【Hello Algorithm】二叉树相关算法
本篇博客介绍:介绍二叉树的相关算法
二叉树相关算法
- 二叉树结构
- 遍历二叉树
- 递归序
- 二叉树的交集
- 非递归方式实现二叉树遍历
- 二叉树的层序遍历
- 二叉树难题
- 二叉树的序列化和反序列化
- lc431
- 求二叉树最宽的层
- 二叉树的后继节点
- 谷歌面试题
二叉树结构
如果对于二叉树的结构还有不了解的同学可以参考我的这篇博客
初识二叉树
遍历二叉树
在学习二叉树算法的时候最经典的题目就是递归遍历二叉树
leetcode题目连接和解法如下
遍历二叉树
我们最常使用的就是递归方法了 先序的整体思想就是先打印头节点 再打印左子树 再打印右子树
class Solution {
public:void _preorderTraversal(TreeNode* root , vector<int>& v){if (root == nullptr){return;}v.push_back(root->val);_preorderTraversal(root->left, v);_preorderTraversal(root->right, v);}vector<int> preorderTraversal(TreeNode* root) {vector<int> v;_preorderTraversal(root , v);return v;}
};
核心代码就是这三行
递归序
v.push_back(root->val);_preorderTraversal(root->left, v);_preorderTraversal(root->right, v);
可是大家有没有想过 为什么我们能通过递归方法得到这个结果呢?
为什么它们的名字叫做先序后序中序呢?
因为这本质上其实是递归序加工的结果
假设我们现在有如下一颗二叉树
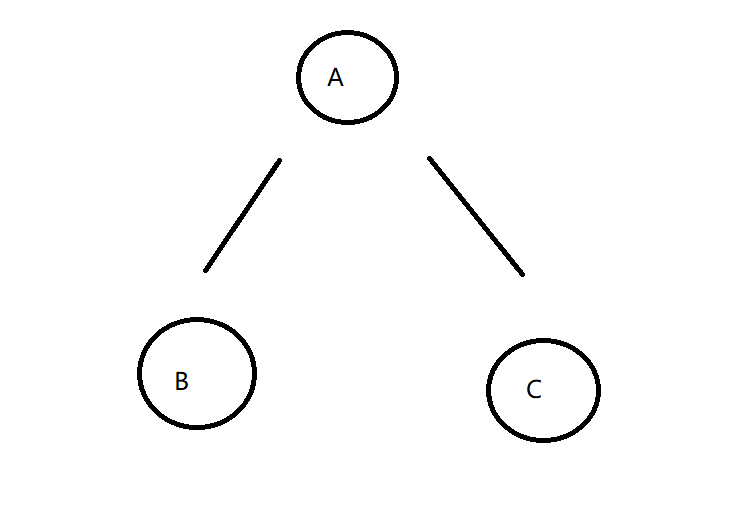
按照我们先序遍历的代码 访问节点的顺序如下
A B B B A C C C A
这个时候我们就可以发现
- 如果我们按照第一次出现的顺序打印就是先序遍历
- 如果我们按照第二次出现的顺序打印就是中序遍历
- 如果我们按照第三次出现的顺序打印就是后序遍历
所以说 先序 中序 后序本质上就是对于递归序的再加工
注:因为我们这里算上主函数调用了三次 所以说会有三次遍历到该节点 如果说调用了四次的话就会访问四次了
二叉树的交集
假设二叉树的先序遍历顺序为 A X B
二叉树的后序遍历顺序为 C X D
其中 A B C D为集合 X是任意一个节点
试证明 A集合交上D集合的子集一定为X的祖先节点
我们要通过两步来证明上面结论的正确性
- 祖先节点在A D集合的子集中
- 其他的节点不在A D集合的子集中
祖先节点在A D集合的子集中
我们都知道 先序遍历的顺序是 头 左 右
后序遍历的顺序是 左 右 头
所以说在先序遍历中 不管X为左子树还是右子树上的节点 它的祖先节点一定是在前面
在后序遍历中 不管X为左子树还是右子树上的节点 它的祖先节点一定是在后面
证毕
其他的节点不在A D集合的子集中
其他节点有四种情况
- 当X作为一个左子树时
- 当X作为一个右子树时
- 当X作为一个左子树上节点时它的右兄弟们
- 当X作为一个右子树上节点时它的左兄弟们
因为这四个问题实际上是两个镜像问题 所以我们讨论两个即可证明完毕
当X作为一个左子树(头节点)时
因为先序遍历的顺序为 头 左 右 所以说它的左右节点肯定在后面的集合中
因为后序遍历的顺序为 左 右 头 所以说它的左右节点肯定在前面的集合中
所以当X作为一个左子树时 它的子节点们不可能有交集
当X为右子树的时候同理
当X作为左子树上的一个节点的时
因为先序遍历的顺序为 头 左 右 所以说它的右兄弟们肯定是在后面的集合中
后序遍历的顺序为 左 右 头 所以说它的右兄弟们们肯定也是在后面的集合中
显然不属于A D的交集
当X作为一个右子树的时候同理
证明完毕
非递归方式实现二叉树遍历
面试中一般不会让我们使用递归方式来实现二叉树的遍历 如果我们用了 面试官也会让我们重新再使用非递归的方式写一遍
所以说我们也要掌握非递归方式的二叉树遍历
非递归方式实现二叉树的前序遍历
前序遍历的顺序是 头 左 右
我们可以通过栈结构来实现该遍历顺序
- 首先将头节点压栈
- 头节点出栈 之后将头节点的左右子节点按照右 左的顺序分别压栈(如果不存在就不操作)
- 接着弹出栈顶的一个元素 当作一个新的头节点来操作
- 重复步骤2 3 直到栈为空
这个的原理就是 我们可以将每个节点都看作是一个头节点 它的遍历顺序一定是 头 左 右
那么我们按照栈的顺序去运行(先入栈右 再入栈左) 那么遍历的顺序肯定是 头节点 左节点 右节点 而遍历到下一个节点的时候 又会是重复一遍上面的操作(相当于分解成了一个个的小任务)
所以说会造成先序遍历的效果
代码表示如下
class Solution {
