C++ STL库的介绍和使用
文章目录
- C++ STL库的介绍和使用
- STL六大组件
- 算法的分类
- 迭代器
- 一个简单的例子
- 容器和自定义类型
- 容器嵌套容器
- 常用容器
- string
- vector
- deque
- stack
- queue
- list
- set/multiset
- pair
- map/multimap
- 容器的使用时机
- 函数对象(仿函数)
- 谓词
- 内建函数对象
- 适配器
- bind2nd和bind1st
- not1 和 not2 mem_fun_ref和ptr_fun
- 算法
- 常用的遍历算法
- 常用的查找算法
- 其他
- 算数生成算法
- 集合算法
C++ STL库的介绍和使用
STL(标准模板库),是惠普实验室开发的一系列软件的统称。现在主要出现在C++中,但是在引入C++之前该技术已经存在了很长时间了。STL从广义上分为:容器(container) 算法(algorithm) 迭代器(iterator),容器和算法之间通过迭代器进行无缝衔接。STL几乎所有的代码都采用了模板类或者是模板函数,这相比于创痛的由函数和类组成的库来说提供了更好的代码重用机会。STL标准模板库,在我们C++标准程序库中隶属于STL的占到了80%以上。
STL六大组件
-
容器:各种数据结构 vector list deque set map等,存放数据
-
算法:如sort find copy for_each等,操作数据
-
迭代器:容器和算法的桥梁
-
仿函数:为算法提供更多的策略
-
适配器:为算法提供更多的参数接口
-
空间配置器:管容器和算法的空间
STL六大组件的交互关系:容器通过空间配置器获取数据存储空间,算法通过迭代器获取存储器的内容,仿函数可以协助算法完成不同的策略变化,适配器可以修饰仿函数。
算法的分类
质变算法:运算过程中会更好区间内的数据,如拷贝、替换、删除等
非质变算法:运算过程中不会更改区间内容,如查找、计数、遍历等
迭代器
迭代器是一种抽象的概念,提供一种方法,使之能够依顺序访问某个容器所含的各个元素,而无需暴露该容器的内部表示方式。
迭代器的设计思维是STL的关键所在,STL中心思想是把容器和算法分开,彼此设计独立。
一个简单的例子
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
void print(int it)
{cout << it << " ";
}
void test()
{vector<int> vv;vv.push_back(1);vv.push_back(2);vv.push_back(3);// 开始迭代器,指向开始位置vector<int>::iterator itBegin = vv.begin();// 结束迭代器,指向尾元素的下一个位置vector<int>::iterator itEnd = vv.end();for(auto it = itBegin; it!= itEnd; it++){cout << *it << " ";}cout << endl;// 需要了解,可用vs查看对应的实现源码,可以看到整体实现思路是上面的forfor_each(itBegin, itEnd, print);cout << endl;
}
int main(int argc, char* argv[])
{test();return 0;
}
容器和自定义类型
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
class Person
{
public:Person(int a, int n): age(a), num(n) {}int age;int num;
};
void print(const Person &it)
{cout << it.age << " " << it.num << endl;
}void test()
{vector<Person> vv;vv.push_back(Person(1,1));vv.push_back(Person(2,2));vv.push_back(Person(3,3));for_each(vv.begin(), vv.end(), print);
}
int main(int argc, char* argv[])
{test();return 0;
}
容器嵌套容器
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
void print2(int a)
{cout << a << " " ;
}
void print(const vector<int> &a)
{for_each(a.begin(), a.end(), print2);
}
void test()
{vector<int> a;a.push_back(1);a.push_back(2);a.push_back(3);vector<int> b;b.push_back(4);b.push_back(5);b.push_back(6);vector<int> c;c.push_back(7);c.push_back(8);c.push_back(9);vector<vector<int>> aa;aa.push_back(a);aa.push_back(b);aa.push_back(c);for_each(aa.begin(), aa.end(), print);
}
int main(int argc, char* argv[])
{test();return 0;
}
常用容器
string
C风格的字符串太过复杂,难以掌握,不太适合大程序的开发,所以C++标准库定义了一种string类,定义在头文件中。
string和C风格字符串对比:
-
char是一个指针,string是一个类,string封装了char,管理了这个字符串,是一个char类型的容器。
-
string封装了很多实用的成员方法,查找find、拷贝copy、删除delete、替换replace、插入insert
-
不用考虑内存的释放和越界,string管理了char*所分配的内存,每一次string的赋值,取值都由string类负责维护,不用担心复制越界和取值越界等算法
下面的例子列举了一些简单使用:
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
// 字符串赋值
void test()
{string str("5152");string str3;str3 = str;cout << str3 << endl;string str2;str2 = "hello world";cout << str2 << endl;string str1;str1 = 'H';cout << str1 << endl;string str4;str4.assign(str);cout << str4 << endl;
}
// 字符串存取
void test02()
{string str = "hello world";cout << str[1] << endl;cout << str.at(1) << endl;str[1] = 'E';str[7] = 'O';cout << str << endl;try{
// str[100] = 'H';str.at(100) = 'H';}catch (exception &e){cout << e.what() << endl;}
}
// 字符串拼接
void test03()
{string str1 = "hello ";string str2 = "world";str1+=str2;cout << str1 << endl;string str3 = "hello ";str3+="world";cout << str3 << endl;str3.append(" mmmm");cout << str3 << endl;str3.append(" mmmm", 3);cout << str3 << endl;str3.append(str2, 2, 3);cout << str3 << endl;
}
// 字符串查找和替换
void test04()
{string str1 = "hello world";int a = str1.find('e');cout << a << endl;a = str1.find('e', 3);cout << a << endl;a = str1.find("worl");cout << a << endl;// 表示从0开始替换5个字符,替换成后面的str1.replace(0, 5, "mmmmm");cout << str1 << endl;
}
// 字符串比较和子串的提取
void test05()
{string str1 = "hello world";string str2 = "hello";int a = str1.compare(str2);cout << a << endl;a = str1.compare("oooo");cout << a << endl;a = str1.compare("hello world");cout << a << endl;string str = str1.substr(0, 8);cout << str << endl;string str11 = "asd:asdas:asdasdasd:dadssad:dasdsa";int pos = 0;while(1){int ret = str11.find(":", pos);if(ret < 0){string tmp = str11.substr(pos, str11.size() - pos);cout << tmp << endl;break;}string tmp = str11.substr(pos, ret - pos);cout << tmp << endl;pos = ret + 1;}
}
// 字符串的插入和删除
void test06()
{string str = "hello world";str.insert(5, " hehe");cout << str << endl;str.erase(5, 5);cout << str << endl;str.clear();cout << str << endl;
}
// 字符串和C风格字符串转换
void test07()
{char *aa = "hello world";string str = aa;const char *cc = str.c_str();cout << str << endl;cout << cc << endl;
}
int main(int argc, char* argv[])
{test07();return 0;
}
vector
vector的数据安排以及操作方式与数组相似,两者的唯一差别在于运用的灵活性。数组是静态空间,一旦配置了就不能改变,要更换大一点或者小一点的空间,可以,但是需要自己去做空间分配和数据拷贝,然后释放原先的空间。vector是动态空间,随着元素的加入,它的内部机制会自动扩充空间以容纳新元素。因此vector的运用对于内存的合理利用与利用的灵活性有很大的帮助,我们不必担心空间不足而开辟一块很大的array。
vector的迭代器:随机访问迭代器
随机访问迭代器:迭代器+n可以通过编译器编译,就是随机访问迭代器。
vector的容量(capacity)和大小(size)是有区别的。
-
capacity:是空间能容纳元素的最大个数
-
size:是空间中实际存放的个数
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
void print(const vector<int> &aa)
