【100天精通Python】Day55:Python 数据分析_Pandas数据选取和常用操作
目录
Pandas数据选择和操作
1 选择列和行
2 过滤数据
3 添加、删除和修改数据
4 数据排序
 Pandas数据选择和操作
Pandas数据选择和操作
Pandas是一个Python库,用于数据分析和操作,提供了丰富的功能来选择、过滤、添加、删除和修改数据。
1 选择列和行
Pandas 提供了多种方式来选择行和列,这取决于您希望获取的数据的类型和结构。
1.1 选择列
(1)使用列标签
使用列标签来选择一个或多个列。您可以将列标签传递给 DataFrame 的索引器,例如
[]。(2)使用
.loc[]方法
.loc[]方法可以根据标签名称选择行和列。对于列选择,可以使用:选择所有行。
1.2 选择行
(1)使用行索引
使用行索引来选择一个或多个行。您可以使用
.loc[]方法或.iloc[]方法。(2)使用
.iloc[]方法
.iloc[]方法使用整数位置来选择行和列。它与.loc[]方法的不同之处在于,它使用整数索引而不是标签。
示例代码:
import pandas as pddata = {'A': [1, 2, 3], 'B': [4, 5, 6], 'C': [7, 8, 9]}
df = pd.DataFrame(data)# 选择单个列
column_A = df['A']
print("单个列 'A':\n", column_A)
# 结果:
# 单个列 'A':
# 0 1
# 1 2
# 2 3
# Name: A, dtype: int64# 选择多个列
columns_AB = df[['A', 'B']]
print("多个列 'A' 和 'B':\n", columns_AB)
# 结果:
# 多个列 'A' 和 'B':
# A B
# 0 1 4
# 1 2 5
# 2 3 6# 使用 .loc[] 选择列
column_A_loc = df.loc[:, 'A']
print("使用 .loc[] 选择列 'A':\n", column_A_loc)
# 结果:
# 使用 .loc[] 选择列 'A':
# 0 1
# 1 2
# 2 3
# Name: A, dtype: int64# 选择多个列
columns_AB_loc = df.loc[:, ['A', 'B']]
print("使用 .loc[] 选择多个列 'A' 和 'B':\n", columns_AB_loc)
# 结果:
# 使用 .loc[] 选择多个列 'A' 和 'B':
# A B
# 0 1 4
# 1 2 5
# 2 3 6# 使用 .loc[] 选择单个行
row_0_loc = df.loc[0]
print("使用 .loc[] 选择单个行 (索引 0):\n", row_0_loc)
# 结果:
# 使用 .loc[] 选择单个行 (索引 0):
# A 1
# B 4
# C 7
# Name: 0, dtype: int64# 使用 .loc[] 选择多个行
rows_01_loc = df.loc[0:1]
print("使用 .loc[] 选择多个行 (索引 0 到 1):\n", rows_01_loc)
# 结果:
# 使用 .loc[] 选择多个行 (索引 0 到 1):
# A B C
# 0 1 4 7
# 1 2 5 8# 使用 .iloc[] 选择单个行
row_0_iloc = df.iloc[0]
print("使用 .iloc[] 选择单个行 (整数位置 0):\n", row_0_iloc)
# 结果:
# 使用 .iloc[] 选择单个行 (整数位置 0):
# A 1
# B 4
# C 7
# Name: 0, dtype: int64# 使用 .iloc[] 选择多个行
rows_01_iloc = df.iloc[0:2]
print("使用 .iloc[] 选择多个行 (整数位置 0 到 1):\n", rows_01_iloc)
# 结果:
# 使用 .iloc[] 选择多个行 (整数位置 0 到 1):
# A B C
# 0 1 4 7
# 1 2 5 8# 混合选择行和列
subset = df.loc[0:1, ['A', 'B']]
print("选择特定的行和列:\n", subset)
# 结果:
# 选择特定的行和列:
# A B
# 0 1 4
# 1 2 5
2 过滤数据
在Pandas中,您可以使用不同的方法来过滤数据,根据特定条件筛选出满足条件的数据。以下是一些过滤数据的示例和方法:
2.1 基于条件的过滤
通过创建一个条件表达式,您可以选择DataFrame中满足条件的行。
import pandas as pddata = {'A': [1, 2, 3, 4, 5],'B': [10, 20, 30, 40, 50]}
df = pd.DataFrame(data)# 选择满足条件的行,例如 'A' 列大于 3 的行
filtered_data = df[df['A'] > 3]
print(filtered_data)
输出结果:
A B
3 4 40
4 5 50
2.2 使用多个条件
您可以组合多个条件,使用 &(与)和 |(或)等逻辑运算符。
# 选择同时满足多个条件的行,例如 'A' 列大于 2 且 'B' 列小于 30 的行
filtered_data = df[(df['A'] > 2) & (df['B'] < 30)]
print(filtered_data)
输出结果:
A B
2 3 30
2.3 使用 isin() 进行筛选
您可以使用 isin() 方法来筛选出匹配指定值的行。
# 选择 'A' 列中匹配特定值的行
filtered_data = df[df['A'].isin([2, 4])]
print(filtered_data)
输出结果:
A B
1 2 20
3 4 40
2.4 使用字符串方法
如果您的数据包含字符串列,您可以使用字符串方法进行过滤。
data = {'Name': ['Alice', 'Bob', 'Charlie', 'David'],'Age': [25, 30, 35, 40]}
df = pd.DataFrame(data)# 选择包含特定字符串的行
filtered_data = df[df['Name'].str.contains('b', case=False)]
print(filtered_data)
输出结果:
Name Age
1 Bob 30
3 添加、删除和修改数据
3.1 添加数据
(1)添加行
要向 DataFrame 添加新行,通常可以创建一个新的数据项,然后将其附加到 DataFrame。这可以使用
append方法来完成。确保设置ignore_index=True来重置索引。(2)添加列
要添加新列,只需分配一个新的列名并提供相应的数据。这样可以在 DataFrame 中增加新的列,以便存储额外的信息。
3.2 删除数据
(1)删除行
使用
drop方法可以删除指定的行。您可以指定要删除的行的索引或标签,并使用axis=0参数来表示删除行。(2)删除列
要删除列,使用
drop方法并设置axis=1参数,然后指定要删除的列名。这将允许您从 DataFrame 中移除不需要的列。
3.3 修改数据
(1)修改特定单元格的值
要修改 DataFrame 中特定单元格的值,您可以使用
.loc[]方法,通过指定行和列的标签或索引,来更新该单元格的值。(2)更新多个值
要批量更新数据,通常可以使用条件来选择要更新的行,然后赋予新的值。这可以帮助您一次性更新多个数据点,而不必一个一个手动修改。
3.4 代码示例
import pandas as pd# 创建一个示例 DataFrame
data = {'Name': ['Alice', 'Bob', 'Charlie'],'Age': [25, 30, 35]}
df = pd.DataFrame(data)# 添加新行
new_row = pd.Series({'Name': 'David', 'Age': 40})
df = df.append(new_row, ignore_index=True)
# 结果:
# Name Age
# 0 Alice 25
# 1 Bob 30
# 2 Charlie 35
# 3 David 40# 添加新列
df['City'] = ['New York', 'Los Angeles', 'Chicago', 'Houston']
# 结果:
# Name Age City
# 0 Alice 25 New York
# 1 Bob 30 Los Angeles
# 2 Charlie 35 Chicago
# 3 David 40 Houston# 删除行
df = df.drop(2) # 删除索引为2的行
# 结果:
# Name Age City
# 0 Alice 25 New York
# 1 Bob 30 Los Angeles
# 3 David 40 Houston# 删除列
df = df.drop('City', axis=1) # 删除名为 'City' 的列