public:vector<int> preorderTraversal(TreeNode* root) {stack<TreeNode*> st;vector<int> v;if (root == nullptr){return v;}st.push(root);TreeNode* cur = nullptr;while(!st.empty()){cur = st.top();st.pop();if (cur->right){st.push(cur->right);}if (cur->left){st.push(cur->left);}v.push_back(cur->val);}return v;}
};
非递归方式实现二叉树的后序遍历
我们前序遍历既然能通过压栈顺序实现头 左 右的顺序
那么我们控制下左右节点进入的时间我们就可以实现 头 右 左的顺序
之后我们再逆序一下 就能完成 左 右 头的顺序了 这也就是后序遍历的顺序
代码表示如下
class Solution {
public:vector<int> postorderTraversal(TreeNode* root) {stack<TreeNode*> st;vector<int> v;if (root == nullptr){return v;}st.push(root);TreeNode* cur = nullptr;while(!st.empty()){cur = st.top();st.pop();if (cur->left){st.push(cur->left);}if (cur->right){st.push(cur->right);}v.push_back(cur->val);}reverse(v.begin() , v.end());return v;}
};
非递归方式实现二叉树的中序遍历
其实中序遍历改非递归是最难理解的 但是实际上代码量并不多
- 头节点先进栈
- 我们设置一个当前指针cur指向栈中的第一个节点 以这个节点作为头节点 它的左节点全部入栈 直到遇到空节点为止
- 遇到空节点之后取出栈中的头节点 并且将其右节点入栈 (如果存在的话)
- 重复步骤2 3
代码表示如下
class Solution {
public:vector<int> inorderTraversal(TreeNode* root) {vector<int> v;if (root == nullptr){return v;}stack<TreeNode*> st;TreeNode* cur = root;while (!st.empty() || cur != nullptr){if (cur){st.push(cur);cur = cur->left;}else {cur = st.top();st.pop();v.push_back(cur->val);cur = cur->right;}}return v;}
};
原理解释如下
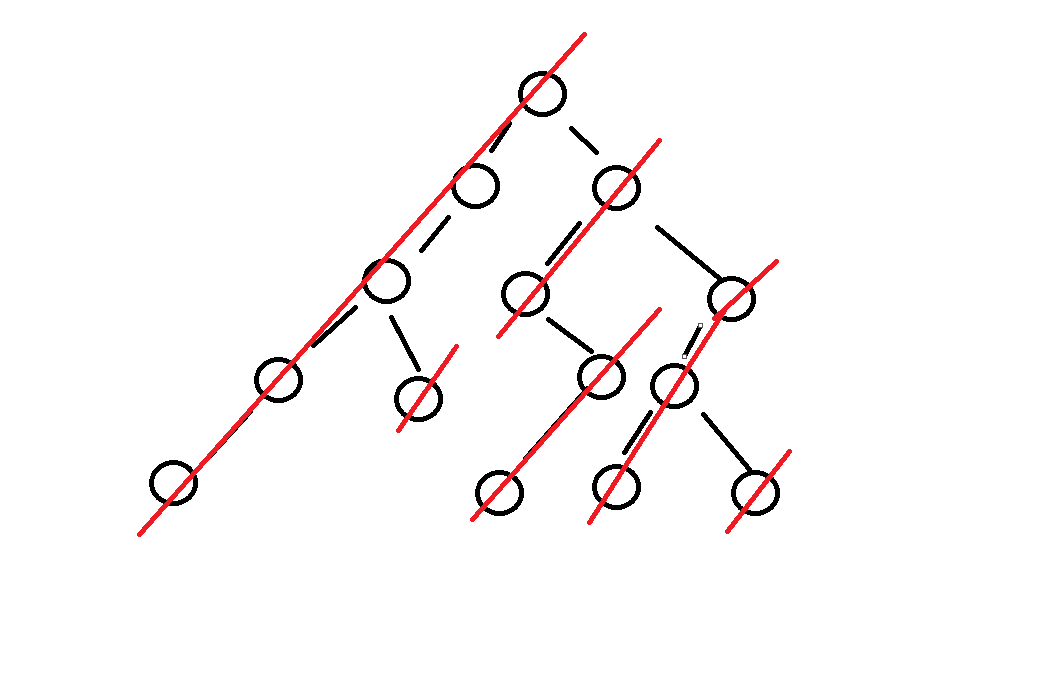
如上图所示 我们的二叉树一定可以被一颗子树的左边界分隔为两部分的
而对于整棵树来说 我们是先把我们的左边界压到栈中去的 所以说我们遍历的顺序一定是先左的
而当我们遍历到空的时候 我们会先打印当前节点 也就是 头
之后节点跳向右(也就是遍历右节点了)
而由于我们是按照栈的顺序存储着这些节点的 所以说一定是处理完左边界的每一棵树才会处理上面的内容 于是乎便会达到我们中序遍历的目的了
二叉树的层序遍历
关于层序遍历问题 博主之前写过博客介绍 这里就不过过多赘述了 具体可以参考我的这篇博客
二叉树的层序遍历
二叉树难题
二叉树的序列化和反序列化
二叉树的序列化和反序列化是leetcode上一道十分著名的题目
可是抛开这个题目本身不谈 二叉树的序列化和反序列化本身也是我们日常工作一个很重要的内容
这里首先介绍下序列化和反序列化
- 序列化: 将对象转化为字节流的过程
- 反序列化: 将字节流转化为对象的过程
因为我们平时在工作中 二叉树是保存在内存中的 而在内存中的二叉树结构我们并不能持久化保存 所以说我们需要进行序列化 方便在任何时间任何地点复现这颗二叉树
而序列化的一种比较好的方式 就是将二叉树转化为字符串
序列化一共有两种方式
一种是前序遍历序列化 一种是层序遍历序列化
前序遍历序列化和反序列化
前序遍历序列化要说简单其实也很简单
我们只需要按照前序的顺序将二叉树构造成一个字符串就行 如果出现空节点我们就将空节点定义为一个特殊字符比如说 ',' 又比如说 '*'
下面是序列化的代码
void rserialize(TreeNode* root , string& str){if (root == nullptr){str += "None,";}else{str += to_string(root->val) + ",";rserialize(root->left , str);rserialize(root->right , str);}}string serialize(TreeNode* root) {string ret; rserialize(root, ret);return ret;}
