JDK源码剖析之PriorityQueue优先级队列
写在前面
版本信息:
JDK1.8
PriorityQueue介绍
在数据结构中,队列分为FIFO、LIFO 两种模型,分别为先进先出,后进后出、先进后出,后进先出(栈) 而一切数据结构都是基于数组或者是链表实现。
在Java中,定义了Queue接口,接口中定义了CRUD的基本方法。分别add、offer、remove、poll等等,而PriorityQueue 实现此接口实现了基本的CRUD的同时拥有了自己的特性,从名字来看也能知道是优先级队列 : 保持队列头部节点是整条队列中永远是最小或者最大的节点,其实现原理就是一个小顶堆或者大顶堆。上文提及到一切数据结构都是基于数组或者是链表实现,而这里使用了数组实现。
public class PriorityQueue<E> extends AbstractQueue<E>implements java.io.Serializable {transient Object[] queue; // 由数组实现
}public abstract class AbstractQueue<E>extends AbstractCollection<E>implements Queue<E> {}小顶堆和大顶堆介绍
从上文描述了PriorityQueue的底层实现是小顶堆或者大顶堆,那么在看源码之前,我们需要先明白小顶堆和大顶堆如何实现~
小顶堆:一颗完全二叉树,其中任意父节点都要小于左右子节点,所以树的根节点是整棵树的最小节点
大顶堆:一颗完全二叉树,其中任意父节点都要大于左右子节点,所以树的根节点是整棵树的最大节点

Comparable和Comparator区别
在看PriorityQueue源码之前还需要分析Comparable和Comparator区别。
Comparable:类需要实现此接口,重写compareTo方法,在compareTo方法中定义比较逻辑,使用时把类强转成Comparable调用compareTo方法,把比较对象传入。所以侵入性比较强,与业务代码强耦合。
Comparator:这个就是一个比较器,只需要把A比较对象和B比较对象都传入即可,不需要于业务代码强耦合
PriorityQueue添加元素源码分析
下文直接把PriorityQueue叫成小顶堆
我们直接从offer方法入手~
public boolean offer(E e) {if (e == null)throw new NullPointerException();modCount++; // 用于检测是否并发// 因为size从0开始,所以size的值就是数组的索引值。int i = size;// 是否需要扩容if (i >= queue.length)grow(i + 1); // 为下次索引+1size = i + 1;// 如果是第一个,那么就直接占用数组第一个元素即可,// 因为不管是小顶堆还是大堆堆第一个都直接插入。if (i == 0)queue[0] = e;else// 非第一个节点,此时就需要调整siftUp(i, e);return true;
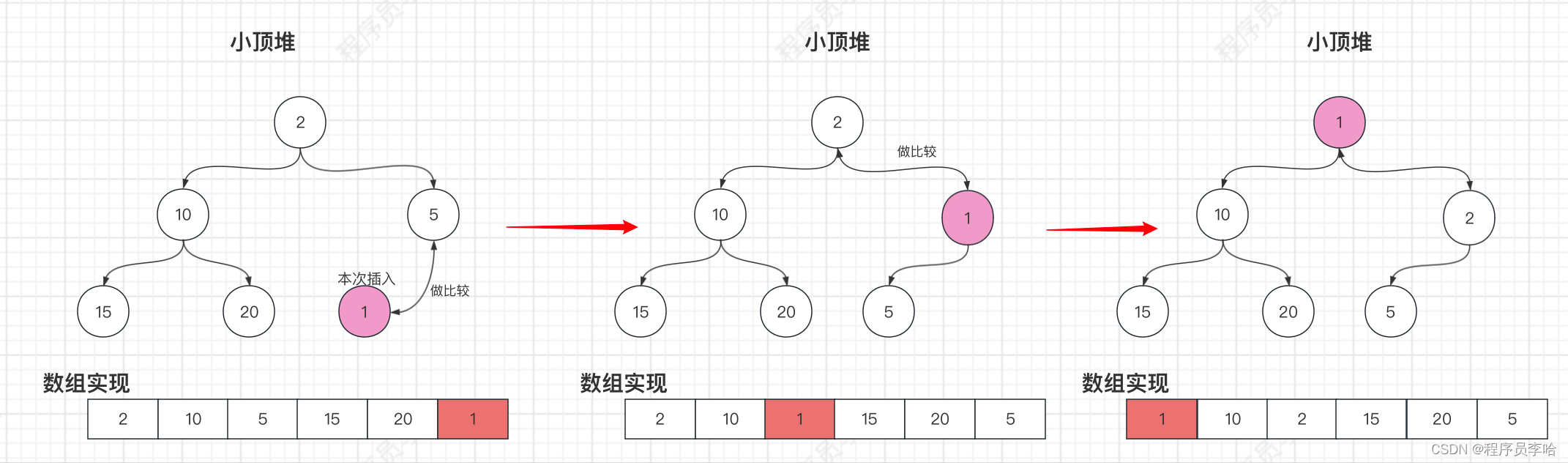
}这里的逻辑比较简单,因为这里使用数组实现的小顶堆(也即使用数组实现完全二叉树),而小顶堆的第一个节点是最小的,所以当0索引直接插入即可,非0索引就需要调整小顶堆。这里应该有很多读者是第一次见数组实现二叉树,所以这里把上文的二叉树进行扩展,把数组部分画上去。

