PaddleOCR学习笔记1-初步尝试
尝试使用PaddleOCR方法,如何使用自定义的模型方法,参数怎么配置,图片识别尝试简单提高识别率方法。
目前仅仅只是初步学习下如何使用PaddleOCR的方法。
一,测试识别图片:
1.png :

正确文本内容为“哲学可以帮助辩别现代科技创新发展的方向”
二,测试代码:
paddleocr_test2.py : 结合使用了之前学习的PIL和NumPy库,自定义模型实际还是使用的官网提供的最新版本模型,我还没学习如何自己训练模型,只是为了学习如何使用参数变量。
from paddleocr import PaddleOCR
from PIL import Image,ImageDraw
import numpy as np'''
自定义模型测试ocr方法
'''
def test_model_ocr(img):# paddleocr 目前支持的多语言语种可以通过修改lang参数进行切换# 例如`ch`, `en`, `fr`, `german`, `korean`, `japan`# 使用CPU预加载,不用GPU# 模型路径下必须包含model和params文件,目前开源的v3版本模型 已经是识别率很高的了# 还要更好的就要自己训练模型了。ocr = PaddleOCR(det_model_dir='./inference/ch_PP-OCRv3_det_infer/',rec_model_dir='./inference/ch_PP-OCRv3_rec_infer/',cls_model_dir='./inference/ch_ppocr_mobile_v2.0_cls_infer/',use_angle_cls=True, lang="ch", use_gpu=False)# 识别图片文件result = ocr.ocr(img, cls=True)return result# 打印所有结果信息
def print_ocr_result(result):# print(result)for index in range(len(result)):rst = result[index]for line in rst:points = line[0]text = line[1][0]score = line[1][1]print('points : ', points)print('text : ', text)print('score : ', score)print('==========================================')# 转换图片
def convert_image(image, threshold=None):# 阈值 控制二值化程度,不能超过256,[200, 256]# 适当调大阈值,可以提高文本识别率,经过测试有效。if threshold is None:threshold = 200print('threshold : ', threshold)# 首先进行图片灰度处理image = image.convert("L")pixels = image.load()# 在进行二值化for x in range(image.width):for y in range(image.height):if pixels[x, y] > threshold:pixels[x, y] = 255else:pixels[x, y] = 0return imageif __name__ == "__main__":img_path = "1.png"# 1,直接识别图片文本print('1,直接识别图片文本')result1 = test_model_ocr(img_path)# 打印所有结果信息print_ocr_result(result1)# 2,转换为ndarray数组 识别图片文本print('2,转换为ndarray数组 识别图片文本')# 打开图片img1 = Image.open(img_path)# Image图像转换为ndarray数组img_1 = np.array(img1)# print(img_1)result2 = test_model_ocr(img_1)# 打印所有结果信息print_ocr_result(result2)# 3,转换图片, 识别图片文本print('3,转换图片,阈值=200时,再转换为ndarray数组, 识别图片文本')# 转换图片img2 = convert_image(img1, 200)# img2.show()# img2.save("11.png")# Image图像转换为ndarray数组img_2 = np.array(img2)# print(img_2)# 识别图片result3 = test_model_ocr(img_2)# 打印所有结果信息print_ocr_result(result3)# 4,转换图片, 识别图片文本print('4,转换图片,阈值=220时,再转换为ndarray数组, 识别图片文本')# 转换图片img3 = convert_image(img1, 220)# Image图像转换为ndarray数组img_3 = np.array(img3)# 识别图片result4 = test_model_ocr(img_3)# 打印所有结果信息print_ocr_result(result4)三,测试结果:
1,直接识别图片文本
[2023/06/25 10:38:41] ppocr DEBUG: Namespace(alpha=1.0, benchmark=False, beta=1.0, cls_batch_num=6, cls_image_shape='3, 48, 192', cls_model_dir='./inference/ch_ppocr_mobile_v2.0_cls_infer/', cls_thresh=0.9, cpu_threads=10, crop_res_save_dir='./output', det=True, det_algorithm='DB', det_box_type='quad', det_db_box_thresh=0.6, det_db_score_mode='fast', det_db_thresh=0.3, det_db_unclip_ratio=1.5, det_east_cover_thresh=0.1, det_east_nms_thresh=0.2, det_east_score_thresh=0.8, det_limit_side_len=960, det_limit_type='max', det_model_dir='./inference/ch_PP-OCRv3_det_infer/', det_pse_box_thresh=0.85, det_pse_min_area=16, det_pse_scale=1, det_pse_thresh=0, det_sast_nms_thresh=0.2, det_sast_score_thresh=0.5, draw_img_save_dir='./inference_results', drop_score=0.5, e2e_algorithm='PGNet', e2e_char_dict_path='./ppocr/utils/ic15_dict.txt', e2e_limit_side_len=768, e2e_limit_type='max', e2e_model_dir=None, e2e_pgnet_mode='fast', e2e_pgnet_score_thresh=0.5, e2e_pgnet_valid_set='totaltext', enable_mkldnn=False, fourier_degree=5, gpu_mem=500, help='==SUPPRESS==', image_dir=None, image_orientation=False, ir_optim=True, kie_algorithm='LayoutXLM', label_list=['0', '180'], lang='ch', layout=True, layout_dict_path=None, layout_model_dir=None, layout_nms_threshold=0.5, layout_score_threshold=0.5, max_batch_size=10, max_text_length=25, merge_no_span_structure=True, min_subgraph_size=15, mode='structure', ocr=True, ocr_order_method=None, ocr_version='PP-OCRv3', output='./output', page_num=0, precision='fp32', process_id=0, re_model_dir=None, rec=True, rec_algorithm='SVTR_LCNet', rec_batch_num=6, rec_char_dict_path='C:\\Users\\86159\\AppData\\Local\\Programs\\Python\\Python37\\lib\\site-packages\\paddleocr\\ppocr\\utils\\ppocr_keys_v1.txt', rec_image_inverse=True, rec_image_shape='3, 