TreeNode* rdeserialize(list<string>& dataArray) {if (dataArray.front() == "None"){dataArray.erase(dataArray.begin());return nullptr;} TreeNode* root = new TreeNode(stoi(dataArray.front()));dataArray.erase(dataArray.begin());root->left = rdeserialize(dataArray);root->right = rdeserialize(dataArray);return root;}// Decodes your encoded data to tree.TreeNode* deserialize(string data) {list<string> dataArray;string str;for (auto& ch : data){if (ch == ','){dataArray.push_back(str);str.clear();}else {str.push_back(ch);}}if (!str.empty()){dataArray.push_back(str);str.clear();}return rdeserialize(dataArray);}
层序遍历序列化
层序遍历的序列化方式和层序遍历其实大差不差 唯一的区别就是将空指针也放入到其中(比如说我下面就使用None来标识一个空指针)
string serialize(TreeNode* root) {if (root == nullptr){return "";}list<string> dataArray;TreeNode* cur = root;dataArray.push_back(to_string(cur->val) + ",");queue<TreeNode*> q;q.push(root);while (!q.empty()){cur = q.front();q.pop();if (cur -> left){dataArray.push_back(to_string(cur->left->val) + ",");q.push(cur->left);}else {dataArray.push_back("None,");}if (cur->right){dataArray.push_back(to_string(cur->right->val) + ",");q.push(cur->right);}else {dataArray.push_back("None,");}}string ans;for (auto x : dataArray){ans += x;}return ans;}层序遍历的反序列化
反序列化的时候我们可以先将字符串分隔并且放到一个list中
再初始化一个队列 我们一次实例化每个队列中节点的左右子节点 如果非空则我们将左右节点放入到队列中去
// Decodes your encoded data to tree.TreeNode* deserialize(string data) {if (data == ""){return nullptr;}list<string> dataArray;string str;for (auto ch : data){if (ch == ','){dataArray.push_back(str);str.clear();}else {str += ch;} }TreeNode* cur = Build(dataArray.front());dataArray.erase(dataArray.begin());TreeNode* root = cur;queue<TreeNode*> que;que.push(cur);while (!que.empty() || !dataArray.empty()){cur = que.front();que.pop();cur -> left = Build(dataArray.front()); dataArray.erase(dataArray.begin());cur -> right = Build(dataArray.front()); dataArray.erase(dataArray.begin());if (cur -> left){que.push(cur->left);}if (cur->right){que.push(cur->right);}}return root;}
lc431
求二叉树最宽的层
该题目使用层序遍历就能很简单的解决 这里就不过多讲解了
二叉树的层序遍历参考上面的代码
二叉树的后继节点
首先我们给出定义 二叉树的后继节点就是在二叉树的中序遍历顺序中 该节点的下一个节点 (如果存在的话)
比如说下面这一棵二叉树
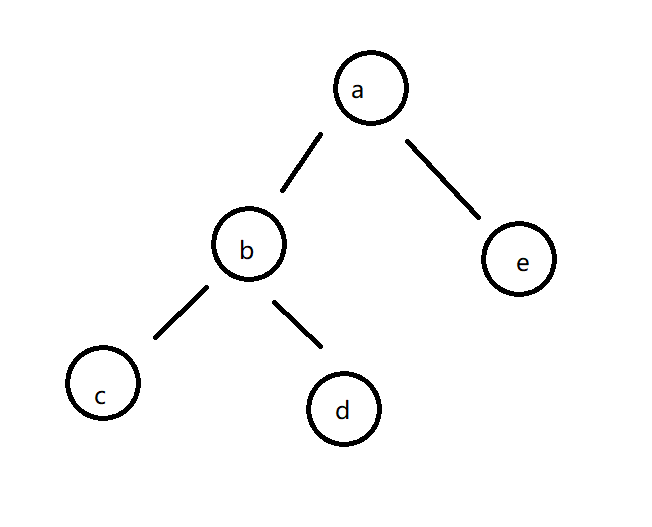
d的后继节点就是a
解决这个问题主要分两种情况讨论
- d节点有右孩子
- d节点没有右孩子
d节点有右孩子
如果d节点有右孩子的话 我们只需要找到它右子树的最左节点即可
(因为d节点打印完之后肯定打印它的右子树 而它右子树的最左节点则是最先被打印的)
d节点没有右孩子
此时我们向上找它的父节点
- 如果它是父节点的左孩子 那么父节点就是它的后继节点(因为这个时候父节点的左子树全部中序遍历完了)
- 如果它是父节点的右孩子 则一直向上找父节点 直到找到为止
谷歌面试题
我们拿出一个长纸条
先对折一次 我们会发现纸条中间出现了一个凹折痕 我们将其标记为1凹

