Java学习笔记之----I/O(输入/输出)二
【今日】
孩儿立志出乡关,学不成名誓不还。

文件输入/输出流
程序运行期间,大部分数据都在内存中进行操作,当程序结束或关闭时,这些数据将消失。如果需要将数据永久保存,可使用文件输入/输出流与指定的文件建立连接,将需要的数据永久保存到文件中。
一 FilelnputStream与FileOutputStream类
文件字节流
FileInputStream类与FileOutputStream类都用来操作磁盘文件。如果用户的文件读取需求比较简单,则可以使用FileInputStream类,该类继承自InputStream类。FileOutputStream类与 FilelnputStream类对应,提供了基本的文件写入能力。FileOutputStream类是OutputStream类的子类。
FileInputStream类常用的构造方法如下:
😶🌫️FileInputStream(String name)
😶🌫️FileInputStream(File file)第一个构造方法使用给定的文件名name创建一个 FilelnputStream对象,第二个构造方法使用File对象创建 FileInputStream对象。第一个构造方法比较简单,但第二个构造方法允许在把文件连接输入流之前对文件做进一步分析。
FileOutputStream类有与FileInputStream类相同的参数构造方法,创建一个FileOutputStream对象时,可以指定不存在的文件名,但此文件不能是一个已被其他程序打开的文件。
【代码块】输出流
package mt;import java.io.File;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;public class Demo {public static void main(String[] args) {File f = new File("word.txt"); //在MyProject下创建文本word.txtFileOutputStream out = null; //赋予空值try {out = new FileOutputStream(f);String str = "你见过凌晨4点的洛杉矶吗?";byte b[] = str.getBytes();//字符串转换为字节数组try {out.write(b);} catch (IOException e) {// TODO 自动生成的 catch 块e.printStackTrace();}} catch (FileNotFoundException e) {e.printStackTrace();}finally {if(out !=null) {try {out.close();} catch (IOException e) {// TODO 自动生成的 catch 块e.printStackTrace();}}}}
}还没运行前可以看到左侧的项目中并没有word.txt项目。
 【运行刷新】
【运行刷新】
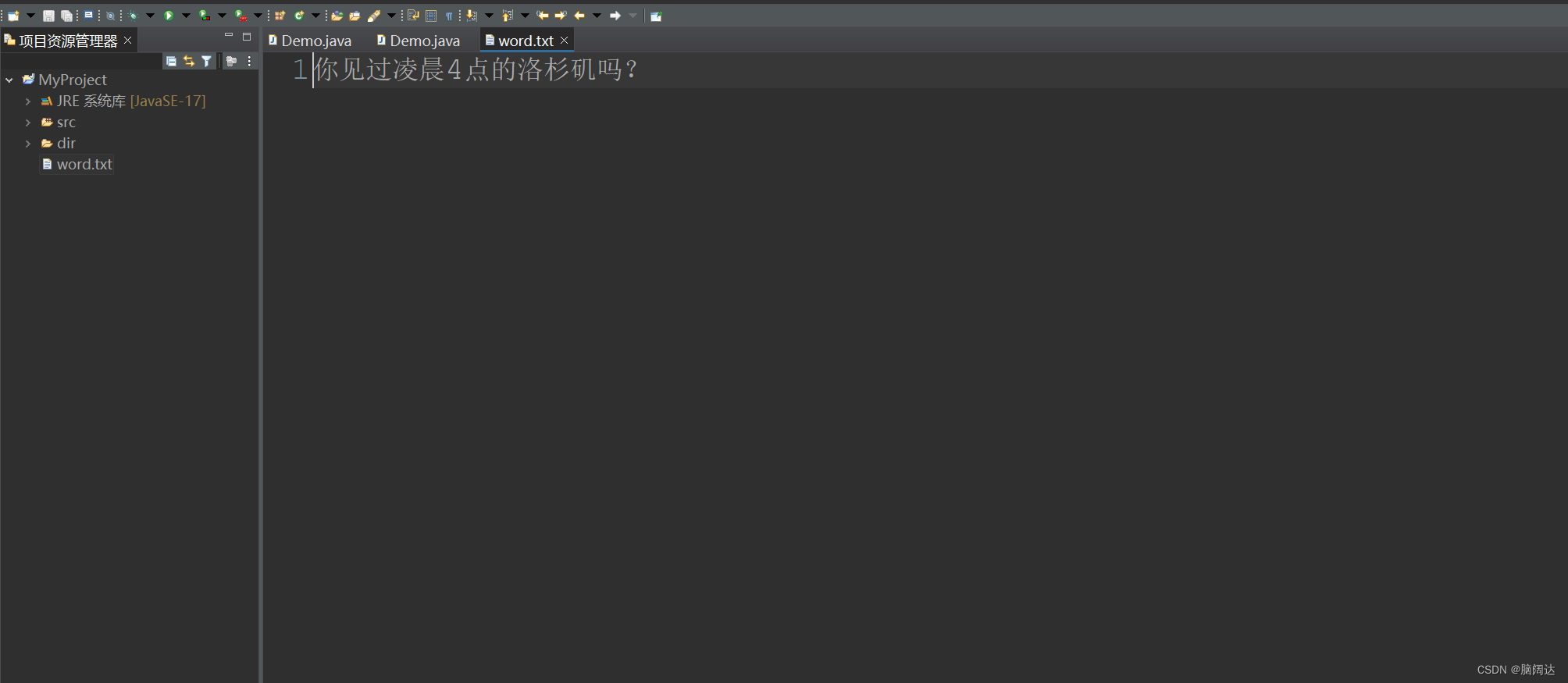
当我们反复向这个文件中写值的时候,它会覆盖前面的内容。
如果我们将out = new FileOutputStream(f);
改为out = new FileOutputStream(f,true):文件输出流,在文件末尾追加内容。
改为out = new FileOutputStream(f,true):文件输出流,替换内容。




