A Mathematical Framework for Transformer Circuits—Part (1)
A Mathematical Framework for Transformer Circuits
- 前言
- Summary of Results
- REVERSE ENGINEERING RESULTS
- CONCEPTUAL TAKE-AWAYS
- Transformer Overview
- Model Simplifications
- High-Level Architecture
- Virtual Weights and the Residual Stream as a Communication Channel
- VIRTUAL WEIGHTS
- SUBSPACES AND RESIDUAL STREAM BANDWIDTH
- Attention Heads are Independent and Additive
- Attention Heads as Information Movement
- OBSERVATIONS ABOUT ATTENTION HEADS
最近看到了一篇文章,从数学角度对Tranformer进行解读的文章《A Mathematical Framework for Transformer Circuits》,文章以结构较为简单的Transformer为例,通过对其进行逆向工程来实现数学层面的解析,并逐步推广至复杂结构的Transformer,很有启发性,特此记录。
主要是关于三个部分,【一种新的观点方式】
- Zero layer transformers
- One layer attention-only transformers
- Two layer attention-only transformers
主要为翻译,但不全是,有笔者自己的理解与解释。
前言
在本文中,我们试图对逆向工程变压器采取非常简化的步骤。鉴于现代语言模型令人难以置信的复杂性和规模,我们发现从尽可能简单的模型开始并从那里开始工作是最有成效的。我们的目标是发现简单的算法模式、图案或框架,这些模型、图案或框架随后可以应用于更大、更复杂的模型。具体来说,在本文中,我们将研究只有注意力块的两层或两层以下的变压器——这与GPT-3这样的大型现代变压器形成鲜明对比,GPT-3有96层,并将注意力块与MLP块交替使用。
我们发现,通过以一种新的但数学等效的方式概念化变压器的运行,我们能够理解这些小模型,并深入了解它们在内部的运行方式。特别值得注意的是,我们发现,我们称之为“感应头(induction heads)”的特定注意力头可以解释这些小模型中的上下文学习,而这些头只在至少有两个注意力层的模型中发展。我们还浏览了一些这些负责人对特定数据采取行动的例子。
在第一篇论文中,我们不试图将我们的见解应用于更大的模型,但在即将发表的一篇论文中,我们将表明,我们理解变压器的数学框架和感应头的概念,仍然至少部分地与更大、更现实的模型相关——尽管我们离能够完全反向工程此类模型还有很长的路要走。
Summary of Results
REVERSE ENGINEERING RESULTS
先来看本文主要结论
为了探索逆向工程 transformers 面临哪些挑战,研究者对几个 attention-only 的 toy 模型进行了逆向功能。
- 零层 transformers 模型的二元统计。研究者发现,二元表可以直接通过权重访问。
- 单层 attention-only transformers 是二元和 skip 三元模型的集合。同零层 transformers 一样,二元和 skip 三元表可以直接通过权重访问,无需运行模型。这些 skip 三元模型的表达能力惊人,包括实现一种非常简单的上下文内学习。
- 两层attention-only transformers是使用注意力头的组合来实现更复杂的算法。这些组合算法也可以直接从权重中检测到。值得注意的是,两层模型使用注意头组合来创建“感应头”,这是一种非常通用的上下文学习算法。
- 一层和两层attention-only transformers使用非常不同的算法来执行上下文学习。两层注意力头使用质量上更复杂的推理时间算法——特别是我们称之为感应头的特殊类型的注意力头——来执行上下文学习,形成一个与大型模型相关的重要过渡点。
CONCEPTUAL TAKE-AWAYS
我们发现,变压器架构的许多微妙细节要求我们以与InceptionV1 Circuits work
Thread: Circuits (作者之前的工作) 截然不同的方式进行逆向工程。我们将在下面的部分中解开其中的每一点,但现在简要总结一下。一旦进入具体的每部分,作者还将扩展在这里介绍的许多术语。
- 注意头可以理解为独立的操作,每个操作都输出一个结果,该结果被添加到残差流中。为了计算效率,注意头通常用替代的“concatenate and multiply”公式来描述,但这在数学上是等价的。
- 只注意的模型可以写成可解释的端到端函数的总和,将token映射到logits的变化。这些函数对应于通过模型的“路径”,如果冻结注意力模式,这些函数是线性的。
- 变压器具有大量的线性结构。只需拆分和并将矩阵链相乘,就可以学到很多东西。
- 注意头可以理解为有两个在很大程度上独立的计算:一个是计算注意力模式的QK(“查询键”)通路,一个是计算每个token在关注时如何影响输出的OV(“输出值”)通路。
- 键、查询和值向量可以被认为是低秩矩阵 W Q T W K , W O W V W_Q^TW_K,W_OW_V WQTWK,WOWV计算的中间结果,不提到它们也可描述transfromer。
- 注意力头的组合大大增加了transformer的表达能力。有三种不同的注意力头组成方式,对应于键、查询和值。键和查询组合与值组合非常不同。
- transformer的所有组件(the token embedding, attention heads, MLP layers, and unembedding)通过读取和写入残差流的不同子空间相互通信。与其分析残差流向量,不如将残差流分解为所有这些不同的通信通道,对应于通过模型的路径。
Transformer Overview
在我们尝试逆向工程transfromer之前,简要回顾一下transfromer的高级结构并描述下对它们的看法。
在许多情况下,我们发现以等效但非标准的方式重构变压器是有帮助的。机械可解释性要求我们将模型分解为人类可解释的部分。重要的第一步是找到表示形式,这样更容易对模型进行推理。在现代深度学习中,有充分的理由!非常强调计算效率,我们对模型的数学描述往往反映了如何编写高效代码来运行模型的决定。但是,当有许多等效的方法来表示相同的计算时,最人性化可解释的表示和最高效的表示可能会有所不同。
回顾transformer还将让我们在术语上保持一致,这些术语有时会有所不同。在这个过程中,我们还将介绍一些符号,但由于这个符号在许多章节中使用,我们在符号附录中提供了所有符号的详细描述,作为读者的简明参考。
Model Simplifications
为了以最干净的形式展示本文中的想法,作者专注于“toy transformer”,并进行了一些简化。
toy 类似一个大楼和一个大楼的模型,很形象的描述
在本文的大部分内容中,作者将做出非常实质性的改变:只专注于没有MLP层的“attention-only”Transformer。这么做的一部分原因是具有attention heads的数据流程提出了蒸馏数据流程(Distill circuits work)从未面临的问题,而且单独考虑具有attention heads的数据流程能够使作者更为优雅地处理这些问题。
High-Level Architecture
本文作者主要研究自回归的decoder-only transformer 语言模型。
Transformer模型可分为三部分:token embedding,一组residual blocks,token unembedding。其中,每个residual block由一个attention层和MLP层按序组成。attention层和MLP层均通过线形投影从residual stream中“读取”其输入,然后通过添加一个线形投影将其结果“写入”到residual stream。每个attention层由多个并行执行的heads组成。Transformer的高层架构图如图1. 所示。

