图神经网络教程之GCN(pyG)
图神经网络-pyG版本的GCN
Data(数据)
data.x、data.edge_index、data.edge_attr、data.y、data.pos
- 举个例子

import torch
from torch_geometric.data import Data
edge_index = torch.tensor([[0, 1, 1, 2],[1, 0, 2, 1]], dtype=torch.long)
#代表0-1 1-0 和 1-2 2-1 ,因为是无向图,所以有双向边
x = torch.tensor([[-1], [0], [1]], dtype=torch.float)
# 代表每个节点
data = Data(x=x, edge_index=edge_index)
>>> Data(edge_index=[2, 4], x=[3, 1])
# 数据构成
其中edge_index也可以这么构建
edge_index = torch.tensor([[0, 1],[1, 0],[1, 2],[2, 1]], dtype=torch.long)
- 一些实用函数
print(data.keys())
>>> ['x', 'edge_index']
print(data['x'])
>>> tensor([[-1.0],[0.0],[1.0]])
for key, item in data:print(f'{key} found in data')
>>> x found in data
>>> edge_index found in data
'edge_attr' in data
>>> False
data.num_nodes
>>> 3
data.num_edges
>>> 4
data.num_node_features
>>> 1
data.has_isolated_nodes()
>>> False
data.has_self_loops()
>>> False
data.is_directed()
>>> False
# Transfer data object to GPU.
device = torch.device('cuda')
data = data.to(device)
- 包含一些数据集
from torch_geometric.datasets import TUDataset
dataset = TUDataset(root='/tmp/ENZYMES', name='ENZYMES')
- 数据转换
转换是torchvision中转换图像和执行增强的常见方式,pyG带有自己的转换。
#对ShapeNet数据集的转换。
from torch_geometric.datasets import ShapeNet
dataset = ShapeNet(root='/tmp/ShapeNet', categories=['Airplane'])
dataset[0]
>>> Data(pos=[2518, 3], y=[2518])
通过转换从点云生成最近邻图,将点云数据集转换为图数据集
import torch_geometric.transforms as T
from torch_geometric.datasets import ShapeNet
dataset = ShapeNet(root='/tmp/ShapeNet', categories=['Airplane'],pre_transform=T.KNNGraph(k=6))
dataset[0]
>>> Data(edge_index=[2, 15108], pos=[2518, 3], y=[2518])
- 图表上的表示学习
-
导入所需的库和模块:
torch:PyTorch的主要库。torch.nn.functional as F:PyTorch的神经网络函数模块,用于定义神经网络的层和操作。torch_geometric.nn:PyTorch Geometric库中的神经网络模块,包括图卷积网络(GCN)的实现。torch_geometric.datasets:PyTorch Geometric中的数据集模块,用于加载图数据集。
-
加载Cora数据集:
dataset = Planetoid(root='/tmp/Cora', name='Cora')这行代码加载了Cora数据集,这是一个用于节点分类的图数据集。数据集将被下载到
/tmp/Cora目录中。 -
定义了一个名为
GCN的神经网络类:class GCN(torch.nn.Module):这个类继承自PyTorch的
torch.nn.Module基类,表示它是一个神经网络模型。 -
在
GCN类的构造函数中,定义了两个图卷积层(GCNConv):def __init__(self):super(GCN, self).__init__()self.conv1 = GCNConv(dataset.num_node_features, 16)self.conv2 = GCNConv(16, dataset.num_classes)GCNConv层是图卷积层,用于从图数据中提取特征。self.conv1是第一个GCNConv层,它将输入特征的维度设置为dataset.num_node_features(Cora数据集中节点的特征维度)并输出16维特征。self.conv2是第二个GCNConv层,将16维特征映射到数据集的类别数。
-
检查并设置GPU或CPU设备:
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')这段代码会检查你的系统是否有可用的GPU,并将
device设置为GPU或CPU,以便在相应的设备上运行模型。 -
创建并将模型和数据移动到所选设备上:
model = GCN().to(device) data = dataset[0].to(device)这将实例化之前定义的GCN模型,并将模型的参数和计算移动到GPU或CPU上。
-
定义优化器(这里使用Adam优化器):
