依赖项的处理与层的创建与注册

依赖项的处理与层的创建与注册
- 依赖项的处理与层的创建与注册
- 新问题
- 什么是
layer? layer的创建与注册- 与函数同时创建和绑定
- 单独上传
layer再绑定函数(推荐)
- 真正的运行时依赖
- 注册包的约定
- 与平台强关联的运行时
- 1. 云端安装依赖
- 2. 本地构建
Amazon Linux 2容器环境 - 3. 利用 CI 构建并进行上传和部署
- 镜像部署
- Next Chapter
- 完整示例及文章仓库地址
新问题
在一个 nodejs 函数里,我们往往会去安装和使用各种各样的依赖包,来辅助我们项目的开发。
这些依赖以及对应的版本都被注册在了 package.json里 (由 npm init创建)。在安装依赖之后,它们会被存放在当前项目的 node_modules 目录里。而 sls deploy 默认也会把 node_modules 里所有文件,打包压缩后,和代码一起上传到云上。这点很好理解,没有依赖项,函数压根跑不起来。
但是当我们 node_modules 依赖足够大,足够深之后,整个 node_modules 就会变成一个黑洞。随随便便就有 1GB/2GB 甚至更多,这时候去进行 sls deploy 就会变成一种折磨,因为要压缩 node_modules,这个行为耗时太长了,即使压缩好了,上传到 S3 对象存储也要花费很久的时间。
如何解决? 这时候就需要让我们的 layer(层)出场了。
什么是 layer?
layer 你可以理解成,预先放置在我们 Lambda 函数容器中的文件包,你可以在里面放一些代码,库,数据文件,配置文件甚至是一些自定义语言运行时。比如我在使用的时候,往往会把 运行时 依赖的包,打成 zip 上传上去,又或者有些爬虫函数,需要使用 chromium 来模仿用户的行为,那么这种case则需要在 layer 里面直接内置一个 headless chromium。
这些文件最终都会被挂载到函数容器中的 /opt 目录。
layer 的创建与注册
这里我给出一个示例,假设运行时的依赖只有 uuid (假设我们只依赖这一个包)
我们现在项目中安装 npm i uuid 并使用它:
// index.ts
import { v4 } from 'uuid'
v4()
// ...code...
这时候 uuid 在函数package.json这一层的 node_modules 文件夹里,测试运行后,运转良好。
让我们在当前目录下,创建一个 layers 文件夹,然后再在里面创建一个 uuid(名称可自定义)文件夹,创建 package.json 并写入:
{"dependencies": {"uuid": "^9.0.0"}
}
layers/uuid/package.json#dependencies字段中的uuid即为你主目录下安装的版本。
然后执行 npm i/yarn 安装依赖 (不要使用pnpm),安装完成后会出现 layers/uuid/node_modules 文件夹,接下来就可以 layer 的上传和绑定了。
与函数同时创建和绑定
我们可以复用原先部署函数的那个 serverless.yml 文件,让它不但部署函数,也同时创建 layer 并进行绑定。具体配置如下:
layers:# layer 配置uuid:# 路径path: layers/uuid# aws lambda layer 里的名称name: ${sls:stage}-uuidfunctions:api:# ...package:individually: true# 既然我们把所有运行时都打成 layer 了自然不用上传 node_modules 了patterns:- "!node_modules/**"# layer 绑定配置layers:# 绑定 UuidLambdaLayer- !Ref UuidLambdaLayerenvironment:# 环境变量,告诉函数应该从哪里找依赖NODE_PATH: "./:/opt/node_modules"
其中最重要的就是2个layers的配置了,其中 !Ref UuidLambdaLayer 这个其实就是引用了layers.uuid,只不过它的命名是一种约定,即 uuid 的 u 大写加上 LambdaLayer,于是就变成了 UuidLambdaLayer 了,命名规则为 layer 名称的 Title_Case 加 LambdaLayer。
注意!
NODE_PATH: "./:/opt/node_modules"这个环境变量是必不可少的,不然会导致无法从layer中加载node_modules相关配置的参考链接
此时使用 sls package 会在 .serverless 目录下生成 2 个 zip:
api.zip函数代码包uuid.ziplayer包
这2个压缩包的名字,就是我们在 serverless.yml注册的名字。
sls deploy 会把它们依次上传,先layer后function,并把layer上传部署后的结果,注册进我们的function,从而达成绑定的效果。
单独上传 layer 再绑定函数(推荐)
除了与函数同时创建和绑定的形式,我们还可以分步骤单独上传 layer 再绑定函数,这也是我推荐的方式。
这个就顾名思义,我们可以先上传layer拿到结果,在把结果写到函数的 serverless.yml 中去。这样步骤方面分为了 2 步,但是好处却是显而易见的。
它适用于这样的场景,我们的 layer 包很大,且不经常更新,这种情况是没有必要每次都去打包上传 layer 的。
我们部署只需要部署我们自己的函数代码,然后告诉 AWS 应该去绑定哪个 layer 的哪个版本就行。
按照这样的思路,我们就可以把刚刚那个 serverless.yml 拆成 2 个 yml 文件:
- 单独上传
layer配置文件 - 函数的
deploy配置文件,加一行绑定layer的配置即可
单独部署 layer 的配置,内容如下:
# layers/serverless.yml
layers:uuid:path: uuidname: ${sls:stage}-uuid
执行 sls deploy 后上传部署成功会显示:
layers:uuid: arn:aws-cn:lambda:cn-northwest-1:000000000000:layer:dev-uuid:2
这一个字符串就是接下来我们需要写入函数 yml 配置进行绑定的关键,当然当时没保存刷了terminal也没关系,这个信息通过在当前目录执行 sls info 还会显示出来。
接下来我们去函数的 yml 配置去绑定 layers:
# serverless.yml
functions:api:# ....layers:# - !Ref UuidLambdaLayer 改为- arn:aws-cn:lambda:cn-northwest-1:000000000000:layer:dev-uuid:2
