【动手学深度学习】--语言模型
文章目录
- 语言模型
- 1.学习语言模型
- 2.马尔可夫模型与N元语法
- 3.自然语言统计
- 4.读取长序列数据
- 4.1随机采样
- 4.2顺序分区
语言模型
学习视频:语言模型【动手学深度学习v2】
官方笔记:语言模型和数据集
在【文本预处理】中了解了如何将文本数据映射为词元,以及将这些词元可以视为一系列离散的观测,例如单词或字符。假设长度为T的文本序列中的词元依次为 x 1 , x 2 , . . , x T x_1,x_2,..,x_T x1,x2,..,xT,于是, x t ( 1 ≤ t ≤ T ) x_t(1≤t≤T) xt(1≤t≤T)可以被认为是文本序列在时间步t处的观测或标签, 在给定这样的文本序列时,语言模型(language model)的目标是估计序列的联合概率 P ( x 1 , x 2 , . . . , x T ) P(x_1,x_2,...,x_T) P(x1,x2,...,xT)


1.学习语言模型
使用计数来建模



2.马尔可夫模型与N元语法


总结:
- 语言模型估计文本序列的联合概率
- 使用统计方法时常采用n元语法
3.自然语言统计
看看在真实数据上如果进行自然语言统计,根据前面介绍的时光机器数据集构建词表,并打印前10个最常用的(频率最高的)单词
import random
import torch
from d2l import torch as d2ltokens = d2l.tokenize(d2l.read_time_machine())
# 因为每个文本行不一定是一个句子或一个段落,因此我们把所有文本行拼接到一起
corpus = [token for line in tokens for token in line]
vocab = d2l.Vocab(corpus)
vocab.token_freqs[:10]
[('the', 2261),('i', 1267),('and', 1245),('of', 1155),('a', 816),('to', 695),('was', 552),('in', 541),('that', 443),('my', 440)]
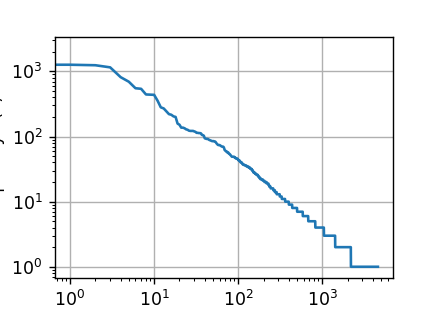
正如我们所看到的,最流行的词看起来很无聊, 这些词通常被称为停用词(stop words),因此可以被过滤掉。 尽管如此,它们本身仍然是有意义的,我们仍然会在模型中使用它们。 此外,还有个明显的问题是词频衰减的速度相当地快。 例如,最常用单词的词频对比,第10个还不到第1个的1/5。 为了更好地理解,我们可以画出的词频图:
freqs = [freq for token, freq in vocab.token_freqs]
d2l.plot(freqs, xlabel='token: x', ylabel='frequency: n(x)',xscale='log', yscale='log')

bigram_tokens = [pair for pair in zip(corpus[:-1], corpus[1:])]
bigram_vocab = d2l.Vocab(bigram_tokens)
bigram_vocab.token_freqs[:10]
[(('of', 'the'), 309),(('in', 'the'), 169),(('i', 'had'), 130),(('i', 'was'), 112),(('and', 'the'), 109),(('the', 'time'), 102),(('it', 'was'), 99),(('to', 'the'), 85),(('as', 'i'), 78),(('of', 'a'), 73)]
这里值得注意:在十个最频繁的词对中,有九个是由两个停用词组成的, 只有一个与“the time”有关。 我们再进一步看看三元语法的频率是否表现出相同的行为方式
trigram_tokens = [triple for triple in zip(corpus[:-2], corpus[1:-1], corpus[2:])]
trigram_vocab = d2l.Vocab(trigram_tokens)
trigram_vocab.token_freqs[:10]
[(('the', 'time', 'traveller'), 59),(('the', 'time', 'machine'), 30),(('the', 'medical', 'man'), 24),(('it', 'seemed', 'to'), 16),(('it', 'was', 'a'), 15),(('here', 'and', 'there'), 15),(('seemed', 'to', 'me'), 14),(('i', 'did', 'not'), 14),(('i', 'saw', 'the'), 13),(('i', 'began', 'to'), 13)]
最后,我们直观地对比三种模型中的词元频率:一元语法、二元语法和三元语法。
bigram_freqs = [freq for token, freq in bigram_vocab.token_freqs]
trigram_freqs = [freq for token, freq in trigram_vocab.token_freqs]
d2l.plot([freqs, bigram_freqs, trigram_freqs], xlabel='token: x',ylabel='frequency: n(x)', xscale='log', yscale='log',legend=['unigram', 'bigram', 'trigram'])
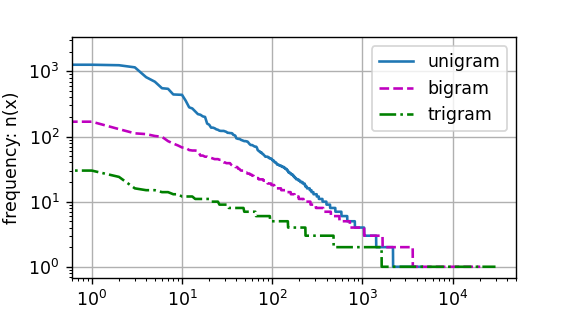
上述表明:
1.除了一元语法词,单词序列似乎也遵循齐普夫定律,尽管公式中的指数 α \alpha α更小(指数的大小受序列长度的影响)
2.词表中n元组的数量并没有那么大,这说明语言中存在相当多的结构,这些结构给了我们应用模型的希望
3.很多n元组很少出现,这使得拉普拉斯平滑非常不适合语言建模,作为代替,我们将使用基于深度学习的模型
4.读取长序列数据