48, 320', rec_model_dir='./inference/ch_PP-OCRv3_rec_infer/', recovery=False, save_crop_res=False, save_log_path='./log_output/', scales=[8, 16, 32], ser_dict_path='../train_data/XFUND/class_list_xfun.txt', ser_model_dir=None, show_log=True, sr_batch_num=1, sr_image_shape='3, 32, 128', sr_model_dir=None, structure_version='PP-StructureV2', table=True, table_algorithm='TableAttn', table_char_dict_path=None, table_max_len=488, table_model_dir=None, total_process_num=1, type='ocr', use_angle_cls=True, use_dilation=False, use_gpu=False, use_mp=False, use_npu=False, use_onnx=False, use_pdf2docx_api=False, use_pdserving=False, use_space_char=True, use_tensorrt=False, use_visual_backbone=True, use_xpu=False, vis_font_path='./doc/fonts/simfang.ttf', warmup=False)
[2023/06/25 10:38:41] ppocr DEBUG: dt_boxes num : 1, elapse : 0.022063255310058594
[2023/06/25 10:38:41] ppocr DEBUG: cls num : 1, elapse : 0.007994413375854492
[2023/06/25 10:38:42] ppocr DEBUG: rec_res num : 1, elapse : 0.22030949592590332
points : [[17.0, 14.0], [514.0, 14.0], [514.0, 33.0], [17.0, 33.0]]
text : 哲学可以帮助辨别现代科技创新发展的方声
score : 0.8344171047210693
==========================================
2,转换为ndarray数组 识别图片文本
[2023/06/25 10:38:42] ppocr DEBUG: Namespace(alpha=1.0, benchmark=False, beta=1.0, cls_batch_num=6, cls_image_shape='3, 48, 192', cls_model_dir='./inference/ch_ppocr_mobile_v2.0_cls_infer/', cls_thresh=0.9, cpu_threads=10, crop_res_save_dir='./output', det=True, det_algorithm='DB', det_box_type='quad', det_db_box_thresh=0.6, det_db_score_mode='fast', det_db_thresh=0.3, det_db_unclip_ratio=1.5, det_east_cover_thresh=0.1, det_east_nms_thresh=0.2, det_east_score_thresh=0.8, det_limit_side_len=960, det_limit_type='max', det_model_dir='./inference/ch_PP-OCRv3_det_infer/', det_pse_box_thresh=0.85, det_pse_min_area=16, det_pse_scale=1, det_pse_thresh=0, det_sast_nms_thresh=0.2, det_sast_score_thresh=0.5, draw_img_save_dir='./inference_results', drop_score=0.5, e2e_algorithm='PGNet', e2e_char_dict_path='./ppocr/utils/ic15_dict.txt', e2e_limit_side_len=768, e2e_limit_type='max', e2e_model_dir=None, e2e_pgnet_mode='fast', e2e_pgnet_score_thresh=0.5, e2e_pgnet_valid_set='totaltext', enable_mkldnn=False, fourier_degree=5, gpu_mem=500, help='==SUPPRESS==', image_dir=None, image_orientation=False, ir_optim=True, kie_algorithm='LayoutXLM', label_list=['0', '180'], lang='ch', layout=True, layout_dict_path=None, layout_model_dir=None, layout_nms_threshold=0.5, layout_score_threshold=0.5, max_batch_size=10, max_text_length=25, merge_no_span_structure=True, min_subgraph_size=15, mode='structure', ocr=True, ocr_order_method=None, ocr_version='PP-OCRv3', output='./output', page_num=0, precision='fp32', process_id=0, re_model_dir=None, rec=True, rec_algorithm='SVTR_LCNet', rec_batch_num=6, rec_char_dict_path='C:\\Users\\86159\\AppData\\Local\\Programs\\Python\\Python37\\lib\\site-packages\\paddleocr\\ppocr\\utils\\ppocr_keys_v1.txt', rec_image_inverse=True, rec_image_shape='3, 48, 320', rec_model_dir='./inference/ch_PP-OCRv3_rec_infer/', recovery=False, save_crop_res=False, save_log_path='./log_output/', scales=[8, 16, 32], ser_dict_path='../train_data/XFUND/class_list_xfun.txt', ser_model_dir=None, show_log=True, sr_batch_num=1, sr_image_shape='3, 32, 128', sr_model_dir=None, structure_version='PP-StructureV2', table=True, table_algorithm='TableAttn', table_char_dict_path=None, table_max_len=488, table_model_dir=None, total_process_num=1, type='ocr', use_angle_cls=True, use_dilation=False, use_gpu=False, use_mp=False, use_npu=False, use_onnx=False, use_pdf2docx_api=False, use_pdserving=False, use_space_char=True, use_tensorrt=False, use_visual_backbone=True, use_xpu=False, vis_font_path='./doc/fonts/simfang.ttf', warmup=False)
[2023/06/25 10:38:42] ppocr DEBUG: dt_boxes num : 1, elapse : 0.018141746520996094
[2023/06/25 10:38:42] ppocr DEBUG: cls num : 1, elapse : 0.007776021957397461