在看 siftUp调整方法前,我们看一下grow扩容方法, 因为里面有一个思路大家可以学习~
private void grow(int minCapacity) {int oldCapacity = queue.length;// 容量小于64时,扩容为 oldCapacity + oldCapacity +2 // 容量大于64,扩容为 oldCapacity + oldCapacity/2// 等同于,在容量小的时候,每次扩容大一些,当达到64这个阈值后,扩容小一些,要不然空间会太浪费了~int newCapacity = oldCapacity + ((oldCapacity < 64) ?(oldCapacity + 2) :(oldCapacity >> 1));if (newCapacity - MAX_ARRAY_SIZE > 0)newCapacity = hugeCapacity(minCapacity);// 数组拷贝迁移。queue = Arrays.copyOf(queue, newCapacity);
}
在每次扩容的时候,会去判断,当前容量是否大于64,如果小于64就直接 原大小 * 2 + 2 扩容,如果大于64以后直接 原大小 + 原大小/2 扩容。目的是为了在容量小的时候扩容大一些,减少扩容次数。在容量达到64阈值后,扩容小一些,减少内存浪费。
下面开始讲解siftUp调整方法
private void siftUp(int k, E x) {// 用户是否传入comparator比较器if (comparator != null)siftUpUsingComparator(k, x);else// 没传入就使用Comparable// 此时类需要实现Comparable接口siftUpComparable(k, x);
}这里讲解siftUpComparable方法,本质上两个方法没任何区别~
private void siftUpComparable(int k, E x) {Comparable<? super E> key = (Comparable<? super E>) x;while (k > 0) {// 拿到父节点// 因为是使用数组实现的一颗完全二叉树,所以直接-1 右移即可拿到当前插入节点的父节点int parent = (k - 1) >>> 1;Object e = queue[parent];// 与父节点做比较。if (key.compareTo((E) e) >= 0)// 达到用户的预期比较就直接break,要不然继续往父节点的父节点继续做比较,直到根节点break;// 没达到预期,所以把父节点插入到本次插入的节点的位置。queue[k] = e;// 拿到父节点的索引,继续往父节点的父节点做比较。k = parent;}// 插入queue[k] = key;
}这里光看注释,肯定是看不明白的,所以以画图+注释来理解吧~
PriorityQueue获取元素源码分析
直接从poll方法入手~
public E poll() {if (size == 0)return null;// 拿到最后一个节点的索引值。int s = --size;modCount++;// 因为第一个是小顶堆或者大顶堆要的数据。E result = (E) queue[0];// 拿到最后一节点E x = (E) queue[s];queue[s] = null; // help gcif (s != 0)// 调整siftDown(0, x);return result;
}因为小顶堆或者大顶堆都是拿第一个元素,所以这里拿出第一个元素。但是每次拿完就需要调整小顶堆(调整完全二叉树),所以看到siftDown方法。
private void siftDown(int k, E x) {if (comparator != null)siftDownUsingComparator(k, x);elsesiftDownComparable(k, x);
}本质上这两个方法没任何区别,所以继续看到siftDownComparable方法
// k为0
// x是最后一个节点。
private void siftDownComparable(int k, E x) {Comparable<? super E> key = (Comparable<? super E>)x;// 循环的次数// 是通过数组的大小 右移一位就可以知道树高了。int half = size >>> 1; while (k < half) {// 往下层找。int child = (k << 1) + 1; Object c = queue[child]; // 左子节点int right = child + 1; // 右子节点// 左右子节点比较,那个满足规范就作为父节点if (right < size &&((Comparable<? super E>) c).compareTo((E) queue[right]) > 0)// 右节点满足于左节点c = queue[child = right];// 与最后一个节点比较后,达到预期直接退出if (key.compareTo((E) c) <= 0)break;// 替换queue[k] = c;// 下次循环的父节点k = child;}queue[k] = key;
}因为每次poll取走的是第一个元素,所以需要调整整个小顶堆,而第一个元素是小顶堆的根节点,所以需要调整小顶堆找到一个符合的元素作为根节点。从根节点的左右子节点开始比较,左右子节点比较出预期的节点就作为新的根节点。预期的节点作为下次比较的父节点,通过父节点再找到他的左右子节点做比较,周而复始,直到最后一个节点。
这里光看注释,肯定是看不明白的,所以以画图+注释来理解吧~