Virtual Weights and the Residual Stream as a Communication Channel
在Transformer的高层架构图中可知,(上图很清晰了)每一层都将其输出的结果添加到“Residual Stream”,Residual Stream仅是其前面所有层的输出和原始embedding的加和。因为Residual Stream不会对其自身进行处理,并且所有层都通过其进行通信,所以作者将其视为一个通信通道。
Residual Stream是一个深度线形结构。在Residual Stream起始阶段,每一层都通过执行一个任意的线性转换来从residual stream中“读取”信息,此外,在执行加法操作前,每一层都通过执行另一个任意的线性转换来将其输出“写入”到residual stream中。Residual Stream这种线性、累加结构具有很多重要的意义。其中一个基础的意义就是residual stream没有“privileged basis”,可以通过轮换所有与residual stream交互的矩阵来轮换residual stream,并且模型的行为不会被改变。
residual stream就是指从embed—>unembed的直接过程,而不经过任何block。原文有个很可爱的小图。
作者在这里特别强调了线形结构,在神经网络结构中完全线性的Residual Stream是极其不寻常的,即使是ResNet这种被广泛使用的、与Residual Stream最为相似的网络结构,也在其Residual Stream结构上,或访问Residual Stream的数据时使用了非线性激活函数。
Residual Stream结构中忽略了每一层开始时的层归一化,但是由于层归一化是由一个常数标量决定的,所以层归一化是一个常数仿射变换,并且可以合并至线性变换。
VIRTUAL WEIGHTS
Residual Stream是线性的一个特别有用的结果,即可以认为隐式的虚拟权重可以在residual stream中通过乘法操作得到两个层的交互,以此直接连接任意两个层,即使两个层之间隔着多个层。虚拟权重是一个层的输出权重与另一个层的输入权重的乘积,通过这种方式描述了后一层(被指向层)读入由前一层(指向层)写入的信息的程度。

SUBSPACES AND RESIDUAL STREAM BANDWIDTH
residual stream是一个高维度的向量空间。在小模型中可能是数百个维度;在大模型中可以达到数万。这意味着Residual Stream结构中的层可以通过将信息存储在不同的子空间来将不同的信息发送至不同的层。这一点在attention heads中极其重要,因为每个独立的head在相对较小的子空间上运行(通常是64或128维),在heads之间不发生交互的情况下可以很容易地将信息写入完全不相交的子空间。
一但信息写入到了某个子空间中,信息就会一直存储在该子空间,直到另一个层主动删除该信息。从这个角度来看,redidual stream的维度就像“内存”或“带宽”。原始的token embeddings和unembedding主要和redidual stream维度中相对小的一部分交互。这就留下了大多数维度来存储其他层的信息。
Residual Stream带宽通常应该较大。因为Residual Stream带宽中有更多的“计算维度”,例如,神经元和attention head结果维度,远多于用于移动信息的维度。仅是一个单独的MLP层,其神经元的数目是residual stream维度的四倍。因此,例如在一个50层transformer中的第25层中,residual stream中神经元数目是其之前维度的100倍,并且尝试与数目是其之后维度100倍的神经元进行通信,可能采用叠加方式进行通信。作者将这类tensor称为“bottleneck activations”,并且认为对其进行解释非常具有挑战性。这就是作者尝试以虚拟权重的方式将residual stream中发生的不同通信streams分开而不是直接研究这些通信streams的主要原因。
也许是因为对residual stream带宽的高需求,作者观察到一些迹象表明,某些MLP神经元和attention heads可能会担任一种“记忆管理”(“memory management”)的角色,通过读入信息和写出负面信息来清除其它层设置的residual stream维度。
一些MLP神经元的输入权重和输出权重之间具有负的余弦相似度,这可能表明这些神经元将从residual stream中删除信息。类似地,一些attention heads在其 W O W V W_OW_V WOWV矩阵中具有较大的负特征值,并且主要关注当前token,这些attention heads可能作为删除信息的一种机制。值得注意的是,尽管这些可能是“记忆管理”(“memory management”)删除信息的通用机制,但是它们也可能是有条件地删除信息的机制,仅在某些条件下运行。

