Flask狼书笔记 | 05_数据库

文章目录
- 5 数据库
- 5.1 数据库的分类
- 5.2 ORM
- 5.3 使用Flask_SQLAlchemy
- 5.4 数据库操作
- 5.5 定义关系
- 5.6 更新数据库表
- 5.7 数据库进阶
- 小结
5 数据库
这一章学习如何在Python中使用DBMS(数据库管理系统),来对数据库进行管理和操作。本书使用SQLite作为示例。
注:按下Ctrl+F5,或Shift+F5可以清除浏览器缓存。
5.1 数据库的分类
分为SQL(Structured Query Language)数据库和NoSQL(Not Only SQL)数据库。
- SQL:稍显复杂,但不容易出错,可以适应大部分场景。
- NoSQL:灵活,效率高,可扩展性好等。
- 1、文档存储:使用类json格式来表示数据
- 2、键值对存储:通过键来存取数据,读写很快,常作为缓存使用。
5.2 ORM
ORM:Object-Relational Mapping,对象关系映射。
作用:
- 处理查询参数的转义,防止注入。
- 为不同的DBMS提供统一的接口。
- 能直接使用Python操作数据库,不需要写SQL语句。
ORM实现了三层映射关系:表 --> Python类,字段 --> 类属性,记录 --> 类实例。
# 定义表
from foo_orm import Model, Column, String
class Contact(Model):__tablename__ = 'contacts'name = Column(String(100), nullable=False)# 插入记录
contact = Contact(name="zhang san")
5.3 使用Flask_SQLAlchemy
1、连接数据库:
首先连接数据库需要指定URI(Uniform Resource Identifier,统一资源标识符),URL(统一资源定位符)是它的子集。
常用的数据库URI格式:(p143)
SQLite是基于文件的DBMS,不需要数据库服务器,只需要指定数据库文件的绝对路径。配置数据库URI的代码如下:
from flask import Flask
import os
from flask_sqlalchemy import SQLAlchemyapp = Flask(__name__)
t = app.config['SQLALCHEMY_DATABASE_URI'] = os.getenv('DATABASE_URL', 'sqlite:///' + os.path.join(app.root_path, 'data.db'))
db = SQLAlchemy(app)print(t)
print(db)
运行输出:
sqlite:///D:\code_all\gitCode\helloflask_learn\数据库\data.db
<SQLAlchemy>
补充:
os.getenv是一个Python标准库函数,它用于从环境变量中获取指定的值。这个函数的第一个参数是要查找的环境变量名称,第二个参数是默认值,如果未找到指定的环境变量,则返回这个默认值。
2、定义数据库模型:
模型类继承自SQLAlchemy提供的db.Model基类,表的字段由db.Column类的实例表示。
SQLAlchemy常用的字段类型:(p144)
常用的字段参数:(p145)
class Note(db.Model):id = db.Column(db.Integer, primary_key=True)body = db.Column(db.Text)
-
表名称会根据模型的类名称自动生成,可用
__tablename__属性指定。 -
字段名默认为类属性名,看用
name关键字参数指定。
3、创建数据库和表:
db.create_all()
可以查看模型对象的建表SQL语句:
from app import Note
from sqlalchemy.schema import CreateTable
print(CreateTable(Note.__table__))
改动模型类后,再次调用create_all()不会更新表结构。可以调用drop_all()方法删除数据库和表,然后重建。
可以自定义一个flaks命令完成数据库的创建工作,对于sqlite创建成功后会生成一个数据库文件,如data.db。
import click
@app.cli.command()
def initdb():db.create_all()click.echo('Initialized database')
5.4 数据库操作