相关文章:
JDK源码剖析之PriorityQueue优先级队列
写在前面 版本信息: JDK1.8 PriorityQueue介绍 在数据结构中,队列分为FIFO、LIFO 两种模型,分别为先进先出,后进后出、先进后出,后进先出(栈) 而一切数据结构都是基于数组或者是链表实现。 在…...

TSINGSEE青犀AI视频分析/边缘计算/AI算法·人脸识别功能——多场景高效运用
旭帆科技AI智能分析网关可提供海量算法供应,涵盖目标监测、分析、抓拍、动作分析、AI识别等,可应用于各行各业的视觉场景中。同时针对小众化场景可快速定制AI算法,主动适配大厂近百款芯片,打通云/边/端灵活部署,算法一…...
算法_C++——最大连续 1 的个数 III)
力扣(LeetCode)算法_C++——最大连续 1 的个数 III
给定一个二进制数组 nums 和一个整数 k,如果可以翻转最多 k 个 0 ,则返回 数组中连续 1 的最大个数 。 示例 1: 输入:nums [1,1,1,0,0,0,1,1,1,1,0], K 2 输出:6 解释:[1,1,1,0,0,1,1,1,1,1,1] 粗体数字…...

23062C++QT day2
封装一个结构体,结构体中包含一个私有数组,用来存放学生的成绩,包含一个私有变量,用来记录学生个数, 提供一个公有成员函数,void setNum(int num)用于设置学生个数 提供一个公有成员函数:void…...

React三属性之:props
作用 将父组件的参数传递给子组件 父组件 import ./App.css; import React from react; import PropsTest from ./pages/propsTest class App extends React.Component{render(){return(<div><h2>App组件</h2><PropsTest obj{{name:王惊涛,age:27}}>…...

大数据安全 | (一)介绍
目录 📚大数据安全 🐇大数据安全内涵 🐇大数据安全威胁 🐇保障大数据安全 ⭐️采集环节安全技术 ⭐️存储环节安全技术 ⭐️挖掘环节安全技术 ⭐️发布环节安全技术 🐇大数据用于安全 📚隐私及其…...

软件工程的概念及其重要性
软件工程是指将工程原理和方法应用于软件开发过程的学科,涉及软件的设计、开发、测试、维护和管理等各个阶段。它旨在提高软件开发的效率和质量,并确保软件满足用户的需求和预期。 软件工程的重要性体现在以下几个方面: 提高开发效率&#x…...
[足式机器人]Part3 变分法Ch01-2 数学预备知识——【读书笔记】
本文仅供学习使用 本文参考: 《变分法基础-第三版》老大中 《变分学讲义》张恭庆 《Calculus of Variations of Optimal Control Theory》-变分法和最优控制论-Daneil Liberzon Ch01-2 数学基础-预备知识1 1.3.2 向量场的通量和散度1.3.3 高斯定理与格林公式 1.3.2 …...

【嵌入式开发 Linux 常用命令系列 7.1 -- awk 过滤列中含有特定字符的行】
文章目录 awk 过滤列中字符串 上篇文章:嵌入式开发 Linux 常用命令系列 7 – awk 常用方法详细介绍 awk 过滤列中字符串 cat test.log | awk -F $31 {print $0}说明: -F 以什么分隔列,这里是以空格为分隔符;$3代表第3列;$3…...

