手写Spring:第2章-创建简单的Bean容器
文章目录
- 一、目标:创建简单的Bean容器
- 二、设计:创建简单的Bean容器
- 三、实现:创建简单的Bean容器
- 3.0 引入依赖
- 3.1 工程结构
- 3.2 创建简单Bean容器类图
- 3.3 Bean定义
- 3.4 Bean工厂
- 四、测试:创建简单的Bean容器
- 4.1 用户Bean对象
- 4.2 单元测试
- 五、总结:创建简单的Bean容器
一、目标:创建简单的Bean容器
💡 Spring Bean 容器是什么?
- Spring 包含并管理应用对象的配置和生命周期,在这个意义上它是一种用于承载对象的容器。
- 你可以配置你的每个 Bean 对象是如何被创建的。
- 这些 Bean 可以创建一个单独的实例或者每次需要时都生成一个新的实例,以及它们是如何相互关联构建和使用的。
- 如果一个 Bean 对象交给 Spring 容器管理,那么这个 Bean 对象就应该以类似零件的方式被拆解后存放到 Bean 的定义中。
- 这样相当于一种把对象解耦的操作,可以由 Spring 更加容易的管理,就像处理循环依赖等操作。
- 当一个 Bean 对象被定义存放以后,再由 Spring 统一进行装配,这个过程包括:Bean 的初始化、属性填充等。
- 最终我们就可以完整的使用一个 Bean 实例化后的对象了。
- 目标:定义一个简单的 Spring 容器,用于定义、存放和获取 Bean 对象。
二、设计:创建简单的Bean容器
💡 简单的 Spring Bean 容器如何实现?
- 凡是可以存放数据的具体数据结构实现,都可以称之为容器。
- 例如:
ArrayList、LinkedList、HashSet等。 - 但在 Spring Bean 容器的场景下,我们需要一种可以用于存放和名称索引式的数据结构,
HashMap是最合适的。
- 例如:
HashMap:是一种基于扰动函数、负载因子、红黑树转换等技术内容,形成的拉链寻址的数据结构。- 它能让数据更加散列的分布在哈希桶以及碰撞时形成的链表和红黑树上。
- 它的数据结构会尽可能最大限度的让整个数据读取的复杂度在
O(1)~O(Logn)~O(n)之间。 - 当日在极端情况下也会有
O(n)链表查找数据较多的情况,不过我们经过10万数据的扰动函数再寻址验证测试,数据会均匀的散列在各个哈希桶索引上。 - 所以
HashMap非常适合用在 Spring Bean 的容器实现上。
- 一个简单的 Spring Bean 容器实现,还需 Bean 的定义、注册、获取三个基本步骤。

- 定义:
BeanDefinition,它会包括singleton、prototype、BeanClassName等。目前初步实现一个 Object 类型用于存放对象。 - 注册:这个过程就相当于我们把数据存放到
HashMap中,只不过现在HashMap存放的是定义了的 Bean 对象信息。 - 获取:最后就是获取对象,Bean 的名字就是
key,Spring 容器初始化好 Bean 以后,就可以直接获取了。
三、实现:创建简单的Bean容器
3.0 引入依赖
pom.xml
<dependencies><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>4.11</version><scope>test</scope></dependency>
</dependencies>
3.1 工程结构
spring-step-01
|-src|-main| |-java| |-com.lino.springframework| |-BeanDefinition.java| |-BeanFactory.java|-test|-java|-com.lino.springframework.test|-bean| |-UserService.java|-ApiTest.java
3.2 创建简单Bean容器类图

