Stream API
Stream API执行流程
Stream API(java.util.stream)把真正的函数式编程风格引入到Java中,可以极大地提高程序员生产力,让程序员写出高效、简洁的代码
实际开发中项目中多数数据源都是来自MySQL、Oracle等关系型数据库,还有部分来自MongDB、Redis等非关系型数据库
- 当我们从关系型数据库中查询数据时,可以先使用SQL语句在数据库中就对数据进行过滤,排序等操作,最后后台Java程序接收
- 当我们从非关系型数据库中查询数据时,由于不能在数据库中使用SQL语句操作数据,此时只能靠后台Java程序(Stream API)操作数据库中查询到的数据
Stream是Java8中处理集合的关键抽象概念,它可以指定你希望对集合/数组进行的操作(可是是非常复杂的查找、过滤和映射数据等操作)
- 使用Stream API对内存数据(集合/数组)进行操作就类似于使用SQL语句对数据库表中数据的操作,即Stream API提供了一种高效且易于使用的处理数据的方式
Stream和Collection集合的区别: Stream关注的是数据的运算(过滤操作)与CPU打交道, 集合关注的是数据的存储(静态的存储结构)与内存打交道
Stream的特性
- Stream自己不会存储元素
- Stream不会改变源对象,相反他们会返回一个持有结果的新Stream
- Stream操作是延迟执行的,只有执行了终止操作后才会执行中间操作链并产生结果
- Stream一旦执行了终止操作,就不能再次使用该Stream执行其它中间操作或终止操作了,得重新创建一个新的流才行