4.1随机采样
在随机采样中,每个样本都是在原始的长序列上任意捕获的子序列。 在迭代过程中,来自两个相邻的、随机的、小批量中的子序列不一定在原始序列上相邻。 对于语言建模,目标是基于到目前为止我们看到的词元来预测下一个词元, 因此标签是移位了一个词元的原始序列。
下面的代码每次可以从数据中随机生成一个小批量。 在这里,参数batch_size指定了每个小批量中子序列样本的数目, 参数num_steps是每个子序列中预定义的时间步数。
def seq_data_iter_random(corpus, batch_size, num_steps): #@save"""使用随机抽样生成一个小批量子序列"""# 从随机偏移量开始对序列进行分区,随机范围包括num_steps-1corpus = corpus[random.randint(0, num_steps - 1):]# 减去1,是因为我们需要考虑标签num_subseqs = (len(corpus) - 1) // num_steps# 长度为num_steps的子序列的起始索引initial_indices = list(range(0, num_subseqs * num_steps, num_steps))# 在随机抽样的迭代过程中,# 来自两个相邻的、随机的、小批量中的子序列不一定在原始序列上相邻random.shuffle(initial_indices)def data(pos):# 返回从pos位置开始的长度为num_steps的序列return corpus[pos: pos + num_steps]num_batches = num_subseqs // batch_sizefor i in range(0, batch_size * num_batches, batch_size):# 在这里,initial_indices包含子序列的随机起始索引initial_indices_per_batch = initial_indices[i: i + batch_size]X = [data(j) for j in initial_indices_per_batch]Y = [data(j + 1) for j in initial_indices_per_batch]yield torch.tensor(X), torch.tensor(Y)
下面我们生成一个从0到34的序列。 假设批量大小为2,时间步数为5,这意味着可以生成 ⌊(35−1)/5⌋=6个“特征-标签”子序列对。 如果设置小批量大小为2,我们只能得到3个小批量。
my_seq = list(range(35))
for X, Y in seq_data_iter_random(my_seq, batch_size=2, num_steps=5):print('X: ', X, '\nY:', Y)
X: tensor([[13, 14, 15, 16, 17],[28, 29, 30, 31, 32]])
Y: tensor([[14, 15, 16, 17, 18],[29, 30, 31, 32, 33]])
X: tensor([[ 3, 4, 5, 6, 7],[18, 19, 20, 21, 22]])
Y: tensor([[ 4, 5, 6, 7, 8],[19, 20, 21, 22, 23]])
X: tensor([[ 8, 9, 10, 11, 12],[23, 24, 25, 26, 27]])
Y: tensor([[ 9, 10, 11, 12, 13],[24, 25, 26, 27, 28]])
4.2顺序分区
在迭代过程中,除了对原始序列可以随机抽样外, 我们还可以保证两个相邻的小批量中的子序列在原始序列上也是相邻的。 这种策略在基于小批量的迭代过程中保留了拆分的子序列的顺序,因此称为顺序分区。
def seq_data_iter_sequential(corpus, batch_size, num_steps): #@save"""使用顺序分区生成一个小批量子序列"""# 从随机偏移量开始划分序列offset = random.randint(0, num_steps)num_tokens = ((len(corpus) - offset - 1) // batch_size) * batch_sizeXs = torch.tensor(corpus[offset: offset + num_tokens])Ys = torch.tensor(corpus[offset + 1: offset + 1 + num_tokens])Xs, Ys = Xs.reshape(batch_size, -1), Ys.reshape(batch_size, -1)num_batches = Xs.shape[1] // num_stepsfor i in range(0, num_steps * num_batches, num_steps):X = Xs[:, i: i + num_steps]Y = Ys[:, i: i + num_steps]yield X, Y
基于相同的设置,通过顺序分区读取每个小批量的子序列的特征X和标签Y。 通过将它们打印出来可以发现: 迭代期间来自两个相邻的小批量中的子序列在原始序列中确实是相邻的。
for X, Y in seq_data_iter_sequential(my_seq, batch_size=2, num_steps=5):print('X: ', X, '\nY:', Y)
X: tensor([[ 0, 1, 2, 3, 4],[17, 18, 19, 20, 21]])
Y: tensor([[ 1, 2, 3, 4, 5],[18, 19, 20, 21, 22]])
X: tensor([[ 5, 6, 7, 8, 9],[22, 23, 24, 25, 26]])
Y: tensor([[ 6, 7, 8, 9, 10],[23, 24, 25, 26, 27]])
X: tensor([[10, 11, 12, 13, 14],[27, 28, 29, 30, 31]])
Y: tensor([[11, 12, 13, 14, 15],[28, 29, 30, 31, 32]])
现在,我们将上面的两个采样函数包装到一个类中, 以便稍后可以将其用作数据迭代器。
class SeqDataLoader: #@save"""加载序列数据的迭代器"""def __init__(self, batch_size, num_steps, use_random_iter, max_tokens):if use_random_iter:self.data_iter_fn = d2l.seq_data_iter_randomelse:self.data_iter_fn = d2l.seq_data_iter_sequentialself.corpus, self.vocab = d2l.load_corpus_time_machine(max_tokens)self.batch_size, self.num_steps = batch_size, num_stepsdef __iter__(self):return self.data_iter_fn(self.corpus, self.batch_size, self.num_steps)
最后,我们定义了一个函数load_data_time_machine, 它同时返回数据迭代器和词表, 因此可以与其他带有load_data前缀的函数
def load_data_time_machine(batch_size, num_steps, #@saveuse_random_iter=False, max_tokens=10000):"""返回时光机器数据集的迭代器和词表"""data_iter = SeqDataLoader(batch_size, num_steps, use_random_iter, max_tokens)return data_iter, data_iter.vocab
相关文章:
【动手学深度学习】--语言模型
文章目录 语言模型1.学习语言模型2.马尔可夫模型与N元语法3.自然语言统计4.读取长序列数据4.1随机采样4.2顺序分区 语言模型 学习视频:语言模型【动手学深度学习v2】 官方笔记:语言模型和数据集 在【文本预处理】中了解了如何将文本数据映射为词元&…...

uni-app 之 目录结构
目录结构: 工程简介 | uni-app官网 (dcloud.net.cn) pages/index/index.vue 页面元素等 static 静态文件,图片 字体文件等 App.vue 应用配置,用来配置App全局样式以及监听 应用生命周期 index.html 项目运行最终生成的文件 main.js 引用的…...

批量上传图片添加水印
思路: 1、循环图片列表,批量添加水印。 2、与之对应的html页面也要魂环并添加水印。 代码实现: <view style"width: 0;height: 0;overflow: hidden;position:fixed;left: 200%;"><canvas v-for"(item,index) in …...