- Spring Bean 容器的整个实现内容非常简单,也仅仅是包括了一个简单的 BeanFactory 和 BeanDefinition。
- 这里的类名称是与 Spring 源码中一致,只不过现在的类实现会相对来说更简化一些,在后续的实现再继续添加内容。
- BeanFactory:用于定义 Bean 实例化信息,现在的实现是一个 Object 存放对象。
- BeanDefinition:代表了 Bean 对象的工厂,可以存放 Bean 定义到 Map 中以及获取。
3.3 Bean定义
BeanDefinition.java
package com.lino.springframework;/*** @description: Bean 对象信息定义*/
public class BeanDefinition {/*** bean对象*/private Object bean;public BeanDefinition(Object bean) {this.bean = bean;}public Object getBean() {return bean;}
}
- 目前的 Bean 定义中,只有一个 Object 用于存放 Bean 对象。
- 在后续的实现中会逐步完善 BeanDefinition 相关属性的填充。
- 例如:
SCOPE_SINGLETON、SCOPE_PROTOTYPE、ROLE_APPLICATION、ROLE_SUPPORT、ROLE_INFRASTRUCTURE以及 Bean Class 信息。
- 例如:
3.4 Bean工厂
BeanFactory.java
package com.lino.springframework;import java.util.Map;
import java.util.concurrent.ConcurrentHashMap;/*** @description: 简单的 Bean 工厂*/
public class BeanFactory {/*** bean对象Map*/private Map<String, BeanDefinition> beanDefinitionMap = new ConcurrentHashMap<>();public Object getBean(String name) {return beanDefinitionMap.get(name).getBean();}public void registerBeanDefinition(String name, BeanDefinition beanDefinition) {beanDefinitionMap.put(name, beanDefinition);}
}
- 在 Bean 工厂的实现中,包括了 Bean 的注册,这里注册的是 Bean 的定义信息。同时在这个类中还包括了获取 Bean 的操作。
- 目前的 BeanFactory 仍然是简化的实现,但这种简化的实现内容也是整个 Spring 容器中关于 Bean 使用的最终体现结果。
- 只不过实现过程只展示出基本的核心原理。
四、测试:创建简单的Bean容器
4.1 用户Bean对象
UserService.java
package com.lino.springframework.test.bean;/*** @description: 模拟用户 Bean 对象*/
public class UserService {/*** 查询用户信息*/public void queryUserInfo() {System.out.println("查询用户信息");}
}
- 定义一个 UserService 对象。
4.2 单元测试
ApiTest.java
package com.lino.springframework.test;import com.lino.springframework.BeanDefinition;
import com.lino.springframework.BeanFactory;
import com.lino.springframework.test.bean.UserService;
import org.junit.Test;/*** @description: 测试类*/
public class ApiTest {@Testpublic void test_BeanFactory() {// 1.初始化 BeanFactoryBeanFactory beanFactory = new BeanFactory();// 2.注入beanBeanDefinition beanDefinition = new BeanDefinition(new UserService());beanFactory.registerBeanDefinition("userService", beanDefinition);// 3.获取beanUserService userService = (UserService) beanFactory.getBean("userService");userService.queryUserInfo();}
}
- 在单元测试中主要包括 初始化 Bean 工厂、注册 Bean、获取 Bean 三个步骤。
- 在 Bean 的注册中,这里是直接把 UserService 实例化后作为入参传递给 BeanDefinition 的,在后续的陆续实现中,这部分会放入 Bean 工厂中实现。
测试结果
查询用户信息
- 通过测试结果看是正常通过的。
五、总结:创建简单的Bean容器
- 整篇关于 Spring Bean 容器的一个雏形就已经实现完成了。
- 相对于一个知识的学习来说,写代码只是最后的步骤,往往整个思路、设计、方案,才更重要,只要你知道了因为什么,所以什么,才能让你有一个真正的理解。
相关文章:
手写Spring:第2章-创建简单的Bean容器
文章目录 一、目标:创建简单的Bean容器二、设计:创建简单的Bean容器三、实现:创建简单的Bean容器3.0 引入依赖3.1 工程结构3.2 创建简单Bean容器类图3.3 Bean定义3.4 Bean工厂 四、测试:创建简单的Bean容器4.1 用户Bean对象4.2 单…...

