java八股文面试[数据库]——explain
使用 EXPLAIN 关键字可以模拟优化器来执行SQL查询语句,从而知道MySQL是如何处理我们的SQL语句的。分析出查询语句或是表结构的性能瓶颈。
MySQL查询过程
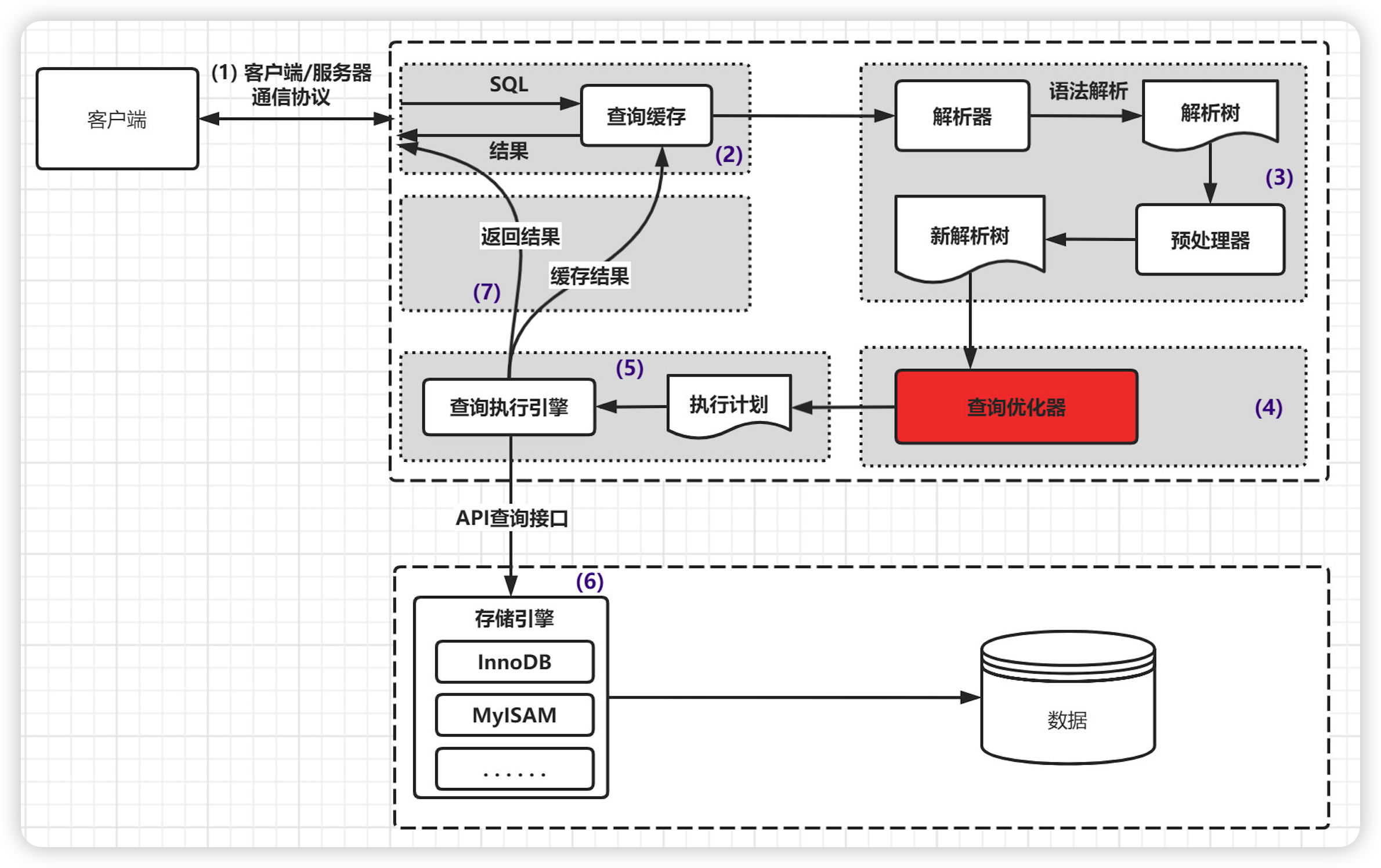
通过explain我们可以获得以下信息:
-
表的读取顺序
-
数据读取操作的操作类型
-
哪些索引可以被使用
-
哪些索引真正被使用
-
表的直接引用
-
每张表的有多少行被优化器查询了
Explain使用方式: explain+sql语句, 通过执行explain可以获得sql语句执行的相关信息
explain select * from users;
type字段中有哪些常见的值?
type字段在 MySQL 官网文档描述如下:
The join type. For descriptions of the different types.
type字段显示的是连接类型 ( join type表示的是用什么样的方式来获取数据),它描述了找到所需数据所使用的扫描方式, 是较为重要的一个指标。
下面给出各种连接类型,按照从最佳类型到最坏类型进行排序:
-- 完整的连接类型比较多 system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL -- 简化之后,我们可以只关注一下几种 system > const > eq_ref > ref > range > index > ALL
一般来说,需要保证查询至少达到 range级别,最好能到ref,否则就要就行SQL的优化调整
下面介绍type字段不同值表示的含义:
| type类型 | 解释 |
|---|---|
| system | 不进行磁盘IO,查询系统表,仅仅返回一条数据 |
| const | 查找主键索引,最多返回1条或0条数据. 属于精确查找 |
| eq_ref | 查找唯一性索引,返回数据最多一条, 属于精确查找 |
| ref | 查找非唯一性索引,返回匹配某一条件的多条数据,属于精确查找,数据返回可能是多条. |
| range | 查找某个索引的部分索引,只检索给定范围的行,属于范围查找. 比如: > 、 < 、in 、between |
| index | 查找所有索引树,比ALL快一些,因为索引文件要比数据文件小. |
| ALL | 不使用任何索引,直接进行全表扫描 |
Extra有哪些主要指标,各自的含义是什么?
Extra 是 EXPLAIN 输出中另外一个很重要的列,该列显示MySQL在查询过程中的一些详细信息
| extra类型 | 解释 |
|---|---|
| Using filesort | MySQL中无法利用索引完成的排序操作称为 “文件排序” |
| Using index | 表示直接访问索引就能够获取到所需要的数据(覆盖索引),不需要通过索引回表 |
| Using index condition | 搜索条件中虽然出现了索引列,但是有部分条件无法使用索引, 会根据能用索引的条件先搜索一遍再匹配无法使用索引的条件。 |
| Using join buffer | 使用了连接缓存, 会显示join连接查询时,MySQL选择的查询算法 |
| Using temporary | 表示MySQL需要使用临时表来存储结果集,常见于排序和分组查询 |
| Using where | 意味着全表扫描或者在查找使用索引的情况下,但是还有查询条件不在索引字段当中 |
实际使用示例:
先解析一条sql语句,看出现什么内容
EXPLAIN SELECT s.uid,s.username,s.name,f.email,f.mobile,f.phone,f.postalcode,f.address
FROM uchome_space AS s,uchome_spacefield AS f
WHERE 1 AND s.groupid=0 AND s.uid=f.uid