这样再在函数这一层执行 sls deploy 这层绑定关系就完成了,同时上传速度也要比 与函数同时创建和绑定 快不少,因为这种方法只要上传函数的代码包,再通过调用 AWS API 告诉它们这层绑定关系即可。
真正的运行时依赖
之前有一个细节没有讲,为什么我们上传 layer 是单独建一个 layers 的目录,在里面单个单个上传,而不是把外面函数的 node_modules 整个打包上传上去呢?
其实那样也可以,但是不够完美,因为这样做会导致layer代码包中的文件,过于冗余。
举个简单的例子,默认情况下 npm 安装包时,会把 devDependencies 和 dependencies 都安装在 node_modules。
比如 dependencies 里就是一些 express/lodash 啥的,devDependencies 里面就是 eslint/sass/webpack 这些开发时用的包,运行代码的时候用不着。
这时候,你直接打包上传 node_modules 显然是可以的,因为你所有的运行时依赖已经在里面了,不幸的是 eslint 等等许多无关紧要的包也进去了,这些加起来有可能会占用你 layer 包整体体积的一般以上甚至更多,显然这是没有必要的。
所以,你必须找到真正的运行时依赖!
注册包的约定
首先你必须在安装包时正确的注册 devDependencies 和 dependencies。
我们把运行时用的到的放在 dependencies 里,到时候也从这里面抽出包名和版本,做成 layer。至于devDependencies 里我们只会把那些开发时用得到的包放在里面,它们就没有必要上传了,本地运行即可。
与平台强关联的运行时
其次你必须很清楚你的运行时是 nodejs 而不是什么浏览器。
虽然说 nodejs 是跨平台的,但是我们使用的第三方库里,有时候会存在着很多和平台强关联的二进制文件。
比如有些包会在下载下来之后,调用 postinstall 脚本获取我们的系统信息(平台,cpu架构),然后根据这些信息去使用不同的二进制文件。
又或者有些包基于 C++ addons 的,安装好之后,才在我们机器上实时去编译,生成适配我们系统平台的二进制文件。
这就导致一个问题,假如你直接用 win/macos 开发,你安装的二进制包,大概率无法在 aws lambda 环境下运行,因为它的环境是 Amazon Linux 2
所以,我们应该在挑选与线上 Lambda 运行时,相似的容器中,进行开发,上传代码和层 (layer)
具体怎么做呢?这里给出三种解决方案:
1. 云端安装依赖
顾名思义,直接在云上的目标容器环境中进行安装依赖这个行为,这也是最简单的解决方案。
2. 本地构建 Amazon Linux 2 容器环境
这要求我们在 docker 容器中开发,拉下 Amazon Linux 2 的镜像,在里面开发并上传层函数和代码包。
3. 利用 CI 构建并进行上传和部署
这个思路便是,由环境相同或者相似的 CI 容器,进行上传和部署。
比如我们可以利用 Github Action 去构建和上传,大致的配置如下:
name: Layeron:workflow_dispatch:jobs:upload:name: uploadtimeout-minutes: 15strategy:fail-fast: falsematrix:# 找一个相似的镜像 osos: [ubuntu-latest]node-version: [18]runs-on: ${{ matrix.os }}steps:- name: Check out codeuses: actions/checkout@v3with:fetch-depth: 2- name: Configure AWS credentials from Test accountuses: aws-actions/configure-aws-credentials@v3with:aws-region: cn-northwest-1aws-access-key-id: ${{ secrets.AWS_ACCESS_KEY_ID }}aws-secret-access-key: ${{ secrets.AWS_SECRET_ACCESS_KEY }}- name: Setup Node.js environmentuses: actions/setup-node@v3with:node-version: ${{ matrix.node-version }}- name: Install Serverlessrun: yarn global add serverless- name: Install puppeteer Layerrun: yarnworking-directory: apps/aws-express-api-ts/layers/puppeteer- name: sls deployrun: yarn deployworking-directory: apps/aws-express-api-ts/layers
镜像部署
当然,假如你使用镜像去部署 lambda,那以上这些问题都可以避免,但是代价便是冷启动时间比较长。
不过很多技术上的问题,都是可以通过付出更多金钱的方式去解决的,这点就综合考虑利弊吧。
Next Chapter
现在你已经学会了 layer 的用法和一些稀奇古怪的场景。
下一篇,《lambda nodejs 函数降低冷启动时间的最佳实践》中,将会详细介绍如何优化我们自身的代码,欢迎阅读。
完整示例及文章仓库地址
https://github.com/sonofmagic/serverless-aws-cn-guide
如果你遇到什么问题,或者发现什么勘误,欢迎提 issue 给我
相关文章:
依赖项的处理与层的创建与注册
依赖项的处理与层的创建与注册 依赖项的处理与层的创建与注册 新问题什么是 layer?layer 的创建与注册 与函数同时创建和绑定单独上传 layer 再绑定函数(推荐) 真正的运行时依赖 注册包的约定与平台强关联的运行时 1. 云端安装依赖2. 本地构建 Amazon Linux 2 容器环境3. 利用…...
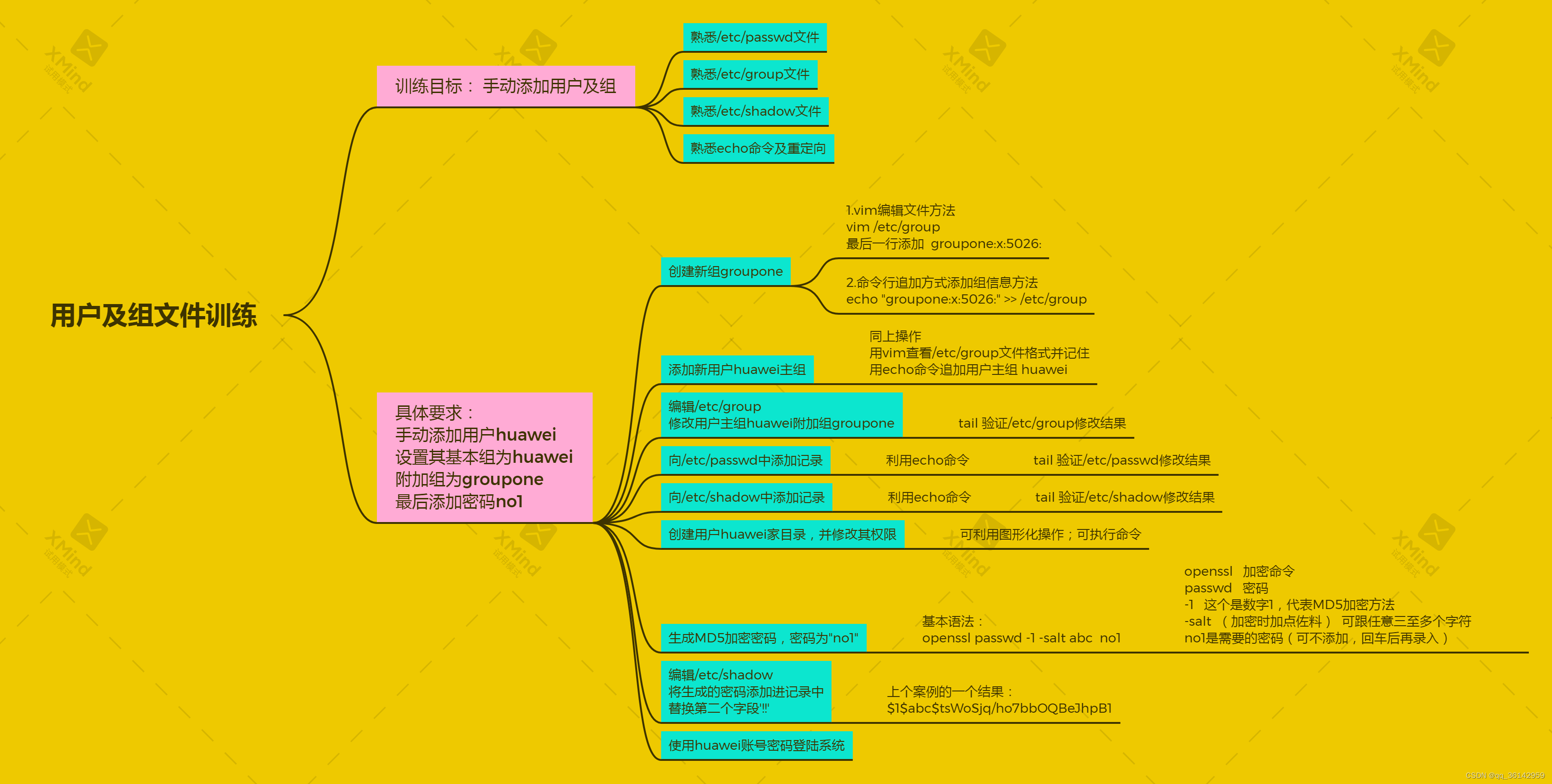
Linux CentOS7 系统中添加用户
在linux centOS7系统中,添加用户是管理员的基本操作。作为学习linux系统的基本操作,对添加用户应该多方面了解。 添加用户的命令useradd,跟上用户名,就可以快速创建一个用户。添加一些选项,可以设置更人性化的用户信息…...
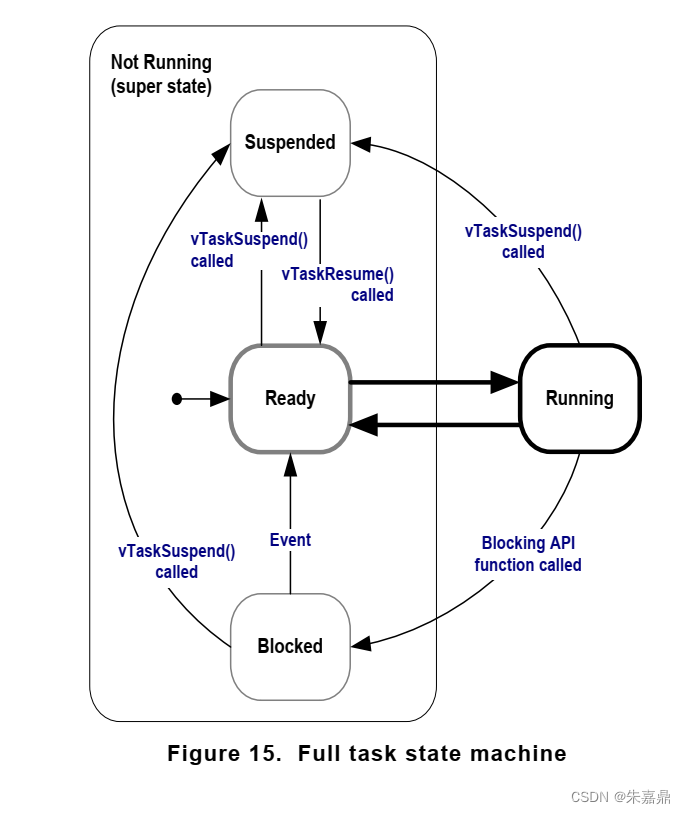
八、任务状态
1、任务状态简介 (1)任务状态可以简单的分为运行和非运行。 (2)非运行状态可以细分为:阻塞状态、暂停状态、就绪状态。 2、阻塞状态(Blocked) (1)举例说明:在日常生活的例子中,母亲在电脑前跟同事沟通时,如果同事一直没回复&a…...