{for(auto it = aa.begin(); it != aa.end(); it++){cout << *it << " ";}cout << endl;fflush(stdout);
}
void test()
{vector<int> v;for(int i = 0; i < 100; ++i){v.push_back(i);}cout << v.size() << endl;cout << v.capacity() << endl;
}
// 另寻空间的次数
void test02()
{int count = 0;vector<int> v;int *p = nullptr;for(int i = 0; i < 1000; ++i){v.push_back(i);if(p!= &v[0]){count++;p = &v[0];}}cout << count << endl;
}
// vector的构造、赋值和交换
void test03()
{vector<int> v(10, 5);print(v);vector<int> v1(v.begin() + 2, v.end() -2);print(v1);vector<int> v2(v);print(v2);vector<int> v3;v3.assign(v.begin() + 1, v.end() - 1);print(v3);vector<int> v4;v4 = v3;print(v4);vector<int> v5;v5.assign(5, 10);print(v5);vector<int> v6(6, 20);print(v6);v5.swap(v6);print(v5);print(v6);
}
// vector大小操作
void test04()
{vector<int> v(10, 5);if(v.empty()){cout << "v is empty" << endl;}else{cout << v.capacity() << endl;cout << v.size() << endl;}print(v);v.resize(16);print(v);v.resize(1024, 5);print(v);v.resize(2);print(v);cout << v.capacity() << endl;cout << v.size() << endl;// 使用swap收缩容量空间,通过交换函数重新申请大小vector<int>(v).swap(v);cout << v.capacity() << endl;cout << v.size() << endl;vector<int> vv(10, 5);cout << "vv:" << vv.capacity() << endl;cout << "vv:" << vv.size() << endl;// 空间预留vv.reserve(50);cout << "vv:" << vv.capacity() << endl;cout << "vv:" << vv.size() << endl;
}
// vector的数据操作
void test05()
{vector<int> v;for(int i = 0; i < 6; i++){v.push_back(i);}cout << v[5] << endl;cout << v.at(5) << endl;cout << v.front() << endl;cout << v.back() << endl;v.insert(v.begin() + 3, 2, 100);print(v);v.pop_back();print(v);v.erase(v.begin()+1,v.begin()+3);print(v);v.erase(v.begin());print(v);v.clear();print(v);
}
int main(int argc, char* argv[])
{test05();return 0;
}
注意: resize只能修改size,不能修改容量。
deque
vector容器时一段连续的内存空间,dequeue则是一种双向开口的联系线性空间。所谓的双向开口,意思是可以在头尾两端分别做元素的插入和删除操作。vector也可以在头尾进行插入操作 ,但是vector的头部插入操作效率奇差,不可以被接受。
deque容器是由一段一段的定量连续空间构成的,一旦有必要在deque前端或者是尾端增加新的空间,便配置一段连续定量的空间,串接在deque的头端或者是尾端。deque最大的工作就是维护这些分段连续的空间的整体性的假象,并提供随机访问接口,避免了重新配置空间,复制,释放的轮回,代价就是复杂的迭代器架构。
#include <iostream>
#include <algorithm>
#include <deque>
using namespace std;
void print(const deque<int> &aa)
{for(auto it = aa.begin(); it != aa.end(); it++){cout << *it << " ";}cout << endl;fflush(stdout);
}
// 初始化和赋值
void test()
{deque<int> v(5, 10);print(v);deque<int> v1;v1.assign(v.begin()+1, v.end()-1);print(v1);deque<int> v2 = v;print(v2);v2.swap(v1);print(v1);print(v2);
}
// 插入和存取
void test02()
{deque<int> v(5, 10);v.resize(10,3);print(v);v.resize(3);print(v);v.push_front(6);print(v);v.push_back(6);print(v);v.pop_front();print(v);v.pop_back();print(v);cout << v[1] << endl;cout << v.at(1) << endl;cout << v.size() << endl;cout << v.empty() << endl;v.clear();cout << v.empty() << endl;
}
int main(int argc, char* argv[])
{test02();return 0;
}
stack
stack是一种先进后出的数据结构,它只有一个出口。stack允许新增元素,移除元素,取得栈顶元素,但是除了顶端外,没有任何办法 存取stack元素。换言之,stack不允许有遍历行为。有元素推入栈的操作称为push, 将元素推出栈的操作称为pop。
stack没有迭代器。
#include <iostream>
#include <algorithm>
#include <stack>
using namespace std;
void test()
{stack<int> ss;ss.push(1);ss.push(2);ss.push(3);ss.push(4);ss.push(5);cout << ss.top() << endl;ss.pop();cout << ss.top() << endl;ss.pop();cout << ss.top() << endl;ss.pop();cout << ss.top() << endl;ss.pop();cout << ss.top() << endl;ss.pop();
}
int main(int argc, char* argv[])
{test();return 0;
}
queue
队列是一种先进先出的数据结构,他有一个出口一个入口,queue容器允许从一端新增元素,从另外一端移除元素。
队列没有迭代器。
#include <iostream>
#include <algorithm>
#include <queue>
using namespace std;
void test()
{queue<int> qq;qq.push(1);qq.push(2);qq.push(3);qq.push(4);qq.push(5);cout << qq.size() << endl;cout << qq.empty() << endl;cout << qq.front() << endl;qq.pop();cout << qq.front() << endl;qq.pop();cout << qq.front() << endl;qq.pop();cout << qq.front() << endl;qq.pop();cout << qq.front() << endl;qq.pop();cout << qq.empty() << endl;
}
int main(int argc, char* argv[])
{test();return 0;
}
list
链表是一种物理存储单元上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针连接次序实现的。链表由一系列节点组成,节点在运行时动态生成。每个节点包括两个部分:一个是存储数据元素的数据域,一个是存储下一个节点地址的指针域。相较于vector的连续线性空间,list就显得负责许多,它的每次插入或者是删除一个元素,就是配置或者释放一个元素的空间。因此,list对于空间的运用具有绝对的精准,一点也不浪费,而且,对于任何位置的元素插入或者是删除,list永远是常数时间。list和vector是两个最长被使用的容器。list是一个双向链表。
链表采用的是动态存储分配,不会造成内存浪费和溢出,链表执行插入和 删除操作十分方便,修改指针即可,不需要移动大量的元素。俩表灵活但是空间和时间额外耗费比较大。
list的迭代器是 双向访问迭代器
#include <iostream>
#include <algorithm>
#include <list>
#include <vector>
using namespace std;
void print(const list<int> &ll)
{for(auto & a : ll){cout << a << " ";}cout << endl;fflush(stdout);
}
class Person
{
public:Person(int a) : age(a){}bool operator<(const Person &right){return this->age < right.age;}int age;
};
class Compare
{
public:bool operator()(const Person &left, const Person &right){return left.age < right.age;}
};
bool operator==(const Person &left, const Person &right)
{return left.age == right.age;
}
bool compare(const Person &left, const Person &right)
{return left.age > right.age;
}
void print(const list<Person> &ll)
{for(auto & a : ll){cout << a.age << " ";}cout << endl;fflush(stdout);
}
void print(const vector<Person> &ll)
{for(auto & a : ll){cout << a.age << " ";}cout << endl;fflush(stdout);
}
void test()
{list<int> ll;ll.push_back(10);ll.push_back(20);ll.push_back(30);ll.push_back(40);print(ll);auto it = find(ll.begin(), ll.end(), 20);ll.insert(++it, 3 ,100);print(ll);ll.reverse();print(ll);ll.sort();print(ll);
