Pytorch从零开始实战01
Pytorch从零开始实战——MNIST手写数字识别
本系列来源于365天深度学习训练营
原作者K同学
文章目录
- Pytorch从零开始实战——MNIST手写数字识别
- 环境准备
- 数据集
- 模型选择
- 模型训练
- 可视化展示
环境准备
本系列基于Jupyter notebook,使用Python3.7.12,Pytorch1.7.0+cu110,torchvision0.8.0,需读者自行配置好环境且有一些深度学习理论基础。
导入需要用到的包
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
import torchvision
import torch.nn.functional as F
import random
from time import time
import random
import numpy as np
import pandas as pd
import datetime
import gc
import os
os.environ['KMP_DUPLICATE_LIB_OK']='True' # 用于避免jupyter环境突然关闭
torch.backends.cudnn.benchmark=True # 用于加速GPU运算的代码
创建设备对象
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
device
device(type=‘cuda’)
设置随机数种子
torch.manual_seed(428)
torch.cuda.manual_seed(428)
torch.cuda.manual_seed_all(428)
random.seed(428)
np.random.seed(428)
数据集
本次实战使用MNIST数据集,这是一个包含了手写数字的灰度图像的数据集,每个图像都是28x28像素大小,并且标记了相应的数字,也是很多计算机视觉初学者第一个使用的数据集。
导入训练集与测试集,使用torchvision.datasets可以在线下载很多常见数据集,只需要将后面参数设置download=True即可直接下载,train=True为训练集,train=False为测试集
# 导入训练集和测试集
train_data = torchvision.datasets.MNIST('data', train=True, transform=torchvision.transforms.ToTensor(),download=True)
test_data = torchvision.datasets.MNIST('data', train=False, transform=torchvision.transforms.ToTensor(),download=True)
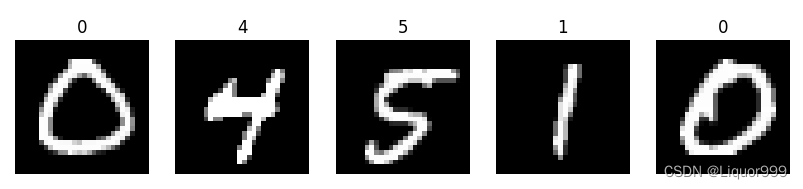
定义一个函数,随机查看5张图片
# 随机展示5个图片 data = torchvision.datasets.... 需要接受tensor格式的对象
def plotsample(data):fig, axs = plt.subplots(1, 5, figsize=(10, 10)) #建立子图for i in range(5):num = random.randint(0, len(data) - 1) #首先选取随机数,随机选取五次#抽取数据中对应的图像对象,make_grid函数可将任意格式的图像的通道数升为3,而不改变图像原始的数据#而展示图像用的imshow函数最常见的输入格式也是3通道npimg = torchvision.utils.make_grid(data[num][0]).numpy()nplabel = data[num][1] #提取标签 #将图像由(3, weight, height)转化为(weight, height, 3),并放入imshow函数中读取axs[i].imshow(np.transpose(npimg, (1, 2, 0))) axs[i].set_title(nplabel) #给每个子图加上标签axs[i].axis("off") #消除每个子图的坐标轴plotsample(train_data)
使用DataLoder将它按照batch_size批量划分,并将训练集顺序打乱。
batch_size = 32
train_dl = torch.utils.data.DataLoader(train_data, batch_size=batch_size, shuffle=True)
test_dl = torch.utils.data.DataLoader(test_data, batch_size=batch_size)
模型选择
由于数据集较为简单,所以本次实验使用简单的卷积神经网络。
第一次卷积和池化:
self.conv1 是第一个卷积层,将输入特征图的通道数从1增加到32,同时使用3x3的卷积核进行卷积。由于没有填充(padding)操作,卷积后的特征图大小减小为原来的大小减2(28x28 -> 26x26)。
self.pool1 是第一个最大池化层,将特征图的大小减半,从26x26变为13x13。
第二次卷积和池化:
self.conv2 是第二个卷积层,将输入特征图的通道数从32增加到64,同样使用3x3的卷积核进行卷积。由于没有填充操作,卷积后的特征图大小再次减小为原来的大小减2(13x13 -> 11x11)。
self.pool2 是第二个最大池化层,将特征图的大小再次减半,从11x11变为5x5。
全连接层:
在进入全连接层之前,需要将最后一个池化层的输出拉平成一个一维向量。这是通过 torch.flatten(x, start_dim=1) 完成的,它将5x5x64的三维张量转换为长度为5x5x64 = 1600的一维向量。
然后,self.fc1 是第一个全连接层,将1600个输入特征映射到64个输出特征。
最后进行10分类输出结果。
num_classes = 10 # 10分类
class Model(nn.Module):def __init__(self):super().__init__()self.conv1 = nn.Conv2d(1, 32, kernel_size=3)self.pool1 = nn.MaxPool2d(2)self.conv2 = nn.Conv2d(32, 64, kernel_size=3)self.pool2 = nn.MaxPool2d(2)self.fc1 = nn.Linear(1600, 64)self.fc2 = nn.Linear(64, num_classes)def forward(self, x):x = self.pool1(F.relu(self.conv1(x)))x = self.pool2(F.relu(self.conv2(x)))x = torch.flatten(x, start_dim=1) # 拉平x = F.relu(self.fc1(x))x = self.fc2(x)return x
将模型转移到GPU中,并使用summary查看模型
from torchinfo import summary
# 将模型转移到GPU中
model = Model().to(device)
summary(model)

