数据集学习笔记(六):目标检测和图像分割标注软件介绍和使用,并转换成YOLO系列可使用的数据集格式
文章目录
- 一、目标检测
- 1.1 labelImg
- 1.2 介绍
- 1.3 安装
- 1.4 使用
- 1.5 转换
- 1.6 验证
- 二、图像分割
- 2.1 labelme
- 2.2 介绍
- 2.3 安装
- 2.4 使用
- 2.5 转换
- 2.6 验证
一、目标检测
1.1 labelImg
1.2 介绍
labelImg是一个开源的图像标注工具,用于创建图像标注数据集。它提供了一个简单易用的界面,允许用户通过绘制边界框或者创建多边形来标注图像中的对象。它支持多种常见的标注格式,如Pascal VOC、YOLO和COCO等。
使用labelImg,用户可以加载图像文件夹,逐个标注图像中的对象,并保存标注结果。该工具还提供了一些快捷键和功能,如缩放、移动和删除标注框,以及快速切换到下一张图像等。此外,labelImg还支持标注图像的困难程度、部分可见性和关键点等。
labelImg是一个跨平台的工具,可以在Windows、Linux和macOS等操作系统上运行。它基于Python和Qt开发,可以通过pip安装或从GitHub上获取源代码。这使得用户可以根据自己的需求进行定制和扩展。
总而言之,labelImg是一个功能强大、易于使用的图像标注工具,适用于创建各种类型的标注数据集,从而用于训练和评估计算机视觉模型。
1.3 安装
pip install labelImg
1.4 使用
- 在cmd中输入labelImg,打开目标标注界面