Attention Heads are Independent and Additive
如上文所述,作者认为Transformer的attention层是一些完全独立的attention heads h ∈ H h\in H h∈H
组成(这点其实不难理解,跟一般的MSA认知一致),这些heads 完全并行的运行,并且每个head都将其输出添加会residual stream。但这并不是Transformer层的典型呈现方式,而且它们的等价性并不明显。
先来看普遍认知的结构,nlp和cv其实都一致
在Transforer的原始文献中[2],attention层的输出表示为堆叠的向量 r h 1 , r h 2 , . . . r^{h_1},r^{h_2},... rh1,rh2,... 和输出矩阵 W O H W_O^H WOH的乘积。如果为每个head将 W O H W_O^H WOH分割为尺寸相等的多个块,那么可以得到如下公式 W O H [ r h 1 r h 2 … ] = [ W O h 1 , W O h 2 , … ] ⋅ [ r h 1 r h 2 … ] = ∑ i W O h i r h i (1) W_{O}^{H}\left[\begin{array}{c} r^{h_{1}} \\ r^{h_{2}} \\ \ldots \end{array}\right]=\left[W_{O}^{h_{1}}, W_{O}^{h_{2}}, \ldots\right] \cdot\left[\begin{array}{c} r^{h_{1}} \\ r^{h_{2}} \\ \ldots \end{array}\right]=\sum_{i} W_{O}^{h_{i}} r^{h_{i}} \tag{1} WOH rh1rh2… =[WOh1,WOh2,…]⋅ rh1rh2… =i∑WOhirhi(1)公式(1)揭示了将 W O H W_O^H WOH拆分后等价于独立地执行各个heads,将每个head乘以各自的输出矩阵,并将结果添加至residual stream。在实现上述公式时,拼接定义通常是首选,因为能够生成一个更大、计算效率更高的矩阵乘法。但是为了从理论上理解Transformers,作者在此更倾向于将其视为独立的加法。[we prefer to think of them as independently additive.]
Attention Heads as Information Movement
如果各个attention heads独立地运行,那么它们将会产生什么样的效果?attention heads的基本行为是移动信息。它们从一个token的residual stream中读取信息,然后将其写入到另一个token的residual stream。从这一章节中得到的主要观察结果是:从其中移动信息的那些tokens,与将被移动的“读取”到的信息以及如何“写入”到目的地是完全分开的。

为了验证这一点,需要以非标准的方式实现attention。给定一个注意力模式,计算attention head的输出通常分为如下三步:
- 从residual stream中为每个token计算value向量 v i = W V x i v_i = W_Vx_i vi=WVxi
- 依据注意力模式,通过线性组合value向量来计算“结果向量” r i = ∑ A i , j v j r_i = \sum A_{i,j}v_j ri=∑Ai,jvj
- 最后,为每个token计算head的输出向量 h ( x ) i = W O r i h(x)_i=W_Or_i h(x)i=WOri
如前文所述,输出矩阵的乘法通常实现为应用于所有heads结果的拼接的一个矩阵乘法,与上述步骤是等效的。
上述的每一步都可以通过矩阵乘法实现,但是作者并未将上述步骤合并为一个步骤,原因如下。
假设 x x x 是一个 2d 矩阵,由表示每个token的向量组成,并且将在不同的边相乘。 W V W_V WV和
W O W_O WO 乘以“表示每个token的向量”(“vector per token”)的边【该边的每个元素表示一个token】,A乘以“位置”(“position”)的边。Tensors能够提供更为自然的一种语言来描述矩阵之间的这种映射关系。将计算attention head输出分为三步的一个动机是可能有助于作者表达矩阵到矩阵之间的线性映射: [ n c o n t e x t , d m o d e l ] → [ n c o n t e x t , d m o d e l ] [n_{context}, d_{model}]\to [n_{context}, d_{model}] [ncontext,dmodel]→[ncontext,dmodel]。数学上称这种线性映射为“(2,2)-tensors”【其实也就和transformer block中的输入输出】。也因此,tensors自然是描述这种变换的语言。
后面会用到一些张量积的表示 Tensor Product / Kronecker Product Notation ⊗ \otimes ⊗
记住就好,定义而已
乘积符合混合乘积性质: ( A ⊗ B ) ( C ⊗ D ) = A C ⊗ B D (A\otimes B)(C\otimes D)=AC\otimes BD (A⊗B)(C⊗D)=AC⊗BD
Left-right multiplying:将 x 乘以一个张量积 A ⊗ W A⊗W A⊗W 等价于同时左乘、右乘: ( A ⊗ W ) x = A x W T (A⊗W)x=AxW^T (A⊗W)x=AxWT。当将它们相加时,等同于将乘积的结果进行相加: ( A 1 ⊗ W 1 + A 2 ⊗ W 2 ) x = A 1 x W 1 T + A 2 x W 2 T (A_1⊗W_1+A_2⊗W_2)x=A_1xW_1^T+A_2xW_2^T (A1⊗W1+A2⊗W2)x=A1xW1T+A2xW2T
使用张量积可以将使用注意力的过程描述为:

What about the attention pattern?
注意力模式:通常计算keys k i = W K x i k_i=W_Kx_i ki=WKxi ,计算queries q i = W Q x i q_i=W_Qx_i qi=WQxi ,通过每个key向量和query向量的点积计算注意力模式 A = s o f t m a x ( q T k ) A=softmax(q^Tk) A=softmax(qTk)。也可以不引入key和query直接计算 A = s o f t m a x ( x T W Q T W K x ) A=softmax(x^TW_Q^TW_Kx) A=softmax(xTWQTWKx).
尽管这个公式在数学上是等价的,但是实际中如果采用这种方式实现注意力,例如,乘以 W O W V W_OW_V WOWV或 W Q T W K W_Q^TW_K WQTWK ,其计算效率极低。
OBSERVATIONS ABOUT ATTENTION HEADS
作者以上述方式重写了attention head,这么做可以揭示出许多以前难以观察到的结构:
- Attention heads将信息从一个token的residual stream移动到另一个token的residual stream。
- 由此可得到一个推论:residual stream向量空间通常被解释为“上下文词嵌入”(“contextual word embedding”),其通常具有与从其它tokens复制的信息相对应的线性子空间,而不是直接与当前token有关。
- 一个attention head实际上是采用了两个线性操作,A和 W O W V W_OW_V WOWV,它们操作不同的维度并且独立地运行,
- A 控制token的信息从哪个token移动哪个token。
- W O W V W_OW_V WOWV控制从源token中读取哪些信息,以及如何将其写入目标token。
当移动信息时, W O V = W O W V W_{OV}=W_OW_V WOV=WOWV 管理attention heads从哪个residual stream子空间读写。通过奇异值分解 U S V = W O V USV=W_{OV} USV=WOV 可以很好地理解这一观点。由于 d h e a d < d m o d e l d_{head} < d_{model} dhead<dmodel, W O V W_{OV} WOV 是低秩的,并且S中只有对角线的一个子集是非零的。右边的奇异向量 V描述了被关注的residual stream中哪个子空间被“读入”(以某种方式存储为value向量),而左奇异向量 U描述了被“读入”的子空间被“写入”到目标residual stream的哪个子空间中。
- A这个等式中唯一的非线性部分(由softmax计算得到)。这就意味着如果固定这个注意力模式,attention heads将执行线性操作。这也意味着,在不固定 A 时,attention heads在某种意义上是“半线性”的,因为每个token的线性操作时恒定的。
- W Q W_Q WQ和 W K W_K WK通常一起被应用,从不是独立的。同样, W O W_O WO和 W V W_V WV 也通常一起被应用。
- 尽管它们被参数化为单独的矩阵,但是 W Q T W K W_Q^TW_K WQTWK和 W O W V W_OW_V WOWV总是可以被认为是单独的低秩矩阵。
- Keys,queries以及alue向量在某些意义上是肤浅的。它们是计算这些低秩矩阵的中间副产品。人们可以很容易地重新参数化低秩矩阵的两个因子以创建不同的向量,但是仍然保持功能不变。
- 因为 W Q T W K W_Q^TW_K WQTWK和 W O W V W_OW_V WOWV总是一起被应用,所以作者定义了表示这些组合矩阵的变量, W O V = W O W V W_{OV}=W_OW_V WOV=WOWV和 W Q K = W Q T W K W_{QK}=W_Q^TW_K WQK=WQTWK。
- 观察attention heads的乘积发现,乘积的行为和attention heads自身很像。根据分配率,
( A h 2 ⊗ W O V h 2 ) ⋅ ( A h 1 ⊗ W O V h 1 ) = ( A h 2 A h 1 ) ⊗ ( W O V h 2 W O V h 1 ) (A^{h_2}⊗W_{OV}^{h_2})⋅(A^{h_1}⊗W_{OV}^{h_1})=(A^{h_2}A^{h_1})⊗(W_{OV}^{h_2}W_{OV}^{h_1}) (Ah2⊗WOVh2)⋅(Ah1⊗WOVh1)=(Ah2Ah1)⊗(WOVh2WOVh1) 。这个乘积的结果在作用上可以视为一个attention head,其注意力模式是由两个heads A h 2 A h 1 A^{h_2}A^{h_1} Ah2Ah1 和一个输出值矩阵 W O V h 2 W O V h 1 W_{OV}^{h_2}W_{OV}^{h_1} WOVh2WOVh1 组成。作者将这些称为“虚拟注意力头”,稍后将进行更深入的讨论。
至此前言结束,下面就是分析每种模式
相关文章:
A Mathematical Framework for Transformer Circuits—Part (1)
A Mathematical Framework for Transformer Circuits 前言Summary of ResultsREVERSE ENGINEERING RESULTSCONCEPTUAL TAKE-AWAYS Transformer OverviewModel SimplificationsHigh-Level ArchitectureVirtual Weights and the Residual Stream as a Communication ChannelVIRTU…...
关于Maven中使用idea发布java项目的步骤:
1.新建Maven模块:...
如何使用ArcGIS Earth制作地图动画视频
通常情况下,我们所看到的地图都是静态展示,对于信息的传递,视频比图片肯定会更加丰富,所以制作地图动画视频更加有利于信息的传递,这里我们讲解一下ArcGIS Earth 2.0如何制作地图动画视频,希望能对你有所帮…...
【Linux成长史】Linux基本指令大全
🎬 博客主页:博主链接 🎥 本文由 M malloc 原创,首发于 CSDN🙉 🎄 学习专栏推荐:LeetCode刷题集 数据库专栏 初阶数据结构 🏅 欢迎点赞 👍 收藏 ⭐留言 📝 如…...