数据准备
public class Employee {private int id;private String name;private int age;private double salary;public int getId() {return id;}public void setId(int id) {this.id = id;}public String getName() {return name;}public void setName(String name) {this.name = name;}public int getAge() {return age;}public void setAge(int age) {this.age = age;}public double getSalary() {return salary;}public void setSalary(double salary) {this.salary = salary;}public Employee() {System.out.println("Employee().....");}public Employee(int id) {this.id = id;System.out.println("Employee(int id).....");}public Employee(int id, String name) {this.id = id;this.name = name;}public Employee(int id, String name, int age, double salary) {this.id = id;this.name = name;this.age = age;this.salary = salary;}@Overridepublic String toString() {return "Employee{" + "id=" + id + ", name='" + name + '\'' + ", age=" + age + ", salary=" + salary + '}';}@Overridepublic boolean equals(Object o) {if (this == o)return true;if (o == null || getClass() != o.getClass())return false;Employee employee = (Employee) o;if (id != employee.id)return false;if (age != employee.age)return false;if (Double.compare(employee.salary, salary) != 0)return false;return name != null ? name.equals(employee.name) : employee.name == null;}@Overridepublic int hashCode() {int result;long temp;result = id;result = 31 * result + (name != null ? name.hashCode() : 0);result = 31 * result + age;temp = Double.doubleToLongBits(salary);result = 31 * result + (int) (temp ^ (temp >>> 32));return result;}
}
提供用于测试数据的类
public class EmployeeData {public static List<Employee> getEmployees() {List<Employee> list = new ArrayList<>();list.add(new Employee(1001, "马化腾", 34, 6000.38));list.add(new Employee(1002, "马云", 12, 9876.12));list.add(new Employee(1003, "刘强东", 33, 3000.82));list.add(new Employee(1004, "雷军", 26, 7657.37));list.add(new Employee(1005, "李彦宏", 65, 5555.32));list.add(new Employee(1006, "比尔盖茨", 42, 9500.43));list.add(new Employee(1007, "任正非", 26, 4333.32));list.add(new Employee(1008, "扎克伯格", 35, 2500.32));return list;}
}
通过一个数据源创建Stream
方式一通过集合:Java8中的Collection接口扩展了两个获取Stream流的方法
| 方法名 | 功能 |
|---|---|
| default Stream stream() | 返回一个顺序流(按照顺序操作元素) |
| default Stream parallelStream() | 返回一个并行流(并发的操作元素) |
@Test
public void test01(){List<Integer> list = Arrays.asList(1,2,3,4,5);// 返回一个顺序流Stream<Integer> stream1 = list.stream();// 返回一个并行流Stream<Integer> stream2 = list.parallelStream();List<Employee> employees = EmployeeData.getEmployees();// 返回一个顺序流Stream<Employee> stream = employees.stream();// 返回一个并行流Stream<Employee> employeeStream = employees.parallelStream();
}
方式二通过数组: Java8中的Arrays的静态方法stream()可以获取对应类型的Stream流
| 方法名 | 功能 |
|---|---|
| static Stream stream(T[] array) | 返回一个自定义类型的Stream流 |
| public static IntStream stream(int[] array) | 返回一个int类型的Stream流 |
| public static LongStream stream(long[] array) | 返回一个long类型的Stream流 |
| public static DoubleStream stream(double[] array) | 返回一个double类型的Stream流 |
@Test
public void test(){// 获取基本数据类型的Stream流int[] arr = {1,2,3,4,5};IntStream stream = Arrays.stream(arr);// 获取引用数据类型的Stram流String[] arr = {"hello","world"};Stream<String> stream = Arrays.stream(arr); // 获取自定义类型的Stream流Employee kyle = new Employee(9527, "Kyle");Employee lucy = new Employee(9421, "Lucy");Employee[] employees = {kyle, lucy};Stream<Employee> stream1 = Arrays.stream(employees);}
方式三通过指定具体数据: 调用Stream类静态方法of()创建一个流
| 方法名 | 功能 |
|---|---|
| public static Stream of(T… values) | 通过手动指定任意个数据创建一个流 |
@Test
public void test04(){Stream<Integer> stream = Stream.of(1,2,3,4,5);stream.forEach(System.out::println);
}
方式四调用Stream类的静态方法iterate()和generate()创建无限流(了解)
| 方法名 | 功能 |
|---|---|
| public static Stream iterate(final T seed, final UnaryOperator f) | 迭代 |
| public static Stream generate(Supplier s) | 生成 |
@Test
public void test() {// 从0开始迭代遍历10个数,没有limit限制会无限迭代Stream.iterate(0, t -> t + 1).limit(10).forEach(System.out::println);// 生成10个随机数,没有limit限制会无限生成Stream.generate(Math::random).limit(10).forEach(System.out::println);
}
中间操作筛选与切片
中间操作就是处理数据的具体操作,每次处理都会返回一个持有结果的新Stream,即中间操作的方法返回值仍然是Stream类型的对象
- 中间操作可以是个操作链可对数据源的数据进行n次处理(多个中间操作),但是所有的中间操作只有在执行终止操作时才会一次性全部处理(惰性求值)
- Stream流一旦执行了终止操作,就不能再次使用该Stream执行其它中间操作,需要根据数据源重新创建一个新的Stream流
| 方 法 | 描 述 |
|---|---|
| filter(Predicatep) | 接收Lambda表达式然后从流中排除某些元素 |
| distinct() | 筛选通过流所生成元素的 hashCode() 和 equals() 去除重复元素 |
| limit(long maxSize) | 截断流使其元素不超过给定数量 |
| skip(long n) | 跳过元素返回一个扔掉了前 n个元素的流 若流中元素不足n个则返回一个空流,与 limit(n) 互补 |
@Test
public void test() {List<Employee> employees = EmployeeData.getEmployees();//1. 查询工资大于7000的员工信息employees.stream().filter(employee -> employee.getSalary() > 7000).forEach(System.out::println);System.out.println("----------------------------");//2. 只输出3条员工信息employees.stream().limit(3).forEach(System.out::println);System.out.println("----------------------------");//3. 跳过前3个元素employees.stream().skip(3).forEach(System.out::println);System.out.println("----------------------------");//4. 通过流所生成元素的hashCode和equals方法去除重复元素employees.add(new Employee(9527, "Kyle", 20, 9999));employees.add(new Employee(9527, "Kyle", 20, 9999));employees.stream().distinct().forEach(System.out::println);
