Dataset 的一些 Java api 操作
文章目录
- 一、使用 Java API 和 JavaRDD<Row> 在 Spark SQL 中向数据帧添加新列
- 二、foreachPartition 遍历 Dataset
- 三、Dataset 自定义 Partitioner
- 四、Dataset 重分区并且获取分区数
一、使用 Java API 和 JavaRDD 在 Spark SQL 中向数据帧添加新列
在应用 mapPartition 函数后创建一个新的数据框:
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.RowFactory;
import org.apache.spark.sql.SparkSession;
import org.apache.spark.sql.types.DataTypes;
import org.apache.spark.sql.types.StructType;import java.io.IOException;
import java.io.Serializable;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;public class Handler implements Serializable {public void handler(Dataset<Row> sourceData) {Dataset<Row> rowDataset = sourceData.where("rowKey = 'abcdefg_123'").selectExpr("split(rowKey, '_')[0] as id","name","time").where("name = '小强'").orderBy(functions.col("id").asc(), functions.col("time").desc());FlatMapFunction<Iterator<Row>,Row> mapPartitonstoTime = rows->{Int count = 0; // 只能在每个分区内自增,不能保证全局自增String startTime = "";String endTime = "";List<Row> mappedRows=new ArrayList<Row>();while(rows.hasNext()){count++;Row next = rows.next();String id = next.getAs("id");if (count == 2) {startTime = next.getAs("time");endTime = next.getAs("time");}Row mappedRow= RowFactory.create(next.getString(0), next.getString(1), next.getString(2), endTime, startTime);mappedRows.add(mappedRow);}return mappedRows.iterator();};JavaRDD<Row> sensorDataDoubleRDD=rowDataset.toJavaRDD().mapPartitions(mapPartitonstoTime);StructType oldSchema=rowDataset.schema();StructType newSchema =oldSchema.add("startTime",DataTypes.StringType,false).add("endTime",DataTypes.StringType,false);System.out.println("The new schema is: ");newSchema.printTreeString();System.out.println("The old schema is: ");oldSchema.printTreeString();Dataset<Row> sensorDataDoubleDF=spark.createDataFrame(sensorDataDoubleRDD, newSchema);sensorDataDoubleDF.show(100, false);}
}
打印结果:
The new schema is:
root|-- id: string (nullable = true)|-- name: string (nullable = true)|-- time: string (nullable = true)The old schema is:
root|-- id: string (nullable = true)|-- name: string (nullable = true)|-- time: string (nullable = true)|-- startTime: string (nullable = true)|-- endTime: string (nullable = true)+-----------+---------+----------+----------+----------+
|id |name |time |startTime |endTime |
+-----------+---------+----------+----------+----------+
|abcdefg_123|xiaoqiang|1693462023|1693462023|1693462023|
|abcdefg_321|xiaoliu |1693462028|1693462028|1693462028|
+-----------+---------+----------+----------+----------+
参考:
java - 使用 Java API 和 JavaRDD 在 Spark SQL 中向数据帧添加新列
java.util.Arrays$ArrayList cannot be cast to java.util.Iterator
二、foreachPartition 遍历 Dataset
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.function.VoidFunction;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;import java.io.IOException;
import java.io.Serializable;
import java.util.Iterator;public class Handler implements Serializable {public void handler(Dataset<Row> sourceData) {JavaRDD<Row> dataRDD = rowDataset.toJavaRDD();dataRDD.foreachPartition(new VoidFunction<Iterator<Row>>() {@Overridepublic void call(Iterator<Row> rowIterator) throws Exception {while (rowIterator.hasNext()) {Row next = rowIterator.next();String id = next.getAs("id");if (id.equals("123")) {String startTime = next.getAs("time");// 其他业务逻辑}}}});// 转换为 lambda 表达式dataRDD.foreachPartition((VoidFunction<Iterator<Row>>) rowIterator -> {while (rowIterator.hasNext()) {Row next = rowIterator.next();String id = next.getAs("id");if (id.equals("123")) {String startTime = next.getAs("time");// 其他业务逻辑}}});}
}
三、Dataset 自定义 Partitioner
参考:spark 自定义 partitioner 分区 java 版
import org.apache.commons.collections.CollectionUtils;
import org.apache.spark.Partitioner;
import org.junit.Assert;import java.util.List;
import java.util.Map;
import java.util.concurrent.ConcurrentHashMap;/*** Created by lesly.lai on 2018/7/25.*/