在Windows上通过SSH公私钥实现无密码登录Linux
在Windows上通过SSH公私钥实现无密码登录Linux 在Windows上生成SSH密钥对: 打开命令提示符或PowerShell窗口。 输入以下命令生成SSH密钥对: ssh-keygen -t rsa -b 4096按照提示输入密钥的保存路径和密码(可选)。 在指定的路径下…...
使用ppt和texlive生成eps图片(高清、可插入latex论文)
一、说明 写论文经常需要生成高清的图片插入到论文中,本文以ppt画图生成高质量的eps图片的实现来介绍具体操作方法。关于为什么要生成eps图片,一个是期刊要求(也有不要求的),另一个是显示图像的质量高。 转化获得eps…...
)
html5学习笔记19-SSE服务器发送事件(Server-Sent Events)
https://www.runoob.com/html/html5-serversentevents.html 允许网页获得来自服务器的更新。类似设置回调函数。 if(typeof(EventSource)!"undefined"){var sourcenew EventSource("demo_sse.php");source.onmessagefunction(event){document.getElement…...
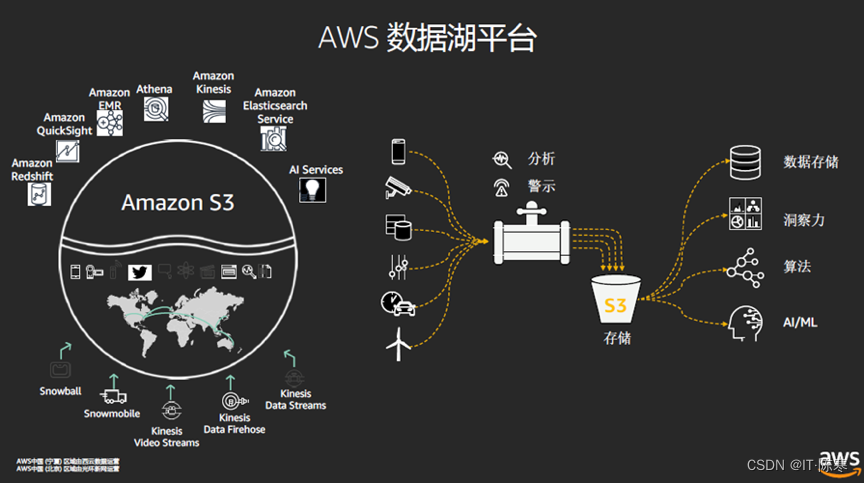
高效数据湖构建与数据仓库融合:大规模数据架构最佳实践
文章目录 数据湖和数据仓库:两大不同理念数据湖数据仓库 数据湖与数据仓库的融合统一数据目录数据清洗和转换数据安全和权限控制数据分析和可视化 数据湖与数据仓库融合的优势未来趋势云原生数据湖自动化数据处理边缘计算与数据湖融合 结论 🎉欢迎来到云…...

Java学习笔记——35多线程02
线程同步 线程同步卖票案例同步代码块同步方法块 线程安全的类StringBufferVectorHashtable Lock锁 线程同步 卖票案例 public class SellTicket implements Runnable{private int tickets10;Overridepublic void run(){while (true){if(tickets>0){System.out.println(Th…...

每日刷题-3
目录 一、选择题 二、编程题 1、计算糖果 2、进制转换 一、选择题 1、 解析:在C语言中,以0开头的整数常量是八进制的,而不是十进制的。所以,0123的八进制表示相当于83的十进制表示,而123的十进制表示不变。printf函数…...
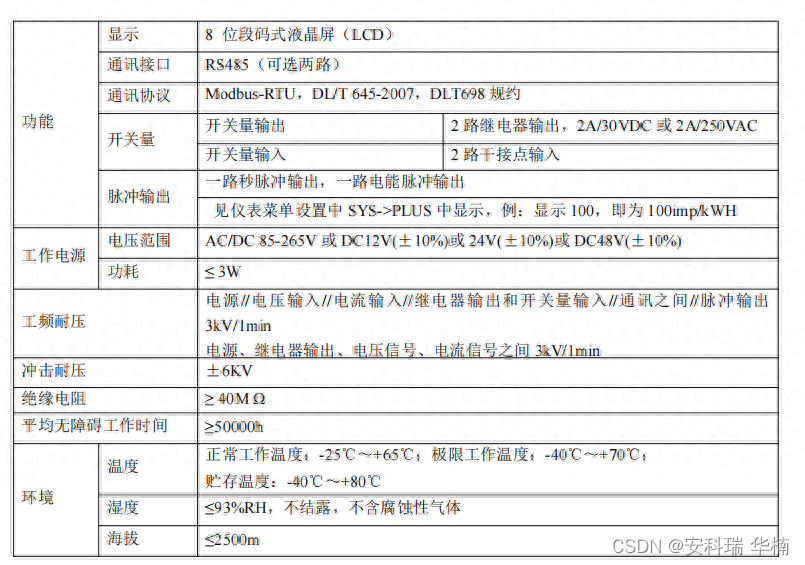
储能直流侧计量表DJSF1352
安科瑞 华楠 具有CE/UL/CPA/TUV认证 DJSF1352-RN导轨式直流电能表带有双路直流输入,主要针对电信基站、直流充电桩、太阳能光伏等应用场合而设计,该系列仪表可测量直流系统中的电压、电流、功率以及正反向电能等。在实际使用现场,即可计量总…...
)
机器学习报错合集(持续更新)
文章目录 1 列表转numpy,尺寸不均匀问题 1 列表转numpy,尺寸不均匀问题 ValueError: setting an array element with a sequence. The requested array has an inhomogeneous shape after 1 dimensions. The detected shape was (4,) inhomogeneous pa…...