基于python的反爬虫技术的研究设计与实现
摘 要 当下的网络是复杂的,网络上的信息非常的丰富,但也造成了大量的信息堆积,特别是大量的重复信息被反复的推送给用户。这是一个流量的时代,很多社会群体都会聚焦具备流量潜力的信息,从而发生蹭热度等行为来提升自己…...
msvcr120.dll放在哪里?怎么修复msvcr120.dll文件
当您在运行某些应用程序或游戏时遇到“msvcr120.dll缺失”错误时,这可能会影响您的使用体验。msvcr120.dll是Microsoft Visual C Redistributable的一部分,并且它提供了程序运行所需的运行时支持,今天我们来讨论一下msvcr120.dl文件缺失了要怎…...

Ubuntu搭建NFS服务
# 服务器初始化步骤 ## 查看磁盘 fdisk -l ## 格式化磁盘,后面的盘符注意对应关系 mkfs.ext4 /dev/sdc ## 新建文件夹 mkdir /mnt/nfs ## 挂载磁盘到创建的文件夹 echo "/dev/sdc /mnt/nfs ext4 defaults 0 0" >> /etc/fstab ## 重新挂载所有分区…...
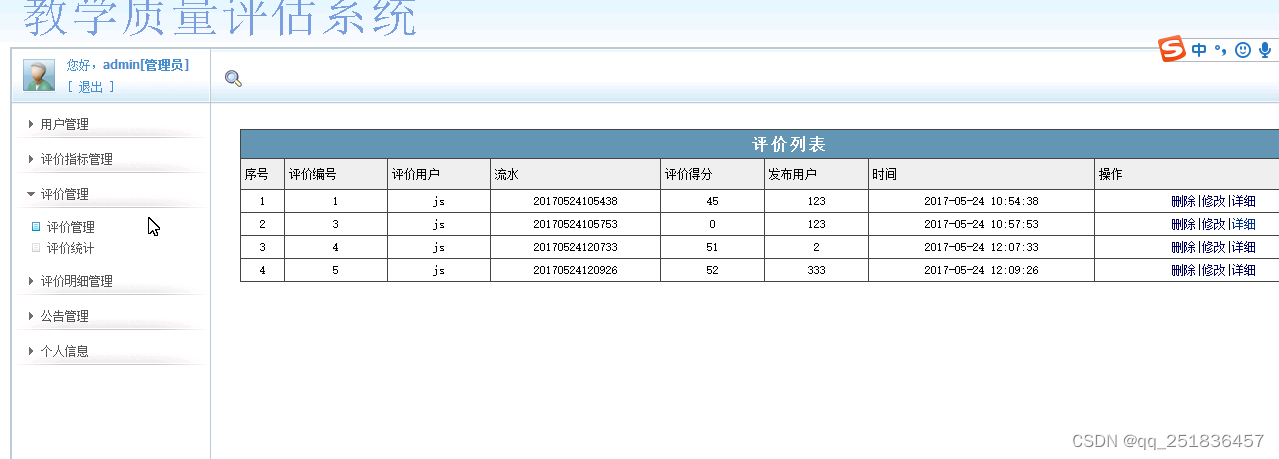
PHP教学质量评估系统Dreamweaver开发mysql数据库web结构php编程计算机网页代码
一、源码特点 PHP教学质量评估系统是一套完善的web设计系统,对理解php编程开发语言有帮助,系统具有完整的源代码和数据库,系统主要采用B/S模式开发。 代码 https://download.csdn.net/download/qq_41221322/88301983 论文 https://down…...

ElementUI浅尝辄止15:Table 表格
用于展示多条结构类似的数据,可对数据进行排序、筛选、对比或其他自定义操作。 Table组件比较常用,常见于数据查询,报表页面,用来展示表格数据。 1.如何使用? //当el-table元素中注入data对象数组后,在el-t…...