模型训练
定义损失函数、学习率、优化算法
loss_fn = nn.CrossEntropyLoss()
learn_rate = 0.01
opt = torch.optim.SGD(model.parameters(), lr=learn_rate)
定义训练函数,返回一个epoch的模型的准确率和损失
def train(dataloader, model, loss_fn, optimizer):size = len(dataloader.dataset)num_batches = len(dataloader)train_loss, train_acc = 0, 0for X, y in dataloader:X, y = X.to(device), y.to(device)pred = model(X)loss = loss_fn(pred, y)optimizer.zero_grad()loss.backward()optimizer.step()train_acc += (pred.argmax(1) == y).type(torch.float).sum().item()train_loss += loss.item()train_acc /= sizetrain_loss /= num_batchesreturn train_acc, train_loss
定义测试函数,与训练函数类似,只是停止梯度更新,节省计算内存消耗
def test (dataloader, model, loss_fn):size = len(dataloader.dataset) num_batches = len(dataloader) test_loss, test_acc = 0, 0with torch.no_grad():for X, target in dataloader:X, target = X.to(device), target.to(device)pred = model(X)loss = loss_fn(pred, target)test_acc += (pred.argmax(1) == target).type(torch.float).sum().item()test_loss += loss.item()test_acc /= sizetest_loss /= num_batchesreturn test_acc, test_loss