}
/*
Employee{id=1002, name='马云', age=12, salary=9876.12}
Employee{id=1004, name='雷军', age=26, salary=7657.37}
Employee{id=1006, name='比尔盖茨', age=42, salary=9500.43}
----------------------------
Employee{id=1001, name='马化腾', age=34, salary=6000.38}
Employee{id=1002, name='马云', age=12, salary=9876.12}
Employee{id=1003, name='刘强东', age=33, salary=3000.82}
----------------------------
Employee{id=1004, name='雷军', age=26, salary=7657.37}
Employee{id=1005, name='李彦宏', age=65, salary=5555.32}
Employee{id=1006, name='比尔盖茨', age=42, salary=9500.43}
Employee{id=1007, name='任正非', age=26, salary=4333.32}
Employee{id=1008, name='扎克伯格', age=35, salary=2500.32}
----------------------------
Employee{id=1001, name='马化腾', age=34, salary=6000.38}
Employee{id=1002, name='马云', age=12, salary=9876.12}
Employee{id=1003, name='刘强东', age=33, salary=3000.82}
Employee{id=1004, name='雷军', age=26, salary=7657.37}
Employee{id=1005, name='李彦宏', age=65, salary=5555.32}
Employee{id=1006, name='比尔盖茨', age=42, salary=9500.43}
Employee{id=1007, name='任正非', age=26, salary=4333.32}
Employee{id=1008, name='扎克伯格', age=35, salary=2500.32}
Employee{id=9527, name='Kyle', age=20, salary=9999.0}
*/
中间操作映射新的Stream
| 方法 | 描述 |
|---|---|
| map(Function f) | 接收一个函数作为参数,该函数会被应用到每个元素上并将其映射成一个新的元素(将元素转换成其他形式或提取信息) |
| mapToDouble(ToDoubleFunction f) | 接收一个函数作为参数,该函数会被应用到每个元素上产生一个新的 DoubleStream |
| mapToInt(ToIntFunction f) | 接收一个函数作为参数,该函数会被应用到每个元素上产生一个新的 IntStream |
| mapToLong(ToLongFunction f) | 接收一个函数作为参数,该函数会被应用到每个元素上产生一个新的 LongStream |
| flatMap(Function f) | 接收一个函数作为参数,将流中的每个值都换成另一个流然后把所有流连接成一个流, |
map和flatMap的区别: map方法最终会得到一个含有多个Stream实例的Stream,flatMap最终会得到一个含有多个元素的Stream
@Test
public void test() {ArrayList list1 = new ArrayList();list1.add(1);list1.add(2);list1.add(3);ArrayList list2 = new ArrayList();list2.add(1);list2.add(2);list2.add(3);// 集合中有4个元素,[1,2,3,[4,5,6]],类似maplist1.add(list2);// 集合中有6个元素,[1,2,3,4,5,6],类似flatMaplist1.addAll(list2);System.out.println(list1);
}
public class LambdaTest{@Testpublic void test() {List<String> strings = Arrays.asList("aa", "bb", "cc", "dd");List<Employee> employees = EmployeeData.getEmployees();// 将集合所有元素转为大写并输出strings.stream().map(s -> s.toUpperCase()).forEach(System.out::println);System.out.println("--------------------------");// 获取员工姓名长度大于3的员工的姓名employees.stream().map(Employee::getName).// 过滤出name长度>3的员工filter(name -> name.length() > 3).// 遍历输出forEach(System.out::println);System.out.println("--------------------------");// 使用map将字符串中的多个字符构成的集合转换为对应的Stream实例,然后再获取每一个Stream中的元素strings.stream().map(LambdaTest::formStringToStream).forEach(characterStream -> characterStream.forEach(System.out::println));// 使用flatMap可以直接获取Stream中Stream实例中的元素System.out.println("--------------------------");strings.stream().flatMap(LambdaTest::formStringToStream).forEach(System.out::println);}public static Stream<Character> formStringToStream(String str) {ArrayList<Character> list = new ArrayList<>();for (char c : str.toCharArray()) {list.add(c);}return list.stream();}}
/*
AA
BB
CC
DD
--------------------------
比尔盖茨
扎克伯格
--------------------------
a
a
b
b
c
c
d
d
--------------------------
*/
中间操作排序
| 方法 | 描述 |
|---|---|
| sorted() | 产生一个新流其中按自然顺序排序 |
| sorted(Comparator com) | 产生一个新流其中按比较器顺序排序 |
@Test
public void test20() {List<Integer> nums = Arrays.asList(13, 54, 97, 52, 43, 64, 27);List<Employee> employees = EmployeeData.getEmployees();//自然排序,如果要对employees自然排序就需要Employee类实现Comparable接口nums.stream().sorted().forEach(System.out::println);//定制排序,先按照年龄升序排,再按照工资降序排employees.stream().sorted((o1, o2) -> {int compare = Integer.compare(o1.getAge(), o2.getAge());if (compare != 0) {return compare;} else {return -Double.compare(o1.getSalary(), o2.getSalary());} }).forEach(System.out::println);
}/*
13
27
43
52
54
64
97
------------------
Employee{id=1002, name='马云', age=12, salary=9876.12}
Employee{id=1004, name='雷军', age=26, salary=7657.37}
Employee{id=1007, name='任正非', age=26, salary=4333.32}
Employee{id=1003, name='刘强东', age=33, salary=3000.82}
Employee{id=1001, name='马化腾', age=34, salary=6000.38}
Employee{id=1008, name='扎克伯格', age=35, salary=2500.32}
Employee{id=1006, name='比尔盖茨', age=42, salary=9500.43}
Employee{id=1005, name='李彦宏', age=65, salary=5555.32}
*/
终止操作匹配与查找
终端操作会从流的流水线生成结果,方法返回值类型就不再是Stream了可以是任何不是流的值(如List,Integer,void等)
- 流进行了终止操作后不能再次使用执行其他中间操作或终止操作
| 方法 | 描述 |
|---|---|
| allMatch(Predicate p) | 检查是否匹配所有元素 |
| anyMatch(Predicate p) | 检查是否至少匹配一个元素 |
| noneMatch(Predicate p) | 检查是否没有匹配所有元素 |
| findFirst() | 返回第一个元素 |
| findAny() | 返回当前流中的任意元素,顺序流会取第一个元素 |
| count() | 返回流中元素总数 |