之后我们将其恢复成对折一次的样子 再次对折 之后我们会发现 多出了两条新的折痕我们将凹下去的折痕标记为2凹 凸起的折痕标记为2凸
之后再重复上面的步骤一次 我们就能够得到下面这张图

通过观察我们可以发现 每个小折痕在对折之后就会在它的上下两侧出现一凹一凸两个折痕
由此我们就可以联想到二叉树
实际上就是 从头节点开始 头节点是凹折痕 之后它的左节点的凹折痕 右节点是凸折痕
以此类推
如果我们要通过中序遍历的方式从上到下打印出这些折痕 我们可以写出以下代码
我们定义 当bool b为真时是凹折痕 当为假时为凸折痕
那么代码如下
void process(int i , int n , bool b)
{if (i > n){return; } process(i+1 , n , 1); if (b) { cout << "a " ; } else { cout << "b "; } process(i+1 , n , 0);
}上面折断代码的意思是 我们假设这颗二叉树有n层高 我们目前在第i层
如果i>n 说明条件不满足 结束
之后我们让左节点打印a 右节点打印b 自己如果bool类型为真打印a 否则b

我们可以看到 与我们画的图一致
相关文章:
【Hello Algorithm】二叉树相关算法
本篇博客介绍:介绍二叉树的相关算法 二叉树相关算法 二叉树结构遍历二叉树递归序二叉树的交集非递归方式实现二叉树遍历二叉树的层序遍历 二叉树难题二叉树的序列化和反序列化lc431求二叉树最宽的层二叉树的后继节点谷歌面试题 二叉树结构 如果对于二叉树的结构还有…...
ExpressLRS开源代码之工程结构
ExpressLRS开源代码之工程结构 1. 源由2. 工程3. 开发环境安装4. pio命令5. ExpressLRS配置6. 硬件认证过程7. 参考资料 1. 源由 ExpressLRS开源代码基于Arduino框架设计,在所支持的硬件环境下,提供900/2400发射机和接收机硬件方案。 该设计提供了一个…...
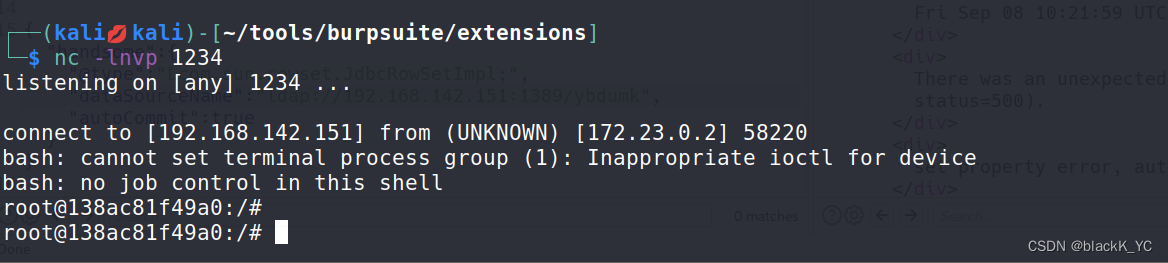
fastjson 1.2.24 反序列化导致任意命令执行漏洞复现
拉取docker容器 访问并抓包 修改为POST 方式,文件类型改为json格式,发送json数据包,发送成功 这里安装一个bp的插件 使用安装的插件 可以看到,插件告诉我们这里有漏洞,并且提供了POC 既然我们发现有 rmi ,…...
 rownum、rowid、oid)
探秘MySQL三个神秘隐藏列(mysql三个隐藏列) rownum、rowid、oid