optimizer = torch.optim.Adam(model.parameters(), lr=0.01, weight_decay=5e-4)这行代码创建一个Adam优化器,并将模型的参数传递给它,用于模型参数的更新。
lr是学习率,weight_decay是L2正则化项的权重。 -
将模型设置为训练模式:
model.train()这行代码将模型切换到训练模式,这对于启用训练特定的层(例如,dropout)非常重要。
-
开始训练循环,训练模型200个epoch:
for epoch in range(200):这是一个训练循环,将模型训练200次。
-
在每个epoch中,首先将优化器的梯度清零:
optimizer.zero_grad()这行代码用于清除之前的梯度信息,以准备计算新的梯度。
-
通过模型前向传播计算预测结果:
out = model(data)这会将数据传递给你的GCN模型,然后返回模型的预测结果。
-
计算损失函数,这里使用负对数似然损失(Negative Log-Likelihood Loss):
loss = F.nll_loss(out[data.train_mask], data.y[data.train_mask])这行代码计算了在训练节点子集上的负对数似然损失。
data.train_mask指定了用于训练的节点子集,data.y是节点的真实标签。 -
反向传播和参数更新:
loss.backward() optimizer.step()这两行代码用于计算梯度并执行梯度下降,更新模型的参数,以最小化损失函数。
-
将模型设置为评估模式:
model.eval()这行代码将模型切换到评估模式,以便在测试数据上进行预测。
-
在测试集上进行预测:
pred = model(data).argmax(dim=1)这行代码用于在测试数据上进行预测,并找到每个节点最可能的类别。
-
计算模型的准确性:
correct = (pred[data.test_mask] == data.y[data.test_mask]).sum() acc = int(correct) / int(data.test_mask.sum()) print(f'Accuracy: {acc:.4f}')这段代码计算了模型在测试集上的准确性,并打印出来。
import torch
import torch.nn.functional as F
from torch_geometric.nn import GCNConv
from torch_geometric.datasets import Planetoid# 加载 Cora 数据集
dataset = Planetoid(root='/tmp/Cora', name='Cora')# 定义 GCN 模型
class GCN(torch.nn.Module):def __init__(self):super(GCN, self).__init__()self.conv1 = GCNConv(dataset.num_node_features, 16)self.conv2 = GCNConv(16, dataset.num_classes)def forward(self, data):x, edge_index = data.x, data.edge_indexx = self.conv1(x, edge_index)x = F.relu(x)x = F.dropout(x, training=self.training)x = self.conv2(x, edge_index)return F.log_softmax(x, dim=1)# 检查并设置 GPU 或 CPU 设备
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')# 创建并将模型和数据移动到所选设备上
model = GCN().to(device)
data = dataset[0].to(device)# 定义优化器
optimizer = torch.optim.Adam(model.parameters(), lr=0.01, weight_decay=5e-4)# 将模型设置为训练模式
model.train()# 训练模型
for epoch in range(200):optimizer.zero_grad()out = model(data)loss = F.nll_loss(out[data.train_mask], data.y[data.train_mask])loss.backward()optimizer.step()# 将模型设置为评估模式
model.eval()# 在测试集上进行预测
pred = model(data).argmax(dim=1)# 计算模型的准确性
correct = (pred[data.test_mask] == data.y[data.test_mask]).sum()
acc = int(correct) / int(data.test_mask.sum())
print(f'Accuracy: {acc:.4f}')optimizer.step()# 将模型设置为评估模式
model.eval()# 在测试集上进行预测
pred = model(data).argmax(dim=1)# 计算模型的准确性
correct = (pred[data.test_mask] == data.y[data.test_mask]).sum()
acc = int(correct) / int(data.test_mask.sum())
print(f'Accuracy: {acc:.4f}')
相关文章:
图神经网络教程之GCN(pyG)
图神经网络-pyG版本的GCN Data(数据) data.x、data.edge_index、data.edge_attr、data.y、data.pos 举个例子 import torch from torch_geometric.data import Data edge_index torch.tensor([[0, 1, 1, 2],[1, 0, 2, 1]], dtypetorch.long) #代表…...

