尚硅谷大数据项目《在线教育之离线数仓》笔记007
视频地址:尚硅谷大数据项目《在线教育之离线数仓》_哔哩哔哩_bilibili
目录
第12章 报表数据导出
P112
01、创建数据表
02、修改datax的jar包
03、ads_traffic_stats_by_source.json文件
P113
P114
P115
P116
P117
P118
P119
P120
P121
P122【122_在线教育数仓开发回顾 04:23】
第12章 报表数据导出
P112
01、创建数据表
# 第12章 报表数据导出
CREATE DATABASE IF NOT EXISTS edu_report DEFAULT CHARSET utf8 COLLATE utf8_general_ci;# 12.1.2 创建表# 01)各来源流量统计
DROP TABLE IF EXISTS ads_traffic_stats_by_source;
CREATE TABLE ads_traffic_stats_by_source
(`dt` DATETIME COMMENT '统计日期',`recent_days` BIGINT COMMENT '最近天数,1:最近1天,7:最近7天,30:最近30天',`source_id` VARCHAR(255) COMMENT '引流来源id',`source_site` VARCHAR(255) COMMENT '引流来源名称',`uv_count` BIGINT COMMENT '访客人数',`avg_duration_sec` BIGINT COMMENT '会话平均停留时长,单位为秒',`avg_page_count` BIGINT COMMENT '会话平均浏览页面数',`sv_count` BIGINT COMMENT '会话数',`bounce_rate` DECIMAL(16, 2) COMMENT '跳出率',PRIMARY KEY (`dt`, `recent_days`, `source_id`)
) COMMENT '各引流来源流量统计';# 02)页面浏览路径分析
DROP TABLE IF EXISTS ads_traffic_page_path;
CREATE TABLE ads_traffic_page_path
(`dt` DATETIME COMMENT '统计日期',`recent_days` BIGINT COMMENT '最近天数,1:最近1天,7:最近7天,30:最近30天',`source` VARCHAR(255) COMMENT '跳转起始页面id',`target` VARCHAR(255) COMMENT '跳转终到页面id',`path_count` BIGINT COMMENT '跳转次数',PRIMARY KEY (`dt`, `recent_days`, `source`, `target`)
) COMMENT '页面浏览路径分析';# 03)各引流来源销售状况统计
DROP TABLE IF EXISTS ads_traffic_sale_stats_by_source;
CREATE TABLE ads_traffic_sale_stats_by_source
(`dt` DATETIME COMMENT '统计日期',`recent_days` BIGINT COMMENT '最近天数,1:最近1天,7:最近7天,30:最近30天',`source_id` VARCHAR(255) COMMENT '引流来源id',`source_site` VARCHAR(255) COMMENT '引流来源名称',`order_total_amount` DECIMAL(16, 2) COMMENT '销售额',`order_user_count` BIGINT COMMENT '下单用户数',`pv_visitor_count` BIGINT COMMENT '引流访客数',`convert_rate` DECIMAL(16, 2) COMMENT '转化率',PRIMARY KEY (`dt`, `recent_days`, `source_id`)
) COMMENT '各引流来源销售状况统计';# 04)用户变动统计
DROP TABLE IF EXISTS ads_user_user_change;
CREATE TABLE ads_user_user_change
(`dt` DATETIME COMMENT '统计日期',`user_churn_count` BIGINT COMMENT '流失用户数',`user_back_count` BIGINT COMMENT '回流用户数',PRIMARY KEY (`dt`)
) COMMENT '用户变动统计';# 05)用户留存率
DROP TABLE IF EXISTS ads_user_user_retention;
CREATE TABLE ads_user_user_retention
(`dt` DATETIME COMMENT '统计日期',`create_date` VARCHAR(255) COMMENT '用户新增日期',`retention_day` INT COMMENT '截至当前日期留存天数',`retention_count` BIGINT COMMENT '留存用户数量',`new_user_count` BIGINT COMMENT '新增用户数量',`retention_rate` DECIMAL(16, 2) COMMENT '留存率',PRIMARY KEY (`dt`, `create_date`, `retention_day`)
) COMMENT '用户留存率';# 06)用户新增活跃统计
DROP TABLE IF EXISTS ads_user_user_stats;
CREATE TABLE ads_user_user_stats
(`dt` DATETIME COMMENT '统计日期',`recent_days` BIGINT COMMENT '最近n日,1:最近1日,7:最近7日,30:最近30日',`new_user_count` BIGINT COMMENT '新增用户数',`active_user_count` BIGINT COMMENT '活跃用户数',PRIMARY KEY (`dt`, `recent_days`)
) COMMENT '用户新增活跃统计';# 07)用户行为漏斗分析
DROP TABLE IF EXISTS ads_user_user_action;
CREATE TABLE ads_user_user_action
(`dt` DATETIME COMMENT '统计日期',`recent_days` BIGINT COMMENT '最近天数,1:最近1天,7:最近7天,30:最近30天',`home_count` BIGINT COMMENT '浏览首页人数',`good_detail_count` BIGINT COMMENT '浏览商品详情页人数',`cart_count` BIGINT COMMENT '加入购物车人数',`order_count` BIGINT COMMENT '下单人数',`payment_count` BIGINT COMMENT '支付人数',PRIMARY KEY (`dt`, `recent_days`)
) COMMENT '用户行为漏斗分析';# 08)新增交易用户统计
DROP TABLE IF EXISTS ads_user_new_buyer_stats;
CREATE TABLE ads_user_new_buyer_stats
(`dt` DATETIME COMMENT '统计日期',`recent_days` BIGINT COMMENT '最近天数,1:最近1天,7:最近7天,30:最近30天',`new_order_user_count` BIGINT COMMENT '新增下单人数',`new_payment_user_count` BIGINT COMMENT '新增支付人数',PRIMARY KEY (`dt`, `recent_days`)
) COMMENT '新增交易用户统计';# 09)各年龄段下单用户数
DROP TABLE IF EXISTS ads_user_order_user_count_by_age_group;
CREATE TABLE ads_user_order_user_count_by_age_group
(`dt` DATETIME COMMENT '统计日期',`recent_days` BIGINT COMMENT '最近天数,1:最近1天,7:最近7天,30:最近30天',`age_group` VARCHAR(255) COMMENT '年龄段,18岁及以下、19-24岁、25-29岁、30-34岁、35-39岁、40-49岁、50岁及以上',`order_user_count` BIGINT COMMENT '下单人数',PRIMARY KEY (`dt`, `recent_days`, `age_group`)
) COMMENT '各年龄段下单用户数统计';# 10)各类别课程交易统计
DROP TABLE IF EXISTS ads_course_trade_stats_by_category;
CREATE TABLE ads_course_trade_stats_by_category
(`dt` DATETIME COMMENT '统计日期',`recent_days` BIGINT COMMENT '最近天数,1:最近1天,7:最近7天,30:最近30天',`category_id` VARCHAR(255) COMMENT '类别id',`category_name` VARCHAR(255) COMMENT '类别名称',`order_count` BIGINT COMMENT '订单数',`order_user_count` BIGINT COMMENT '订单人数' ,`order_amount` DECIMAL(16, 2) COMMENT '下单金额',PRIMARY KEY (`dt`, `recent_days`, `category_id`)
) COMMENT '各类别课程交易统计';# 11)各学科课程交易统计
DROP TABLE IF EXISTS ads_course_trade_stats_by_subject;
CREATE TABLE ads_course_trade_stats_by_subject
(`dt` DATETIME COMMENT '统计日期',`recent_days` BIGINT COMMENT '最近天数,1:最近1天,7:最近7天,30:最近30天',`subject_id` VARCHAR(255) COMMENT '学科id',`subject_name` VARCHAR(255) COMMENT '学科名称',`order_count` BIGINT COMMENT '订单数',`order_user_count` BIGINT COMMENT '订单人数' ,`order_amount` DECIMAL(16, 2) COMMENT '下单金额',PRIMARY KEY (`dt`, `recent_days`, `subject_id`)
) COMMENT '各学科课程交易统计';# 12)各课程交易统计
DROP TABLE IF EXISTS ads_course_trade_stats_by_course;
CREATE TABLE ads_course_trade_stats_by_course
(`dt` DATETIME COMMENT '统计日期',`recent_days` BIGINT COMMENT '最近天数,1:最近 1 天,7:最近 7天,30:最近 30 天',`course_id` VARCHAR(255) COMMENT '课程id',`course_name` VARCHAR(255) COMMENT '课程名称',`order_count` BIGINT COMMENT '下单数',`order_user_count` BIGINT COMMENT '下单人数',`order_amount` DECIMAL(16, 2) COMMENT '下单金额',PRIMARY KEY (`dt`, `recent_days`, `course_id`)
) COMMENT '各课程交易统计';# 13)各课程评价统计
DROP TABLE IF EXISTS ads_course_review_stats_by_course;
CREATE TABLE ads_course_review_stats_by_course
(`dt` DATETIME COMMENT '统计日期',`recent_days` BIGINT COMMENT '最近天数,1:最近 1 天,7:最近 7 天,30:最近 30 天',`course_id` VARCHAR(255) COMMENT '课程id',`course_name` VARCHAR(255) COMMENT '课程名称',`avg_stars` BIGINT COMMENT '用户平均评分',`review_user_count` BIGINT COMMENT '评价用户数',`praise_rate` DECIMAL(16, 2) COMMENT '好评率',PRIMARY KEY (`dt`, `recent_days`, `course_id`)
