优化案例5:视图目标列改写优化
优化案例5:视图目标列改写优化
- 1. 问题描述
- 2. 分析过程
- 2.1 目标SQL
- 2.2 解决思路
- 1)效率低的执行计划
- 2)视图过滤性
- 3)查看已有索引定义
- 2.3 视图改写
- 2.4 增添复合索引
- 3. 优化总结
DM技术交流QQ群:940124259
1. 问题描述
视图改写优化单独拿出一例分享,未做hint优化,简单地改写视图列和增加一个索引就能搞定。
这条SQL本身很简单,被广州同事使出三板斧(统计信息、索引、ET耗时、HINT、清理执行计划),招式使尽,却没去留意视图定义本身内容的特点,利用视图的谓词下推的策略,就能达到优化目的。
截图为同事部分一堆骚操作:
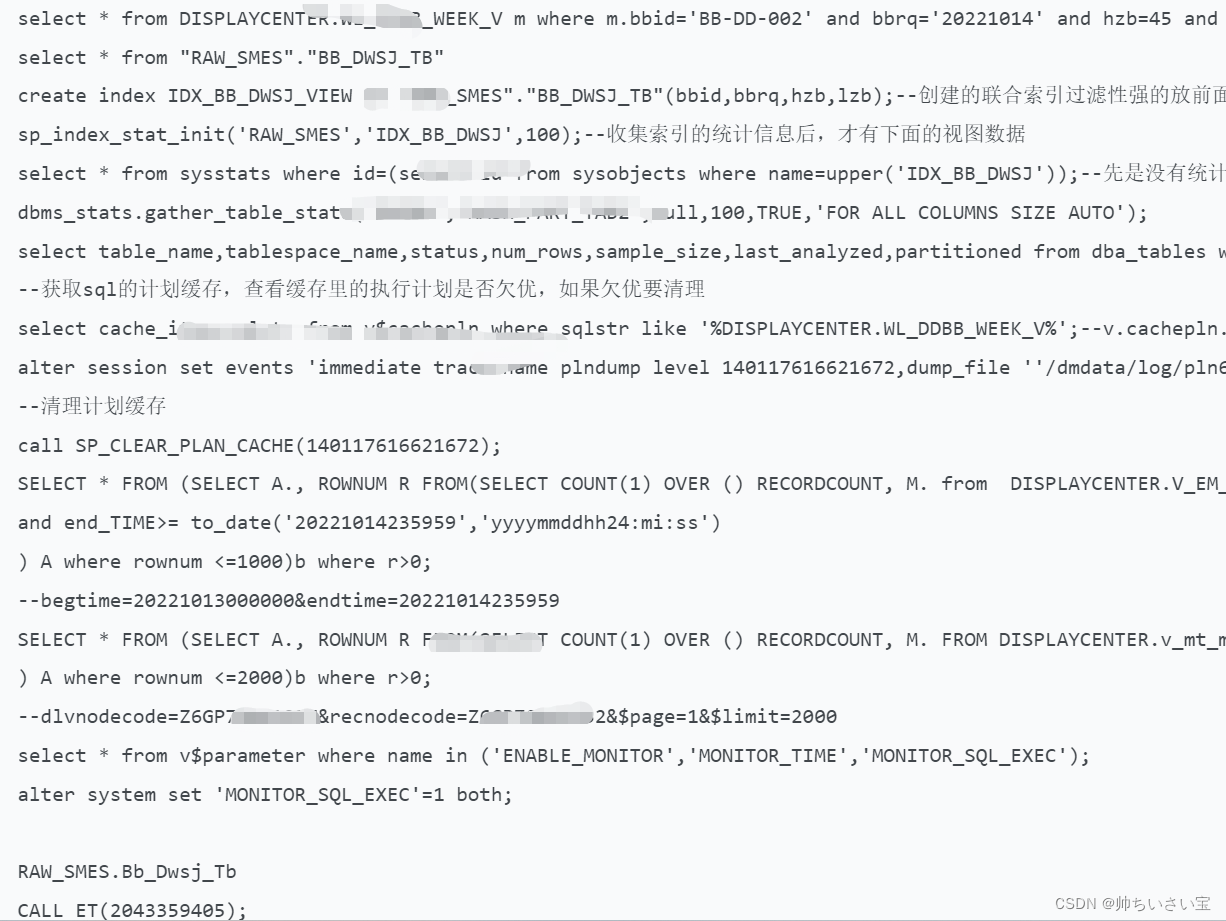
2. 分析过程
2.1 目标SQL
-- 原始SQL代码
SELECT * FROM (SELECT A., ROWNUM R FROM(SELECT COUNT(1) OVER () RECORDCOUNT, M. from DISPLAYCENTER.WL_DDBB_WEEK_V mwhere m.bbid='BB-DD-002' and bbrq='20221014'and hzb=45 and lzb=6 ) A where rownum <=1000)b where r>0; -- telphoning --4ms
-- 视图原始定义WL_DDBB_WEEK_V
CREATE OR REPLACE VIEW WL_DDBB_WEEK_V AS
SELECT t1.bbzd_id bbid, '' bbmc,
SUBSTR (t1.bbzd_date, 1, 4) || SUBSTR (t1.bbzd_date, 7, 2) || SUBSTR (t1.bbzd_date, 9, 2) AS bbrq,
t1.hzd_nm hzb, t1.lzd_nm lzb, dyzd_sj as VALUE
FROM (SELECT
T1.*
FROM RAW_SMES.Bb_Dwsj_Tb T1) t1 ;
2.2 解决思路
1)效率低的执行计划
/*
-- predicate condition
1 #NSET2: [6597, 1, 912]
2 #PRJT2: [6597, 1, 912]; exp_num(8), is_atom(FALSE)
3 #SLCT2: [6597, 1, 912]; B.R > var2
4 #PRJT2: [6597, 1, 912]; exp_num(8), is_atom(FALSE)
5 #RN: [6597, 1, 912]
6 #PRJT2: [6597, 1, 912]; exp_num(7), is_atom(FALSE)
7 #TOPN2: [6597, 1, 912]; top_num(exp11)
8 #AFUN: [6597, 1, 912]; afun_num(1); partition_num(0); order_num(0)
9 #PRJT2: [6597, 34, 912]; exp_num(6), is_atom(FALSE)
10 #SLCT2: [6597, 34, 912]; (exp_cast(T1.HZD_NM) = 45 AND exp_cast(T1.LZD_NM) = 6 AND exp11 || exp11 || exp11 = '20221014')
11 #BLKUP2: [6597, 2754812, 912]; IDX_BB_DWSJ(T1)
12 #SSEK2: [6597, 2754812, 912]; scan_type(ASC), IDX_BB_DWSJ(BB_DWSJ_TB as T1), scan_range[('BB-DD-002',min,min,min),('BB-DD-002',max,max,max))
*/