【android12-linux-5.1】【ST芯片】【RK3588】【LSM6DSR】驱动移植
一、环境介绍 RK3588主板搭载Android12操作系统,内核是Linux5.10,使用ST的六轴传感器LSM6DSR芯片。 二、芯片介绍 LSM6DSR是一款加速度和角速度(陀螺仪)六轴传感器,还内置了一个温度传感器。该芯片可以选择I2C,SPI通讯,还有可编程终端,可以后置摄像头等设备,功能是很…...
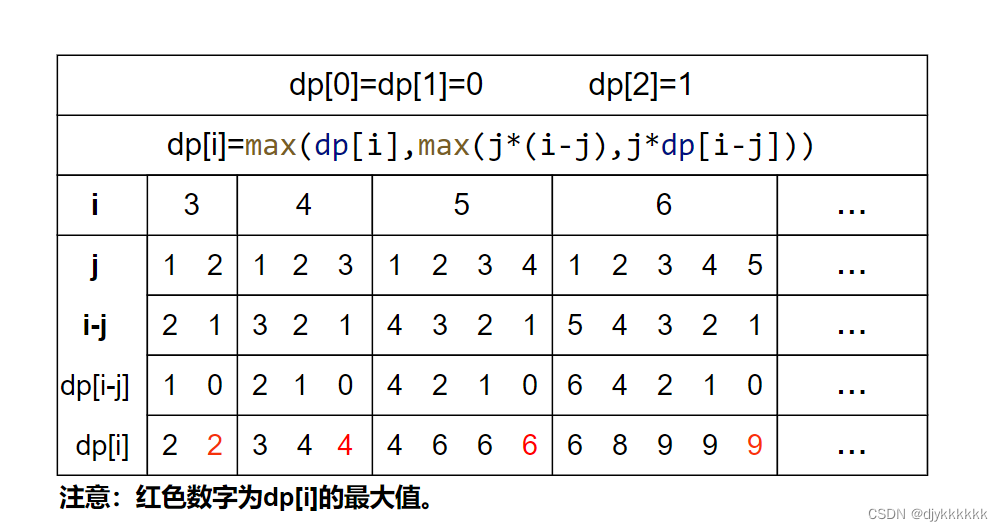
day-41 代码随想录算法训练营(19)动态规划 part 03
343.整数拆分 思路: 1.dp存储的是第i个数,拆分之后最大乘积2.dp[i]max(dp[i],max(j*(i-j),j*dp[i-j]));3.初始化:dp[0]dp[1]0,dp[2]1;4.遍历顺序:外层循环 3-n,内层循环 1-i 2.涉及两次取max: dp[i] 表…...
)
K8S安装部署 初始化操作(一)
准备好服务器和服务器资源 ip hostnameip资源 (2核2G也可以)k8s-master 192.168.37.1184核 4G 40G硬盘k8s-node1192.168.37.1192核 2G 20G硬盘k8s-node2192.168.37.1202核 2G 20G硬盘 初始操作三台同时执行 1、关闭防火墙 [rootlocalhost ~]# s…...
【多线程案例】单例模式(懒汉模式和饿汉模式)
文章目录 1. 什么是单例模式?2. 立即加载/“饿汉模式”3. 延时加载/“懒汉模式”3.1 第一版3.2 第二版3.3 第三版3.4 第四版 1. 什么是单例模式? 提起单例模式,就必须介绍设计模式,而设计模式就是在软件设计中,针对特殊…...
Anaconda - 操作系统安装程序 简要介绍
Anaconda 简要介绍 1. Anaconda 简介2. Anaconda 体系结构3. Anaconda 开发模型4. Anaconda 启动概述5. Anaconda 源码1. 接口2. 自定义组件3. 硬盘分区:使用python-blivet包4. Bootloader5. 各个步骤的配置:6. 安装软件包:7. 安装控制&#…...

