熟悉,可以点击此教程 做参考。
12.在将所有的数据都整合完毕后,点击右上方的 share ,可以将此发布为一个 dashboard
3. 利用 Sagemaker Canvas 作为机器学习的工具
该章节完成如下功能
- 对数据进行额外处理
- 合并多份数据
- 利用 Sagemaker Canvas 构建模型
- 生成预测
详细步骤
1.我们可以利用已有的数据做车辆销售数量预测,维修数预测等。本文以故障率作为 预测的目标为例。首先在 Databrew 将其他多余的 column 取出掉,只保留 series,caragemonth,defect_rate 三个列,目标是根据 series 和 carage,可以推测出不同系列车型的故障率。(也可以在下一步 csv 下载完毕后,手动移除掉这两列)
2.因为 Sagemaker Canvas 目前只支持一个单文件作为模型的 dataset,因此我们首先用 Athena 将多个 Databrew 输出的文件 merge 成单个 csv。 我们打开 Athena 执行 select * 之后像截图右下角所示将结果进行下载,这样我们得到一个单个 csv 文件。
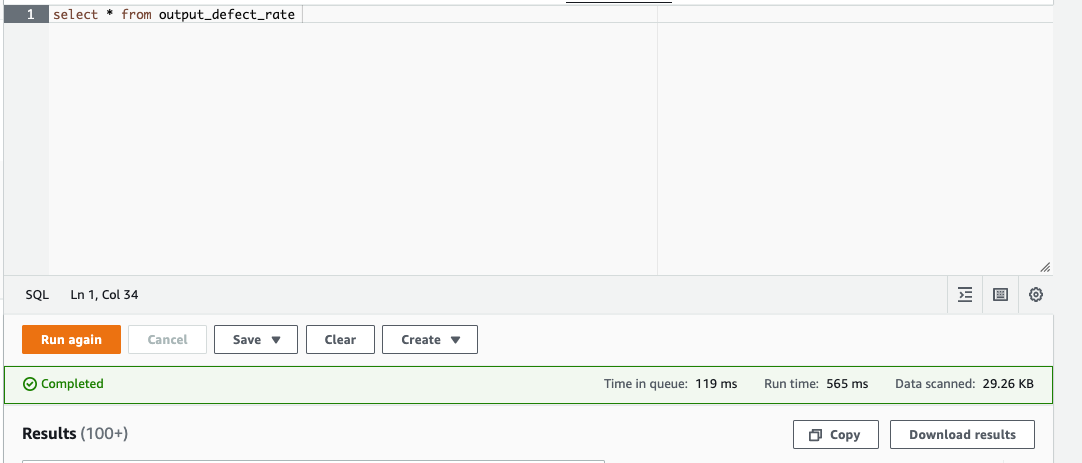