) COMMENT '各课程评价统计';# 14)各分类课程试听留存统计
DROP TABLE IF EXISTS ads_sample_retention_stats_by_category;
CREATE TABLE ads_sample_retention_stats_by_category
(`dt` DATETIME COMMENT '统计日期',`retention_days` BIGINT COMMENT '留存天数,1-7 天',`category_id` VARCHAR(255) COMMENT '分类id',`category_name` VARCHAR(255) COMMENT '分类名称',`sample_user_count` BIGINT COMMENT '试听人数',`retention_rate` DECIMAL(16, 2) COMMENT '试听留存率',PRIMARY KEY (`dt`, `retention_days`, `category_id`)
) COMMENT '各分类课程试听留存统计';# 15)各学科试听留存统计
DROP TABLE IF EXISTS ads_sample_retention_stats_by_subject;
CREATE TABLE ads_sample_retention_stats_by_subject
(`dt` DATETIME COMMENT '统计日期',`retention_days` BIGINT COMMENT '留存天数,1-7 天',`subject_id` VARCHAR(255) COMMENT '学科id',`subject_name` VARCHAR(255) COMMENT '学科名称',`sample_user_count` BIGINT COMMENT '试听人数',`retention_rate` DECIMAL(16, 2) COMMENT '试听留存率',PRIMARY KEY (`dt`, `retention_days`, `subject_id`)
) COMMENT '各学科试听留存统计';# 16)各课程试听留存统计
DROP TABLE IF EXISTS ads_sample_retention_stats_by_course;
CREATE TABLE ads_sample_retention_stats_by_course
(`dt` DATETIME COMMENT '统计日期',`retention_days` BIGINT COMMENT '留存天数,1-7 天',`course_id` VARCHAR(255) COMMENT '课程id',`course_name` VARCHAR(255) COMMENT '课程名称',`sample_user_count` BIGINT COMMENT '试听人数',`retention_rate` DECIMAL(16, 2) COMMENT '试听留存率',PRIMARY KEY (`dt`, `retention_days`, `course_id`)
) COMMENT '各课程试听留存统计';# 17)交易综合指标
DROP TABLE IF EXISTS ads_trade_stats;
CREATE TABLE ads_trade_stats
(`dt` DATETIME COMMENT '统计日期',`recent_days` BIGINT COMMENT '最近天数,1:最近1日,7:最近7天,30:最近30天',`order_total_amount` DECIMAL(16, 2) COMMENT '订单总额,GMV',`order_count` BIGINT COMMENT '订单数',`order_user_count` BIGINT COMMENT '下单人数',PRIMARY KEY (`dt`, `recent_days`)
) COMMENT '交易综合指标';# 18)各省份交易统计
DROP TABLE IF EXISTS ads_trade_order_by_province;
CREATE TABLE ads_trade_order_by_province
(`dt` DATETIME COMMENT '统计日期',`recent_days` BIGINT COMMENT '最近天数,1:最近1天,7:最近7天,30:最近30天',`province_id` VARCHAR(10) COMMENT '省份id',`province_name` VARCHAR(30) COMMENT '省份名称',`region_id` VARCHAR(30) COMMENT '大区id',`area_code` VARCHAR(255) COMMENT '地区编码',`iso_code` VARCHAR(255) COMMENT '国际标准地区编码',`iso_code_3166_2` VARCHAR(255) COMMENT '国际标准地区编码',`order_count` BIGINT COMMENT '订单数' ,`order_user_count` BIGINT COMMENT '下单人数',`order_total_amount` DECIMAL(16, 2) COMMENT '订单金额',PRIMARY KEY (`dt`, `recent_days`, `province_id`, `region_id`, `area_code`, `iso_code`, `iso_code_3166_2`)
) COMMENT '各省份交易统计';# 19)各试卷平均统计
DROP TABLE IF EXISTS ads_examination_paper_avg_stats;
CREATE TABLE ads_examination_paper_avg_stats
(`dt` DATETIME COMMENT '统计日期',`recent_days` BIGINT COMMENT '最近天数,1:最近1天,7:最近7天,30:最近30天',`paper_id` VARCHAR(255) COMMENT '试卷 id',`paper_title` VARCHAR(255) COMMENT '试卷名称',`avg_score` DECIMAL(16, 2) COMMENT '试卷平均分',`avg_during_sec` BIGINT COMMENT '试卷平均时长',`user_count` BIGINT COMMENT '试卷用户数',PRIMARY KEY (`dt`, `recent_days`, `paper_id`)
) COMMENT '各试卷平均统计';# 20)最近 1/7/30 日各试卷成绩分布
DROP TABLE IF EXISTS ads_examination_course_avg_stats;
CREATE TABLE ads_examination_course_avg_stats
(`dt` DATETIME COMMENT '统计日期',`recent_days` BIGINT COMMENT '最近天数,1:最近1天,7:最近7天,30:最近30天',`course_id` VARCHAR(255) COMMENT '课程id',`course_name` VARCHAR(255) COMMENT '课程名称',`avg_score` DECIMAL(16, 2) COMMENT '平均分',`avg_during_sec` BIGINT COMMENT '平均时长',`user_count` BIGINT COMMENT '用户数',PRIMARY KEY (`dt`, `recent_days`, `course_id`)
) COMMENT '各课程考试相关指标';# 21)最近 1/7/30 日各试卷分数分布统计
DROP TABLE IF EXISTS ads_examination_user_count_by_score_duration;
CREATE TABLE ads_examination_user_count_by_score_duration
(`dt` DATETIME COMMENT '统计日期',`recent_days` BIGINT COMMENT '最近天数,1:最近1天,7:最近7天,30:最近30天',`paper_id` VARCHAR(255) COMMENT '试卷 id',`score_duration` VARCHAR(255) COMMENT '分数区间',`user_count` BIGINT COMMENT '各试卷各分数区间用户数',PRIMARY KEY (`dt`, `recent_days`, `paper_id`, `score_duration`)
) COMMENT '各试卷分数分布统计';# 22)最近 1/7/30 日各题目正确率
DROP TABLE IF EXISTS ads_examination_question_accuracy;
CREATE TABLE ads_examination_question_accuracy
(`dt` DATETIME COMMENT '统计日期',`recent_days` BIGINT COMMENT '最近天数,1:最近1天,7:最近7天,30:最近30天',`question_id` VARCHAR(255) COMMENT '题目 id',`accuracy` DECIMAL(16, 2) COMMENT '题目正确率',PRIMARY KEY (`dt`, `recent_days`, `question_id`)
) COMMENT '各题目正确率';# 23)单章视频播放情况统计
DROP TABLE IF EXISTS ads_learn_play_stats_by_chapter;
CREATE TABLE ads_learn_play_stats_by_chapter
(`dt` DATETIME COMMENT '统计日期',`recent_days` BIGINT COMMENT '最近天数,1:最近1天,7:最近7天,30:最近30天',`chapter_id` VARCHAR(30) COMMENT '章节 id',`chapter_name` VARCHAR(200) COMMENT '章节名称',`video_id` VARCHAR(255) COMMENT '视频 id',`video_name` VARCHAR(255) COMMENT '视频名称',`play_count` BIGINT COMMENT '各章节视频播放次数',`avg_play_sec` BIGINT COMMENT '各章节视频人均观看时长',`user_count` BIGINT COMMENT '各章节观看人数',PRIMARY KEY (`dt`, `recent_days`, `chapter_id`, `video_id`)
) COMMENT '单章视频播放情况统计';# 24)各课程播放情况统计
DROP TABLE IF EXISTS ads_learn_play_stats_by_course;
CREATE TABLE ads_learn_play_stats_by_course
(`dt` DATETIME COMMENT '统计日期',`recent_days` BIGINT COMMENT '最近天数,1:最近1天,7:最近7天,30:最近30天',`course_id` VARCHAR(255) COMMENT '课程id',`course_name` VARCHAR(255) COMMENT '课程名称',`play_count` BIGINT COMMENT '各课程视频播放次数',`avg_play_sec` BIGINT COMMENT '各课程视频人均观看时长',`user_count` BIGINT COMMENT '各课程观看人数',PRIMARY KEY (`dt`, `recent_days`, `course_id`)
) COMMENT '各课程播放情况统计';# 25)各课程完课人数统计
DROP TABLE IF EXISTS ads_complete_complete_user_count_per_course;
CREATE TABLE ads_complete_complete_user_count_per_course
(`dt` DATETIME COMMENT '统计日期',`recent_days` BIGINT COMMENT '最近天数,1:最近1天,7:最近7天,30:最近30天',`course_id` VARCHAR(255) COMMENT '课程 id',`user_count` BIGINT COMMENT '各课程完课人数',PRIMARY KEY (`dt`, `recent_days`, `course_id`)
) COMMENT '各课程完课人数统计';# 26)完课综合指标
DROP TABLE IF EXISTS ads_complete_complete_stats;
CREATE TABLE ads_complete_complete_stats
