机器学习---预剪枝、后剪枝(REP、CCP、PEP、)
1. 为什么要进行剪枝
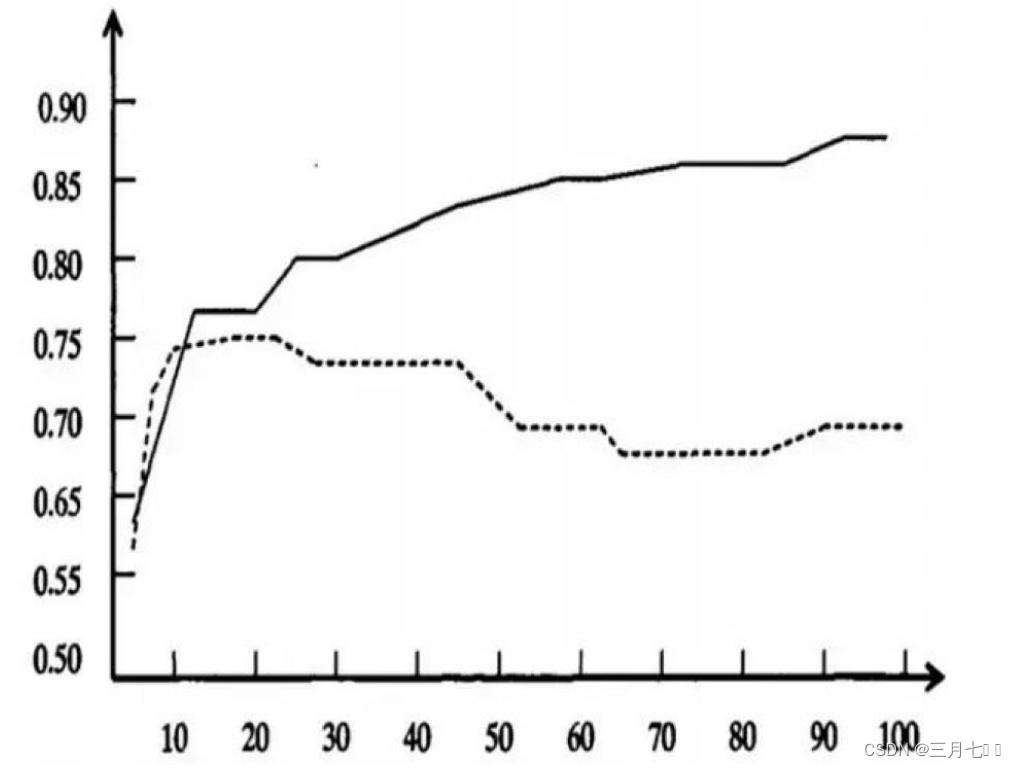
横轴表示在决策树创建过程中树的结点总数,纵轴表示决策树的预测精度。 实线显示的是决策树
在训练集上的精度,虚线显示的则是在⼀个独⽴的测试集上测量出来的精度。 随着树的增⻓,在
训练样集上的精度是单调上升的, 然⽽在独⽴的测试样例上测出的精度先上升后下降。
出现这种情况的原因:
噪声、样本冲突,即错误的样本数据;特征即属性不能完全作为分类标准;巧合的规律性,数据量
不够⼤。
剪枝 (pruning)是决策树学习算法对付"过拟合"的主要⼿段。 在决策树学习中,为了尽可能正确分
类训练样本,结点划分过程将不断重复,有时会造成决策树分⽀过多,这时就可能因训练样本学
得"太好"了,以致于把训练集⾃身的⼀些特点当作所有数据都具有的⼀般性质⽽导致过拟合。因
此,可通过主动去掉⼀些分⽀来降低过拟合的⻛险。
如何判断决策树泛化性能是否提升呢? 可使⽤留出法,即预留⼀部分数据⽤作"验证集"以进⾏性
能评估。例如对下表的⻄⽠数据集,将其随机划分为两部分,其中编号为 {1,2,3,6, 7, 10,
14, 15, 16, 17} 的样例组成训练集,编号为 {4, 5, 8, 9, 11, 12, 13} 的样例组成验证
集。
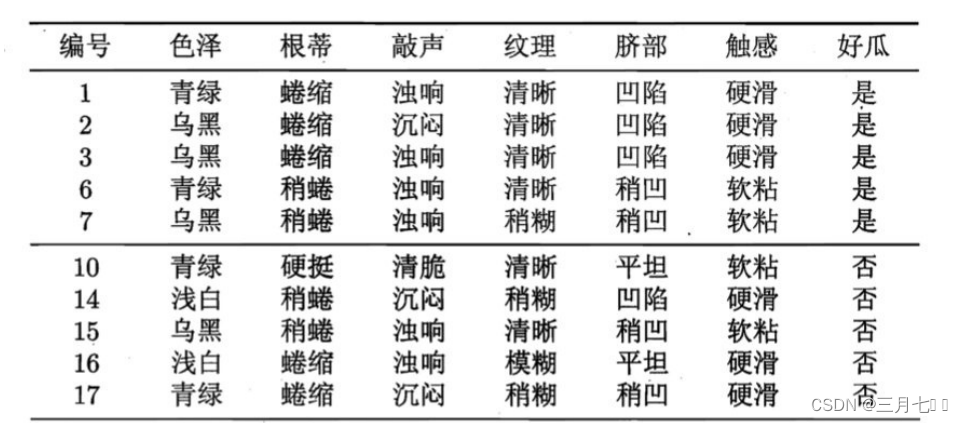
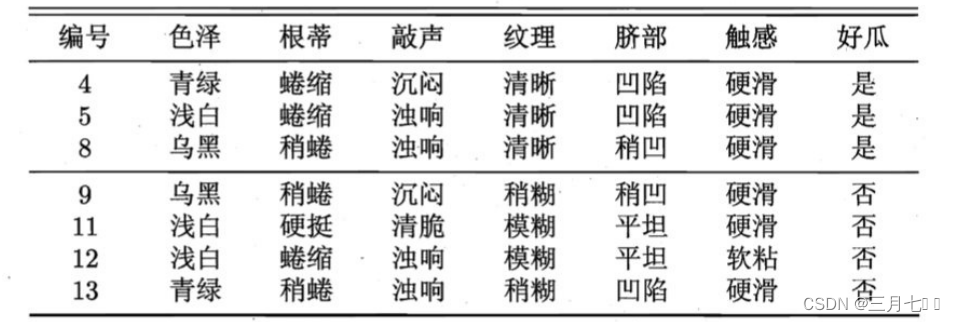
假定采⽤信息增益准则来划分属性选择,则上表中训练集将会⽣成⼀棵下⾯决策树。