前端(十六)——Web应用的安全性研究
🙂博主:小猫娃来啦 🙂文章核心:Web应用的安全性研究 文章目录 概述常见前端安全漏洞XSS(跨站脚本攻击)CSRF(跨站请求伪造) 点击劫持安全性验证与授权用户身份验证授权与权限管理 安全…...

无涯教程-JavaScript - BIN2HEX函数
描述 BIN2HEX函数将二进制数转换为十六进制。 语法 BIN2HEX (number, [places])争论 Argument描述Required/Optionalnumber 您要转换的二进制数。 数字不能超过10个字符(10位)。数字的最高有效位是符号位。其余的9位是幅度位。 负数使用二进制补码表示。 Requiredplaces 要…...
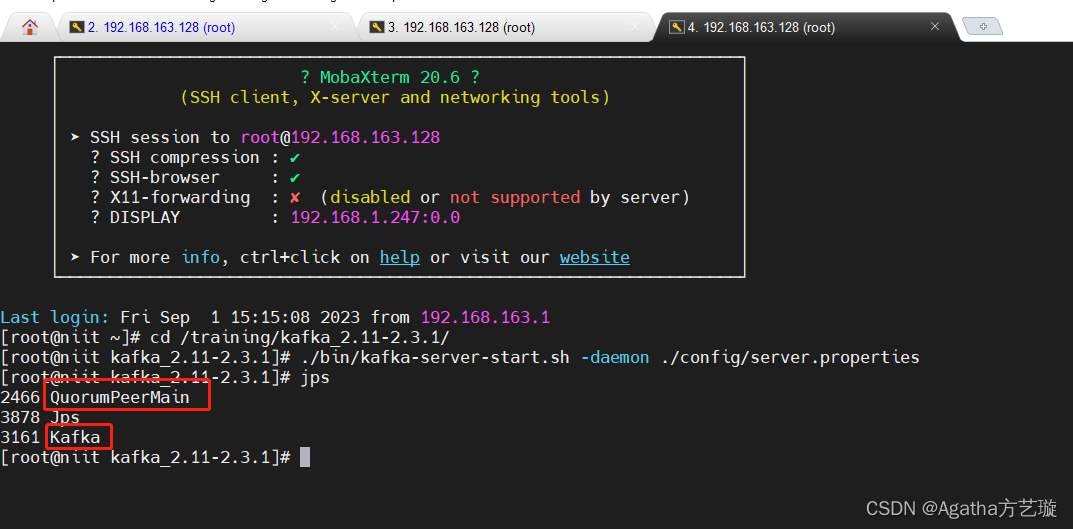
Kafka环境搭建与相关启动命令
一、Kafka环境搭建 点击下载kafka_2.11-2.3.1.tgz文件链接 1、上传kafka_2.11-2.3.1.tgz,解压kafka_2.11-2.3.1.tgz,得到kafka_2.11-2.3.1文件夹 1)上传 #使用mobaxterm将 kafka_2.11-2.3.1.tgz 传入tools文件夹 #用下面代码进入tools文件…...
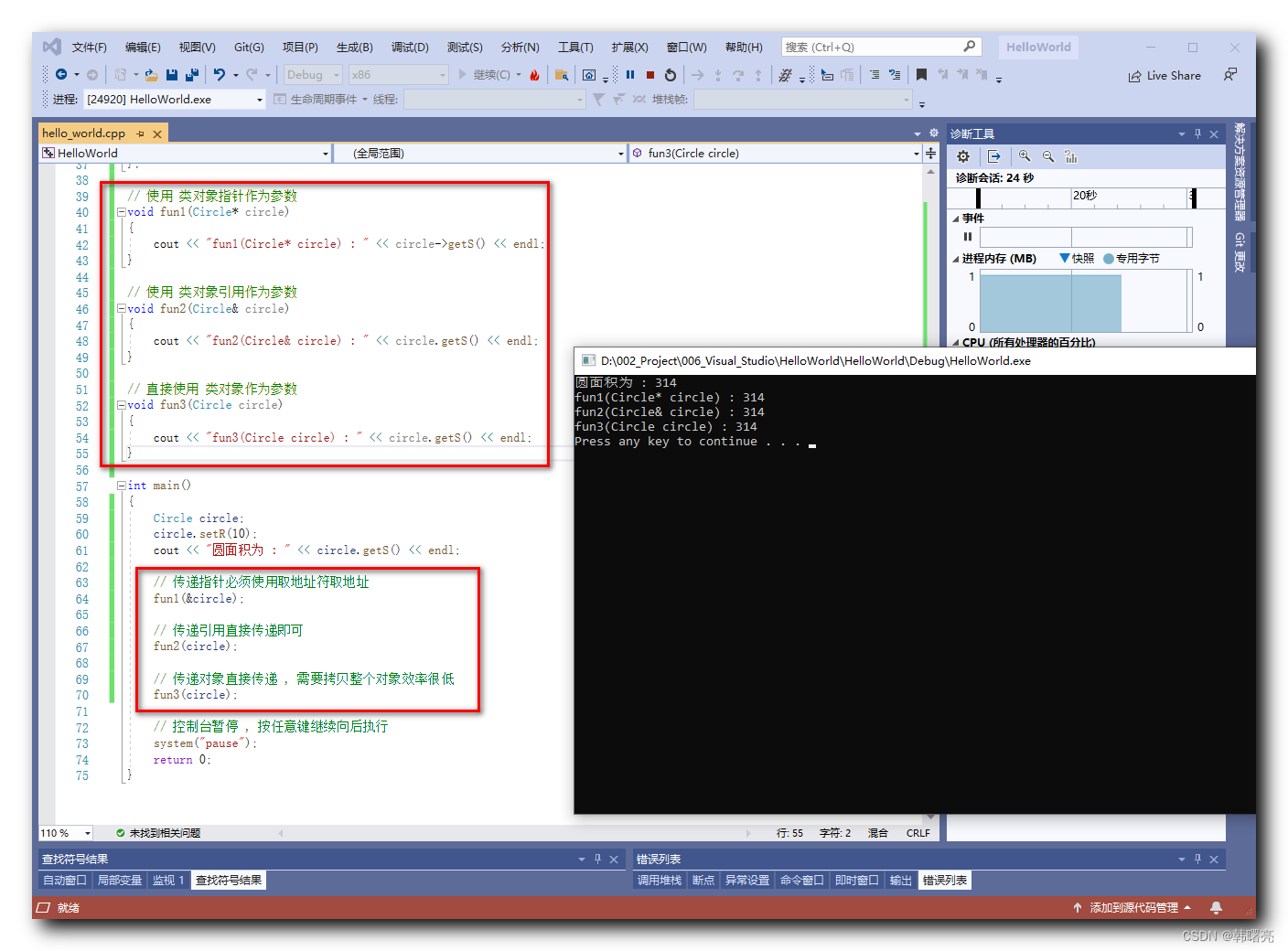
【C++】类的封装 ② ( 封装最基本的表层概念 | 类对象作为参数传递的几种情况 )
文章目录 一、类的封装 : 将数据和方法封装到一个类中1、封装最基本的表层概念2、代码分析 - 基本封装3、代码分析 - 类对象作为参数传递的几种情况 ( 指针 / 引用 / 直接 )4、完整代码示例 一、类的封装 : 将数据和方法封装到一个类中 1、封装最基本的表层概念 将数据和方法封…...