[2023/06/25 10:38:43] ppocr DEBUG: rec_res num : 1, elapse : 0.23012638092041016
points : [[16.0, 14.0], [514.0, 14.0], [514.0, 33.0], [16.0, 33.0]]
text : 哲学可以帮助辨别现代科技创新发展的方户
score : 0.8683586120605469
==========================================
3,转换图片,阈值=200时,再转换为ndarray数组, 识别图片文本
threshold : 200
[2023/06/25 10:38:43] ppocr DEBUG: Namespace(alpha=1.0, benchmark=False, beta=1.0, cls_batch_num=6, cls_image_shape='3, 48, 192', cls_model_dir='./inference/ch_ppocr_mobile_v2.0_cls_infer/', cls_thresh=0.9, cpu_threads=10, crop_res_save_dir='./output', det=True, det_algorithm='DB', det_box_type='quad', det_db_box_thresh=0.6, det_db_score_mode='fast', det_db_thresh=0.3, det_db_unclip_ratio=1.5, det_east_cover_thresh=0.1, det_east_nms_thresh=0.2, det_east_score_thresh=0.8, det_limit_side_len=960, det_limit_type='max', det_model_dir='./inference/ch_PP-OCRv3_det_infer/', det_pse_box_thresh=0.85, det_pse_min_area=16, det_pse_scale=1, det_pse_thresh=0, det_sast_nms_thresh=0.2, det_sast_score_thresh=0.5, draw_img_save_dir='./inference_results', drop_score=0.5, e2e_algorithm='PGNet', e2e_char_dict_path='./ppocr/utils/ic15_dict.txt', e2e_limit_side_len=768, e2e_limit_type='max', e2e_model_dir=None, e2e_pgnet_mode='fast', e2e_pgnet_score_thresh=0.5, e2e_pgnet_valid_set='totaltext', enable_mkldnn=False, fourier_degree=5, gpu_mem=500, help='==SUPPRESS==', image_dir=None, image_orientation=False, ir_optim=True, kie_algorithm='LayoutXLM', label_list=['0', '180'], lang='ch', layout=True, layout_dict_path=None, layout_model_dir=None, layout_nms_threshold=0.5, layout_score_threshold=0.5, max_batch_size=10, max_text_length=25, merge_no_span_structure=True, min_subgraph_size=15, mode='structure', ocr=True, ocr_order_method=None, ocr_version='PP-OCRv3', output='./output', page_num=0, precision='fp32', process_id=0, re_model_dir=None, rec=True, rec_algorithm='SVTR_LCNet', rec_batch_num=6, rec_char_dict_path='C:\\Users\\86159\\AppData\\Local\\Programs\\Python\\Python37\\lib\\site-packages\\paddleocr\\ppocr\\utils\\ppocr_keys_v1.txt', rec_image_inverse=True, rec_image_shape='3, 48, 320', rec_model_dir='./inference/ch_PP-OCRv3_rec_infer/', recovery=False, save_crop_res=False, save_log_path='./log_output/', scales=[8, 16, 32], ser_dict_path='../train_data/XFUND/class_list_xfun.txt', ser_model_dir=None, show_log=True, sr_batch_num=1, sr_image_shape='3, 32, 128', sr_model_dir=None, structure_version='PP-StructureV2', table=True, table_algorithm='TableAttn', table_char_dict_path=None, table_max_len=488, table_model_dir=None, total_process_num=1, type='ocr', use_angle_cls=True, use_dilation=False, use_gpu=False, use_mp=False, use_npu=False, use_onnx=False, use_pdf2docx_api=False, use_pdserving=False, use_space_char=True, use_tensorrt=False, use_visual_backbone=True, use_xpu=False, vis_font_path='./doc/fonts/simfang.ttf', warmup=False)
[2023/06/25 10:38:43] ppocr DEBUG: dt_boxes num : 1, elapse : 0.017957448959350586
[2023/06/25 10:38:43] ppocr DEBUG: cls num : 1, elapse : 0.008005380630493164
[2023/06/25 10:38:43] ppocr DEBUG: rec_res num : 1, elapse : 0.21948766708374023
points : [[16.0, 14.0], [513.0, 14.0], [513.0, 33.0], [16.0, 33.0]]
text : 哲学可以帮助孵别现代科技创新发展的方向
score : 0.8875740170478821
==========================================
4,转换图片,阈值=220时,再转换为ndarray数组, 识别图片文本
threshold : 220
[2023/06/25 10:38:43] ppocr DEBUG: Namespace(alpha=1.0, benchmark=False, beta=1.0, cls_batch_num=6, cls_image_shape='3, 48, 