CPU和GPU性能优化
在Unity游戏开发中,优化CPU和GPU的性能是非常重要的,可以提高游戏的运行效率、降低功耗和延迟,并提高用户体验。以下是一些优化CPU和GPU性能的方法: 1.优化游戏逻辑和算法 减少不必要的计算和内存操作,例如避免频繁的…...
虚拟机(三)VMware Workstation 桥接模式下无法上网
目录 一、背景二、解决方式方式一:关闭防火墙方式二:查看桥接模式下的物理网卡是否对应正确方式三:查看物理主机的网络属性 一、背景 今天在使用 VMware Workstation 里面安装的 Windows 虚拟机的时候,发现虽然在 NAT 模式下可以…...

[BFS] 广度优先搜索
1. 数字操作 常见的模板 // 使用一个数组判断元素是否入过队 int inqueue[N] {0}; // 层数或者可以称为深度 int step 0; // 判断是否可以入队的条件 int isvalid(){ } BFS(int x){ // 将初始的元素压入队列 // 注意每次压队的时候都要将inque[x] 1,表明入队过…...
)
蓝桥杯官网填空题(矩形切割)
题目描述 本题为填空题,只需要算出结果后,在代码中使用输出语句将所填结果输出即可。 小明有一些矩形的材料,他要从这些矩形材料中切割出一些正方形。 当他面对一块矩形材料时,他总是从中间切割一刀,切出一块最大的…...
通过Docker Compose安装MQTT
