【100天精通Python】Day56:Python 数据分析_Pandas数据清洗和处理
目录
数据清洗和处理
1.处理缺失值
1.1 删除缺失值:
1.2 填充缺失值:
1.3 插值:
2 数据类型转换
2.1 数据类型转换
2.2 日期和时间的转换:
2.3 分类数据的转换:
2.4 自定义数据类型的转换:
3 数据去重
4 数据合并和连接
数据清洗和处理
在数据清洗和处理方面,Pandas 提供了多种功能,包括处理缺失值、数据类型转换、数据去重以及数据合并和连接。以下是这些功能的详细描述和示例:
1.处理缺失值
在 Pandas 中处理缺失值有多种方法,包括删除缺失值、填充缺失值和插值。
1.1 删除缺失值:
删除缺失值是最简单的方法,但有时会导致数据损失。您可以使用 dropna() 方法来删除包含缺失值的行或列。
(1)删除包含缺失值的行:
import pandas as pddata = {'A': [1, 2, None, 4],'B': [5, None, 7, 8]}
df = pd.DataFrame(data)# 删除包含缺失值的行
df_cleaned = df.dropna()
print("删除包含缺失值的行的结果:\n", df_cleaned)
(2)删除包含缺失值的列:
# 删除包含缺失值的列
df_cleaned_columns = df.dropna(axis=1)
print("删除包含缺失值的列的结果:\n", df_cleaned_columns)
1.2 填充缺失值:
填充缺失值是用特定值替代缺失值的方法。您可以使用 fillna() 方法来填充缺失值。
使用特定值填充缺失值:
# 使用特定值填充缺失值
df_filled = df.fillna(0) # 用 0 填充缺失值
print("使用特定值填充缺失值的结果:\n", df_filled)
1.3 插值:
插值是一种基于数据的方法,根据已知数据点的值来估计缺失值。Pandas 提供了多种插值方法,如线性插值、多项式插值等。
(1) 线性插值:
线性插值使用已知数据点之间的线性关系来估计缺失值。这是一种简单而常见的插值方法。
import pandas as pddata = {'A': [1, 2, None, 4],'B': [5, None, 7, 8]}
df = pd.DataFrame(data)# 使用线性插值填充缺失值
df_interpolated = df.interpolate()
print("使用线性插值填充缺失值的结果:\n", df_interpolated)
(2) 多项式插值:
多项式插值使用多项式函数来逼近已知数据点,以估计缺失值。您可以指定多项式的阶数。
# 使用多项式插值填充缺失值(阶数为2)
df_poly_interpolated = df.interpolate(method='polynomial', order=2)
print("使用多项式插值填充缺失值的结果:\n", df_poly_interpolated)
(3) 时间序列插值:
对于时间序列数据,可以使用时间相关的插值方法,例如时间线性插值。
# 创建一个带有时间索引的示例 DataFrame
data = {'A': [1, 2, None, 4],'B': [5, None, 7, 8]}
dates = pd.date_range(start='2021-01-01', periods=len(data))
df_time_series = pd.DataFrame(data, index=dates)# 使用时间线性插值填充缺失值
df_time_series_interpolated = df_time_series.interpolate(method='time')
print("使用时间线性插值填充缺失值的结果:\n", df_time_series_interpolated)
2 数据类型转换
在 Pandas 中,数据类型转换是将一列或多列的数据类型更改为其他数据类型的过程。数据类型的转换可以帮助您适应特定的分析需求或确保数据的一致性。以下是一些常见的数据类型转换操作以及示例:
2.1 数据类型转换
- 使用
astype()方法将一列的数据类型转换为其他数据类型,如将整数列转换为浮点数列。 - 使用
pd.to_numeric()将列转换为数值类型,例如整数或浮点数。
import pandas as pd# 创建示例 DataFrame
data = {'A': [1, 2, 3],'B': ['4', '5', '6']}
df = pd.DataFrame(data)# 将列 'A' 从整数转换为浮点数
df['A'] = df['A'].astype(float)# 将列 'B' 从字符串转换为整数
df['B'] = pd.to_numeric(df['B'])print(df)
DataFrame 中的数据类型转换:
df.astype(dtype, copy=True, errors='raise')
dtype: 要将数据类型转换为的目标数据类型。可以是 NumPy 的数据类型(如np.float32)或 Python 数据类型(如float或int)。copy(可选,默认为 True):指定是否返回副本(True)或修改原始 DataFrame(False)。errors(可选,默认为 'raise'):指定如何处理转换错误。如果为 'raise',则会引发异常;如果为 'coerce',则将无法转换的值设置为 NaN。
Series 中的数据类型转换:
s.astype(dtype, copy=True, errors='raise')
import pandas as pd# 创建一个示例 DataFrame
data = {'A': [1, 2, 3],'B': [4, 5, 6]}
df = pd.DataFrame(data)# 将列 'A' 从整数转换为浮点数