3.进行必要的列移除(如第一步所述)
4.将数据上传至 Sagemaker Canvas dataset
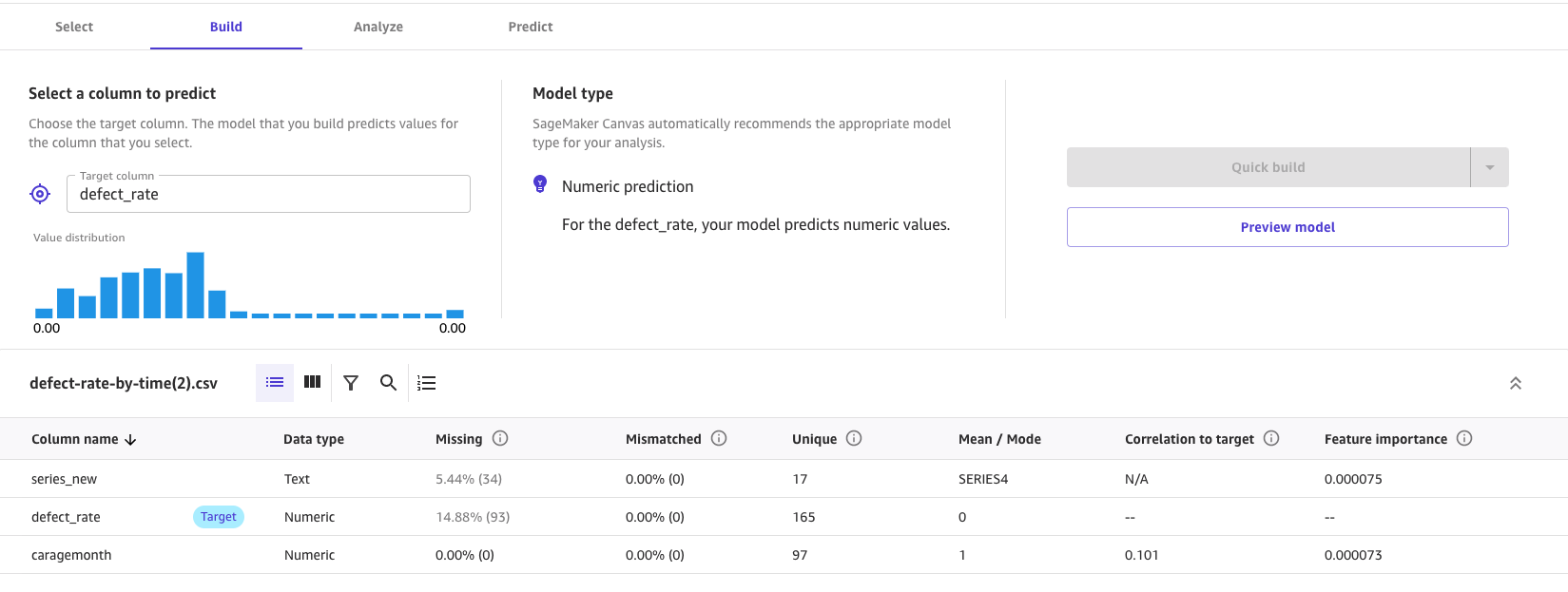
5.Create model,选中此数据集,选中 target 为 defect_rate。 如希望快速生成模型,选择 quick build 以构建模型(2-15min); 如需要更高的精准度,选择 standard build(2-4小时)。本文选择 quick build。
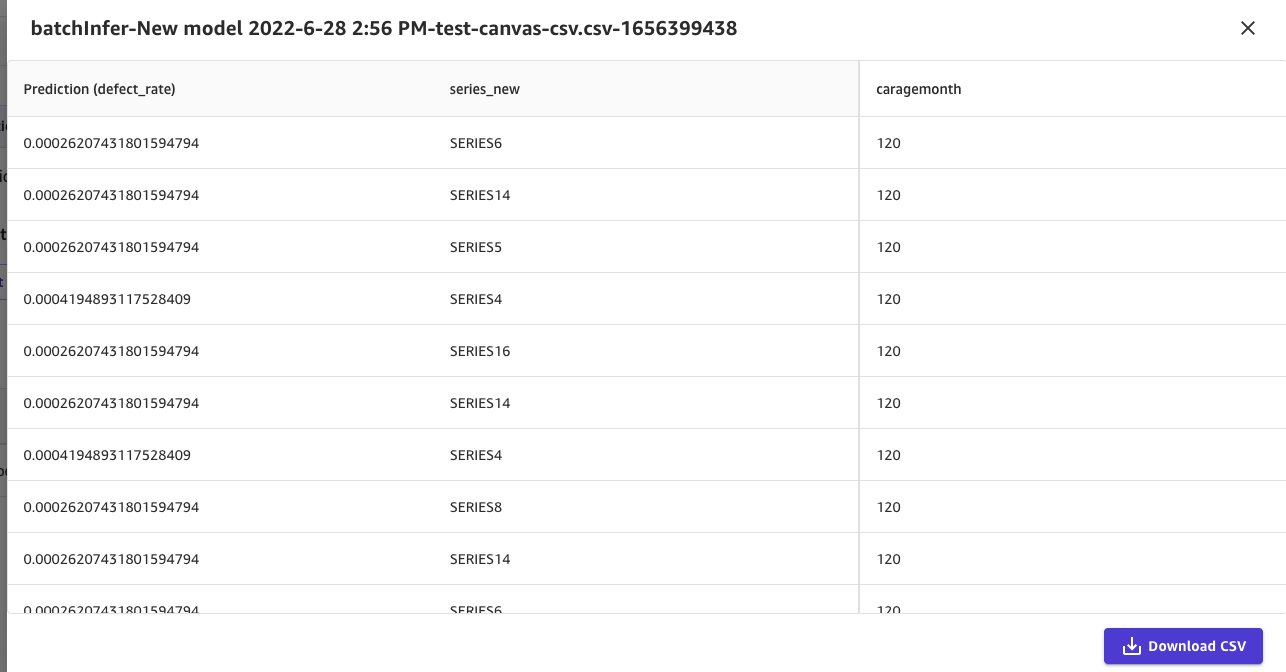
6.等待模型生成后,就可以根据 carage 做故障率的预测。可以上传一份 csv 文件,做 batch prediction;也可以输入单个值进行 single prediction。 本文以前者为例,上传希望预测的 series 和 carage(120个月),最终得到结果如下
8.如果选择的是 Standard build,在模型创建后,SageMaker Canvas 还可以一键将模型共享到 Amazon SageMaker Studio ,使业务分析师可以邀请数据科学家对模型和共享数据集进一步验证和进一步优化 ML 模型,达到生产部署的水平。