接下来,将对这⼀棵树进⾏剪枝。
2. 预剪枝
决策树剪枝的基本策略有"预剪枝" (pre-pruning)和"后剪枝"(post- pruning) 。
预剪枝是指在决策树⽣成过程中,对每个结点在划分前先进⾏估计,若当前结点的划分不能带来决
策树泛化性能提升,则停⽌划分并将当前结点标记为叶结点;后剪枝则是先从训练集⽣成⼀棵完
整的决策树,然后⾃底向上地对⾮叶结点进⾏考察,若将该结点对应的⼦树替换为叶结点能带来决
策树泛化性能提升,则将该⼦树替换为叶结点。
有多种不同的方式可以让决策树停止生长,下面介绍几种停止决策树生长的方法:
①定义一个高度,当决策树达到该高度时就可以停止决策树的生长 ,这是一种最为简单的方法;
②达到某个结点的实例具有相同的特征向量,即使这些实例不属于同一类,也可以停止决策树的生
长。这种方法对于处理数据中的数据冲突问题非常有效;
③定义一个阈值,当达到某个结点的实例个数小于该阈值时就可以停止决策树的生长;
④定义一个阈值,通过计算每次扩张对系统性能的增益,并比较增益值与该阈值的大小来决定是否
停止决策树的生长。
预剪枝方法不但相对简单,效率很高,而且不需要生成整个决策树 ,适合于解决大规模问题。该
方法看起来很直接,但要精确地估计决策树生长的停止时间并不容易,即选取一个恰当的阈值是非
常困难的。高阈值可能导致过分简化的树,而低阈值可能使得树的简化太少。
在测试集上定义损失函数C,目标是通过剪枝使得在测试集上C的值下降。 例如通过剪枝使在测试
集上误差率降低。 首先,自底向上的遍历每一个非叶节点(除了根节点),将当前的非叶节点从树
中剪去,其下所有的叶节点合并成一个节点,代替原来被剪掉的节点。 然后,计算剪去节点前后
的损失函数,如果剪去节点之后损失函数变小了,则说明该节点是可以剪去的,并将其剪去;如果
发现损失函数并没有减少, 说明该节点不可剪去,则将树还原成未剪去之前的状态。 最后,重复
上述过程,直到所有的非叶节点(除了根节点)都被尝试了。
对于上例,⾸先,基于信息增益准则,会选取属性"脐部"来对训练集进⾏划分,并产⽣ 3 个分⽀,
如下图所示。然⽽,是否应该进⾏这个划分呢?预剪枝要对划分前后的泛化性能进⾏估计。在划分
之前,所有样例集中在根结点。
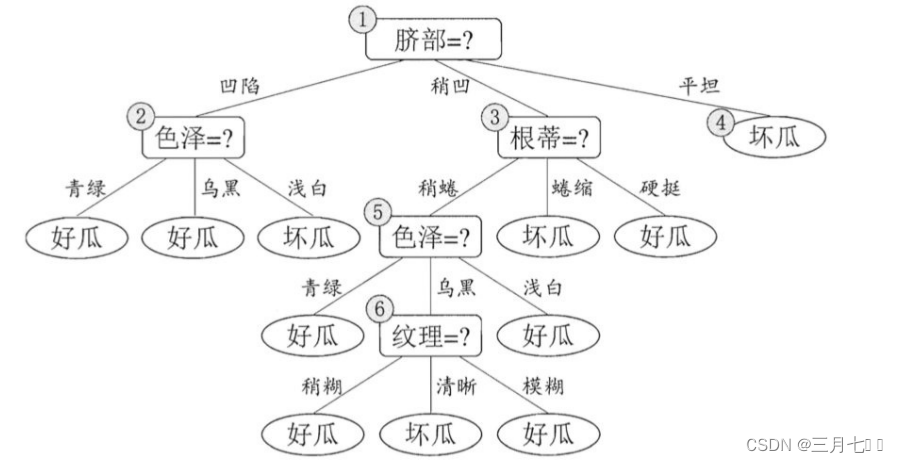
若不进⾏划分,该结点将被标记为叶结点,其类别标记为训练样例数最多的类别,假设将这个叶结
点标记 为"好⽠"。 ⽤前⾯表的验证集对这个单结点决策树进⾏评估。则编号为 {4,5,8} 的样例
被分类正确。另外 4个样例分类错误,于是验证集精度为3 / 7 ∗ 100% = 42.9%。
在⽤属性"脐部"划分之后,上图中的结点2、3、4分别包含编号为 {1,2,3, 14}、 {6,7, 15,
17}、 {10, 16} 的训练样例,因此这 3 个结点分别被标记为叶结点"好⽠"、 "好⽠"、 "坏⽠"。