SQLAlchemy使用数据库会话(也称为事务)来管理数据库操作,会话代表一个临时存储区,对会话对象调用commit()方法时,改动才被提交到数据库。调用rollback()方法可以撤销会话中未提交的改动。
1、CRUD:
即Create、Read、Update、Delete。
- Create
note = Note(body='hello, world')
db.session.add(note)
db.session.commit()
通过add_all()可以一次提交一个列表。
- Read
<模型类>.query.<过滤方法>.<查询方法>
Note.query.filter(Note.body=='hello, world').first
Query对象调用过滤方法的返回值仍然是一个Query对象,就像SQL的操作对象和返回结果都是表。查询方法返回的是模型类实例。
常用的SQLAchemy查询方法:(p148)
all(),first(),count(),paginate(),get(ident)等常用过滤方法:(p150)
filter(),filter_by(),order_by(),limit(),group_by()等常用查询操作符:(p150) LIKE,IN,NOT IN,AND,OR等。
- Update
note = Note.query.get(2)
note.body = 'hello, flask'
db.session.commit()
- Delete
note = Note.query.get(2)
db.session.delete(note)
db.session.commit()
2、在视图函数里操作数据库:
与在python shell中基本一致。
5.5 定义关系
1、配置Python Shell上下文
使用app.shell_context_processor装饰器注册一个shell上下文处理函数,返回包含变量和变量值的字典。
@app.shell_context_processor
def make_shell_context():return dict(db=db, Note=Note)
2、一对多关系
定义一对多关系包含两个部分:定义外键,和定义关系属性。其中关系属性相当于一个快捷查询,不会作为字段被写入到数据库中。下面的关系属性articles会返回该作者所有文章的记录列表。
class Author(db.Model):...articles = db.relationship('Article')class Article(db.Model):...author_id = db.Column(db.Integer, db.ForeignKey('athor.id'))
可以在两侧都定义一个关系属性,称为双向关系,需要用到back_populates关键字参数,值为另一侧的关系属性名。
class Author(db.Model):...articles = db.relationship('Article', back_populates='author')class Article(db.Model):...author_id = db.Column(db.Integer, db.ForeignKey('athor.id'))author = db.relationship('Author', back_populates='articles')
可以使用
backref简化关系定义,(p163)疑惑:为什么要手动在两侧都指定反向引用,而不是添加了外键属性之后就自动的呢?是采用了数据库中的索引吗?
定义关系后,建立关系有两种方式,一种是为外键字段赋值,另一种是通过操作关系属性。
# 为外键字段赋值
article_A.author_id = 1
# 操作关系属性: append, remove, pop
Mike.articles.append(article_A)
常用关系函数参数:p161
常用关系记录加载方式:p161
3、一对一关系
实际上是在通过建立一对多关系的双向关系的基础上转化而来,只是在原来”一“的一方设置userlist=False,将集合属性变为标量属性。此后,无法再使用列表语义操作,如append方法。
class Contry(db.Model):...capital = db.relationship('Capital', uselist=False)
class Capital(db.Model):...contry_id = db.Column(db.Integer, db.ForeignKey('country.id'))contry = db.relationship('Country')