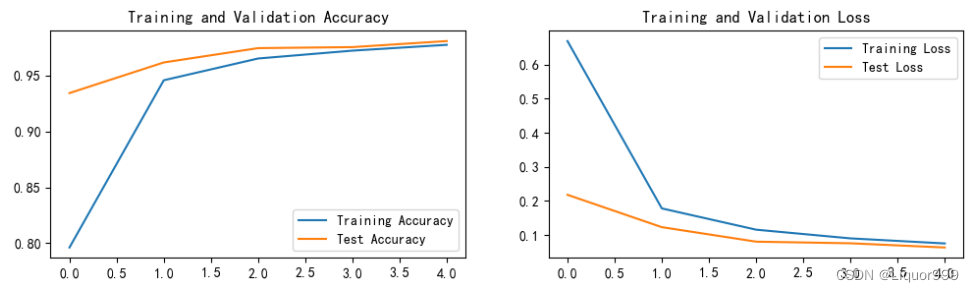
开始训练,一共进行了5轮epoch,最后在训练集准确率可达97.7%,测试集准确率可达98.1%
epochs = 5
train_loss = []
train_acc = []
test_loss = []
test_acc = []for epoch in range(epochs):model.train()epoch_train_acc, epoch_train_loss = train(train_dl, model, loss_fn, opt)model.eval() # 确保模型不会进行训练操作epoch_test_acc, epoch_test_loss = test(test_dl, model, loss_fn)train_acc.append(epoch_train_acc)train_loss.append(epoch_train_loss)test_acc.append(epoch_test_acc)test_loss.append(epoch_test_loss)print("epoch:%d, train_acc:%.1f%%, train_loss:%.3f, test_acc:%.1f%%, test_loss:%.3f"% (epoch + 1, epoch_train_acc * 100, epoch_train_loss, epoch_test_acc * 100, epoch_test_loss))
print("Done")
可视化展示
使用matplotlib进行训练、测试的可视化
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.rcParams['figure.dpi'] = 100 #分辨率epochs_range = range(epochs)plt.figure(figsize=(12, 3))
plt.subplot(1, 2, 1)plt.plot(epochs_range, train_acc, label='Training Accuracy')
plt.plot(epochs_range, test_acc, label='Test Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')plt.subplot(1, 2, 2)