(`dt` DATETIME COMMENT '统计日期',`recent_days` BIGINT COMMENT '最近天数,1:最近1天,7:最近7天,30:最近30天',`user_complete_count` BIGINT COMMENT '完课人数',`user_course_complete_count` BIGINT COMMENT '完课人次',PRIMARY KEY (`dt`, `recent_days`)
) COMMENT '完课综合指标';# 27)各课程人均完成章节视频数
DROP TABLE IF EXISTS ads_complete_complete_chapter_count_per_course;
CREATE TABLE ads_complete_complete_chapter_count_per_course
(`dt` DATETIME COMMENT '统计日期',`recent_days` BIGINT COMMENT '最近天数,1:最近1天,7:最近7天,30:最近30天',`course_id` VARCHAR(255) COMMENT '课程 id',`complete_chapter_count` BIGINT COMMENT '各课程用户平均完成章节数',PRIMARY KEY (`dt`, `recent_days`, `course_id`)
) COMMENT '各课程人均完成章节视频数';02、修改datax的jar包
DataX
- GitHub - alibaba/DataX: DataX是阿里云DataWorks数据集成的开源版本。
- https://github.com/alibaba/DataX/blob/master/mysqlwriter/doc/mysqlwriter.md
- https://github.com/alibaba/DataX/blob/master/hdfsreader/doc/hdfsreader.md
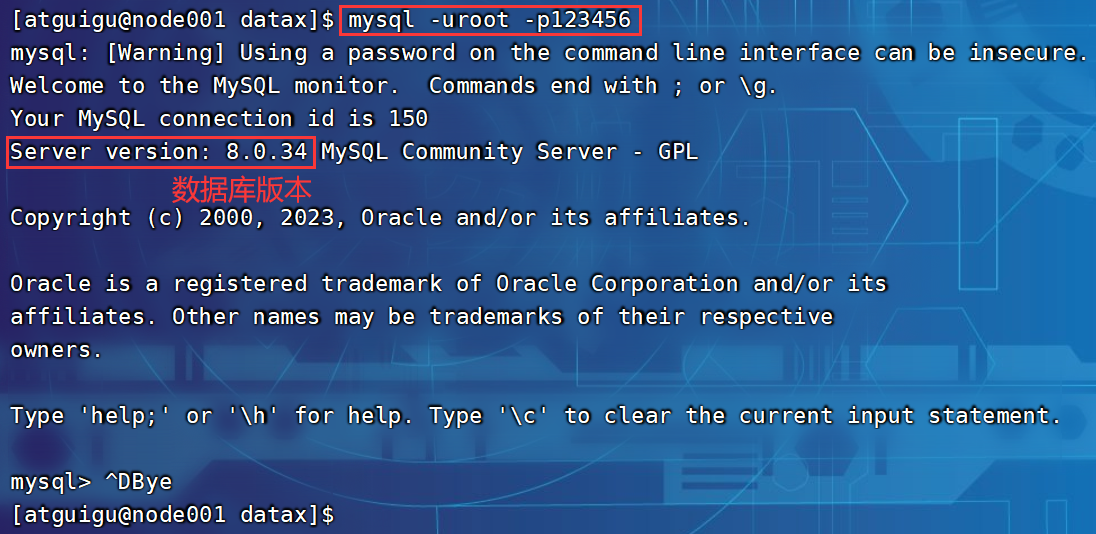
[atguigu@node001 ~]$ cd /opt/module/datax/
[atguigu@node001 datax]$ python bin/datax.py -p"-Dexportdir=/warehouse/edu/ads/ads_traffic_stats_by_source/" job/ads_traffic_stats_by_source.json2023-09-05 10:59:01.854 [job-0] ERROR RetryUtil - Exception when calling callable, 即将尝试执行第1次重试.本次重试计划等待[1000]ms,实际等待[1001]ms, 异常Msg:[Code:[DBUtilErrorCode-10], Description:[连接数据库失败. 请检查您的 账号、密码、数据库名称、IP、Port或者向 DBA 寻求帮助(注意网络环境).]. - 具体错误信息为:com.mysql.jdbc.exceptions.jdbc4.MySQLNonTransientConnectionException: Could not create connection to database server.]
2023-09-05 10:59:03.860 [job-0] ERROR RetryUtil - Exception when calling callable, 即将尝试执行第2次重试.本次重试计划等待[2000]ms,实际等待[2000]ms, 异常Msg:[Code:[DBUtilErrorCode-10], Description:[连接数据库失败. 请检查您的 账号、密码、数据库名称、IP、Port或者向 DBA 寻求帮助(注意网络环境).]. - 具体错误信息为:com.mysql.jdbc.exceptions.jdbc4.MySQLNonTransientConnectionException: Could not create connection to database server.]
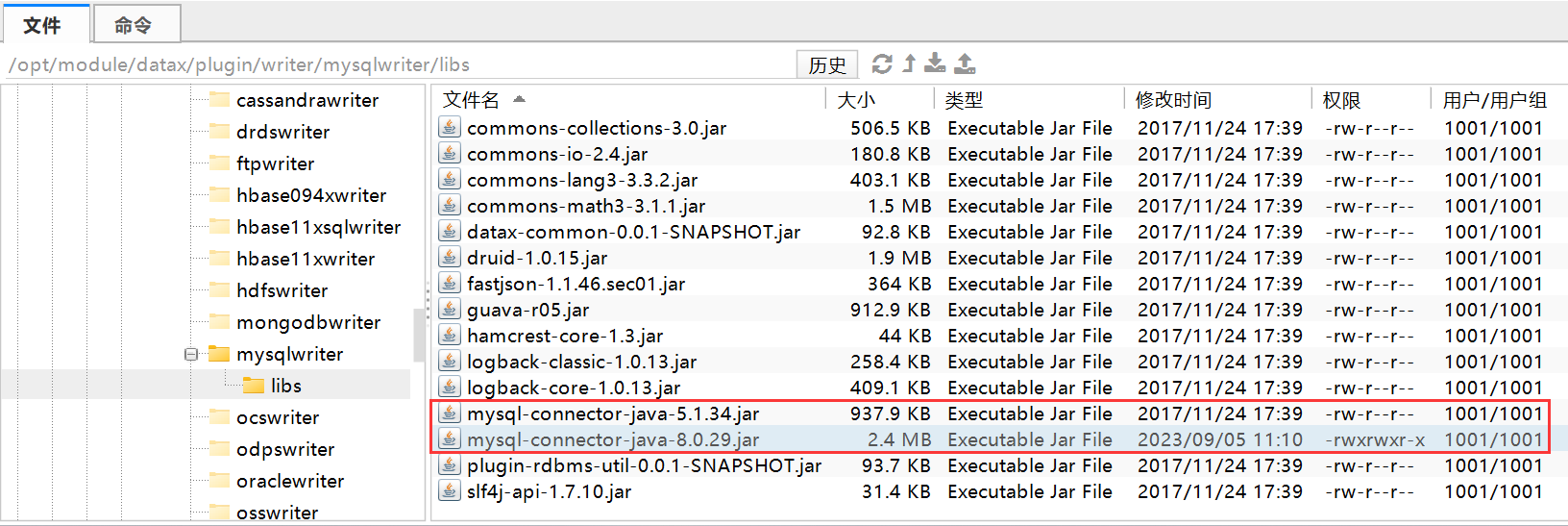
2023-09-05 10:59:07.865 [job-0] ERROR RetryUtil - Exception when calling callable, 即将尝试执行第3次重试.本次重试计划等待[4000]ms,实际等待[4000]ms, 异常Msg:[Code:[DBUtilErrorCode-10], Description:[连接数据库失败. 请检查您的 账号、密码、数据库名称、IP、Port或者向 DBA 寻求帮助(注意网络环境).]. - 具体错误信息为:com.mysql.jdbc.exceptions.jdbc4.MySQLNonTransientConnectionException: Could not create connection to database server.]解决办法:已检查N遍,账号密码没有问题,将/opt/module/datax/plugin/writer/mysqlwriter/libs与/opt/module/datax/plugin/reader/mysqlreader/libs等两个lib目录下的mysql-connector-java-5.1.34.jar包替换为mysql-connector-java-8.0.29.jar。
03、ads_traffic_stats_by_source.json文件
经DataX智能分析,该任务最可能的错误原因是:
com.alibaba.datax.common.exception.DataXException: Code:[DBUtilErrorCode-01], Description:[获取表字段相关信息失败.]. - 获取表:ads_traffic_stats_by_source 的字段的元信息时失败. 请联系 DBA 核查该库、表信息. - java.sql.SQLSyntaxErrorException: Unknown column 'channel' in 'field list'
at com.mysql.cj.jdbc.exceptions.SQLError.createSQLException(SQLError.java:120)
at com.mysql.cj.jdbc.exceptions.SQLExceptionsMapping.translateException(SQLExceptionsMapping.java:122)
at com.mysql.cj.jdbc.StatementImpl.executeQuery(StatementImpl.java:1201)
at com.alibaba.datax.plugin.rdbms.util.DBUtil.getColumnMetaData(DBUtil.java:563)
at com.alibaba.datax.plugin.rdbms.writer.util.OriginalConfPretreatmentUtil.dealColumnConf(OriginalConfPretreatmentUtil.java:125)
at com.alibaba.datax.plugin.rdbms.writer.util.OriginalConfPretreatmentUtil.dealColumnConf(OriginalConfPretreatmentUtil.java:140)
at com.alibaba.datax.plugin.rdbms.writer.util.OriginalConfPretreatmentUtil.doPretreatment(OriginalConfPretreatmentUtil.java:35)
at com.alibaba.datax.plugin.rdbms.writer.CommonRdbmsWriter$Job.init(CommonRdbmsWriter.java:41)
at com.alibaba.datax.plugin.writer.mysqlwriter.MysqlWriter$Job.init(MysqlWriter.java:31)
at com.alibaba.datax.core.job.JobContainer.initJobWriter(JobContainer.java:704)
at com.alibaba.datax.core.job.JobContainer.init(JobContainer.java:304)
at com.alibaba.datax.core.job.JobContainer.start(JobContainer.java:113)
at com.alibaba.datax.core.Engine.start(Engine.java:92)
at com.alibaba.datax.core.Engine.entry(Engine.java:171)
at com.alibaba.datax.core.Engine.main(Engine.java:204)at com.alibaba.datax.common.exception.DataXException.asDataXException(DataXException.java:33)
at com.alibaba.datax.plugin.rdbms.util.DBUtil.getColumnMetaData(DBUtil.java:575)
at com.alibaba.datax.plugin.rdbms.writer.util.OriginalConfPretreatmentUtil.dealColumnConf(OriginalConfPretreatmentUtil.java:125)
at com.alibaba.datax.plugin.rdbms.writer.util.OriginalConfPretreatmentUtil.dealColumnConf(OriginalConfPretreatmentUtil.java:140)
at com.alibaba.datax.plugin.rdbms.writer.util.OriginalConfPretreatmentUtil.doPretreatment(OriginalConfPretreatmentUtil.java:35)
at com.alibaba.datax.plugin.rdbms.writer.CommonRdbmsWriter$Job.init(CommonRdbmsWriter.java:41)
at com.alibaba.datax.plugin.writer.mysqlwriter.MysqlWriter$Job.init(MysqlWriter.java:31)
at com.alibaba.datax.core.job.JobContainer.initJobWriter(JobContainer.java:704)
at com.alibaba.datax.core.job.JobContainer.init(JobContainer.java:304)
at com.alibaba.datax.core.job.JobContainer.start(JobContainer.java:113)
at com.alibaba.datax.core.Engine.start(Engine.java:92)
at com.alibaba.datax.core.Engine.entry(Engine.java:171)
at com.alibaba.datax.core.Engine.main(Engine.java:204)
/opt/module/datax/job/ads_traffic_stats_by_source.json{"job": {"content": [{"reader": {"name": "hdfsreader","parameter": {"column": ["*"],"defaultFS": "hdfs://node001:8020","encoding": "UTF-8","fieldDelimiter": "\t","fileType": "text","nullFormat": "\\N","path": "${exportdir}"}},"writer": {"name": "mysqlwriter","parameter": {"column": ["dt","recent_days","source_id","source_site","uv_count","avg_duration_sec","avg_page_count","sv_count","bounce_rate"],"connection": [{"jdbcUrl": "jdbc:mysql://node001:3306/edu_report?useUnicode=true&characterEncoding=utf-8","table": ["ads_traffic_stats_by_source"]}],"username": "root","password": "123456","writeMode": "replace"}}}],"setting": {"errorLimit": {"percentage": 0.02,"record": 0},"speed": {"channel": 3}}}
}