public class CuxGroupPartitioner extends Partitioner {private int partitions;/*** map<key, partitionIndex>* 主要为了区分不同分区*/private Map<Object, Integer> hashCodePartitionIndexMap = new ConcurrentHashMap<>();public CuxGroupPartitioner(List<Object> groupList) {int size = groupList.size();this.partitions = size;initMap(partitions, groupList);}private void initMap(int size, List<Object> groupList) {Assert.assertTrue(CollectionUtils.isNotEmpty(groupList));for (int i=0; i<size; i++) {hashCodePartitionIndexMap.put(groupList.get(i), i);}}@Overridepublic int numPartitions() {return partitions;}@Overridepublic int getPartition(Object key) {return hashCodePartitionIndexMap.get(key);}public boolean equals(Object obj) {if (obj instanceof CuxGroupPartitioner) {return ((CuxGroupPartitioner) obj).partitions == partitions;}return false;}
}
查看分区分布情况工具类:
(1)Scala:
import org.apache.spark.sql.{Dataset, Row}/*** Created by lesly.lai on 2017/12FeeTask/25.*/
class SparkRddTaskInfo {def getTask(dataSet: Dataset[Row]) {val size = dataSet.rdd.partitions.lengthprintln(s"==> partition size: $size " )import scala.collection.Iteratorval showElements = (it: Iterator[Row]) => {val ns = it.toSeqimport org.apache.spark.TaskContextval pid = TaskContext.get.partitionIdprintln(s"[partition: $pid][size: ${ns.size}] ${ns.mkString(" ")}")}dataSet.foreachPartition(showElements)}
}
(2)Java:
import org.apache.spark.TaskContext;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.function.VoidFunction;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;public class SparkRddTaskInfo {public static void getTask(Dataset<Row> dataSet) {int size = dataSet.rdd().partitions().length;System.out.println("==> partition size:" + size);JavaRDD<Row> dataRDD = dataSet.toJavaRDD();dataRDD.foreachPartition((VoidFunction<Iterator<Row>>) rowIterator -> {List<String> mappedRows = new ArrayList<String>();int count = 0;while (rowIterator.hasNext()) {Row next = rowIterator.next();String id = next.getAs("id");String partitionKey = next.getAs("partition_key");String name = next.getAs("name");mappedRows.add(id + "/" + partitionKey+ "/" + name);}int pid = TaskContext.get().partitionId();System.out.println("[partition: " + pid + "][size: " + mappedRows.size() + "]" + mappedRows);});}
}
调用方式:
import com.vip.spark.db.ConnectionInfos;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.sql.Column;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
import scala.Tuple2;import java.util.List;
import java.util.stream.Collectors;/*** Created by lesly.lai on 2018/7/23.*/
public class SparkSimpleTestPartition {public static void main(String[] args) throws InterruptedException {SparkSession sparkSession = SparkSession.builder().appName("Java Spark SQL basic example").getOrCreate();// 原始数据集Dataset<Row> originSet = sparkSession.read().jdbc(ConnectionInfos.TEST_MYSQL_CONNECTION_URL, "people", ConnectionInfos.getTestUserAndPasswordProperties());originSet.selectExpr("split(rowKey, '_')[0] as id","concat(split(rowKey, '_')[0],'_',split(rowKey, '_')[1]) as partition_key","split(rowKey, '_')[1] as name".createOrReplaceTempView("people");// 获取分区分布情况工具类SparkRddTaskInfo taskInfo = new SparkRddTaskInfo();Dataset<Row> groupSet = sparkSession.sql(" select partition_key from people group by partition_key");List<Object> groupList = groupSet.javaRDD().collect().stream().map(row -> row.getAs("partition_key")).collect(Collectors.toList());// 创建pairRDD 目前只有pairRdd支持自定义partitioner,所以需要先转成pairRddJavaPairRDD pairRDD = originSet.javaRDD().mapToPair(row -> {return new Tuple2(row.getAs("partition_key"), row);});// 指定自定义partitionerJavaRDD javaRdd = pairRDD.partitionBy(new CuxGroupPartitioner(groupList)).map(new Function<Tuple2<String, Row>, Row>(){@Overridepublic Row call(Tuple2<String, Row> v1) throws Exception {return v1._2;}});Dataset<Row> result = sparkSession.createDataFrame(javaRdd, originSet.schema());// 打印分区分布情况taskInfo.getTask(result);}
}
四、Dataset 重分区并且获取分区数
System.out.println("1-->"+rowDataset.rdd().partitions().length);System.out.println("1-->"+rowDataset.rdd().getNumPartitions());Dataset<Row> hehe = rowDataset.coalesce(1);System.out.println("2-->"+hehe.rdd().partitions().length);System.out.println("2-->"+hehe.rdd().getNumPartitions());
运行结果:
1-->29
1-->29
2-->2
2-->2
注意:在使用 repartition() 时两次打印的结果相同:
print(rdd.getNumPartitions())
rdd.repartition(100)
print(rdd.getNumPartitions())
产生上述问题的原因有两个:
首先 repartition() 是惰性求值操作,需要执行一个 action 操作才可以使其执行。
其次,repartition() 操作会返回一个新的 rdd,并且新的 rdd 的分区已经修改为新的分区数,因此必须使用返回的 rdd,否则将仍在使用旧的分区。
修改为:rdd2 = rdd.repartition(100)
参考:repartition() is not affecting RDD partition size
相关文章:

Dataset 的一些 Java api 操作
文章目录 一、使用 Java API 和 JavaRDD<Row> 在 Spark SQL 中向数据帧添加新列二、foreachPartition 遍历 Dataset三、Dataset 自定义 Partitioner四、Dataset 重分区并且获取分区数 一、使用 Java API 和 JavaRDD 在 Spark SQL 中向数据帧添加新列 在应用 mapPartition…...

Vue + Element UI 前端篇(十一):第三方图标库
Vue Element UI 实现权限管理系统 前端篇(十一):第三方图标库 使用第三方图标库 用过Elment的同鞋都知道,Element UI提供的字体图符少之又少,实在是不够用啊,幸好现在有不少丰富的第三方图标库可用&…...
)
HDFS:Hadoop文件系统(HDFS)
Hadoop文件系统(HDFS)是一个分布式文件系统,主要用于存储和处理大规模的数据集。HDFS是Apache Hadoop的核心组件之一,能够支持上千个节点的集群,并能够处理PB级别的数据。 HDFS将大文件切割成小的数据块(默…...

SpringMvc--综合案例
目录 1.SpringMvc的常用注解 2.参数传递 基础类型(String) 创建一个paramController类: 创建一个index.jsp 测试结果 复杂方式 编辑 测试结果 RequestParam 测试结果 PathVariable 测试结果 RequestBody pom.xml依赖导入 输…...

工业4.0时代生产系统对接集成优势,MES和ERP专业一体化管理-亿发
在现代制造业中,市场变化都在不断加速。企业面临着不断加强生产效率、生产质量和快速适应市场需求的挑战。在制造行业,日常管理中的ERP系统、MES系统就显得尤为重要。越来越多的企业正在采用MES系统和ERP管理系统的融合,以实现智能化生产管理…...

IT运维监控系统和网络运维一样吗
IT运维监控系统和网络运维不是一样的。IT运维监控系统是一系列IT管理产品的统称,它所包含的产品功能强大、易于使用、解决方案齐全,可一站式满足用户的各种IT管理需求。而网络运维是指对网络设备进行监控、维护和管理,包括硬件故障的排除、软…...

c语言flag的使用
flag在c语言中标识某种状态或记录某种信息,可以通过修改flag中来控制程序流程,判断某种状态是否存在或记录某种信息 操作:(1)初始化 (2)赋值 (3)判断 (4)修改 (5)去初始化 #include <stdlib.h>int power_state_check;int main() {int i 0;power_state_check…...