- open dir选择图片的文件夹、Change Save Dir选择label保存的位置、在View下选择auto save mode可以不用每次都要点击保存、在File里面选择YOLO数据集的格式(点击pascalVOC切换)。
- 通过w来选择标注区域,然后写上类别名
- 键盘输入a是上一张,d是下一张
- 然后按照这种格式将图片和label进行分开(train和valid同理)
1.5 转换
如果通过labelImg直接得到txt标签文本是不用进行转换就可以提供给YOLO进行训练的。
如果是保存的XML文本,则需要通过下面代码进行转换。
修改两个路径:xml文件地址和创建保存txt文件的地址
import os
import xml.etree.ElementTree as ET# xml文件存放目录(修改成自己的文件名)
input_dir = r'E:\auto_label\annotation'# 输出txt文件目录(自己创建的文件夹)
out_dir = r'E:\auto_label\labels'class_list = []# 获取目录所有xml文件
def file_name(input_dir):F = []for root, dirs, files in os.walk(input_dir):for file in files:# print file.decode('gbk') #文件名中有中文字符时转码if os.path.splitext(file)[1] == '.xml':t = os.path.splitext(file)[0]F.append(t) # 将所有的文件名添加到L列表中return F # 返回L列表# 获取所有分类
def get_class(filelist):for i in filelist:f_dir = input_dir + "\\" + i + ".xml"in_file = open(f_dir, encoding='UTF-8')filetree = ET.parse(in_file)in_file.close()root = filetree.getroot()for obj in root.iter('object'):cls = obj.find('name').textif cls not in class_list:class_list.append(cls)def ConverCoordinate(imgshape, bbox):# 将xml像素坐标转换为txt归一化后的坐标xmin, xmax, ymin, ymax = bboxwidth = imgshape[0]height = imgshape[1]dw = 1. / widthdh = 1. / heightx = (xmin + xmax) / 2.0y = (ymin + ymax) / 2.0w = xmax - xminh = ymax - ymin# 归一化x = x * dwy = y * dhw = w * dwh = h * dhreturn x, y, w, hdef readxml(i):f_dir = input_dir + "\\" + i + ".xml"txtresult = ''outfile = open(f_dir, encoding='UTF-8')filetree = ET.parse(outfile)outfile.close()root = filetree.getroot()# 获取图片大小size = root.find('size')width = int(size.find('width').text)height = int(size.find('height').text)imgshape = (width, height)# 转化为yolov5的格式for obj in root.findall('object'):# 获取类别名obj_name = obj.find('name').textobj_id = class_list.index(obj_name)# 获取每个obj的bbox框的左上和右下坐标bbox = obj.find('bndbox')xmin = float(bbox.find('xmin').text)xmax = float(bbox.find('xmax').text)ymin = float(bbox.find('ymin').text)ymax = float(bbox.find('ymax').text)bbox_coor = (xmin, xmax, ymin, ymax)x, y, w, h = ConverCoordinate(imgshape, bbox_coor)txt = '{} {} {} {} {}\n'.format(obj_id, x, y, w, h)txtresult = txtresult + txt# print(txtresult)f = open(out_dir + "\\" + i + ".txt", 'a')f.write(txtresult)f.close()# 获取文件夹下的所有文件
filelist = file_name(input_dir)# 获取所有分类
get_class(filelist)# 打印class
print(class_list)# xml转txt
for i in filelist:readxml(i)# 在out_dir下生成一个class文件
f = open(out_dir + "\\classes.txt", 'a')
classresult = ''
for i in class_list:classresult = classresult + i + "\n"
f.write(classresult)
f.close()1.6 验证
import cv2
import os# 读取txt文件信息
def read_list(txt_path):pos = []with open(txt_path, 'r') as file_to_read:while True:lines = file_to_read.readline() # 整行读取数据if not lines:break# 将整行数据分割处理,如果分割符是空格,括号里就不用传入参数,如果是逗号, 则传入‘,'字符。p_tmp = [float(i) for i in lines.split(' ')]pos.append(p_tmp) # 添加新读取的数据# Efield.append(E_tmp)passreturn pos# txt转换为box
def convert(size, box):xmin = (box[1] - box[3] / 2.) * size[1]xmax = (box[1] + box[3] / 2.) * size[1]ymin = (box[2] - box[4] / 2.) * size[0]ymax = (box[2] + box[4] / 2.) * size[0]box = (int(xmin), int(ymin), int(xmax), int(ymax))return boxdef draw_box_in_single_image(image_path, txt_path):# 读取图像image = cv2.imread(image_path)pos = read_list(txt_path)for i in range(len(pos)):label = classes[int(str(int(pos[i][0])))]print('label is '+label)box = convert(image.shape, pos[i])image = cv2.rectangle(image,(box[0], box[1]),(box[2],box[3]),colores[int(str(int(pos[i][0])))],2)cv2.putText(image, label,(box[0],box[1]-2), 0, 1, colores[int(str(int(pos[i][0])))], thickness=2, lineType=cv2.LINE_AA)cv2.imshow("images", image)cv2.waitKey(0)if __name__ == '__main__':img_folder = "D:\datasets\YOLO/images"img_list = os.listdir(img_folder)img_list.sort()label_folder = "D:\datasets\YOLO/labels"label_list = os.listdir(label_folder)label_list.sort()classes = {0: "cat", 1: "dog"}colores = [(0,0,255),(255,0,255)]for i in range(len(img_list)):image_path = img_folder + "\\" + img_list[i]txt_path = label_folder + "\\" + label_list[i]draw_box_in_single_image(image_path, txt_path)
二、图像分割
2.1 labelme
2.2 介绍
LabelMe是一个在线图像标注工具,旨在帮助用户对图像进行标注和注释。它提供了一个简单易用的界面,让用户可以方便地在图像上绘制边界框、标记点、线条等,并为每个标注对象添加文字描述。
LabelMe的主要特点包括:
-
灵活多样的标注工具:LabelMe提供了多种标注工具,包括矩形框、多边形、线条、点等,可以满足不同类型图像的标注需求。
-
支持多种标注任务:LabelMe适用于各种标注任务,包括对象检测、语义分割、关键点标注等。
-
数据的可视化和管理:LabelMe支持将标注结果可视化展示,用户可以在网页上查看和编辑标注结果。此外,LabelMe还提供了数据管理功能,可以方便地组织和管理大量的标注数据。
-
数据的导入和导出:LabelMe支持将标注数据导入和导出为常见的数据格式,如XML、JSON等,方便与其他机器学习和计算机视觉工具集成。
总的来说,LabelMe是一个功能强大且易于使用的在线图像标注工具,适用于各种图像标注任务,并提供了方便的数据管理和导入导出功能。
2.3 安装