}
void test01()
{list<Person> ll;ll.push_back(10);ll.push_back(20);ll.push_back(30);ll.push_back(40);print(ll);ll.remove(Person(20));print(ll);ll.sort();print(ll);ll.sort(compare);print(ll);
}
void test02()
{vector<Person> ll;ll.push_back(20);ll.push_back(10);ll.push_back(30);ll.push_back(40);sort(ll.begin(), ll.end(), compare);print(ll);sort(ll.begin(), ll.end(), Compare());print(ll);sort(ll.begin(), ll.end(), [&](const Person &left, const Person &right) -> bool {return left.age > right.age;});print(ll);
}
int main(int argc, char* argv[])
{test02();return 0;
}
注意: list删除自定义数据,必须重载==运算符,否则无法匹配是否相等。
set/multiset
set的特性是:所有元素都会根据元素的键值自动排序。set元素不像map那样可以同时拥有键和值,set元素既是键又是值。set不允许两个元素拥有同样的键值。
set不可以通过迭代器修改set的值,set的值也是键,关系到set元素的排序规则。
multiset的特性和用法和set完全相同,唯一不同的是multiset允许键值重复。set和multiset的底层实现是红黑树,红黑书是平衡二叉树的一种。
#include <iostream>
#include <algorithm>
#include <set>
using namespace std;
void print(const set<int> &ll)
{for(auto & a : ll){cout << a << " ";}cout << endl;fflush(stdout);
}
class Compare
{
public:bool operator()(const int& p1,const int& p2) const//一定要定义为常函数,且参数需要限定为const{return p1 > p2;}
};
void print(const set<int, Compare> &ll)
{for(auto & a : ll){cout << a << " ";}cout << endl;fflush(stdout);
}
void test()
{set<int> ss;ss.insert(2);ss.insert(3);ss.insert(45);ss.insert(10);ss.insert(2);print(ss);cout << ss.size() << endl;ss.erase(3);print(ss);cout << ss.count(2) << endl;multiset<int> ss2;ss2.insert(2);ss2.insert(3);ss2.insert(45);ss2.insert(10);ss2.insert(2);ss2.erase(3);cout << ss2.count(2) << endl;auto it = ss.find(5);it != ss.end()? cout << "找到了" << endl : cout << "没有找到" << endl;auto it1 = lower_bound(ss.begin(), ss.end(), 10);auto it2 = upper_bound(ss.begin(), ss.end(), 10);auto mm = ss.equal_range(30);
}
void test01()
{set<int, Compare> ss;ss.insert(2);ss.insert(6);ss.insert(8);print(ss);
}
int main(int argc, char* argv[])
{test01();return 0;
}
注意: set存放自定义数据类型的时候必须指定排序规则。
pair
对组是将一对值组合成一个值,这一对值可以具有不同的数据类型,两个值可以分别用pair的两个公有属性first和second进行访问。
#include <iostream>
#include <algorithm>
using namespace std;
void test()
{pair<int, int> pp(1, 2);cout << pp.first << " " << pp.second << endl;pair<int, int> pp1 = make_pair(1, 2);cout << pp1.first << " " << pp1.second << endl;
}
int main(int argc, char* argv[])
{test();return 0;
}
map/multimap
map的特性是所有元素会根据元素的键值自动排序。map所有的元素都是pair,同时拥有实值和键值,pair的第一个元素是键值,第二个元素被视为实值,map不允许两个元素有相同的键值。
map的键值不可变,实值是可变的。
multimap和map的操作类似,唯一的区别就是multimap键值可重复。map和multimap都是以红黑树为底层实现机制。
#include <iostream>
#include <algorithm>
#include <map>
using namespace std;
void print(const map<int, int> &ll)
{for(auto & a : ll){cout << a.first << " " << a.second << " " << endl;}fflush(stdout);
}
void test()
{int a = 10;int &b = a;a = 20;cout << a << endl;cout << b << endl;
}
int main(int argc, char* argv[])
{test();return 0;
}
容器的使用时机
| 典型的存储结构 | 可随机存取 | |
|---|---|---|
| vector | 单端数组 | 是 |
| deque | 双端数组 | 是 |
| list | 双向列表 | 否 |
| set/multiset | 红黑树 | 否 |
| map/multimap | 红黑树 | 否(针对于ke) |
| 元素查询 | 元素插入删除 | |
|---|---|---|
| vector | 慢 | 尾部 |
| deque | 慢 | 两端 |
| list | 非常慢 | 任何位置 |
| set/multiset | 快 | |
| map/multimap | 快 |
函数对象(仿函数)
重载函数调用操作符的对象,其对象常称为函数对象,即他们是行为类似于函数的对象,也叫仿函数,其实就是重载了"()"操作符,使得对象可以像函数那样调用。
注意:
- 函数对象是一个类,不是一个函数。
- 函数对象重载了"()"操作符,使他可以像函数一样调用。
分类:
-
如果一个函数重载了"()"且需要一个参数,则称为一元仿函数
-
如果一个函数重载了"()"且需要两个参数,则称为二元仿函数
总结:
- 函数对象通常不定义构造函数和析构函数,所以在构造和析构的时候不会发生任何问题,避免了函数调用的运行时问题。
- 函数对象超出了普通函数的概念,函数对象可以有自己的状态
- 函数对象可以内联编译,性能好。用函数指针几乎不可能
- 模板函数对象使得函数对象具有通用性,这就是他的优势之一
谓词
指的是普通函数或者是仿函数的返回值是bool类型的函数对象。
如果operator接受一个参数,则叫一元谓词,如果接受2个参数则称为二元谓词。
#include <iostream>
#include <algorithm>
#include <vector>
using namespace std;
bool findBigThan10(int a)
{return a > 10;
}
class Find20
{
public:bool operator()(int v){return v > 20;}
};
void test()
{vector<int> vv;vv.push_back(10);vv.push_back(20);vv.push_back(30);vv.push_back(40);vv.push_back(50);vv.push_back(60);auto ret = find_if(vv.begin(), vv.end(), findBigThan10);auto ret1 = find_if(vv.begin(), vv.end(), Find20());cout << *ret << endl;cout << *ret1 << endl;
}
bool compare(int left, int right)
{return left > right;
}
class Compare
{
public:bool operator()(int left, int right){return left < right;}
};
void test02()
{vector<int> vv;vv.push_back(10);vv.push_back(20);vv.push_back(30);vv.push_back(40);vv.push_back(50);vv.push_back(60);sort(vv.begin(), vv.end(), compare);for_each(vv.begin(), vv.end(), [](int val){cout << val << " ";});cout << endl;sort(vv.begin(), vv.end(), Compare());for_each(vv.begin(), vv.end(), [](int val){cout << val << " ";});cout << endl;
}
int main(int argc, char* argv[])
{test02();return 0;
}
内建函数对象
STL内建了一些函数对象,分为:算数类函数对象,关系运算类函数对象,逻辑运算类仿函数。这些仿函数所产生的对象,用法和一般函数完全相同,当然我们还可以产生无名的临时对象来履行函数功能。
下面列出一些简单的例子。如果想要查看内建的函数,可以到对应的文件内查看对应的函数原型。
#include <iostream>
#include <algorithm>
#include <vector>
using namespace std;
bool findBigThan10(int a)
{return a > 10;
}
class Find20
{
public:bool operator()(int v){return v > 20;}
};
void test()
{plus<int> p;cout << p(10, 20) << endl;cout << plus<int>()(50, 20) << endl;minus<int> p1;cout << p1(10, 20) << endl;
}
int main(int argc, char* argv[])
{test();return 0;
}
适配器