1. id
SELECT识别符。这是SELECT查询序列号。这个不重要,查询序号即为sql语句执行的顺序,看下面这条sql
EXPLAIN SELECT * FROM (SELECT* FROM uchome_space LIMIT 10) AS s
它的执行结果为

可以看到这时的id变化了
如果是子查询,id序号会自增,id值越大优先级就越高,越先被执行
id 相同与不同,同时存在
mysql> EXPLAIN -> select * from(select * from tb_order tb1 where tb1.id =1) s1,tb_user tb2 where s1.tb_user_id = tb2.id;
+----+-------------+------------+--------+---------------+---------+---------+-------+------+-------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+------------+--------+---------------+---------+---------+-------+------+-------+
| 1 | PRIMARY | <derived2> | system | NULL | NULL | NULL | NULL | 1 | NULL |
| 1 | PRIMARY | tb2 | const | PRIMARY | PRIMARY | 4 | const | 1 | NULL |
| 2 | DERIVED | tb1 | const | PRIMARY | PRIMARY | 4 | const | 1 | NULL |
+----+-------------+------------+--------+---------------+---------+---------+-------+------+-------+2.select_type
select类型,数据读取操作的操作类型,它有以下几种值
2.1 simple
它表示简单的select,没有union和子查询
2.2 primary
最外面的select,在有子查询的语句中,最外面的select查询就是primary,上图中就是这样
2.3 union
union语句的第二个或者说是后面那一个.现执行一条语句,
explain select * from uchome_space limit 10 union select * from uchome_space limit 10,10
会有如下结果