P113
12.2.2 DataX配置文件生成脚本
P114
第13章 数据仓库工作流调度
Apache DolphinScheduler是一个分布式、易扩展的可视化DAG工作流任务调度平台。致力于解决数据处理流程中错综复杂的依赖关系,使调度系统在数据处理流程中开箱即用。
P115
第2章 DolphinScheduler部署说明
第3章 DolphinScheduler集群模式部署
3.6 一键部署DolphinScheduler
[atguigu@node001 apache-dolphinscheduler-2.0.3-bin]$ jpsall
================ node001 ================
5360 QuorumPeerMain
2832 NameNode
9296 WorkerServer
3411 JobHistoryServer
5988 RunJar
9668 ApiApplicationServer
6100 RunJar
9414 LoggerServer
3000 DataNode
9545 AlertServer
10540 Jps
7020 NodeManager
================ node002 ================
5296 NodeManager
5984 WorkerServer
6032 LoggerServer
6231 Jps
4745 QuorumPeerMain
5178 ResourceManager
4986 DataNode
================ node003 ================
3985 NodeManager
4658 LoggerServer
4884 Jps
1861 DataNode
3594 QuorumPeerMain
1967 SecondaryNameNode
[atguigu@node001 apache-dolphinscheduler-2.0.3-bin]$ P116
3.7 DolphinScheduler启停命令
[atguigu@node001 apache-dolphinscheduler-2.0.3-bin]$ cd /opt/module/dolphinScheduler/ds-2.0.3/
[atguigu@node001 ds-2.0.3]$ ll
总用量 60
drwxrwxr-x 2 atguigu atguigu 4096 9月 6 11:21 bin
drwxrwxr-x 5 atguigu atguigu 4096 9月 6 11:21 conf
-rwxrwxr-x 1 atguigu atguigu 5190 9月 6 11:22 install.sh
drwxrwxr-x 2 atguigu atguigu 20480 9月 6 11:22 lib
drwxrwxr-x 2 atguigu atguigu 4096 9月 6 11:23 logs
drwxrwxr-x 2 atguigu atguigu 4096 9月 6 11:22 pid
drwxrwxr-x 2 atguigu atguigu 4096 9月 6 11:22 script
drwxrwxr-x 3 atguigu atguigu 4096 9月 6 11:22 sql
drwxrwxr-x 8 atguigu atguigu 4096 9月 6 11:22 ui
[atguigu@node001 ds-2.0.3]$ cd bin/
[atguigu@node001 bin]$ ll
总用量 20
-rwxrwxr-x 1 atguigu atguigu 6770 9月 6 11:21 dolphinscheduler-daemon.sh
-rwxrwxr-x 1 atguigu atguigu 2427 9月 6 11:21 start-all.sh
-rwxrwxr-x 1 atguigu atguigu 3332 9月 6 11:21 status-all.sh
-rwxrwxr-x 1 atguigu atguigu 2428 9月 6 11:21 stop-all.sh
[atguigu@node001 bin]$ node003没有运行WorkerServer,资源不够,将资源改为8g就能运行了,但没必要。
P117
启动hadoop、zookeeper、hive、hive-service2、ds。
- [atguigu@node001 ~]$ myhadoop.sh start
- [atguigu@node001 ~]$ zookeeper.sh start
- [atguigu@node001 ~]$ nohup /opt/module/hive/hive-3.1.2/bin/hive &
- [atguigu@node001 ~]$ nohup /opt/module/hive/hive-3.1.2/bin/hive --service hiveserver2 &
- [atguigu@node001 ~]$ /opt/module/dolphinScheduler/ds-2.0.3/bin/start-all.sh
[atguigu@node001 ~]$ myhadoop.sh start================ 启动 hadoop集群 ================---------------- 启动 hdfs ----------------
Starting namenodes on [node001]
Starting datanodes
Starting secondary namenodes [node003]--------------- 启动 yarn ---------------
Starting resourcemanager
Starting nodemanagers--------------- 启动 historyserver ---------------
[atguigu@node001 ~]$ zookeeper.sh start
---------- zookeeper node001 启动 ----------
ZooKeeper JMX enabled by default
Using config: /opt/module/zookeeper/zookeeper-3.5.7/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
---------- zookeeper node002 启动 ----------
ZooKeeper JMX enabled by default
Using config: /opt/module/zookeeper/zookeeper-3.5.7/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
---------- zookeeper node003 启动 ----------
ZooKeeper JMX enabled by default
Using config: /opt/module/zookeeper/zookeeper-3.5.7/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[atguigu@node001 ~]$ nohup /opt/module/hive/hive-3.1.2/bin/hive &
[1] 3741
[atguigu@node001 ~]$ nohup: 忽略输入并把输出追加到"nohup.out"[atguigu@node001 ~]$ nohup /opt/module/hive/hive-3.1.2/bin/hive --service hiveserver2 &
[2] 3912
[atguigu@node001 ~]$ nohup: 忽略输入并把输出追加到"nohup.out"[atguigu@node001 ~]$ /opt/module/dolphinScheduler/ds-2.0.3/bin/start-all.sh
node001:default
...DolphinScheduler工作流运行之后在工作流实例中查不到是什么原因?将node001的运行内存从4G调为8G即可。
P118
第5章 DolphinScheduler进阶
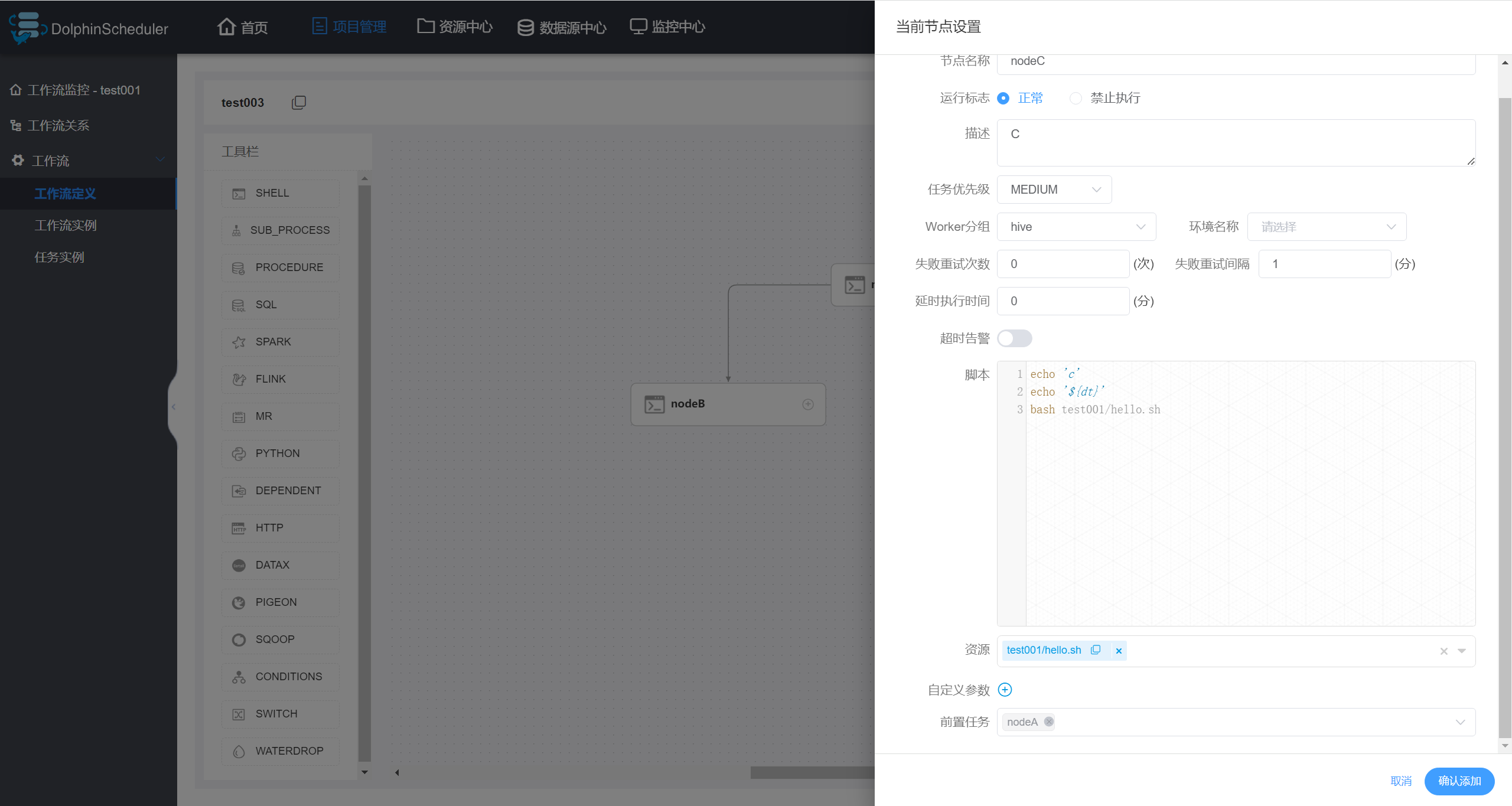
5.1 工作流传参
DolphinScheduler支持对任务节点进行灵活的传参,任务节点可通过${参数名}引用参数值。
由此可得,优先级由高到低:本地参数 > 全局参数 > 上游任务传递的参数。
5.1.5 参数优先级
3)结论
(1)本地参数 > 全局参数 > 上游任务传递的参数;
(2)多个上游节点均传递同名参数时,下游节点会优先使用值为非空的参数;
(3)如果存在多个值为非空的参数,则按照上游任务的完成时间排序,选择完成时间最早的上游任务对应的参数。
P119
5.2 引用依赖资源
P120
13.2 数据准备
启动hadoop、zookeeper、kafka、maxwell、f1、f2、f3。
P121
13.3 工作流调度实操
[2023-09-06 17:15:26,824] ERROR [Broker id=0] Received LeaderAndIsrRequest with correlation id 1 from controller 1 epoch 33 for partition __consumer_offsets-44 (last update controller epoch 33) but cannot become follower since the new leader -1 is unavailable. (state.change.logger)