从执行计划步骤12 SSEK2和步骤10 SLCT2操作符的附加信息可以看出视图的过滤条件被下放。 但回表大严重(2754812行),由此可以推断这表很大,然而看着应用复合索引,只能命中一个字段定位,二次回表再过滤,不慢才怪。 所以影响此SQL的罪魁祸首是回表200+W的数据,造成大量的逻辑读和磁盘读。
2)视图过滤性
select count(*) from DISPLAYCENTER.WL_DDBB_WEEK_V ; -- 110 265 448 1亿1千万的数据行
select count(*) from DISPLAYCENTER.WL_DDBB_WEEK_V m where m.bbid='BB-DD-002' and m.bbrq='20221014'; -- 816 过滤性极强
select count(*) from DISPLAYCENTER.WL_DDBB_WEEK_V m where m.bbid='BB-DD-002' and hzb=45 and lzb=6 and bbrq='20221014'; -- 1
视图里面只有一个基表且数据量庞大,bbid和bbrq组合条件过滤性很强,对它们建个索引效果更好。
3)查看已有索引定义
/*
-- 表定义
CREATE TABLE "RAW_SMES"."BB_DWSJ_TB"
(
"QYZD_BH" VARCHAR2(40),
"DWZD_BH" VARCHAR2(30),
"BBZD_ID" VARCHAR2(20),
"BBZD_DATE" VARCHAR2(10),
"BBZD_YEAR" VARCHAR2(10),
"BBZD_MON" VARCHAR2(10),
"BBZD_DAY" VARCHAR2(10),
"BBZD_QUA" VARCHAR2(10),
"BBZD_TENDAY" VARCHAR2(10),
"BBZD_WEEK" VARCHAR2(10),
"HZD_ZB" NUMBER,
"LZD_ZB" NUMBER,
"H_BZBM" VARCHAR2(30),
"L_BZBM" VARCHAR2(30),
"DYZD_SJ" VARCHAR2(500),
"DYZD_DATA" NUMBER(20,6),
"XSSX" NUMBER,
"HZD_NM" VARCHAR2(50),
"LZD_NM" VARCHAR2(50),
"INSERT_ODS_TIME" TIMESTAMP(0),
"UPDATE_ODS_TIME" TIMESTAMP(0),
"M_ROW$$" VARCHAR2(128)) STORAGE(ON "RAW_SCGK", CLUSTERBTR) ;-- 索引定义
CREATE UNIQUE INDEX "UK_M_ROW" ON "RAW_SMES"."BB_DWSJ_TB"("M_ROW$$" ASC) STORAGE(ON "RAW_SCGK", CLUSTERBTR) ;
CREATE INDEX "IDX_BB_DWSJ" ON "RAW_SMES"."BB_DWSJ_TB"("BBZD_ID" ASC,"BBZD_DATE" ASC,"HZD_NM" ASC,"LZD_NM" ASC) STORAGE(ON "RAW_SCGK", CLUSTERBTR) ;
*/
看到索引定义("BBZD_ID" ASC,"BBZD_DATE" ASC,"HZD_NM" ASC,"LZD_NM" ASC) 时,知道他们离优化成功半步之遥,不懂BBZD_DATE字段被视图转换拼接, 已不再是原始字段,所以这个索引无法利用上第2个字段,则解释清楚1)所说的执行计划涉及的回表严重。
2.3 视图改写
原始视图的bbrq视图列定义SUBSTR (t1.bbzd_date, 1, 4) || SUBSTR (t1.bbzd_date, 7, 2) || SUBSTR (t1.bbzd_date, 9, 2) AS bbrq, 写得太复杂,无非就是从字符类型的bbzd_date截取出合法的日期格式数据,把一大趾函数转换简单化,变成stuff函数,减少复杂计算, 还能让后面建函数索引更简单方便。-- redefination view reduce function cost