docker push image harbor http 镜像
前言 搭建的 harbor 仓库为 http 协议,在本地登录后,推送镜像发生如下报错: docker push 192.168.xx.xx/test/grafana:v10.1.1 The push refers to repository [192.168.xx.xx/test/grafana] Get "https://192.168.xx.xx/v2/": dia…...
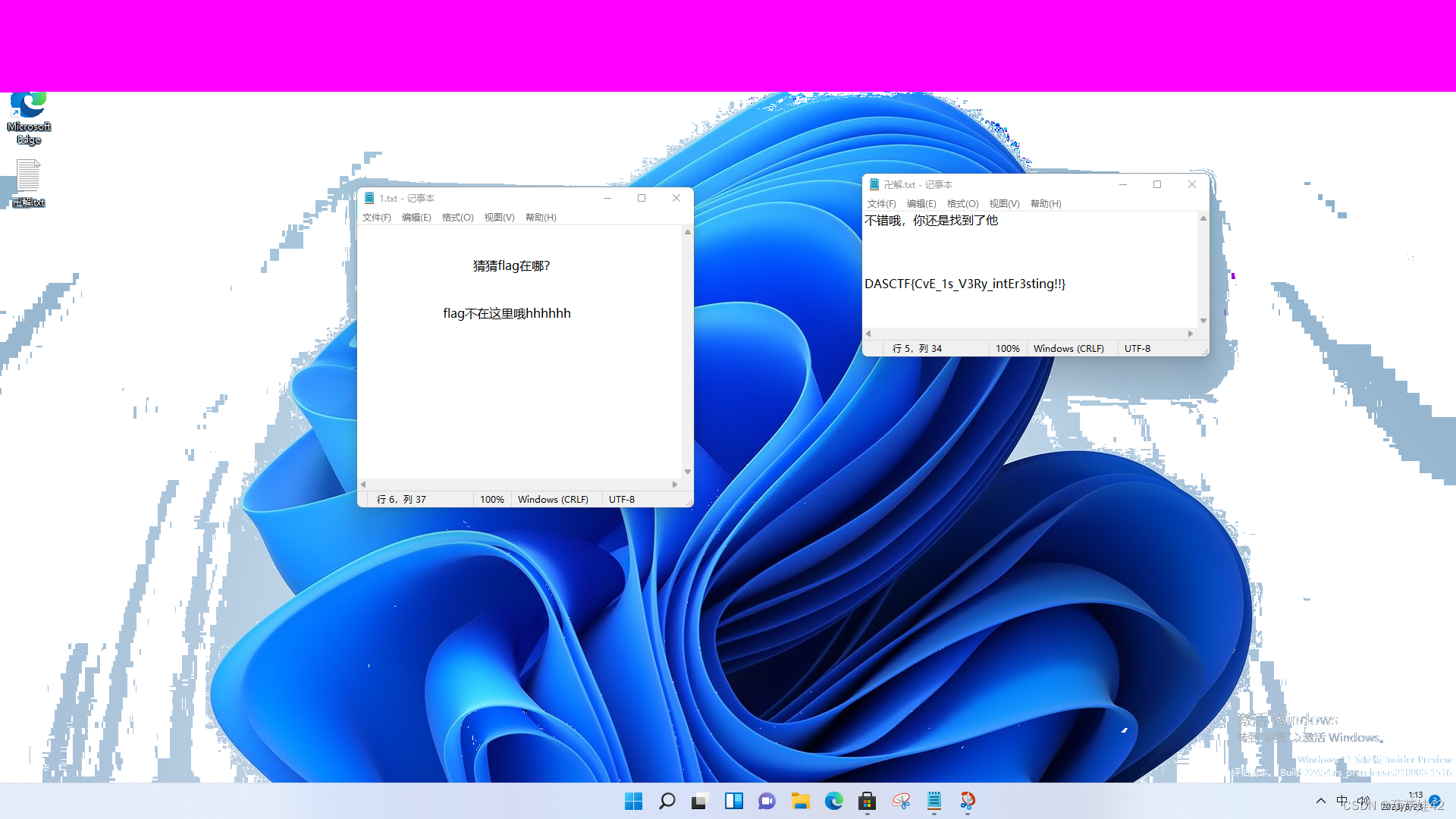
羊城杯2023 部分wp
目录 D0nt pl4y g4m3!!!(php7.4.21源码泄露&pop链构造) Serpent(pickle反序列化&python提权) ArkNights(环境变量泄露) Ez_misc(win10sinpping_tools恢复) D0nt pl4y g4m3!!!(php7.4.21源码泄露&pop链构造) 访问/p0p.php 跳转到了游戏界面 应该是存在302跳转…...