ChatGPT:深度学习和机器学习的知识桥梁
目录 ChatGPT简介 ChatGPT的特点 ChatGPT的应用领域 ChatGPT的工作原理 与ChatGPT的交互 ChatGPT的优势 ChatGPT在机器学习中的应用 ChatGPT在深度学习中的应用 总结 近年来,随着深度学习技术的不断发展,自然语言处理技术也取得了显著的进步。其…...

python-基本数据类型-笔记
数字型digit:int整型 float浮点型 complex复数 布尔型bool:True False 字符串str:用一对引号(单、双、三单、三双等引号)作为定界线 列表list:[ ] 元组tuple:( ) 字典dict:{ } 由键值…...

如何使用API数据接口给自己创造收益
使用API数据接口创造收益的方法有很多,以下是一些常见的方法,并附有代码示例: 一、数据分析与预测 通过获取API数据接口中的大量数据,我们可以进行深入的数据分析,并利用这些数据来预测未来的趋势和行为。例如&#…...
第三方软件信息安全测评服务范围
安全测试 第三方软件信息安全cnas资质测评服务范围: 1、信息安全风险评估 依据《GB/T 20984-2007 信息安全技术信息安全风险评估规范》,通过风险评估项目的实施,对信息系统的重要资产、资产所面临的威胁、资产存在的脆弱性、已采取的防护措…...

测试开发 | Java 接口自动化测试首选方案:REST Assured 实践
1 . 初识 REST Assured 在 REST Assured 的官方 GitHub 上有这样一句简短的描述: Java DSL for easy testing of REST services 简约的 REST 服务测试 Java DSL 1.1 优点: REST Assured 官方的 README 第一句话对进行了一个优点的概述,总的…...
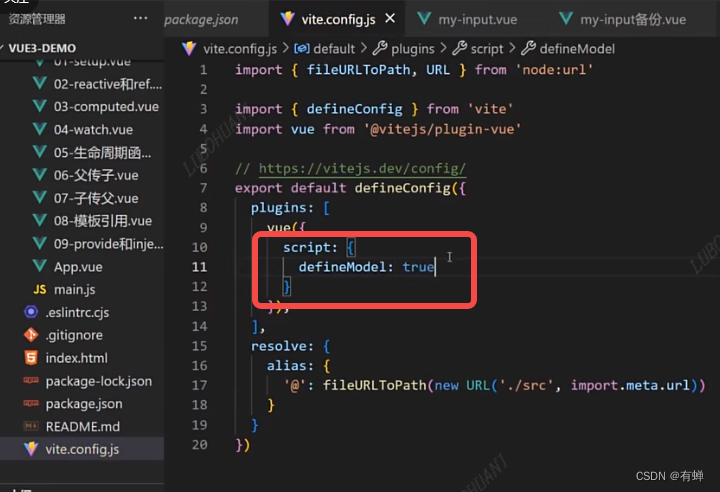
vue3:13、Vue3.3新特性-defineModel
旧版本的语法 新版本语法...