4、多对多关系
一对多关系中在“多”的一方存放外键,则“多”一方的每条记录只能有一条关系。我们可以单独创建一个关联表(db.Table)来存储外键,表示多对多关系。使用secondary参数来指定关联表。
association_table = db.Table('association',db.Column('student_id', db.Integer, db.ForeignKey('student.id')),db.Column('teacher_id', db.Integer, db.ForeignKey('teacher.id')))class Student(db.Model):...teachers = db.relationship('Teacher', secondary=association_table, back_populates='students')class Teacher(db.Model):...students = db.relationship('Student', secondary=association_table, back_populates='teachers')
5.6 更新数据库表
1、重新生成表
方法很简单,但缺点是会丢失原来的所有数据。
db.drop_all()
db.create_all()
2、使用Flask-Migrate迁移(p169)
可以保留数据库中原有的数据。自动生成的迁移命令不一定可靠,必要时检查一下。
flask db init # 创建迁移环境
flask db migrate # 生成迁移脚本
flask db upgrade # 应用迁移
flask db downgrade # 撤销一次迁移
5.7 数据库进阶
1、级联操作(p172)
在relationship方法可以配置cascade参数,所有可用值为save-update,merge,refresh-expire,expunge,delete。默认值为save-update,merge。
class Post(db.Model):...comments = db.relationship(..., cascade='save-update, merge, delete')
-
save-update:
db.session.add()将Post对象添加到数据库会话时,相关的Comment对象也会被添加到数据库会话。 -
delete:Post记录被删除时,相关的Comment记录也会被删除。
-
delete-orphan:Post与Comment记录解除关系操作时,相应的Comment记录会被删除。
-
all:包含除了
delete-orphan之外的所有可用值。
2、事件监听(p176)
在Flask中有请求回调函数,而SQLAlchemy也提供了listens_for()装饰器来注册事件回调函数。装饰器接受两个参数,target表示监听的对象,identifier表示被监听事件的类型。被注册的监听函数需要接收对应事件方法的所有参数。
疑惑:“事件方法”指什么?怎么知道它有哪些参数?
class Draft(db.Model):...edit_time = ...@db.event.listens_for(Draft.body, 'set', named=True)
def increment_edit_time(**kwargs):if kwargs['target'].edit_time is not None:kwargs['target'].edit_time += 1
设置named参数为True可以使用kwargs接收所有参数(不知道为啥)。kwargs中的target参数表示触发事件的模型类实例。
小结
SQLAlchemy入门教程:(p177)http://docs.sqlalchemy.org/en/latest/orm/tutorial.html
数据库这一章我看得有点拖拉,正值开学,可能需要好些天才能找回学习状态。大部分东西我还是之前都有所了解,因此看得比较流畅。在最近开发自己的玩具程序的过程中,数据库这一环节可给我制造了不少麻烦(特别是配环境),它在我眼里的黑盒程度又比较高,书中说到本章只是一个简单的介绍,不过暂时于我也够用了。
相关文章:
Flask狼书笔记 | 05_数据库
文章目录 5 数据库5.1 数据库的分类5.2 ORM5.3 使用Flask_SQLAlchemy5.4 数据库操作5.5 定义关系5.6 更新数据库表5.7 数据库进阶小结 5 数据库 这一章学习如何在Python中使用DBMS(数据库管理系统),来对数据库进行管理和操作。本书使用SQLit…...