[2023-09-06 17:15:26,824] ERROR [Broker id=0] Received LeaderAndIsrRequest with correlation id 1 from controller 1 epoch 33 for partition __consumer_offsets-32 (last update controller epoch 33) but cannot become follower since the new leader -1 is unavailable. (state.change.logger)
[2023-09-06 17:15:26,824] ERROR [Broker id=0] Received LeaderAndIsrRequest with correlation id 1 from controller 1 epoch 33 for partition __consumer_offsets-41 (last update controller epoch 33) but cannot become follower since the new leader -1 is unavailable. (state.change.logger)
[2023-09-06 19:32:27,802] ERROR [Controller id=0 epoch=34] Controller 0 epoch 34 failed to change state for partition __transaction_state-27 from OfflinePartition to OnlinePartition (state.change.logger)
kafka.common.StateChangeFailedException: Failed to elect leader for partition __transaction_state-27 under strategy OfflinePartitionLeaderElectionStrategy(false)
at kafka.controller.ZkPartitionStateMachine.$anonfun$doElectLeaderForPartitions$7(PartitionStateMachine.scala:424)
at scala.collection.mutable.ResizableArray.foreach(ResizableArray.scala:62)
at scala.collection.mutable.ResizableArray.foreach$(ResizableArray.scala:55)
at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:49)
at kafka.controller.ZkPartitionStateMachine.doElectLeaderForPartitions(PartitionStateMachine.scala:421)
at kafka.controller.ZkPartitionStateMachine.electLeaderForPartitions(PartitionStateMachine.scala:332)
at kafka.controller.ZkPartitionStateMachine.doHandleStateChanges(PartitionStateMachine.scala:238)
at kafka.controller.ZkPartitionStateMachine.handleStateChanges(PartitionStateMachine.scala:158)
at kafka.controller.PartitionStateMachine.triggerOnlineStateChangeForPartitions(PartitionStateMachine.scala:74)
at kafka.controller.PartitionStateMachine.triggerOnlinePartitionStateChange(PartitionStateMachine.scala:59)
at kafka.controller.KafkaController.onBrokerStartup(KafkaController.scala:536)
at kafka.controller.KafkaController.processBrokerChange(KafkaController.scala:1594)
at kafka.controller.KafkaController.process(KafkaController.scala:2484)
at kafka.controller.QueuedEvent.process(ControllerEventManager.scala:52)
at kafka.controller.ControllerEventManager$ControllerEventThread.process$1(ControllerEventManager.scala:130)
at kafka.controller.ControllerEventManager$ControllerEventThread.$anonfun$doWork$1(ControllerEventManager.scala:133)
at scala.runtime.java8.JFunction0$mcV$sp.apply(JFunction0$mcV$sp.java:23)
at kafka.metrics.KafkaTimer.time(KafkaTimer.scala:31)
at kafka.controller.ControllerEventManager$ControllerEventThread.doWork(ControllerEventManager.scala:133)
at kafka.utils.ShutdownableThread.run(ShutdownableThread.scala:96)
[2023-09-06 19:32:27,805] INFO [Controller id=0 epoch=34] Changed partition __consumer_offsets-22 from OfflinePartition to OnlinePartition with state LeaderAndIsr(leader=1, leaderEpoch=37, isr=List(1), zkVersion=37) (state.change.logger)
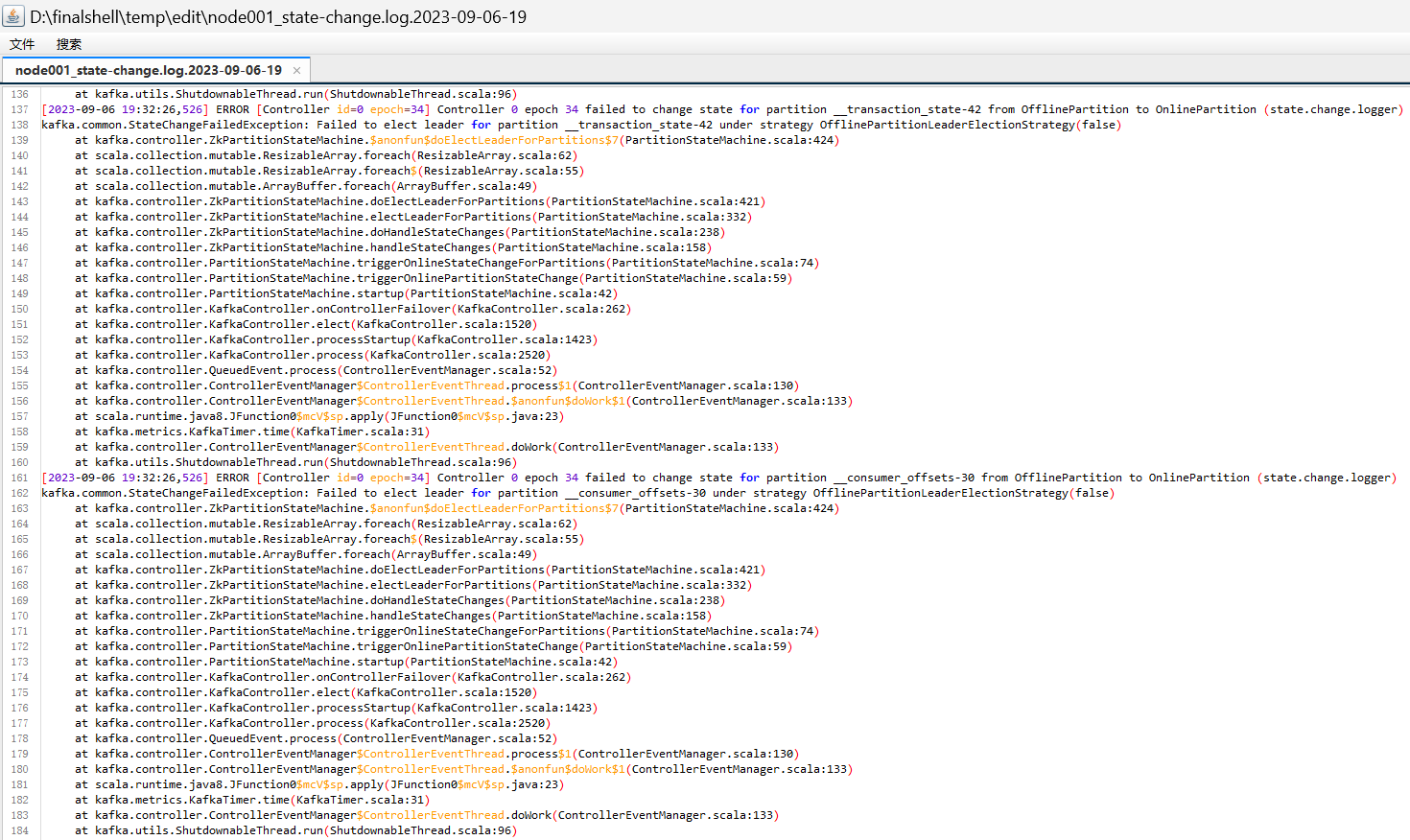
maxwell 报错: java.lang.RuntimeException: error: unhandled character set ‘utf8mb3‘
- maxwell 报错: java.lang.RuntimeException: error: unhandled character set ‘utf8mb3‘_你的482的博客-CSDN博客
- Maxwell安装使用 - 掘金
这个问题是因为MySQL从 5.5.3 开始,用 utf8mb4 编码来实现完整的 UTF-8,其中 mb4 表示 most bytes 4,最多占用4个字节。而原来的utf8则被utf8mb3则代替。 一种解决方案是,将MySQL降级,重新安装5.5.3以下的版本。 另一种方法则是修改maxwell源码。 解压打开,找到有问题的类:com.zendesk.maxwell.schema.columndef.StringColumnDef,加上能识别utf8mb3的语句,重新打包。 打包好的maxwell-1.19.0.jar替换maxwell/lib/maxwell-1.19.0.jar,重启即可。
启动hadoop、zookeeper、kafka、maxwell、f1.sh、f2.sh、f3.sh。
关闭采集的相关组件:kafka、flume(f1、f2、f3)、maxwell;启动hadoop、hive、zookeeper、dolphinscheduler ...
忘记启动zookeeper了...
Error starting ApplicationContext. To display the conditions report re-run your application with 'debug' enabled.
[ERROR] 2023-09-07 14:46:32.033 org.springframework.boot.SpringApplication:[843] - Application run failed
org.springframework.beans.factory.UnsatisfiedDependencyException: Error creating bean with name 'monitorServiceImpl': Unsatisfied dependency expressed through field 'registryClient'; nested exception is org.springframework.beans.factory.BeanCreationException: Error creating bean with name 'registryClient': Invocation of init method failed; nested exception is org.apache.dolphinscheduler.registry.api.RegistryException: zookeeper connect timeout...