结论
本文提供了一个基于图形化的数据处理和 AutoML 的方案,利用 Glue Databrew 和 Sagemaker Canvas 等服务,构建一个无代码数据分析和机器学习平台,一方面,帮助客户业务分析师降低数据处理和ML 专业知识的学习曲线,降低跨部门沟通成本,保持 AutoML 结果的可解释性,方便与数据科学家在模型和数据集层面共享并持续优化。 另一方面,此平台基于无服务器,无需客户管理服务器,按需付费。
本篇作者

李天歌 Amazon 解决方案架构师,负责基于 Amazon 的云计算方案架构咨询和设计,擅长开发,serverless 等领域,具有丰富的解决客户实际问题的经验。

梁睿 梁睿,Amazon 解决方案架构师,主要负责企业级客户的上云工作,服务客户涵盖从汽车,传统生产制造,金融,酒店,航空,旅游等,擅长 DevOps 领域。11年 IT 专业服务经验,历任程序开发,软件架构师、解决方案架构师。
文章来源:https://dev.amazoncloud.cn/column/article/630b3a84269604139cb5e9ea?sc_medium=regulartraffic&sc_campaign=crossplatform&sc_channel=CSDN
相关文章:
在 Amazon 搭建无代码可视化的数据分析和建模平台
现代企业常常会有利用数据分析和机器学习帮助解决业务痛点的需求。如制造业中,利用设备采集上来的数据做预测性维护,质量控制;在零售业中,利用客户端端采集的数据做渠道转化率分析,个性化推荐等。 亚马逊云科技开发者…...

Pinely Round 2 (Div. 1 + Div. 2) G. Swaps(组合计数)
题目 给定一个长度为n(n<1e6)的序列,第i个数ai(1<ai<n), 操作:你可以将当前i位置的数和a[i]位置的数交换 交换可以操作任意次,求所有本质不同的数组的数量,答案对1e97取模 思路来源 力扣群 潼神 心得 感…...

elasticSearch+kibana+logstash+filebeat集群改成https认证
文章目录 一、生成相关证书二、配置elasticSearh三、配置kibana四、配置logstash五、配置filebeat六、连接https es的java api 一、生成相关证书 ps:主节点操作 切换用户:su es 进入目录:cd /home/es/elasticsearch-7.6.2 创建文件&#x…...