# 结果:
# Name Age
# 0 Alice 25
# 1 Bob 30
# 3 David 40# 修改特定单元格的值
df.loc[1, 'Age'] = 31
# 结果:
# Name Age
# 0 Alice 25
# 1 Bob 31
# 3 David 40# 更新多个值
df.loc[df['Age'] > 30, 'Age'] = 32 # 更新年龄大于30的行的年龄为32
# 结果:
# Name Age
# 0 Alice 25
# 1 Bob 32
# 3 David 32# 输出最终结果
print(df)
4 数据排序
在 Pandas 中,您可以使用 sort_values() 方法对 DataFrame 中的数据进行排序。以下是有关如何进行列排序、包括升序和降序排序,以及如何按多列进行排序。
4.1 按列排序:
要按列对数据进行排序,首先选择要排序的列名称,并使用 sort_values() 方法进行操作。默认情况下,数据将按升序排序。
升序排序:使用
sort_values(by='列名'),其中 '列名' 是您要排序的列的名称。例如,df.sort_values(by='Age')将按 'Age' 列的升序进行排序。降序排序:要按降序排序,可以使用
sort_values(by='列名', ascending=False),其中 '列名' 是您要排序的列的名称。例如,df.sort_values(by='Age', ascending=False)将按 'Age' 列的降序进行排序。
4.2 按多列排序:
如果需要按多列进行排序,您可以通过提供列名称的列表来实现。首先,按列表中的第一个列名进行排序,然后按照列表中的下一个列名进行排序。
例如,要按 'City' 列升序排序,然后按 'Age' 列升序排序,您可以使用
sort_values(by=['City', 'Age'])。
4.3 重置索引:
请注意,排序后的 DataFrame 可能会保留之前的索引顺序。如果希望重新设置索引以匹配新的排序顺序,可以使用
reset_index(drop=True)方法来删除旧的索引并创建一个新的整数索引。
4.4 代码示例
import pandas as pd# 创建一个示例 DataFrame
data = {'Name': ['Alice', 'Bob', 'Charlie', 'David'],'Age': [25, 30, 35, 40],'City': ['New York', 'Los Angeles', 'Chicago', 'Houston']}
df = pd.DataFrame(data)# 按列排序
# 默认按升序排序
df_sorted = df.sort_values(by='Age')
# 按照 'Age' 列的升序排序
print("按 'Age' 列的升序排序:\n", df_sorted)# 按照 'Age' 列的降序排序
df_sorted_desc = df.sort_values(by='Age', ascending=False)
print("\n按 'Age' 列的降序排序:\n", df_sorted_desc)# 按多列排序
# 先按 'City' 列升序排序,再按 'Age' 列升序排序
df_multi_sorted = df.sort_values(by=['City', 'Age'])
print("\n按 'City' 列和 'Age' 列的升序排序:\n", df_multi_sorted)# 恢复索引
df_multi_sorted = df_multi_sorted.reset_index(drop=True)
print("\n重置索引后的 DataFrame:\n", df_multi_sorted)
这个示例演示了如何在 Pandas 中按列对数据进行排序,包括升序和降序排序以及按多列排序。您还可以使用
reset_index()方法来重置排序后的 DataFrame 的索引。
相关文章:
【100天精通Python】Day55:Python 数据分析_Pandas数据选取和常用操作
目录 Pandas数据选择和操作 1 选择列和行 2 过滤数据 3 添加、删除和修改数据 4 数据排序 Pandas数据选择和操作 Pandas是一个Python库,用于数据分析和操作,提供了丰富的功能来选择、过滤、添加、删除和修改数据。 1 选择列和行 Pandas 提供了多种…...