此时,验证集中编号为 {4, 5, 8,11, 12} 的样例被分类正确,验证集精度为5 / 7 ∗ 100% =
71.4% > 42.9%。于是,⽤"脐部"进⾏划分得以确定。
然后,决策树算法应该对结点2进⾏划分,基于信息增益准则将挑选出划分属性"⾊泽"。然⽽,在
使⽤"⾊泽"划分后,编号为 {5} 的验证集样本分类结果会由正确转为错误,使得验证集精度下降为
57.1%。于是,预剪枝策略将禁⽌结点2被划分。 对结点3,最优划分属性为"根蒂",划分后验证集
精度仍为 71.4%. 这个划分不能提升验证集精度,于是,预剪枝策略禁⽌结点3被划分。 对结点4,
其所含训练样例已属于同⼀类,不再进⾏划分。于是,基于预剪枝策略从上表数据所⽣成的决策树
如上图所示,其验证集精度为 71.4%。这是⼀棵仅有⼀层划分的决策树,也称"决策树桩" (decision
stump)。
3. 后剪枝
后剪枝先从训练集⽣成⼀棵完整决策树,继续使⽤上⾯的案例,从前⾯计算,了解到前⾯构造的决
策树的验证集精度为 42.9%。
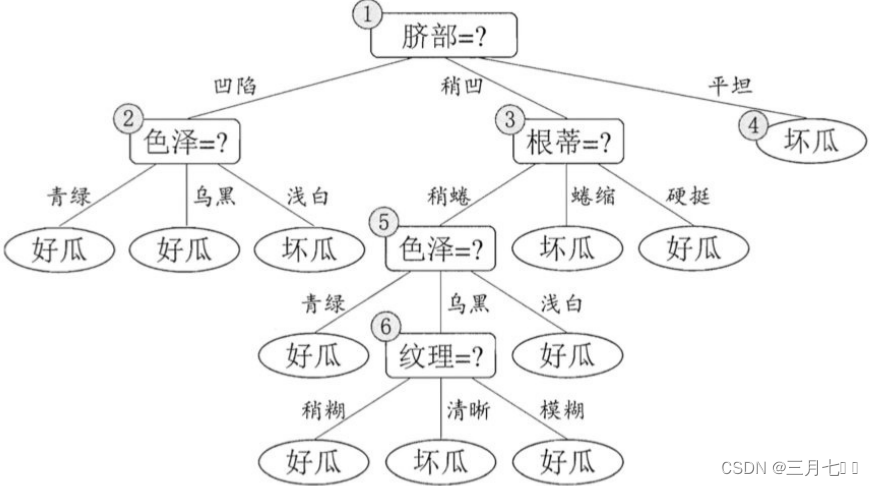
后剪枝⾸先考察结点6,若将其领衔的分⽀剪除则相当于把6替换为叶结点。替换后的叶结点包含编
号为 {7, 15} 的训练样本,于是该叶结点的类别标记为"好⽠",此时决策树的验证集精度提高至
57.1%。于是,后剪枝策略决定剪枝,如下图所示。
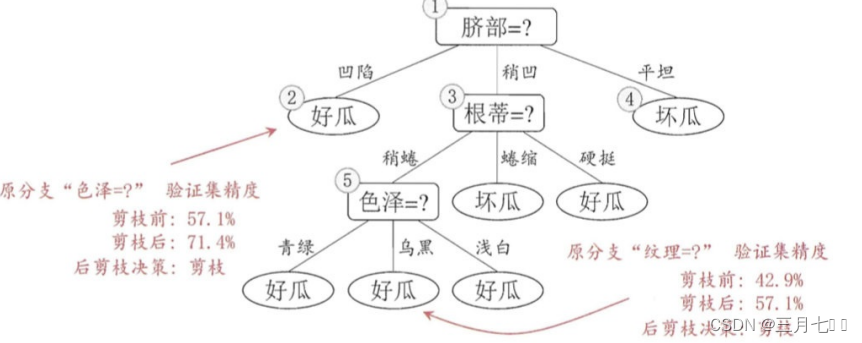
然后考察结点5,若将其领衔的⼦树替换为叶结点,则替换后的叶结点包含编号为 {6,7,15}的训
练样例,叶结点类别标记为"好⽠";此时决策树验证集精度仍为 57.1%. 于是,可以不进⾏剪枝。
对结点2,若将其领衔的⼦树替换为叶结点,则替换后的叶结点包含编号为 {1, 2, 3, 14} 的训
练样例,叶结点标记为"好⽠",此时决策树的验证集精度提高至 71.4%。于是,后剪枝策略决定剪
枝。对结点3和1,若将其领衔的子树替换为叶结点,则所得决策树的验证集精度分别为 71.4% 与
42.9%,均未得到提高,于是它们被保留。 最终,基于后剪枝策略所⽣成的决策树就如上图所示,
其验证集精度为 71.4%。
对⽐两种剪枝⽅法:
后剪枝决策树通常⽐预剪枝决策树保留了更多的分⽀。
⼀般情形下,后剪枝决策树的⽋拟合⻛险很小,泛化性能往往优于预剪枝决策树。 但后剪枝过程
是在⽣成完全决策树之后进⾏的。 并且要自底向上地对树中的所有非叶结点进行逐⼀考察,因此
其训练时间开销比未剪枝决策树和预剪枝决策树都要⼤得多。
4. 剪枝的方法
Reduced-Error Pruning(REP,错误率降低剪枝):
REP方法是一种比较简单的后剪枝的方法,在该方法中,可用的数据被分成两个样例集合:一个训
练集用来形成学习到的决策树,一个分离的验证集用来评估这个决策树在后续数据上的精度,确切
地说是用来评估修剪这个决策树的影响。 这个方法的动机是:即使学习器可能会被训练集中的随
机错误和巧合规律所误导,但验证集合不大可能表现出同样的随机波动。所以验证集可以用来对过
度拟合训练集中的虚假特征提供防护检验。
该剪枝方法考虑将树上的每个节点作为修剪的候选对象,决定是否修剪这个结点由如下步骤组成:
①删除以此结点为根的子树
②使其成为叶子结点
③赋予该结点关联的训练数据的最常见分类
④当修剪后的树对于验证集合的性能不会比原来的树差时,才真正删除该结点
训练集合可能过拟合,使用验证集合数据能够对其进行修正,反复进行上面的操作,从底向上的处
理结点,删除那些能够最大限度的提高验证集合的精度的结点,直到进一步修剪有害为止(有害是
指修剪会减低验证集合的精度)。
Pesimistic-Error Pruning(PEP,悲观错误剪枝):
悲观错误剪枝法是根据剪枝前后的错误率来判定子树的修剪。该方法引入了统计学上连续修正的概
念弥补REP中的缺陷,在评价子树的训练错误公式中添加了一个常数,假定每个叶子结点都自动对
实例的某个部分进行错误的分类。 把一棵子树(具有多个叶子节点)的分类用一个叶子节点来替
代的话,在训练集上的误判率肯定是上升的,但是在新数据上不一定。于是,需要把子树的误判计
算加上一个经验性的惩罚因子。
对于一个叶子节点,它覆盖了N个样本,其中有E个错误,那么该叶子节点的错误率为
(E+0.5)/N。这个0.5就是惩罚因子,那么一棵子树,它有L个叶子节点,那么该子树的误判率估
计为![]()