Linux上安装FTP
1、登录FTP,执行安装命令 yum -y install vsftpd 2、启动FTP服务器,设置开启自启动 systemctl enable vsftpd.service systemctl start vsftpd.service systemctl status vsftpd.service #查看状态, 显示active说明FTP启动成功 3、修改FTP配置文件/et…...
)
C/C++使用GDAL库编程窍门之——通用可移植性库(Common Portability Library, CPL)
C/C使用GDAL库编程窍门之——通用可移植性库(Common Portability Library, CPL) CPL简介 GDAL全称地理空间数据抽象库(Geospatial Data Abstraction Library),是一个强大的地理栅格空间数据转换库,支持众…...
 宏定义)
Linux container_of() 宏定义
container_of 宏 今天遇到了一段这样的代码,大致意思是 通过该struct结构体变量的成员的地址来反推该struct结构体变量的地址 并且用到了内核的宏,container_of() static inline struct nova_inode_info *NOVA_I(struct inode *inode) {return container…...

详解python中的序列类型---列表list
概述 列表类型是包含0个或多个元素的有序序列,属于序列类型。列表可以进行元素的增加、删除、替换、查找等操作。列表没有长度限制,无素类型可以不同,不需要预定长度。 列表类型用中括号[]表示,也可以通过list(x)函数将集合或字…...