探秘MySQL三个神秘隐藏列 MySQL是一款流行的关系型数据库管理系统,被广泛应用于Web应用程序开发和数据存储。然而,MySQL也有一些神秘的隐藏列,这些隐藏列可以帮助我们更好地管理和查询数据。 接下来,我们将探秘MySQL三个神秘隐藏…...
leetcode刷题--数组类
文章目录 1. 485 最大连续1的个数2. 495 提莫攻击3. 414 第三大的数4. 628 三个数的最大乘积5. 645 错误的集合6. 697 数组的度7. 448 找到所有数组中消失的数字9. 41 缺失的第一个正数10. 274 H指数11. 453 最小操作次数使得数组元素相等12. 665 非递减数列13. 283 移动零14. …...
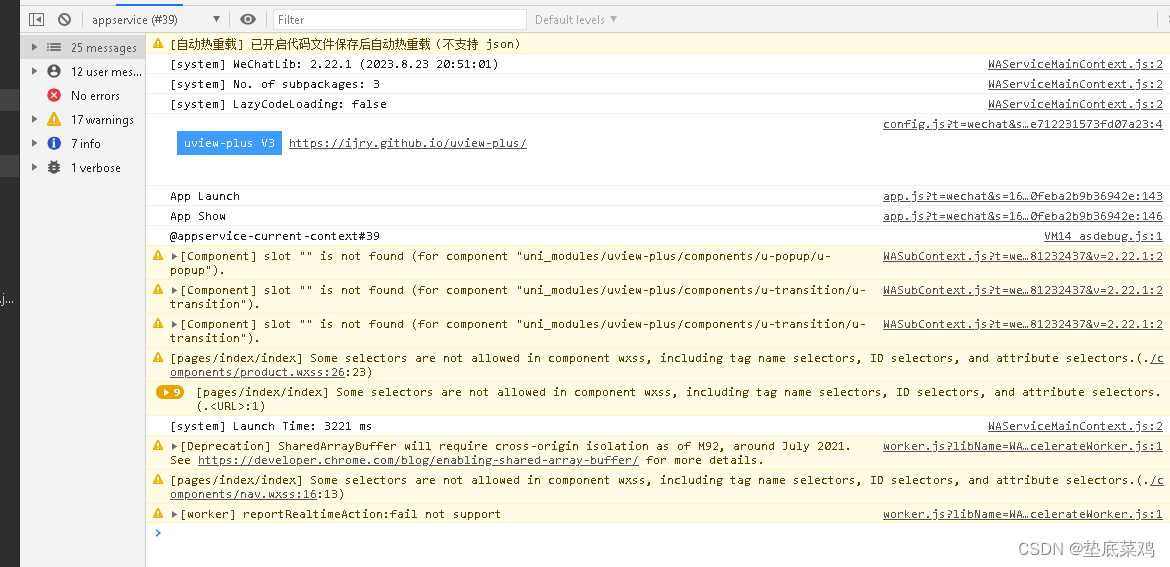
Vue3---uni-app--高德地图引用BUG
先给报错信息:module libs/map//libs/map_min.js is not defined, require args is /libs/map_min.js 查看我引用方法: 本人查阅资料发现 是 require 使用的是 commonJS方式引用说这个适配Vue2可我项目是Vue3应该使用ES6语法糖 然后我有跑了项目发现BU…...
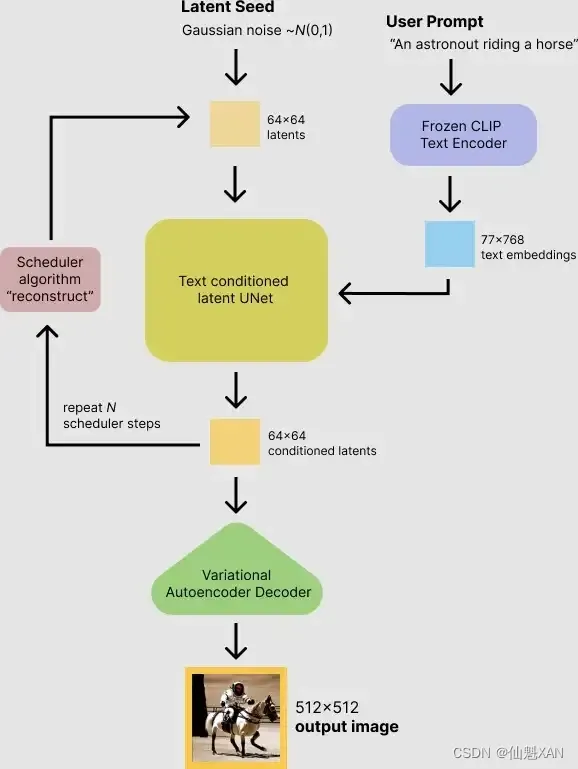
Stable Diffuse 之 本地环境部署/安装包下载搭建过程简单记录
Stable Diffuse 之 本地环境部署/安装包下载搭建过程简单记录 目录 Stable Diffuse 之 本地环境部署/安装包下载搭建过程简单记录 一、简单介绍 二、注意事项 三、环境搭建 git 下载和安装 python 下载和安装 stable-diffusion-webui 下载和安装 测试 stable diffuse w…...
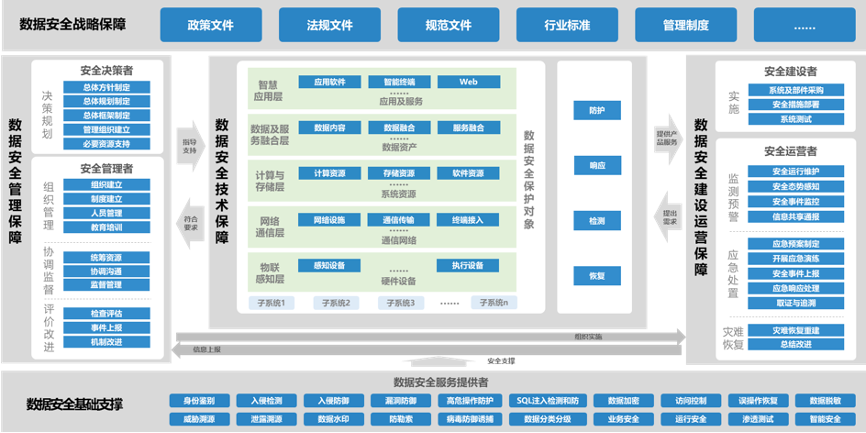
护航数字政府建设,美创科技成为“数字政府建设赋能计划”成员单位
近日,“2023软博会-软件驱动数字政府创新发展论坛”顺利召开,本次论坛由中国信息通信研究院、中国通信标准化协会承办,中国通信标准化协会云计算标准和开源推进委员会、数字政府建设赋能计划支持。 天津市工业和信息化局总经济师杨冬梅、中国…...
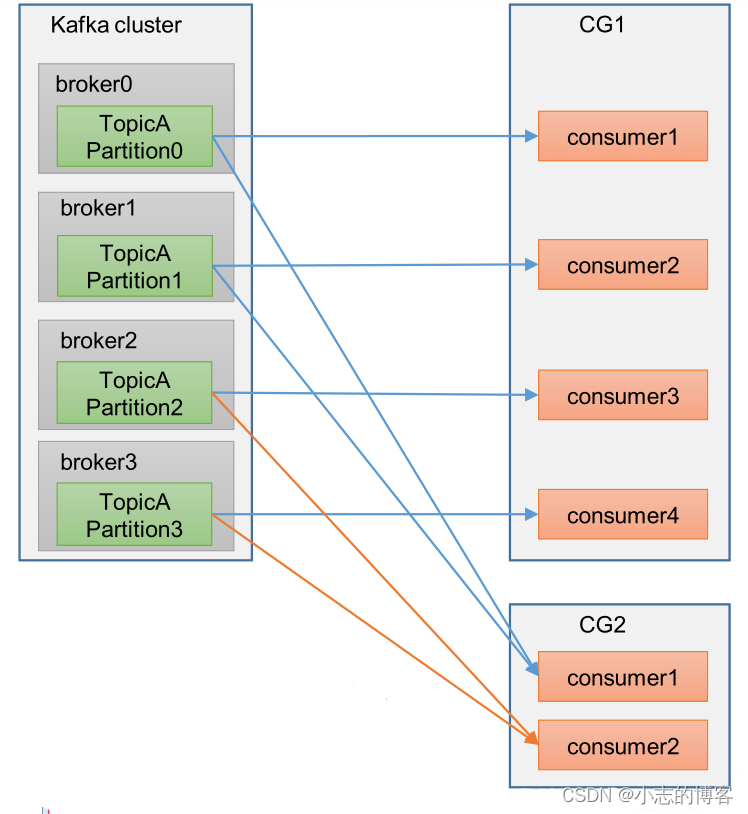
Kafka3.0.0版本——消费者(消费者组原理)
目录 一、消费者组原理1.1、消费者组概述1.2、消费者组图解示例1.3、消费者组注意事项 一、消费者组原理 1.1、消费者组概述 Consumer Group(CG):消费者组,由多个consumer组成。形成一个消费者组的条件,是所有消费者…...