bind2nd和bind1st
#define _HAS_AUTO_PTR_ETC 1
#include <iostream>
#include <algorithm>
#include <functional>
#include <vector>
using namespace std;
void print(int a, int b)
{cout << a << " " << b << " " << endl;
}
class Print : public binary_function<int, int, void>
{
public:void operator()(int a, int b) const{cout << a << " " << b << " " << endl;}
};
void test()
{vector<int> vv;vv.push_back(10);vv.push_back(20);vv.push_back(30);vv.push_back(40);for_each(vv.begin(), vv.end(), bind1st(Print(), 5));for_each(vv.begin(), vv.end(), bind2nd(Print(), 5));
}
int main(int argc, char* argv[])
{test();return 0;
}
not1 和 not2 mem_fun_ref和ptr_fun
这里列出标题,不做代码展示
算法
算法主要是由头文件组成,是所有stl头文件中最大的一个,其中常用的功能涉及到比较,交换,查找,遍历,修改,翻转,排序,合并等。体积很小,只包括在几个序列容器上进行的简单运算的模板函数,定义了一些模板类,用以声明函数对象。
常用的遍历算法
- for_each
- transform
#define _HAS_AUTO_PTR_ETC 1
#include <iostream>
#include <algorithm>
#include <functional>
#include <vector>
using namespace std;
int mvTransform(int a)
{return a;
}
class Print : public binary_function<int, int, void>
{
public:void operator()(int a, int b) const{cout << a << " " << b << " " << endl;}
};
void test()
{vector<int> vv;vv.push_back(10);vv.push_back(20);vv.push_back(30);vv.push_back(40);vector<int> bb;bb.resize(vv.size());transform(vv.begin(), vv.end(), bb.begin(), mvTransform);for_each(bb.begin(), bb.end(), bind2nd(Print(), 5));
}
int main(int argc, char* argv[])
{test();return 0;
}
常用的查找算法
- find
- find_if
- adjacent_find 查找相邻的重复元素
- binary_find 二分查找,前提是容器必须有序
- count 统计元素出现次数
- count_if 按照条件统计次数
#define _HAS_AUTO_PTR_ETC 1
#include <iostream>
#include <algorithm>
#include <functional>
#include <vector>
using namespace std;
class Person
{
public:Person(int a) : age(a) {}int age;
};
bool operator==(const Person &left, const Person &right)
{return left.age == right.age;
}
void test()
{vector<int> vv;vv.push_back(10);vv.push_back(10);vv.push_back(20);vv.push_back(30);vv.push_back(30);auto it = adjacent_find(vv.begin(), vv.end());if(it != vv.end()){cout << *it << endl;}vector<Person> vp;vp.push_back(50);vp.push_back(50);auto itP = adjacent_find(vp.begin(), vp.end());if(itP != vp.end()){cout << itP->age << endl;}}
int main(int argc, char* argv[])
{test();return 0;
}
其他
- merge
- sort
- random_shuffle 打乱
- reverse 反转
- copy
- replace
- replace_if
- swap 交换函数
#define _HAS_AUTO_PTR_ETC 1
#include <iostream>
#include <algorithm>
#include <functional>
#include <vector>
using namespace std;
void test()
{vector<int> vv;vv.push_back(10);vv.push_back(10);vv.push_back(20);vv.push_back(20);vv.push_back(30);vv.push_back(30);vv.push_back(40);vv.push_back(40);vector<int> v2;v2.push_back(10);v2.push_back(30);vector<int> v3;v3.resize(vv.size() + v2.size());merge(vv.begin(), vv.end(), v2.begin(), v2.end(), v3.begin());for_each(v3.begin(), v3.end(), [](int a){cout << a << " ";});
}
int main(int argc, char* argv[])
{test();return 0;
}
算数生成算法
- accumulate 累加求和
- fill
#define _HAS_AUTO_PTR_ETC 1
#include <iostream>
#include <algorithm>
#include <functional>
#include <vector>
#include <numeric>
using namespace std;
void test()
{vector<int> vv;vv.push_back(10);vv.push_back(10);int sum = accumulate(vv.begin(), vv.end(), 0);cout << sum << endl;fill(vv.begin(), vv.end(), 20);for_each(vv.begin(), vv.end(), [](int a){ cout << a << endl; });
}
int main(int argc, char* argv[])
{test();return 0;
}
集合算法
- set_intersection 求交集
#define _HAS_AUTO_PTR_ETC 1
#include <iostream>
#include <algorithm>
#include <functional>
#include <vector>
#include <numeric>
using namespace std;
void test()
{vector<int> vv;vv.push_back(10);vv.push_back(20);vv.push_back(30);vv.push_back(40);vector<int> v2;v2.push_back(30);v2.push_back(40);v2.push_back(50);v2.push_back(60);vector<int> v3;v3.resize(4);auto it = set_intersection(vv.begin(), vv.end(), v2.begin(), v2.end(), v3.begin());int size = 4 - (v3.end() - it);v3.resize(size);for_each(v3.begin(), v3.end(), [](int a){ cout << a << endl;});
}
int main(int argc, char* argv[])
{test();return 0;
}
- set_union 求交集
#define _HAS_AUTO_PTR_ETC 1
#include <iostream>
#include <algorithm>
#include <functional>
#include <vector>
#include <numeric>
using namespace std;
void test()
{vector<int> vv;vv.push_back(10);vv.push_back(20);vv.push_back(30);vv.push_back(40);vector<int> v2;v2.push_back(30);v2.push_back(40);v2.push_back(50);v2.push_back(60);vector<int> v3;v3.resize(8);auto it = set_union(vv.begin(), vv.end(), v2.begin(), v2.end(), v3.begin());int size = 8 -(v3.end() - it);v3.resize(size);for_each(v3.begin(), v3.end(), [](int a){ cout << a << endl;});
}
int main(int argc, char* argv[])
{test();return 0;
}
- set_difference 求差集
#define _HAS_AUTO_PTR_ETC 1
#include <iostream>
#include <algorithm>
#include <functional>
#include <vector>
#include <numeric>
using namespace std;
void test()
{vector<int> vv;vv.push_back(10);vv.push_back(20);vv.push_back(30);vv.push_back(40);vector<int> v2;v2.push_back(30);v2.push_back(40);v2.push_back(50);v2.push_back(60);vector<int> v3;v3.resize(4);auto it = set_difference(vv.begin(), vv.end(), v2.begin(), v2.end(), v3.begin());int size = 4 -(v3.end() - it);v3.resize(size);for_each(v3.begin(), v3.end(), [](int a){ cout << a << endl;});
}
int main(int argc, char* argv[])
{test();return 0;
}
相关文章:

C++ STL库的介绍和使用
文章目录 C STL库的介绍和使用STL六大组件算法的分类迭代器 一个简单的例子容器和自定义类型容器嵌套容器常用容器stringvectordequestackqueuelistset/multisetpairmap/multimap 容器的使用时机函数对象(仿函数)谓词内建函数对象适配器bind2nd和bind1st…...
Excel数学、工程和科学计算插件:FORMULADESK Studio
如果 Excel 是您的武器 - 让我们磨砺您的剑!为整天使用 Excel 的人们提供创新的 Excel 加载项,你需要这个 FORMULADESK Studio。。。 Excel 插件为任何使用 Excel 执行数学、工程和科学计算的人提供了必备工具。 * 将公式视为真正的数学方程 * 为您的公…...

大规模 Spring Cloud 微服务无损上下线探索与实践
文章目录 什么是无损上下线?大规模 Spring Cloud 微服务架构实现无损上下线的挑战无损上下线的实践1. 使用负载均衡器2. 使用数据库迁移工具3. 动态配置管理4. 错误处理和回滚 未来的趋势1. 容器编排2. 服务网格3. 自动化测试和验证 结论 🎉欢迎来到云原…...

【LeetCode】剑指 Offer 54. 二叉搜索树的第k大节点
题目: 给定一棵二叉搜索树,请找出其中第 k 大的节点的值。 示例 1: 输入: root [3,1,4,null,2], k 13/ \1 4\2 输出: 4 示例 2: 输入: root [5,3,6,2,4,null,null,1], k 35/ \3 6/ \2 4/1 输出: 4 限制: 1 ≤ k ≤ 二叉搜索树…...
C++设计模式_03_模板方法Template Method
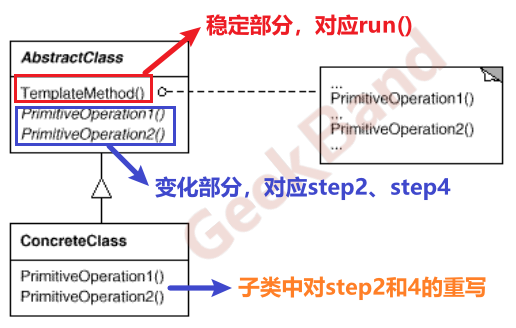
文章目录 1. 设计模式分类1.1 GOF-23 模式分类1.2 从封装变化角度对模式分类 2. 重构(使用模式的方法)2.1 重构获得模式 Refactoring to Patterns2.2 重构关键技法 3. “组件协作”模式4. Template Method 模式4.1 动机( Motivationÿ…...