CREATE OR REPLACE VIEW DISPLAYCENTER.WL_DDBB_WEEK_V
AS
SELECT
t1.bbzd_id bbid,
'' bbmc ,
stuff(t1.bbzd_date, 5, 2, '') AS bbrq, -- 改写位置
t1.hzd_nm hzb ,
t1.lzd_nm lzb ,
dyzd_sj as VALUE
FROM
(
SELECT T1.* FROM RAW_SMES.Bb_Dwsj_Tb T1
)
t1 ;
2.4 增添复合索引
create index idx_comb_bbid_hzb_lzb on “RAW_SMES”.“BB_DWSJ_TB”(BBZD_ID, STUFF(bbzd_date, 5, 2, ‘’), HZD_NM,LZD_NM ) ONLINE;
将就原来他们建的索引IDX_BB_DWSJ的逻辑,把第2个字段替换成stuff函数。再来一探执行计划的变化,不出意外的话,将会充分利用上索引前两个字段的过滤性。
/* 执行时间:4毫秒
1 #NSET2: [163, 1, 912]
2 #PRJT2: [163, 1, 912]; exp_num(8), is_atom(FALSE)
3 #SLCT2: [163, 1, 912]; B.R > var2
4 #PRJT2: [163, 1, 912]; exp_num(8), is_atom(FALSE)
5 #RN: [163, 1, 912]
6 #PRJT2: [163, 1, 912]; exp_num(7), is_atom(FALSE)
7 #TOPN2: [163, 1, 912]; top_num(exp11)
8 #AFUN: [163, 1, 912]; afun_num(1); partition_num(0); order_num(0)
9 #PRJT2: [163, 68469, 912]; exp_num(6), is_atom(FALSE)
10 #SLCT2: [163, 68469, 912]; (exp_cast(T1.HZD_NM) = 45 AND exp_cast(T1.LZD_NM) = 6)
11 #BLKUP2: [163, 68469, 912]; IDX_COMB_BBID_HZB_LZB(T1)
12 #SSEK2: [163, 68469, 912]; scan_type(ASC), IDX_COMB_BBID_HZB_LZB(BB_DWSJ_TB as T1), scan_range[('BB-DD-002','20221014',min,min),('BB-DD-002','20221014',max,max))
*/
3. 优化总结
懂得索引合理创建,不要乱建索引,复合索引的组合字段弄得太多不是好事,因为能利用上的索引键就一个或两个,完全没意义弄这么多索引键,潜在隐藏一个信息,索引体积太大,索引B+树庞大,可能引起大量的IO读写,影响索引扫描的效率。
一定要充分利用索引特性,够小(体积小,可以理解为表的瘦身版),够高效(过滤性强)。
明白视图的优化手段,无非包含视图上拉、视图合并等等优化思想。
相关文章:
优化案例5:视图目标列改写优化
优化案例5:视图目标列改写优化 1. 问题描述2. 分析过程2.1 目标SQL2.2 解决思路1)效率低的执行计划2)视图过滤性3)查看已有索引定义 2.3 视图改写2.4 增添复合索引 3. 优化总结 DM技术交流QQ群:940124259 1. 问题描述…...
Origin绘制彩色光谱图
成果图 1、双击线条打开如下窗口 2、选择“图案”-》颜色-》按点-》映射-》Wavelength 3、选择颜色映射 4、单击填充-》选择加载调色板-》Rainbow-》确定 5、单击级别,设置成从370到780,右侧增量选择2(越小,颜色渐变越细腻&am…...