天津web前端培训班 前端是否适合零基础学?
随着HTML 5和ECMAScript 6的正式发布,大量的前端业务逻辑,极大地增加了前端的代码量,前端代码的模块化、按需加载和依赖管理势在必行,因此Web前端越来越被人们重视。 Web前端的就业前景 Web前端开发工程师薪资持续走高ÿ…...

Paimon+StarRocks 湖仓一体数据分析方案
本文整理自阿里云高级开发工程师曾庆栋(曦乐)在 Streaming Lakehouse Meetup 分享的内容,深入探讨了传统数据仓库分析、PaimonStarRocks湖仓一体数据分析、StarRocks 与 Paimon 的协同使用方法与实现原理,以及StarRocks 社区湖仓分…...
界面控件DevExtreme(v23.2)下半年发展路线图
在这篇文章中,我们将介绍DevExtreme在v23.2中发布的一些主要特性,这些特性既适用于DevExtreme JavaScript (Angular、React、Vue、jQuery),也适用于基于DevExtreme的ASP. NET MVC/Core控件。 DevExtreme包含全面的高性能和响应式UI小部件集合…...

docker镜像配置mysql、redis
mysql 拉取mysql镜像 docker pull mysql:5.7创建并运行mysql容器 docker run -p 3306:3306 --name mysql\-v /mydata/mysql/log:/var/log/mysql\-v /mydata/mysql/data:/var/lib/mysql\-v /mydata/mysql/conf:/etc/mysql \-e MYSQL_ROOT_PASSWORD123456\-d mysql:5.7-e 设置…...