第二条语句使用了union
2.4 dependent union
UNION中的第二个或后面的SELECT语句,取决于外面的查询
2.5 union result
从UNION表获取结果的select,UNION的结果,如上面所示
2.6 DERIVED
在FROM列表中包含的子查询会被标记为DERIVED(衍生表),MYSQL会递归执行这些子查询,把结果集放到零时表中。
还有几个参数,这里就不说了,不重要
3 table
该行数据是关于哪张表,输出的行所用的表,这个参数显而易见,容易理解
4 type
连接类型。有多个参数,先从最佳类型到最差类型介绍 重要且困难
访问类型 由好到差system > const > eq_ref > ref > range > index > ALL
4.1 system
表仅有一行,这是const类型的特列,平时不会出现,这个也可以忽略不计
4.2 const
表最多有一个匹配行,const用于比较primary key 或者unique索引。因为只匹配一行数据,所以很快
记住一定是用到primary key 或者unique,并且只检索出两条数据的 情况下才会是const,看下面这条语句
explain SELECT * FROM `asj_admin_log` limit 1,结果是

虽然只搜索一条数据,但是因为没有用到指定的索引,所以不会使用const.继续看下面这个
explain SELECT * FROM `asj_admin_log` where log_id = 111

log_id是主键,所以使用了const。所以说可以理解为const是最优化的
4.3 eq_ref
对于eq_ref的解释,mysql手册是这样说的:"对于每个来自于前面的表的行组合,从该表中读取一行。这可能是最好的联接类型,除了const类型。它用在一个索引的所有部分被联接使用并且索引是UNIQUE或PRIMARY KEY"。eq_ref可以用于使用=比较带索引的列。看下面的语句
explain select * from uchome_spacefield,uchome_space where uchome_spacefield.uid = uchome_space.uid
得到的结果是下图所示。很明显,mysql使用eq_ref联接来处理uchome_space表。