【数据库设计】向量搜索HNSW算法优化
做向量存储的过程中,遇到向量搜索的情况处理,HNSW算法是目前向量搜索的主要算法之一,采用的是图算法,主要的问题是使用内存大,训练时间长。做算法优化过程中获得部分技巧,分享出来。 一、算法本身的优化 对…...

多通道振弦数据记录仪应用桥梁安全监测的关键要点
多通道振弦数据记录仪应用桥梁安全监测的关键要点 随着近年来桥梁建设和维护的不断推进,桥梁安全监测越来越成为公共关注的焦点。多通道振弦数据记录仪因其高效、准确的数据采集和处理能力,已经成为桥梁安全监测中不可或缺的设备。本文将从以下几个方面…...

深入了解HTTP代理的工作原理
HTTP代理是一种常见的网络代理方式,它可以帮助用户隐藏自己的IP地址,保护个人隐私和安全。了解HTTP代理的工作原理对于使用HTTP代理的用户来说非常重要。本文将深入介绍HTTP代理的工作原理。 代理服务器的作用 HTTP代理的工作原理基于代理服务器的作用。…...

2023年高教社杯数学建模国赛选题人数+C题进阶版修改思路详解
C题思路 修改版 C题保奖 数据预处理 3σ原则 区间判断法、人为判定 问题 1 聚类分析进行简单的分类 相互关系 数据服从正态分布(K-S检验等判定分布类型后) 才能做person相关性 图表结合(热力图、数据结果表) 分布规律 宏…...
第三章微服务配置中心
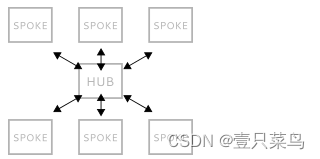
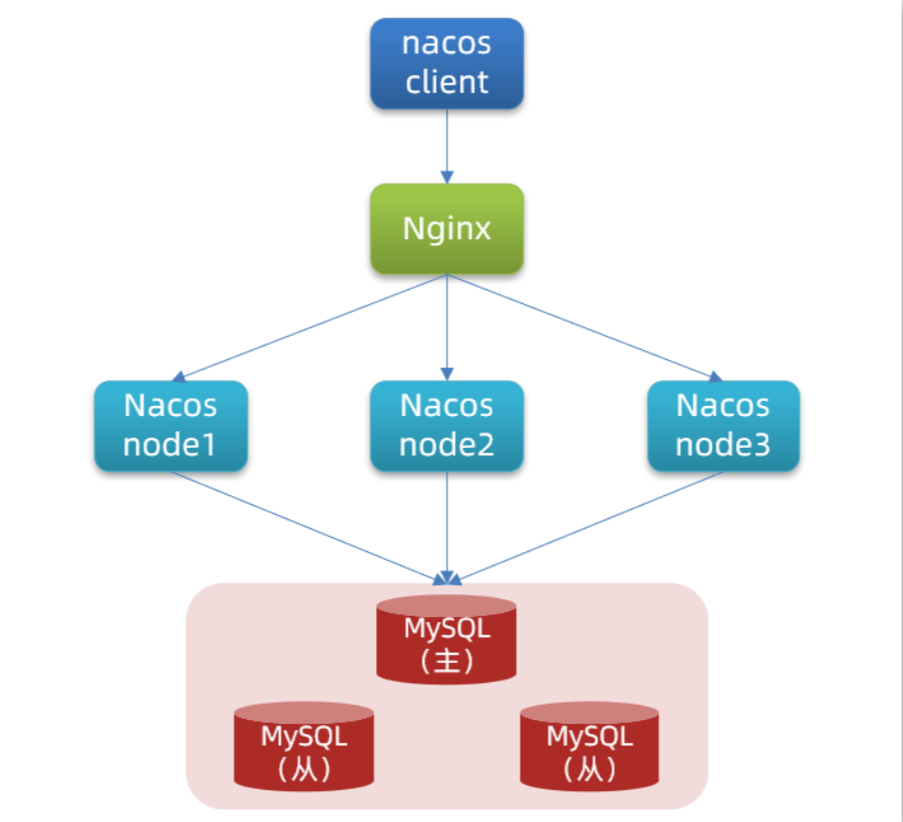
文章目录 Nacos配置中心统一配置管理在nacos中添加配置文件从微服务拉取配置 配置热更新多环境共享配置 搭建Nacos集群搭建集群初始化数据库配置Nacos启动nginx反向代理 Nacos配置中心 Nacos配置管理 Nacos除了可以做注册中心,同样可以做配置管理来使用。 统一配置…...