plt.plot(epochs_range, train_loss, label='Training Loss')
plt.plot(epochs_range, test_loss, label='Test Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
相关文章:
Pytorch从零开始实战01
Pytorch从零开始实战——MNIST手写数字识别 本系列来源于365天深度学习训练营 原作者K同学 文章目录 Pytorch从零开始实战——MNIST手写数字识别环境准备数据集模型选择模型训练可视化展示 环境准备 本系列基于Jupyter notebook,使用Python3.7.12,Py…...
inappropriate address 127.0.0.1 for the fudge command, line ignored 时间同步的时候报错
1、安装ntp服务后,启动ntpd正常,但是在查看ntpd服务状态时,有一个红色的报错,报错信息如下: inappropriate address 127.0.0.1 for the fudge command, line ignored 2、解决方法:编辑ntp配置文件…...
linux并发服务器 —— 项目实战(九)
阻塞/非阻塞、同步/异步 数据就绪 - 根据系统IO操作的就绪状态 阻塞 - 调用IO方法的线程进入阻塞状态(挂起) 非阻塞 - 不会改变线程的状态,通过返回值判断 数据读写 - 根据应用程序和内核的交互方式 同步 - 数据的读写需要应用层去读写 …...
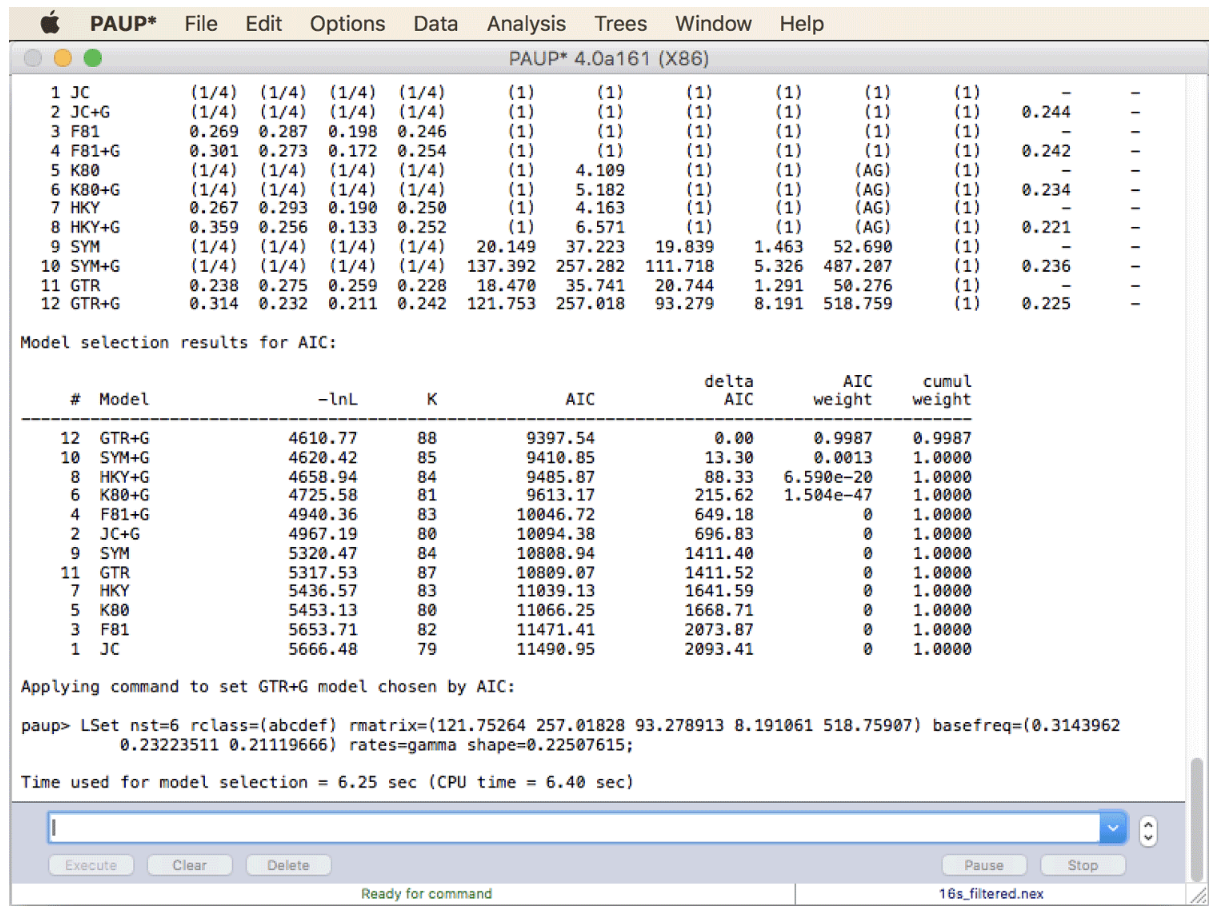
生信教程|替代模型选择
摘要 由于教程时间比较久远,因此不建议实操,仅阅读以了解学习。 在运行基于可能性的系统发育分析之前,用户需要决定模型中应包含哪些自由参数:是否应该为所有替换假设单一速率(如序列进化的 Jukes-Cantor 模型…...
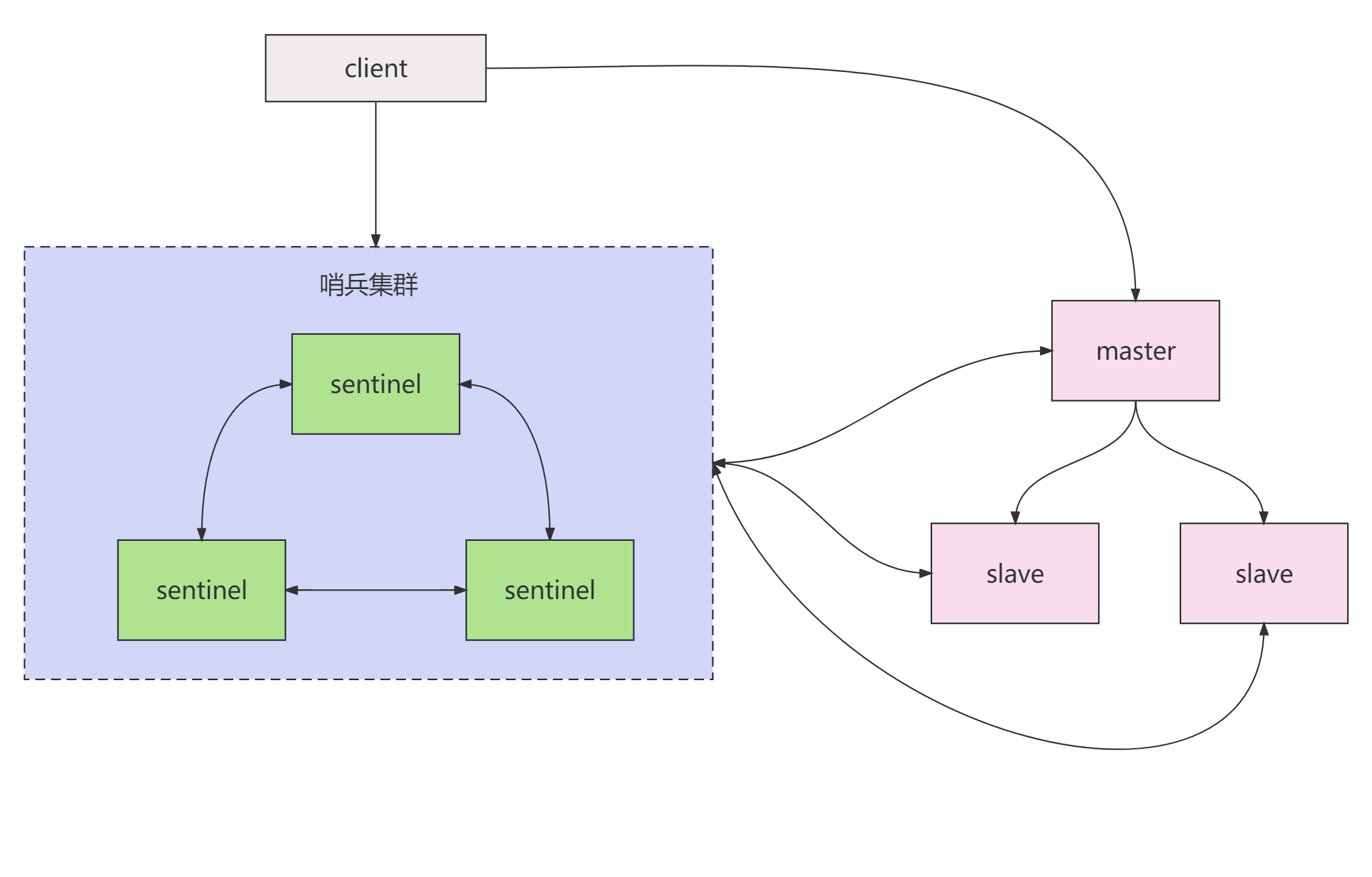
redis持久化、主从和哨兵架构
一、redis持久化 1、RDB快照(snapshot) redis配置RDB存储模式,修改redis.conf文件如下配置: # 在300s内有100个或者以上的key被修改就会把redis中的数据持久化到dump.rdb文件中 # save 300 100# 配置数据存放目录(现…...