【代码】输入流
package mt;import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;public class Demo {public static void main(String[] args) {File f = new File("word.txt"); //在MyProject下创建文本word.txtFileOutputStream out = null; //赋予空值try {out = new FileOutputStream(f,false);String str = "你见过凌晨4点的洛杉矶吗?";byte b[] = str.getBytes();//字符串转换为字节数组try {out.write(b);} catch (IOException e) {// TODO 自动生成的 catch 块e.printStackTrace();}} catch (FileNotFoundException e) {e.printStackTrace();}finally {if(out !=null) {try {out.close();} catch (IOException e) {// TODO 自动生成的 catch 块e.printStackTrace();}}}FileInputStream in = null;try {in = new FileInputStream(f);//输入流读取文件byte b2[] = new byte[1024];//创建缓冲区in.read(b2);//将文件信息读入缓存数组中System.out.println("文本中的内容是:"+new String(b2));} catch (IOException e) {e.printStackTrace();}finally {if(in!=null) {try {in.close();} catch (IOException e) {e.printStackTrace();}}}}
}
【运行结果】
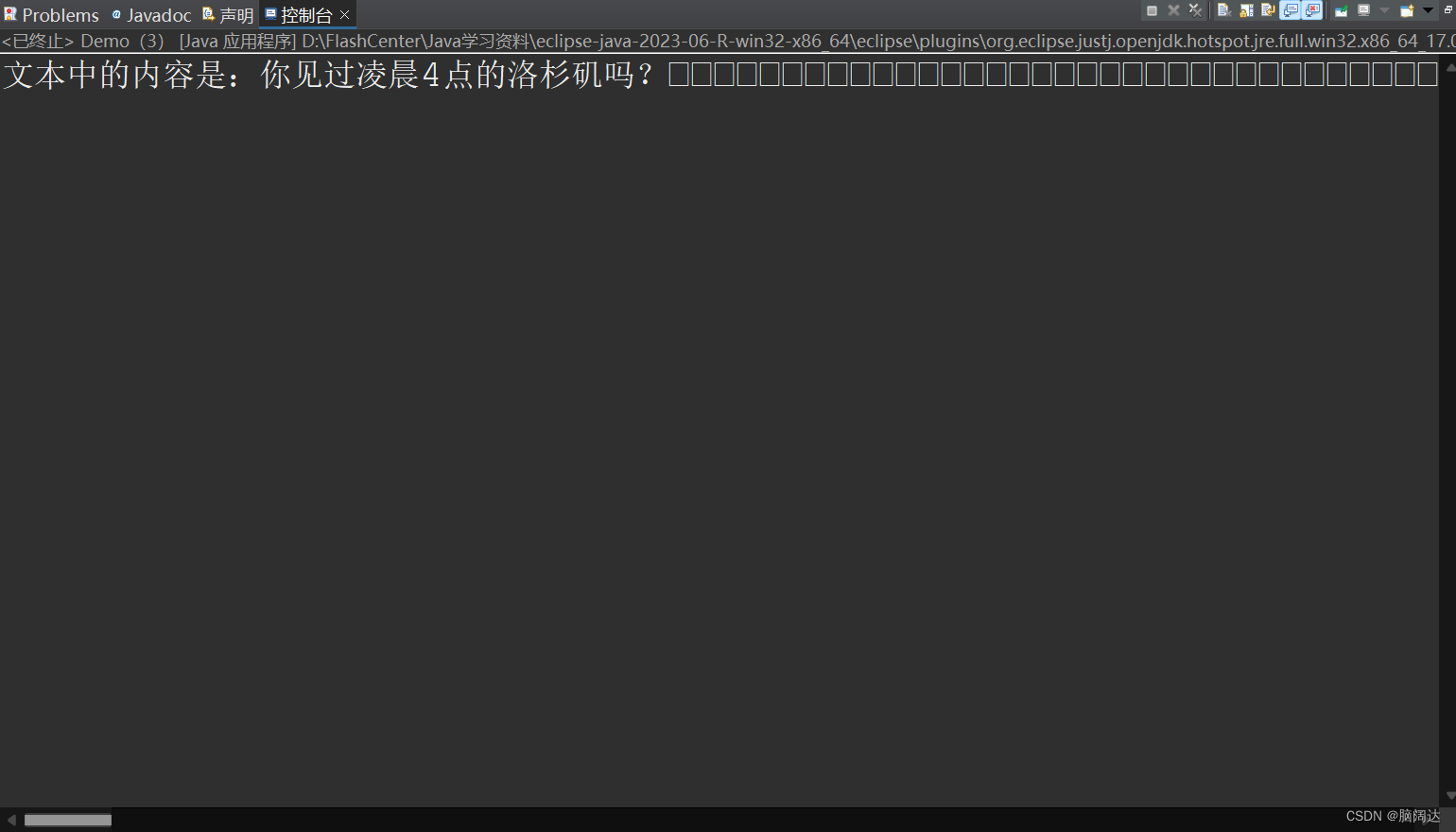
观察运行结果我们可以发现输出文本内容后,后面还跟了一串空格,这是因为我们创建的缓冲区字节数是1024远远大于这些汉字所占用的字节,如何去除这些空格呢?
我们可以这样做:
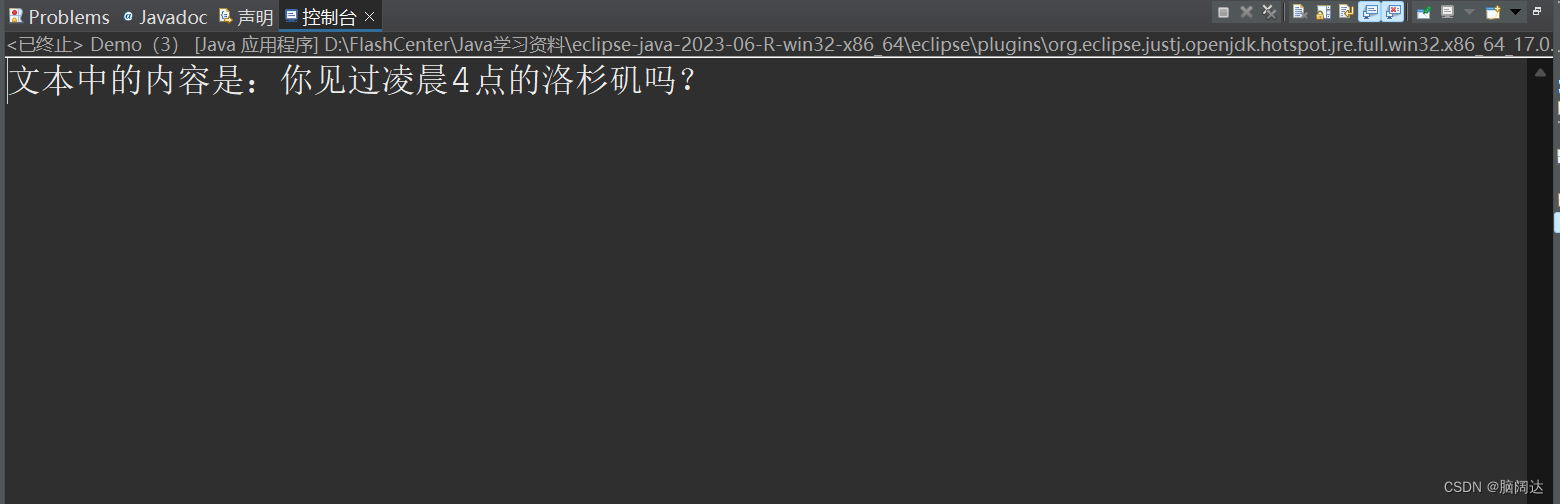
这样做是因为in.read()可以返回所读取的数组的总长度,在让它从索引0到len进行输出就可以 去除空格,看一下运行结果:

我们也可以直接对文本的内容进行修改,只用输入流进行输出:
我们先在word.txt里面写入歌词:
【运行的代码】
package mt;import java.io.File;
import java.io.FileInputStream;
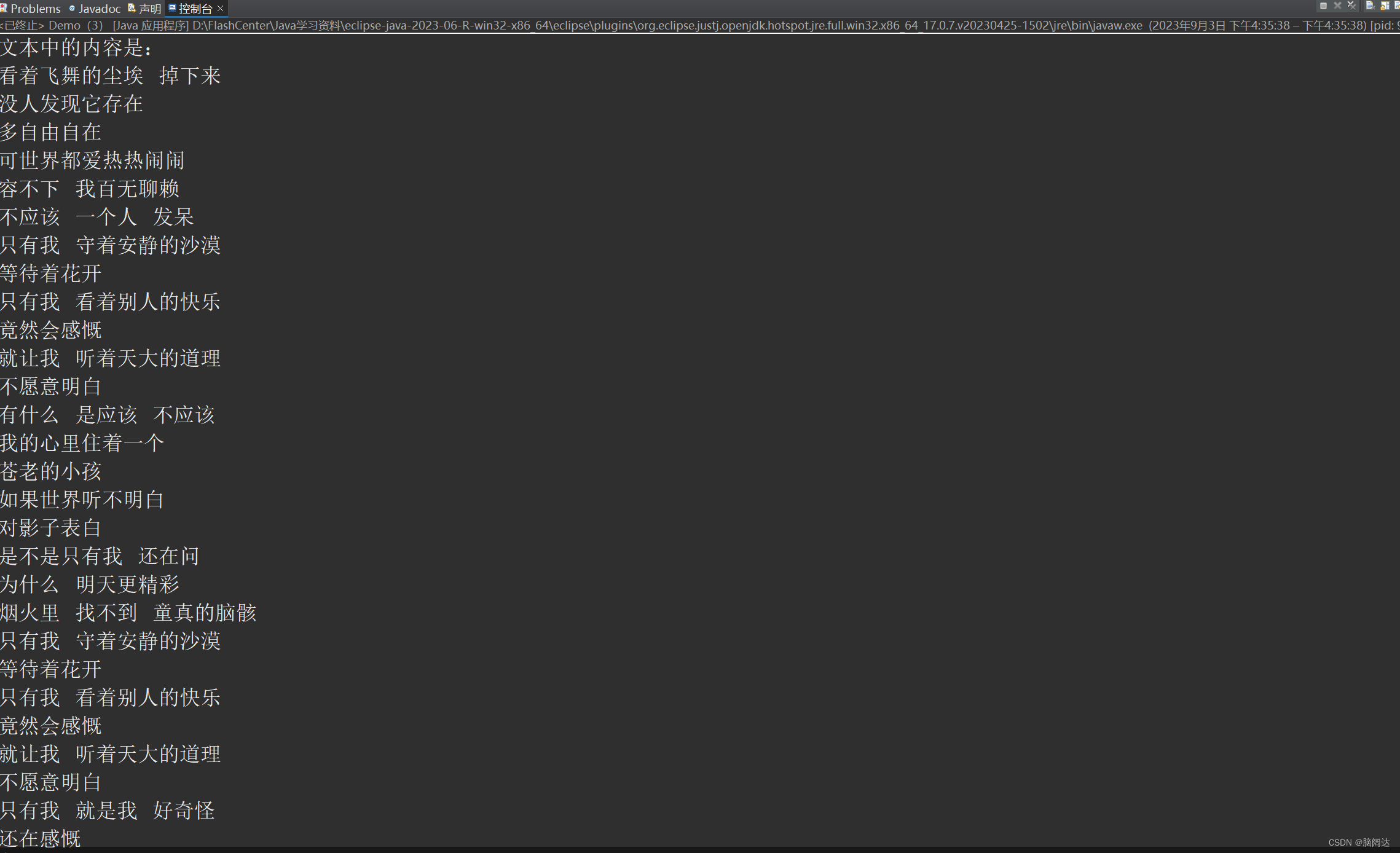
import java.io.IOException;public class Demo {public static void main(String[] args) {File f = new File("word.txt"); //在MyProject下创建文本word.txtFileInputStream in = null;try {in = new FileInputStream(f);//输入流读取文件byte b2[] = new byte[1024];//创建缓冲区int len = in.read(b2);//读入缓冲区的总字节数System.out.println("文本中的内容是:\n"+new String(b2,0,len));} catch (IOException e) {e.printStackTrace();}finally {if(in!=null) {try {in.close();} catch (IOException e) {e.printStackTrace();}}}}
}【运行结果】
二 FileReader和 FileWriter 类
文件字符流
使用FileOutputStream类向文件中写入数据与使用FileInputStream类从文件中将内容读出来,都存在一点不足,即这两个类都只提供了对字节或字节数组的读取方法。由于汉字在文件中占用两个字节,如果使用字节流,读取不好可能会出现乱码现象,此时采用字符流FileReader类或 FileWriter类即可避免这种现象。
FileReader类和 FileWriter类对应了 FilelnputStream类和 FileOutputStream类。FileReader类顺序地读取文件,只要不关闭流,每次调用read(方法就顺序地读取源中其余的内容,直到源的末尾或流被关闭。

【代码】输出流
package mt;import java.io.File;
import java.io.FileWriter;
import java.io.IOException;public class Demo {public static void main(String[] args) {File f = new File("word.txt");FileWriter fw = null;try {fw = new FileWriter(f);String str ="只是一场烟火散落的尘埃";fw.write(str);} catch (IOException e) {e.printStackTrace();}finally {if(fw!=null) {try {fw.close();} catch (IOException e) {e.printStackTrace();}}}}
}
【运行结果】 
【代码】输入流
package mt;import java.io.File;
import java.io.FileReader;
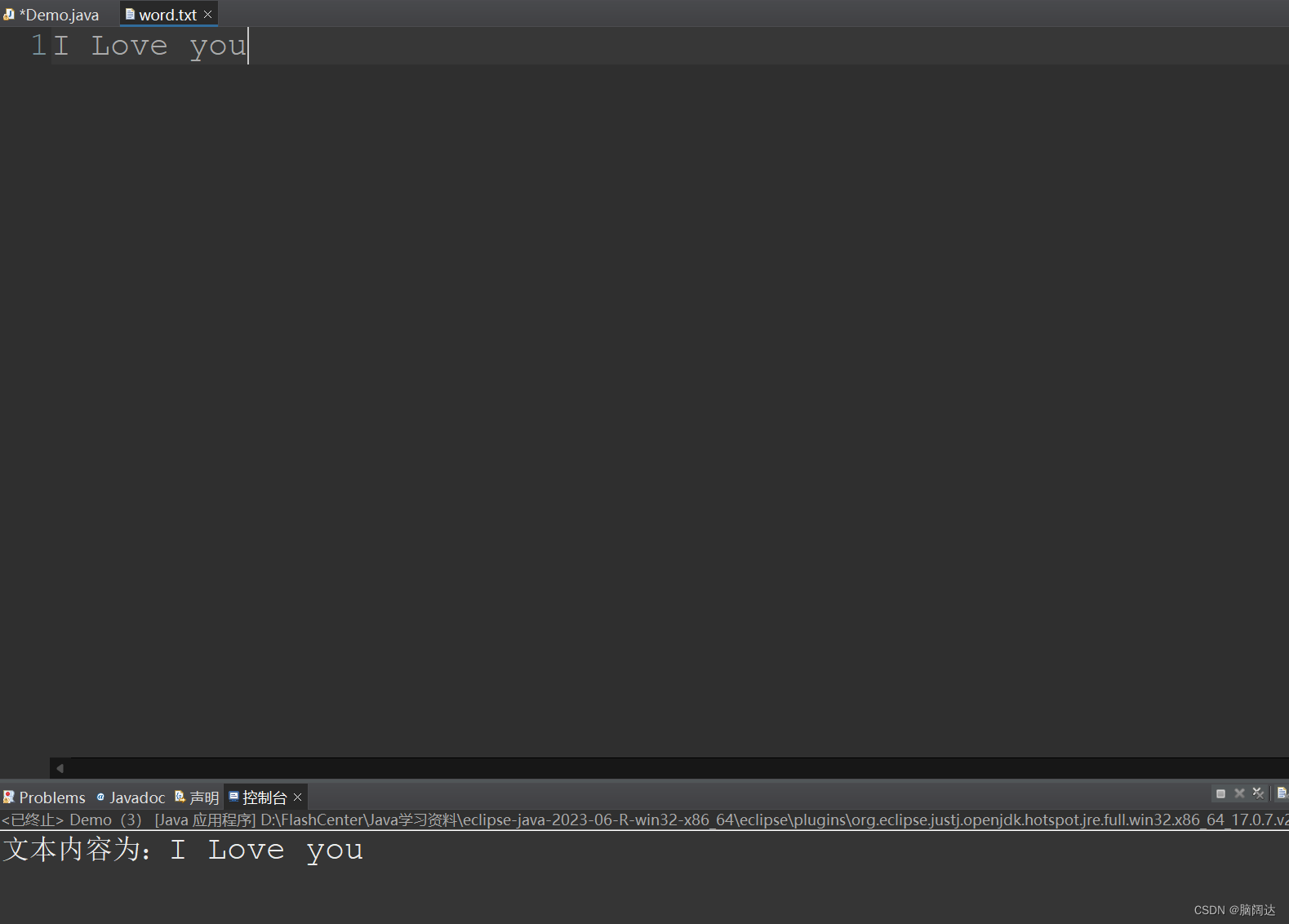
import java.io.IOException;public class Demo {public static void main(String[] args) {File f = new File("word.txt");FileReader fr = null;try {fr = new FileReader(f);char ch[] = new char[1024];int len = fr.read(ch);System.out.println("文本内容为:"+new String(ch,0,len));} catch (IOException e) {e.printStackTrace();}finally {if(fr!=null) {try {fr.close();} catch (IOException e) {e.printStackTrace();}}}}
}【运行结果】
带缓存的输入/输出流
首先我们了解一下什么是缓冲区:
我们要将一推箱子由A运到B地,如果我们派人一次一次的去搬运,是十分慢的。如果直接用货车运输,那么方便许多。这里货车就充当了缓冲区的功能。