目前的疑问:
4.3.1 为什么是只有uchome_space一个表用到了eq_ref,并且sql语句如果变成
explain select * from uchome_space,uchome_spacefield where uchome_space.uid = uchome_spacefield.uid
结果还是一样,需要说明的是uid在这两个表中都是primary
4.4 ref
对于每个来自于前面的表的行组合,所有有匹配索引值的行将从这张表中读取。如果联接只使用键的最左边的前缀,或如果键不是UNIQUE或PRIMARY KEY(换句话说,如果联接不能基于关键字选择单个行的话),则使用ref。如果使用的键仅仅匹配少量行,该联接类型是不错的。
看下面这条语句 explain select * from uchome_space where uchome_space.friendnum = 0,得到结果如下,这条语句能搜出1w条数据
4.5 ref_or_null
该联接类型如同ref,但是添加了MySQL可以专门搜索包含NULL值的行。在解决子查询中经常使用该联接类型的优化。
上面这五种情况都是很理想的索引使用情况
4.6 index_merge
该联接类型表示使用了索引合并优化方法。在这种情况下,key列包含了使用的索引的清单,key_len包含了使用的索引的最长的关键元素。
4.7 unique_subquery
4.8 index_subquery
4.9 range
给定范围内的检索,使用一个索引来检查行。看下面两条语句
explain select * from uchome_space where uid in (1,2)
explain select * from uchome_space where groupid in (1,2)
uid有索引,groupid没有索引,结果是第一条语句的联接类型是range,第二个是ALL.以为是一定范围所以说像 between也可以这种联接,很明显
explain select * from uchome_space where friendnum = 17
这样的语句是不会使用range的,它会使用更好的联接类型就是上面介绍的ref
只检索给定范围的行,使用一个索引来选着行。key列显示使用了哪个索引。一般在你的WHERE 语句中出现between 、< 、> 、in 等查询,这种给定范围扫描比全表扫描要好。因为他只需要开始于索引的某一点,而结束于另一点,不用扫描全部索引。
4.10 index
该联接类型与ALL相同,除了只有索引树被扫描。这通常比ALL快,因为索引文件通常比数据文件小。(也就是说虽然all和Index都是读全表,但index是从索引中读取的,而all是从硬盘中读的)
当查询只使用作为单索引一部分的列时,MySQL可以使用该联接类型。
FUll Index Scan 扫描遍历索引树(扫描全表的索引,从索引中获取数据)。
4.11 ALL
对于每个来自于先前的表的行组合,进行完整的表扫描。如果表是第一个没标记 const的表,这通常不好,并且通常在它情况下 很差。通常可以增加更多的索引而不要使用 ALL,使得行能基于前面的表中的常数值或列值被检索出。
全表扫描 从磁盘中获取数据 百万级别的数据ALL类型的数据尽量优化
5 possible_keys
提示使用哪个索引会在该表中找到行,不太重要
显示可能应用在这张表的索引,一个或者多个。查询涉及到的字段若存在索引,则该索引将被列出,但不一定被查询实际使用。
6 keys
MYSQL使用的索引,简单且重要
实际使用到的索引。如果为NULL,则没有使用索引。查询中如果使用了覆盖索引,则该索引仅出现在key列表中。覆盖索引:select 后的 字段与我们建立索引的字段个数一致。
7 key_len
MYSQL使用的索引长度
表示索引中使用的字节数,可通过该列计算查询中使用的索引长度。在不损失精确性的情况下,长度越短越好。key_len 显示的值为索引字段的最大可能长度,并非实际使用长度,即key_len是根据表定义计算而得,不是通过表内检索出来的。
8 ref
ref列显示使用哪个列或常数与key一起从表中选择行。
显示索引的哪一列被使用了,如果可能的话,是一个常数。哪些列或常量被用于查找索引列上的值。
9 rows
显示MYSQL执行查询的行数,简单且重要,数值越大越不好,说明没有用好索引
(每张表有多少行被优化器查询):根据表统计信息及索引选用的情况,大致估算找到所需记录需要读取的行数。
10 Extra
该列包含MySQL解决查询的详细信息。
10.1 Distinct
MySQL发现第1个匹配行后,停止为当前的行组合搜索更多的行。一直没见过这个值
10.2 Not exists
10.3 range checked for each record
没有找到合适的索引
10.4 using filesort
MYSQL手册是这么解释的“MySQL需要额外的一次传递,以找出如何按排序顺序检索行。通过根据联接类型浏览所有行并为所有匹配WHERE子句的行保存排序关键字和行的指针来完成排序。然后关键字被排序,并按排序顺序检索行。”目前不太明白
我的理解:如果存在排序并且取出的列包括text类型会使用到using filesort,这会非常慢
10.5 using index
只使用索引树中的信息而不需要进一步搜索读取实际的行来检索表中的信息。这个比较容易理解,就是说明是否使用了索引
explain select * from ucspace_uchome where uid = 1的extra为using index(uid建有索引)
explain select count(*) from uchome_space where groupid=1 的extra为using where(groupid未建立索引)
10.6 using temporary