192', cls_model_dir='./inference/ch_ppocr_mobile_v2.0_cls_infer/', cls_thresh=0.9, cpu_threads=10, crop_res_save_dir='./output', det=True, det_algorithm='DB', det_box_type='quad', det_db_box_thresh=0.6, det_db_score_mode='fast', det_db_thresh=0.3, det_db_unclip_ratio=1.5, det_east_cover_thresh=0.1, det_east_nms_thresh=0.2, det_east_score_thresh=0.8, det_limit_side_len=960, det_limit_type='max', det_model_dir='./inference/ch_PP-OCRv3_det_infer/', det_pse_box_thresh=0.85, det_pse_min_area=16, det_pse_scale=1, det_pse_thresh=0, det_sast_nms_thresh=0.2, det_sast_score_thresh=0.5, draw_img_save_dir='./inference_results', drop_score=0.5, e2e_algorithm='PGNet', e2e_char_dict_path='./ppocr/utils/ic15_dict.txt', e2e_limit_side_len=768, e2e_limit_type='max', e2e_model_dir=None, e2e_pgnet_mode='fast', e2e_pgnet_score_thresh=0.5, e2e_pgnet_valid_set='totaltext', enable_mkldnn=False, fourier_degree=5, gpu_mem=500, help='==SUPPRESS==', image_dir=None, image_orientation=False, ir_optim=True, kie_algorithm='LayoutXLM', label_list=['0', '180'], lang='ch', layout=True, layout_dict_path=None, layout_model_dir=None, layout_nms_threshold=0.5, layout_score_threshold=0.5, max_batch_size=10, max_text_length=25, merge_no_span_structure=True, min_subgraph_size=15, mode='structure', ocr=True, ocr_order_method=None, ocr_version='PP-OCRv3', output='./output', page_num=0, precision='fp32', process_id=0, re_model_dir=None, rec=True, rec_algorithm='SVTR_LCNet', rec_batch_num=6, rec_char_dict_path='C:\\Users\\86159\\AppData\\Local\\Programs\\Python\\Python37\\lib\\site-packages\\paddleocr\\ppocr\\utils\\ppocr_keys_v1.txt', rec_image_inverse=True, rec_image_shape='3, 48, 320', rec_model_dir='./inference/ch_PP-OCRv3_rec_infer/', recovery=False, save_crop_res=False, save_log_path='./log_output/', scales=[8, 16, 32], ser_dict_path='../train_data/XFUND/class_list_xfun.txt', ser_model_dir=None, show_log=True, sr_batch_num=1, sr_image_shape='3, 32, 128', sr_model_dir=None, structure_version='PP-StructureV2', table=True, table_algorithm='TableAttn', table_char_dict_path=None, table_max_len=488, table_model_dir=None, total_process_num=1, type='ocr', use_angle_cls=True, use_dilation=False, use_gpu=False, use_mp=False, use_npu=False, use_onnx=False, use_pdf2docx_api=False, use_pdserving=False, use_space_char=True, use_tensorrt=False, use_visual_backbone=True, use_xpu=False, vis_font_path='./doc/fonts/simfang.ttf', warmup=False)
[2023/06/25 10:38:44] ppocr DEBUG: dt_boxes num : 1, elapse : 0.019538402557373047
[2023/06/25 10:38:44] ppocr DEBUG: cls num : 1, elapse : 0.00800013542175293
[2023/06/25 10:38:44] ppocr DEBUG: rec_res num : 1, elapse : 0.22036981582641602
points : [[15.0, 14.0], [515.0, 14.0], [515.0, 33.0], [15.0, 33.0]]
text : 哲学可以帮助辩别现代科技创新发展的方向
score : 0.8834166526794434
==========================================通过测试结果可以看出,图片经过二值化转换后,再转换为ndarray数组,最后再调用PaddlerOCR识别方法,返回的识别文本最为准确。
之前也了解过OCR识别的步骤流程,后面还要继续深入学习下,从这几个方面提高图片识别率。
=====================================================================
步骤流程:
1. 图像输入、预处理:
不同的图像格式有不同的存储、压缩方式,目前有OpenCV、CxImage等。
2. 二值化:
如今数码摄像头拍摄的图片大多是彩色图像,彩色图像所含信息量巨大,不适用于OCR技术。为了让计算机更快的、更好地进行OCR相关计算,
我们需要先对彩色图进行处理,使图片只剩下前景信息与背景信息。二值化也可以简单地将其理解为“黑白化”。
3. 图像降噪:
对于不同的图像根据噪点的特征进行去噪的过程称为降噪。
4. 倾斜校正:
由于一般用户,在拍照文档时,难以拍摄得完全符合水平平齐与竖直平齐(我本人就经常拍的歪歪扭扭),
因此拍照出来的图片不可避免的产生倾斜,这就需要图像处理软件进行校正。
5. 版面分析:
将文档图片分段落,分行的过程称为版面分析。
6. 字符切割:
由于拍照、书写条件的限制,经常造成字符粘连、断笔,直接使用此类图像进行OCR分析将会极大限制OCR性能。
因此需要进行字符切割,即:将不同字符之间分割开。
7. 字符识别:
早期以模板匹配为主,后期以结合深度网络的特征提取为主。版面还原:将识别后的文字像原始文档图片那样排列,
段落、位置、顺序不变地输出到Word文档、PDF文档等,这一过程称为版面还原。
8. 后期处理:根据特定的语言上下文的关系,对识别结果进行校正。
9. 输出:将识别出的字符以某一格式的文本输出。
=====================================================================
相关文章:
PaddleOCR学习笔记1-初步尝试
尝试使用PaddleOCR方法,如何使用自定义的模型方法,参数怎么配置,图片识别尝试简单提高识别率方法。 目前仅仅只是初步学习下如何使用PaddleOCR的方法。 一,测试识别图片: 1.png : 正确文本内容为“哲学可以帮助辩别现…...
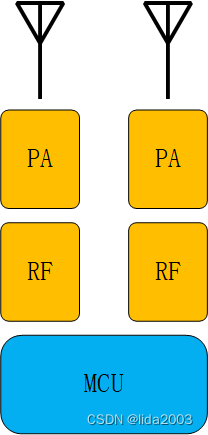
ExpressLRS开源代码之框架结构
ExpressLRS开源代码之框架结构 1. 源由2. Arduino应用框架3. ExpressLRS应用框架4. 硬件设计框架4.1 单天线4.2 双天线单PA4.3 双天线双PA 5. 应用软件设计6. 参考资料 1. 源由 最近为了理解《ExpressLRS开源之基本调试数据含义》,做了一些源代码的研读。 概念、文…...
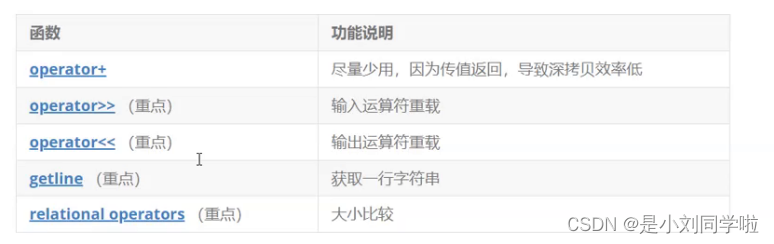
【C++ • STL】一文带你走进string
文章目录 一、STL简介二、标准库中的string类三、string类的常用接口说明2.1 string类对象的常见构造2.2 string类对象的访问及遍历操作2.2.1 元素访问2.2.2 迭代器 2.3 string类对象的容量操作2.4 string类对象的修改操作2.5 string类非成员函数 四、总结 ヾ(๑╹◡╹)&#x…...
GPT引领前沿热点、AI绘图
GPT对于每个科研人员已经成为不可或缺的辅助工具,不同的研究领域和项目具有不同的需求。如在科研编程、绘图领域: 1、编程建议和示例代码: 无论你使用的编程语言是Python、R、MATLAB还是其他语言,都可以为你提供相关的代码示例。 2、数据可…...
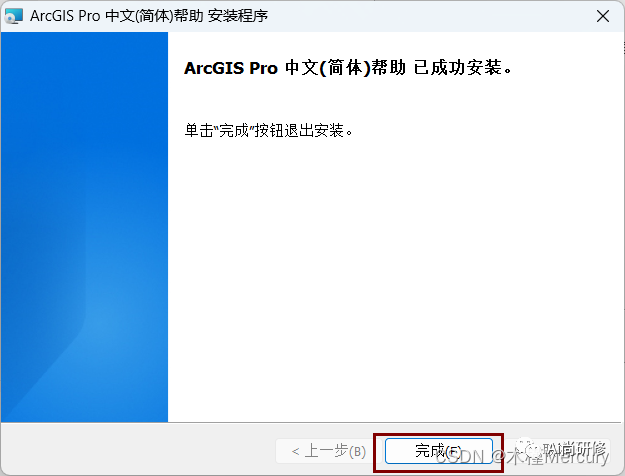
ArcGIS Pro3.0.2保姆级安装教程
软件简介: ArcGIS Pro是ERSI推出的新一代原生态64位ArcGIS桌面产品。具备强大的二维、三维一体化功能,继承了传统桌面产品ArcMap等产品几乎所有的功能,并在多个方面作了进一步的优化和改进,是云端一体化、数据科学与空间数据科学…...