缓存是I/O的一种性能优化。缓存流为I1O流增加了内存缓存区,使得在流上执行skip)、mark()和reset()方法都成为可能。
一 BufferedInputStream与 BufferedOutputStream类
缓冲字节流
BufferedInputStream 类可以对所有InputStream类进行带缓存区的包装以达到性能的优化。BufferedInputStream类有两个构造方法:
1.BufferedInputStream(InputStream in)
2.BufferedInputStream(InputStream in,int size)第一种形式的构造方法创建了一个有32个字节的缓存区。
第二种形式的构造方法按指定的大小来创建缓存区。
一个最优的缓存区的大小,取决于它所在的操作系统、可用的内存空间以及机器配置。从构造方法可以看出,BufferedInputStream对象位于InputStream类对象之后。
BufferedInputStream读取文件过程 
使用 BufferedOutputStream类输出信息和仅用OutputStream类输出信息完全一样,只不过BufferedOutputStream有一个flush)方法用来将缓存区的数据强制输出完。BufferedOutputStream类也有两个构造方法:
BufferedOutputStream(OutputStream in)。
BufferedOutputStream(OutputStream in,int size)。
第一种构造方法创建一个有32个字节的缓存区。第二种构造方法以指定的大小来创建缓存区。
缓冲输入流
不使用缓存区效果:
【代码】
package mt;import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;public class Demo {public static void main(String[] args) {File f = new File("D:\\FlashCenter\\歌词.txt");FileInputStream in = null;long start = System.currentTimeMillis();//获取流开始的毫秒值try {in = new FileInputStream(f);byte b[] = new byte[1024];//缓冲区字节数组(这个缓冲区与Buffered不同)while(in.read()!=-1) {//当有值时循环输出}long end = System.currentTimeMillis();//获取流结束的毫秒值System.out.println("运行经历的毫秒数:"+(end-start));} catch (IOException e) {e.printStackTrace();}finally {if(in !=null) {try {in.close();} catch (IOException e) {e.printStackTrace();}}}}
}
【 运行效果】
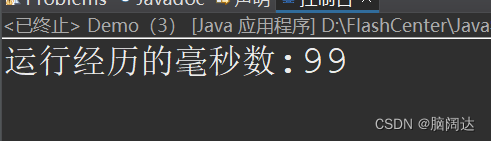
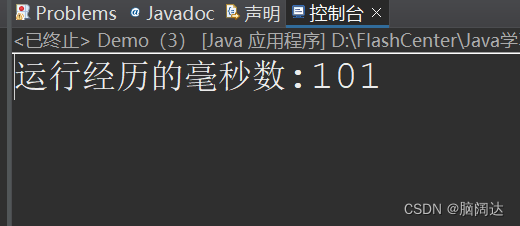
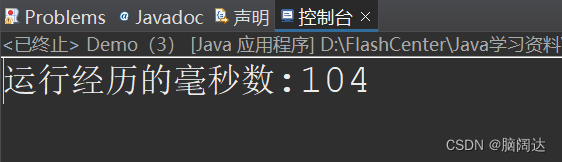
使用缓冲流效果:
【代码】
package mt;import java.io.BufferedInputStream;
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;public class Demo {public static void main(String[] args) {File f = new File("D:\\FlashCenter\\歌词.txt");FileInputStream in = null;BufferedInputStream bi = null;long start = System.currentTimeMillis();//获取流开始的毫秒值try {in = new FileInputStream(f);bi = new BufferedInputStream(in);//将文件字节流包装成缓冲字节流byte b[] = new byte[1024];//缓冲区字节数组(这个缓冲区与Buffered不同)while(bi.read()!=-1) {//当有值时循环输出}long end = System.currentTimeMillis();//获取流结束的毫秒值System.out.println("运行经历的毫秒数:"+(end-start));} catch (IOException e) {e.printStackTrace();}finally {if(in !=null) {try {in.close();} catch (IOException e) {e.printStackTrace();}}if(bi!=null) {try {bi.close();} catch (IOException e) {e.printStackTrace();}}}}
}【 运行效果】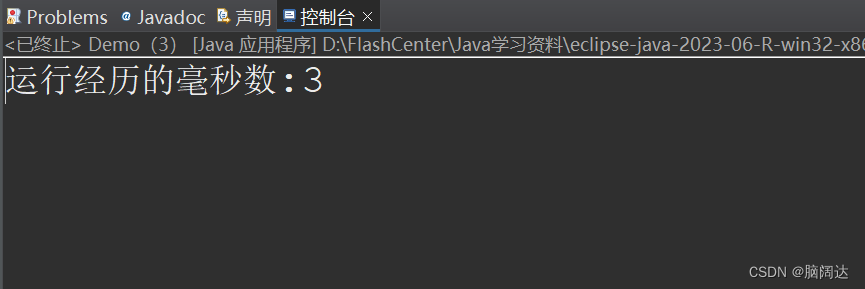
从运行效果来看,可以看出大大的提高了运行的效率。
缓冲输出流
【代码】
package mt;import java.io.BufferedOutputStream;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;public class Demo2 {public static void main(String[] args) {File f =new File("word.txt");FileOutputStream out = null;BufferedOutputStream bo = null;try {out = new FileOutputStream(f);bo = new BufferedOutputStream(out);//包装文件输出流String str = "天生我才必有用,千金散尽还复来!";byte b[] = str.getBytes();bo.write(b);//这里也能够提高效率//使用缓冲字节流输出时,要多进行刷新操作。bo.flush();//刷新。强制将缓存区数据写入文件,即使缓冲区没有写满。} catch (IOException e) {e.printStackTrace();}finally {try {out.close();} catch (IOException e) {e.printStackTrace();}}}}【运行结果】
总结:
无论BufferedInputStream与 BufferedOutputStream类,在这里都有提高运行效率的结果。
二 BufferedReader与BufferedWriter类
缓冲字符流
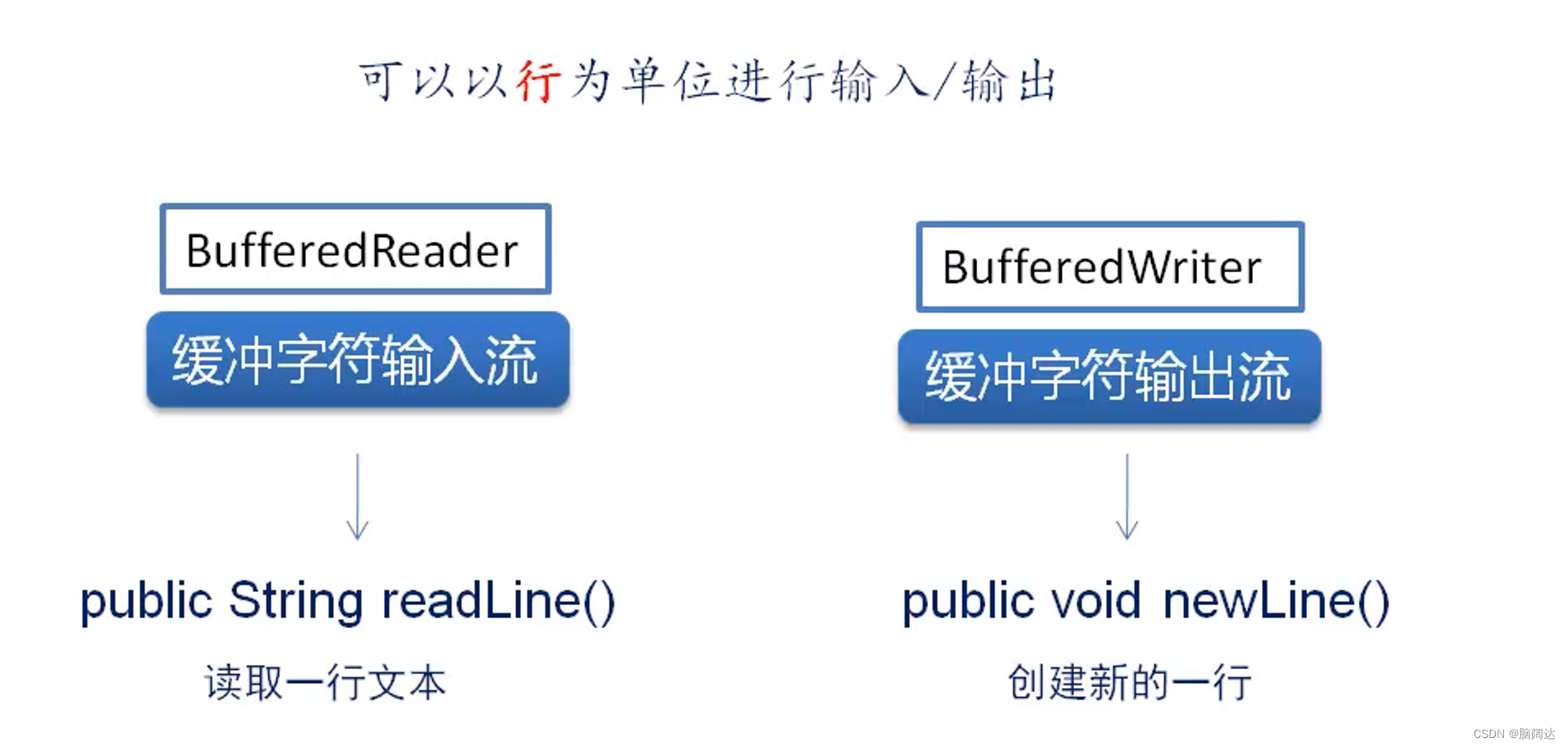
BufferedReader类与BufferedWriter类分别继承Reader类与Writer类。这两个类同样具有内部事机制,并能够以行为单位进行输入/输出。
BufferedReader类常用的方法如下:
read0方法:读取单个字符。
readLine()方法:读取一个文本行,并将其返回为字符串。若无数据可读,则返回null。
BufferedWriter类中的方法都返回void。常用的方法如下:
write(String s,int offint len)方法:写入字符串的某一部分。
flush()方法:刷新该流的缓存。
newLine(方法:写入一个行分隔符。
在使用BufferedWriter类的Write()方法时,数据并没有立刻被写入输出流,而是首先进入缓存区中如果想立刻将缓存区中的数据写入输出流,一定要调用flush)方法。
缓冲字符输出流代码实列:
package mt;import java.io.BufferedWriter;
import java.io.File;
import java.io.FileWriter;
import java.io.IOException;public class Demo {public static void main(String[] args) {File f = new File("word.txt");FileWriter fw = null;BufferedWriter bw = null;try {fw = new FileWriter(f);bw = new BufferedWriter(fw);//将文件字符输出流包装成缓存字符流String str1 = "世界那么大";String str2 = "我想去看看";bw.write(str1);//第一行bw.newLine();//创建新行bw.write(str2);//第二行} catch (IOException e) {e.printStackTrace();}finally {//要注意流关闭的顺序,先创建的后关闭if(bw!=null) {try {bw.close();} catch (IOException e) {e.printStackTrace();}}if(fw!=null) {try {fw.close();} catch (IOException e) {e.printStackTrace();}}}}
}
运行效果: 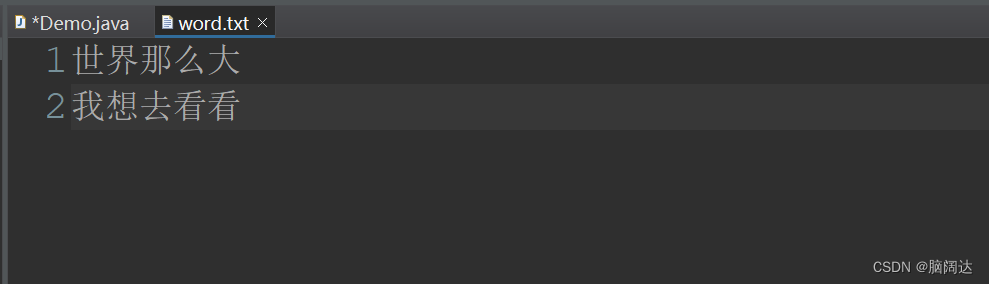
缓冲字符流输入代码实列:
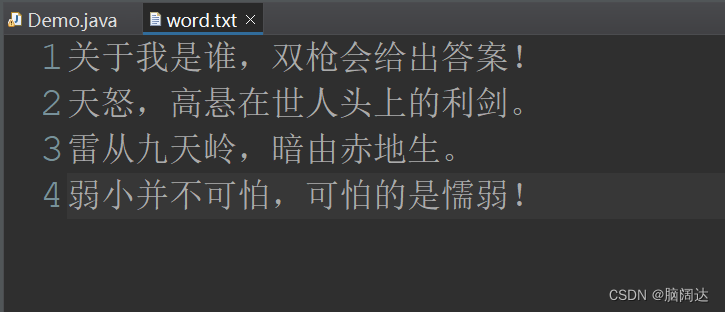
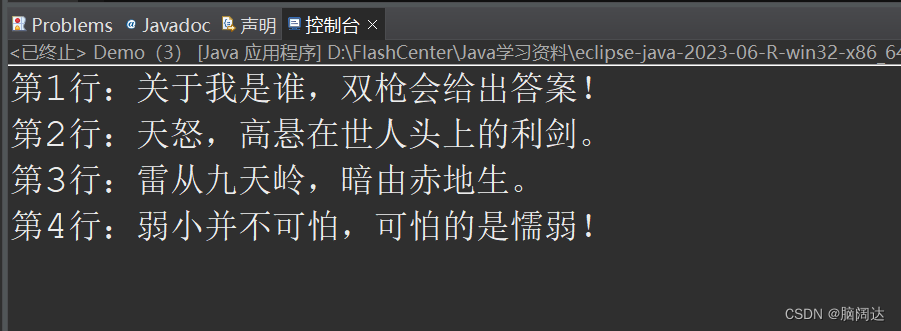
package mt;import java.io.BufferedReader;import java.io.File;import java.io.FileReader;import java.io.IOException;public class Demo {public static void main(String[] args) {File f = new File("word.txt");FileReader fr = null;BufferedReader br = null;try {fr = new FileReader(f);br = new BufferedReader(fr);String tmp = null;int i = 1;while((tmp = br.readLine())!=null) {//循环读取文件中的内容System.out.println("第"+i+"行:"+tmp);i++;}br.readLine();//读一行} catch (IOException e) {e.printStackTrace();}finally {if(br!=null) {try {br.close();} catch (IOException e) {e.printStackTrace();}}}if(fr!=null) {try {fr.close();} catch (IOException e) {e.printStackTrace();}}}
}运行效果:
文本内容:
输出效果:
总结:
BufferedReader与BufferedWriter类除了提高效率以外,它还可以以行为单位,来对字符数据进行操作。比如:BufferedReader的readLine()方法,BufferedWriter的newLine()方法。
数据的输入/输出流
数据输入/输出流(DataInputStream类与DataOutputStream类)允许应用程序以与机器无关的方式从底层输入流中读取基本Java数据类型。也就是说,当读取一个数据时,不必再关心这个数值应当是哪种字节。
一 DataInputStream类与DataOutputStream类
DatalnputStream类与DataOutputStream类的构造方法如下。
DataInputStream(InputStream in):使用指定的基础InputStream对象创建一个 DataInputStream对象。
DataOutputStream(OutputStream out):创建一个新的数据输出流,将数据写入指定基础输出流。
DataOutputStream类提供了将字符串、double数据、int数据、boolean数据写入文件的方法。其中,将字符串写入文件的方法有3种,分别是writeBytes(String s)、writeChars(String s)、writeUTF(Strings)。由于Java中的字符是Unicode编码,是双字节的,writeBytes0方法只是将字符串中的每一个字符的低字节内容写入目标设备中;而writeCharsO方法将字符串中的每一个字符的两个字节的内容都写到目标设备中;writeUTFO方法将字符串按照UTF编码后的字节长度写入目标设备,然后才是每一个字节的UTF编码。
DataInputStream类只提供了一个readUTF0方法返回字符串。这是因为要在一个连续的字节流读取一个字符串,如果没有特殊的标记作为一个字符串的结尾,并且不知道这个字符串的长度,就无法知道读取到什么位置才是这个字符串的结束。DataOutputStream类中只有writeUTFO方法向目标设备中写入字符串的长度,所以也能准确地读回写入字符串。
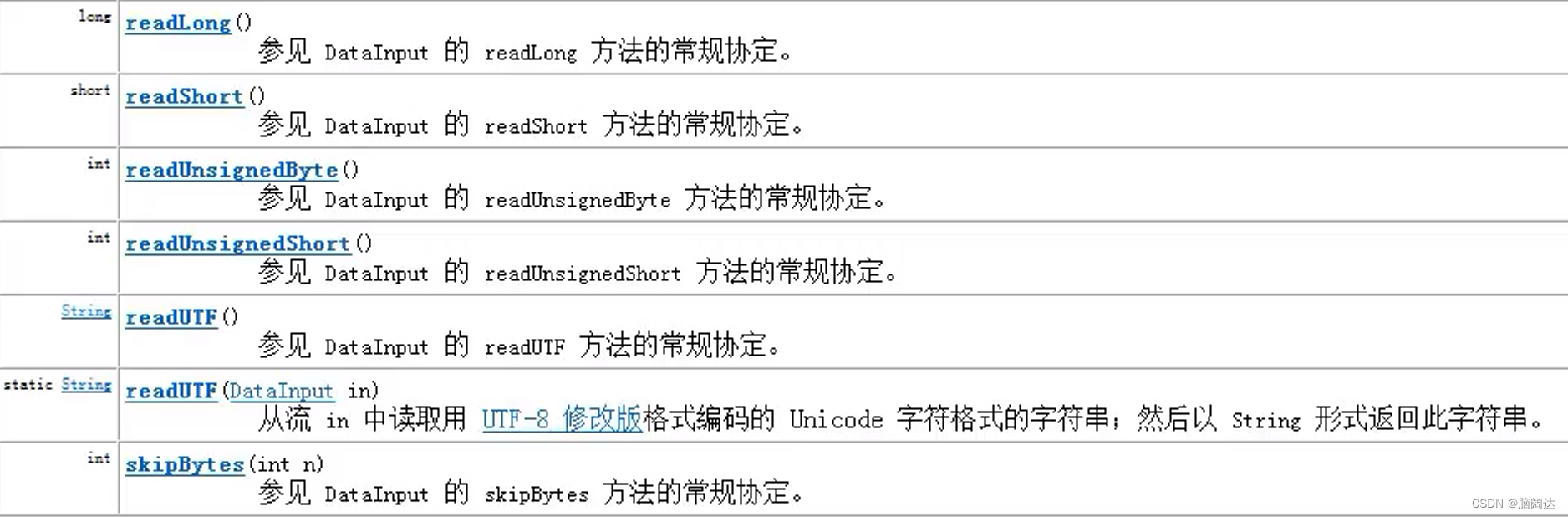
API中的部分方法:
输入流:
输出流:

代码实列:
package mt;import java.io.DataInputStream;
import java.io.DataOutputStream;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;public class Demo {public static void main(String[] args) {File f = new File("word.txt");FileOutputStream out = null;DataOutputStream dos = null;try {out = new FileOutputStream(f);dos = new DataOutputStream(out);//将文件流包装为数据流dos.writeUTF("这是写入字符串数据。"); //写入字符串数据dos.writeDouble(3.14); //写入浮点型数据dos.writeBoolean(false); //写入布尔类型dos.writeInt(123); //写入整型数据} catch (IOException e) {e.printStackTrace();}finally {if(out!=null) {try {out.close();} catch (IOException e) {e.printStackTrace();}}if(dos!=null) {try {dos.close();} catch (IOException e) {e.printStackTrace();}}}}
}我们运行以后发现运行结果为乱码:

这是因为通过数据输出流写入文本的是字节码,我们想要得到里面的数据就需要用数据输入流将里面的数据读出来。然后通过对应的方法进行解析得到结果。
我们添加上数据的输入流在来进行:
代码如下:
package mt;import java.io.DataInputStream;
import java.io.DataOutputStream;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;public class Demo {public static void main(String[] args) {File f = new File("word.txt");FileOutputStream out = null;DataOutputStream dos = null;try {out = new FileOutputStream(f);dos = new DataOutputStream(out);//将文件流包装为数据流dos.writeUTF("这是写入字符串数据。"); //写入字符串数据dos.writeDouble(3.14); //写入浮点型数据dos.writeBoolean(false); //写入布尔类型dos.writeInt(123); //写入整型数据} catch (IOException e) {e.printStackTrace();}finally {if(out!=null) {try {out.close();} catch (IOException e) {e.printStackTrace();}}if(dos!=null) {try {dos.close();} catch (IOException e) {e.printStackTrace();}}}DataInputStream di = null;FileInputStream in = null;try {in = new FileInputStream(f);di = new DataInputStream(in);System.out.println("readUTF()读取数据:"+di.readUTF());System.out.println("readdouble()读取数据:"+di.readDouble());System.out.println("readBoolean()读取数据:"+di.readBoolean());System.out.println("readInt()读取数据:"+di.readInt());} catch (IOException e) {e.printStackTrace();}finally {if(in!=null) {try {in.close();} catch (IOException e) {e.printStackTrace();}}if(di!=null) {try {di.close();} catch (IOException e) {e.printStackTrace();}}}}
} 运行结果: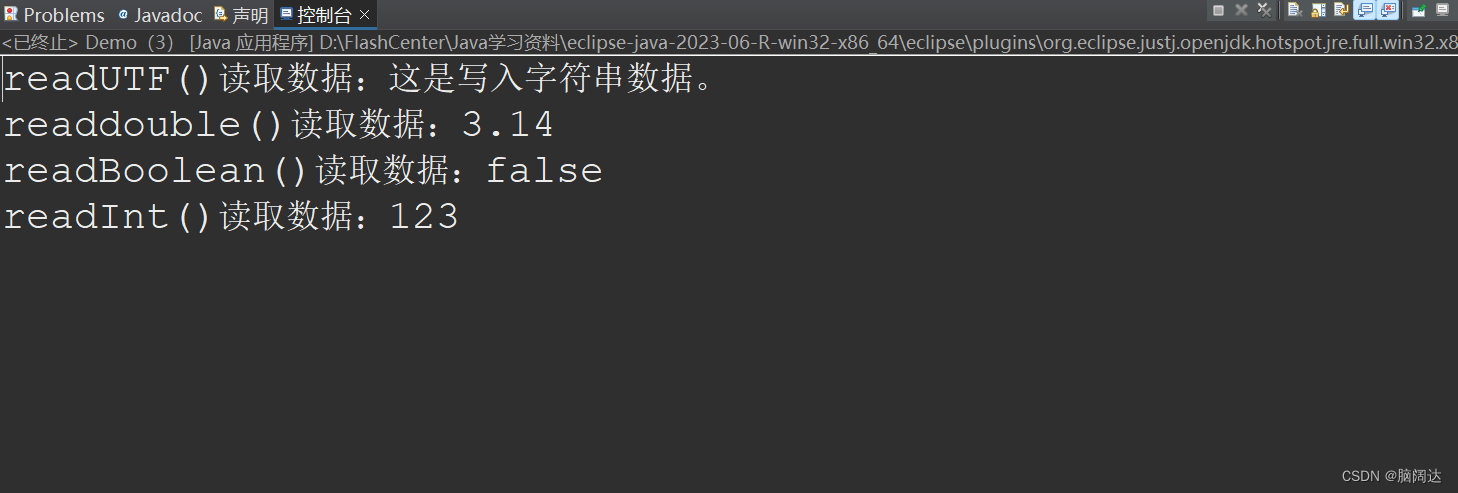
 Thank!
Thank!
相关文章:
Java学习笔记之----I/O(输入/输出)二
【今日】 孩儿立志出乡关,学不成名誓不还。 文件输入/输出流 程序运行期间,大部分数据都在内存中进行操作,当程序结束或关闭时,这些数据将消失。如果需要将数据永久保存,可使用文件输入/输出流与指定的文件建立连接&a…...
2024字节跳动校招面试真题汇总及其解答(一)
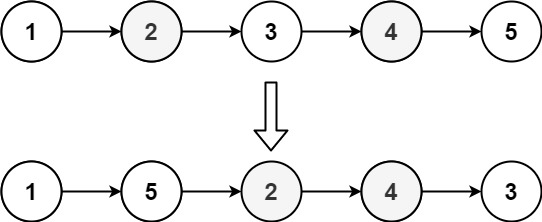
1. 【算法题】重排链表 给定一个单链表 L 的头节点 head ,单链表 L 表示为: L0 → L1 → … → Ln - 1 → Ln请将其重新排列后变为: L0 → Ln → L1 → Ln - 1 → L2 → Ln - 2 → … 不能只是单纯的改变节点内部的值,而是需要实际的进行节点交换。 示例 1: 输入:hea…...
【Nginx23】Nginx学习:响应头与Map变量操作
Nginx学习:响应头与Map变量操作 响应头是非常重要的内容,浏览器或者客户端有很多东西可能都是根据响应头来进行判断操作的,比如说最典型的 Content-Type ,之前我们也演示过,直接设置一个空的 types 然后指定默认的数据…...