Python 连接 Oracle 详解
文章目录 1 首先,安装第三方库 cx_Oracle2 其次,配置命令 1 首先,安装第三方库 cx_Oracle 参考 CSDN 博客:Python 安装第三方库详解(含离线) 2 其次,配置命令 import cx_Oracle# 1.数据库连接…...

认识模块化
1. 模块化的基本概念 1.1 什么是模块化 模块化是指解决一个复杂问题时,自顶向下逐层把系统划分成若干模块的过程。对于整个系统来说,模块是可组 合、分解和更换的单元。 1. 现实生活中的模块化 2.编程领域中的模块化 编程领域中的模块化,…...

2023年及以后语言、视觉和生成模型的发展和展望
一、简述 在过去的十年里,研究人员都在追求类似的愿景——帮助人们更好地了解周围的世界,并帮助人们更好地了解周围的世界。把事情做完。我们希望建造功能更强大的机器,与人们合作完成各种各样的任务。各种任务。复杂的信息搜寻任务。创造性任务,例如创作音乐、绘制新图片或…...
OpenLdap +PhpLdapAdmin + Grafana docker-compose部署安装
目录 一、OpenLdap介绍 二、PhpLdapAdmin介绍 三、使用docker-compose进行安装 1. docker-compose.yml 2. grafana配置文件 3. provisioning 四、安装openldap、phpldapadmin、grafana 五、配置OpenLDAP 1. 登陆PhpLdapAdmin web管理 2. 需要注意的细节 内容介绍参考…...

Java | 排序内容大总结
不爱生姜不吃醋⭐️ 如果本文有什么错误的话欢迎在评论区中指正 与其明天开始,不如现在行动! 文章目录 🌴前言🌴算法整理🌴两个结论🌴总结 🌴前言 本文内容是关于选择排序、冒泡排序、插入排序…...