pip install labelme -i https://pypi.tuna.tsinghua.edu.cn/simple/
2.4 使用
参考链接:点击
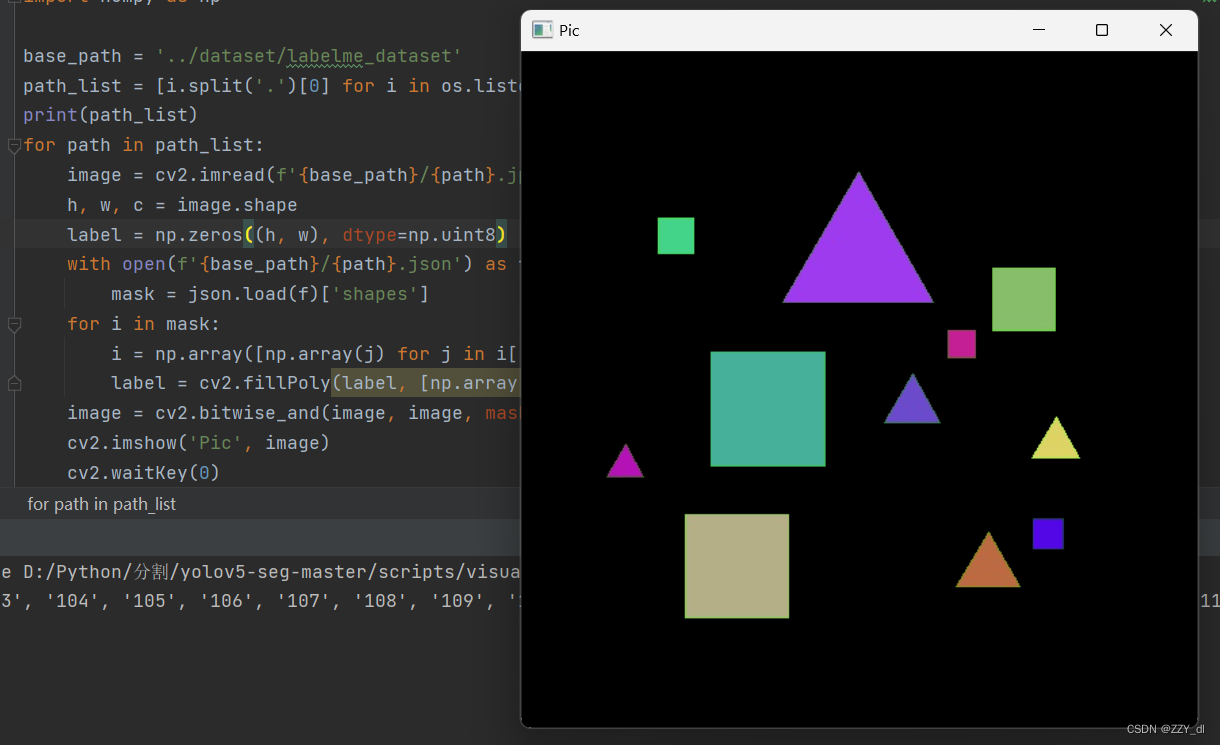
打完标签后,会在我们图片的目录下相应的生成JSON标签文件,首先我们先验证一下我们打的标签和图片是否对应,如果没问题那么我们才转换成YOLO可训练的标签文件。参考代码如下:
import os, cv2, json
import numpy as npbase_path = '../dataset/labelme_dataset'
path_list = [i.split('.')[0] for i in os.listdir(base_path) if 'json' in i]
print(path_list)
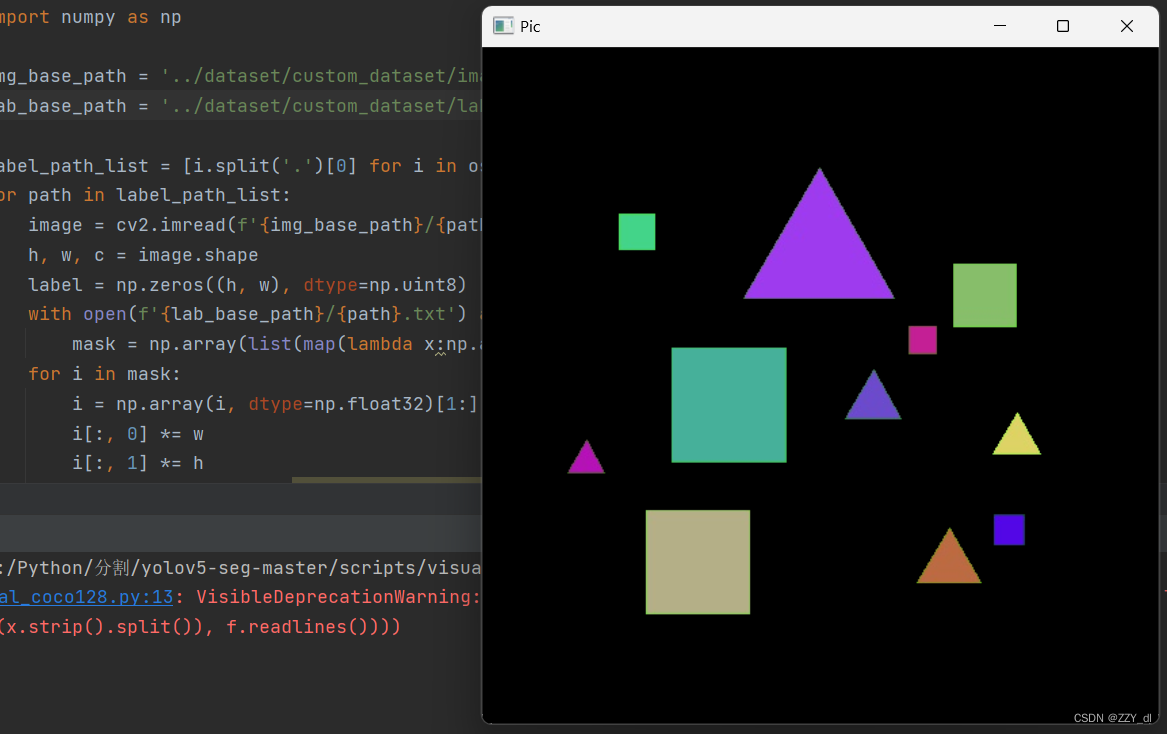
for path in path_list:image = cv2.imread(f'{base_path}/{path}.jpg')h, w, c = image.shapelabel = np.zeros((h, w), dtype=np.uint8)with open(f'{base_path}/{path}.json') as f:mask = json.load(f)['shapes']for i in mask:i = np.array([np.array(j) for j in i['points']])label = cv2.fillPoly(label, [np.array(i, dtype=np.int32)], color=255)image = cv2.bitwise_and(image, image, mask=label)cv2.imshow('Pic', image)cv2.waitKey(0)cv2.destroyAllWindows()
2.5 转换
既然打的标签文件是没问题的,那么我们开始转换成YOLO可用的TXT文件,转换代码如下:
import os, cv2, json
import numpy as npclasses = ['square', 'triangle'] # 修改成对应的类别base_path = '../dataset/labelme_dataset' # 指定json和图片的位置
path_list = [i.split('.')[0] for i in os.listdir(base_path)]
for path in path_list:image = cv2.imread(f'{base_path}/{path}.jpg')h, w, c = image.shapewith open(f'{base_path}/{path}.json') as f:masks = json.load(f)['shapes']with open(f'{base_path}/{path}.txt', 'w+') as f:for idx, mask_data in enumerate(masks):mask_label = mask_data['label']if '_' in mask_label:mask_label = mask_label.split('_')[0]mask = np.array([np.array(i) for i in mask_data['points']], dtype=np.float)mask[:, 0] /= wmask[:, 1] /= hmask = mask.reshape((-1))if idx != 0:f.write('\n')f.write(f'{classes.index(mask_label)} {" ".join(list(map(lambda x:f"{x:.6f}", mask)))}')
通过这个代码可以在当前目录生成对应文件名的TXT标签文件,然后我们需要将其划分为训练集、验证集和测试集,可通过下面的代码:
import os, shutil, random
import numpy as nppostfix = 'jpg' # 里面都是jpg图片
base_path = '../dataset/labelme_dataset' # 原图片和TXT文件
dataset_path = '../dataset/custom_dataset' # 保存的目标位置
val_size, test_size = 0.1, 0.2os.makedirs(dataset_path, exist_ok=True)
os.makedirs(f'{dataset_path}/images', exist_ok=True)
os.makedirs(f'{dataset_path}/images/train', exist_ok=True)
os.makedirs(f'{dataset_path}/images/val', exist_ok=True)
os.makedirs(f'{dataset_path}/images/test', exist_ok=True)
os.makedirs(f'{dataset_path}/labels/train', exist_ok=True)
os.makedirs(f'{dataset_path}/labels/val', exist_ok=True)
os.makedirs(f'{dataset_path}/labels/test', exist_ok=True)path_list = np.array([i.split('.')[0] for i in os.listdir(base_path) if 'txt' in i])
random.shuffle(path_list)
train_id = path_list[:int(len(path_list) * (1 - val_size - test_size))]
val_id = path_list[int(len(path_list) * (1 - val_size - test_size)):int(len(path_list) * (1 - test_size))]
test_id = path_list[int(len(path_list) * (1 - test_size)):]for i in train_id:shutil.copy(f'{base_path}/{i}.{postfix}', f'{dataset_path}/images/train/{i}.{postfix}')shutil.copy(f'{base_path}/{i}.txt', f'{dataset_path}/labels/train/{i}.txt')for i in val_id:shutil.copy(f'{base_path}/{i}.{postfix}', f'{dataset_path}/images/val/{i}.{postfix}')shutil.copy(f'{base_path}/{i}.txt', f'{dataset_path}/labels/val/{i}.txt')for i in test_id:shutil.copy(f'{base_path}/{i}.{postfix}', f'{dataset_path}/images/test/{i}.{postfix}')shutil.copy(f'{base_path}/{i}.txt', f'{dataset_path}/labels/test/{i}.txt')
2.6 验证
通过结合TXT标签文件以及图片来进行可视化,以验证其是否正确。
import os, cv2
import numpy as npimg_base_path = '../dataset/custom_dataset/images/train'
lab_base_path = '../dataset/custom_dataset/labels/train'label_path_list = [i.split('.')[0] for i in os.listdir(img_base_path)]
for path in label_path_list:image = cv2.imread(f'{img_base_path}/{path}.jpg')h, w, c = image.shapelabel = np.zeros((h, w), dtype=np.uint8)with open(f'{lab_base_path}/{path}.txt') as f:mask = np.array(list(map(lambda x:np.array(x.strip().split()), f.readlines())))for i in mask:i = np.array(i, dtype=np.float32)[1:].reshape((-1, 2))i[:, 0] *= wi[:, 1] *= hlabel = cv2.fillPoly(label, [np.array(i, dtype=np.int32)], color=255)image = cv2.bitwise_and(image, image, mask=label)cv2.imshow('Pic', image)cv2.waitKey(0)cv2.destroyAllWindows()
相关文章:
数据集学习笔记(六):目标检测和图像分割标注软件介绍和使用,并转换成YOLO系列可使用的数据集格式
文章目录 一、目标检测1.1 labelImg1.2 介绍1.3 安装1.4 使用1.5 转换1.6 验证 二、图像分割2.1 labelme2.2 介绍2.3 安装2.4 使用2.5 转换2.6 验证 一、目标检测 1.1 labelImg 1.2 介绍 labelImg是一个开源的图像标注工具,用于创建图像标注数据集。它提供了一个…...
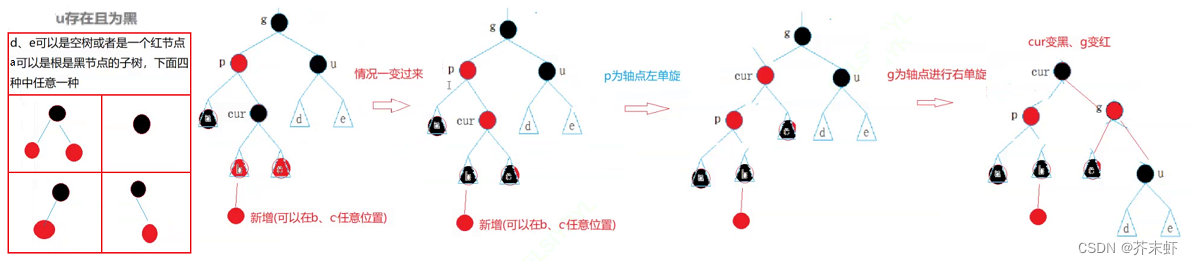
【高阶数据结构】红黑树 {概念及性质;红黑树的结构;红黑树的实现;红黑树插入操作详细解释;红黑树的验证}
红黑树 一、红黑树的概念 红黑树(Red Black Tree) 是一种自平衡二叉查找树,在每个结点上增加一个存储位表示结点的颜色,可以是Red或Black。 通过对任何一条从根到叶子的路径上各个结点着色方式的限制,红黑树确保没有…...