项目复盘:从实践中学习
引言 在我们的工作生涯中,每一个项目都是一次学习的机会。项目复盘是对已完成项目的全面评估,旨在理解我们做得好的地方,以及需要改进的地方。这篇文章将分享我们如何进行项目复盘,以及我们从中学到了什么。 项目背景 在我们开…...
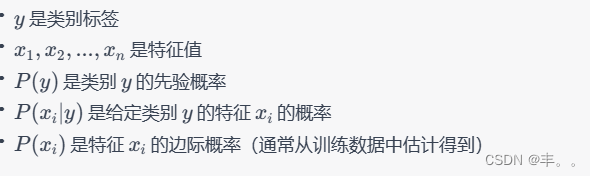
机器学习和数据挖掘02-Gaussian Naive Bayes
概念 贝叶斯定理: 贝叶斯定理是概率中的基本定理,描述了如何根据更多证据或信息更新假设的概率。在分类的上下文中,它用于计算给定特征集的类别的后验概率。 特征独立性假设: 高斯朴素贝叶斯中的“朴素”假设是,给定…...

【面试题精讲】Java Stream排序的实现方式
首发博客地址 系列文章地址 如何使用Java Stream进行排序 在Java中,使用Stream进行排序可以通过sorted()方法来实现。sorted()方法用于对Stream中的元素进行排序操作。具体实现如下: 对基本类型元素的排序: 使用sorted()方法对Stream进行排序…...
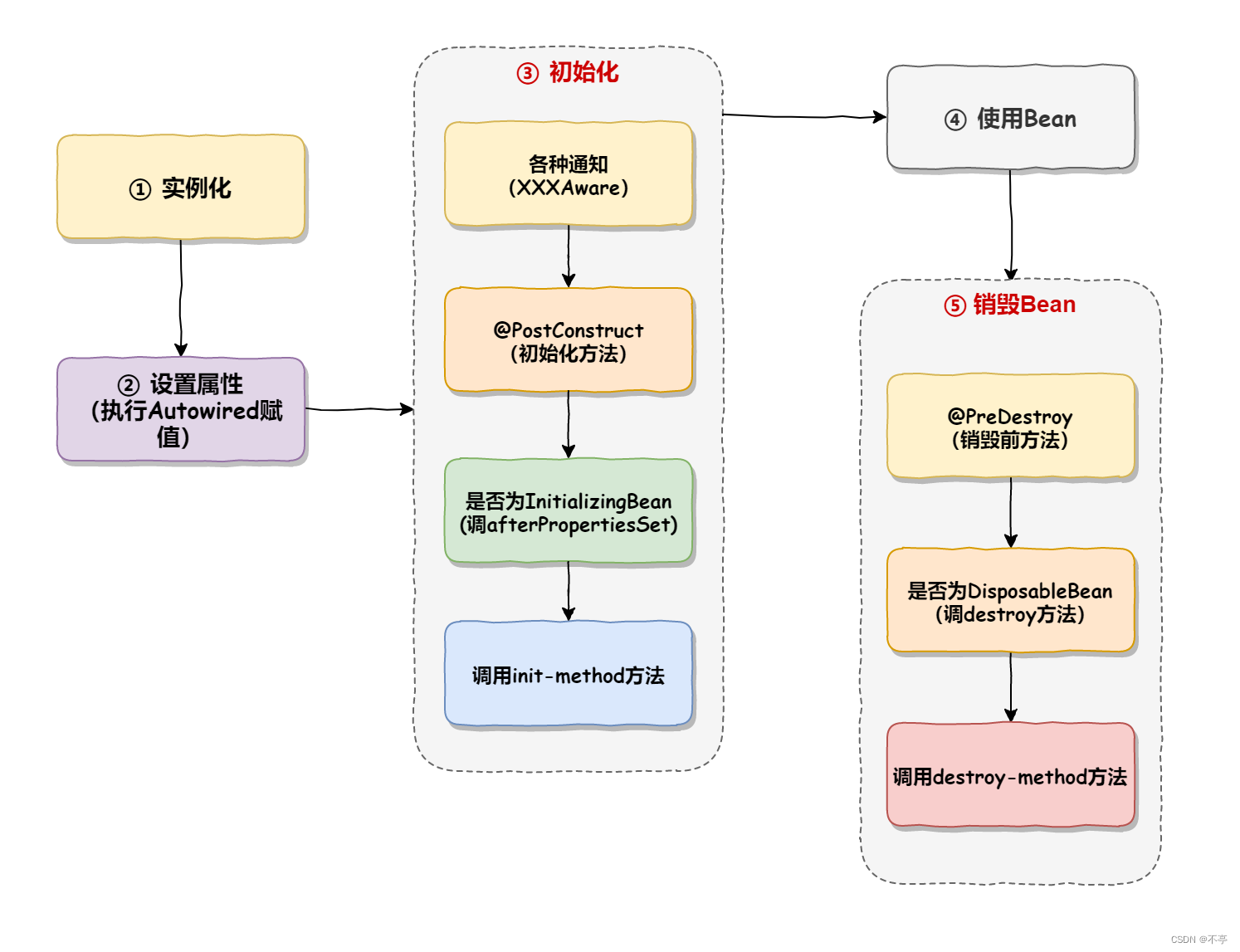
浅谈Spring