datax将数据同步至hdfs里面,mysql_to_hdfs_full.sh;
数据导入到ods层中,hdfs_to_ods_db.sh、
ods_to_dwd.sh。
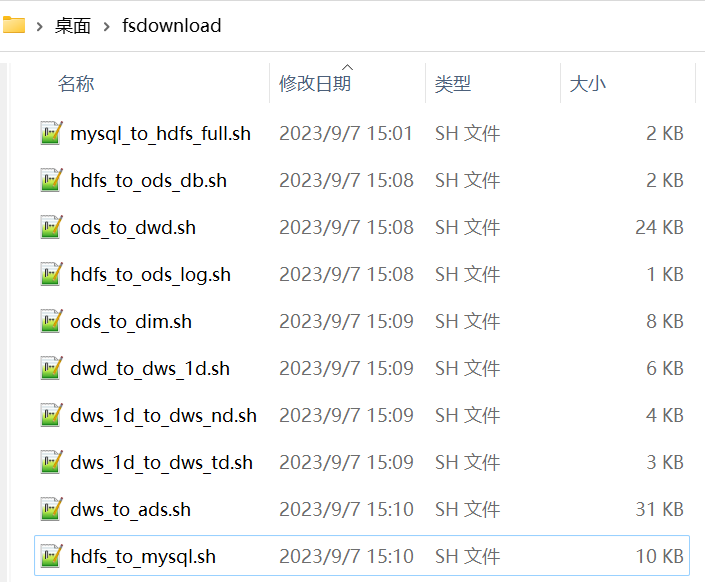
export HADOOP_HOME=/opt/module/hadoop/hadoop-3.1.3
export HADOOP_CONF_DIR=/opt/module/hadoop/hadoop-3.1.3/etc/hadoop
export SPARK_HOME=/opt/module/spark/spark-3.0.0-bin-hadoop3.2
export JAVA_HOME=/opt/module/jdk/jdk1.8.0_212
export HIVE_HOME=/opt/module/hive/hive-3.1.2
export DATAX_HOME=/opt/module/dataxexport PATH=$HADOOP_HOME/bin:$SPARK_HOME/bin:$JAVA_HOME/bin:$HIVE_HOME/bin:$DATAX_HOME/bin:$PATH
串联