一、文件和目录说明 1、MQTT安装时的文件和目录 EMQX 安装完成后会创建一些目录用来存放运行文件和配置文件,存储数据以及记录日志。 不同安装方式得到的文件和目录位置有所不同,具体如下: 注意: 压缩包解压安装时,目…...

Golang企业面试题
Golang企业面试题 基础 高级 Golang有哪些优势?Golang数据类型有哪些Golang中的包如何使用Go 支持什么形式的类型转换?什么是 Goroutine?你如何停止它?如何在运行时检查变量类型?Go 两个接口之间可以存在什么关系&a…...
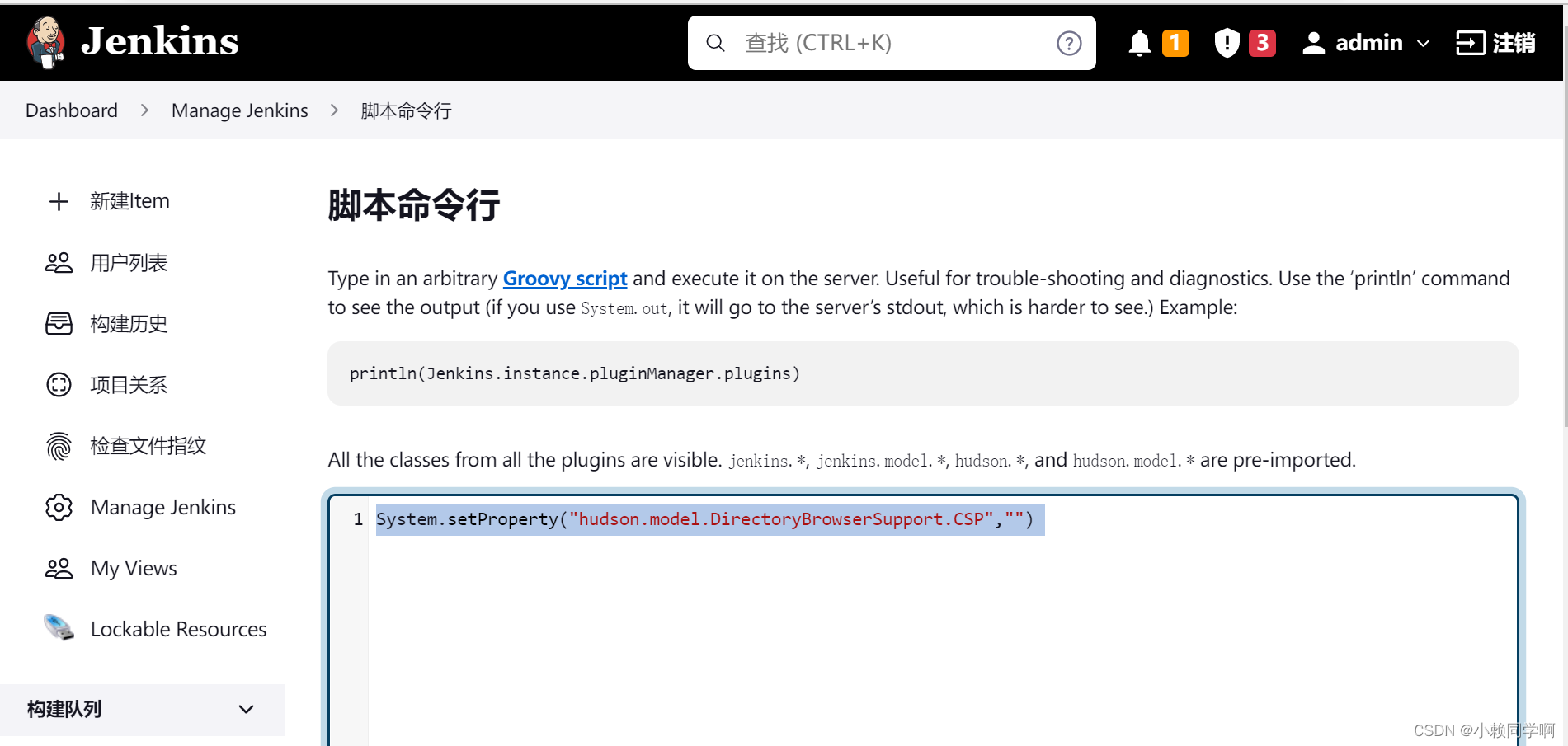
Jenkins测试报告样式优化
方式一:修改Content Security Policy(临时解决,Jenkins重启后失效) 1、jenkins首页—>ManageJenkins—>Tools and Actions标题下—>Script Console 2、粘贴脚本输入框中:System.setProperty("hudson.model.Directo…...
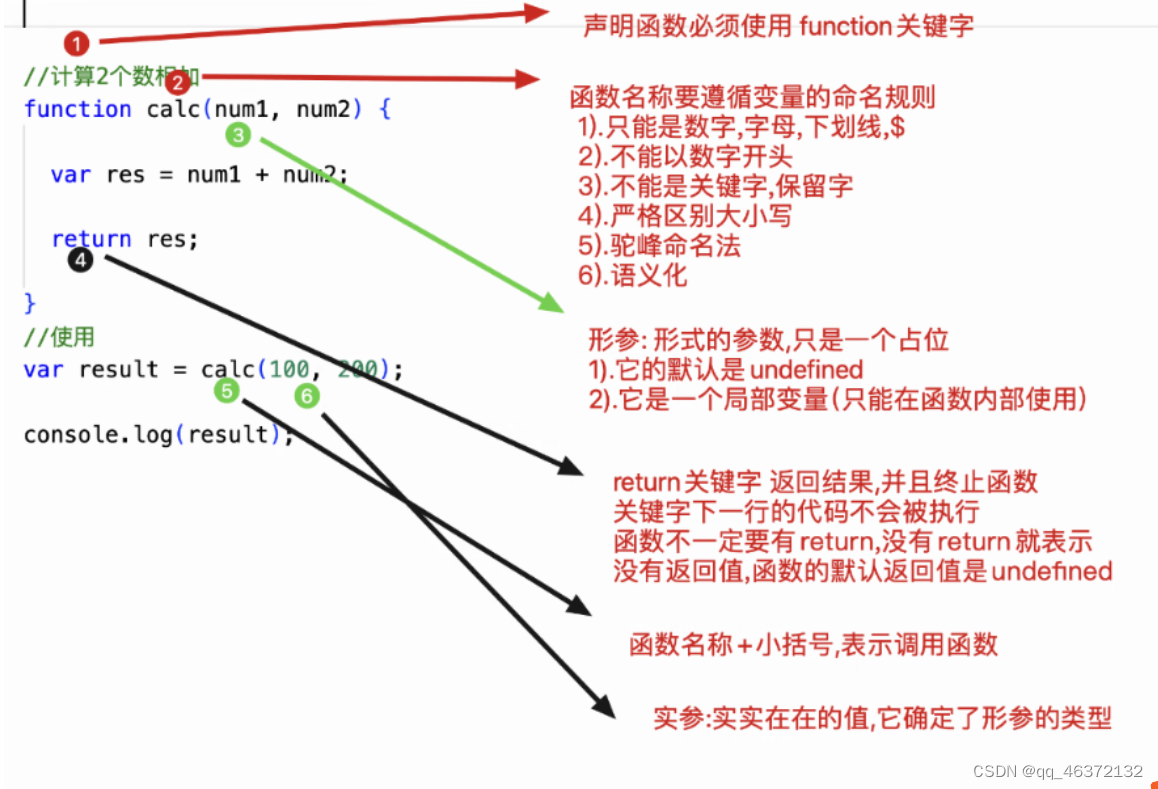
函数相关概念
4.函数 1.函数的概念 1.什么是函数? 把特点的代码片段,抽取成为独立运行的实体 2.使用函数的好处1.重复使用,提供效率2.提高代码的可读性3.有利用程序的维护 3.函数的分类1.内置函数(系统函数)已经提高的alert(); prompt();confirm();print()document.write(),console.log()…...