Go 语言入门指南:基础语法和常用特性解析
什么是Go语言? Go语言是Google开发的一种静态强类型、编译型、并发型,并具有垃圾回收功能的编程语言。它用批判吸收的眼光,融合C语言、Java等众家之长,将简洁、高效演绎得淋漓尽致。 Go语言语法与C相近,但功能上有&a…...
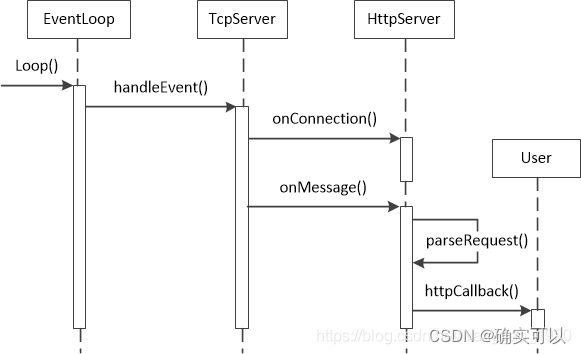
20.添加HTTP模块
添加一个简单的静态HTTP。 这里默认读者是熟悉http协议的。 来看看http请求Request的例子 客户端发送一个HTTP请求到服务器的请求消息,其包括:请求行、请求头部、空行、请求数据。 HTTP之响应消息Response 服务器接收并处理客户端发过来的请求后会返…...
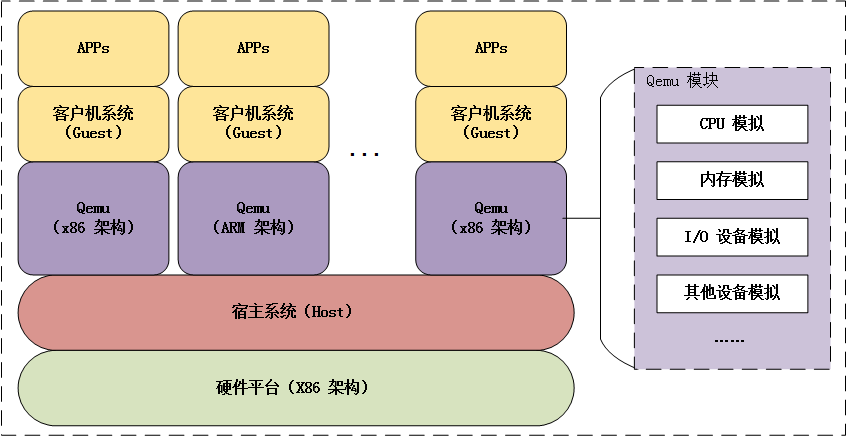
Qemu 架构 硬件模拟器
Qemu 架构 硬件模拟器 Qemu 是纯软件实现的虚拟化模拟器, 几乎可以模拟任何硬件设备, 我们最熟悉的就是能够模拟一台能够独立运行操作系统的虚拟机, 虚拟机认为自己和硬件打交道, 但其实是和 Qemu 模拟出来的硬件打交道ÿ…...
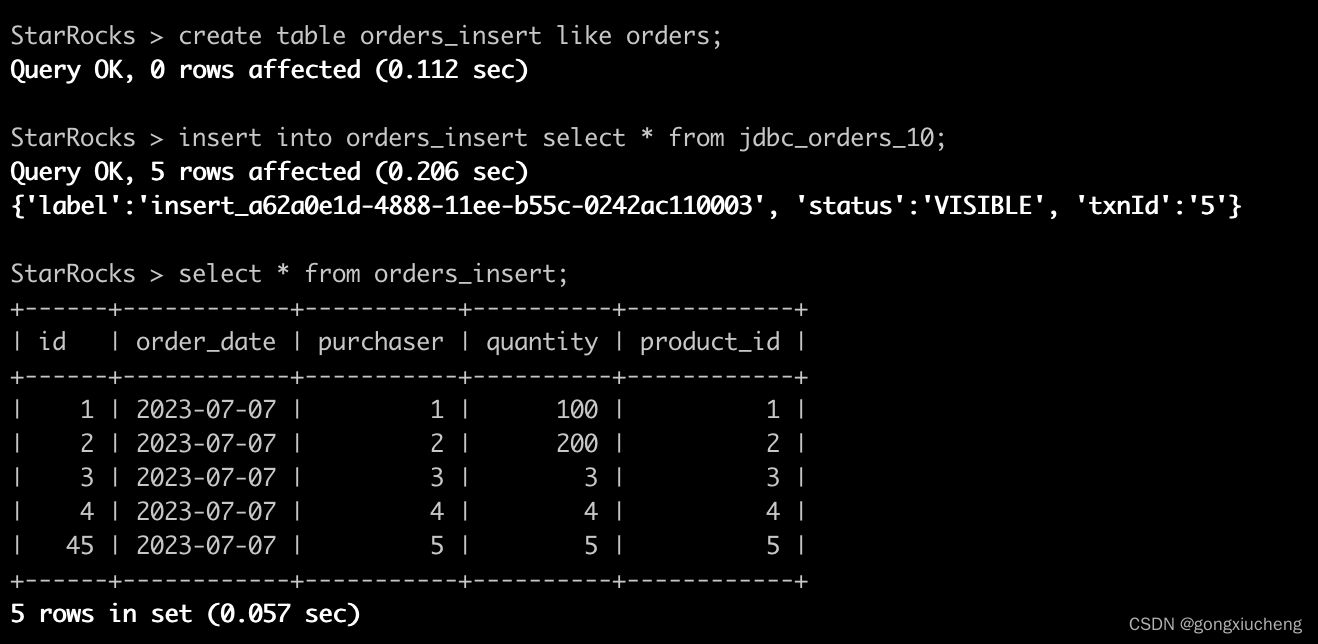
通过starrocks jdbc外表查询sqlserver
1.sqlserver环境准备,使用docker环境,可以参考使用flink sqlserver cdc 同步数据到StarRocks_gongxiucheng的博客-CSDN博客 部署获得sqlserver环境; 2.获取starrocks环境,也可以通过docker部署,参考:使用…...

ArcGIS 10.5安装教程!
软件介绍: ArcGIS Desktop 10.5中文特别版是一款功能强大的GSI专业电子地图信息编辑和开发软件,ArcGIS Desktop 包括两种可实现制图和可视化的主要应用程序,即 ArcMap 和 ArcGIS Pro。ArcMap 是用于在 ArcGIS Desktop 中进行制图、编辑、分析…...

ConstraintLayout约束布局
1.进行复杂页面布局时,最外层的根布局不要用ConstraintLayout. 示例布局: <?xml version"1.0" encoding"utf-8"?> <androidx.constraintlayout.widget.ConstraintLayout xmlns:android"http://schemas.android.co…...