这样的话,可以看到一棵子树虽然具有多个子节点,但由于加上了惩罚因子,所以子树的误判率计
算未必占到便宜。剪枝后内部节点变成了叶子节点,其误判个数J也需要加上一个惩罚因子,变成
J+0.5 。那么子树是否可以被剪枝就取决于剪枝后的错误J+0.5在![]()
的标准误差内。对于样本的误差率e,可以根据经验把它估计成各种各样的分布模型,比如是二项
式分布,比如是正态分布。 那么一棵树错误分类一个样本值为1,正确分类一个样本值为0,该树
错误分类的概率(误判率)为e(e为分布的固有属性,可以通过![]()
统计出来),那么树的误判次数就是伯努利分布,就可以估计出该树的误判次数均值和标准差:
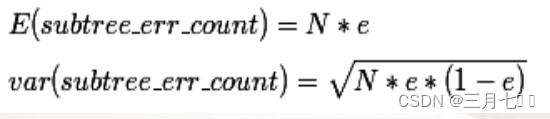
把子树替换成叶子节点后,该叶子的误判次数也是一个伯努利分布,其概率误判率e为(E+0.5)/N,
因此叶子节点的误判次数均值为 ![]()
使用训练数据,子树总是比替换为一个叶节点后产生的误差小, 但是使用校正后有误差计算方法
却并非如此,当子树的误判个数大过对应叶节点的误判个数一个标准差之后,就决定剪枝:
![]()
这个条件就是剪枝的标准。当然并不一定非要大一个标准差,可以给定任意的置信区间,设定一定
的显著性因子,就可以估算出误判次数的上下界。
比如:
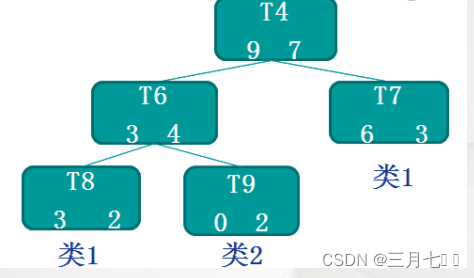
T4这棵子树的误差率:(7+0.5*3)/16=0.53125
子树误判次数的标准误差:![]()
子树替换为一个叶节点后,其误判个数为:7+0.5=7.5
因为8.5+1.996>7.5,所以决定将子树T4替换这一个叶子节点。
Cost-Complexity Pruning(CCP,代价复杂度剪枝):
该算法为子树 Tt 定义了代价(cost)和复杂度(complexity),以及一个可由用户设置的衡量代价
与复杂度之间关系的参数α,其中,代价指在剪枝过程中因子树 Tt 被叶节点替代而增加的错分样
本,复杂度表示剪枝后子树 Tt 减少的叶结点数,α则表示剪枝后树的复杂度降低程度与代价间的关
系,定义为 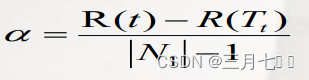
其中, |N1|:子树 Tt 中的叶节点数;
R(t):结点 t 的错误代价,计算公式为R(t)= r(t)*p(t), r(t)为结点 t 的错分样本率,
p(t)为落入结点 t 的样本占所有样本的比例;
R(Tt):子树 Tt 错误代价,计算公式为R(Tt)=∑R(i),i为子树 Tt 的叶节点。
比如:
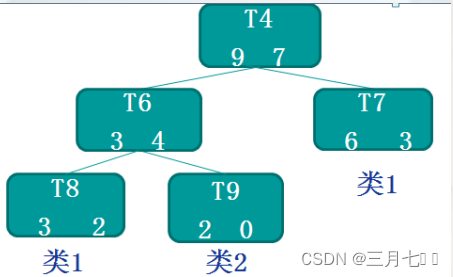
我们以非叶结点 T4 为例,假设已有的数据有60条,那么 R(t)=r(t)*p(t)=(7/16)*(16/60)=7/60
R(Tt)=∑R(i)=(2/5)*(5/60)+(0/2)*(2/60)+(3/9)*(9/60)=5/60
α=(R(t)-R(Tt))/(|N1|-1)=1/60
CCP剪枝算法分为两个步骤:
①对于完全决策树 T 的每个非叶结点计算 α 值,循环剪掉具有最小 α 值的子树,直到剩下根节
点。在该步可得到一系列的剪枝树{T0, T1,T2......Tm}。其中 T0 为原有的完全决策树,Tm为
根结点,Ti+1为对 Ti 进行剪枝的结果;
②从子树序列中,根据真实的误差估计选择最佳决策树。
通常使用1-SE(1 standard error of minimum error)规则从步骤1产生的一系列剪枝树中选择一棵
最佳的剪枝决策树。方法为,假定 一个含有N'个样本的剪枝集,分别用在步骤1中产生的剪枝树
Ti 对该剪枝集进行分类,记 Ti 所有叶结点上长生的错分样本数为Ei,令E'=min {Ei},定义E'
的标准错误为: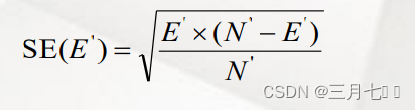
所得的最佳剪枝树 Tbest 是满足条件 Ei ≤ E'+ SE(E')且包含的接点数最少的那棵剪枝树 Ti。
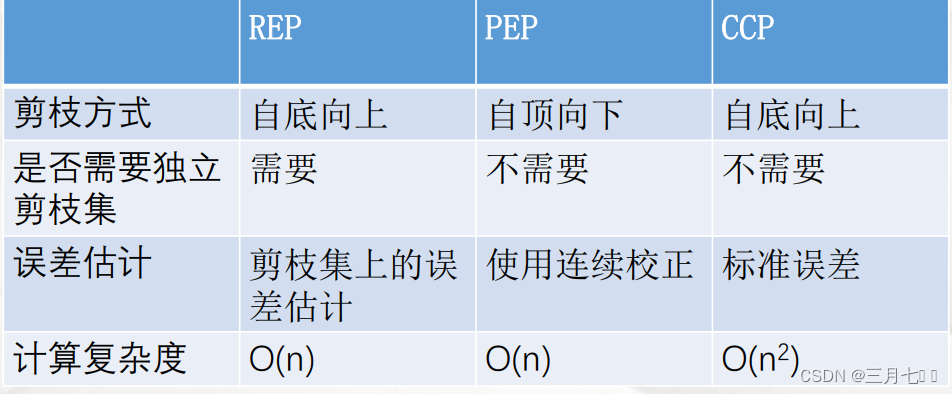
几种后剪枝方法的比较:
相关文章:
机器学习---预剪枝、后剪枝(REP、CCP、PEP、)
1. 为什么要进行剪枝 横轴表示在决策树创建过程中树的结点总数,纵轴表示决策树的预测精度。 实线显示的是决策树 在训练集上的精度,虚线显示的则是在⼀个独⽴的测试集上测量出来的精度。 随着树的增⻓,在 训练样集上的精度是单调上升的&…...