获取对象占用内存
添加依赖 <dependency><groupId>org.apache.lucene</groupId><artifactId>lucene-core</artifactId><version>4.0.0</version> </dependency>添加vm启动参数 --add-opens java.base/java.langALL-UNNAMED --add-opens java.ba…...
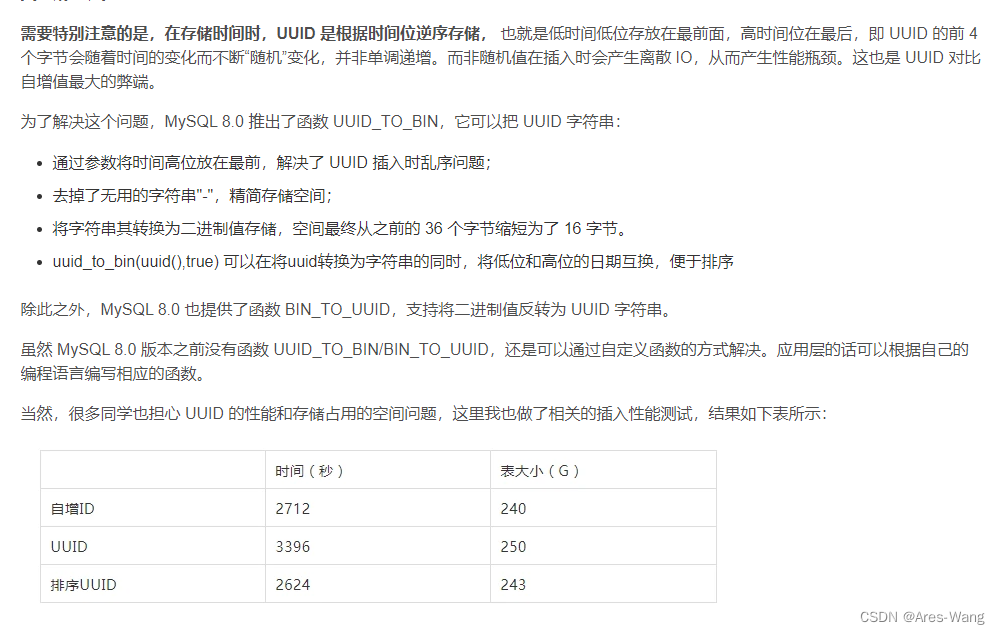
mysql UUID 作为主键的问题
UUID 在MySQL中,可以使用UUID()函数来生成一个新的UUID值。该函数的返回值是一个字符串类型,表示一个32位的十六进制数字,其中包含4个连字符“-”,例如:“6ccd780c-baba-1026-9564-0040f4311e29”。 varchar(32) 32*4…...