通过pyinstaller将python项目打包成exe执行文件
目录 第一步:安装pyinstaller 第二步:获取一个ico图标(也即是自己这个exe文件最后的图标) 第三步:打包 第一步:安装pyinstaller pip install pyinstaller 第二步:获取一个ico图标ÿ…...

P1068 [NOIP2009 普及组] 分数线划定
题目描述 世博会志愿者的选拔工作正在 A 市如火如荼的进行。为了选拔最合适的人才,A 市对所有报名的选手进行了笔试,笔试分数达到面试分数线的选手方可进入面试。面试分数线根据计划录取人数的 150 % 150\% 150% 划定,即如果计划录取 m m …...

应用在汽车新风系统中消毒杀菌的UVC灯珠
在病毒、细菌的传播可以说是一个让人敏感而恐惧的事情。而对于车内较小的空间,乘坐人员流动性大,更容易残留细菌病毒。车内缺少通风,残留的污垢垃圾也会滋生细菌,加快细菌的繁殖。所以对于车内消毒就自然不容忽视。 那么问题又来…...

TOOLLLM: FACILITATING LARGE LANGUAGE MODELS TO MASTER 16000+ REAL-WORLD APIS
本文是LLM系列的文章之一,针对《TOOLLLM: FACILITATING LARGE LANGUAGE MODELS TO MASTER 16000 REAL-WORLD APIS》的翻译。 TOOLLLMs:让大模型掌握16000的真实世界APIs 摘要1 引言2 数据集构建3 实验4 相关工作5 结论 摘要 尽管开源大型语言模型&…...

日语AI面试高效通关秘籍:专业解读与青柚面试智能助攻
在如今就业市场竞争日益激烈的背景下,越来越多的求职者将目光投向了日本及中日双语岗位。但是,一场日语面试往往让许多人感到步履维艰。你是否也曾因为面试官抛出的“刁钻问题”而心生畏惧?面对生疏的日语交流环境,即便提前恶补了…...

Python实现prophet 理论及参数优化
文章目录 Prophet理论及模型参数介绍Python代码完整实现prophet 添加外部数据进行模型优化 之前初步学习prophet的时候,写过一篇简单实现,后期随着对该模型的深入研究,本次记录涉及到prophet 的公式以及参数调优,从公式可以更直观…...

(二)原型模式
原型的功能是将一个已经存在的对象作为源目标,其余对象都是通过这个源目标创建。发挥复制的作用就是原型模式的核心思想。 一、源型模式的定义 原型模式是指第二次创建对象可以通过复制已经存在的原型对象来实现,忽略对象创建过程中的其它细节。 📌 核心特点: 避免重复初…...

c#开发AI模型对话
AI模型 前面已经介绍了一般AI模型本地部署,直接调用现成的模型数据。这里主要讲述讲接口集成到我们自己的程序中使用方式。 微软提供了ML.NET来开发和使用AI模型,但是目前国内可能使用不多,至少实践例子很少看见。开发训练模型就不介绍了&am…...

华为OD机考-机房布局
import java.util.*;public class DemoTest5 {public static void main(String[] args) {Scanner in new Scanner(System.in);// 注意 hasNext 和 hasNextLine 的区别while (in.hasNextLine()) { // 注意 while 处理多个 caseSystem.out.println(solve(in.nextLine()));}}priv…...

腾讯云V3签名
想要接入腾讯云的Api,必然先按其文档计算出所要求的签名。 之前也调用过腾讯云的接口,但总是卡在签名这一步,最后放弃选择SDK,这次终于自己代码实现。 可能腾讯云翻新了接口文档,现在阅读起来,清晰了很多&…...

Go语言多线程问题
打印零与奇偶数(leetcode 1116) 方法1:使用互斥锁和条件变量 package mainimport ("fmt""sync" )type ZeroEvenOdd struct {n intzeroMutex sync.MutexevenMutex sync.MutexoddMutex sync.Mutexcurrent int…...
[论文阅读]TrustRAG: Enhancing Robustness and Trustworthiness in RAG
TrustRAG: Enhancing Robustness and Trustworthiness in RAG [2501.00879] TrustRAG: Enhancing Robustness and Trustworthiness in Retrieval-Augmented Generation 代码:HuichiZhou/TrustRAG: Code for "TrustRAG: Enhancing Robustness and Trustworthin…...