| max(Comparator c) | 返回流中最大值 |
| min(Comparator c) | 返回流中最小值 |
| forEach(Consumer c) | 内部迭代(使用 Collection 接口需要用户去做迭代,称为外部迭代。 相反,Stream API 使用内部迭代——它帮你把迭代做了) |
@Test
public void test21(){List<Employee> employees = EmployeeData.getEmployees();// 练习:是否所有的员工的工资是否都大于5000System.out.println("是否所有的员工的工资是否都大于5000:"+employees.stream().allMatch(employee -> employee.getSalary() > 5000));// 练习:是否存在员工年龄小于15System.out.println("是否存在员工年龄小于15:"+employees.stream().anyMatch(employee -> employee.getAge() < 15));// 练习:是否不存在员工姓“马”System.out.println("是否不存在员工姓马:"+employees.stream().noneMatch(employee -> employee.getName().startsWith("马")));// 返回流中的第一个元素System.out.println("返回第一个元素:"+employees.stream().findFirst());// 返回当前流中的任意元素System.out.println("返回当前流中的任意元素"+employees.stream().findAny());// 返回流中元素的总个数(返回总个数前可以先过滤)System.out.println("返回元素总数:"+employees.stream().count());// 返回流中最高工资System.out.println("返回最高工资:"+employees.stream().map(Employee::getSalary).max(Double::compare));// 返回最低工资的员工System.out.println("返回最高工资:"+employees.stream().min(e1,e2 -> Double.compare(e1.getSalary(),e2.getSalary()));// 返回流中最小值System.out.println("返回最小年龄:"+employees.stream().map(Employee::getAge).min(Integer::compare));// 内部迭代employees.stream().forEach(System.out::println);System.out.println("-------------");// 使用集合的遍历操作employees.forEach(System.out::println);
}/*
是否所有的员工的工资是否都大于5000:false
是否存在员工年龄小于15:true
是否不存在员工姓马:false
返回第一个元素:Optional[Employee{id=1001, name='马化腾', age=34, salary=6000.38}]
返回当前流中的任意元素Optional[Employee{id=1001, name='马化腾', age=34, salary=6000.38}]
返回元素总数:8
返回最高工资:Optional[9876.12]
返回最小年龄:Optional[12]
Employee{id=1001, name='马化腾', age=34, salary=6000.38}
Employee{id=1002, name='马云', age=12, salary=9876.12}
Employee{id=1003, name='刘强东', age=33, salary=3000.82}
Employee{id=1004, name='雷军', age=26, salary=7657.37}
Employee{id=1005, name='李彦宏', age=65, salary=5555.32}
Employee{id=1006, name='比尔盖茨', age=42, salary=9500.43}
Employee{id=1007, name='任正非', age=26, salary=4333.32}
Employee{id=1008, name='扎克伯格', age=35, salary=2500.32}
-------------
Employee{id=1001, name='马化腾', age=34, salary=6000.38}
Employee{id=1002, name='马云', age=12, salary=9876.12}
Employee{id=1003, name='刘强东', age=33, salary=3000.82}
Employee{id=1004, name='雷军', age=26, salary=7657.37}
Employee{id=1005, name='李彦宏', age=65, salary=5555.32}
Employee{id=1006, name='比尔盖茨', age=42, salary=9500.43}
Employee{id=1007, name='任正非', age=26, salary=4333.32}
Employee{id=1008, name='扎克伯格', age=35, salary=2500.32}
*/
终止操作归约
map和reduce的连接通常称为map-reduce模式,因Google用它来进行网络搜索而出名
| 方法 | 描述 |
|---|---|
| reduce(T identity, BinaryOperator b) | 可以将流中元素反复结合起来返回一个值T |
| reduce(BinaryOperator b) | 可以将流中元素反复结合起来返回一个值Optional |
@Test
public void test22() {List<Integer> nums = Arrays.asList(13, 32, 23, 31, 94, 20, 77, 21, 17);List<Employee> employees = EmployeeData.getEmployees();// 练习1:计算1-10的自然数的和(0是初始值)System.out.println(nums.stream().reduce(0, Integer::sum));// 练习2:手动计算公司所有员工工资总和System.out.println(employees.stream().map(Employee::getSalary).reduce((o1, o2) -> o1 + o2));// 调用Integer的sum方法计算年龄总和System.out.println(employees.stream().map(Employee::getAge).reduce(Integer::sum));// 计算公司所有员工工资综合Stream<Double> salaryStream = employ.stream.map(Employee::getSalary);Optional<Double> sumMoney = salaryStream.reduce(Double::sum);System.out.println(sumMoney);
}
/*
328
Optional[48424.08]
Optional[273]
Optional[48424.08]
*/
终止操作收集
| 方 法 | 描 述 |
|---|---|
| collect(Collector c) | 接收一个Collector接口的实现将流转换为其他形式,用于给Stream中元素做汇总的方法 |
Collector接口中方法的实现决定了如何对流执行收集的操作(如收集到List、Set、Map),可以方便地创建常见收集器实例
| 方法 | 返回类型 | 作用 |
|---|---|---|
| toList | List | 把流中元素收集到List |
| List emps= list.stream().collect(Collectors.toList()); | ||
| toSet | List | 把流中元素收集到List |
| Set emps= list.stream().collect(Collectors.toSet()); | ||
| toCollection | Collection | 把流中元素收集到创建的集合 |
| Collection emps =list.stream().collect(Collectors.toCollection(ArrayList::new)); | ||
| counting | Long | 计算流中元素的个数 |
| long count = list.stream().collect(Collectors.counting()); | ||
| summinglnt | Integer | 对流中元素的整数属性求和 |
| int total=list.stream().collect(Collectors.summingInt(Employee::getSalary)); | ||
| averagingInt | Double | 计算流中元素Integer属性的平均值 |
| double avg = list.stream().collect(Collectors.averagingInt(Employee::getSalary)); | ||
| summarizinglnt | IntSummaryStatistics | 收集流中Integer属性的统计值。如:平均值 |
| int SummaryStatisticsiss=list.stream().collect(Collectors.summarizingInt(Employee::getSalary)); | ||
| joining | String | 连接流中每个字符串 |
| String str= list.stream().map(Employee::getName).collect(Collectors.joining()); | ||
| maxBy | Optional | 根据比较器选择最大值 |
| optionalmax=list.stream().collect(Collectors.maxBy(comparingInt(Employee::getSalary)); | ||
| minBy | Optional | 根据比较器选择最小值 |
| Optionalmin = list.stream().collect(Collectors.minBy(comparingInt(Employee::getSalary)); | ||
| reducing | 归约产生的类型 | 从一个作为累加器的初始值开始,利用BinaryOperator与流中元素逐个结合,从而归约成单个值 |