2023高教社杯全国大学生数学建模竞赛选题建议
如下为C君的2023高教社杯全国大学生数学建模竞赛(国赛)选题建议, 提示:DS C君认为的难度:C<B<A,开放度:B<A<C 。 D、E题推荐选E题,后续会直接更新E论文和思路…...

分类预测 | MATLAB实现GRNN广义回归神经网络多特征分类预测
分类预测 | MATLAB实现GRNN广义回归神经网络多特征分类预测 目录 分类预测 | MATLAB实现GRNN广义回归神经网络多特征分类预测分类效果基本介绍模型描述预测过程程序设计参考资料分类效果 基本介绍 MATLAB实现GRNN广义回归神经网络多特...

低功耗窗帘电机解决方案成功应用并通过 Matter 1.1 认证
Nordic Semiconductor官方宣布与HooRii Tech(和众科技)携手合作,基于 Nordic nRF52840 芯片平台打造的 HRN71模组,成功赋能低功耗窗帘电机品牌发布Matter产品。低功耗窗帘电机获得 Matter 1.1 认证意味着它具有与其他 Matter 认证…...

如何修复老照片?老照片修复翻新的方法
老旧照片,尤其是黑白照片,往往因为年代久远、保存方式不当等原因而出现褪色、污损、划痕等问题,会比较难以修复,就算是技术精湛的专业修复师,也是需要投入极大时间精力的,效果也是不可预料的。 修复老照片…...
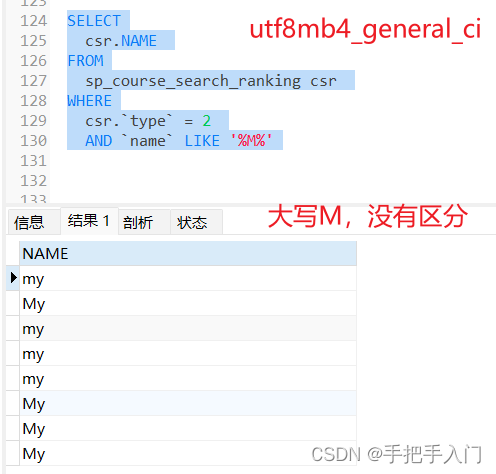
MySQL:区分大小写
查看MySQL版本 show variables; 1、查看 MySQL 当前的区分大小写设置: SHOW VARIABLES LIKE lower_case_table_names; 或者 show Variables like %table_names 2、更改大小写敏感设置: 在 MySQL 5.7 中,更改大小写敏感设置要求修改配置文件 …...

刷题笔记19——优势洗牌和去重保持字典序
摆出无比亲密的态度,装模作样地与对方套近乎,频繁地联系对方。这都说明他们并不相信自己得到了对方的信赖,若是互相信赖,便不会依赖亲密的感觉。在外人看来,反而显得冷淡。 ——尼采《人性的,太人性的》 ha…...
星际争霸之小霸王之小蜜蜂(十一)--杀杀杀
系列文章目录 星际争霸之小霸王之小蜜蜂(十)--鼠道 星际争霸之小霸王之小蜜蜂(九)--狂鼠之灾 星际争霸之小霸王之小蜜蜂(八)--蓝皮鼠和大脸猫 星际争霸之小霸王之小蜜蜂(七)--消失…...

腾讯云免费SSL证书申请流程_每年免费50个HTTPS证书
2023腾讯云免费SSL证书申请流程,一个腾讯云账号可以申请50张免费SSL证书,免费SSL证书为DV证书,仅支持单一域名,申请腾讯云免费SSL证书3分钟即可申请成功,免费SSL证书品牌为TrustAsia亚洲诚信,腾讯云百科分享…...

C#上位机开发目录
C#上位机序列1: 多线程(线程同步,事件触发,信号量,互斥锁,共享内存,消息队列) C#上位机序列2: 同步异步(async、await) C#上位机序列3: 流程控制(串行,并行,…...