箭头函数(arrow function)与普通函数之间的区别是什么?
聚沙成塔每天进步一点点 ⭐ 专栏简介⭐ 语法简洁性:⭐ this 的绑定:⭐ 不能用作构造函数:⭐ 没有 arguments 对象:⭐ 不适用于方法:⭐ 写在最后 ⭐ 专栏简介 前端入门之旅:探索Web开发的奇妙世界 记得点击上…...

大数据学习栈记——Neo4j的安装与使用
本文介绍图数据库Neofj的安装与使用,操作系统:Ubuntu24.04,Neofj版本:2025.04.0。 Apt安装 Neofj可以进行官网安装:Neo4j Deployment Center - Graph Database & Analytics 我这里安装是添加软件源的方法 最新版…...

CTF show Web 红包题第六弹
提示 1.不是SQL注入 2.需要找关键源码 思路 进入页面发现是一个登录框,很难让人不联想到SQL注入,但提示都说了不是SQL注入,所以就不往这方面想了 先查看一下网页源码,发现一段JavaScript代码,有一个关键类ctfs…...

Xshell远程连接Kali(默认 | 私钥)Note版
前言:xshell远程连接,私钥连接和常规默认连接 任务一 开启ssh服务 service ssh status //查看ssh服务状态 service ssh start //开启ssh服务 update-rc.d ssh enable //开启自启动ssh服务 任务二 修改配置文件 vi /etc/ssh/ssh_config //第一…...

el-switch文字内置
el-switch文字内置 效果 vue <div style"color:#ffffff;font-size:14px;float:left;margin-bottom:5px;margin-right:5px;">自动加载</div> <el-switch v-model"value" active-color"#3E99FB" inactive-color"#DCDFE6"…...

《基于Apache Flink的流处理》笔记
思维导图 1-3 章 4-7章 8-11 章 参考资料 源码: https://github.com/streaming-with-flink 博客 https://flink.apache.org/bloghttps://www.ververica.com/blog 聚会及会议 https://flink-forward.orghttps://www.meetup.com/topics/apache-flink https://n…...
-HIve数据分析)
大数据学习(132)-HIve数据分析
🍋🍋大数据学习🍋🍋 🔥系列专栏: 👑哲学语录: 用力所能及,改变世界。 💖如果觉得博主的文章还不错的话,请点赞👍收藏⭐️留言Ǵ…...

【Java学习笔记】BigInteger 和 BigDecimal 类
BigInteger 和 BigDecimal 类 二者共有的常见方法 方法功能add加subtract减multiply乘divide除 注意点:传参类型必须是类对象 一、BigInteger 1. 作用:适合保存比较大的整型数 2. 使用说明 创建BigInteger对象 传入字符串 3. 代码示例 import j…...

ubuntu22.04 安装docker 和docker-compose
首先你要确保没有docker环境或者使用命令删掉docker sudo apt-get remove docker docker-engine docker.io containerd runc安装docker 更新软件环境 sudo apt update sudo apt upgrade下载docker依赖和GPG 密钥 # 依赖 apt-get install ca-certificates curl gnupg lsb-rel…...

【Kafka】Kafka从入门到实战:构建高吞吐量分布式消息系统
Kafka从入门到实战:构建高吞吐量分布式消息系统 一、Kafka概述 Apache Kafka是一个分布式流处理平台,最初由LinkedIn开发,后成为Apache顶级项目。它被设计用于高吞吐量、低延迟的消息处理,能够处理来自多个生产者的海量数据,并将这些数据实时传递给消费者。 Kafka核心特…...

大数据治理的常见方式
大数据治理的常见方式 大数据治理是确保数据质量、安全性和可用性的系统性方法,以下是几种常见的治理方式: 1. 数据质量管理 核心方法: 数据校验:建立数据校验规则(格式、范围、一致性等)数据清洗&…...