df['A'] = df['A'].astype(float)# 将列 'B' 从整数转换为字符串
df['B'] = df['B'].astype(str)# 将列 'C' 从字符串转换为整数并处理转换错误(设置无法转换的值为 NaN)
df['C'] = pd.to_numeric(df['C'], errors='coerce').astype(int)print(df.dtypes)
上述示例中,我们演示了如何使用
astype()和pd.to_numeric()进行数据类型的转换,包括整数转浮点数、整数转字符串以及字符串转整数并处理转换错误的情况。
2.2 日期和时间的转换:
- 使用
pd.to_datetime()将列转换为日期时间类型,以便进行日期时间操作。
import pandas as pd# 创建示例 DataFrame
data = {'Date': ['2021-01-01', '2021-01-02', '2021-01-03'],'Value': [10, 15, 20]}
df = pd.DataFrame(data)# 将 'Date' 列从字符串转换为日期时间类型
df['Date'] = pd.to_datetime(df['Date'])print(df.dtypes)
2.3 分类数据的转换:
- 使用
astype('category')将列转换为分类数据类型,适用于有限的离散值。
import pandas as pd# 创建示例 DataFrame
data = {'Category': ['A', 'B', 'A', 'C']}
df = pd.DataFrame(data)# 将 'Category' 列转换为分类数据类型
df['Category'] = df['Category'].astype('category')print(df.dtypes)
2.4 自定义数据类型的转换:
- 您可以使用自定义函数来将数据转换为所需的数据类型,例如使用
apply()方法。
import pandas as pd# 创建示例 DataFrame
data = {'Numbers': ['1', '2', '3', '4']}
df = pd.DataFrame(data)# 自定义函数将字符串转换为整数并应用到 'Numbers' 列
df['Numbers'] = df['Numbers'].apply(lambda x: int(x))print(df.dtypes)
3 数据去重
在 Pandas 中,您可以使用 drop_duplicates() 方法来删除重复的行。这个方法会返回一个新的 DataFrame,其中不包含重复的行。以下是如何在 Pandas 中执行数据去重操作的示例:
import pandas as pd# 创建示例 DataFrame
data = {'Name': ['Alice', 'Bob', 'Alice', 'David', 'Bob'],'Age': [25, 30, 25, 40, 30]}
df = pd.DataFrame(data)# 执行去重操作,基于所有列
df_no_duplicates = df.drop_duplicates()print("原始 DataFrame:")
print(df)print("\n去重后的 DataFrame:")
print(df_no_duplicates)
上述示例中,drop_duplicates() 方法将基于所有列的内容来去重。如果要基于特定列进行去重,您可以通过传递 subset 参数来指定:
# 基于 'Name' 列进行去重
df_no_duplicates_name = df.drop_duplicates(subset=['Name'])print("基于 'Name' 列去重后的 DataFrame:")
print(df_no_duplicates_name)
您还可以使用 keep 参数来控制保留哪一个重复值。例如,keep='first'(默认值)将保留第一个出现的值,而 keep='last' 将保留最后一个出现的值:
# 基于 'Name' 列进行去重,保留最后一个出现的值
df_keep_last = df.drop_duplicates(subset=['Name'], keep='last')print("基于 'Name' 列去重,保留最后一个出现的值的 DataFrame:")
print(df_keep_last)
这些示例演示了如何使用 Pandas 进行数据去重。根据您的需求,您可以选择不同的去重方式。
4 数据合并和连接
在 Pandas 中,您可以使用不同的方法进行数据合并和连接,这通常用于将多个数据集组合在一起以进行分析。以下是一些常见的数据合并和连接操作以及示例:
4.1 pd.concat():
用于将多个 DataFrame 沿指定轴(通常是行轴或列轴)堆叠在一起。pd.concat() 默认在行轴(axis=0)上堆叠多个 DataFrame,也就是沿着行方向将它们连接在一起。如果您想在列轴(axis=1)上堆叠多个 DataFrame,可以通过指定 axis 参数为1 来实现。
import pandas as pd# 创建两个示例 DataFrame
df1 = pd.DataFrame({'A': ['A0', 'A1', 'A2'],'B': ['B0', 'B1', 'B2']})df2 = pd.DataFrame({'A': ['A3', 'A4', 'A5'],'B': ['B3', 'B4', 'B5']})# 在行轴上堆叠两个 DataFrame
result1 = pd.concat([df1, df2])# 在列轴上堆叠两个 DataFrame
result2 = pd.concat([df1, df2], axis=1)print(result1,result2)
输出:

4.2 pd.merge():
用于基于一个或多个键(列)将两个 DataFrame 合并在一起,类似于 SQL 的 JOIN 操作。
import pandas as pd# 创建两个示例 DataFrame
left = pd.DataFrame({'key': ['K0', 'K1', 'K2'],'value_left': ['V0', 'V1', 'V2']})right = pd.DataFrame({'key': ['K1', 'K2', 'K3'],'value_right': ['V3', 'V4', 'V5']})# 基于 'key' 列进行合并
result = pd.merge(left, right, on='key')print(result)
输出

4.3 df.join():
用于将两个 DataFrame 沿索引合并。
import pandas as pd# 创建两个示例 DataFrame
df1 = pd.DataFrame({'A': ['A0', 'A1', 'A2'],'B': ['B0', 'B1', 'B2']}, index=['I0', 'I1', 'I2'])df2 = pd.DataFrame({'C': ['C0', 'C1', 'C2'],'D': ['D0', 'D1', 'D2']}, index=['I1', 'I2', 'I3'])# 沿索引合并两个 DataFrame
result = df1.join(df2)print(result)
输出:

这些是一些常见的数据合并和连接操作示例。根据您的需求,您可以选择适当的方法来合并和连接数据集。 Pandas 提供了丰富的选项和参数,以满足不同的合并和连接需求。
相关文章:
【100天精通Python】Day56:Python 数据分析_Pandas数据清洗和处理
目录 数据清洗和处理 1.处理缺失值 1.1 删除缺失值: 1.2 填充缺失值: 1.3 插值: 2 数据类型转换 2.1 数据类型转换 2.2 日期和时间的转换: 2.3 分类数据的转换: 2.4 自定义数据类型的转换: 3 数…...

【vue】使用无障碍工具条(详细)
引入:使用的是太阳湾的无障碍工具条,代码地址:https://gitee.com/tywAmblyopia/ToolsUI 具体步骤:下载代码后,将其中的 canyou 文件夹拖入 vue 项目中的 public 文件夹中; 上图是在项目目录中的样子&#…...