如何才能搭建高质量的在线产品手册呢?
随着科技的发展,越来越多的企业将目光投向互联网,并将自己的产品推向了线上。而对于这些线上产品,拥有一份完备的、易用、高质量的在线产品手册显得尤为重要。 如何才能搭建高质量的在线产品手册呢? 一、确定手册的内容和格式 …...

从零开始学习软件测试-第38天笔记
接口测试 什么是接口 接口是两个独立部件共享信息的边界,测试中常说的接口大部分是web接口。web接口是遵循了http或者https协议的URL。 数据的流转过程 由客户端通过接口将数据发送给服务器。服务器收到数据之后,取出想要的数据,拼装成一…...

ASP.NET Core 8 的 Web App
Web App Web App 与 Web API 的不同之处在于包含 UI 部分,所谓的 UI 就是 HTML 页面。 Web App 支持几种渲染HTML 的方式: 服务端渲染客户端渲染混合渲染 服务端渲染 服务端渲染UI是在浏览器请求的时候,服务端生成 HTML,然后返…...
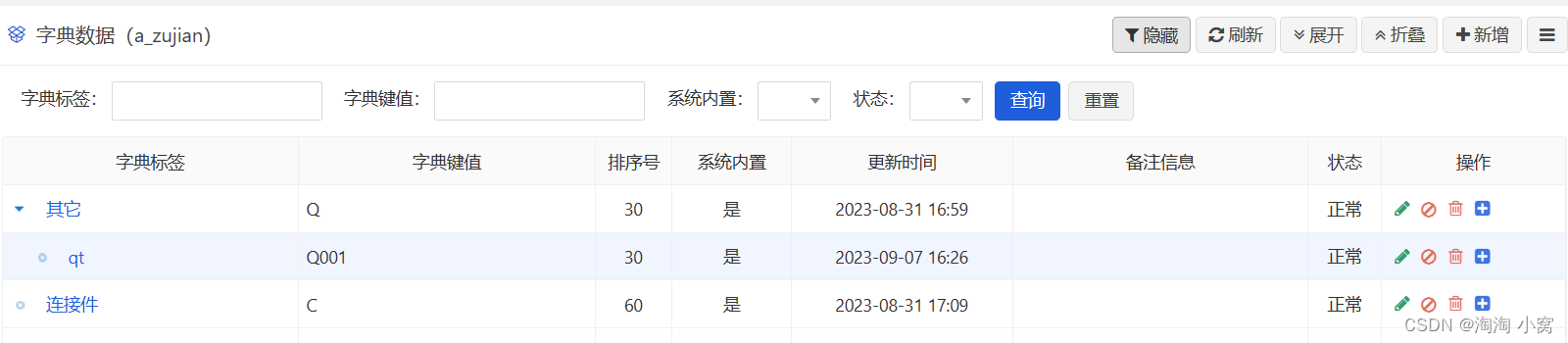
jeesite自定义数据字典,自定义字典表,自带树选择数据源(保姆级图文教程)
文章目录 前言一、框架自带树字典表如何使用二、自定义表作为字典表1. 下拉选项使用自建表作为字典表。实际效果框架示例实际开发代码2. 结构树选择使用自建表作为字典表。效果展示实际开发代码总结前言 项目开发中字典表如果不满足实际需求,比如使用自己的表作为字典,系统自…...

基于v-md-editor的在线文档编辑实现
概述 前面的文章讲到了基于语雀的在线文档编辑器的实现,在本文,将基于v-md-editor实现在线文档的编辑。 实现后效果 实现 说明:本文是基于Vue3实现的,实现了:1.Markdown的在线编辑和预览;2. 文件的上传和…...
)
C(结构体指针、利用结构体指针偏移获取数据)
记录问题,还没有研究明白 struct MY_STRUCT{int a;short b;char s[100];double d; }; int main(){ MY_STRUCT s{1,2,"he",999};MY_STRUCT* struct_ptr &s;char *char_p (char *) &s.s;int *int_ap &s.a;short * int_bp &s.b;double …...

数据结构和算法之插入排序
一、插入排序 插入排序是一种简单直观的排序算法。它的原理是通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入。 #mermaid-svg-v2YbPqchr8qWCPvn {font-family:"trebuchet ms",verdana,arial,san…...

感应电动机
引言 感应电动机,这个名字对于普通人来说可能有些陌生,但它在我们的日常生活和工作中占据着举足轻重的地位。从各类电器设备到工业生产设备,感应电动机的应用广泛而深入。了解感应电动机的种类和主要结构有助于我们更好地理解其工作原理,从而为我们的生活和工作带来更多便利…...