如何理解C++中的void*
1.什么是void* 首先void*中的void代表一个任意的数据类型,"星号"代表一个指针,所以其就是一个任意数据类型的指针。 其实就是一个未指定跳跃力的指针。 那void*的跳跃力又什么时候指定?在需要使用的时候指定就可以了,…...
MVC,MVP,MVVM的理解和区别
MVC MVC ,早期的开发架构,在安卓里,用res代表V,activity代表Controller层,Model层完成数据请求,更新操作,activity完成view的绑定,以及业务逻辑的编写,更新view…...
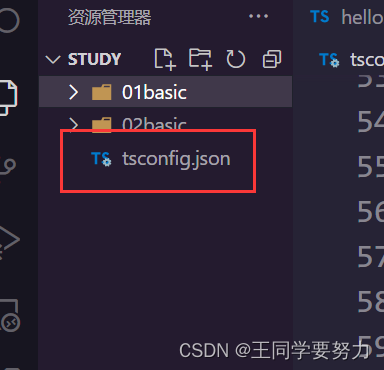
【TypeScript】一直提示 :无法重新声明块范围变量
【TypeScript】一直提示 :无法重新声明块范围变量 问题描述:在VSCode中编写ts代码时,编写保存完之后,通过tsc 文件名.ts编译就会看到变量名下面出现了红色的波浪线,提示的内容是无法重新声明块范围变量。 解决方法&am…...

【python自动化】七月PytestAutoApi开源框架学习笔记(一)
前言 本篇内容为学习七月大佬开源框架PytestAutoApi记录的相关知识点,供大家学习探讨 项目地址:https://gitee.com/yu_xiao_qi/pytest-auto-api2 阅读本文前,请先对该框架有一个整体学习,请认真阅读作者的README.md文件。 本文…...

Python学习 -- logging模块
logging 模块是 Python 中用于记录日志的标准库,它提供了丰富的功能,可以帮助开发者进行日志记录和管理。以下是关于logging模块的详细使用方式,包括日志级别、处理流程、Logger 类、Handler 类、Filter 类、Formatter 类以及模块中常用函数等…...

【socket】getaddrinfo、getsockname、getpeername对比
这三个函数都是在网络编程中用来获取地址信息的,但是它们的使用场景和功能有所不同。getaddrinfo(): 这个函数主要用于将一个主机名(或者 IP 地址)和端口号转换成适用于 socket() 函数的一个或多个套接字地址结构。它能够处理 IPv4 和 IPv6 地…...
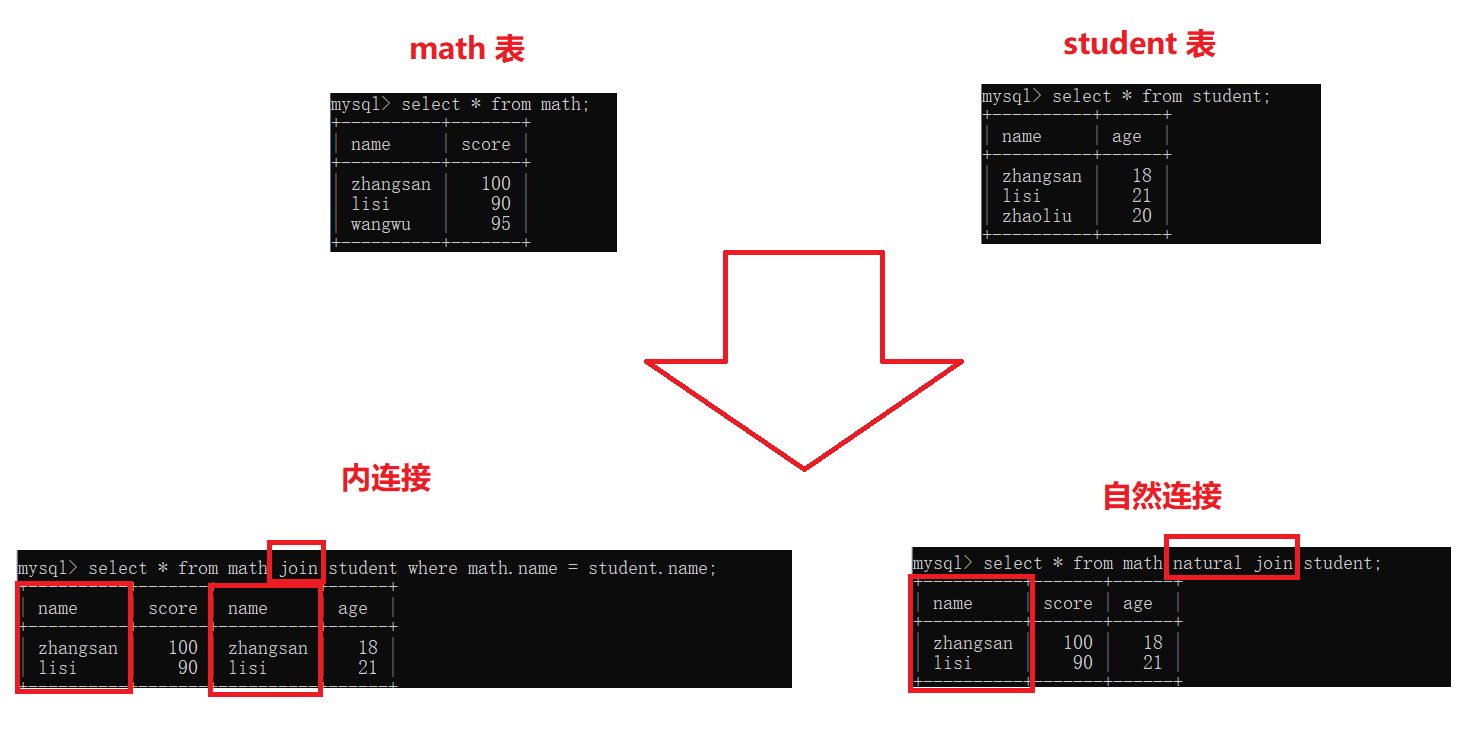
【MySQL】表的增删改查(进阶)
表的增删改查(进阶) 一. 数据库约束1. 约束类型2. NULL约束3. UNIQUE:唯一约束4. DEFAULT:默认值约束5. PRIMARY KEY:主键约束6. FOREIGN KEY:外键约束7. CHECK约束 二. 表的设计1. 一对一2. 一对多3. 多对…...