HJ70 矩阵乘法计算量估算
Powered by:NEFU AB-IN Link 文章目录 HJ70 矩阵乘法计算量估算题意思路代码 HJ70 矩阵乘法计算量估算 题意 矩阵乘法的运算量与矩阵乘法的顺序强相关。 例如: A是一个5010的矩阵,B是1020的矩阵,C是205的矩阵 计算ABC有两种顺序:…...

Doris数据库使用记录
新建表 create table tonly_attendance(vin varchar(64),diggings_name varchar(256),area varchar(64),diggings_type varchar(256),work_time decimal(20,2),engine_run_time decimal(20,2),upload_time varchar(64))DUPLICATE KEY (vin)distributed by hash (vin)删除之…...

华为OD机试真题【篮球比赛】
1、题目描述 【篮球比赛】 一个有N个选手参加比赛,选手编号为1~N(3<N<100),有M(3<M<10)个评委对选手进行打分。 打分规则为每个评委对选手打分,最高分10分,最低分1分。…...
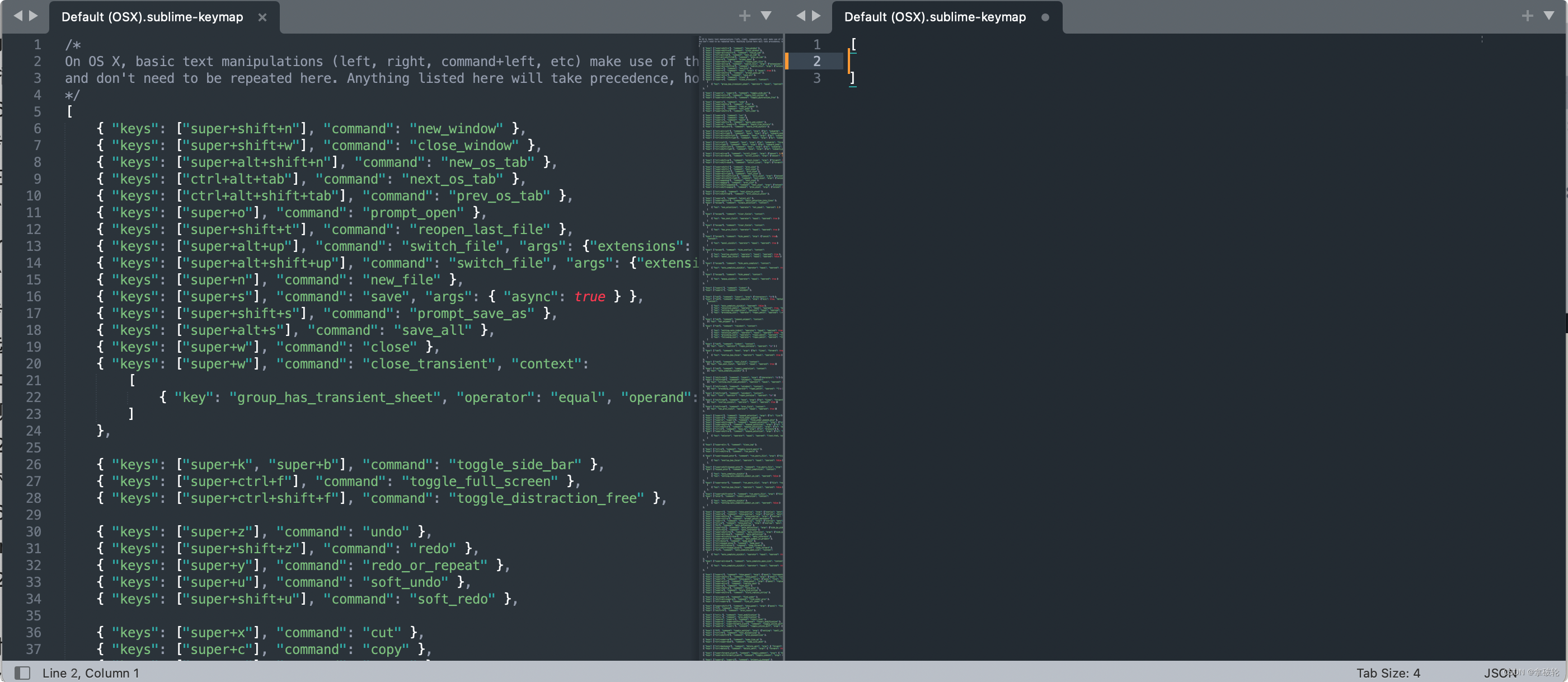
sublime text 格式化json快捷键配置
以 controlcommandj 为例。 打开Sublime Text,依次点击左上角菜单Sublime Text->Preferences->Key Bindings,出现以下文件: 左边的是Sublime Text默认的快捷键,不可编辑。右边是我们自定义快捷键的地方,在中括号…...

Spring Cloud 面试题总结
Spring Cloud和各子项目版本对应关系 Spring Cloud 是一个用于构建分布式系统的开发工具包,它基于Spring Boot提供了一组模块和功能,用于构建微服务架构中的分布式应用程序。Spring Cloud的不同子项目有各自的版本,下面是一些常见的Spring C…...

如何实现24/7客户服务自动化?
传统的客服制胜与否的法宝在于人,互联网时代,对于产品线广的大型企业来说:单靠人力,成本大且效率低,相对于产品相对单一的中小型企业来说:建设传统客服系统的成本难以承受,企业客户服务的转型已…...

2022年12月 C/C++(六级)真题解析#中国电子学会#全国青少年软件编程等级考试
C/C++编程(1~8级)全部真题・点这里 第1题:区间合并 给定 n 个闭区间 [ai; bi],其中i=1,2,…,n。任意两个相邻或相交的闭区间可以合并为一个闭区间。例如,[1;2] 和 [2;3] 可以合并为 [1;3],[1;3] 和 [2;4] 可以合并为 [1;4],但是[1;2] 和 [3;4] 不可以合并。 我们的任务是…...