Python 爬虫—scrapy
scrapy用于从网站中提取所需数据的开源协作框架。以一种快速、简单但可扩展的方式。 该爬虫框架适合于那种静态页面, js 加载的话,如果你无法模拟它的 API 请求,可能就需要使用 selenium 这种使用无头浏览器的方式来完成你的需求了 入门 imp…...
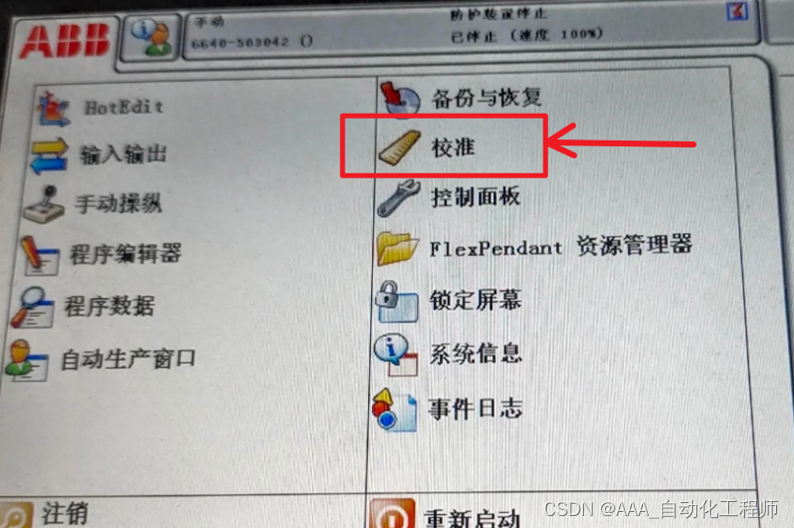
ABB机器人20032转数计数器未更新故障报警处理方法
ABB机器人20032转数计数器未更新故障报警处理方法 ABB的机器人上面安装有电池,需要定期进行更换(正常一年换一次),如果长时间不更换,电量过低,就会出现转数计数器未更新的报警,各轴编码器的位置就会丢失,在更换新电池后,需要更新转数计数器。 具体步骤如下: 先用手动…...