关于安卓13中Android/data目录下的文件夹只能查看无法进行删改的问题
前言 因为升级了安卓13,然后有个app需要恢复数据,打算和以前一样直接删除Android/data下对应目录再添加,结果不行,以下是结合网上以及自己手机情况来做的一种解决方案。 解决 准备: 待恢复app(包名com.…...
Vulnhub: Masashi: 1靶机
kali:192.168.111.111 靶机:192.168.111.236 信息收集 端口扫描 nmap -A -sC -v -sV -T5 -p- --scripthttp-enum 192.168.111.236查看80端口的robots.txt提示三个文件 snmpwalk.txt内容,tftp服务在1337端口 sshfolder.txt内容,…...
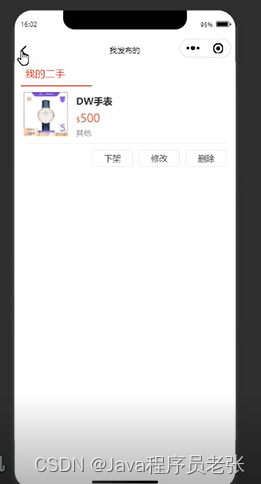
校园二手物品交易系统微信小程序设计
系统简介 本网最大的特点就功能全面,结构简单,角色功能明确。其不同角色实现以下基本功能。 服务端 后台首页:可以直接跳转到后台首页。 用户信息管理:管理所有申请通过的用户。 商品信息管理:管理校园二手物品中…...

2025盘古石杯决赛【手机取证】
前言 第三届盘古石杯国际电子数据取证大赛决赛 最后一题没有解出来,实在找不到,希望有大佬教一下我。 还有就会议时间,我感觉不是图片时间,因为在电脑看到是其他时间用老会议系统开的会。 手机取证 1、分析鸿蒙手机检材&#x…...

unix/linux,sudo,其发展历程详细时间线、由来、历史背景
sudo 的诞生和演化,本身就是一部 Unix/Linux 系统管理哲学变迁的微缩史。来,让我们拨开时间的迷雾,一同探寻 sudo 那波澜壮阔(也颇为实用主义)的发展历程。 历史背景:su的时代与困境 ( 20 世纪 70 年代 - 80 年代初) 在 sudo 出现之前,Unix 系统管理员和需要特权操作的…...

鱼香ros docker配置镜像报错:https://registry-1.docker.io/v2/
使用鱼香ros一件安装docker时的https://registry-1.docker.io/v2/问题 一键安装指令 wget http://fishros.com/install -O fishros && . fishros出现问题:docker pull 失败 网络不同,需要使用镜像源 按照如下步骤操作 sudo vi /etc/docker/dae…...

CMake 从 GitHub 下载第三方库并使用
有时我们希望直接使用 GitHub 上的开源库,而不想手动下载、编译和安装。 可以利用 CMake 提供的 FetchContent 模块来实现自动下载、构建和链接第三方库。 FetchContent 命令官方文档✅ 示例代码 我们将以 fmt 这个流行的格式化库为例,演示如何: 使用 FetchContent 从 GitH…...

项目部署到Linux上时遇到的错误(Redis,MySQL,无法正确连接,地址占用问题)
Redis无法正确连接 在运行jar包时出现了这样的错误 查询得知问题核心在于Redis连接失败,具体原因是客户端发送了密码认证请求,但Redis服务器未设置密码 1.为Redis设置密码(匹配客户端配置) 步骤: 1).修…...

【Nginx】使用 Nginx+Lua 实现基于 IP 的访问频率限制
使用 NginxLua 实现基于 IP 的访问频率限制 在高并发场景下,限制某个 IP 的访问频率是非常重要的,可以有效防止恶意攻击或错误配置导致的服务宕机。以下是一个详细的实现方案,使用 Nginx 和 Lua 脚本结合 Redis 来实现基于 IP 的访问频率限制…...