【Spring Cloud系列】 雪花算法原理及实现
【Spring Cloud系列】 雪花算法原理及实现 文章目录 【Spring Cloud系列】 雪花算法原理及实现一、概述二、生成ID规则部分硬性要求三、ID号生成系统可用性要求四、解决分布式ID通用方案4.1 UUID4.2 数据库自增主键4.3 基于Redis生成全局id策略 五、SnowFlake(雪花算…...

Postgresql 阿里云部署排雷
启动服务bug: 根据你的输出,可以看到 PostgreSQL 服务启动失败,并且显示以下错误消息: pg_ctl: cannot be run as root Please log in (using, e.g., "su") as the (unprivileged) user that will own the server proc…...
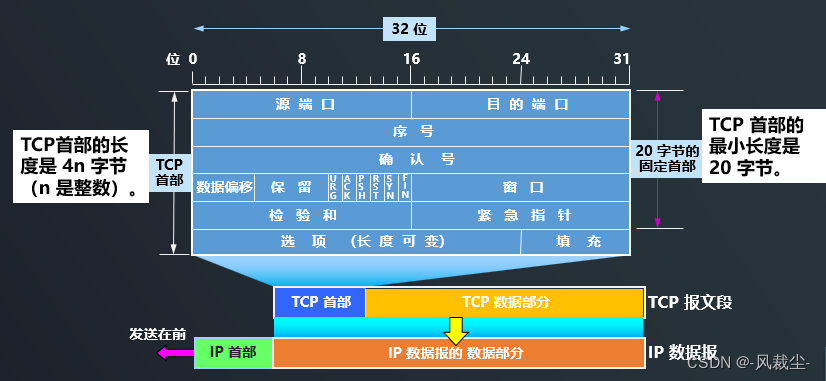
l8-d10 TCP协议是如何实现可靠传输的
一、TCP主要特点 TCP 是面向连接的运输层协议,在无连接的、不可靠的 IP 网络服务基础之上提供可靠交付的服务。为此,在 IP 的数据报服务基础之上,增加了保证可靠性的一系列措施。 TCP主要特点 1.TCP 是面向连接的运输层协议。 每一条 TCP 连…...