2023软考学习营
...
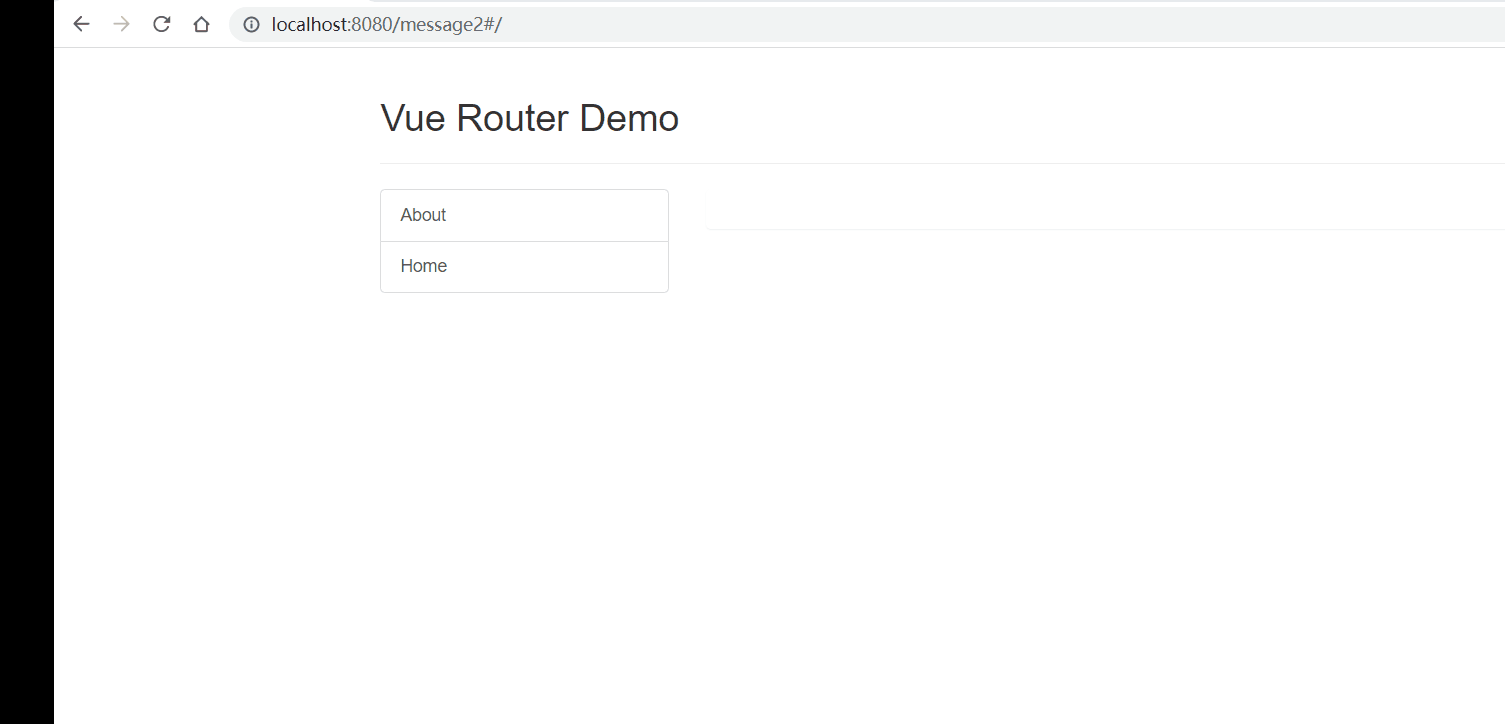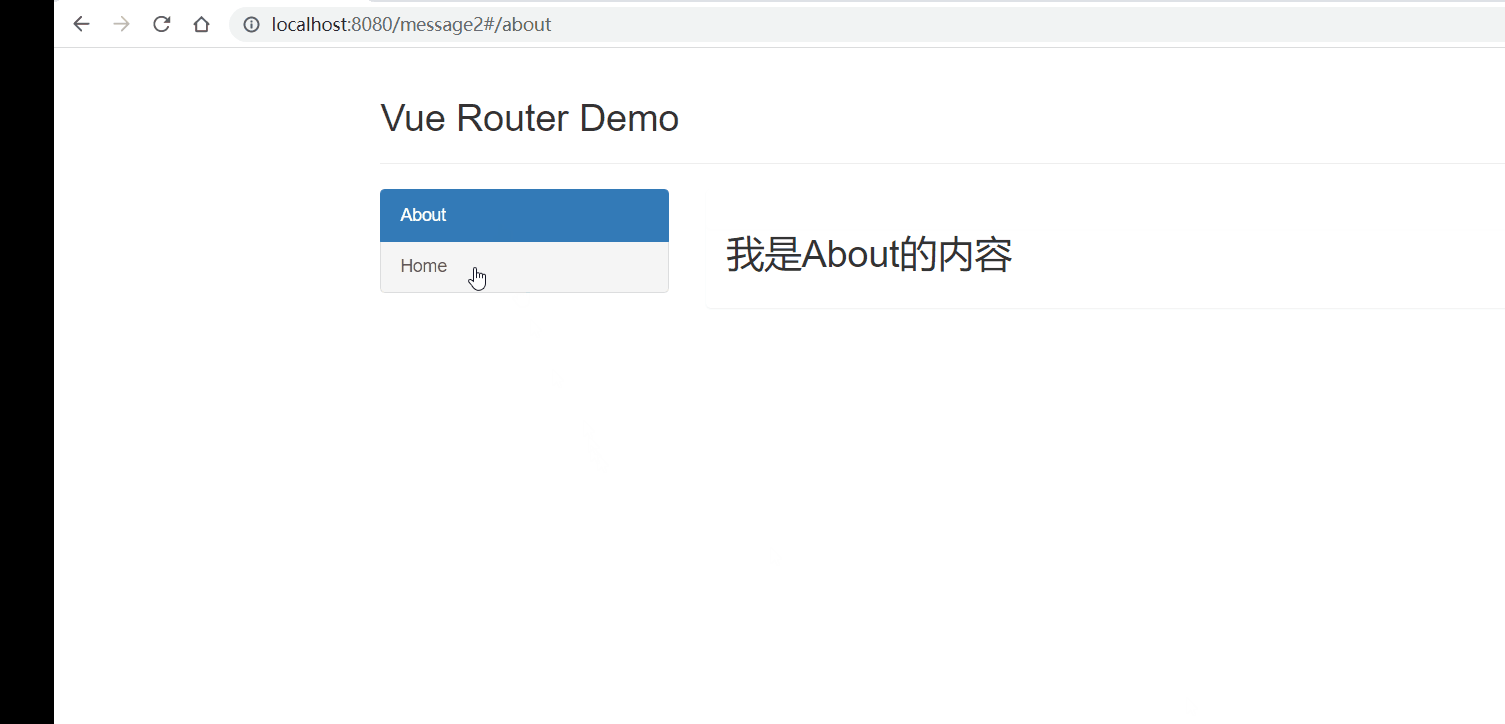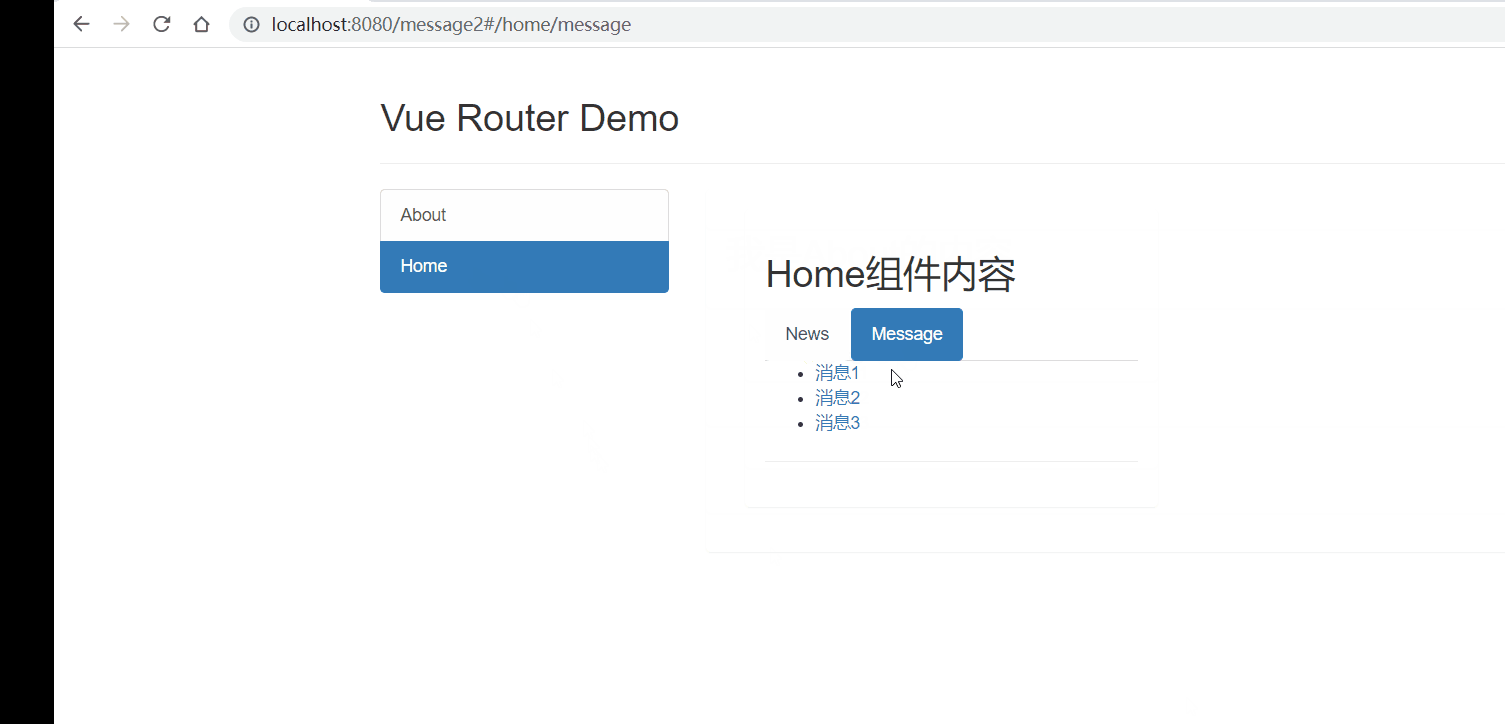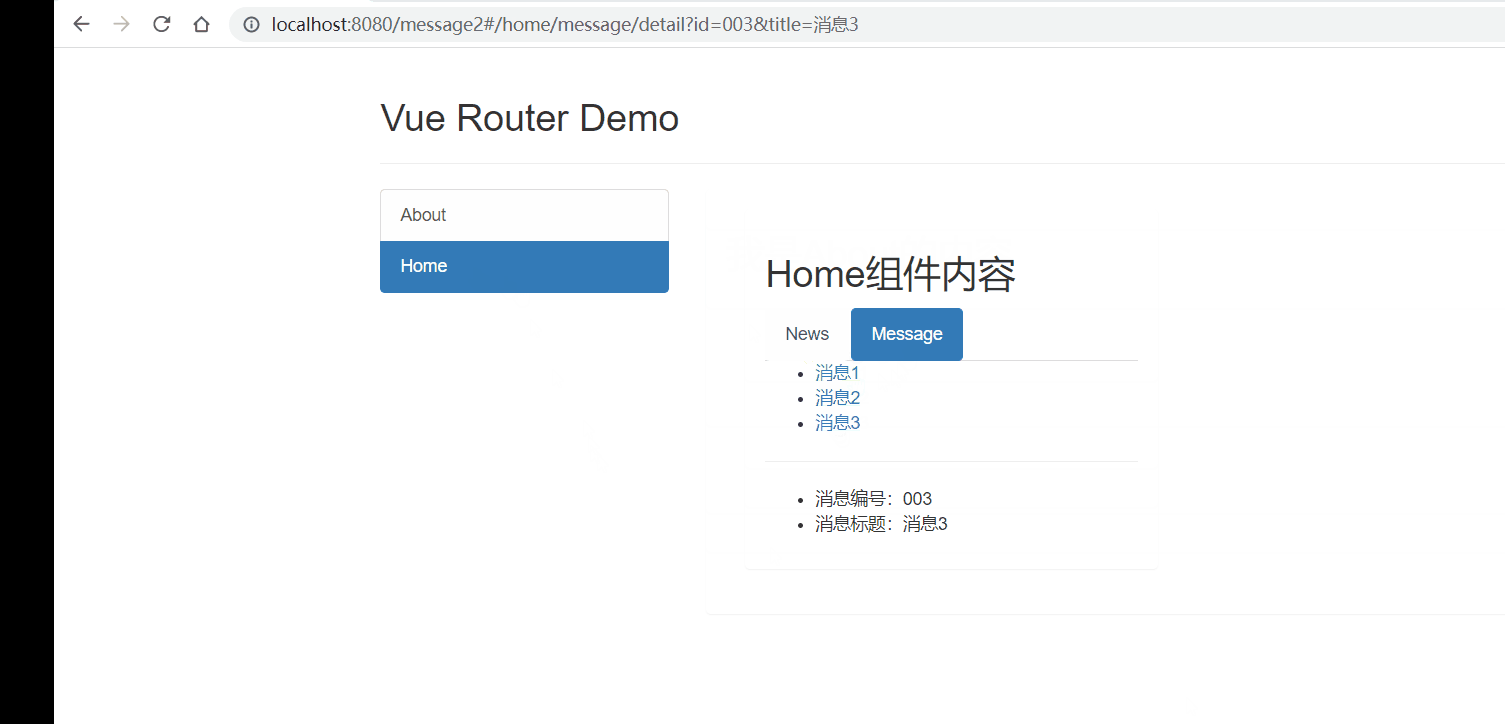
Vue2进阶篇学习笔记
文章目录 Vue2进阶学习笔记前言1、Vue脚手架学习1.1 Vue脚手架概述1.2 Vue脚手架安装1.3 常用属性1.4 插件 2、组件基本概述3、非单文件组件3.1 非单文件组件的基本使用3.2 组件的嵌套 4、单文件组件4.1 快速体验4.2 Todo案例 5、浏览器本地存储6、组件的自定义事件6.1 使用自定…...