Spring是一个轻量级的控制反转(IoC)和面向切面(AOP)的容器(框架)。 一、什么是IOC? IoC Inversion of Control 翻译成中⽂是“控制反转”的意思,也就是说 Spring 是⼀个“控制反转”的容器。 1.1控制反转推导 这个控制反转怎…...
Java 复习笔记 - 面向对象进阶篇
文章目录 一,Static(一)Static的概述(二)静态变量(三)静态方法(四)工具类(五)static的注意事项 二,继承(一)继…...
微信小程序中识别html标签的方法
rich-text组件 在微信小程序中有一个组件rich-text可以识别文本节点或是元素节点 具体入下: //需要识别的数据放在data中,然后放在nodes属性中即可 <rich-text nodes"{{data}}"></rich-text>详情可以参考官方文档:https://developers.weixin.qq.com/mi…...
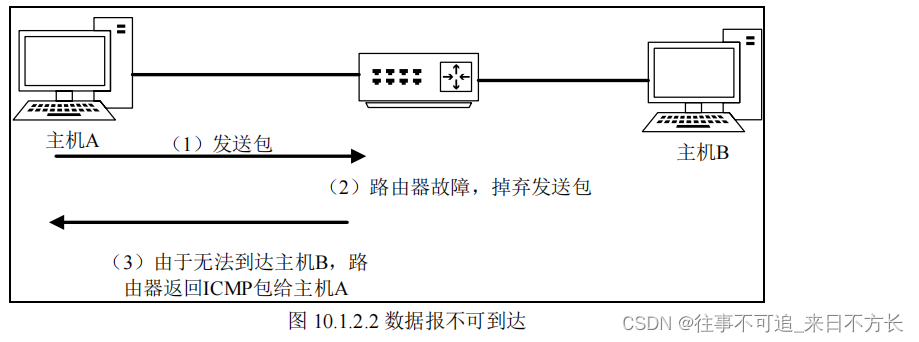
02_常见网络层协议的头结构
1.ARP报文的报文结构 ARP首部的5个字段的含义: 硬件类型:值为1表示以太网MAC地址。 协议类型:表示要映射的协议地址类型,0x0800 表示映射为IP地址。 硬件地址长度:在以太网ARP的请求和应答中都是6,表示M…...