9月9日扒面经
堆和栈的区别? 分配方式:堆内存是由程序员手动分配和释放的,而栈内存是由编译器自动分配和释放的。内存管理:堆内存需要手动管理内存的分配和释放,程序员需要显式地调用malloc()或new来分配内存,并使用fre…...
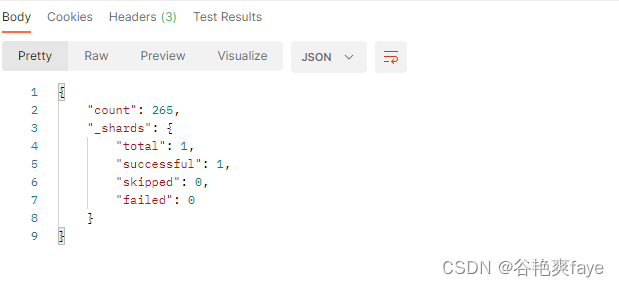
项目实战:ES的增加数据和查询数据
文章目录 背景在ES中增加数据新建索引删除索引 在ES中查询数据查询数据总数量 项目具体使用(实战)引入依赖方式一:使用配置类连接对应的es服务器创建配置类编写业务逻辑----根据关键字查询相关的聊天内容在ES中插入数据 总结提升 背景 最近需…...
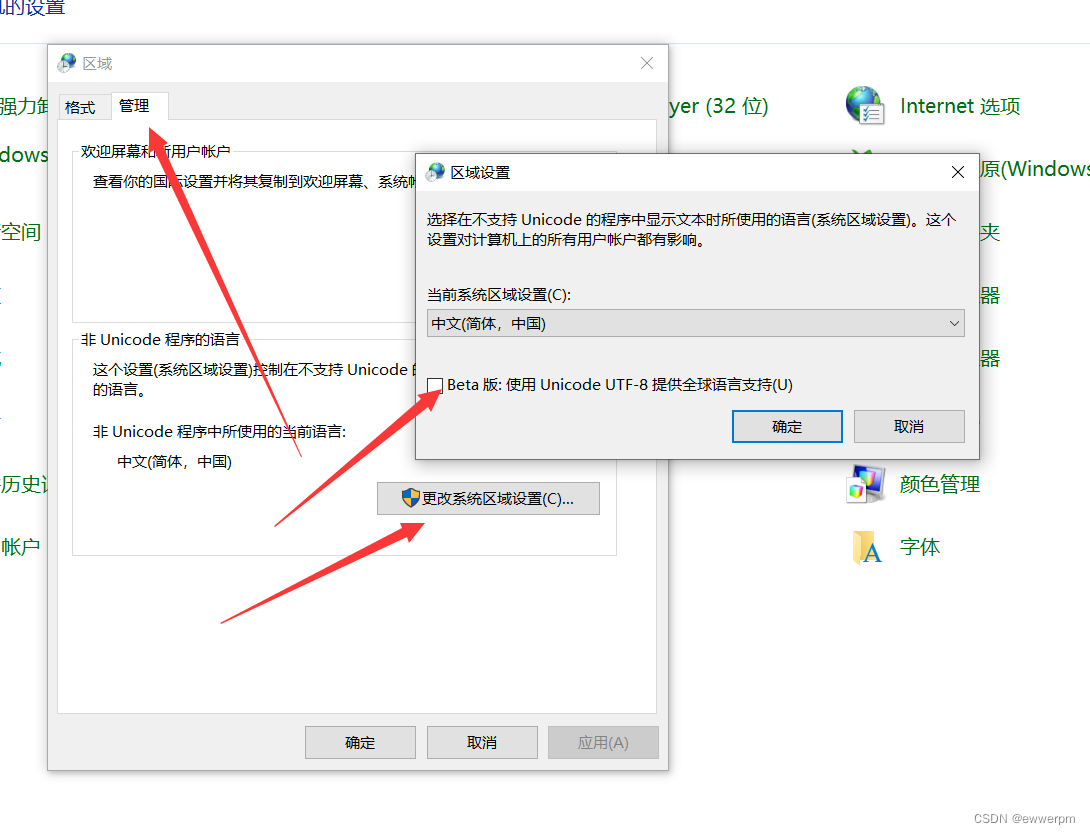
vs code调试rust乱码问题解决方案
在terminal中 用chcp 65001 修改一下字符集,就行了。有的博主推荐 修改 区域中的设置,这会引来很大的问题。千万不要修改如下设置:...
大数据课程K22——Spark的SparkSQL的API调用
文章作者邮箱:yugongshiye@sina.cn 地址:广东惠州 ▲ 本章节目的 ⚪ 掌握Spark的通过api使用SparkSQL; 一、通过api使用SparkSQL 1. 实现步骤 1. 打开scala IDE开发环境,创建一个scala工程。 2. 导入spark相关依赖jar包。 3. 创建包路径以object类。 4.…...

数据结构学习系列之顺序表的两种删除方式
方式1:在顺序表的末端删除所存储的数据元素,代码如下:示例代码: int delete_seq_list_1(list_t *seq_list){if(NULL seq_list){printf("入参为NULL\n");return -1;}if(0 seq_list->count){printf("顺序表为空…...