解读Java对Execl读取数据
1.读取execl文件路径,或者打开execl // 初始化文件流FileInputStream in = null;in = new FileInputStream(new File(path));workbook = new XSSFWorkbook(in);sheet = workbook.getSheetAt(0);rows = sheet.getPhysicalNumberOfRows(); 2.读取execl中sheet页数,即获取当前E…...
RHCE——十七、文本搜索工具-grep、正则表达式
RHCE 一、文本搜索工具--grep1、作用2、格式3、参数4、注意5、示例5.1 操作对象文件:/etc/passwd5.2 grep过滤命令示例 二、正则表达式1、概念2、基本正则表达式2.1 常见元字符2.2 POSIX字符类2.3 示例 3、扩展正则表达式3.1 概念3.2 示例 三、作业1、作业一2、作业…...
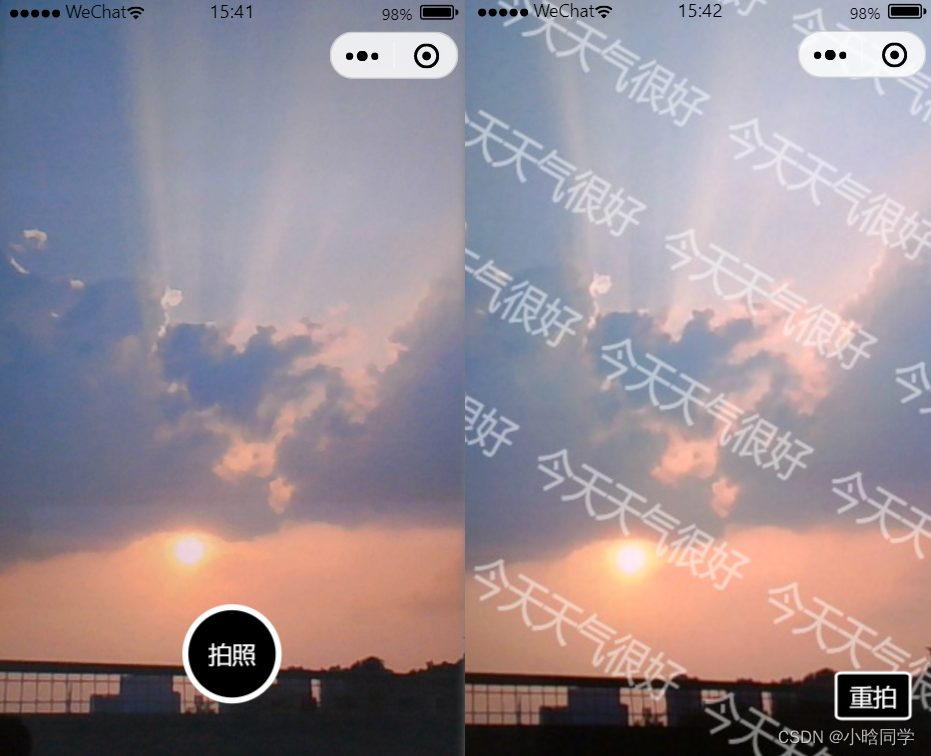
小程序实现摄像头拍照 + 水印绘制
文章标题 01 功能说明02 使用方式 & 效果图2.1 基础用法2.2 拍照 底部定点水印 预览2.3 拍照 整体背景水印 预览 03 全部代码3.1 页面布局 html3.2 业务核心 js3.3 基础样式 css 01 功能说明 需求:小程序端需要调用前置摄像头进行拍照,并且将拍…...
SpringMVC:从入门到精通,7篇系列篇带你全面掌握--三.使用SpringMVC完成增删改查
🥳🥳Welcome Huihuis Code World ! !🥳🥳 接下来看看由辉辉所写的关于SpringMVC的相关操作吧 目录 🥳🥳Welcome Huihuis Code World ! !🥳🥳 效果演示 一.导入项目的相关依赖 二.…...