配置LVS_DR模式以及nginx负载均衡
一、配置LVS--DR模式: yum install ipvsadm 配置 LVS 负载均衡服务 ( 1 )手动添加 LVS 转发 1 )用户访问: www.uolookking.com-->vip 192 .168.79.110 ##> 这个是在 DNS 配置 hzitedu 域的 DNS 记录设置 w…...

虚拟数字人直播软件实现带货功能,成为新一代直播风口!
随着短视频带货市场的不断发展,虚拟数字人直播技术逐渐成为热门话题。而在现如今的市场趋势下直播带货则成为了一种火热的营销方式。那么,虚拟数字人直播软件是否可以结合起来,实现无人直播带货的效果呢?让我们来了解一下。 灰豚数…...
和经典解法)
01背包问题暴力解法(回溯法)和经典解法
暴力解法(回溯法) import java.util.Arrays; import java.util.Scanner;public class Main {private final static int N 999;public static int SumValue 0;public static int SumWeight 0;public static int OptimalValue 0;public static int O…...

K8S的CKA考试环境和题目
CKA考试这几年来虽然版本在升级,但题目一直没有大的变化,通过K8S考试的方法就是在模拟环境上反复练习,通过练习熟悉考试环境和考试过程中可能遇到的坑。这里姚远老师详细向大家介绍一下考试的环境和题目,需要详细资料的同学请在文…...

docker清理
1. 查看docker 磁盘占用 docker system df 2. 参考: Docker磁盘占用与清理问题_docker system prune_蓝鲸123的博客-CSDN博客...