C# 记事本应用程序
using System; using System.Collections.Generic; using System.ComponentModel; using System.Data; using System.Drawing; using System...

模型训练:优化人工智能和机器学习,完善DevOps工具的使用
作者:JFrog大中华区总经理董任远 据说法餐的秘诀在于黄油、黄油、更多的黄油。同样,对于DevOps而言,成功的三大秘诀是自动化、自动化、更高程度的自动化,而这一切归根结底都在于构建能够更快速地不断发布新版软件的流程。 尽管人…...
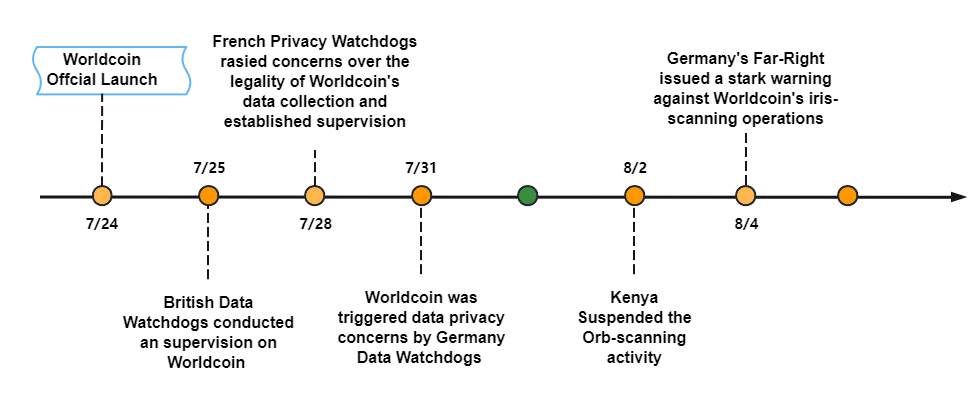
WorldCoin 运营数据,业务安全分析
WorldCoin 运营数据,业务安全分析 Worldcoin 的白皮书中声明,Worldcoin 旨在构建一个连接全球人类的新型数字经济系统,由 OpenAI 创始人 Sam Altman 于 2020 年发起。通过区块链技术在 Web3 世界中实现更加公平、开放和包容的经济体系&#…...

Java之Calender类的详细解析
Calendar类 3.1 概述 java.util.Calendar类表示一个“日历类”,可以进行日期运算。它是一个抽象类,不能创建对象,我们可以使用它的子类:java.util.GregorianCalendar类。 有两种方式可以获取GregorianCalendar对象: …...
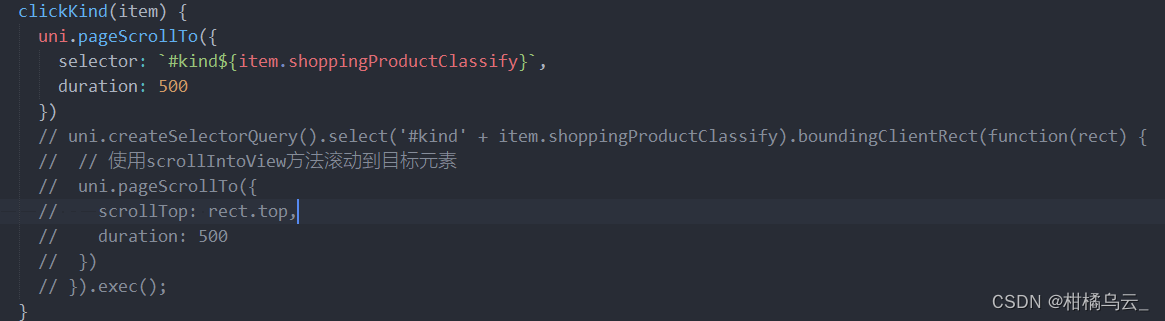
uniapp 微信小程序 锚点跳转
uniapp文档 以下是我遇到的业务场景,是点击商品分类的某一类 然后页面滚动至目标分类, 首先第一步是设置锚点跳转的目的地,在目标的dom上面添加id属性 然后给每个分类每一项添加点击事件,分类这里的item数据里面有一字段是和上…...