前端代理报错Error occured while trying to proxy to: localhost:端口
webpack配置进行前端代理时, 报错信息如下:(DEPTH_ZERO_SELF_SIGNED_CERT) 需设置:secure为false即可解决此报错 // webpack配置前端代理config["/test"]{target: https://xxxx.com,changeOrigin: true,secure: false // 这个配置…...
QT DAY6
#include "widget.h" #include "ui_widget.h"Widget::Widget(QWidget *parent): QWidget(parent), ui(new Ui::Widget) {ui->setupUi(this);socket new QTcpSocket(this);//如果连接服务器成功,该客户端就会发射一个connected的信号。//我们…...
Slint学习文档
Slint学习文档 Slint Learn如何学习本文档学习顺序标志说明 Slint With VSCodeSlint With Rust依赖👎定义宏 Slint与Rust分离1.添加编译依赖(slint-build)2.编写slint文件3.编写build.rs4.编写main.rs 普通组件主窗体Windowexample 文本Texte…...
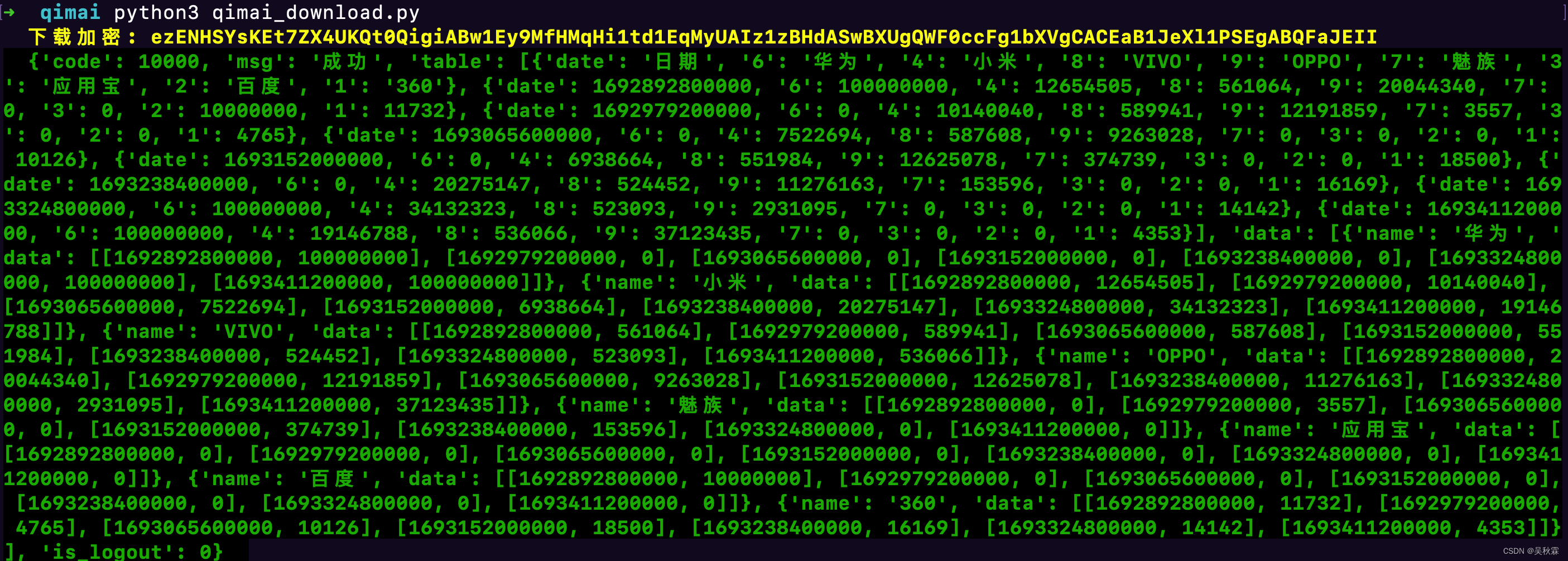
【最新!七麦下载量analysis参数】逆向分析与Python实现加密算法
文章目录 1. 写在前面2. 请求分析3. 加密分析4. 算法实现 1. 写在前面 之前出过一个关于榜单analysis的分析,有兴趣的可以查看这篇文章:七麦榜单analysis加密分析 最近运营团队那边有同事找到我们,说工作中偶尔需要统计分析一下某APP在一些主…...
)
蓝桥杯练习题(3的倍数)
问题描述 小蓝对 3 的倍数很感兴趣。现在他手头有三个不同的数 a,b,c, 他想知道, 这三个数中是不是有两个数的和是 3 的倍数。 例如, 当 a3,b4,c6 时, 可以找到 a 和 c 的和是 3 的倍数。 例如, 当 a3,b4,c7 时, 没办法找到两个数的和是 3 的倍数。 输入格式 输入三行, 每行…...