队列和栈两种数据结构的区别和Python实现
队列和栈是两种数据结构,其内部都是按照固定顺序来存放变量的,二者的区别在于对数据的存取顺序 栈是最后存入的数据最先取出,即后进先出 队列是先存入的数据最先取出,即先进先出 Python实现栈 使用append()方法存入数据,使用pop()方法读取数据 # 定义一个空列表(当做栈使…...
java 企业工程管理系统软件源码+Spring Cloud + Spring Boot +二次开发+ MybatisPlus + Redis
鸿鹄工程项目管理系统 Spring CloudSpring BootMybatisVueElementUI前后端分离构建工程项目管理系统 1. 项目背景 一、随着公司的快速发展,企业人员和经营规模不断壮大。为了提高工程管理效率、减轻劳动强度、提高信息处理速度和准确性,公司对内部工程管…...
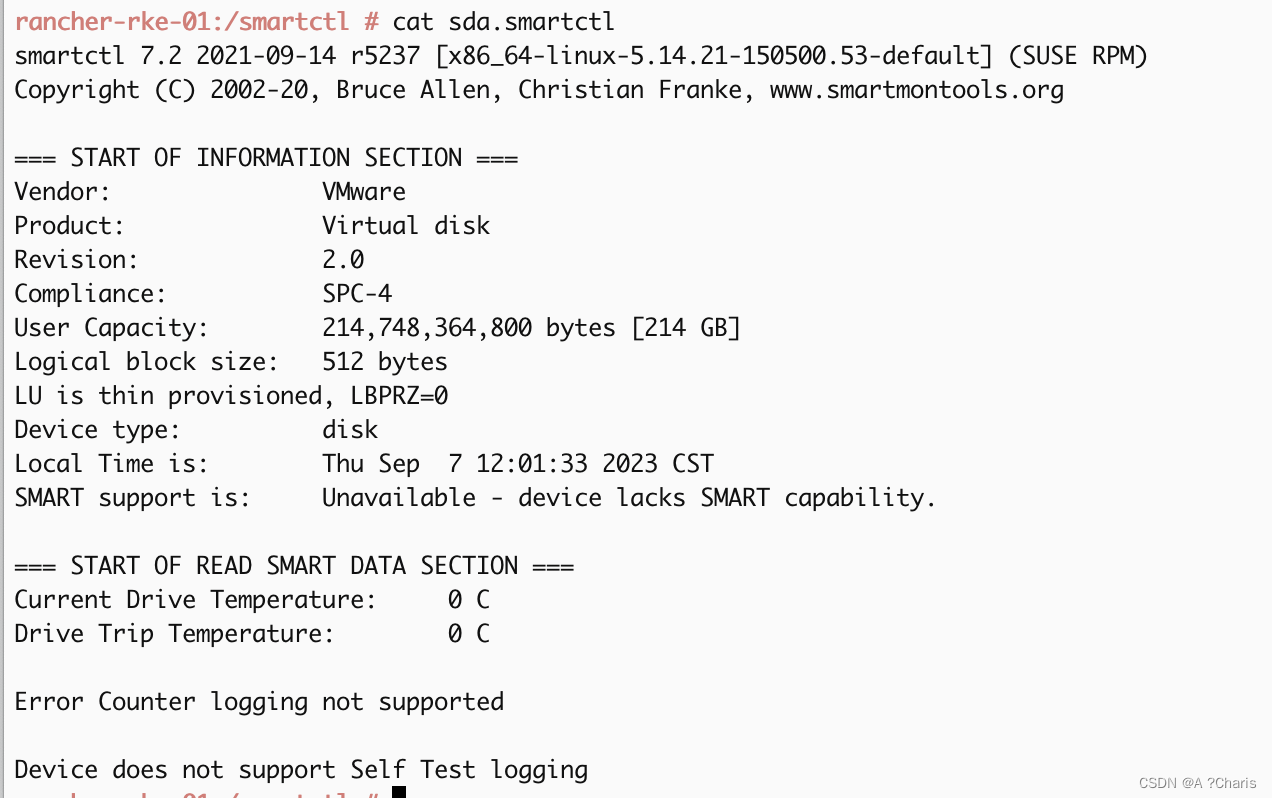
使用Smartctl脚本输入当前所有磁盘的状态
一、安装Smartctl yum install smartmontools 二、写一个脚本输出当前所有磁盘的状态并且按名称分别写入到文件中 #!/bin/bashfor dev in $(lsblk -l | grep disk | awk {print $1}) doecho "检测磁盘 $dev"smartctl -a /dev/$dev > $dev.smartctl done 以下是这…...
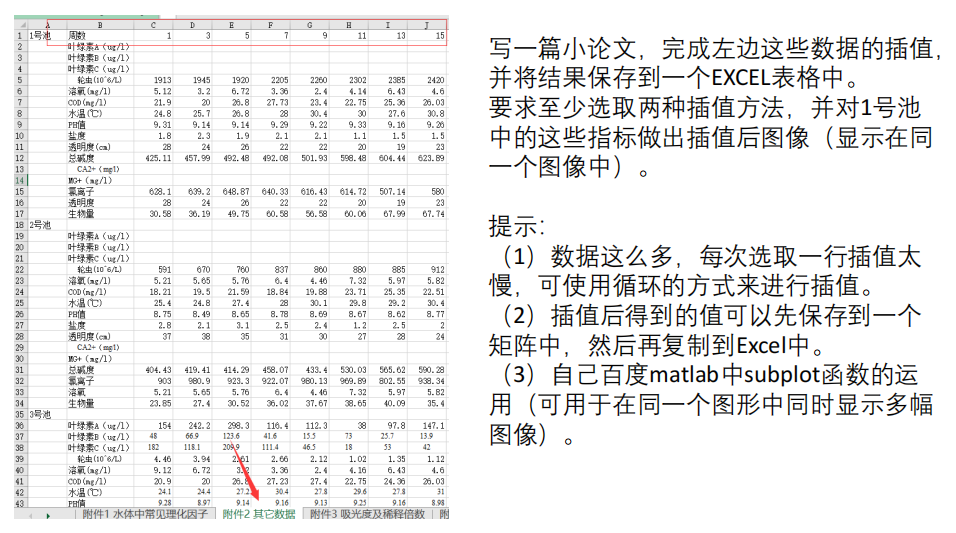
数学建模之插值法
目录 1 插值法概述2 插值法原理3 拉格朗日插值4 牛顿插值5 三次Hermite插值(重点)6 三次样条插值(重点)7 各种插值法总结8 n 维数据的插值9 插值法拓展10 课后作业 1 插值法概述 数模比赛中,常常需要根据已知的函数点进…...