Unity 引擎中国版 “团结引擎” 发布
导读Unity 官方宣布,Unity 中国正式推出 Unity 中国版引擎 —— 团结引擎,同时也开启了 Unity 中国本土化进程的全新篇章。作为推动团结引擎落地的核心人物,Unity 中国 CEO 张俊波称致力于将其打造为一款更懂中国开发者的引擎。 团结引擎以 U…...
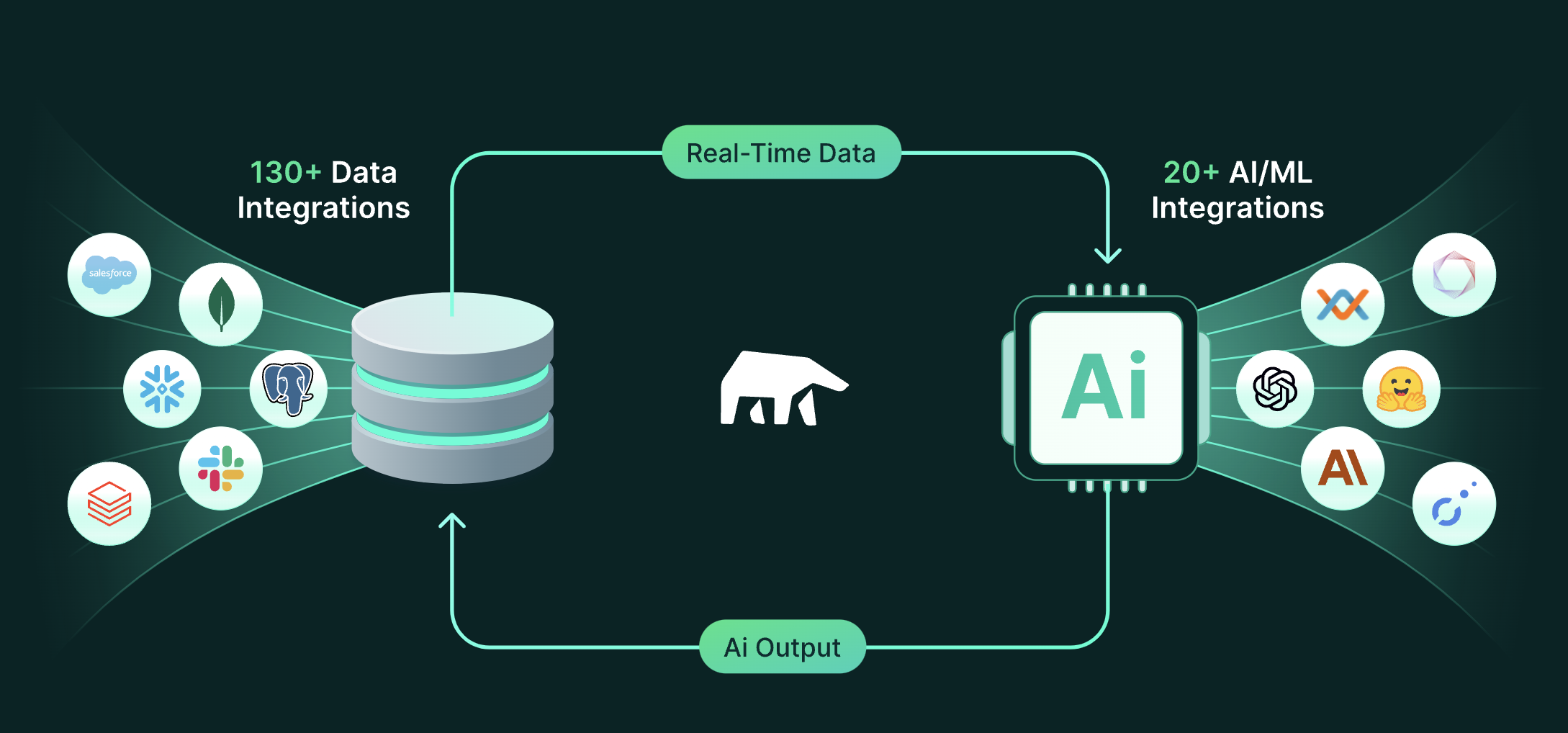
MindsDB为许多不支持内置机器学习的数据库带来了机器学习功能
选择平台的首要原则是“靠近数据”,让代码靠近数据是保持低延迟的必要条件。 机器学习,特别是深度学习往往会多次遍历所有数据(遍历一次被称为一个epoch)。对于非常大的数据集来说,理想的情况是在存储数据的地方建立模型,这样就不需要大量的数据传输。目前已经有部分数据…...