AjaxJavaScriptcss模仿百度一下模糊查询功能
1、效果 如下图所示,我们在输入大学时,程序会到后端查询名字中包含大学的数据,并展示到前端页面。 用户选择一个大学,该大学值会被赋值到input表单,同时关闭下拉表单; 当页面展示的数据都不符合条件时&…...
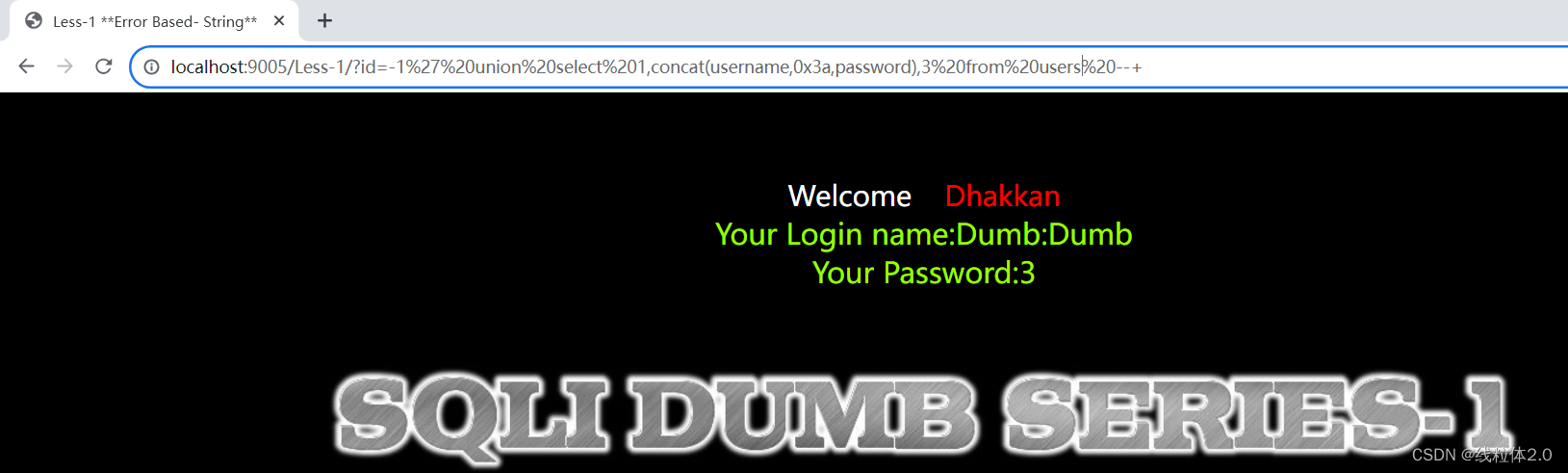
sqli-labs复现
sqli-labs第一关复现 环境搭建下载phpstudy下载sqli-labs浏览器加载 第一关复现 环境搭建 下载phpstudy phpstudy是一个可以快速帮助我们搭建web服务器环境的软件 官网:https://www.xp.cn/ 这里我选择的是windows 64bit 客户端版本,安装路径为C:\php…...

k8s入门到实战--跨服务调用
service.png 背景 在做传统业务开发的时候,当我们的服务提供方有多个实例时,往往我们需要将对方的服务列表保存在本地,然后采用一定的算法进行调用;当服务提供方的列表变化时还得及时通知调用方。 student: url: - 192.168.1…...
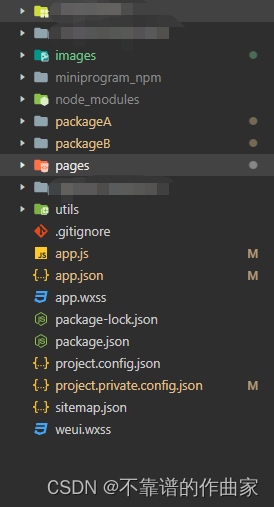
小程序中使用分包
前言 小程序在未使用的分包的情况下仅支持大小为2M,如果图片等资源过多的情况下可以使用分包功能,使用分包的情况下单个分包大小不能超过2M,总大小不能超过20M,分包有两种情况:普通分包和独立分包,下面介绍的是普通分包。官方文档…...