java实现命令模式
命令模式是一种行为设计模式,它允许您将请求封装为对象,以便您可以将其参数化、队列化、记录和撤销。在 Java 中实现命令模式涉及创建一个命令接口,具体命令类,以及一个接收者类,该接收者类执行实际操作。下面是一个简…...
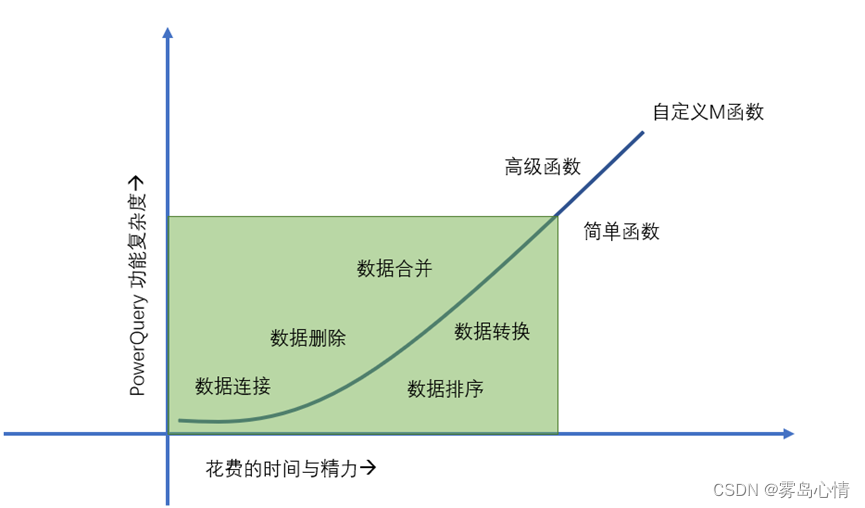
【PowerQuery】PowerQuery学习路径
PowerQuery这么好,怎么去学习呢?相信很多初读本书的朋友迫切的希望了解整个PowerQuery全景知识和它提供的相应的功能。但是对于PowerQuery来说,一开始就会进行自定义函数的构建当然也是不可能的,这里有相应的学习路径来进行由浅入深的学习,帮助读者更好的理解PowerQuery的…...
JDK7多线程并发环境HashMap死循环infinite loop,CPU拉满100%,Java
JDK7多线程并发环境HashMap死循环infinite loop,CPU拉满100%,Java HashMap底层数据实现是数组链表,链表在哈希碰撞后装入新数据,像是一个桶。 HashMap在JDK7的实现中,并发环境存在死循环infinite loop问题。导致的结果…...

Linux下的系统编程——认识进程(七)
前言: 程序是指储存在外部存储(如硬盘)的一个可执行文件, 而进程是指处于执行期间的程序, 进程包括 代码段(text section) 和 数据段(data section), 除了代码段和数据段外, 进程一般还包含打开的文件, 要处理的信号和CPU上下文等等.下面让我们开始对Linux进程有个…...

2023年9月CSPM-3国标项目管理中级认证报名,找弘博创新
CSPM-3中级项目管理专业人员评价,是中国标准化协会(全国项目管理标准化技术委员会秘书处),面向社会开展项目管理专业人员能力的等级证书。旨在构建多层次从业人员培养培训体系,建立健全人才职业能力评价和激励机制的要…...

使用ChatGLMTokenizer处理json格式数据
我下载了一些中文wikipedia数据,准备采用ChatGLMTokenizer对齐进行清洗,整理为预训练语料。 import numpy as np import json from tqdm import tqdm from chatglm_tokenizer.tokenization_chatglm import ChatGLMTokenizertokenizer ChatGLMTokenizer…...

Redis基础特性及应用练习-php
redis持久化(persistence) redis支持两种方式的持久化,可以单独使用或者结合起来使用。 第一种:RDB方式(redis默认的持久化方式) rdb方式的持久化是通过快照完成的,当符合一定条件时redis会自…...