主成分分析笔记
主成分分析是指在尽量减少失真的前提下,将高维数据压缩成低微的方式。 减少失真是指最大化压缩后数据的方差。 记 P P P矩阵为 n m n\times m nm( n n n行 m m m列)的矩阵,表示一共有 m m m组数据,每组数据有 n n n…...
android studio 的 adb配置
首先在 Android Studio 中 打开 File -> Settings: 下载 “Google USB Driver” 这个插件 (真机调试的时候要用到), 并且记一下上面的SDK路径: 右键桌面上的 “我的电脑”, 点击 “高级系统设置”, 配置计算机的高级属性, 有两步: 添加一个新的环境变量 ANDROID_HOME, 变量…...

【HTML5高级第一篇】Web存储 - cookie、localStorage、sessionStorage
文章目录 一、数据存储1.1 cookie1.1.1 概念介绍1.1.2 存储与获取1.1.3 方法的封装1.1.4 总结 1.2 localstorage 与 sessionstorage1.2.1 概述1.2.2 操作数据的属性或方法1.2.3 案例-提交问卷1.2.4 Web Storage带来的好处 附录:1. HTML5提供的数据持久化技术&#x…...
Flink---1、概述、快速上手
1、Flink概述 1.1 Flink是什么 Flink的官网主页地址:https://flink.apache.org/ Flink的核心目标是“数据流上有状态的计算”(Stateful Computations over Data Streams)。 具体说明:Apache Flink是一个“框架和分布式处理引擎”,用于对无界…...
QT实现TCP通信(服务器与客户端搭建)
一、TCP通信框架 二、QT中的服务器操作 创建一个QTcpServer类对象,该类对象就是一个服务器调用listen函数将该对象设置为被动监听状态,监听时,可以监听指定的ip地址,也可以监听所有主机地址,可以通过指定端口号&#x…...

云备份项目
云备份项目 1. 云备份认识 自动将本地计算机上指定文件夹中需要备份的文件上传备份到服务器中。并且能够随时通过浏览器进行查看并且下载,其中下载过程支持断点续传功能,而服务器也会对上传文件进行热点管理,将非热点文件进行压缩存储&…...

基础算法(一)
目录 一.排序 快速排序: 归并排序: 二.二分法 整数二分模板: 浮点二分: 一.排序 快速排序: 从数列中挑出一个元素,称为 "基准"重新排序数列,所有元素比基准值小的摆放在基准前面,所有元素比基准值大的摆在基准的后面&#…...
Consider defining a bean of type问题解决
Consider defining a bean of type问题解决 Consider defining a bean of type问题解决 包之后,发现项目直接报错Consider defining a bean of type。 会有一些包你明明Autowired 但是还是找不到什么bean 导致你项目启动不了 解决方法一: 这个问题主要是因为项目拆包…...

Android 1.2.1 使用Eclipse + ADT + SDK开发Android APP
1.2.1 使用Eclipse ADT SDK开发Android APP 1.前言 这里我们有两条路可以选,直接使用封装好的用于开发Android的ADT Bundle,或者自己进行配置 因为谷歌已经放弃了ADT的更新,官网上也取消的下载链接,这里提供谷歌放弃更新前最新…...
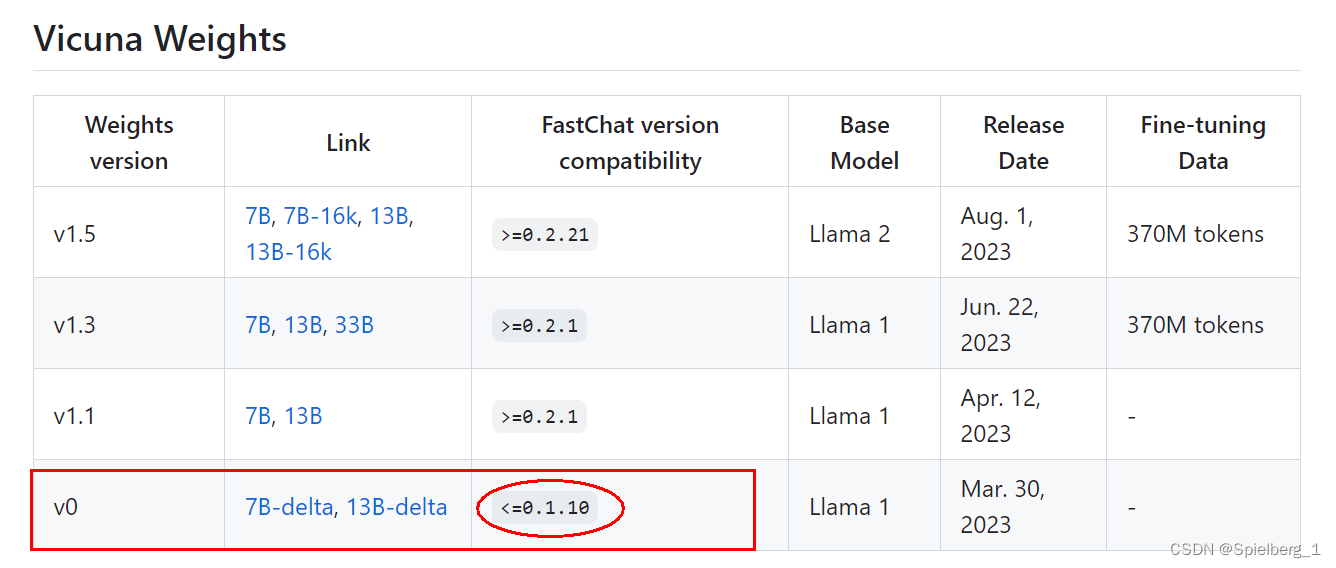
Llama-7b-hf和vicuna-7b-delta-v0合并成vicuna-7b-v0
最近使用pandagpt需要vicuna-7b-v0,重新过了一遍,前段时间部署了vicuna-7b-v3,还是有不少差别的,transforms和fastchat版本更新导致许多地方不匹配,出现很多错误,记录一下。 更多相关内容可见Fastchat实战…...