ChatGLM学习
GLM paper:https://arxiv.org/pdf/2103.10360.pdfchatglm 130B:https://arxiv.org/pdf/2210.02414.pdf 前置知识补充 双流自注意力 Two-stream self-attention mechanism(双流自注意机制)是一种用于自然语言处理任务的注意力机制…...

Flink之Watermark
1.乱序问题 流处理从事件产生,到流经source,再到operator,中间是有一个过程和时间的,虽然大部分情况下,流到operator的数据都是按照事件产生的时间顺序来的,但是也不排除由于网络、分布式等原因࿰…...

二轮平衡小车3:PID速度环
使用芯片:STM32 F103 C8T6 今日继续我的二路平衡小车开发之路,今日编写的是二轮平衡小车的PID速度环,我准备了纸飞机串口助手软件来辅助测试调节PID。 本文主要贴代码,之前的文章都有原理,代码中相应初始化驱动部分也…...

C语言之练习题
欢迎来到我的世界 希望这篇文章对你有所帮助,有不足的地方还请指正,大家一起学习交流 ! 目录 前言编程题第一题:珠玑妙算第二题:寻找奇数第三题:寻找峰值第四题:数对 总结 前言 这是暑假题目的收尾文章&am…...
没钱,没人,没经验?传统制造型企业如何用无代码实现转型
2023年,国家市场监督管理总局发布了三项重要标准,包括《工业互联网平台选型要求》、《工业互联网平台微服务参考框架》和《工业互联网平台开放应用编程接口功能要求》。这些标准的发布对于完善工业互联网平台标准体系,提升多样化工业互联网平…...

CentOS ARM 部署 kubernetes v1.24.6
1.背景 之前安装的kubernetes版本为v1.19.0 树莓派使用(CentOS7.9 armv71 Kubernetes1.19.0), 由于版本过低,一些HPA相关的功能支持不是特别好,因此需要将版本升级,本次会将版本升级为v1.24.6. 2. 如何upgrade 2.1. 优雅升级 kubeadm自带…...

LeetCode 725. Split Linked List in Parts【链表】中等
本文属于「征服LeetCode」系列文章之一,这一系列正式开始于2021/08/12。由于LeetCode上部分题目有锁,本系列将至少持续到刷完所有无锁题之日为止;由于LeetCode还在不断地创建新题,本系列的终止日期可能是永远。在这一系列刷题文章…...

云计算中的负载均衡技术,确保资源的平衡分配
文章目录 1. 硬件负载均衡器2. 软件负载均衡器3. DNS负载均衡4. 内容分发网络(CDN) 🎈个人主页:程序员 小侯 🎐CSDN新晋作者 🎉欢迎 👍点赞✍评论⭐收藏 ✨收录专栏:云计算 ✨文章内…...

探索 SOCKS5 代理在跨境电商中的网络安全应用
随着全球化的发展,跨境电商成为了商业界的一颗新星,为企业提供了无限的发展机遇。然而,随之而来的是网络安全的挑战,特别是在处理国际网络流量时。在这篇文章中,我们将探讨如何利用 SOCKS5 代理和代理 IP 技术来加强跨…...

全网独家:编译CentOS6.10系统的openssl-1.1.1多版本并存的rpm安装包
CentOS6.10系统原生的openssl版本太老,1.0.1e,不能满足一些新版本应用软件的要求,但是它又被wget、mysql-libs、python-2.6.6、yum等一众系统包所依赖,不能再做升级。故需考虑在不影响系统原生openssl的情况下,安装较新…...