| int total=list.stream().collect(Collectors.reducing(0, Employe::getSalar, Integer::sum)); | ||
| collectingAndThen | 转换函数返回的类型 | 包裹另一个收集器,对其结果转换函数 |
| int how= list.stream().collect(Collectors.collectingAndThen(Collectors.toList(), List::size)); | ||
| groupingBy | Map<K, List> | 根据某属性值对流分组,属性为K,结果为V |
| Map<Emp.Status, List>map= list.stream().collect(Collectors.groupingBy(Employee::getStatus)); | ||
| partitioningBy | Map<Boolean,List> | 根据true或false进行分区 |
| Map<Boolean,List>vd=list.stream().collect(Collectors.partitioningBy(Employee::getManage)); |
@Test
public void test23() {// 练习1:查找工资大于6000的员工,结果返回为一个ListList<Employee> employees = EmployeeData.getEmployees();List<Employee> list = employees.stream().filter(employee -> employee.getSalary() > 6000).collect(Collectors.toList());list.forEach(System.out::println);System.out.println("--------------------");// 练习2:查找年龄大于20的员工,结果返回为一个Listemployees.add(new Employee(9527,"Kyle",21,9999));employees.add(new Employee(9527,"Kyle",21,9999));Set<Employee> set = employees.stream().filter(employee -> employee.getAge() > 20).collect(Collectors.toSet());set.forEach(System.out::println);
}/*
Employee{id=1001, name='马化腾', age=34, salary=6000.38}
Employee{id=1002, name='马云', age=12, salary=9876.12}
Employee{id=1004, name='雷军', age=26, salary=7657.37}
Employee{id=1006, name='比尔盖茨', age=42, salary=9500.43}
--------------------
Employee{id=1001, name='马化腾', age=34, salary=6000.38}
Employee{id=1007, name='任正非', age=26, salary=4333.32}
Employee{id=1008, name='扎克伯格', age=35, salary=2500.32}
Employee{id=1006, name='比尔盖茨', age=42, salary=9500.43}
Employee{id=1005, name='李彦宏', age=65, salary=5555.32}
Employee{id=1003, name='刘强东', age=33, salary=3000.82}
Employee{id=9527, name='Kyle', age=21, salary=9999.0}
Employee{id=1004, name='雷军', age=26, salary=7657.37}
*/
Optional类
空指针异常是导致Java应用程序失败的最常见原因,以前为了解决空指针异常Google公司著名的Guava项目引入了Optional类(通过检查空值的方式来防止代码污染)
受到Google Guava的启发Java 8也引入了java.util.Optional类,Optional类是一个可以为null的容器对象
- Optional类可以保存类型T的值代表这个值存在
- 以前用null表示一个值不存在,现在Optional类保存null表示这个值不存在可以避免空指针异常
创建Optional类
创建Optional类对象的方法
| 方法名 | 功能 |
|---|---|
| Optional.of(T t) | 创建一个Optional实例,t必须非空 |
| Optional.empty() | 创建一个空的Optional实例 |
| Optional.ofNullable(T t) | t可以为null |
准备实体类Boy和Girl
public class Boy {private Girl girl;public Boy() {}public Boy(Girl girl) {this.girl = girl;}@Overridepublic String toString() {return "Boy{" +"girl=" + girl +'}';}
}
public class Girl {private String name;public Girl() {}public Girl(String name) {this.name = name;}@Overridepublic String toString() {return "Girl{" +"name='" + name + '\'' +'}';}
}
@Test
public void test(){Girl girl = new Girl();// 如果girl等于null会报空指针异常Optional<Girl> optionalGirl = Optional.of(girl);
}@Test
public void test25(){Girl girl = new Girl();girl = null;// girl可以为nullOptional<Girl> optionalGirl = Optional.ofNullable(girl);// girl为null输出Optional.empty,girl不为null输出Optional[Girl{name="null"}]System.out.println(optionalGirl);// girl为null输出Girl{name="赵丽颖"},girl不为null输出Girl{name="null"}Girl girl1 = optionalGirl.orElse(new Girl("赵丽颖"));System.out.println(girl1);
}
使用Optional
判断Optional容器中是否包含对象
| 方法名 | 功能 |
|---|---|
| boolean isPresent() | 判断是否包含对象 |
| void ifPresent(Consumer<? super T> consumer) | 如果有值,就执行Consumer接口的实现代码,并且该值会作为参数传给它 |
获取Optional容器的对象
| 方法名 | 功能 |
|---|---|
| T get() | 如果调用对象包含值返回该值,否则抛异常 |
| T orElse(T other) | 如果有值(内部封装的t非空)则将其返回,否则返回指定的other对象 |
| T orElseGet(Supplier<? extends T> other) | 如果有值则将其返回,否则返回由Supplier接口实现提供的对象 |
| T orElseThrow(Supplier<? extends X> exceptionSupplier) | 如果有值则将其返回,否则抛出由Supplier接口实现提供的异常 |
@Test
public void test26(){Boy boy = new Boy();boy = null;// 此会出现空指针异常String girlName = getGirlName(boy);System.out.println(girlName);
}// 获取女孩的名字,容易出现空指针异常
private String getGirlName(Boy boy) {return boy.getGirl().getName();
}
@Test
public void test27(){Boy boy = new Boy();boy = null;String girlName = getGirlName1(boy);System.out.println(girlName);
}// 优化以后的getGirlName():
public String getGirlName1(Boy boy){if(boy != null){Girl girl = boy.getGirl();if(girl != null){return girl.getName();}}return null;
}
使用Optional类
@Test
public void test28(){// 樱岛麻衣Boy boy = null;// 喜多川海梦boy = new Boy();// Lucyboy = new Boy(new Girl("Lucy"));String girlName = getGirlName2(boy);System.out.println(girlName);
}//使用Optional类的getGirlName()
public String getGirlName2(Boy boy){Optional<Boy> boyOptional = Optional.ofNullable(boy);//此时的boy1一定非空Boy boy1 = boyOptional.orElse(new Boy(new Girl("樱岛麻衣")));Girl girl = boy1.getGirl();Optional<Girl> girlOptional = Optional.ofNullable(girl);//girl1一定非空Girl girl1 = girlOptional.orElse(new Girl("喜多川海梦"));return girl1.getName();
}
相关文章:
Stream API
Stream API执行流程 Stream API(java.util.stream)把真正的函数式编程风格引入到Java中,可以极大地提高程序员生产力,让程序员写出高效、简洁的代码 实际开发中项目中多数数据源都是来自MySQL、Oracle等关系型数据库,还有部分来自MongDB、Redis等非关系型数据库 …...