机器学习笔记之最优化理论与方法(七)无约束优化问题——常用求解方法(上)
机器学习笔记之最优化理论与方法——基于无约束优化问题的常用求解方法[上] 引言总体介绍回顾:线搜索下降算法收敛速度的衡量方式线性收敛范围高阶收敛范围 二次终止性朴素算法:坐标轴交替下降法最速下降法(梯度下降法)梯度下降法的特点 针对最速下降法缺…...
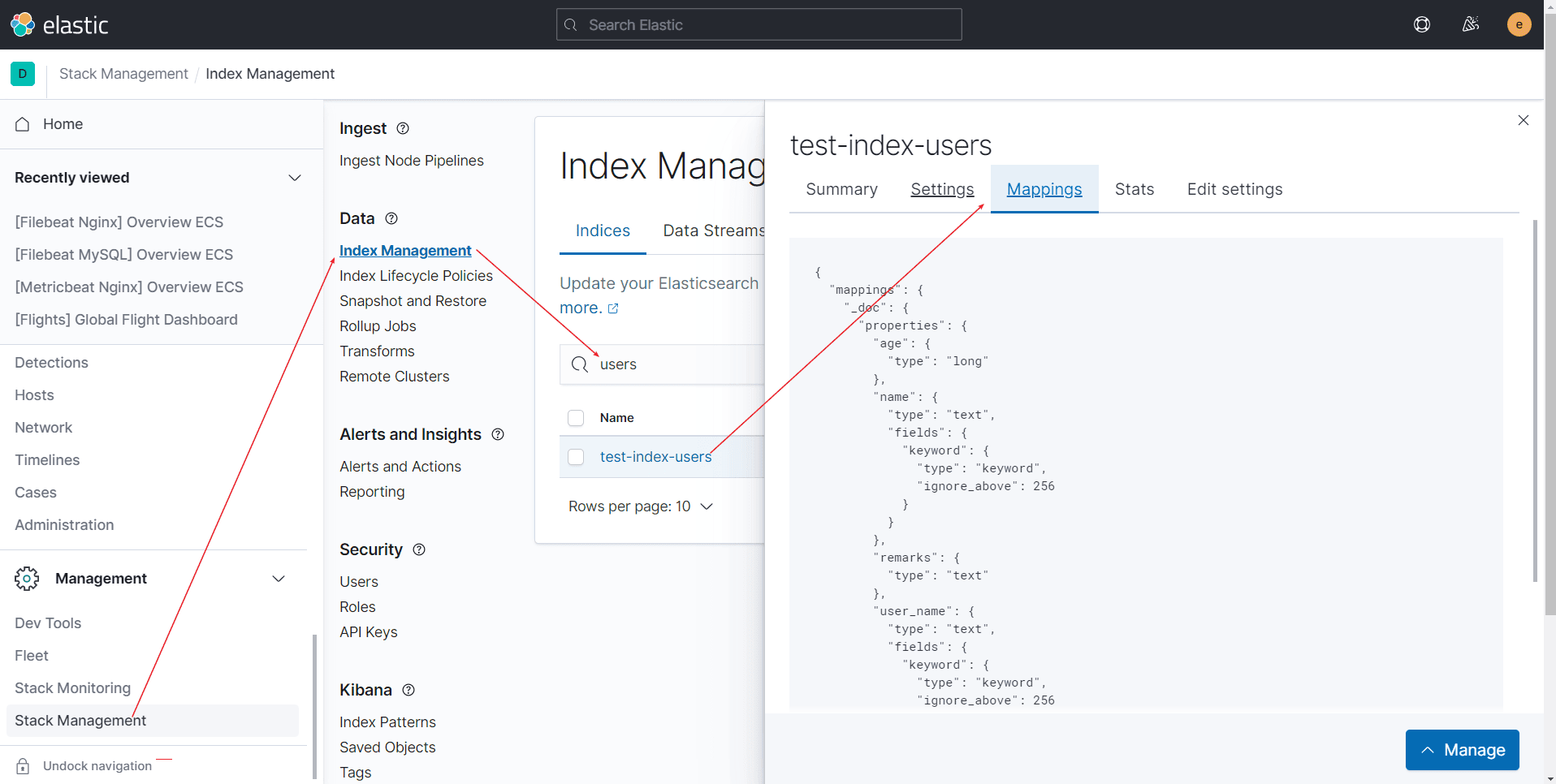
ES-索引管理
前言 数据类型 搜索引擎是对数据的检索,所以我们先从生活中的数据说起。我们生活中的数据总体分为两种: 结构化数据非结构化数据 结构化数据: 也称作行数据,是由二维表结构来逻辑表达和实现的数据,严格地遵循数…...

linux中常用shell脚本整理
linux常见shell脚本整理 备份日志 #!/bin/bash # 每日创建新的备份日志-根据日期备份 tar -czf log-date %Y%m%d.tar.gz /var/log # 通过crontab 每日定时启动 00 03 * * 5 /root/logbak.sh 监控内存和磁盘容量,小于给定值时报警 #!/bin/bash # 实…...