世界级黑客丨电脑犯罪界的汉尼拔
被美国FBI称为电脑界的汉尼拔的人,有什么样的故事? 这个人就是世界级黑客凯文李波尔森,他在早期是正儿八经的黑客,他在17岁的时候就使用TRS-80电脑攻入美国国防部的高等研究计划署网络,但是当时他进去啥也没干&#x…...

Flask RESTful 示例
目录 1. 环境准备2. 安装依赖3. 修改main.py4. 运行应用5. API使用示例获取所有任务获取单个任务创建新任务更新任务删除任务 中文乱码问题: 下面创建一个简单的Flask RESTful API示例。首先,我们需要创建环境,安装必要的依赖,然后…...

利用ngx_stream_return_module构建简易 TCP/UDP 响应网关
一、模块概述 ngx_stream_return_module 提供了一个极简的指令: return <value>;在收到客户端连接后,立即将 <value> 写回并关闭连接。<value> 支持内嵌文本和内置变量(如 $time_iso8601、$remote_addr 等)&a…...

基于距离变化能量开销动态调整的WSN低功耗拓扑控制开销算法matlab仿真
目录 1.程序功能描述 2.测试软件版本以及运行结果展示 3.核心程序 4.算法仿真参数 5.算法理论概述 6.参考文献 7.完整程序 1.程序功能描述 通过动态调整节点通信的能量开销,平衡网络负载,延长WSN生命周期。具体通过建立基于距离的能量消耗模型&am…...

【SpringBoot】100、SpringBoot中使用自定义注解+AOP实现参数自动解密
在实际项目中,用户注册、登录、修改密码等操作,都涉及到参数传输安全问题。所以我们需要在前端对账户、密码等敏感信息加密传输,在后端接收到数据后能自动解密。 1、引入依赖 <dependency><groupId>org.springframework.boot</groupId><artifactId...

Spring Boot+Neo4j知识图谱实战:3步搭建智能关系网络!
一、引言 在数据驱动的背景下,知识图谱凭借其高效的信息组织能力,正逐步成为各行业应用的关键技术。本文聚焦 Spring Boot与Neo4j图数据库的技术结合,探讨知识图谱开发的实现细节,帮助读者掌握该技术栈在实际项目中的落地方法。 …...

用docker来安装部署freeswitch记录
今天刚才测试一个callcenter的项目,所以尝试安装freeswitch 1、使用轩辕镜像 - 中国开发者首选的专业 Docker 镜像加速服务平台 编辑下面/etc/docker/daemon.json文件为 {"registry-mirrors": ["https://docker.xuanyuan.me"] }同时可以进入轩…...

Map相关知识
数据结构 二叉树 二叉树,顾名思义,每个节点最多有两个“叉”,也就是两个子节点,分别是左子 节点和右子节点。不过,二叉树并不要求每个节点都有两个子节点,有的节点只 有左子节点,有的节点只有…...

微软PowerBI考试 PL300-在 Power BI 中清理、转换和加载数据
微软PowerBI考试 PL300-在 Power BI 中清理、转换和加载数据 Power Query 具有大量专门帮助您清理和准备数据以供分析的功能。 您将了解如何简化复杂模型、更改数据类型、重命名对象和透视数据。 您还将了解如何分析列,以便知晓哪些列包含有价值的数据,…...

佰力博科技与您探讨热释电测量的几种方法
热释电的测量主要涉及热释电系数的测定,这是表征热释电材料性能的重要参数。热释电系数的测量方法主要包括静态法、动态法和积分电荷法。其中,积分电荷法最为常用,其原理是通过测量在电容器上积累的热释电电荷,从而确定热释电系数…...

逻辑回归暴力训练预测金融欺诈
简述 「使用逻辑回归暴力预测金融欺诈,并不断增加特征维度持续测试」的做法,体现了一种逐步建模与迭代验证的实验思路,在金融欺诈检测中非常有价值,本文作为一篇回顾性记录了早年间公司给某行做反欺诈预测用到的技术和思路。百度…...