手写Spring:第3章-实现Bean的定义、注册、获取
文章目录 一、目标:实现Bean的定义、注册、获取二、设计:实现Bean的定义、注册、获取三、实现:实现Bean的定义、注册、获取3.1 工程结构3.2 实现Bean的定义、注册、获取类图3.3 定义Bean异常3.4 BeanDefinition定义和注册3.4.1 BeanDefinitio…...

这些国外客户真直接
最近在某平台上遇到的客户,很大一部分都是非英语国家的客户,然而他们也有很多共性的习惯。 第一种:直接表达自己对这个产品感兴趣,然后接下来就没有下文了,而之所以可以看得懂,则是借助平台本身的翻译系统&…...
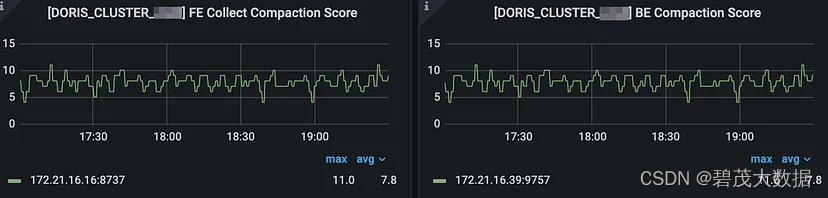
使用Apache Doris自动同步整个 MySQL/Oracle 数据库进行数据分析
Flink-Doris-Connector 1.4.0 允许用户一步将包含数千个表的整个数据库(MySQL或Oracle )摄取到Apache Doris(一种实时分析数据库)中。 通过内置的Flink CDC,连接器可以直接将上游源的表模式和数据同步到Apache Doris&…...
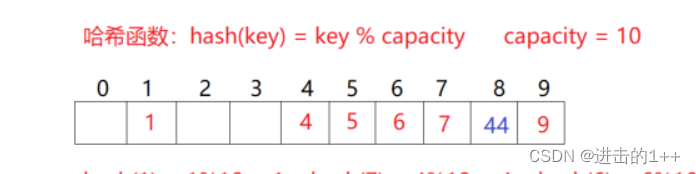
【1++的数据结构】之哈希(一)
👍作者主页:进击的1 🤩 专栏链接:【1的数据结构】 文章目录 一,什么是哈希?二,哈希冲突哈希函数哈希冲突解决 unordered_map与unordered_set 一,什么是哈希? 首先我们要…...
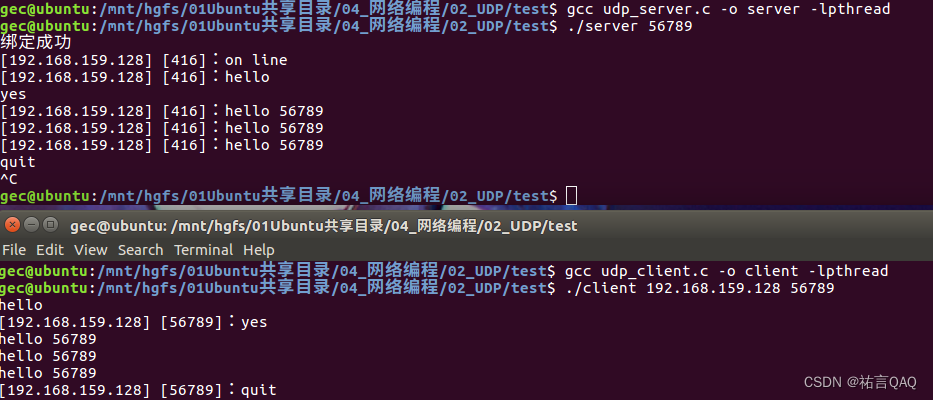
【网络编程】深入了解UDP协议:快速数据传输的利器
(꒪ꇴ꒪ ),Hello我是祐言QAQ我的博客主页:C/C语言,数据结构,Linux基础,ARM开发板,网络编程等领域UP🌍快上🚘,一起学习,让我们成为一个强大的攻城狮࿰…...
WordPress(5)在主题中添加文章字数和预计阅读时间
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 样式图一、添加位置二、找到主题文件样式图 提示:以下是本篇文章正文内容,下面案例可供参考 一、添加位置 二、找到主题文件 在主题目录下functions.php文件把下面的代码添加进去: // 文章字数…...
STM32WB55开发(1)----套件概述
STM32WB55开发----1.套件概述 所用器件视频教学样品申请优势支持协议系统控制和生态系统访问功能示意图系统框图跳线设置开发板原理图 所用器件 所使用的器件是我们自行设计的开发板,该开发板是基于 STM32WB55 系列微控制器所构建。STM32WBXX_VFQFPN68 不仅是一款评…...