f12工具
抓包工具 elements查看器: 可用于自动化脚本的元素定位,前端页面-html页面 Selenium提供了八种定位元素方式 1、id 2、name 3、class_name 4、tag_name 5、link_text 6、partial_link_text 7、XPath(倾向于用相对路径://input【name“phone”】…...

Spring MVC实现RESTful
在 Spring MVC 中,我们可以通过 RequestMapping PathVariable 注解的方式,来实现 RESTful 风格的请求。 1. 通过RequestMapping 注解的路径设置 当请求中携带的参数是通过请求路径传递到服务器中时,我们就可以在 RequestMapping 注解的 val…...

ClickHouse配置Hdfs存储数据
文章目录 背景配置单机配置HA高可用Hdfs集群性能测试统计trait最多的10个trait term统计性状xxx minValue > 500 0000的数量结论 参考文档 背景 由于公司初始使用Hadoop这一套,所以希望ClickHouse也能使用Hdfs作为存储 看了下ClickHouse的文档,拿Hdf…...
zabbix监控网络设备和zabbix proxy
监控linux主机 [rootrocky8 conf]# yum -y install net-snmp vim /etc/snmp/snmpd.conf com2sec notConfigUser default 123456##修改此行,设置团体密码,默认为public,此处 改为123456 view systemview included .1. ##添加此行,自定义授权,否则 zabbix 无法获取数据 [rootr…...

halcon双目标定双相机标定
halcon双目标定 *取消更新 dev_update_off () *获取窗体句柄 dev_get_window (WindowHandle) *设置窗体字体样式 set_display_font (WindowHandle, 16, mono, true, false) *设置线条粗细 dev_set_line_width (3) *创建空对象 gen_empty_obj (ImageL) *读取指定文件内子集 li…...
Vue框架学习记录之环境安装与第一个Vue项目
Node.js的安装与配置 首先是Node.js的安装,安装十分简单,只需要去官网下载安装包后,一路next即可。 Node.js是一个开源的、跨平台的 JavaScript 运行时环境 下载地址,有两个版本,一个是推荐的,一个是最新…...
【DockerCE】Docker-CE 24.0.6正式版发布
官网下载地址(For RHEL/CentOS 7.9): https://download.docker.com/linux/centos/7/x86_64/stable/Packages/ 相对于24.0.5版本,本次24.0.6版本更新的rpm包有 5 个,使用目录对比软件对比的结果如下: 在Lin…...

【管理运筹学】第 7 章 | 图与网络分析(1,图论背景以及基本概念、术语、矩阵表示)
文章目录 引言一、图与网络的基本知识1.1 图与网络的基本概念1.1.1 图的定义1.1.2 图中相关术语1.1.3 一些特殊图类1.1.4 图的运算 1.2 图的矩阵表示1.2.1 邻接矩阵1.2.2 可达矩阵1.2.3 关联矩阵1.2.4 权矩阵 写在最后 引言 按照正常进度应该学习动态规划了,但我想…...

支持CAN FD的Kvaser PCIEcan 4xCAN v2编码: 73-30130-01414-5如何应用?
这里是引用 Kvaser PCIEcan 4xCAN v2(编码: 73-30130-01414-5)是一款小巧而先进的多通道实时CAN接口,可发送和接收CAN总线上的标准和扩展CAN消息,时间戳精度高。其与所有使用Kvaser CANlib的应用程序兼容。 主要特性 PCI Express…...

经济2023---风口
改革开放以来,中国共有12次比较好的阶级跃迁的机会: 包括80年代选部委院校、办乡镇企业、倒卖商品;90年代下海、选外语外贸、炒股;00年代从事资源品行业、选金融、炒房;10年代选计算机、搞互联网、买比特币。 从这里…...

JWFD开源工作流-矩阵引擎设计-高维向量空间分析法
JWFD开源工作流-矩阵引擎设计-高维向量空间分析法 在把已知的流程节点查找到之后,输出下标,但是我们发现,还有一些节点并未被 探测到,遍历并没有完全的完成,仍然有泄露的节点在其中,这个问题…...

WIN10访问Ubuntu的Samba
WIN10访问Ubuntu的Samba 在Ubuntu中安装好Samba后,如果无法在Win10里访问共享目录或者无法进行写操作,可以进行如下检查: 检查用户是否添加到共享和共享组 $ sudo adduser yourname sambashare 可以编辑:,查看文件/etc…...

AbstractExecutorService 抽象类
java.util.concurrent.AbstractExecutorService 是 Java 并发编程中的一个抽象类,它定义了 ExecutorService 接口的基本行为。ExecutorService 是一个接口,它提供了一种以异步方式执行任务的方法。 AbstractExecutorService 类包含以下一些重要的方法: void execute(Runnab…...