安装Qe-7.2细节
编译 直接编译报错,发现要使用gpu加速。 检查linux的GPU: nvidia-smi lspci |grep -i nvidia module load cuda ./configure make all 安装curl mkdir build cd build …/configure --prefix/home/bin/local/curl make make install 加入路径: expor…...
3.运行项目
克隆项目 使用安装的git克隆vue2版本的若依项目,博主使用的版本是3.8.6. git clone https://gitee.com/y_project/RuoYi-Vue.git目录结构如下图所示,其中ruoyi-ui是前端的内容,其它均为后端的内容。 配置mysql数据库 在数据库里新建一个…...

【算法题】2651. 计算列车到站时间
题目: 给你一个正整数 arrivalTime 表示列车正点到站的时间(单位:小时),另给你一个正整数 delayedTime 表示列车延误的小时数。 返回列车实际到站的时间。 注意,该问题中的时间采用 24 小时制。 示例 1…...

Mybatis传递实体对象只能直接获取,不能使用对象.属性方式获取
mybatis的自动识别参数功能很强大,pojo实体类可以直接写进mapper接口里面,不需要在mapper.xml文件中添加paramType,但是加了可以提高mybatis的效率 不加Param注解,取值的时候直接写属性 //这里是单参数,可以不加param!…...

flink 写入数据到 kafka 后,数据过一段时间自动删除
版本 flink 1.16.0kafka 2.3 流程描述: flink利用KafkaSource,读取kafka的数据,然后经过一系列的处理,通过KafkaSink,采用 EXACTLY_ONCE 的模式,将处理后的数据再写入到新的topic中。 问题描述࿱…...
golong基础相关操作--一
package main//go语言以包作为管理单位,每个文件必须先声明包 //程序必须有一个main包 // 导入包,必须要要使用 // 变量声明了,必须要使用 import ("fmt" )/* * 包内部的变量 */ var aa 3var ss "kkk"var bb truevar …...
【深度学习】基于卷积神经网络的铁路信号灯识别方法
基于卷积神经网络的铁路信号灯识别方法 摘 要:1 引言2 卷积神经网络模型2.1 卷积神经网络结构2.2.1 卷积层2.2.2 池化层2.2.3 全连接层 3 卷积神经网络算法实现3.1 数据集制作3.2 卷积神经网络的训练过程3.2.1 前向传播过程 4 实验5 结语 摘 要: 目前中…...

DR IP-SoC China 2023 Day演讲预告 | 龙智Perforce专家解析芯片开发中的数字资产管理
2023年9月6日(周三),龙智即将亮相于上海举行的D&R IP-SoC China 2023 Day,呈现集成了Perforce与Atlassian产品的芯片开发解决方案,助力企业更好、更快地进行芯片开发。 D&R IP-SoC China 2023 Day 是中国首个…...

解决github连接不上的问题
改 hosts 我们在浏览器输入 GitHub 的网址时,会向 DNS 服务器发送一个请求,获取到 GitHub 网站所在的服务器 IP 地址,从而进行访问。 就像你是一名快递员,在送快递前要先找中间人询问收件人的地址。而 DNS 就是这个告诉你目标地址…...

# DevOps名词定义梳理
DevOps名词定义梳理 极限编程座右铭:如果它令你很受伤,那么就做更多的练习(If it hurts, do it more often) 经常人们会把这些名词用错: 构建:就是把源代码制成成品的过程,这个过程一般会有单元…...

Redis Cluster
文章目录 一、集群搭建1 节点规划2 集群启动 二、配置一致性1 基本分工2 更新规则 三、Sharding1 数据分片分片实现分片特点 2 slot迁移迁移原因迁移支持集群扩容迁移错误背景现象问题分析验证猜想 集群缩容 3. 请求路由client端server端migrating节点的读写importing节点的读写…...
Pandas常用指令
astype astype的作用是转换数据类型,astype是没办法直接在原df上进行修改的,只能通过赋值的形式将原有的df进行覆盖,即df df.astype(dtype) astype的基本语法 DataFrame.astype(dtype, copyTrue, errorsraise) dtype参数指定将数据类型转换…...

Java经典面试题汇总:Java Web
1. JSP 和 servlet 有什么区别?JSP 是 servlet 技术的扩展,本质上就是 servlet 的简易方式。servlet 和 JSP 最主要的不同点在于, servlet 的应用逻辑是在 Java 文件中,并且完全从表示层中的 html 里分离开来,而 JSP 的…...

PvZ Toolkit终极指南:3分钟掌握植物大战僵尸修改技巧
PvZ Toolkit终极指南:3分钟掌握植物大战僵尸修改技巧 【免费下载链接】pvztoolkit 植物大战僵尸 PC 版综合修改器 项目地址: https://gitcode.com/gh_mirrors/pv/pvztoolkit PvZ Toolkit是一款专为经典游戏《植物大战僵尸》PC版设计的开源修改工具࿰…...

在js,vue,java,mysql中$的含义
JavaScript 中的 $在JavaScript中,$符号并没有特殊的含义。它只是一个普通的字符,可以作为变量名、函数名、对象属性名等使用。不过,由于历史原因,$符号在JavaScript中常常被用来表示与DOM操作或动画相关的库或函数,最…...

3分钟技术赋能:手机号逆向查询QQ号的智能解决方案
3分钟技术赋能:手机号逆向查询QQ号的智能解决方案 【免费下载链接】phone2qq 项目地址: https://gitcode.com/gh_mirrors/ph/phone2qq 在数字身份管理日益复杂的今天,我们时常面临这样的困境:忘记了自己多年前注册的QQ号,…...

最小差异对比法:高效区分相似概念的教学技术
1. 问题背景与核心需求在知识传播和教学场景中,我们经常需要向学习者解释两个相似概念之间的细微差别。传统方法往往采用独立描述或简单对比的方式,但这种方式容易让学习者忽略关键差异点。生成最小差异对比答案对(Minimal Pair)是…...

别再只会apt了!在统信UOS/麒麟KOS上,用dpkg命令搞定微信、WPS等.deb包的安装与管理
国产系统进阶指南:dpkg命令在统信UOS/麒麟KOS中的高阶应用 当你在统信UOS或麒麟KOS上双击一个.deb文件却遭遇安装失败时,是否意识到这背后隐藏着一个更强大的工具世界?作为国产操作系统的深度用户,掌握dpkg命令不仅能解决90%的第三…...
)
别再手写循环了!用MATLAB内置函数和这个自定义函数搞定滑动窗口(附完整代码)
MATLAB滑动窗口优化实战:从循环到向量化的性能飞跃 在信号处理、时间序列分析和机器学习特征工程中,滑动窗口技术无处不在。传统实现往往依赖显式循环,这不仅代码冗长,在MATLAB中更会带来显著的性能损耗。本文将带你突破基础循环思…...


PyCharm连接Docker容器开发,我踩过的那些坑:从端口映射到root登录权限
PyCharm连接Docker容器开发避坑指南:从端口映射到SSH配置的深度解析 在开发环境中将PyCharm与Docker容器无缝对接,本应是提升效率的利器,却常常因为各种"坑"而让人望而却步。作为一名长期在Mac和Windows双平台使用PyCharm专业版进行…...

电磁铁的磁性可以无限增强吗
电磁铁的磁性无法无限增强,这主要源于材料的磁饱和特性。当磁场强度达到临界值后,即便继续增大电流或增加线圈匝数,磁性也难以持续提升。铁芯材料内部存在大量微小磁畴,在外加磁场作用下,这些磁畴会逐渐转向与磁场一致…...