P122【122_在线教育数仓开发回顾 04:23】

相关文章:
尚硅谷大数据项目《在线教育之离线数仓》笔记007
视频地址:尚硅谷大数据项目《在线教育之离线数仓》_哔哩哔哩_bilibili 目录 第12章 报表数据导出 P112 01、创建数据表 02、修改datax的jar包 03、ads_traffic_stats_by_source.json文件 P113 P114 P115 P116 P117 P118 P119 P120 P121 P122【122_在…...
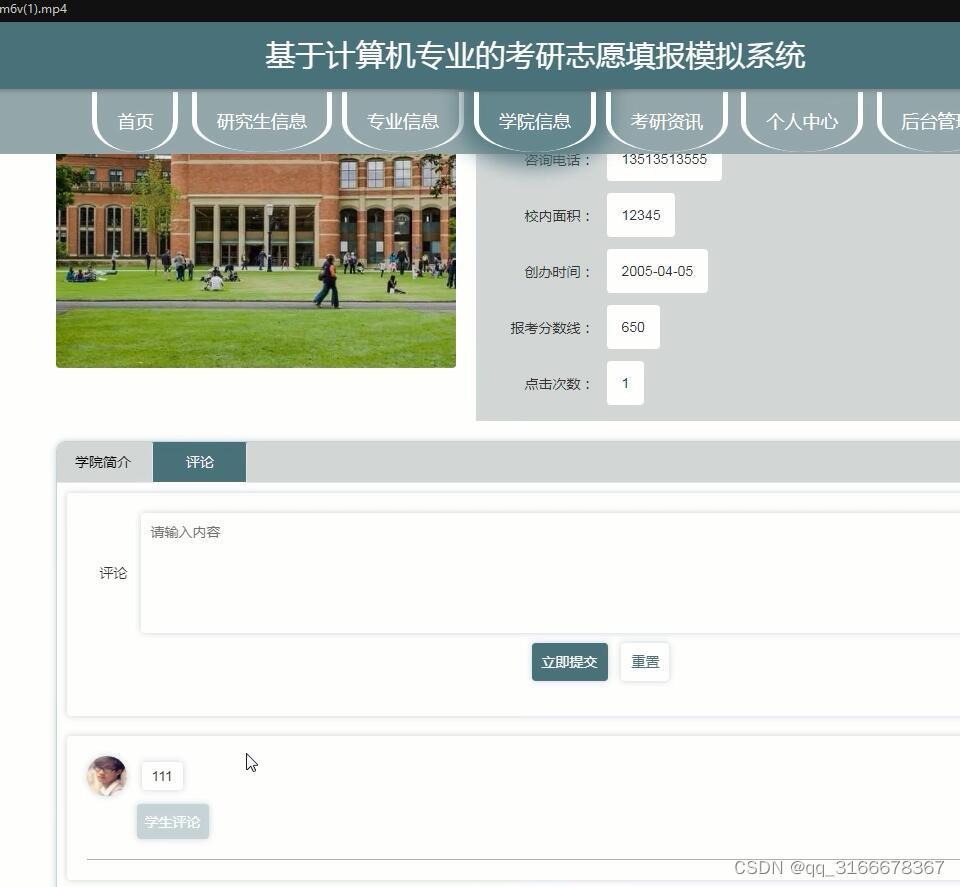
python考研志愿填报模拟系统vue
本系统提供给管理员对学生、院校、研究生信息、专业信息、学院信息等诸多功能进行管理。本系统对于学生输入的任何信息都进行了一定的验证,为管理员操作提高了效率,也使其数据安全性得到了保障。本考研志愿填报模拟系统以Django作为框架,B/S模…...

【LeetCode-面试经典150题-day20】
目录 70.爬楼梯 198.打家劫舍 139.单词拆分 322.零钱兑换 300.最长递增子序列 70.爬楼梯 题意: 假设你正在爬楼梯。需要 n 阶你才能到达楼顶。 每次你可以爬 1 或 2 个台阶。你有多少种不同的方法可以爬到楼顶呢? 提示: 1 < n < …...
回归与聚类算法系列②:线性回归
目录 1、定义与公式 2、应用场景 3、特征与目标的关系分析 线性回归的损失函数 为什么需要损失函数 损失函数 ⭐如何减少损失 4、优化算法 正规方程 梯度下降 优化动态图 偏导 正规方程和梯度下降比较 5、优化方法GD、SGD、SAG 6、⭐线性回归API 7、实例&#…...

springBoot:redis使用
需求:查询酒店房间列表 1、引入依赖 <!--redis--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId></dependency> 2、配置yml文件 server:port: 80…...

cmake 选择 vs编译器
QQ:2967732156 QQ交流群:622684416 // 编译VS2017版本的Tars, Release版本 // win32 cmake .. -G "Visual Studio 15 2017" -D CMAKE_BUILD_TYPERelease // x64 cmake .. -G "Visual Studio 15 2017 Win64" -D CMAKE_BUILD_…...

项目(智慧教室)第一部分:cubemx配置,工程文件的移植,触摸屏的检测,项目bug说明
第一章:需求与配置 一。项目需求 二。实现外设控制 注意: 先配置引脚,再配置外设。否则会出现一些不可预料的问题 1.时钟,串口,灯,蜂鸣器配置 (1)RCC配置为外部时钟,修…...

Springboot集成redis--不同环境切换
1.单机配置 spring:redis:mode: singletonhost: 127.0.0.1port: 6379lettuce:pool:max-active: 8 #连接池最大阻塞等待时间(使用负值表示没有限制max-idle: 2 #连接池中的最大空闲连接min-idle: 1 #连接池最大阻塞等待时间(使用负值表示没有限…...

稀疏数组的实现
文章目录 目录 文章目录 前言 一 什么是稀疏数组? 二 稀疏数组怎么存储数据? 三 稀疏数组的实现 总结 前言 大家好,好久不见了,这篇博客是数据结构的第一篇文章,望大家多多支持! 一 什么是稀疏数组? 稀疏数组(Sparse Array)是一种数据结构&a…...

表达式语言的新趋势!了解SPEL如何改变开发方式
文章首发地址 SpEL(Spring Expression Language)是一种表达式语言,由Spring框架提供和支持。它可以在运行时对对象进行解析和计算,用于动态地构建和操作对象的属性、方法和表达式。以下是SpEL的一些特性和功能: 表达式…...
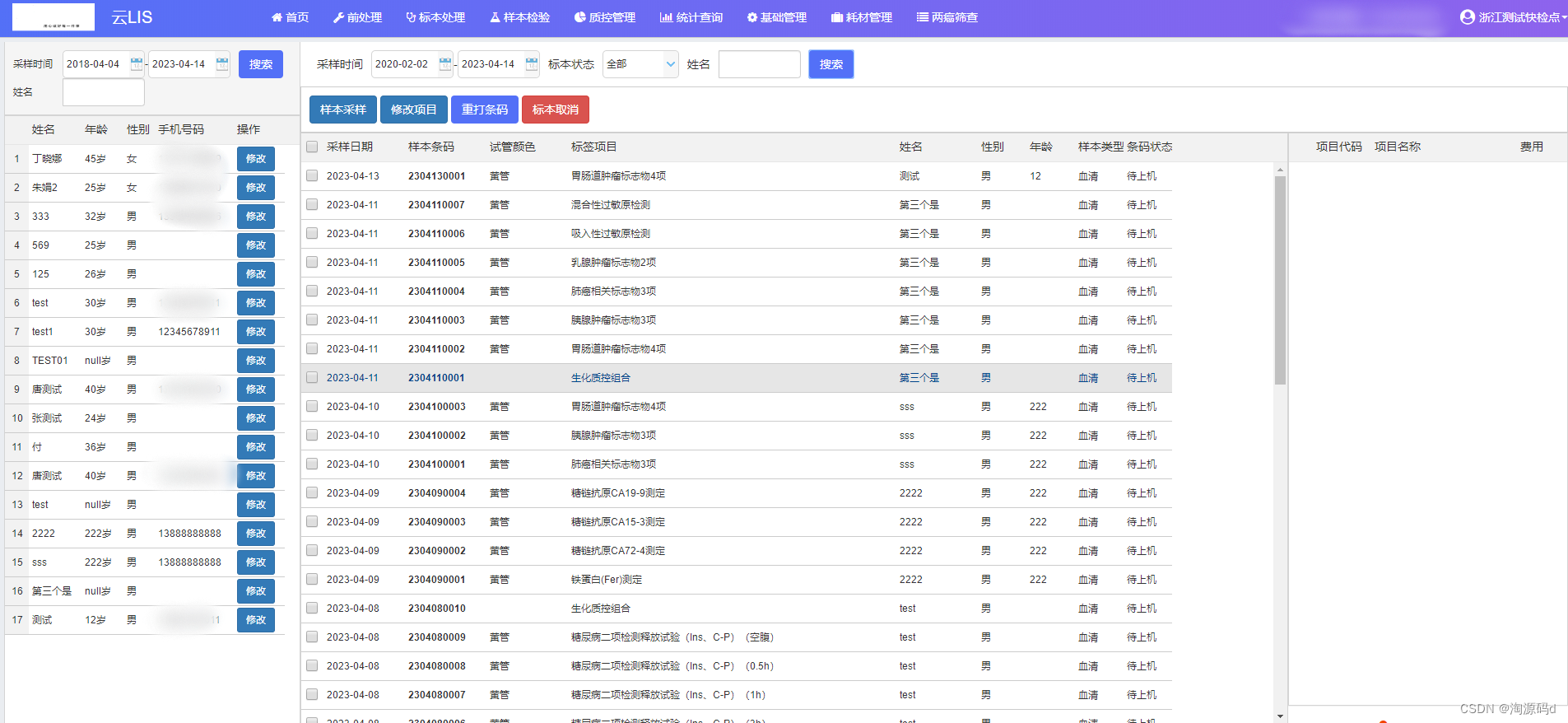
一套成熟的实验室信息管理系统(云LIS源码)ASP.NET CORE
一套成熟的实验室信息管理系统,集前处理、检验、报告、质控、统计分析、两癌等模块为一体的网络管理系统。它的开发和应用将加快检验科管理的统一化、网络化、标准化的进程。 LIS把检验、检疫、放免、细菌微生物及科研使用的各类分析仪器,通过计算机联…...

NPM使用技巧
NPM使用技巧 前言技巧全局模块位置PowerShell报错安装模块冲突 NPM介绍NPM命令使用方法基本命令模块命令查看模块运行命令镜像管理 常用模块rimrafyarn 前言 本文包含NodeJS中NPM包管理器的使用技巧,具体内容包含NPM介绍、NPM命令、常用模块等内容,还包…...

java学习一
目录 Java 与 C 的区别 Java程序是编译执行还是解释执行 编译型语言 解释型语言 Java 与 C 的区别 Java 是纯粹的面向对象语言,所有的对象都继承自 java.lang.Object,C 兼容 C ,不但支持面向对象也支持面向过程。Java 通过虚拟机从而实现…...