rhcsa学习2(vim、创建管理用户、组等)
创建、查看和编辑文本文件 重定向符号 > 进程使用称为文件描述符的编号通道来获取输入并发送输出。所有进程在开始时至少要有三个文件描述符。如果程序打开连接至其他文件的单独连接,则可能要使用更大编号的文件描述符 上述通过通道1去写入,且写入的文…...
)
【使用教程】Github(自用)
1.下载Git⼯具 使在windows 命令⾏下边可以输⼊这两个命令: gitssh-keygen 2.配置git信息: 在命令⾏⾥输⼊: $ git config --global user.name “你在Github上注册的账号” $ git config --global user.email 你在Github上注册的邮箱 3. c…...
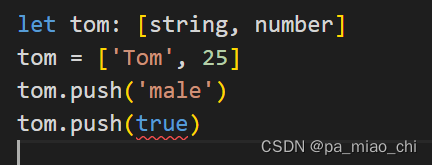
typeScript学习笔记(一)
学习资源来自: 类与接口 TypeScript 入门教程 (xcatliu.com) 一.TypeScript的安装和运行 1.安装TypeScript 通过npm(Node.js包管理器)安装Visual Studio的TypeScript插件:(Visual Studio 2017和Visual Studio 2015 Update 3默认包含了Ty…...

C++_核心编程_多态案例二-制作饮品
#include <iostream> #include <string> using namespace std;/*制作饮品的大致流程为:煮水 - 冲泡 - 倒入杯中 - 加入辅料 利用多态技术实现本案例,提供抽象制作饮品基类,提供子类制作咖啡和茶叶*//*基类*/ class AbstractDr…...

React第五十七节 Router中RouterProvider使用详解及注意事项
前言 在 React Router v6.4 中,RouterProvider 是一个核心组件,用于提供基于数据路由(data routers)的新型路由方案。 它替代了传统的 <BrowserRouter>,支持更强大的数据加载和操作功能(如 loader 和…...

基于Flask实现的医疗保险欺诈识别监测模型
基于Flask实现的医疗保险欺诈识别监测模型 项目截图 项目简介 社会医疗保险是国家通过立法形式强制实施,由雇主和个人按一定比例缴纳保险费,建立社会医疗保险基金,支付雇员医疗费用的一种医疗保险制度, 它是促进社会文明和进步的…...

基于Uniapp开发HarmonyOS 5.0旅游应用技术实践
一、技术选型背景 1.跨平台优势 Uniapp采用Vue.js框架,支持"一次开发,多端部署",可同步生成HarmonyOS、iOS、Android等多平台应用。 2.鸿蒙特性融合 HarmonyOS 5.0的分布式能力与原子化服务,为旅游应用带来…...

Python实现prophet 理论及参数优化
文章目录 Prophet理论及模型参数介绍Python代码完整实现prophet 添加外部数据进行模型优化 之前初步学习prophet的时候,写过一篇简单实现,后期随着对该模型的深入研究,本次记录涉及到prophet 的公式以及参数调优,从公式可以更直观…...

【2025年】解决Burpsuite抓不到https包的问题
环境:windows11 burpsuite:2025.5 在抓取https网站时,burpsuite抓取不到https数据包,只显示: 解决该问题只需如下三个步骤: 1、浏览器中访问 http://burp 2、下载 CA certificate 证书 3、在设置--隐私与安全--…...

Springboot社区养老保险系统小程序
一、前言 随着我国经济迅速发展,人们对手机的需求越来越大,各种手机软件也都在被广泛应用,但是对于手机进行数据信息管理,对于手机的各种软件也是备受用户的喜爱,社区养老保险系统小程序被用户普遍使用,为方…...
混合(Blending))
C++.OpenGL (20/64)混合(Blending)
混合(Blending) 透明效果核心原理 #mermaid-svg-SWG0UzVfJms7Sm3e {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-SWG0UzVfJms7Sm3e .error-icon{fill:#552222;}#mermaid-svg-SWG0UzVfJms7Sm3e .error-text{fill…...
)
安卓基础(Java 和 Gradle 版本)
1. 设置项目的 JDK 版本 方法1:通过 Project Structure File → Project Structure... (或按 CtrlAltShiftS) 左侧选择 SDK Location 在 Gradle Settings 部分,设置 Gradle JDK 方法2:通过 Settings File → Settings... (或 CtrlAltS)…...

通过MicroSip配置自己的freeswitch服务器进行调试记录
之前用docker安装的freeswitch的,启动是正常的, 但用下面的Microsip连接不上 主要原因有可能一下几个 1、通过下面命令可以看 [rootlocalhost default]# docker exec -it freeswitch fs_cli -x "sofia status profile internal"Name …...