【LeetCode-中等题】79. 单词搜索
文章目录 题目方法一:递归 回溯 题目 方法一:递归 回溯 需要一个标记数组 来标志格子字符是否被使用过了先找到word 的第一个字符在表格中的位置,再开始递归递归的结束条件是如果word递归到了最后一个字符了,说明能在矩阵中找到单…...

揭秘iPhone 15 Pro Max:苹果如何战胜三星
三星Galaxy S23 Ultra在我们的最佳拍照手机排行榜上名列前茅有几个原因,但iPhone 15 Pro Max正在努力夺回榜首——假设它有一个特定的功能。别误会我的意思,苹果一直在追赶三星,因为它的iPhone 14 Pro和14 Pro Max都表现强劲。尽管如此&#…...
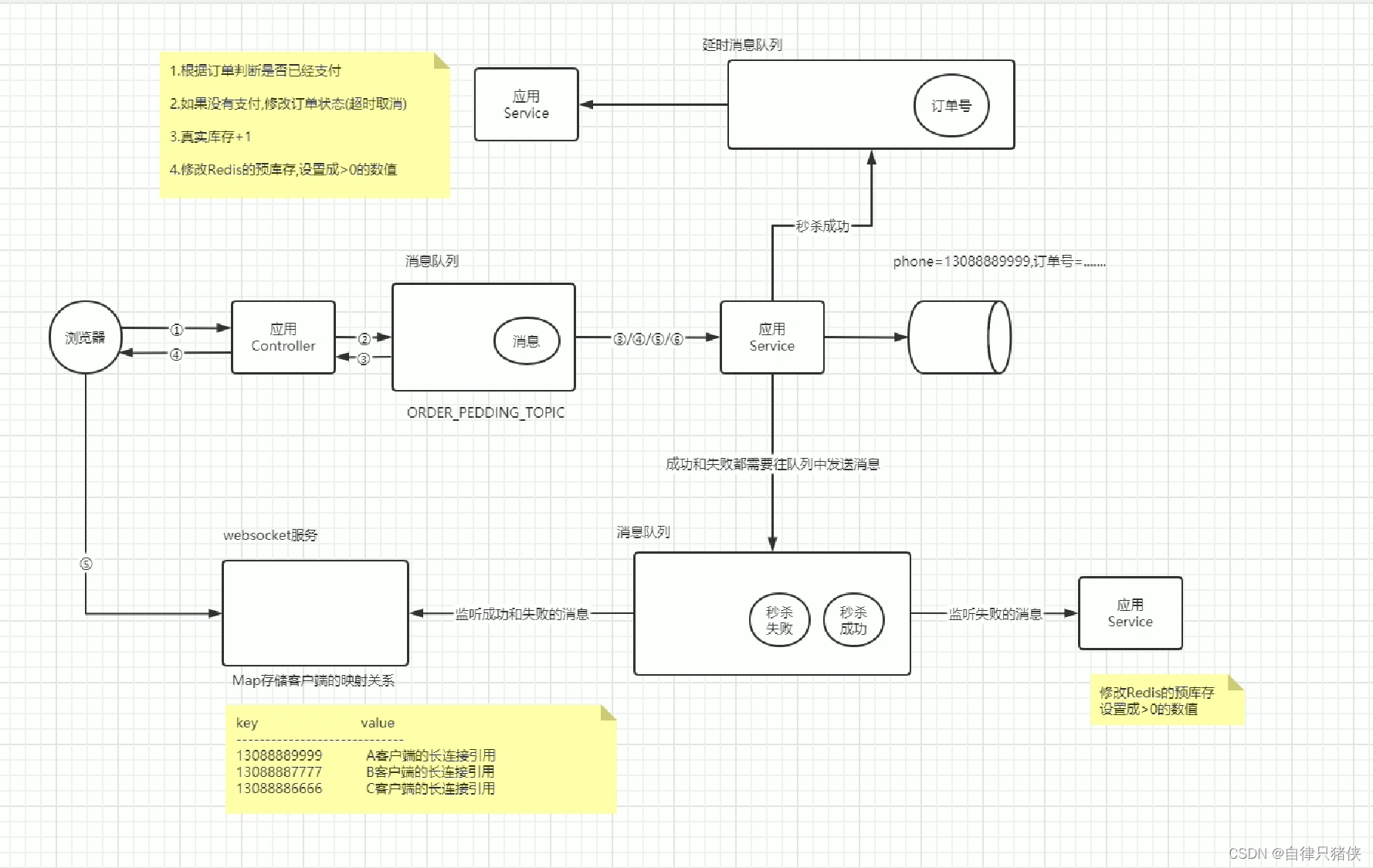
分布式秒杀方案--java
前提:先把商品详情和秒杀商品缓存redis中,减少对数据库的访问(可使用定时任务) 秒杀商品无非就是那几步(前面还可能会有一些判断,如用户是否登录,一人一单,秒杀时间验证等࿰…...