CentOS7无法连接网络 右上角网络图标消失
在使用 linux 的过程中,有时会出现网络图标消失的问题,这时系统会没有网络。 有些 linux 的网络连接由 NetworkManager 管理, 问题应由它解决。 先执行一下 systemctl restart NetworkManager 看有没有效果。 原因一 :NetworkMan…...

为什么创建 Redis 集群时会自动错开主从节点?
哈喽大家好,我是咸鱼 在《一台服务器上部署 Redis 伪集群》这篇文章中,咸鱼在创建 Redis 集群时并没有明确指定哪个 Redis 实例将担任 master,哪个将担任 slave /usr/local/redis-4.0.9/src/redis-trib.rb create --replicas 1 192.168.149…...
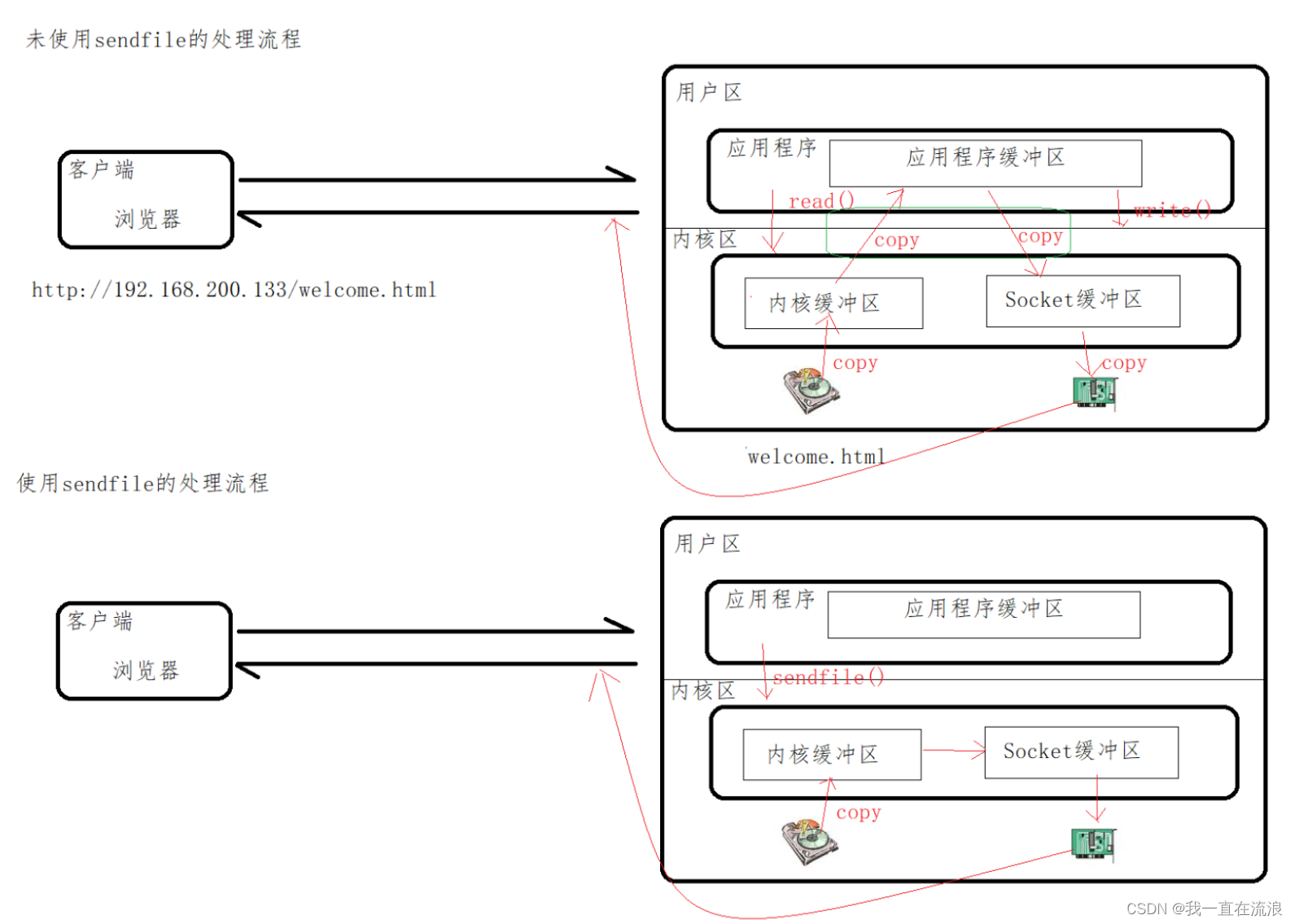
分布式 - 服务器Nginx:基础系列之Nginx静态资源配置优化sendfile | tcp_nopush | tcp_nodelay
文章目录 1. sendfile 指令2. tcp_nopush 指令3. tcp_nodelay 指令 1. sendfile 指令 请求静态资源的过程:客户端通过网络接口向服务端发送请求,操作系统将这些客户端的请求传递给服务器端应用程序,服务器端应用程序会处理这些请求ÿ…...