CUDA相关知识科普
显卡 显卡(Video card,Graphics card)全称显示接口卡,又称显示适配器,是计算机最基本配置、最重要的配件之一。就像电脑联网需要网卡,主机里的数据要显示在屏幕上就需要显卡。因此,显卡是电脑进…...

恒运资本:总市值和总资产区别?
总市值和总财物是财政术语中经常被提到的两个概念,很多人会将它们混淆。在金融领域中,了解这两个概念的差异十分重要。本文将从多个视点深入分析总市值和总财物的差异。 1.定义 总市值是指公司发行的一切股票的商场总价值。所谓商场总价值…...

CTF安全竞赛介绍
目录 一、赛事简介 二、CTF方向简介 1.Web(Web安全) (1)简介 (2)涉及主要知识 2.MISC(安全杂项) (1)介绍 (2)涉及主要知识 3…...

DC/DC开关电源学习笔记(四)开关电源电路主要器件及技术动态
(四)开关电源电路主要器件及技术动态 1.半导体器件2.变压器3.电容器4.功率二极管5.其他常用元件5.1 电阻5.2 电容5.3 电感5.4 变压器5.5 二极管5.6 整流桥5.7 稳压管5.8 绝缘栅-双极性晶体管1.半导体器件 功率半导体器件仍然是电力电子技术发展的龙头, 电力电子技术的进步必…...
数据可视化与数字孪生:理解两者的区别
在数字化时代,数据技术正在引领创新,其中数据可视化和数字孪生是两个备受关注的概念。尽管它们都涉及数据的应用,但在本质和应用方面存在显著区别。本文带大探讨数据可视化与数字孪生的差异。 概念 数据可视化: 数据可视化是将复…...
)
C++ socket编程(TCP)
服务端保持监听客户端, 服务端采用select实现,可以监听多个客户端 客户端源码 在这里插入代码片 #include <iostream> //#include <windows.h> #include <WinSock2.h> #include <WS2tcpip.h> using namespace std; #pragma co…...

ldd用于打印程序或库文件所依赖的共享库列表
这是一个Linux命令行指令,将两个常用的命令 ldd 和 grep 组合使用。我来逐一为您解释: ldd: 这是一个Linux工具,用于打印程序或库文件所依赖的共享库列表。通常,当你有一个可执行文件并且想知道它链接到哪些动态库时,你…...
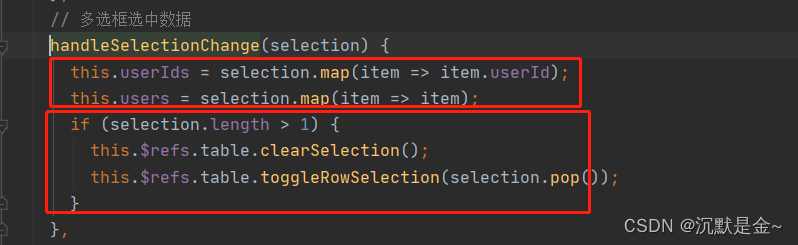
vue+elementUI el-table实现单选
if (selection.length > 1) {this.$refs.table.clearSelection();this.$refs.table.toggleRowSelection(selection.pop());}...
前端组件库造轮子——Message组件开发教程
前端组件库造轮子——Message组件开发教程 前言 本系列旨在记录前端组件库开发经验,我们的组件库项目目前已在Github开源,下面是项目的部分组件。文章会详细介绍一些造组件库轮子的技巧并且最后会给出完整的演示demo。 文章旨在总结经验,开…...
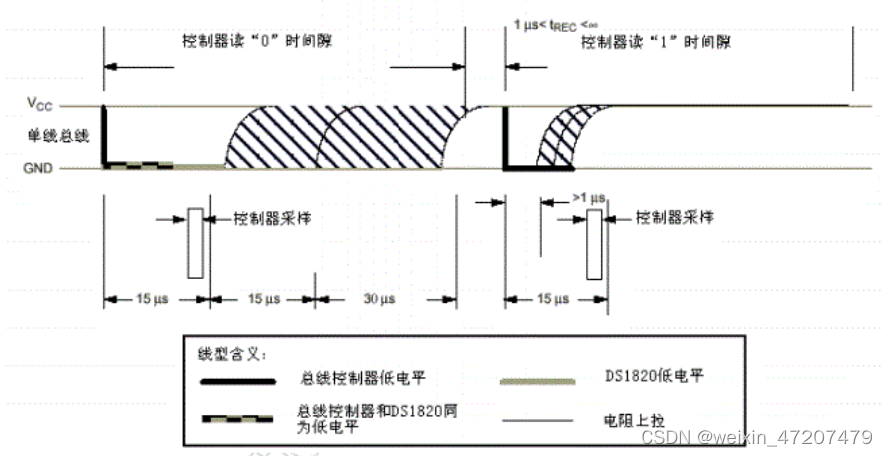
单片机第二季:温度传感器DS18B20
目录 1,DS18B20介绍 2,DS18B20数据手册 2.1,初始化时序 2.2,读写时序 3,DS18B20工作流程 4,代码 1,DS18B20介绍 DS18B20的基本特征: (1)内置集成ADC,外部数字接…...