高频golang面试题:简单聊聊内存逃逸?
文章目录 问题怎么答举例 问题 知道golang的内存逃逸吗?什么情况下会发生内存逃逸? 怎么答 golang程序变量会携带有一组校验数据,用来证明它的整个生命周期是否在运行时完全可知。如果变量通过了这些校验,它就可以在栈上分配。…...

【2023年数学建模国赛C题解题思路】
第一问 要求分析分析蔬菜各品类及单品销售量的分布规律及相互关系。该问题可以拆分成三个角度进行剖析。 1)各种类蔬菜的销售量分布、蔬菜种类与销售量之间的关系;2)各种类蔬菜的销售量的月份分布、各种类蔬菜销售量与月份之间的相关关系&a…...

Jenkins+Allure+Pytest的持续集成
一、配置 allure 环境变量 1、下载 allure是一个命令行工具,可以去 github 下载最新版:https://github.com/allure-framework/allure2/releases 2、解压到本地 3、配置环境变量 复制路径如:F:\allure-2.13.7\bin 环境变量、Path、添加 F:\a…...
yo!这里是进程控制
目录 前言 进程创建 fork()函数 写时拷贝 进程终止 退出场景 退出方法 进程等待 等待原因 等待方法 1.wait函数 2.waitpid函数 等待结果(status介绍) 进程替换 替换原理 替换函数 进程替换例子 shell简易实现 后记 前言 学习完操作…...
多线程快速入门
线程与进程区别 每个正在系统上运行的程序都是一个进程。每个进程包含一到多个线程。线程是一组指令的集合,或者是程序的特殊段,它可以在程序里独立执行。也可以把它理解为代码运行的上下文。所以线程基本上是轻量级的进程,它负责在单个程序里…...
架构篇)
Redis 7 第七讲 哨兵模式(sentinal)架构篇
哨兵模式 哨兵巡查监控后台master主机是否故障,如果出现故障根据投票时自动将某一个从库转换成新的主库,继续对外服务。 作用 1. 监控redis运行状态,包括master和slave 2. 当master down机,能自动将salve切换成新的master 应用场景 主从监控监控主从redis库运行的状态…...

laravel框架系列(一),Dcat Admin 安装
介绍 Laravel 是一个流行的 PHP 开发框架,它提供了一套简洁、优雅的语法和丰富的功能,用于快速构建高质量的 Web 应用程序。 以下是 Laravel 的一些主要特点和功能: MVC 架构:Laravel 使用经典的模型-视图-控制器(MV…...