介绍PHP
PHP是一种流行的服务器端编程语言,用于开发Web应用程序。它是一种开源的编程语言,具有易学易用的语法和强大的功能。PHP支持在服务器上运行的动态网页和Web应用程序的快速开发。 PHP可以与HTML标记语言结合使用,从而能够生成动态的Web页面&a…...

CVPR 2025 MIMO: 支持视觉指代和像素grounding 的医学视觉语言模型
CVPR 2025 | MIMO:支持视觉指代和像素对齐的医学视觉语言模型 论文信息 标题:MIMO: A medical vision language model with visual referring multimodal input and pixel grounding multimodal output作者:Yanyuan Chen, Dexuan Xu, Yu Hu…...

MySQL 隔离级别:脏读、幻读及不可重复读的原理与示例
一、MySQL 隔离级别 MySQL 提供了四种隔离级别,用于控制事务之间的并发访问以及数据的可见性,不同隔离级别对脏读、幻读、不可重复读这几种并发数据问题有着不同的处理方式,具体如下: 隔离级别脏读不可重复读幻读性能特点及锁机制读未提交(READ UNCOMMITTED)允许出现允许…...

在HarmonyOS ArkTS ArkUI-X 5.0及以上版本中,手势开发全攻略:
在 HarmonyOS 应用开发中,手势交互是连接用户与设备的核心纽带。ArkTS 框架提供了丰富的手势处理能力,既支持点击、长按、拖拽等基础单一手势的精细控制,也能通过多种绑定策略解决父子组件的手势竞争问题。本文将结合官方开发文档,…...

TRS收益互换:跨境资本流动的金融创新工具与系统化解决方案
一、TRS收益互换的本质与业务逻辑 (一)概念解析 TRS(Total Return Swap)收益互换是一种金融衍生工具,指交易双方约定在未来一定期限内,基于特定资产或指数的表现进行现金流交换的协议。其核心特征包括&am…...
)
【RockeMQ】第2节|RocketMQ快速实战以及核⼼概念详解(二)
升级Dledger高可用集群 一、主从架构的不足与Dledger的定位 主从架构缺陷 数据备份依赖Slave节点,但无自动故障转移能力,Master宕机后需人工切换,期间消息可能无法读取。Slave仅存储数据,无法主动升级为Master响应请求ÿ…...

智能仓储的未来:自动化、AI与数据分析如何重塑物流中心
当仓库学会“思考”,物流的终极形态正在诞生 想象这样的场景: 凌晨3点,某物流中心灯火通明却空无一人。AGV机器人集群根据实时订单动态规划路径;AI视觉系统在0.1秒内扫描包裹信息;数字孪生平台正模拟次日峰值流量压力…...

HarmonyOS运动开发:如何用mpchart绘制运动配速图表
##鸿蒙核心技术##运动开发##Sensor Service Kit(传感器服务)# 前言 在运动类应用中,运动数据的可视化是提升用户体验的重要环节。通过直观的图表展示运动过程中的关键数据,如配速、距离、卡路里消耗等,用户可以更清晰…...

从 GreenPlum 到镜舟数据库:杭银消费金融湖仓一体转型实践
作者:吴岐诗,杭银消费金融大数据应用开发工程师 本文整理自杭银消费金融大数据应用开发工程师在StarRocks Summit Asia 2024的分享 引言:融合数据湖与数仓的创新之路 在数字金融时代,数据已成为金融机构的核心竞争力。杭银消费金…...

华为OD机试-最短木板长度-二分法(A卷,100分)
此题是一个最大化最小值的典型例题, 因为搜索范围是有界的,上界最大木板长度补充的全部木料长度,下界最小木板长度; 即left0,right10^6; 我们可以设置一个候选值x(mid),将木板的长度全部都补充到x,如果成功…...

Python 训练营打卡 Day 47
注意力热力图可视化 在day 46代码的基础上,对比不同卷积层热力图可视化的结果 import torch import torch.nn as nn import torch.optim as optim from torchvision import datasets, transforms from torch.utils.data import DataLoader import matplotlib.pypl…...