python中的逻辑运算
逻辑运算 逻辑运算符是python用来进行逻辑判断的运算符,虽然运算符只有and、or、not三种,但是理解这三个运算符的原理才是最重要的 python中对false的认定 逻辑运算符是python用来进行逻辑判断的运算符,虽然运算符只有and、or、not三种&…...
TortoiseGit设置作者信息和用户名、密码存储
前言 Git 客户端每次与服务器交互,都需要输入密码,但是我们可以配置保存密码,只需要输入一次,就不再需要输入密码。 操作说明 在任意文件夹下,空白处,鼠标右键点击 在弹出菜单中按照下图点击 依次点击下…...

Fragment.OnPause的事情
我们知道Fragment的生命周期依附于相应Activity的生命周期,如果activity A调用了onPause,则A里面的fragment也会相应收到onPause回调,这里以support27.1.1版本的源码来说明Fragment生命周期onPause的事情。 当activity执行onPause时ÿ…...
【C++基础】5. 变量作用域
文章目录 【 1. 局部变量 】【 2. 全局变量 】【 3. 局部变量和全局变量的初始化 】 作用域是程序的一个区域,一般来说有三个地方可以定义变量: 在函数或一个代码块内部声明的变量,称为局部变量。 在函数参数的定义中声明的变量,称…...

Python列表排序
介绍一个关于列表排序的sort方法,看下面的案例: """ 列表的sort方法来对列表进行自定义排序 """# 准备列表 my_list [["a", 33], ["b", 55], ["c", 11]]# 排序,基于带名函数 …...
(云HIS)云医院管理系统源码 SaaS模式 B/S架构 基于云计算技术
通过提供“一个中心多个医院”平台,为集团连锁化的医院和区域医疗提供最前沿的医疗信息化云解决方案。 一、概述 云HIS系统源码是一款满足基层医院各类业务需要的健康云产品。该系统能帮助基层医院完成日常各类业务,提供病患预约挂号支持、收费管理、病…...

sql:SQL优化知识点记录(十一)
(1)用Show Profile进行sql分析 新的一个优化的方式show Profile 运行一些查询sql: 查看一下我们执行过的sql 显示sql查询声明周期完整的过程: 当执行过程出现了下面这4个中的时,就会有问题导致效率慢 8这个sql创建…...

leetcode-链表类题目
文章目录 链表(Linked List) 链表(Linked List) 定义:链表(Linked List)是一种线性表数据结构,他用一组任意的存储单元来存储数据,同时存储当前数据元素的直接后继元素所…...

数据结构——哈希
哈希表 是一种使用哈希函数组织数据的数据结构,它支持快速插入和搜索。 哈希表(又称散列表)的原理为:借助 哈希函数,将键映射到存储桶地址。更确切地说, 1.首先开辟一定长度的,具有连续物理地址…...

效果好的it监控系统特点
一个好的IT监控系统应该具备以下特点: 全面性:IT监控系统应该能够监视和管理IT系统的所有方面,包括网络、服务器、应用程序和数据库等。这样可以确保系统的各个方面都得到充分的监视和管理。 可靠性:IT监控系统需要保持高可…...

leetcode1288. 删除被覆盖区间(java)
删除被覆盖区间 题目描述贪心法代码演示 题目描述 难度 - 中等 leetcode1288. 删除被覆盖区间 给你一个区间列表,请你删除列表中被其他区间所覆盖的区间。 只有当 c < a 且 b < d 时,我们才认为区间 [a,b) 被区间 [c,d) 覆盖。 在完成所有删除操作…...

Python 虚拟环境相关命令
一 激活 在 cd venv/scripts 进入虚拟环境 执行命令 activate 1、创建虚拟环境 $ python -m venv 2、激活虚拟环境 $ source <venv>/bin/activate 3、关闭虚拟环境 $ deactivate...