Linux:工具(vim,gcc/g++,make/Makefile,yum,git,gdb)
目录 ---工具功能 1. vim 1.1 vim的模式 1.2 vim常见指令 2. gcc/g 2.1 预备知识 2.2 gcc的使用 3.make,Makefile make.Makefile的使用 4.yum --yum三板斧 5.git --git三板斧 --Linux下提交代码到远程仓库 6.gdb 6.1 gdb的常用指令 学习目标: 1.知道…...
小节1:Python字符串打印
1、字符串拼接 用可以将两个字符串拼接成一个字符串 print("你好 " "这是一串代码") 输出: 2、单双引号转义 当打印的字符串中带有引号或双引号时,使用\或\"表示 print("He said \"Let\s go!\"") 输…...

2023国赛C题解题思路代码及图表:蔬菜类商品的自动定价与补货决策
2023国赛C题:蔬菜类商品的自动定价与补货决策 C题表面上看上去似乎很简单,实际上23题非常的难,编程难度非常的大,第二题它是一个典型的动态规划加仿真题目,我们首先要计算出销量与销售价格,批发价格之间的…...
数据可视化工具中的显眼包:奥威BI自带方案上阵
根据经验来看,BI数据可视化分析项目是由BI数据可视化工具和数据分析方案两大部分共同组成,且大多数时候方案都需从零开始,反复调整,会耗费大量时间精力成本。而奥威BI数据可视化工具别具匠心,将17年经验凝聚成标准化、…...

LeetCode算法心得——生成特殊数字的最少操作(贪心找规律)
大家好,我是晴天学长,这是一个简单贪心思维技巧题,主要考察的还是临场发挥的能力。需要的小伙伴可以关注支持一下哦!后续会继续更新的。 2) .算法思路 0 00 50 25 75 末尾是这两个的才能被45整除 思路:分别找&#x…...

使用docker在3台服务器上搭建基于redis 6.x的一主两从三台均是哨兵模式
一、环境及版本说明 如果服务器已经安装了docker,则忽略此步骤,如果没有安装,则可以按照一下方式安装: 1. 在线安装(有互联网环境): 请看我这篇文章 传送阵>> 点我查看 2. 离线安装(内网环境):请看我这篇文章 传送阵>> 点我查看 说明:假设每台服务器已…...

浅谈 React Hooks
React Hooks 是 React 16.8 引入的一组 API,用于在函数组件中使用 state 和其他 React 特性(例如生命周期方法、context 等)。Hooks 通过简洁的函数接口,解决了状态与 UI 的高度解耦,通过函数式编程范式实现更灵活 Rea…...

python打卡day49
知识点回顾: 通道注意力模块复习空间注意力模块CBAM的定义 作业:尝试对今天的模型检查参数数目,并用tensorboard查看训练过程 import torch import torch.nn as nn# 定义通道注意力 class ChannelAttention(nn.Module):def __init__(self,…...

React hook之useRef
React useRef 详解 useRef 是 React 提供的一个 Hook,用于在函数组件中创建可变的引用对象。它在 React 开发中有多种重要用途,下面我将全面详细地介绍它的特性和用法。 基本概念 1. 创建 ref const refContainer useRef(initialValue);initialValu…...

shell脚本--常见案例
1、自动备份文件或目录 2、批量重命名文件 3、查找并删除指定名称的文件: 4、批量删除文件 5、查找并替换文件内容 6、批量创建文件 7、创建文件夹并移动文件 8、在文件夹中查找文件...

LeetCode - 394. 字符串解码
题目 394. 字符串解码 - 力扣(LeetCode) 思路 使用两个栈:一个存储重复次数,一个存储字符串 遍历输入字符串: 数字处理:遇到数字时,累积计算重复次数左括号处理:保存当前状态&a…...

【CSS position 属性】static、relative、fixed、absolute 、sticky详细介绍,多层嵌套定位示例
文章目录 ★ position 的五种类型及基本用法 ★ 一、position 属性概述 二、position 的五种类型详解(初学者版) 1. static(默认值) 2. relative(相对定位) 3. absolute(绝对定位) 4. fixed(固定定位) 5. sticky(粘性定位) 三、定位元素的层级关系(z-i…...

2021-03-15 iview一些问题
1.iview 在使用tree组件时,发现没有set类的方法,只有get,那么要改变tree值,只能遍历treeData,递归修改treeData的checked,发现无法更改,原因在于check模式下,子元素的勾选状态跟父节…...

Module Federation 和 Native Federation 的比较
前言 Module Federation 是 Webpack 5 引入的微前端架构方案,允许不同独立构建的应用在运行时动态共享模块。 Native Federation 是 Angular 官方基于 Module Federation 理念实现的专为 Angular 优化的微前端方案。 概念解析 Module Federation (模块联邦) Modul…...
基础光照(Basic Lighting))
C++.OpenGL (10/64)基础光照(Basic Lighting)
基础光照(Basic Lighting) 冯氏光照模型(Phong Lighting Model) #mermaid-svg-GLdskXwWINxNGHso {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-GLdskXwWINxNGHso .error-icon{fill:#552222;}#mermaid-svg-GLd…...