并发编程 - go版
1.并发编程基础概念 进程和线程 A. 进程是程序在操作系统中的一次执行过程,系统进行资源分配和调度的一个独立单位。B. 线程是进程的一个执行实体,是CPU调度和分派的基本单位,它是比进程更小的能独立运行的基本单位。C.一个进程可以创建和撤销多个线程;同一个进程中…...

离线语音识别方案分析
随着人工智能技术的不断发展,语音识别技术也得到了广泛的应用,从智能家居到车载系统,语音识别正在改变我们与设备的交互方式。尤其是离线语音识别,由于其在没有网络连接的情况下仍然能提供稳定、准确的语音处理能力,广…...

【深度学习新浪潮】什么是credit assignment problem?
Credit Assignment Problem(信用分配问题) 是机器学习,尤其是强化学习(RL)中的核心挑战之一,指的是如何将最终的奖励或惩罚准确地分配给导致该结果的各个中间动作或决策。在序列决策任务中,智能体执行一系列动作后获得一个最终奖励,但每个动作对最终结果的贡献程度往往…...
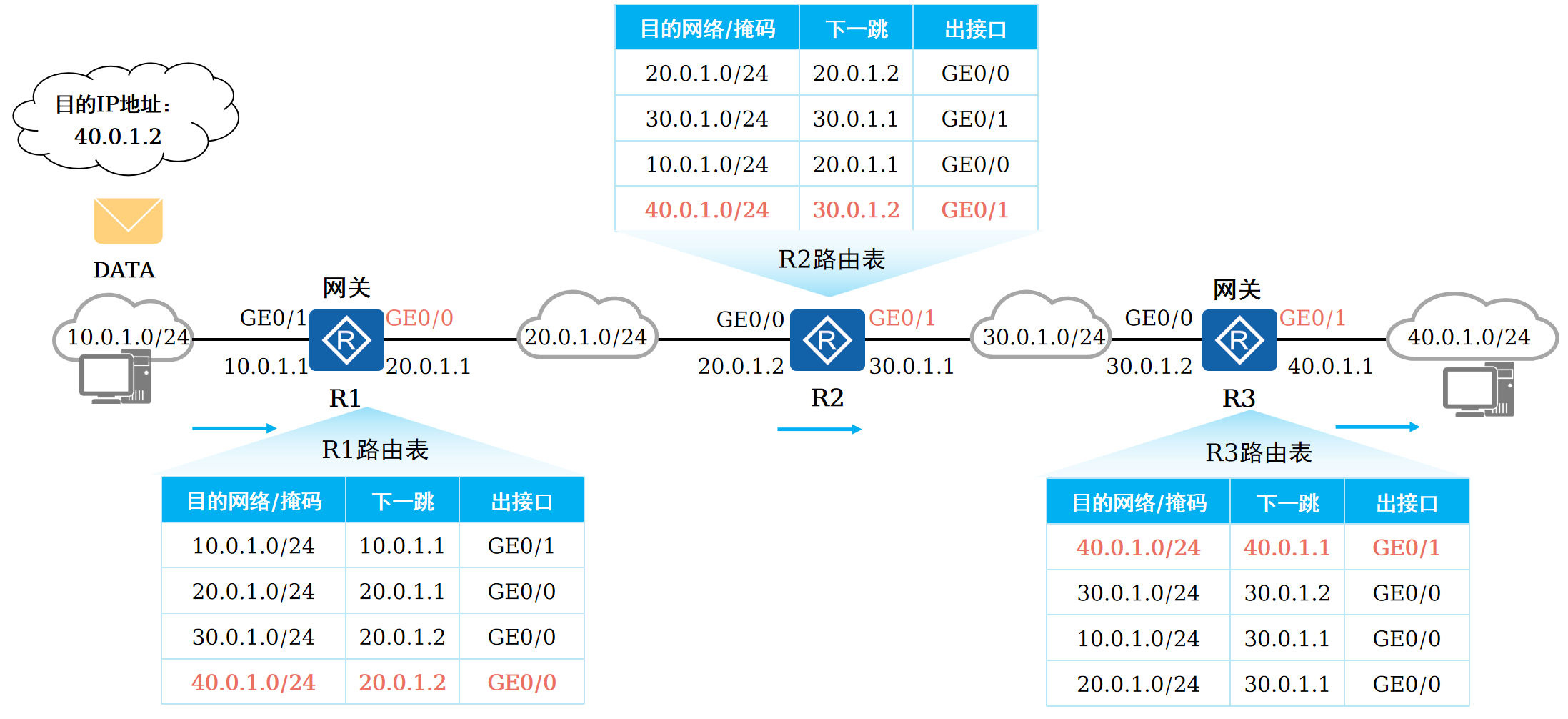
路由基础-路由表
本篇将会向读者介绍路由的基本概念。 前言 在一个典型的数据通信网络中,往往存在多个不同的IP网段,数据在不同的IP网段之间交互是需要借助三层设备的,这些设备具备路由能力,能够实现数据的跨网段转发。 路由是数据通信网络中最基…...