Python 正则表达式:强大的文本处理工具
概念: 正则表达式是一种强大的文本匹配和处理工具,它可以用来在字符串中查找、替换和提取符合某种规则的内容。在Python中,使用re模块可以轻松地操作正则表达式,它提供了丰富的功能和灵活的语法。 场景: 正则表达式…...

Linux如何查看系统时间
文章目录 一、使用date命令查看系统时间二、通过/var/log/syslog文件查看系统时间三、通过/proc/uptime文件查看系统运行时间四、通过hwclock命令查看硬件时间五、通过timedatectl命令设置系统时区六、通过NTP协议同步网络时间七、通过ntpstat命令检查NTP同步状态八、使用cal命…...

46. 出勤率问题
文章目录 题目需求实现一题目来源 题目需求 现有用户出勤表(user_login)如下。 user_id (用户id)course_id (课程id)login_in (登录时间)login_out (登出时间)112022-06-02 09:08:242022-06-02 10:09:361…...
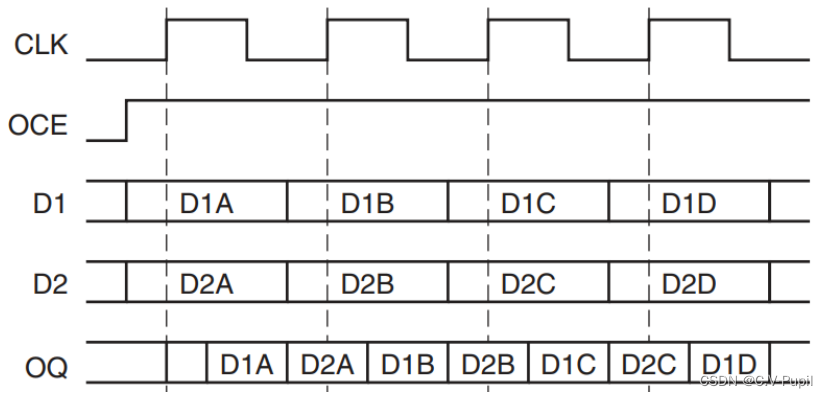
Xilinx IDDR与ODDR原语的使用
文章目录 ODDR原语1. OPPOSITE_EDGE 模式2. SAME_EDGE 模式 ODDR原语 例化模板: ODDR #(.DDR_CLK_EDGE("OPPOSITE_EDGE"), // "OPPOSITE_EDGE" or "SAME_EDGE" .INIT(1b0), // Initial value of Q: 1b0 or 1b1.SRTYPE("SYNC…...

面试系列 - 序列化和反序列化详解
Java 序列化是一种将对象转换为字节流的过程,可以将对象的状态保存到磁盘文件或通过网络传输。反序列化则是将字节流重新转换为对象的过程。Java 提供了一个强大的序列化框架,允许你在对象的持久化和网络通信中使用它。 一、Java 序列化的基本原理 Jav…...
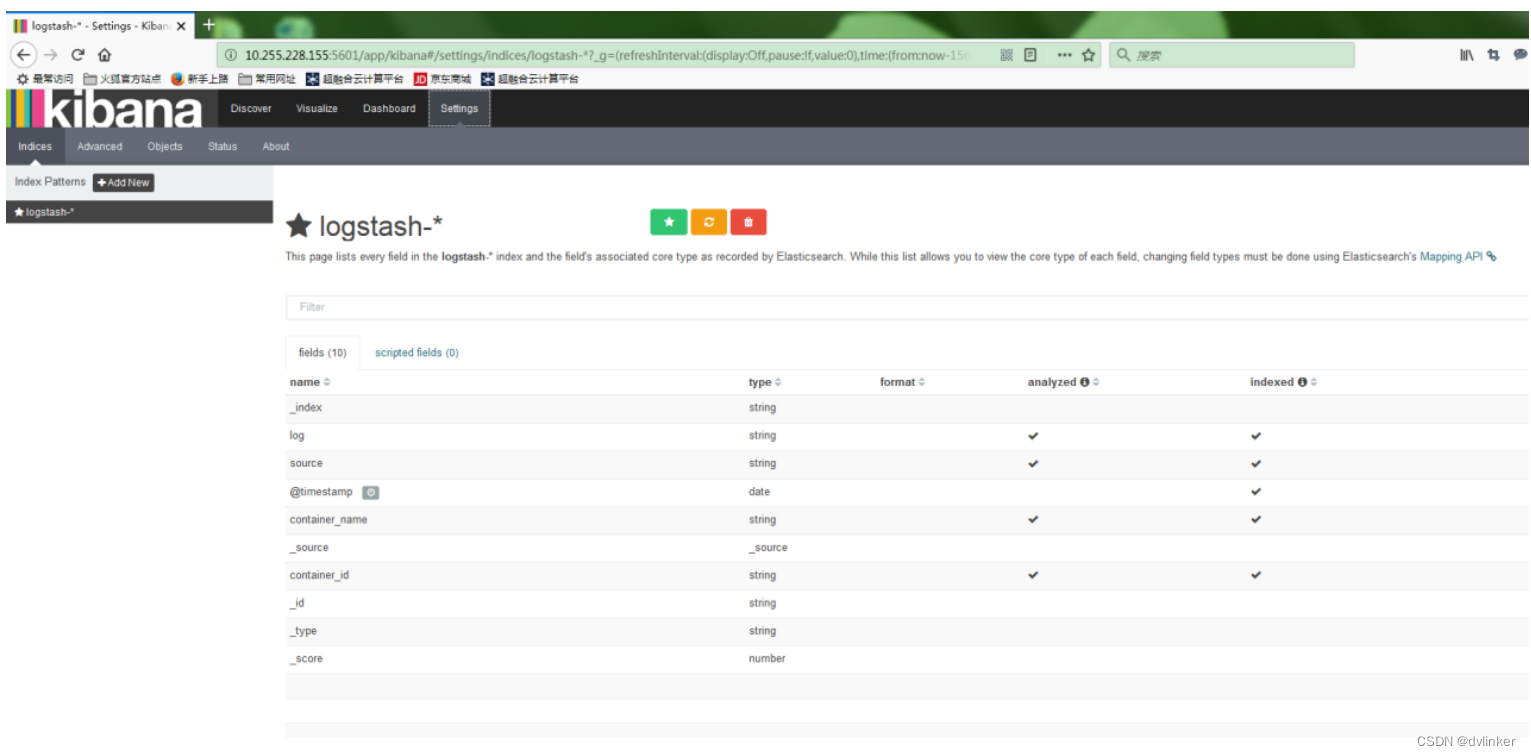
基于Elasticsearch + Fluentd + Kibana(EFK)搭建日志收集管理系统
目录 1、EFK简介 2、EFK框架 2.1、Fluentd系统架构 2.2、Elasticsearch系统架构 2.3、Kibana系统架构 3、Elasticsearch接口 4、EFK在虚拟机中安装步骤 4.1、安装elasticsearch 4.2、安装kibana 4.3、安装fluentd 4.4、进入kibana创建索引 5、Fluentd配置介绍 VC常…...

【Python小项目之Tkinter应用】解决Python的Pyinstaller将.py文件打包成.exe可执行文件后文件过大的问题
文章目录 前言1. 创建新项目2.删除原项目中的全部文件3.将要打包的文件放入该项目目录下4.创建虚拟环境5.设置解释器为虚拟环境中的python解释器6.查看是否成功使用虚拟环境中的python解…...