GPT带我学-设计模式-迭代器模式
1 什么是迭代器设计模式? 迭代器设计模式是一种行为型设计模式,用于提供一种统一的方式来遍历一个集合对象中的元素,而不需要暴露该对象的内部结构。它将集合对象的遍历操作与集合对象本身分离开来,使得遍历操作可以独立于集合对…...
的Python实现)
数学建模--层次分析法(AHP)的Python实现
目录 1.算法流程简介 2.算法核心代码 3.算法效果展示 1.算法流程简介 """ AHP:层次分析法,层次分析法还是比较偏向于主观的判断的,所以在建模的时候尽可能不要去使用层次分析法 不过在某些创新的评价方法上,也是能够运用层次分析使得评价变得全面一些,有可…...

机器学习笔记之最优化理论与方法(三)凸集的简单认识(下)
机器学习笔记之最优化理论与方法——凸集的简单认识[下] 引言回顾:基本定义——凸集关于保持集合凸性的运算仿射变换 凸集基本性质:投影定理点与凸集的分离支撑超平面定理 引言 继续凸集的简单认识(上)进行介绍,本节将介绍凸集的基本性质以及…...
Apipost:API文档、调试、Mock与测试的一体化协作平台
随着数字化转型的加速,API(应用程序接口)已经成为企业间沟通和数据交换的关键。而在API开发和管理过程中,API文档、调试、Mock和测试的协作显得尤为重要。Apipost正是这样一款一体化协作平台,旨在解决这些问题…...

Homebrew下载安装及使用教程
Homebrew是什么? 简单来说,就是用命令行的形式去管理mac系统的包或软件。 安装命令 /bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"国内请使用镜像源进行下载 执行上述命令后会要求输入…...

【Codeforces】CF193D Two Segments
题目链接 CF方向 Luogu方向 题目解法 考虑在值域上的问题:有多少段区间,对应在排列上不超过 2 2 2 段 肯定需要枚举一个端点,另一个快速算出,考虑枚举值域区间右端点 r r r,计算 l l l 可以发现,新增…...