Numpy知识点回顾与学习
Numpy知识点回顾与学习 什么是Numpy? Numpy使用Python进行科学计算的基础包。因为机器学习当中很多都会用到数组、线性代数等知识,经常需要和数组打交道,所以Numpy学习成为了科研之路上必须掌握的一门技能。Numpy包含以下的内容:…...
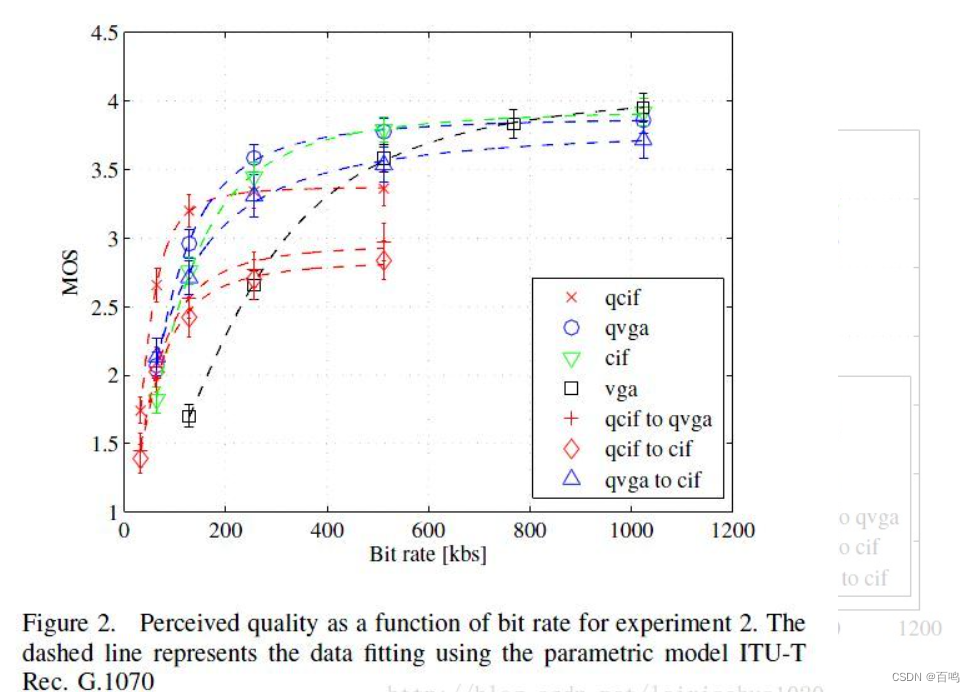
H.264视频编码推荐的分辨率和码率配置表
Video Encoding Settings for H.264 Excellence 针对H.264编码格式,根据不同分辨率,推荐其对应的码率配置关系如下图所示: 如下为上限,超过这个上限再增加码率基本无太大意义!根据业务场景、帧率,建议码率…...

Greenplum 实用工具-gpaddmirrors
注:本文翻译自https://docs.vmware.com/en/VMware-Greenplum/7/greenplum-database/utility_guide-ref-gpaddmirrors.html gpaddmirrors工具用于向未配置镜像的Greenplum数据库系统添加镜像segment。 语法 gpaddmirrors [-p <port_offset>] [-m <datadi…...

详解 Cent OS JDK 8.0 安装配置
环境配置 云服务器云耀云服务器L操作系统CentOS 7.9 64bit | 公共镜像JDK版本64 bit JDK 1.8 下载地址 JDK官网下载地址Java Downloads | Oraclehttps://www.oracle.com/java/technologies/downloads/#java8百度网盘 ARM64 链接:https://pan.baidu.com/s/1wQ1mp…...