华为云AI开发平台ModelArts
华为云ModelArts:重塑AI开发流程的“智能引擎”与“创新加速器”! 在人工智能浪潮席卷全球的2025年,企业拥抱AI的意愿空前高涨,但技术门槛高、流程复杂、资源投入巨大的现实,却让许多创新构想止步于实验室。数据科学家…...

.Net框架,除了EF还有很多很多......
文章目录 1. 引言2. Dapper2.1 概述与设计原理2.2 核心功能与代码示例基本查询多映射查询存储过程调用 2.3 性能优化原理2.4 适用场景 3. NHibernate3.1 概述与架构设计3.2 映射配置示例Fluent映射XML映射 3.3 查询示例HQL查询Criteria APILINQ提供程序 3.4 高级特性3.5 适用场…...

Day131 | 灵神 | 回溯算法 | 子集型 子集
Day131 | 灵神 | 回溯算法 | 子集型 子集 78.子集 78. 子集 - 力扣(LeetCode) 思路: 笔者写过很多次这道题了,不想写题解了,大家看灵神讲解吧 回溯算法套路①子集型回溯【基础算法精讲 14】_哔哩哔哩_bilibili 完…...

[ICLR 2022]How Much Can CLIP Benefit Vision-and-Language Tasks?
论文网址:pdf 英文是纯手打的!论文原文的summarizing and paraphrasing。可能会出现难以避免的拼写错误和语法错误,若有发现欢迎评论指正!文章偏向于笔记,谨慎食用 目录 1. 心得 2. 论文逐段精读 2.1. Abstract 2…...

OkHttp 中实现断点续传 demo
在 OkHttp 中实现断点续传主要通过以下步骤完成,核心是利用 HTTP 协议的 Range 请求头指定下载范围: 实现原理 Range 请求头:向服务器请求文件的特定字节范围(如 Range: bytes1024-) 本地文件记录:保存已…...

视频字幕质量评估的大规模细粒度基准
大家读完觉得有帮助记得关注和点赞!!! 摘要 视频字幕在文本到视频生成任务中起着至关重要的作用,因为它们的质量直接影响所生成视频的语义连贯性和视觉保真度。尽管大型视觉-语言模型(VLMs)在字幕生成方面…...
可以参考以下方法:)
根据万维钢·精英日课6的内容,使用AI(2025)可以参考以下方法:
根据万维钢精英日课6的内容,使用AI(2025)可以参考以下方法: 四个洞见 模型已经比人聪明:以ChatGPT o3为代表的AI非常强大,能运用高级理论解释道理、引用最新学术论文,生成对顶尖科学家都有用的…...

return this;返回的是谁
一个审批系统的示例来演示责任链模式的实现。假设公司需要处理不同金额的采购申请,不同级别的经理有不同的审批权限: // 抽象处理者:审批者 abstract class Approver {protected Approver successor; // 下一个处理者// 设置下一个处理者pub…...
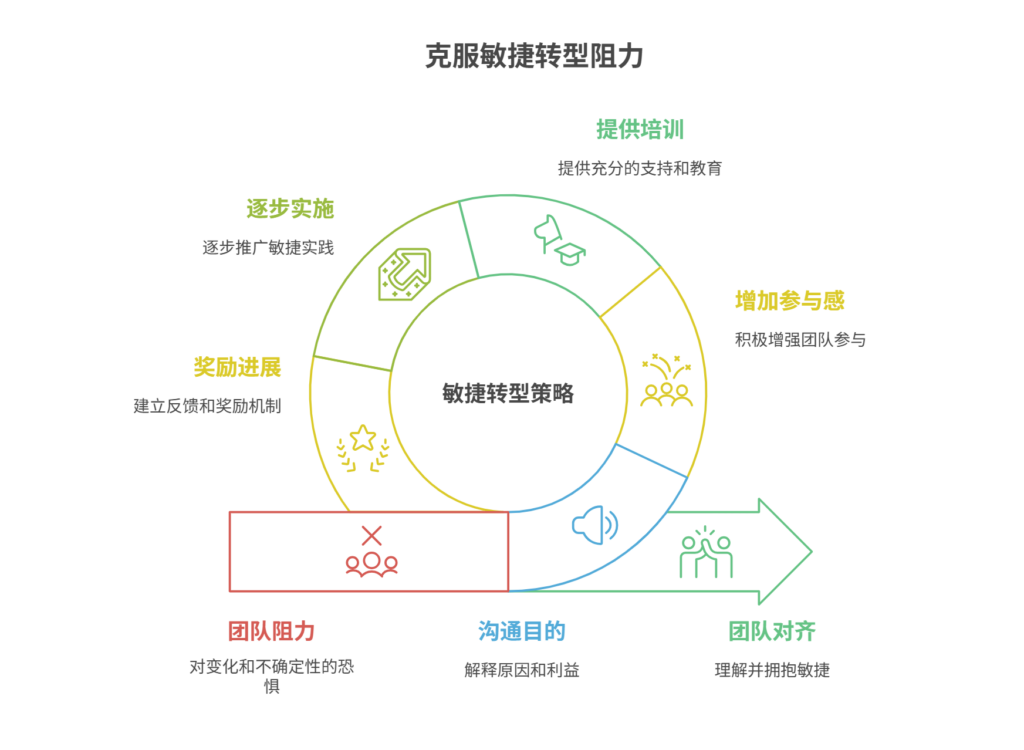
如何应对敏捷转型中的团队阻力
应对敏捷转型中的团队阻力需要明确沟通敏捷转型目的、提升团队参与感、提供充分的培训与支持、逐步推进敏捷实践、建立清晰的奖励和反馈机制。其中,明确沟通敏捷转型目的尤为关键,团队成员只有清晰理解转型背后的原因和利益,才能降低对变化的…...

实战三:开发网页端界面完成黑白视频转为彩色视频
一、需求描述 设计一个简单的视频上色应用,用户可以通过网页界面上传黑白视频,系统会自动将其转换为彩色视频。整个过程对用户来说非常简单直观,不需要了解技术细节。 效果图 二、实现思路 总体思路: 用户通过Gradio界面上…...