内存管理概述
前言 在学习计算机科学时,内存管理是一个非常重要的概念。简单地说,内存是计算机用来存储和访问数据的地方。而内存管理是计算机系统如何分配、使用和管理内存的过程。 为什么要学习内存管理? 1. 高效性:内存管理能够帮助计算机更…...
Spring的重试机制-SpringRetry
在我们的日常开发中,经查会遇到调用接口失败的情况,这时候就需要通过一些方法来进行重试,比如通过while循环手动重复调用或,或者通过记录错误接口url和参数到数据库,然后手动调用接口,或者通过JDK/CGLib动态…...
水稻叶病害数据集(目标检测,yolo使用)
1.数据集文件夹 train文件夹(44229张),test文件夹(4741张),valid文件夹(6000张) 2.train文件夹展示 labels展示 标签txt展示 data.yaml文件展示 对数据集感兴趣的可以关注最后一行…...
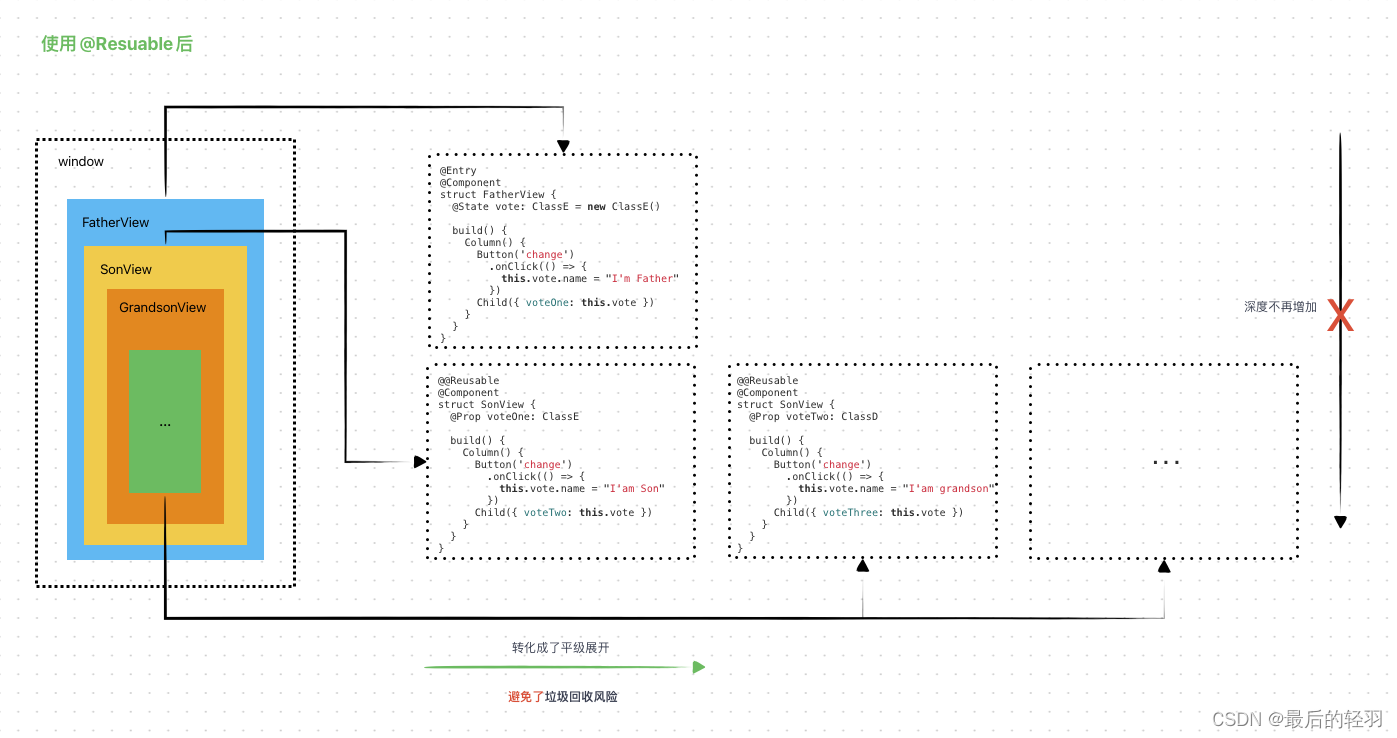
鸿蒙系列-如何使用好 ArkUI 的 @Reusable?
如何使用好 ArkUI 的 Reusable? OpenHarmony 组件复用机制 在ArkUI中,UI显示的内容均为组件,由框架直接提供的称为 系统组件,由开发者定义的称为 自定义组件。 在进行 UI 界面开发时,通常不是简单的将系统组件进行组合…...

展锐平台音频框架
Audio DT介绍 1.概述 DT(Device Tree)是一种描述硬件的数据结构,DTS即设备树源码。 2.Audio DTS 文件架构 \bsp\kernel\kernel.4.14\arch\arm64\boot\sprd ums512.dts //SOC级相关节点 ——sc2730.dtsi //Codec ——sharkl5Pro.dts…...

webpack loader和plugins的区别
在Webpack中,Loader和Plugin是两个不同的概念,用于不同的目的。 Loader是用于处理非JavaScript模块的文件的转换工具。它们将文件作为输入,并将其转换为Webpack可以处理的模块。例如,当您在Webpack配置中使用Babel Loader时&…...