ABAP GN_DELIVERY_CREATE 报错 VL 561
GN_DELIVERY_CREATE 去创建内向交货单的时候。 报错 VL 561 Essential transfer parameters are missing in record 表示一些必输字段没输入 诸如一些,物料号。单位。等一些字段 输入之后即可 DATA: ls_return TYPE bapireturn.DATA: lt_return TYPE STANDARD T…...
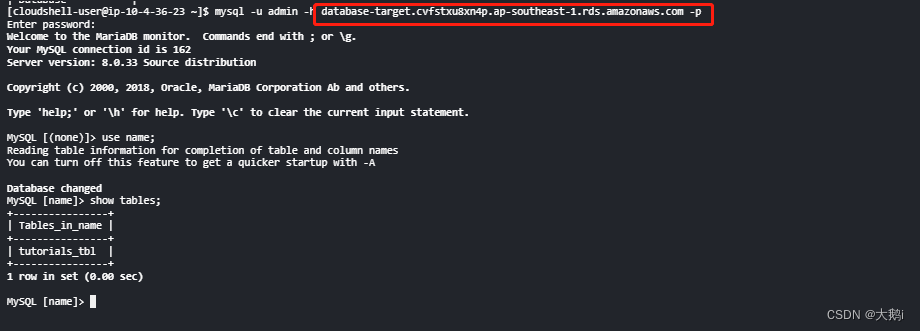
AWS-数据库迁移工具DMS-场景:单账号跨区域迁移RDS for Mysql
参考文档: 分为几个环节: 要使用 AWS DMS 迁移至 Amazon RDS 数据库实例: 1.创建复制实例 有坑内存必须8g或者以上,我测试空库 都提示内存不足 2.创建目标和源终端节点 目标空库也得自己创建哈 3.刷新源终端节点架构 4.创建迁…...

【漏洞复现】E-office文件包含漏洞
漏洞描述 Weaver E-Office是中国泛微科技(Weaver)公司的一个协同办公系统。泛微 E-Office 是一款标准化的协同 OA 办公软件,实行通用化产品设计,充分贴合企业管理需求,本着简洁易用、高效智能的原则,为企业快速打造移动化、无纸化、数字化的办公平台。 该漏洞是由于存在…...

Linux 系统常用命令总结
目录 提示一、文件和目录操作二、文件查看和编辑三、文件权限管理四、文件压缩和解压缩五、查找文件六、系统信息和状态七、用户和权限管理八、网络相关操作九、包管理十、进程管理十一、时间和日期十二、系统关机和重启十三、文件传输十四、其他常用命令 提示 [ ]:…...

【数据结构】树的基础入门
文章目录 什么是树树的常见术语树的表示树的应用 什么是树 相信大家刚学数据结构的时候最先接触的就是顺序表,栈,队列等线性结构. 而树则是一种非线性存储结构,存储的是具有“一对多”关系的数据元素的集合 非线性 体现在它是由n个有限结点(可以是零个结点)组成一个具有层次关…...

【多线程】Thread的常用方法
Thread的常用方法 1.构造器 Thread提供的常见构造器说明public Thread(String name)可以为当前线程指定名称public Thread(Runnable target)封装Runnable对象成为线程对象public Thread(Runnable target,String name)封装Runnable对象成为线程对象,并指定线程名称…...
windows 下docker安装宝塔镜像 宝塔docker获取镜像
1. docker 安装宝塔 打开链接:https://www.docker.com/get-started,找对应的版本下载docker,安装docker打开百度云盘:链接:https://pan.baidu.com/s/1DGIjpKkNDAmy4roaKGLA_w 提取码:u8bi 2. 设置镜像 点…...

华为云AI开发平台ModelArts
华为云ModelArts:重塑AI开发流程的“智能引擎”与“创新加速器”! 在人工智能浪潮席卷全球的2025年,企业拥抱AI的意愿空前高涨,但技术门槛高、流程复杂、资源投入巨大的现实,却让许多创新构想止步于实验室。数据科学家…...

第一篇:Agent2Agent (A2A) 协议——协作式人工智能的黎明
AI 领域的快速发展正在催生一个新时代,智能代理(agents)不再是孤立的个体,而是能够像一个数字团队一样协作。然而,当前 AI 生态系统的碎片化阻碍了这一愿景的实现,导致了“AI 巴别塔问题”——不同代理之间…...