Android12 ethernet和wifi共存
1.修改网络优先走wifi packages/modules/Connectivity/service/src/com/android/server/connectivity/NetworkRanker.java -44,7 44,7 import java.util.Arrays;import java.util.Collection;import java.util.List;import java.util.function.Predicate; - import andro…...
记录使用layui弹窗实现签名、签字
一、前言 本来项目使用的是OCX方式做签字的,因为项目需要转到国产化,不在支持OCX方式,需要使用前端进行签字操作 注:有啥问题看看文档,或者换着思路来,本文仅供参考! 二、使用组件 获取jSign…...
【AIGC系列】Stable Diffusion 小白快速入门课程大纲
一、前言 本文是《Stable Diffusion 从入门到企业级应用实战》系列课程的前置学习引导部分,《Stable Diffusion新手完整学习地图课程》的课程大纲。该课程主要的培训对象是: 没有人工智能背景,想快速上手Stable Diffusion的初学者;想掌握St…...
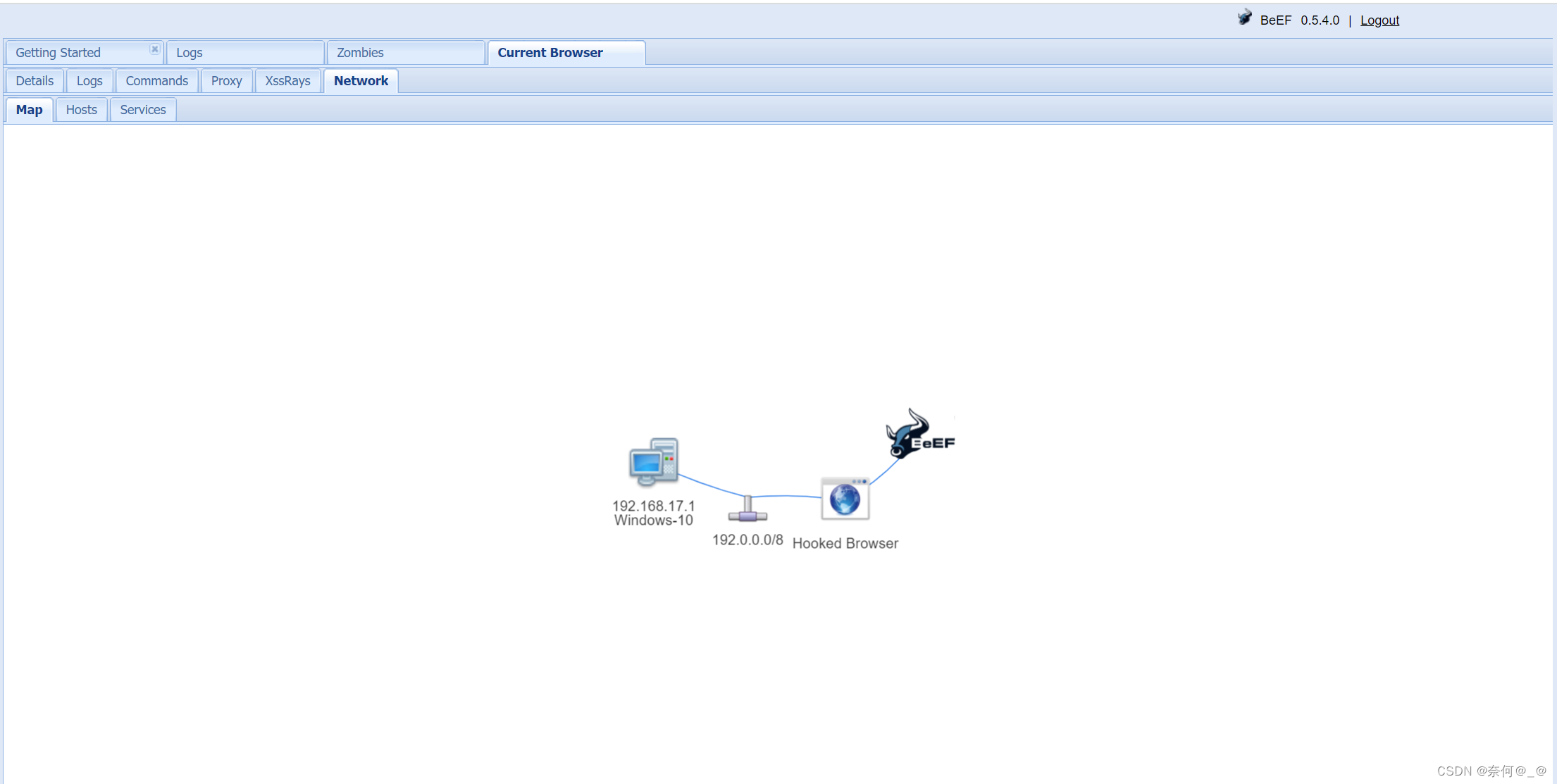
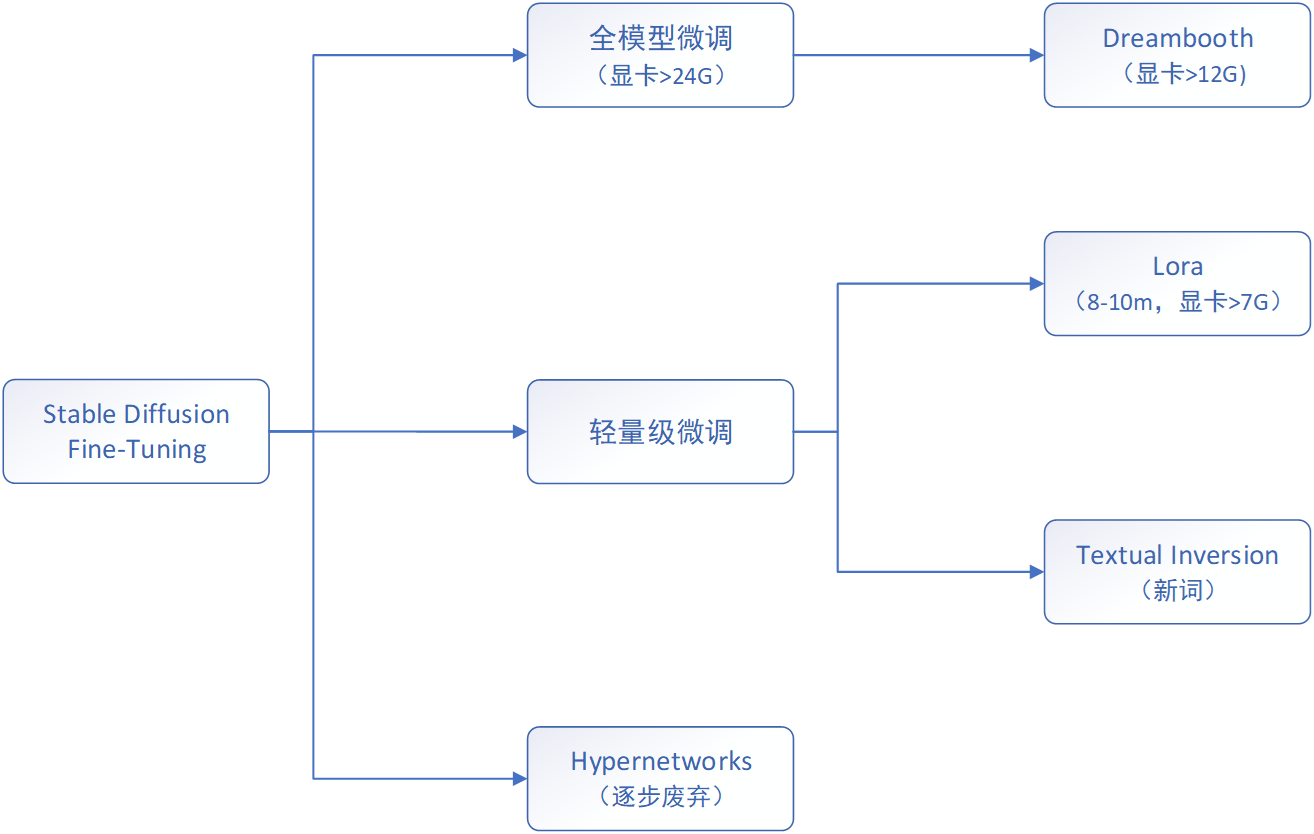
在kali环境下安装Beef-Xss靶场搭建
目录 一、更新安装包 二、安装beef-xss 三、启动Beef-Xss工具 1、查看hook.js 2、查看后台登录地址 3、查看用户名和登录密码 4、登录页面 5、点击 Hook me:将配置的页面导入BEEF中 一、更新安装包 ┌──(root㉿kali)-[/home/kali] └─# apt-get update 二、安装be…...