Centos、OpenEuler系统安装mysql
要在CentOS上安装MySQL并设置开机自启和root密码,请按照以下步骤进行操作: 确保您的CentOS系统已连接到Internet,并且具有管理员权限(root或sudo访问权限)。打开终端或SSH会话,使用以下命令安装MySQL&…...
如何在Win10系统上安装WSL(适用于 Linux 的 Windows 子系统)
诸神缄默不语-个人CSDN博文目录 本文介绍的方法不是唯一的安装方案,但在我的系统上可用。 文章目录 1. 视频版2. 文字版和代码3. 本文撰写过程中使用到的其他网络参考资料 1. 视频版 B站版:在Windows上安装Linux (WSL, 适用于 Linux 的 Windows 子系统…...

<6>-MySQL表的增删查改
目录 一,create(创建表) 二,retrieve(查询表) 1,select列 2,where条件 三,update(更新表) 四,delete(删除表…...
:にする)
日语学习-日语知识点小记-构建基础-JLPT-N4阶段(33):にする
日语学习-日语知识点小记-构建基础-JLPT-N4阶段(33):にする 1、前言(1)情况说明(2)工程师的信仰2、知识点(1) にする1,接续:名词+にする2,接续:疑问词+にする3,(A)は(B)にする。(2)復習:(1)复习句子(2)ために & ように(3)そう(4)にする3、…...

以下是对华为 HarmonyOS NETX 5属性动画(ArkTS)文档的结构化整理,通过层级标题、表格和代码块提升可读性:
一、属性动画概述NETX 作用:实现组件通用属性的渐变过渡效果,提升用户体验。支持属性:width、height、backgroundColor、opacity、scale、rotate、translate等。注意事项: 布局类属性(如宽高)变化时&#…...

电脑插入多块移动硬盘后经常出现卡顿和蓝屏
当电脑在插入多块移动硬盘后频繁出现卡顿和蓝屏问题时,可能涉及硬件资源冲突、驱动兼容性、供电不足或系统设置等多方面原因。以下是逐步排查和解决方案: 1. 检查电源供电问题 问题原因:多块移动硬盘同时运行可能导致USB接口供电不足&#x…...

转转集团旗下首家二手多品类循环仓店“超级转转”开业
6月9日,国内领先的循环经济企业转转集团旗下首家二手多品类循环仓店“超级转转”正式开业。 转转集团创始人兼CEO黄炜、转转循环时尚发起人朱珠、转转集团COO兼红布林CEO胡伟琨、王府井集团副总裁祝捷等出席了开业剪彩仪式。 据「TMT星球」了解,“超级…...

linux 错误码总结
1,错误码的概念与作用 在Linux系统中,错误码是系统调用或库函数在执行失败时返回的特定数值,用于指示具体的错误类型。这些错误码通过全局变量errno来存储和传递,errno由操作系统维护,保存最近一次发生的错误信息。值得注意的是,errno的值在每次系统调用或函数调用失败时…...

高防服务器能够抵御哪些网络攻击呢?
高防服务器作为一种有着高度防御能力的服务器,可以帮助网站应对分布式拒绝服务攻击,有效识别和清理一些恶意的网络流量,为用户提供安全且稳定的网络环境,那么,高防服务器一般都可以抵御哪些网络攻击呢?下面…...

自然语言处理——循环神经网络
自然语言处理——循环神经网络 循环神经网络应用到基于机器学习的自然语言处理任务序列到类别同步的序列到序列模式异步的序列到序列模式 参数学习和长程依赖问题基于门控的循环神经网络门控循环单元(GRU)长短期记忆神经网络(LSTM)…...

网络编程(UDP编程)
思维导图 UDP基础编程(单播) 1.流程图 服务器:短信的接收方 创建套接字 (socket)-----------------------------------------》有手机指定网络信息-----------------------------------------------》有号码绑定套接字 (bind)--------------…...
)
Typeerror: cannot read properties of undefined (reading ‘XXX‘)
最近需要在离线机器上运行软件,所以得把软件用docker打包起来,大部分功能都没问题,出了一个奇怪的事情。同样的代码,在本机上用vscode可以运行起来,但是打包之后在docker里出现了问题。使用的是dialog组件,…...