云原生周刊:k0s 成为 CNCF 沙箱项目
开源项目推荐 HAMi HAMi(原名 k8s‑vGPU‑scheduler)是一款 CNCF Sandbox 级别的开源 K8s 中间件,通过虚拟化 GPU/NPU 等异构设备并支持内存、计算核心时间片隔离及共享调度,为容器提供统一接口,实现细粒度资源配额…...
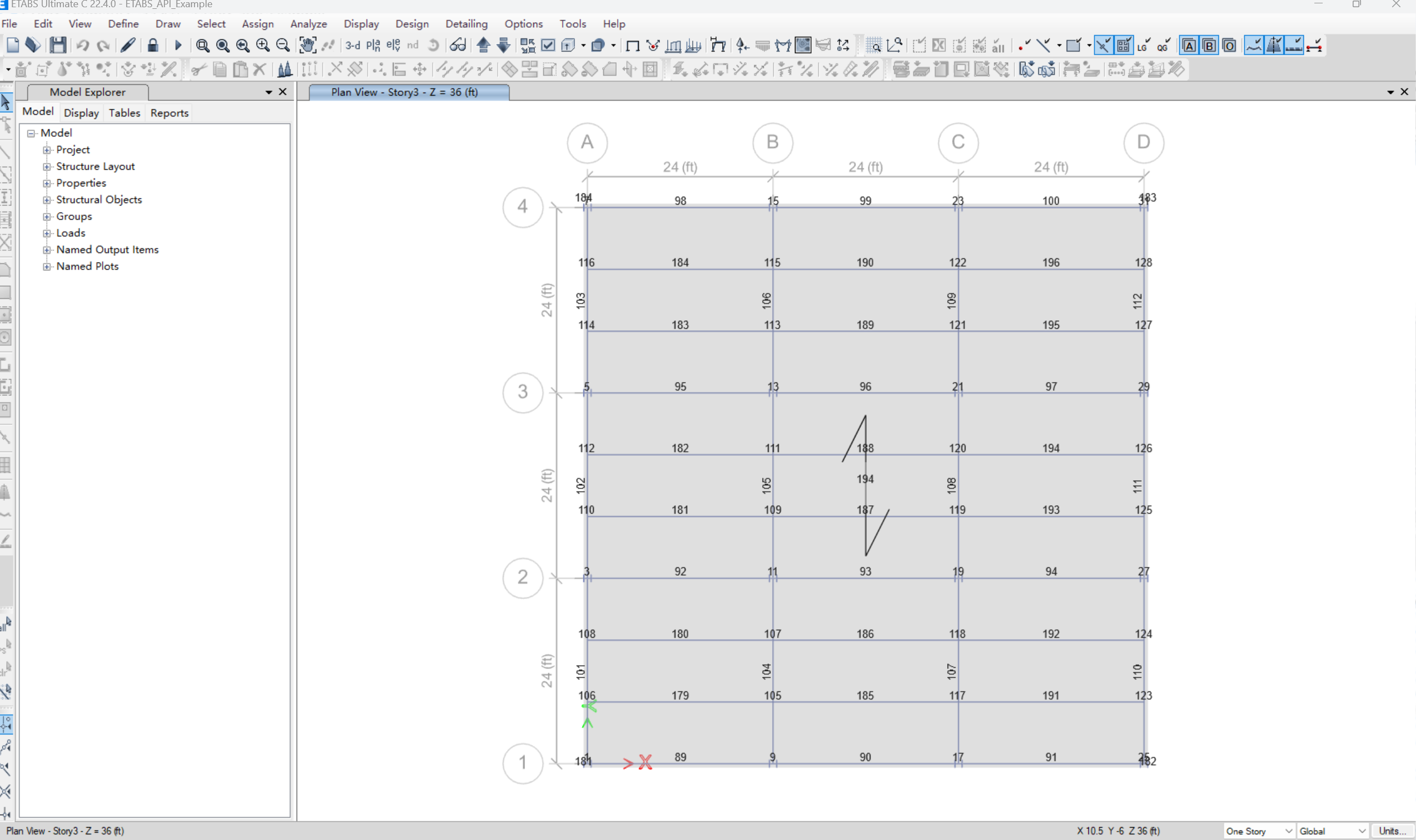
【Post-process】【VBA】ETABS VBA FrameObj.GetNameList and write to EXCEL
ETABS API实战:导出框架元素数据到Excel 在结构工程师的日常工作中,经常需要从ETABS模型中提取框架元素信息进行后续分析。手动复制粘贴不仅耗时,还容易出错。今天我们来用简单的VBA代码实现自动化导出。 🎯 我们要实现什么? 一键点击,就能将ETABS中所有框架元素的基…...