Caliper 配置文件解析:config.yaml
Caliper 是一个区块链性能基准测试工具,用于评估不同区块链平台的性能。下面我将详细解释你提供的 fisco-bcos.json 文件结构,并说明它与 config.yaml 文件的关系。 fisco-bcos.json 文件解析 这个文件是针对 FISCO-BCOS 区块链网络的 Caliper 配置文件,主要包含以下几个部…...

如何理解 IP 数据报中的 TTL?
目录 前言理解 前言 面试灵魂一问:说说对 IP 数据报中 TTL 的理解?我们都知道,IP 数据报由首部和数据两部分组成,首部又分为两部分:固定部分和可变部分,共占 20 字节,而即将讨论的 TTL 就位于首…...

Spring Cloud Gateway 中自定义验证码接口返回 404 的排查与解决
Spring Cloud Gateway 中自定义验证码接口返回 404 的排查与解决 问题背景 在一个基于 Spring Cloud Gateway WebFlux 构建的微服务项目中,新增了一个本地验证码接口 /code,使用函数式路由(RouterFunction)和 Hutool 的 Circle…...

【Linux】自动化构建-Make/Makefile
前言 上文我们讲到了Linux中的编译器gcc/g 【Linux】编译器gcc/g及其库的详细介绍-CSDN博客 本来我们将一个对于编译来说很重要的工具:make/makfile 1.背景 在一个工程中源文件不计其数,其按类型、功能、模块分别放在若干个目录中,mak…...

离线语音识别方案分析
随着人工智能技术的不断发展,语音识别技术也得到了广泛的应用,从智能家居到车载系统,语音识别正在改变我们与设备的交互方式。尤其是离线语音识别,由于其在没有网络连接的情况下仍然能提供稳定、准确的语音处理能力,广…...
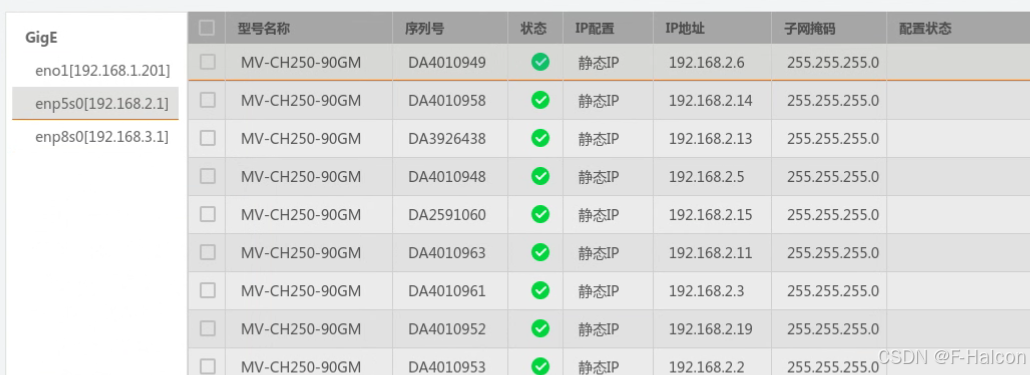
Ubuntu系统多网卡多相机IP设置方法
目录 1、硬件情况 2、如何设置网卡和相机IP 2.1 万兆网卡连接交换机,交换机再连相机 2.1.1 网卡设置 2.1.2 相机设置 2.3 万兆网卡直连相机 1、硬件情况 2个网卡n个相机 电脑系统信息,系统版本:Ubuntu22.04.5 LTS;内核版本…...

用递归算法解锁「子集」问题 —— LeetCode 78题解析
文章目录 一、题目介绍二、递归思路详解:从决策树开始理解三、解法一:二叉决策树 DFS四、解法二:组合式回溯写法(推荐)五、解法对比 递归算法是编程中一种非常强大且常见的思想,它能够优雅地解决很多复杂的…...

ArcGIS Pro+ArcGIS给你的地图加上北回归线!
今天来看ArcGIS Pro和ArcGIS中如何给制作的中国地图或者其他大范围地图加上北回归线。 我们将在ArcGIS Pro和ArcGIS中一同介绍。 1 ArcGIS Pro中设置北回归线 1、在ArcGIS Pro中初步设置好经纬格网等,设置经线、纬线都以10间隔显示。 2、需要插入背会归线…...