抓包工具fiddler的基础知识
目录 简介 1、作用 2、使用场景 3、http报文分析 3.1、请求报文 3.2、响应报文 4、介绍fiddler界面功能 4.1、AutoResponder(自动响应器) 4.2、Composer(设计请求) 4.3、断点 4.4、弱网测试 5、app抓包 简介 fiddler是位于客户端和服务端之间的http代理 1、作用 监控浏…...

监控基本概念
监控:这个词在不同的上下文中有不同的含义,在讲到监控MySQL或者监控Redis时,这里只涉及数据采集和可视化,不涉及告警引擎和事件处理。要是监控系统的话,不但包括数据采集和可视化,而且也包括告警和事件发送…...
详解)
后进先出(LIFO)详解
LIFO 是 Last In, First Out 的缩写,中文译为后进先出。这是一种数据结构的工作原则,类似于一摞盘子或一叠书本: 最后放进去的元素最先出来 -想象往筒状容器里放盘子: (1)你放进的最后一个盘子(…...

挑战杯推荐项目
“人工智能”创意赛 - 智能艺术创作助手:借助大模型技术,开发能根据用户输入的主题、风格等要求,生成绘画、音乐、文学作品等多种形式艺术创作灵感或初稿的应用,帮助艺术家和创意爱好者激发创意、提高创作效率。 - 个性化梦境…...

业务系统对接大模型的基础方案:架构设计与关键步骤
业务系统对接大模型:架构设计与关键步骤 在当今数字化转型的浪潮中,大语言模型(LLM)已成为企业提升业务效率和创新能力的关键技术之一。将大模型集成到业务系统中,不仅可以优化用户体验,还能为业务决策提供…...
)
论文解读:交大港大上海AI Lab开源论文 | 宇树机器人多姿态起立控制强化学习框架(二)
HoST框架核心实现方法详解 - 论文深度解读(第二部分) 《Learning Humanoid Standing-up Control across Diverse Postures》 系列文章: 论文深度解读 + 算法与代码分析(二) 作者机构: 上海AI Lab, 上海交通大学, 香港大学, 浙江大学, 香港中文大学 论文主题: 人形机器人…...

简易版抽奖活动的设计技术方案
1.前言 本技术方案旨在设计一套完整且可靠的抽奖活动逻辑,确保抽奖活动能够公平、公正、公开地进行,同时满足高并发访问、数据安全存储与高效处理等需求,为用户提供流畅的抽奖体验,助力业务顺利开展。本方案将涵盖抽奖活动的整体架构设计、核心流程逻辑、关键功能实现以及…...

Xshell远程连接Kali(默认 | 私钥)Note版
前言:xshell远程连接,私钥连接和常规默认连接 任务一 开启ssh服务 service ssh status //查看ssh服务状态 service ssh start //开启ssh服务 update-rc.d ssh enable //开启自启动ssh服务 任务二 修改配置文件 vi /etc/ssh/ssh_config //第一…...

《从零掌握MIPI CSI-2: 协议精解与FPGA摄像头开发实战》-- CSI-2 协议详细解析 (一)
CSI-2 协议详细解析 (一) 1. CSI-2层定义(CSI-2 Layer Definitions) 分层结构 :CSI-2协议分为6层: 物理层(PHY Layer) : 定义电气特性、时钟机制和传输介质(导线&#…...

IT供电系统绝缘监测及故障定位解决方案
随着新能源的快速发展,光伏电站、储能系统及充电设备已广泛应用于现代能源网络。在光伏领域,IT供电系统凭借其持续供电性好、安全性高等优势成为光伏首选,但在长期运行中,例如老化、潮湿、隐裂、机械损伤等问题会影响光伏板绝缘层…...
可以参考以下方法:)
根据万维钢·精英日课6的内容,使用AI(2025)可以参考以下方法:
根据万维钢精英日课6的内容,使用AI(2025)可以参考以下方法: 四个洞见 模型已经比人聪明:以ChatGPT o3为代表的AI非常强大,能运用高级理论解释道理、引用最新学术论文,生成对顶尖科学家都有用的…...

【数据分析】R版IntelliGenes用于生物标志物发现的可解释机器学习
禁止商业或二改转载,仅供自学使用,侵权必究,如需截取部分内容请后台联系作者! 文章目录 介绍流程步骤1. 输入数据2. 特征选择3. 模型训练4. I-Genes 评分计算5. 输出结果 IntelliGenesR 安装包1. 特征选择2. 模型训练和评估3. I-Genes 评分计…...