【go】异步任务解决方案Asynq实战
文章目录 一.Asynq介绍二.所需工具三.代码示例四.Reference 一.Asynq介绍 Asynq 是一个 Go 库,一个高效的分布式任务队列。 Asynq 工作原理: 客户端(生产者)将任务放入队列服务器(消费者)从队列中拉出任…...

(LeetCode 每日一题) 3442. 奇偶频次间的最大差值 I (哈希、字符串)
题目:3442. 奇偶频次间的最大差值 I 思路 :哈希,时间复杂度0(n)。 用哈希表来记录每个字符串中字符的分布情况,哈希表这里用数组即可实现。 C版本: class Solution { public:int maxDifference(string s) {int a[26]…...

OpenLayers 可视化之热力图
注:当前使用的是 ol 5.3.0 版本,天地图使用的key请到天地图官网申请,并替换为自己的key 热力图(Heatmap)又叫热点图,是一种通过特殊高亮显示事物密度分布、变化趋势的数据可视化技术。采用颜色的深浅来显示…...

微软PowerBI考试 PL300-选择 Power BI 模型框架【附练习数据】
微软PowerBI考试 PL300-选择 Power BI 模型框架 20 多年来,Microsoft 持续对企业商业智能 (BI) 进行大量投资。 Azure Analysis Services (AAS) 和 SQL Server Analysis Services (SSAS) 基于无数企业使用的成熟的 BI 数据建模技术。 同样的技术也是 Power BI 数据…...

(二)TensorRT-LLM | 模型导出(v0.20.0rc3)
0. 概述 上一节 对安装和使用有个基本介绍。根据这个 issue 的描述,后续 TensorRT-LLM 团队可能更专注于更新和维护 pytorch backend。但 tensorrt backend 作为先前一直开发的工作,其中包含了大量可以学习的地方。本文主要看看它导出模型的部分&#x…...

dedecms 织梦自定义表单留言增加ajax验证码功能
增加ajax功能模块,用户不点击提交按钮,只要输入框失去焦点,就会提前提示验证码是否正确。 一,模板上增加验证码 <input name"vdcode"id"vdcode" placeholder"请输入验证码" type"text&quo…...

定时器任务——若依源码分析
分析util包下面的工具类schedule utils: ScheduleUtils 是若依中用于与 Quartz 框架交互的工具类,封装了定时任务的 创建、更新、暂停、删除等核心逻辑。 createScheduleJob createScheduleJob 用于将任务注册到 Quartz,先构建任务的 JobD…...

【ROS】Nav2源码之nav2_behavior_tree-行为树节点列表
1、行为树节点分类 在 Nav2(Navigation2)的行为树框架中,行为树节点插件按照功能分为 Action(动作节点)、Condition(条件节点)、Control(控制节点) 和 Decorator(装饰节点) 四类。 1.1 动作节点 Action 执行具体的机器人操作或任务,直接与硬件、传感器或外部系统…...

【配置 YOLOX 用于按目录分类的图片数据集】
现在的图标点选越来越多,如何一步解决,采用 YOLOX 目标检测模式则可以轻松解决 要在 YOLOX 中使用按目录分类的图片数据集(每个目录代表一个类别,目录下是该类别的所有图片),你需要进行以下配置步骤&#x…...

selenium学习实战【Python爬虫】
selenium学习实战【Python爬虫】 文章目录 selenium学习实战【Python爬虫】一、声明二、学习目标三、安装依赖3.1 安装selenium库3.2 安装浏览器驱动3.2.1 查看Edge版本3.2.2 驱动安装 四、代码讲解4.1 配置浏览器4.2 加载更多4.3 寻找内容4.4 完整代码 五、报告文件爬取5.1 提…...

Rapidio门铃消息FIFO溢出机制
关于RapidIO门铃消息FIFO的溢出机制及其与中断抖动的关系,以下是深入解析: 门铃FIFO溢出的本质 在RapidIO系统中,门铃消息FIFO是硬件控制器内部的缓冲区,用于临时存储接收到的门铃消息(Doorbell Message)。…...