为了解决查询,MySQL需要创建一个临时表来容纳结果。典型情况如查询包含可以按不同情况列出列的GROUP BY和ORDER BY子句时。
出现using temporary就说明语句需要优化了,举个例子来说
EXPLAIN SELECT ads.id FROM ads, city WHERE city.city_id = 8005 AND ads.status = 'online' AND city.ads_id=ads.id ORDER BY ads.id desc
id select_type table type possible_keys key key_len ref rows filtered Extra
------ ----------- ------ ------ -------------- ------- ------- -------------------- ------ -------- -------------------------------
1 SIMPLE city ref ads_id,city_id city_id 4 const 2838 100.00 Using temporary; Using filesort
1 SIMPLE ads eq_ref PRIMARY PRIMARY 4 city.ads_id 1 100.00 Using where
这条语句会使用using temporary,而下面这条语句则不会
EXPLAIN SELECT ads.id FROM ads, city WHERE city.city_id = 8005 AND ads.status = 'online' AND city.ads_id=ads.id ORDER BYcity.ads_id desc
id select_type table type possible_keys key key_len ref rows filtered Extra
------ ----------- ------ ------ -------------- ------- ------- -------------------- ------ -------- ---------------------------
1 SIMPLE city ref ads_id,city_id city_id 4 const 2838 100.00 Using where; Using filesort
1 SIMPLE ads eq_ref PRIMARY PRIMARY 4 city.ads_id 1 100.00 Using where
这是为什么呢?他俩之间只是一个order by不同,MySQL 表关联的算法是 Nest Loop Join,是通过驱动表的结果集作为循环基础数据,然后一条一条地通过该结果集中的数据作为过滤条件到下一个表中查询数据,然后合并结果。EXPLAIN 结果中,第一行出现的表就是驱动表(Important!)以上两个查询语句,驱动表都是 city,如上面的执行计划所示!
对驱动表可以直接排序,对非驱动表(的字段排序)需要对循环查询的合并结果(临时表)进行排序 (Important!)
因此,order by ads.id desc 时,就要先 using temporary 了
驱动表的定义
1)指定了联接条件时,满足查询条件的记录行数少的表为[驱动表];
2)未指定联接条件时,行数少的表为[驱动表](Important!)。
永远用小结果集驱动大结果集
当不确定是用哪种类型的join时,让mysql优化器自动去判断,我们只需写select * from t1,t2 where t1.field = t2.field
通俗解释:select * from table order by field
其中filed建普通索引,这种情况会使用到using temporary,因为虽然这时候使用到了索引,但因为扫描的是全表,mysql优化器会判断:反正是搜索全表而且要排序,因为这时候要回行,我还不如不沿着索引找数据,直接全部检索出所有数据来在排序。
如果语句这么写 select * from table where field > 1 order by field.mysql优化器就会这么判断:这时候不是搜全表,我需要先根据where条件,沿着索引树搜出想要的相应索引数据,在回行(一边找索引一边回行)。这时候就不需要临时表了
10.7 using where
WHERE子句用于限制哪一个行匹配下一个表或发送到客户。除非你专门从表中索取或检查所有行,如果Extra值不为Using where并且表联接类型为ALL或index,查询可能会有一些错误。(这个说明不是很理解,因为很多很多语句都会有where条件,而type为all或index只能说明检索的数据多,并不能说明错误,useing where不是很重要,但是很常见)
如果想要使查询尽可能快,应找出Using filesort 和Using temporary的Extra值。
10.8 Using sort_union(...) , Using union(...) , Using intersect(...)
这些函数说明如何为index_merge联接类型合并索引扫描
10.9 Using index for group-by
类似于访问表的Using index方式,Using index for group-by表示MySQL发现了一个索引,可以用来查询GROUP BY或DISTINCT查询的所有列,而不要额外搜索硬盘访问实际的表。并且,按最有效的方式使用索引,以便对于每个组,只读取少量索引条目。
知识来源:马士兵教育
MYSQL explain详解_Venlenter的博客-CSDN博客
Mysql中explain作用详解_Mysql_脚本之家
相关文章:

java八股文面试[数据库]——explain
使用 EXPLAIN 关键字可以模拟优化器来执行SQL查询语句,从而知道MySQL是如何处理我们的SQL语句的。分析出查询语句或是表结构的性能瓶颈。 MySQL查询过程 通过explain我们可以获得以下信息: 表的读取顺序 数据读取操作的操作类型 哪些索引可以被使用 …...

Kafka3.0.0版本——增加副本因子
目录 一、服务器信息二、启动zookeeper和kafka集群2.1、先启动zookeeper集群2.2、再启动kafka集群 三、增加副本因子3.1、增加副本因子的概述3.2、增加副本因子的示例3.2.1、创建topic(主题)3.2.2、手动增加副本存储 一、服务器信息 四台服务器 原始服务器名称原始服务器ip节点…...
升级iOS 17出现白苹果、不断重启等系统问题怎么办?
iOS 17发布后了,很多果粉都迫不及待的将iphone/ipad升级到最新iOS17系统,体验新系统功能。 但部分果粉因硬件、软件的各种情况,导致升级系统后出现故障,比如白苹果、不断重启、卡在系统升级界面等等问题。 如果遇到了这些系统问题…...

6. `Java` 并发基础之`ReentrantReadLock`
前言:随着多线程程序的普及,线程同步的问题变得越来越常见。Java中提供了多种同步机制来确保线程安全,其中之一就是ReentrantLock。ReentrantLock是Java中比较常用的一种同步机制,它提供了一系列比synchronized更加灵活和可控的操…...
float浮动布局大战position定位布局
华子目录 布局方式普通文档流布局浮动布局(浮动主要针对与black,inline元素)float属性浮动用途浮动元素父级高度塌陷 position属性定位篇相对定位(relative为属性值,配合left属性,和top属性使用)…...
算法 数据结构 递归插入排序 java插入排序 递归求解插入排序算法 如何用递归写插入排序 插入排序动图 插入排序优化 数据结构(十)
1. 插入排序(insertion-sort): 是一种简单直观的排序算法。它的工作原理是通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入 算法稳定性: 对于两个相同的数,经过…...
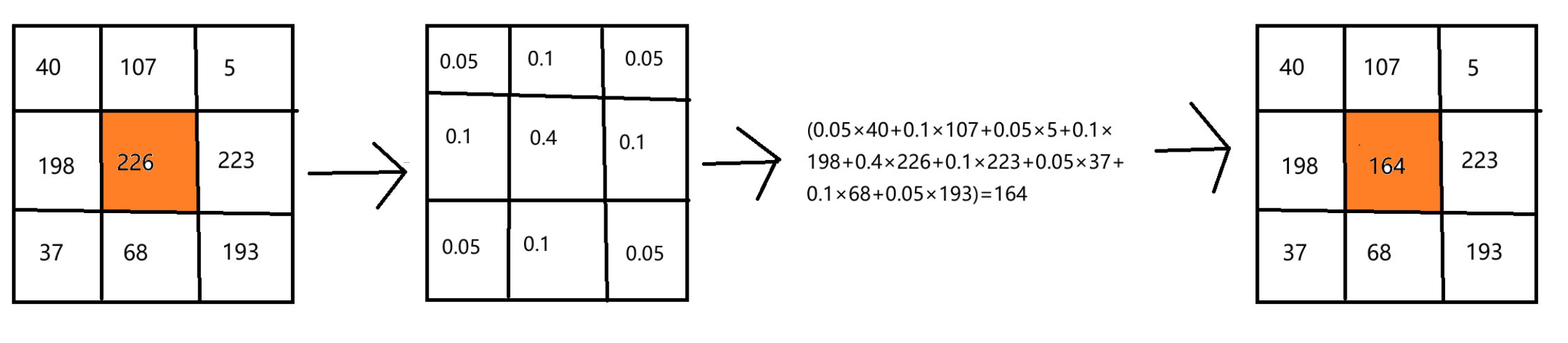
OpenCV(二十二):均值滤波、方框滤波和高斯滤波
目录 1.均值滤波 2.方框滤波 3.高斯滤波 1.均值滤波 OpenCV中的均值滤波(Mean Filter)是一种简单的滤波技术,用于平滑图像并减少噪声。它的原理非常简单:对于每个像素,将其与其周围邻域内像素的平均值作为新的像素值…...
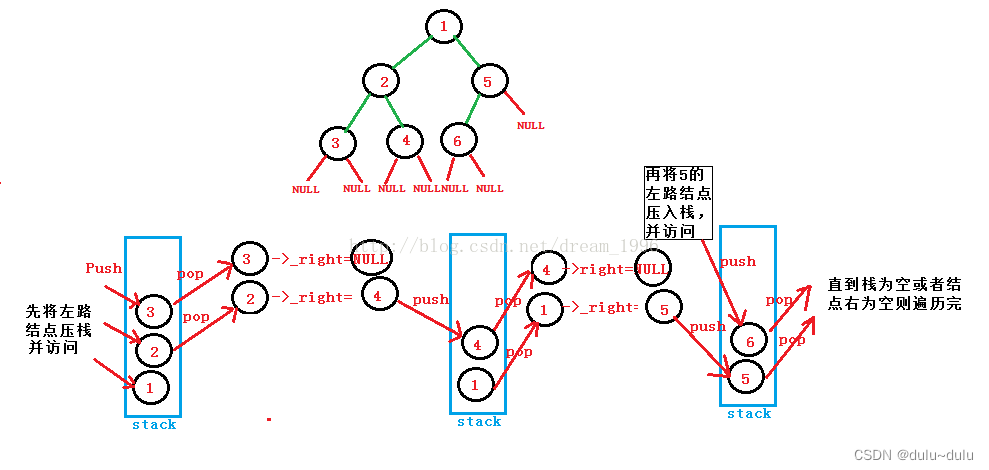
二叉树的递归遍历和非递归遍历
目录 一.二叉树的递归遍历 1.先序遍历二叉树 2.中序遍历二叉树 3.后序遍历二叉树 二.非递归遍历(栈) 1.先序遍历 2.中序遍历 3.后序遍历 一.二叉树的递归遍历 定义二叉树 #其中TElemType可以是int或者是char,根据要求自定 typedef struct BiNode{TElemType data;stru…...

JDK17:未来已来,你准备好了吗?
🌷🍁 博主猫头虎(🐅🐾)带您 Go to New World✨🍁 🦄 博客首页——🐅🐾猫头虎的博客🎐 🐳 《面试题大全专栏》 🦕 文章图文…...