【动手学深度学习】--语言模型
文章目录 语言模型1.学习语言模型2.马尔可夫模型与N元语法3.自然语言统计4.读取长序列数据4.1随机采样4.2顺序分区 语言模型 学习视频:语言模型【动手学深度学习v2】 官方笔记:语言模型和数据集 在【文本预处理】中了解了如何将文本数据映射为词元&…...

uni-app 之 目录结构
目录结构: 工程简介 | uni-app官网 (dcloud.net.cn) pages/index/index.vue 页面元素等 static 静态文件,图片 字体文件等 App.vue 应用配置,用来配置App全局样式以及监听 应用生命周期 index.html 项目运行最终生成的文件 main.js 引用的…...

批量上传图片添加水印
思路: 1、循环图片列表,批量添加水印。 2、与之对应的html页面也要魂环并添加水印。 代码实现: <view style"width: 0;height: 0;overflow: hidden;position:fixed;left: 200%;"><canvas v-for"(item,index) in …...

CPU和GPU性能优化
在Unity游戏开发中,优化CPU和GPU的性能是非常重要的,可以提高游戏的运行效率、降低功耗和延迟,并提高用户体验。以下是一些优化CPU和GPU性能的方法: 1.优化游戏逻辑和算法 减少不必要的计算和内存操作,例如避免频繁的…...

【大模型RAG】拍照搜题技术架构速览:三层管道、两级检索、兜底大模型
摘要 拍照搜题系统采用“三层管道(多模态 OCR → 语义检索 → 答案渲染)、两级检索(倒排 BM25 向量 HNSW)并以大语言模型兜底”的整体框架: 多模态 OCR 层 将题目图片经过超分、去噪、倾斜校正后,分别用…...

基于FPGA的PID算法学习———实现PID比例控制算法
基于FPGA的PID算法学习 前言一、PID算法分析二、PID仿真分析1. PID代码2.PI代码3.P代码4.顶层5.测试文件6.仿真波形 总结 前言 学习内容:参考网站: PID算法控制 PID即:Proportional(比例)、Integral(积分&…...

AI Agent与Agentic AI:原理、应用、挑战与未来展望
文章目录 一、引言二、AI Agent与Agentic AI的兴起2.1 技术契机与生态成熟2.2 Agent的定义与特征2.3 Agent的发展历程 三、AI Agent的核心技术栈解密3.1 感知模块代码示例:使用Python和OpenCV进行图像识别 3.2 认知与决策模块代码示例:使用OpenAI GPT-3进…...
` 方法)
深入浅出:JavaScript 中的 `window.crypto.getRandomValues()` 方法
深入浅出:JavaScript 中的 window.crypto.getRandomValues() 方法 在现代 Web 开发中,随机数的生成看似简单,却隐藏着许多玄机。无论是生成密码、加密密钥,还是创建安全令牌,随机数的质量直接关系到系统的安全性。Jav…...

【磁盘】每天掌握一个Linux命令 - iostat
目录 【磁盘】每天掌握一个Linux命令 - iostat工具概述安装方式核心功能基础用法进阶操作实战案例面试题场景生产场景 注意事项 【磁盘】每天掌握一个Linux命令 - iostat 工具概述 iostat(I/O Statistics)是Linux系统下用于监视系统输入输出设备和CPU使…...

Java - Mysql数据类型对应
Mysql数据类型java数据类型备注整型INT/INTEGERint / java.lang.Integer–BIGINTlong/java.lang.Long–––浮点型FLOATfloat/java.lang.FloatDOUBLEdouble/java.lang.Double–DECIMAL/NUMERICjava.math.BigDecimal字符串型CHARjava.lang.String固定长度字符串VARCHARjava.lang…...
)
python爬虫:Newspaper3k 的详细使用(好用的新闻网站文章抓取和解析的Python库)
更多内容请见: 爬虫和逆向教程-专栏介绍和目录 文章目录 一、Newspaper3k 概述1.1 Newspaper3k 介绍1.2 主要功能1.3 典型应用场景1.4 安装二、基本用法2.2 提取单篇文章的内容2.2 处理多篇文档三、高级选项3.1 自定义配置3.2 分析文章情感四、实战案例4.1 构建新闻摘要聚合器…...

CocosCreator 之 JavaScript/TypeScript和Java的相互交互
引擎版本: 3.8.1 语言: JavaScript/TypeScript、C、Java 环境:Window 参考:Java原生反射机制 您好,我是鹤九日! 回顾 在上篇文章中:CocosCreator Android项目接入UnityAds 广告SDK。 我们简单讲…...

select、poll、epoll 与 Reactor 模式
在高并发网络编程领域,高效处理大量连接和 I/O 事件是系统性能的关键。select、poll、epoll 作为 I/O 多路复用技术的代表,以及基于它们实现的 Reactor 模式,为开发者提供了强大的工具。本文将深入探讨这些技术的底层原理、优缺点。 一、I…...

vue3+vite项目中使用.env文件环境变量方法
vue3vite项目中使用.env文件环境变量方法 .env文件作用命名规则常用的配置项示例使用方法注意事项在vite.config.js文件中读取环境变量方法 .env文件作用 .env 文件用于定义环境变量,这些变量可以在项目中通过 import.meta.env 进行访问。Vite 会自动加载这些环境变…...