python官方标准库
文章目录 1. 标准库2. Python标准库介绍3. 示例 1. 标准库 https://docs.python.org/zh-cn/3/library/ https://pypi.org/ 2. Python标准库介绍 Python 语言参考手册 描述了 Python 语言的具体语法和语义,这份库参考则介绍了与 Python 一同发行的标准库。它还描…...
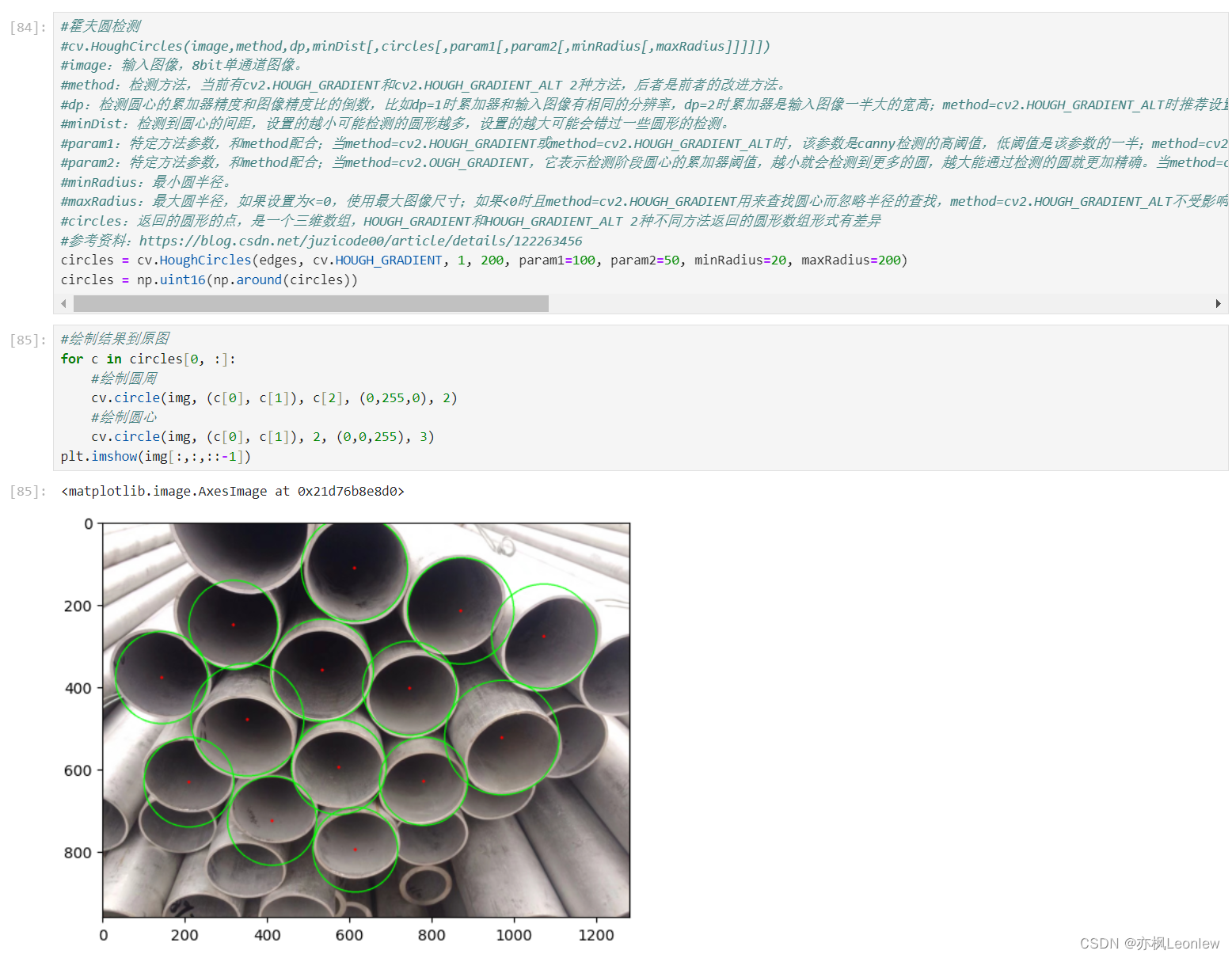
Python Opencv实践 - 霍夫圆检测(Hough Circles)
import cv2 as cv import numpy as np import matplotlib.pyplot as pltimg cv.imread("../SampleImages/steelpipes.jpg") print(img.shape) plt.imshow(img[:,:,::-1])#转为二值图 gray cv.cvtColor(img, cv.COLOR_BGR2GRAY) plt.imshow(gray, cmap plt.cm.gray…...

异步请求库的实际应用案例:爬取豆瓣经典电影
在日常爬虫过程中,你有没有遇到过需要爬取大量数据的情况,但是传统的同步请求方式让您等得焦头烂额? 这个问题的根源在于传统的同步请求方式。当我们使用同步请求时,程序会一直等待服务器的响应,直到数据返回后才能继续…...

day52 ResNet18 CBAM
在深度学习的旅程中,我们不断探索如何提升模型的性能。今天,我将分享我在 ResNet18 模型中插入 CBAM(Convolutional Block Attention Module)模块,并采用分阶段微调策略的实践过程。通过这个过程,我不仅提升…...

sqlserver 根据指定字符 解析拼接字符串
DECLARE LotNo NVARCHAR(50)A,B,C DECLARE xml XML ( SELECT <x> REPLACE(LotNo, ,, </x><x>) </x> ) DECLARE ErrorCode NVARCHAR(50) -- 提取 XML 中的值 SELECT value x.value(., VARCHAR(MAX))…...

短视频矩阵系统文案创作功能开发实践,定制化开发
在短视频行业迅猛发展的当下,企业和个人创作者为了扩大影响力、提升传播效果,纷纷采用短视频矩阵运营策略,同时管理多个平台、多个账号的内容发布。然而,频繁的文案创作需求让运营者疲于应对,如何高效产出高质量文案成…...

基于PHP的连锁酒店管理系统
有需要请加文章底部Q哦 可远程调试 基于PHP的连锁酒店管理系统 一 介绍 连锁酒店管理系统基于原生PHP开发,数据库mysql,前端bootstrap。系统角色分为用户和管理员。 技术栈 phpmysqlbootstrapphpstudyvscode 二 功能 用户 1 注册/登录/注销 2 个人中…...

Xela矩阵三轴触觉传感器的工作原理解析与应用场景
Xela矩阵三轴触觉传感器通过先进技术模拟人类触觉感知,帮助设备实现精确的力测量与位移监测。其核心功能基于磁性三维力测量与空间位移测量,能够捕捉多维触觉信息。该传感器的设计不仅提升了触觉感知的精度,还为机器人、医疗设备和制造业的智…...