K8s和Docker
Kubernetes(简称为K8s)和Docker是两个相关但又不同的技术。 一、Docker 1、Docker是一种容器化平台,用于将应用程序及其依赖项打包成可移植的容器。 2、Docker容器可以在任何支持Docker的操作系统上运行 好处:提供了一种轻量级…...

使用物理机服务器应该注意的事项
使用物理机服务器应该注意的事项 如今云计算的发展已经遍布各大领域,尽管现在的云服务器火遍全网,但是仍有一些大型企业依旧选择使用独立物理服务器,你知道这是为什么吗?壹基比小鑫来告诉你吧。 独立物理服务器托管业务适合大中…...

py脚本解决ArcGIS Server服务内存过大的问题
在一台服务器上,使用ArcGIS Server发布地图服务,但是地图服务较多,在发布之后,服务器的内存持续处在95%上下的高位状态,导致服务器运行状态不稳定,经常需要重新启动。重新启动后重新进入这种内存高位的陷阱…...

Go语言Web开发入门指南
Go语言Web开发入门指南 欢迎来到Go语言的Web开发入门指南。Go语言因其出色的性能和并发支持而成为Web开发的热门选择。在本篇文章中,我们将介绍如何使用Go语言构建简单的Web应用程序,包括路由、模板、数据库连接和静态文件服务。 准备工作 在开始之前…...

保姆级教程——VSCode如何在Mac上配置C++的运行环境
vscode官方下载: 点击官网链接,下载对应的pkg,安装打开; https://code.visualstudio.com/插件安装 点击箭头所指插件商店按钮,yyds; 下载C/C 插件; 
Java 操作FTP服务器进行下载文件
用Java去操作FTP服务器去做下载,本文章里面分为单个下载和批量下载,批量下载只不过多了一层循环,为了方便参考,我代码都贴出来了。 不管单个下载还是多个,一定要记得,远程服务器的直接写文件夹路径…...

物理机服务器应该注意的事
物理机服务器应该注意的事 1、选址 服务器是个非常重要的硬件产品,对机房的也是有一定的要求的,比如温度、安全性,噪音、电源稳定性等等问题都需要解决!但是不是每个人都会选择自己建立一个机房,毕竟各方面加起来的成本都太高。这…...

信息化发展24
信息技术的发展 1 )在计算机软硬件方面, 计算机硬件技术将向超高速、超小型、平行处理、智能化的方向发展, 计算机硬件设备的体积越来越小、速度越来越高、容量越来越大、功耗越来越低、可靠性越来越高。 2 )计算机软件越来越丰富…...

Qt开发_调用OpenCV(3.4.7)设计完成人脸检测系统
一、前言 近年来,人脸识别技术得到了广泛的应用,它可以在各种场景中实现自动化的人脸检测和识别,例如安防监控、人脸解锁、人脸支付等。 该项目的目标是设计一个简单易用但功能强大的人脸检测系统,可以实时从摄像头采集视频,并对视频中的人脸进行准确的检测和框选。通过…...

Java 中 List 删除元素
fori循环 删除某个元素后,list的大小发生了变化,会导致遍历准确。 这种方式可以用在删除特定的一个元素时使用,但不适合循环删除多个元素时使用 增强for循环 删除元素后继续循环会报错误信息ConcurrentModificationException,但是…...
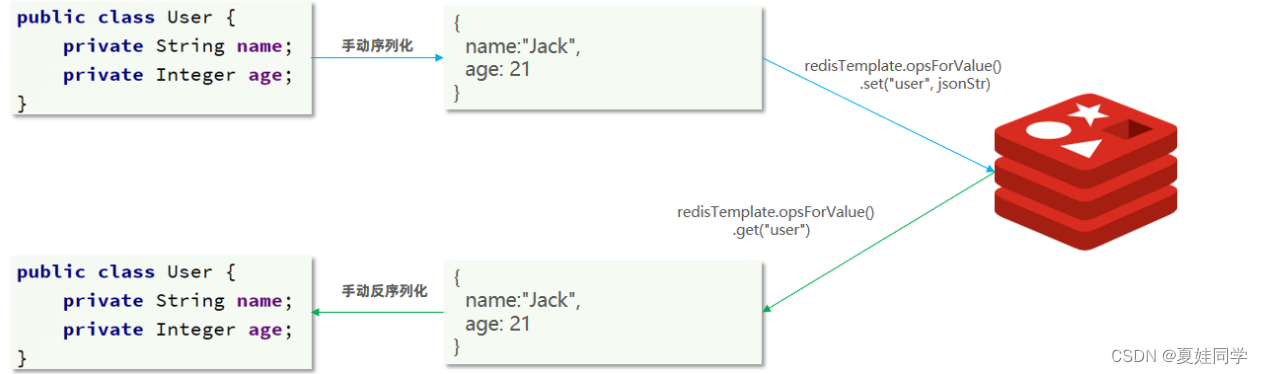
Redis:StringRedisTemplate简介
(笔记总结自b站黑马程序员课程) 为了在反序列化时知道对象的类型,JSON序列化器会将类的class类型写入json结果中,存入Redis,会带来额外的内存开销。 为了减少内存的消耗,我们可以采用手动序列化的方式&am…...