代理IP与网络安全在跨境电商中的关键作用
跨境电商已成为全球商业的重要组成部分,然而,随之而来的网络安全问题也日益凸显。为了在海外市场取得成功,不仅需要优质的商品和服务,还需要稳定、安全的网络连接。本文将介绍如何运用Socks5代理IP技术解决这些挑战。 1. 代理IP与…...
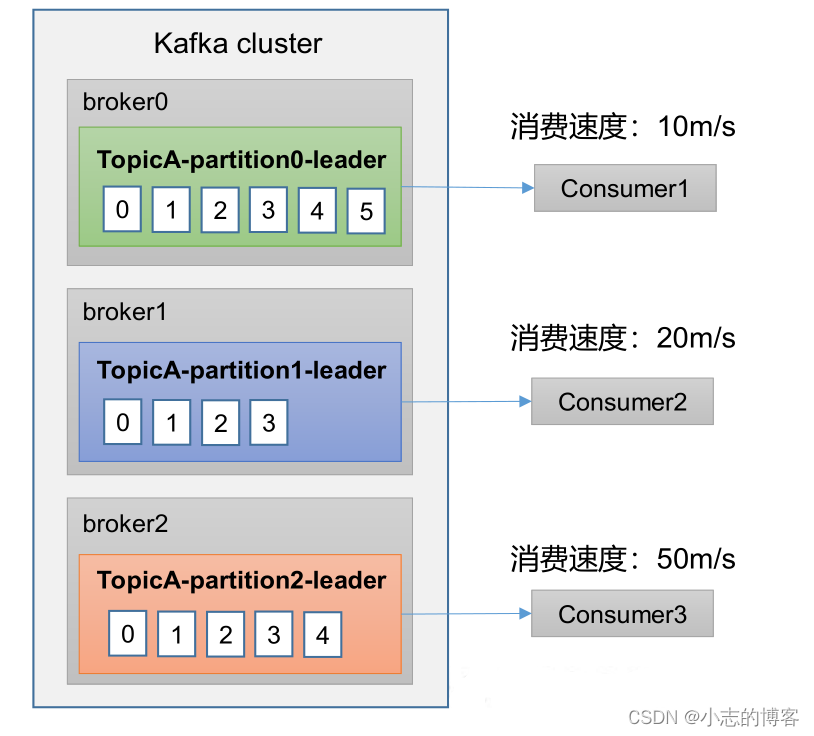
Kafka3.0.0版本——消费者(消费方式)
目录 一、Kafka 消费方式1.1、pull(拉) 模式1.2、push (推)模式1.3、Kafka采用pull(拉) 模式缺点 一、Kafka 消费方式 1.1、pull(拉) 模式 consumer采用从broker中主动拉取数据。K…...

uni-app rich-text组件富文本图片展示不全问题
背景:phpfastadmin富文本插件上传富文本内容到数据库,uni-app渲染富文本内容。这里后端不需要特殊处理。uni-app的rich-text组件展示图片跑板。直接贴代码。 <template><view><title-bar title"会员动态" back backcolor"…...
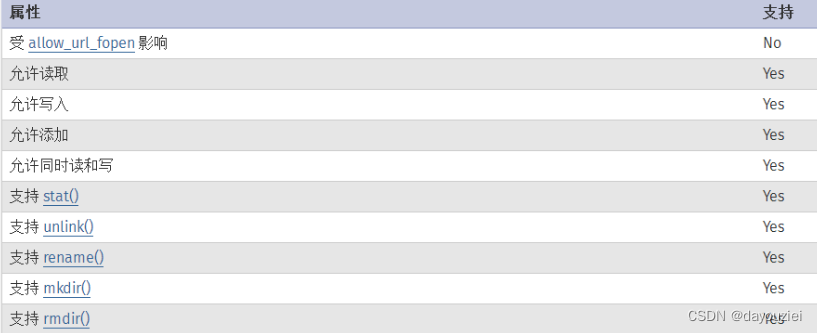
文件包含漏洞学习小结
目录 一、介绍 二、常见文件包含函数 三、文件包含漏洞代码举例分析 四、文件包含漏洞利用方式 4.1 本地文件包含 1、读取敏感文件 2、文件包含可运行的php代码 ①包含图片码 ②包含日志文件 ③包含环境变量getshell ④临时文件包含 ⑤伪协议 4.2 远程文件包含 4.…...
同时安装python2和3解决方案
我先安装python3后,按照网上步骤,继续安装好python2,直接运行python -v只能显示python2,运行python3找不到此命令,通过https://blog.csdn.net/qq_64409509/article/details/131514944这篇文章找到了解决方案࿰…...
)
通过jr-qrcode生成二维码并下载到客户端本地(Vue)
生成二维码 首先生成二维码图片的地址 引入jr-qrcode import jrQrcode from jr-qrcode; 生成二维码图片的地址 // 生成二维码地址 getQRCodeUrl(spreadUrl) {const QRCodeUrl jrQrcode.getQrBase64(spreadUrl);return QRCodeUrl; }that.backUrl jrQrcode.getQrBase64(da…...