网络通信基础
IP地址 使用ip地址来描述网络上一个设备所在的位置 端口号 区分一个主机上不同的程序,一个网络程序,在启动的时候,都需要绑定一个或者多个端口号,后续的通信过程都需要依赖端口号来进行展开的,mysql默认的端口号是3306 协议 描述了网络通信传输的数据的含义,表示一种约定,…...

框架分析(10)-SQLAlchemy
框架分析(10)-SQLAlchemy 专栏介绍SQLAlchemy特性分析ORM支持数据库适配器事务支持查询构建器数据库连接池事务管理器数据库迁移特性总结 优缺点优点强大的对象关系映射支持多种数据库灵活的查询语言自动管理数据库连接支持事务管理易于扩展和定制 缺点学…...
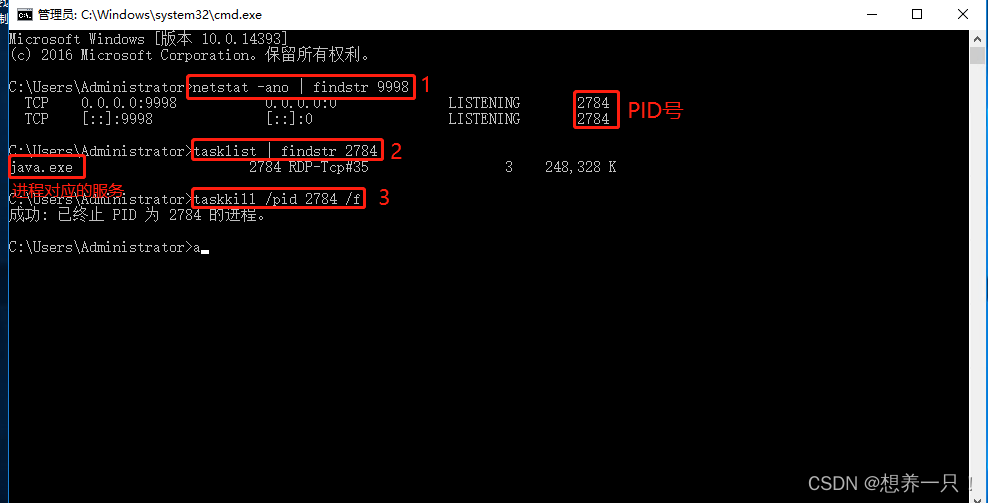
Linux/Windows中根据端口号关闭进程及关闭Java进程
目录 Linux 根据端口号关闭进程 关闭Java服务进程 Windows 根据端口号关闭进程 Linux 根据端口号关闭进程 第一步:根据端口号查询进程PID,可使用如下命令 netstat -anp | grep 8088(以8088端口号为例) 第二步:…...
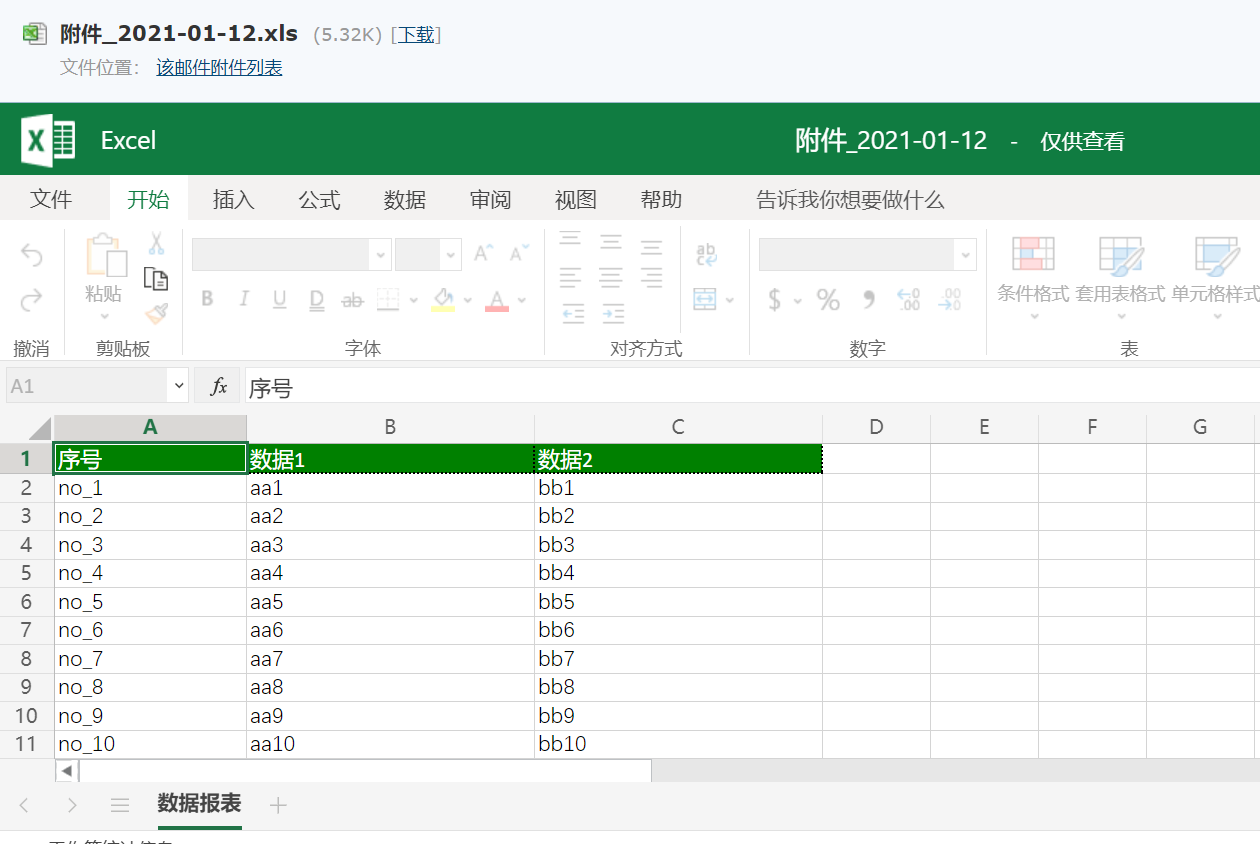
基于springboot实现了后台定时统计数据报表并将数据生成excel文件作为附件,然后通过邮件发送通知的功能
概述 本例子基于springboot实现了后台定时统计数据报表并将数据生成excel文件作为附件,然后通过邮件发送通知的功能。 详细 一、准备工作 1、首先注册两个邮箱,一个发送邮箱,一个接收邮箱。 2、发送邮箱开启IMAP/SMTP/POP3服务,…...
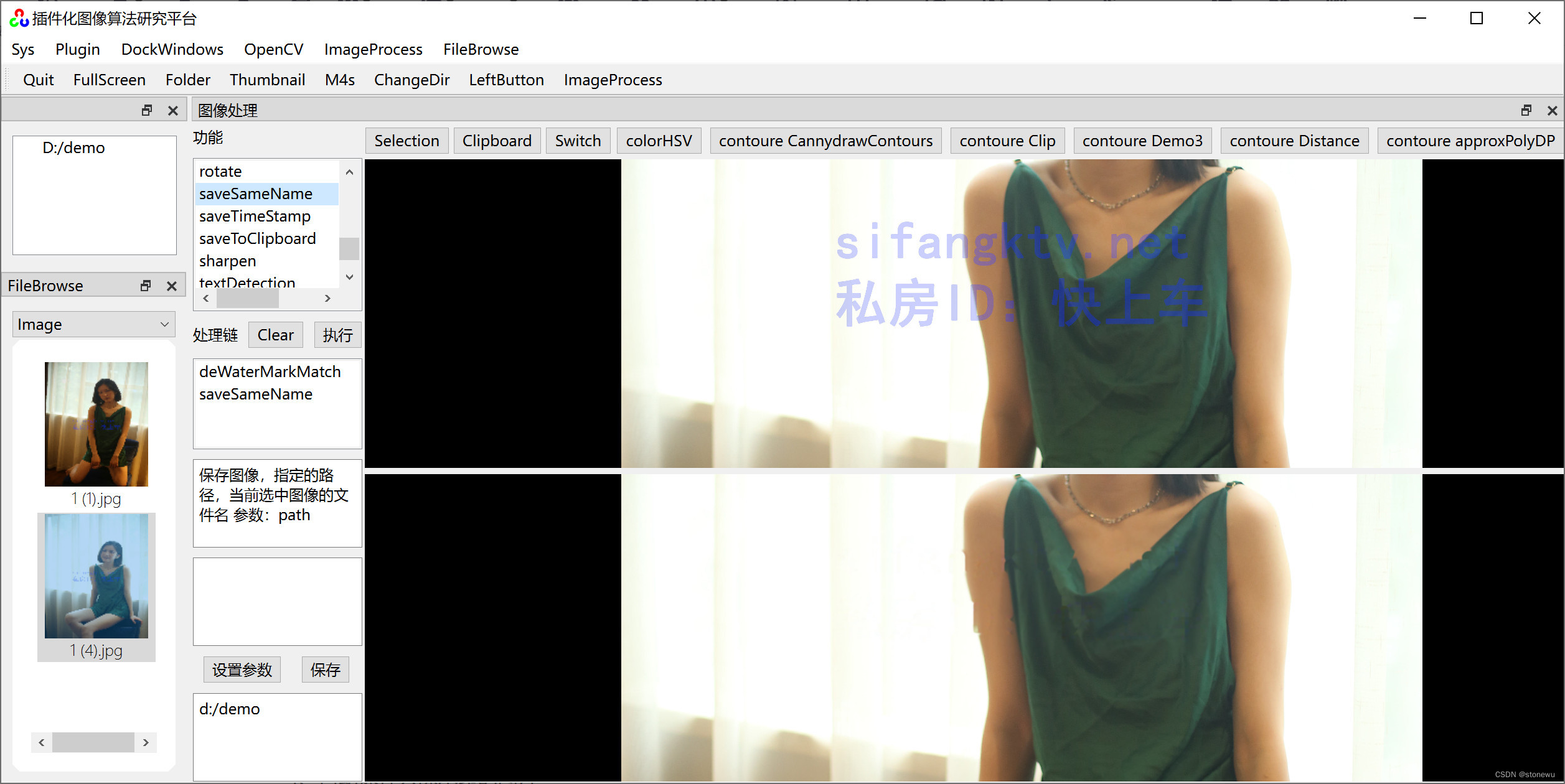
opencv 提取选中区域内指定hsv颜色的水印
基于《QT 插件化图像算法研究平台》做的功能插件。提取选中区域内指定hsv颜色的水印。 《QT 插件化图像算法研究平台》有个HSV COLOR PICK功能,可以很直观、方便地分析出水印 的hsv颜色,比如, 蓝色:100,180,0,255,100,255。 然后利用 opencv …...