PV PVC in K8s
摘要 在Kubernetes中,PV(Persistent Volume)和PVC(Persistent Volume Claim)是用于管理持久化存储的重要资源对象。PV表示存储的实际资源,而PVC表示对PV的声明性要求。当应用程序需要使用持久化存储时&…...
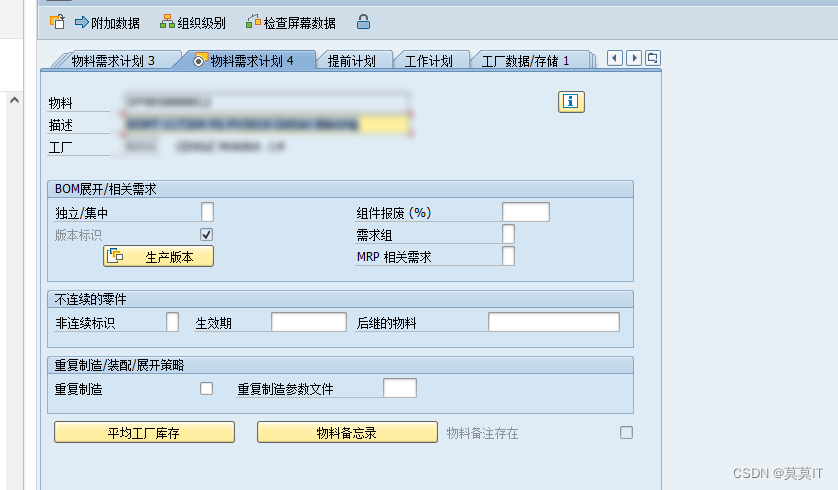
SAP-PP:基础概念笔记-5(物料主数据的MRP1~4视图)
文章目录 前言一、MRP1视图Base Unit of Measure(UoM)MRP 组采购组ABC 指示器Plant-Specific Material Status 特定的工厂物料状态MRP 类型 MRP TypeMRP 类型 MRP TypeMaster Production Scheduling(MPS) 主生产计划基于消耗的计划(CBP)再订货点Reorder-…...
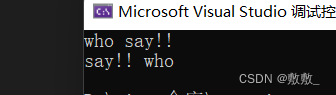
【C语言】初阶测试 (带讲解)
目录 ① 选择题 1. 下列程序执行后,输出的结果为( ) 2. 以下程序的输出结果是? 3. 下面的代码段中,执行之后 i 和 j 的值是什么() 4. 以下程序的k最终值是: 5. 以下程序的最终的输出结果为ÿ…...
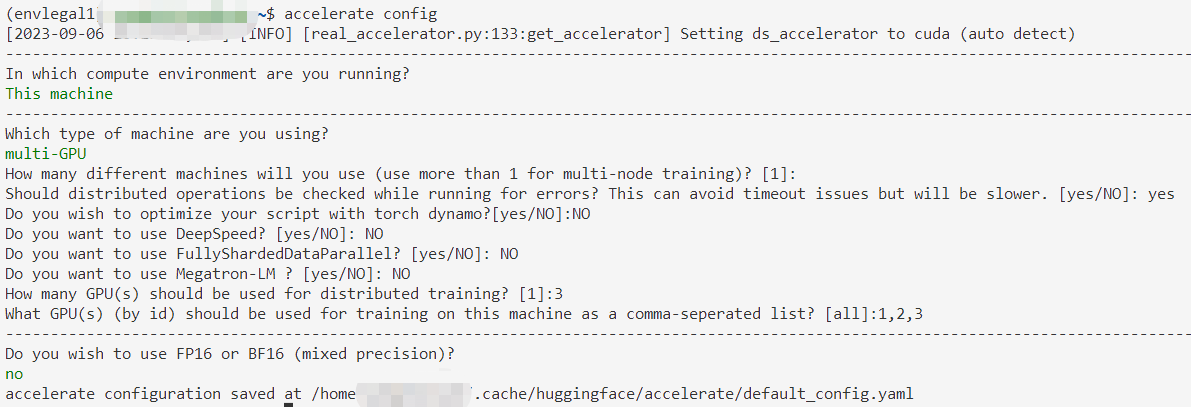
用huggingface.Accelerate进行分布式训练
诸神缄默不语-个人CSDN博文目录 本文属于huggingface.transformers全部文档学习笔记博文的一部分。 全文链接:huggingface transformers包 文档学习笔记(持续更新ing…) 本部分网址:https://huggingface.co/docs/transformers/m…...
unity 物体至视图中心以及新对象创建位置
如果游戏对象不在视野中心或在视野之外, 一种方法是双击Hierarchy中的对象名称 另一种是选中后按F 新建物体时对象的位置不是在坐标原点,而是在当前屏幕的中心...
船舶稳定性和静水力计算——绘图体平面图,静水力,GZ计算(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

Python 网页爬虫的原理是怎样的?
网页爬虫是一种自动化工具,用于从互联网上获取和提取信息。它们被广泛用于搜索引擎、数据挖掘、市场研究等领域。 网页爬虫的工作原理可以分为以下几个步骤:URL调度、页面下载、页面解析和数据提取。 URL调度: 网页爬虫首先需要一个初始的U…...
)
Java 语言特性(面试系列2)
一、SQL 基础 1. 复杂查询 (1)连接查询(JOIN) 内连接(INNER JOIN):返回两表匹配的记录。 SELECT e.name, d.dept_name FROM employees e INNER JOIN departments d ON e.dept_id d.dept_id; 左…...

深入剖析AI大模型:大模型时代的 Prompt 工程全解析
今天聊的内容,我认为是AI开发里面非常重要的内容。它在AI开发里无处不在,当你对 AI 助手说 "用李白的风格写一首关于人工智能的诗",或者让翻译模型 "将这段合同翻译成商务日语" 时,输入的这句话就是 Prompt。…...

Lombok 的 @Data 注解失效,未生成 getter/setter 方法引发的HTTP 406 错误
HTTP 状态码 406 (Not Acceptable) 和 500 (Internal Server Error) 是两类完全不同的错误,它们的含义、原因和解决方法都有显著区别。以下是详细对比: 1. HTTP 406 (Not Acceptable) 含义: 客户端请求的内容类型与服务器支持的内容类型不匹…...

《通信之道——从微积分到 5G》读书总结
第1章 绪 论 1.1 这是一本什么样的书 通信技术,说到底就是数学。 那些最基础、最本质的部分。 1.2 什么是通信 通信 发送方 接收方 承载信息的信号 解调出其中承载的信息 信息在发送方那里被加工成信号(调制) 把信息从信号中抽取出来&am…...

DBAPI如何优雅的获取单条数据
API如何优雅的获取单条数据 案例一 对于查询类API,查询的是单条数据,比如根据主键ID查询用户信息,sql如下: select id, name, age from user where id #{id}API默认返回的数据格式是多条的,如下: {&qu…...
)
【服务器压力测试】本地PC电脑作为服务器运行时出现卡顿和资源紧张(Windows/Linux)
要让本地PC电脑作为服务器运行时出现卡顿和资源紧张的情况,可以通过以下几种方式模拟或触发: 1. 增加CPU负载 运行大量计算密集型任务,例如: 使用多线程循环执行复杂计算(如数学运算、加密解密等)。运行图…...

Device Mapper 机制
Device Mapper 机制详解 Device Mapper(简称 DM)是 Linux 内核中的一套通用块设备映射框架,为 LVM、加密磁盘、RAID 等提供底层支持。本文将详细介绍 Device Mapper 的原理、实现、内核配置、常用工具、操作测试流程,并配以详细的…...

技术栈RabbitMq的介绍和使用
目录 1. 什么是消息队列?2. 消息队列的优点3. RabbitMQ 消息队列概述4. RabbitMQ 安装5. Exchange 四种类型5.1 direct 精准匹配5.2 fanout 广播5.3 topic 正则匹配 6. RabbitMQ 队列模式6.1 简单队列模式6.2 工作队列模式6.3 发布/订阅模式6.4 路由模式6.5 主题模式…...

音视频——I2S 协议详解
I2S 协议详解 I2S (Inter-IC Sound) 协议是一种串行总线协议,专门用于在数字音频设备之间传输数字音频数据。它由飞利浦(Philips)公司开发,以其简单、高效和广泛的兼容性而闻名。 1. 信号线 I2S 协议通常使用三根或四根信号线&a…...

MySQL 知识小结(一)
一、my.cnf配置详解 我们知道安装MySQL有两种方式来安装咱们的MySQL数据库,分别是二进制安装编译数据库或者使用三方yum来进行安装,第三方yum的安装相对于二进制压缩包的安装更快捷,但是文件存放起来数据比较冗余,用二进制能够更好管理咱们M…...