适配器模式:接口的平滑过渡
欢迎来到设计模式系列的第七篇文章!在前面的几篇文章中,我们已经学习了一些常见的设计模式,今天我们将继续探讨另一个重要的设计模式——适配器模式。 适配器模式简介 适配器模式是一种结构型设计模式,它主要用于将一个类的接口…...
vscode搭建springboot开发环境
前言 idea好用到但是收money,eclipse免费但是界面有点丑,所以尝试使用vscode开发springboot 提前准备 安装jdk,jdk需要大于11 安装vscode 安装maven 安装插件 主要是下面的插件 Extension Pack for JavaSpring Boot Extension PackDepe…...
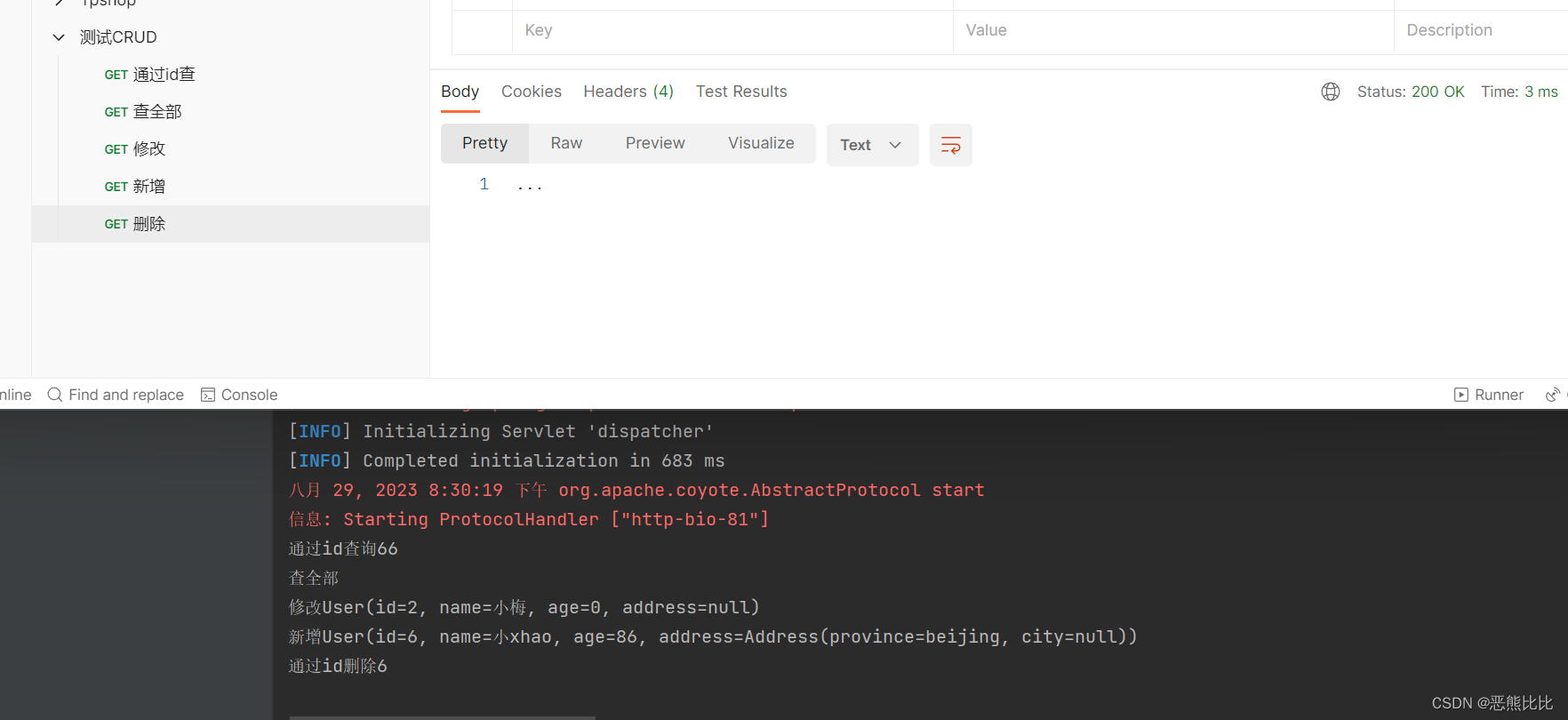
SpringMVC-学习笔记
文章目录 1.概述1.1 SpringMVC快速入门 2. 请求2.1 加载控制2.2 请求的映射路径2.3 get和post请求发送2.4 五种请求参数种类2.5 传递JSON数据2.6 日期类型参数传递 3.