Qt的学习(二)
1. 创建Hello Word 两种方式,实现helloworld: 1.通过图形化的方式,在界面上创建出一个控件,显示helloworld 2.通过纯代码的方式,通过编写代码,在界面上创建控件, 显示hello world; …...
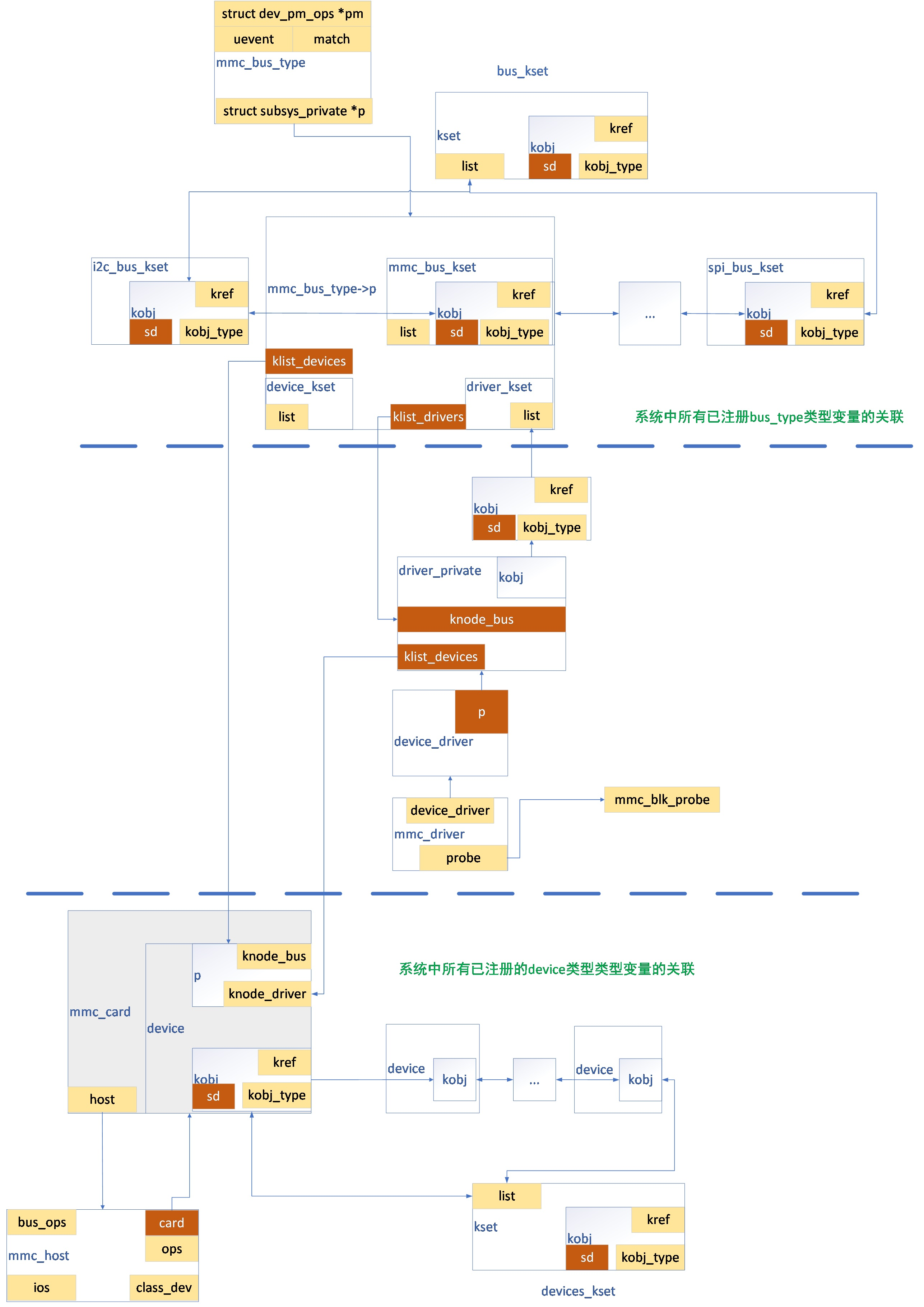
Linux 内存管理调试分析:ftrace、perf、crash 的系统化使用
Linux 内存管理调试分析:ftrace、perf、crash 的系统化使用 Linux 内核内存管理是构成整个内核性能和系统稳定性的基础,但这一子系统结构复杂,常常有设置失败、性能展示不良、OOM 杀进程等问题。要分析这些问题,需要一套工具化、…...
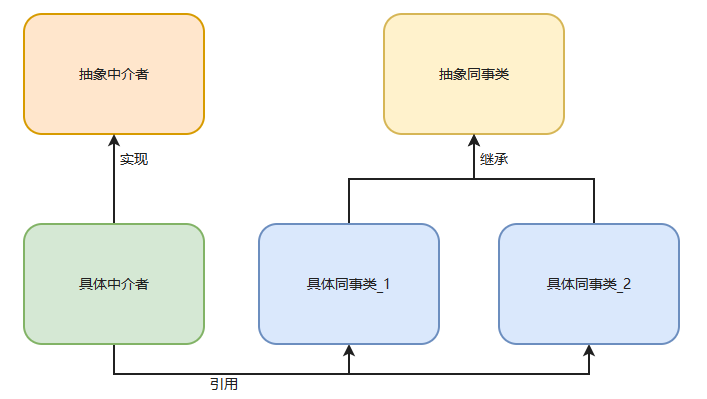
设计模式-3 行为型模式
一、观察者模式 1、定义 定义对象之间的一对多的依赖关系,这样当一个对象改变状态时,它的所有依赖项都会自动得到通知和更新。 描述复杂的流程控制 描述多个类或者对象之间怎样互相协作共同完成单个对象都无法单独度完成的任务 它涉及算法与对象间职责…...

React 样式方案与状态方案初探
React 本身只提供了基础 UI 层开发范式,其他特性的支持需要借助相关社区方案实现。本文将介绍 React 应用体系中样式方案与状态方案的主流选择,帮助开发者根据项目需求做出合适的选择。 1. React 样式方案 1.1. 内联样式 (Inline Styles) 通过 style …...

【设计模式】1.简单工厂、工厂、抽象工厂模式
every blog every motto: You can do more than you think. https://blog.csdn.net/weixin_39190382?typeblog 0. 前言 以下是 简单工厂模式、工厂方法模式 和 抽象工厂模式 的 Python 实现与对比,结合代码示例和实际应用场景说明: 1. 简单工厂模式&a…...