如何理解张量、张量索引、切片、张量维度变换
Tensor 张量 Tensor,中文翻译“张量”,是一种特殊的数据结构,与数组和矩阵非常相似。在 PyTorch 中,使用张量对模型的输入和输出以及模型的参数进行编码。 Tensor 是一个 Python Class。PyTorch 官方文档中定义“Tensor࿰…...
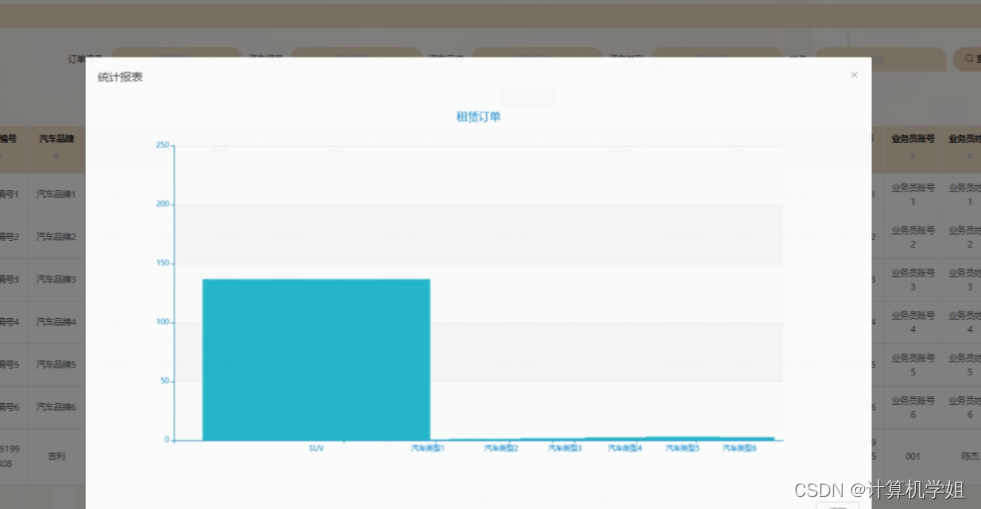
基于SpringBoot的汽车租赁系统
基于SpringBootVue的汽车租赁系统,前后端分离 开发语言:Java数据库:MySQL技术:SpringBoot、Vue、Mybaits Plus、ELementUI工具:IDEA/Ecilpse、Navicat、Maven 角色:管理员、业务员、用户 管理员 用户管理…...