React19源码系列之 事件插件系统
事件类别 事件类型 定义 文档 Event Event 接口表示在 EventTarget 上出现的事件。 Event - Web API | MDN UIEvent UIEvent 接口表示简单的用户界面事件。 UIEvent - Web API | MDN KeyboardEvent KeyboardEvent 对象描述了用户与键盘的交互。 KeyboardEvent - Web…...

鱼香ros docker配置镜像报错:https://registry-1.docker.io/v2/
使用鱼香ros一件安装docker时的https://registry-1.docker.io/v2/问题 一键安装指令 wget http://fishros.com/install -O fishros && . fishros出现问题:docker pull 失败 网络不同,需要使用镜像源 按照如下步骤操作 sudo vi /etc/docker/dae…...

RNN避坑指南:从数学推导到LSTM/GRU工业级部署实战流程
本文较长,建议点赞收藏,以免遗失。更多AI大模型应用开发学习视频及资料,尽在聚客AI学院。 本文全面剖析RNN核心原理,深入讲解梯度消失/爆炸问题,并通过LSTM/GRU结构实现解决方案,提供时间序列预测和文本生成…...

使用 Streamlit 构建支持主流大模型与 Ollama 的轻量级统一平台
🎯 使用 Streamlit 构建支持主流大模型与 Ollama 的轻量级统一平台 📌 项目背景 随着大语言模型(LLM)的广泛应用,开发者常面临多个挑战: 各大模型(OpenAI、Claude、Gemini、Ollama)接口风格不统一;缺乏一个统一平台进行模型调用与测试;本地模型 Ollama 的集成与前…...

laravel8+vue3.0+element-plus搭建方法
创建 laravel8 项目 composer create-project --prefer-dist laravel/laravel laravel8 8.* 安装 laravel/ui composer require laravel/ui 修改 package.json 文件 "devDependencies": {"vue/compiler-sfc": "^3.0.7","axios": …...

回溯算法学习
一、电话号码的字母组合 import java.util.ArrayList; import java.util.List;import javax.management.loading.PrivateClassLoader;public class letterCombinations {private static final String[] KEYPAD {"", //0"", //1"abc", //2"…...

jmeter聚合报告中参数详解
sample、average、min、max、90%line、95%line,99%line、Error错误率、吞吐量Thoughput、KB/sec每秒传输的数据量 sample(样本数) 表示测试中发送的请求数量,即测试执行了多少次请求。 单位,以个或者次数表示。 示例:…...

使用SSE解决获取状态不一致问题
使用SSE解决获取状态不一致问题 1. 问题描述2. SSE介绍2.1 SSE 的工作原理2.2 SSE 的事件格式规范2.3 SSE与其他技术对比2.4 SSE 的优缺点 3. 实战代码 1. 问题描述 目前做的一个功能是上传多个文件,这个上传文件是整体功能的一部分,文件在上传的过程中…...

【安全篇】金刚不坏之身:整合 Spring Security + JWT 实现无状态认证与授权
摘要 本文是《Spring Boot 实战派》系列的第四篇。我们将直面所有 Web 应用都无法回避的核心问题:安全。文章将详细阐述认证(Authentication) 与授权(Authorization的核心概念,对比传统 Session-Cookie 与现代 JWT(JS…...

OCR MLLM Evaluation
为什么需要评测体系?——背景与矛盾 能干的事: 看清楚发票、身份证上的字(准确率>90%),速度飞快(眨眼间完成)。干不了的事: 碰到复杂表格(合并单元…...