使用U盘同步WSL2中的git项目
1、将U盘挂载到WSL2中 假设U盘在windows资源管理器中被识别为F盘,需要在WSL2中创建一个目录挂载U盘 sudo mkdir /mnt/f sudo mount -t drvfs F: /mnt/f后续所有的操作都完成后,拔掉U盘前,可以使用下面的命令从WSL2中安全的移除U盘 umount …...
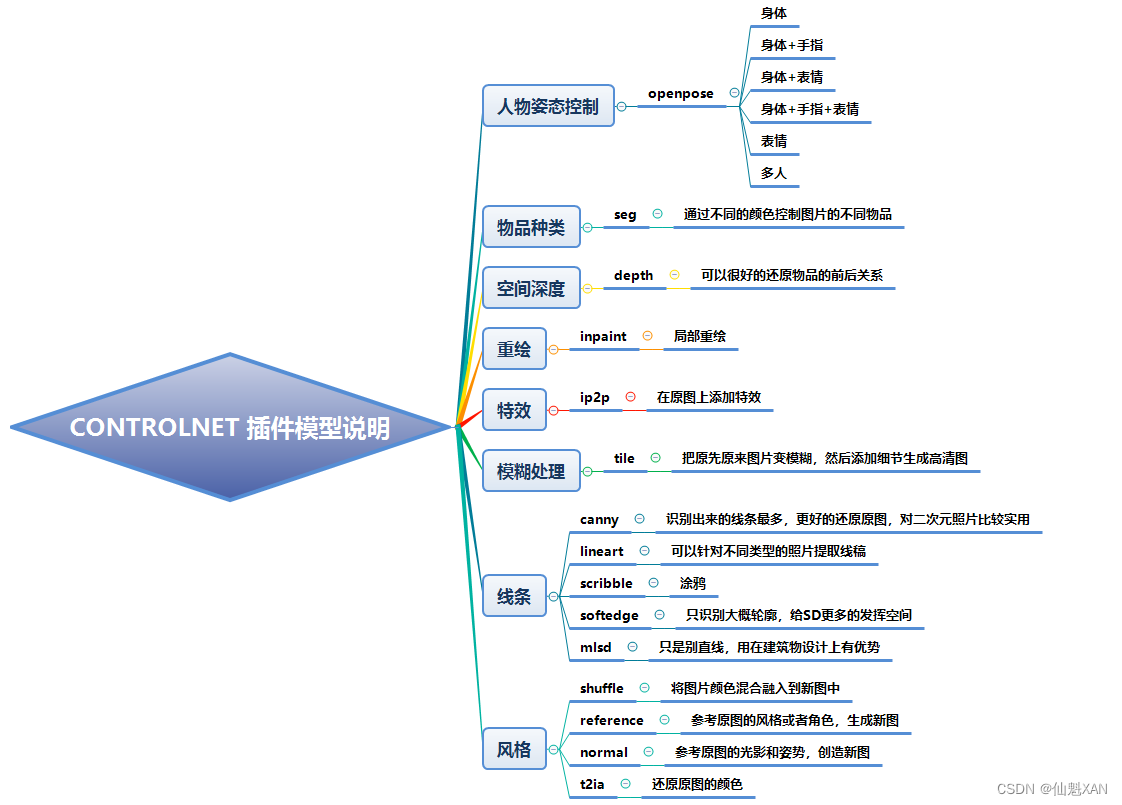
Stable Diffuse AI 绘画 之 ControlNet 插件及其对应模型的下载安装
Stable Diffuse AI 绘画 之 ControlNet 插件及其对应模型的下载安装 目录 Stable Diffuse AI 绘画 之 ControlNet 插件及其对应模型的下载安装 一、简单介绍 二、ControlNet 插件下载安装 三、ControlNet 插件模型下载安装 四、ControlNet 插件其他的下载安装方式 五、Co…...
CMAK学习
VS中的cmake_cmake vs_今天也要debug的博客-CSDN博客 利用vs2017 CMake开发跨平台C项目实战_cmake vs2017_神气爱哥的博客-CSDN博客 【【入门】在VS中使用CMake管理若干程序】https://www.bilibili.com/video/BV1iz4y117rZ?vd_source0aeb782d0b9c2e6b0e0cdea3e2121eba...

Python 推导式
Python 推导式 Python 推导式是一种独特的数据处理方式,可以从一个数据序列构建另一个新的数据序列的结构体。 Python 支持各种数据结构的推导式: 列表(list)推导式字典(dict)推导式集合(set)推导式元组(tuple)推导式 列表推导式 列表推导式格式为&…...

es6的新特性有哪些
ES6(ECMAScript 2015)是JavaScript的一个重要版本,引入了许多新的语法和功能。以下是ES6的一些主要特性: 块级作用域(Block Scope):引入了let和const关键字,可以在块级作用域中声明变…...

logstash 消费kafka数据,转发到tcp端口
1, logstash 配置文件 [roothost1: ] cat /opt/logstash/kafka-to-tcp.yml input { kafka {bootstrap_servers > "192.168.0.11:9092" #这里可以是kafka集群,如"192.168.149.101:9092,192.168.149.102:9092"consumer_threads &…...