AI Agent与Agentic AI:原理、应用、挑战与未来展望
文章目录 一、引言二、AI Agent与Agentic AI的兴起2.1 技术契机与生态成熟2.2 Agent的定义与特征2.3 Agent的发展历程 三、AI Agent的核心技术栈解密3.1 感知模块代码示例:使用Python和OpenCV进行图像识别 3.2 认知与决策模块代码示例:使用OpenAI GPT-3进…...

AtCoder 第409场初级竞赛 A~E题解
A Conflict 【题目链接】 原题链接:A - Conflict 【考点】 枚举 【题目大意】 找到是否有两人都想要的物品。 【解析】 遍历两端字符串,只有在同时为 o 时输出 Yes 并结束程序,否则输出 No。 【难度】 GESP三级 【代码参考】 #i…...

前端导出带有合并单元格的列表
// 导出async function exportExcel(fileName "共识调整.xlsx") {// 所有数据const exportData await getAllMainData();// 表头内容let fitstTitleList [];const secondTitleList [];allColumns.value.forEach(column > {if (!column.children) {fitstTitleL…...

什么是库存周转?如何用进销存系统提高库存周转率?
你可能听说过这样一句话: “利润不是赚出来的,是管出来的。” 尤其是在制造业、批发零售、电商这类“货堆成山”的行业,很多企业看着销售不错,账上却没钱、利润也不见了,一翻库存才发现: 一堆卖不动的旧货…...

pikachu靶场通关笔记22-1 SQL注入05-1-insert注入(报错法)
目录 一、SQL注入 二、insert注入 三、报错型注入 四、updatexml函数 五、源码审计 六、insert渗透实战 1、渗透准备 2、获取数据库名database 3、获取表名table 4、获取列名column 5、获取字段 本系列为通过《pikachu靶场通关笔记》的SQL注入关卡(共10关࿰…...

React---day11
14.4 react-redux第三方库 提供connect、thunk之类的函数 以获取一个banner数据为例子 store: 我们在使用异步的时候理应是要使用中间件的,但是configureStore 已经自动集成了 redux-thunk,注意action里面要返回函数 import { configureS…...

VM虚拟机网络配置(ubuntu24桥接模式):配置静态IP
编辑-虚拟网络编辑器-更改设置 选择桥接模式,然后找到相应的网卡(可以查看自己本机的网络连接) windows连接的网络点击查看属性 编辑虚拟机设置更改网络配置,选择刚才配置的桥接模式 静态ip设置: 我用的ubuntu24桌…...
与常用工具深度洞察App瓶颈)
iOS性能调优实战:借助克魔(KeyMob)与常用工具深度洞察App瓶颈
在日常iOS开发过程中,性能问题往往是最令人头疼的一类Bug。尤其是在App上线前的压测阶段或是处理用户反馈的高发期,开发者往往需要面对卡顿、崩溃、能耗异常、日志混乱等一系列问题。这些问题表面上看似偶发,但背后往往隐藏着系统资源调度不当…...

Python基于历史模拟方法实现投资组合风险管理的VaR与ES模型项目实战
说明:这是一个机器学习实战项目(附带数据代码文档),如需数据代码文档可以直接到文章最后关注获取。 1.项目背景 在金融市场日益复杂和波动加剧的背景下,风险管理成为金融机构和个人投资者关注的核心议题之一。VaR&…...

【从零学习JVM|第三篇】类的生命周期(高频面试题)
前言: 在Java编程中,类的生命周期是指类从被加载到内存中开始,到被卸载出内存为止的整个过程。了解类的生命周期对于理解Java程序的运行机制以及性能优化非常重要。本文会深入探寻类的生命周期,让读者对此有深刻印象。 目录 …...