响应3.1 响应格式 4.REST风格4.1 介绍4.2 RESTful快速入门4.3 简化操作 1.概述 SpringMVC是一个基于Java的Web…...
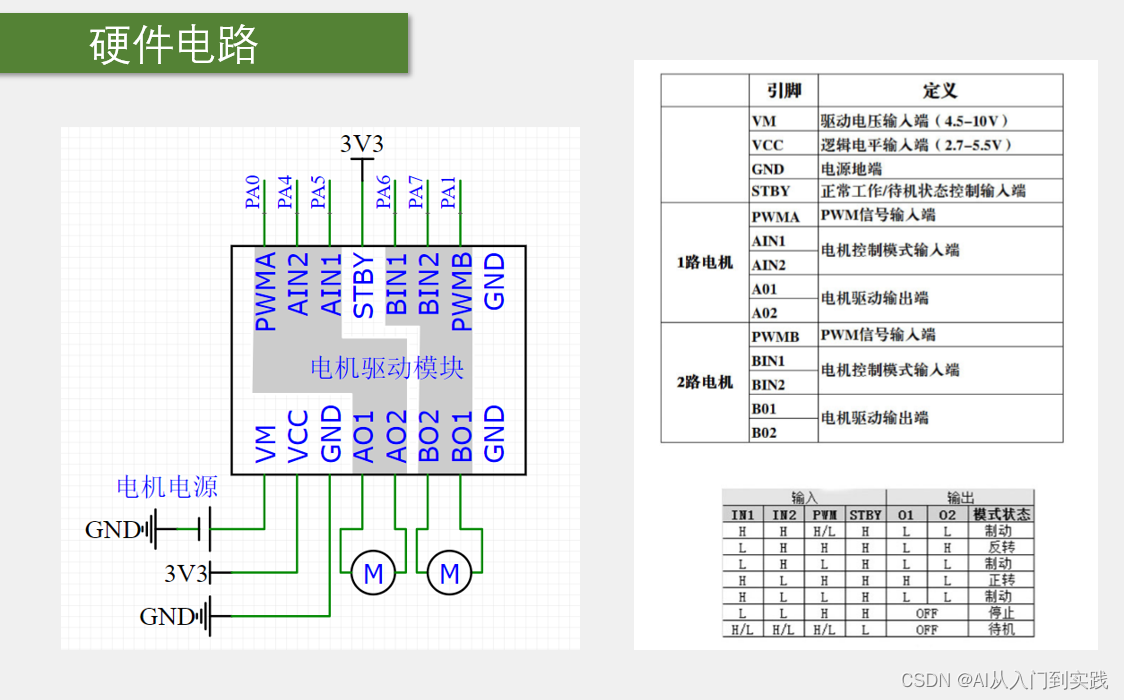
【STM32】学习笔记(TIM定时器)
TIM(Timer)定时器 定时器可以对输入的时钟进行计数,并在计数值达到设定值时触发中断 16位计数器、预分频器、自动重装寄存器的时基单元,在72MHz计数时钟下可以实现最大59.65s的定时 不仅具备基本的定时中断功能,而且…...
Jdk8 动态编译 Java 源码为 Class 文件(三)
Jdk8 动态编译 Java 源码为 Class 文件 一.JDK版本二.工程介绍1.依赖2.启动类3.配置类(用于测试依赖注入)4.工具类1.Java 源码文件读取类2.SpringBoot 容器实例管理类 5.测试类1.抽象类2.接口类3.默认抽象实现4.默认接口实现 6.接口类1.测试接口2.类重载…...