命令执行漏洞(附例题)
一.原理 应用有时需要调用一些执行系统命令的函数,如PHP中的system、exec、shell_exec、passthru、popen、proc_popen等,当用户能控制这些函数的参数时,就可以将恶意系统命令拼接到正常命令中,从而造成命令执行攻击。 二.利用条…...

变量 varablie 声明- Rust 变量 let mut 声明与 C/C++ 变量声明对比分析
一、变量声明设计:let 与 mut 的哲学解析 Rust 采用 let 声明变量并通过 mut 显式标记可变性,这种设计体现了语言的核心哲学。以下是深度解析: 1.1 设计理念剖析 安全优先原则:默认不可变强制开发者明确声明意图 let x 5; …...

k8s从入门到放弃之Ingress七层负载
k8s从入门到放弃之Ingress七层负载 在Kubernetes(简称K8s)中,Ingress是一个API对象,它允许你定义如何从集群外部访问集群内部的服务。Ingress可以提供负载均衡、SSL终结和基于名称的虚拟主机等功能。通过Ingress,你可…...

剑指offer20_链表中环的入口节点
链表中环的入口节点 给定一个链表,若其中包含环,则输出环的入口节点。 若其中不包含环,则输出null。 数据范围 节点 val 值取值范围 [ 1 , 1000 ] [1,1000] [1,1000]。 节点 val 值各不相同。 链表长度 [ 0 , 500 ] [0,500] [0,500]。 …...

spring:实例工厂方法获取bean
spring处理使用静态工厂方法获取bean实例,也可以通过实例工厂方法获取bean实例。 实例工厂方法步骤如下: 定义实例工厂类(Java代码),定义实例工厂(xml),定义调用实例工厂ÿ…...

Python如何给视频添加音频和字幕
在Python中,给视频添加音频和字幕可以使用电影文件处理库MoviePy和字幕处理库Subtitles。下面将详细介绍如何使用这些库来实现视频的音频和字幕添加,包括必要的代码示例和详细解释。 环境准备 在开始之前,需要安装以下Python库:…...

【碎碎念】宝可梦 Mesh GO : 基于MESH网络的口袋妖怪 宝可梦GO游戏自组网系统
目录 游戏说明《宝可梦 Mesh GO》 —— 局域宝可梦探索Pokmon GO 类游戏核心理念应用场景Mesh 特性 宝可梦玩法融合设计游戏构想要素1. 地图探索(基于物理空间 广播范围)2. 野生宝可梦生成与广播3. 对战系统4. 道具与通信5. 延伸玩法 安全性设计 技术选…...

OPenCV CUDA模块图像处理-----对图像执行 均值漂移滤波(Mean Shift Filtering)函数meanShiftFiltering()
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 在 GPU 上对图像执行 均值漂移滤波(Mean Shift Filtering),用于图像分割或平滑处理。 该函数将输入图像中的…...

AI病理诊断七剑下天山,医疗未来触手可及
一、病理诊断困局:刀尖上的医学艺术 1.1 金标准背后的隐痛 病理诊断被誉为"诊断的诊断",医生需通过显微镜观察组织切片,在细胞迷宫中捕捉癌变信号。某省病理质控报告显示,基层医院误诊率达12%-15%,专家会诊…...

云原生安全实战:API网关Kong的鉴权与限流详解
🔥「炎码工坊」技术弹药已装填! 点击关注 → 解锁工业级干货【工具实测|项目避坑|源码燃烧指南】 一、基础概念 1. API网关(API Gateway) API网关是微服务架构中的核心组件,负责统一管理所有API的流量入口。它像一座…...
 + 力扣解决)
LRU 缓存机制详解与实现(Java版) + 力扣解决
📌 LRU 缓存机制详解与实现(Java版) 一、📖 问题背景 在日常开发中,我们经常会使用 缓存(Cache) 来提升性能。但由于内存有限,缓存不可能无限增长,于是需要策略决定&am…...