【Apollo】自动驾驶技术的介绍
阿波罗是百度发布的名为“Apollo(阿波罗)”的向汽车行业及自动驾驶领域的合作伙伴提供的软件平台。 帮助汽车行业及自动驾驶领域的合作伙伴结合车辆和硬件系统,快速搭建一套属于自己的自动驾驶系统。 百度开放此项计划旨在建立一个以合作为中…...
HTML emoji整理 表情符号
<!DOCTYPE html> <html lang"en"><head><meta charset"UTF-8" /><title>测试</title></head><body><div style"font-size: 50px;">🔔</div><script>let count 0d…...

使用VSCode开发Django指南
使用VSCode开发Django指南 一、概述 Django 是一个高级 Python 框架,专为快速、安全和可扩展的 Web 开发而设计。Django 包含对 URL 路由、页面模板和数据处理的丰富支持。 本文将创建一个简单的 Django 应用,其中包含三个使用通用基本模板的页面。在此…...

Linux 文件类型,目录与路径,文件与目录管理
文件类型 后面的字符表示文件类型标志 普通文件:-(纯文本文件,二进制文件,数据格式文件) 如文本文件、图片、程序文件等。 目录文件:d(directory) 用来存放其他文件或子目录。 设备…...

DeepSeek 赋能智慧能源:微电网优化调度的智能革新路径
目录 一、智慧能源微电网优化调度概述1.1 智慧能源微电网概念1.2 优化调度的重要性1.3 目前面临的挑战 二、DeepSeek 技术探秘2.1 DeepSeek 技术原理2.2 DeepSeek 独特优势2.3 DeepSeek 在 AI 领域地位 三、DeepSeek 在微电网优化调度中的应用剖析3.1 数据处理与分析3.2 预测与…...

【算法训练营Day07】字符串part1
文章目录 反转字符串反转字符串II替换数字 反转字符串 题目链接:344. 反转字符串 双指针法,两个指针的元素直接调转即可 class Solution {public void reverseString(char[] s) {int head 0;int end s.length - 1;while(head < end) {char temp …...

Java-41 深入浅出 Spring - 声明式事务的支持 事务配置 XML模式 XML+注解模式
点一下关注吧!!!非常感谢!!持续更新!!! 🚀 AI篇持续更新中!(长期更新) 目前2025年06月05日更新到: AI炼丹日志-28 - Aud…...

Spring Boot+Neo4j知识图谱实战:3步搭建智能关系网络!
一、引言 在数据驱动的背景下,知识图谱凭借其高效的信息组织能力,正逐步成为各行业应用的关键技术。本文聚焦 Spring Boot与Neo4j图数据库的技术结合,探讨知识图谱开发的实现细节,帮助读者掌握该技术栈在实际项目中的落地方法。 …...

NFT模式:数字资产确权与链游经济系统构建
NFT模式:数字资产确权与链游经济系统构建 ——从技术架构到可持续生态的范式革命 一、确权技术革新:构建可信数字资产基石 1. 区块链底层架构的进化 跨链互操作协议:基于LayerZero协议实现以太坊、Solana等公链资产互通,通过零知…...

如何在最短时间内提升打ctf(web)的水平?
刚刚刷完2遍 bugku 的 web 题,前来答题。 每个人对刷题理解是不同,有的人是看了writeup就等于刷了,有的人是收藏了writeup就等于刷了,有的人是跟着writeup做了一遍就等于刷了,还有的人是独立思考做了一遍就等于刷了。…...

基于Java Swing的电子通讯录设计与实现:附系统托盘功能代码详解
JAVASQL电子通讯录带系统托盘 一、系统概述 本电子通讯录系统采用Java Swing开发桌面应用,结合SQLite数据库实现联系人管理功能,并集成系统托盘功能提升用户体验。系统支持联系人的增删改查、分组管理、搜索过滤等功能,同时可以最小化到系统…...

LangChain知识库管理后端接口:数据库操作详解—— 构建本地知识库系统的基础《二》
这段 Python 代码是一个完整的 知识库数据库操作模块,用于对本地知识库系统中的知识库进行增删改查(CRUD)操作。它基于 SQLAlchemy ORM 框架 和一个自定义的装饰器 with_session 实现数据库会话管理。 📘 一、整体功能概述 该模块…...