航天智信:严控航天系统研发安全,助力建设“航天强国”
航天智信作为中国航天科工三院在信息装备领域“做大做强”的重要布局,主要从事系统运用与联合体系研究,复杂信息系统的顶层设计、总体论证及研制生产,提供体系级、系统级信息系统整体解决方案,以及信息安全系统的设计研发与集成验…...

设计模式和设计原则回顾
设计模式和设计原则回顾 23种设计模式是设计原则的完美体现,设计原则设计原则是设计模式的理论基石, 设计模式 在经典的设计模式分类中(如《设计模式:可复用面向对象软件的基础》一书中),总共有23种设计模式,分为三大类: 一、创建型模式(5种) 1. 单例模式(Sing…...

Linux 文件类型,目录与路径,文件与目录管理
文件类型 后面的字符表示文件类型标志 普通文件:-(纯文本文件,二进制文件,数据格式文件) 如文本文件、图片、程序文件等。 目录文件:d(directory) 用来存放其他文件或子目录。 设备…...

【人工智能】神经网络的优化器optimizer(二):Adagrad自适应学习率优化器
一.自适应梯度算法Adagrad概述 Adagrad(Adaptive Gradient Algorithm)是一种自适应学习率的优化算法,由Duchi等人在2011年提出。其核心思想是针对不同参数自动调整学习率,适合处理稀疏数据和不同参数梯度差异较大的场景。Adagrad通…...

智慧工地云平台源码,基于微服务架构+Java+Spring Cloud +UniApp +MySql
智慧工地管理云平台系统,智慧工地全套源码,java版智慧工地源码,支持PC端、大屏端、移动端。 智慧工地聚焦建筑行业的市场需求,提供“平台网络终端”的整体解决方案,提供劳务管理、视频管理、智能监测、绿色施工、安全管…...

五年级数学知识边界总结思考-下册
目录 一、背景二、过程1.观察物体小学五年级下册“观察物体”知识点详解:由来、作用与意义**一、知识点核心内容****二、知识点的由来:从生活实践到数学抽象****三、知识的作用:解决实际问题的工具****四、学习的意义:培养核心素养…...

使用van-uploader 的UI组件,结合vue2如何实现图片上传组件的封装
以下是基于 vant-ui(适配 Vue2 版本 )实现截图中照片上传预览、删除功能,并封装成可复用组件的完整代码,包含样式和逻辑实现,可直接在 Vue2 项目中使用: 1. 封装的图片上传组件 ImageUploader.vue <te…...

涂鸦T5AI手搓语音、emoji、otto机器人从入门到实战
“🤖手搓TuyaAI语音指令 😍秒变表情包大师,让萌系Otto机器人🔥玩出智能新花样!开整!” 🤖 Otto机器人 → 直接点明主体 手搓TuyaAI语音 → 强调 自主编程/自定义 语音控制(TuyaAI…...

多模态大语言模型arxiv论文略读(108)
CROME: Cross-Modal Adapters for Efficient Multimodal LLM ➡️ 论文标题:CROME: Cross-Modal Adapters for Efficient Multimodal LLM ➡️ 论文作者:Sayna Ebrahimi, Sercan O. Arik, Tejas Nama, Tomas Pfister ➡️ 研究机构: Google Cloud AI Re…...

Linux --进程控制
本文从以下五个方面来初步认识进程控制: 目录 进程创建 进程终止 进程等待 进程替换 模拟实现一个微型shell 进程创建 在Linux系统中我们可以在一个进程使用系统调用fork()来创建子进程,创建出来的进程就是子进程,原来的进程为父进程。…...

Kafka入门-生产者
生产者 生产者发送流程: 延迟时间为0ms时,也就意味着每当有数据就会直接发送 异步发送API 异步发送和同步发送的不同在于:异步发送不需要等待结果,同步发送必须等待结果才能进行下一步发送。 普通异步发送 首先导入所需的k…...