云启出海,智联未来|阿里云网络「企业出海」系列客户沙龙上海站圆满落地
借阿里云中企出海大会的东风,以**「云启出海,智联未来|打造安全可靠的出海云网络引擎」为主题的阿里云企业出海客户沙龙云网络&安全专场于5.28日下午在上海顺利举办,现场吸引了来自携程、小红书、米哈游、哔哩哔哩、波克城市、…...

高频面试之3Zookeeper
高频面试之3Zookeeper 文章目录 高频面试之3Zookeeper3.1 常用命令3.2 选举机制3.3 Zookeeper符合法则中哪两个?3.4 Zookeeper脑裂3.5 Zookeeper用来干嘛了 3.1 常用命令 ls、get、create、delete、deleteall3.2 选举机制 半数机制(过半机制࿰…...

MMaDA: Multimodal Large Diffusion Language Models
CODE : https://github.com/Gen-Verse/MMaDA Abstract 我们介绍了一种新型的多模态扩散基础模型MMaDA,它被设计用于在文本推理、多模态理解和文本到图像生成等不同领域实现卓越的性能。该方法的特点是三个关键创新:(i) MMaDA采用统一的扩散架构…...

将对透视变换后的图像使用Otsu进行阈值化,来分离黑色和白色像素。这句话中的Otsu是什么意思?
Otsu 是一种自动阈值化方法,用于将图像分割为前景和背景。它通过最小化图像的类内方差或等价地最大化类间方差来选择最佳阈值。这种方法特别适用于图像的二值化处理,能够自动确定一个阈值,将图像中的像素分为黑色和白色两类。 Otsu 方法的原…...

linux 错误码总结
1,错误码的概念与作用 在Linux系统中,错误码是系统调用或库函数在执行失败时返回的特定数值,用于指示具体的错误类型。这些错误码通过全局变量errno来存储和传递,errno由操作系统维护,保存最近一次发生的错误信息。值得注意的是,errno的值在每次系统调用或函数调用失败时…...

uniapp微信小程序视频实时流+pc端预览方案
方案类型技术实现是否免费优点缺点适用场景延迟范围开发复杂度WebSocket图片帧定时拍照Base64传输✅ 完全免费无需服务器 纯前端实现高延迟高流量 帧率极低个人demo测试 超低频监控500ms-2s⭐⭐RTMP推流TRTC/即构SDK推流❌ 付费方案 (部分有免费额度&#x…...

[Java恶补day16] 238.除自身以外数组的乘积
给你一个整数数组 nums,返回 数组 answer ,其中 answer[i] 等于 nums 中除 nums[i] 之外其余各元素的乘积 。 题目数据 保证 数组 nums之中任意元素的全部前缀元素和后缀的乘积都在 32 位 整数范围内。 请 不要使用除法,且在 O(n) 时间复杂度…...

【开发技术】.Net使用FFmpeg视频特定帧上绘制内容
目录 一、目的 二、解决方案 2.1 什么是FFmpeg 2.2 FFmpeg主要功能 2.3 使用Xabe.FFmpeg调用FFmpeg功能 2.4 使用 FFmpeg 的 drawbox 滤镜来绘制 ROI 三、总结 一、目的 当前市场上有很多目标检测智能识别的相关算法,当前调用一个医疗行业的AI识别算法后返回…...

网站指纹识别
网站指纹识别 网站的最基本组成:服务器(操作系统)、中间件(web容器)、脚本语言、数据厍 为什么要了解这些?举个例子:发现了一个文件读取漏洞,我们需要读/etc/passwd,如…...

20个超级好用的 CSS 动画库
分享 20 个最佳 CSS 动画库。 它们中的大多数将生成纯 CSS 代码,而不需要任何外部库。 1.Animate.css 一个开箱即用型的跨浏览器动画库,可供你在项目中使用。 2.Magic Animations CSS3 一组简单的动画,可以包含在你的网页或应用项目中。 3.An…...