用python实现基本数据结构【03/4】

说明
如果需要用到这些知识却没有掌握,则会让人感到沮丧,也可能导致面试被拒。无论是花几天时间“突击”,还是利用零碎的时间持续学习,在数据结构上下点功夫都是值得的。那么Python 中有哪些数据结构呢?列表、字典、集合,还有……栈?Python 有栈吗?本系列文章将给出详细拼图。
9章:Advanced Linked Lists
之前曾经介绍过单链表,一个链表节点只有data和next字段,本章介绍高级的链表。
Doubly Linked List,双链表,每个节点多了个prev指向前一个节点。双链表可以用来编写文本编辑器的buffer。
class DListNode:def __init__(self, data):self.data = dataself.prev = Noneself.next = Nonedef revTraversa(tail):curNode = tailwhile cruNode is not None:print(curNode.data)curNode = curNode.prevdef search_sorted_doubly_linked_list(head, tail, probe, target):""" probing technique探查法,改进直接遍历,不过最坏时间复杂度仍是O(n)searching a sorted doubly linked list using the probing techniqueArgs:head (DListNode obj)tail (DListNode obj)probe (DListNode or None)target (DListNode.data): data to search"""if head is None: # make sure list is not emptyreturn Falseif probe is None: # if probe is null, initialize it to first nodeprobe = head# if the target comes before the probe node, we traverse backward, otherwise# traverse forwardif target < probe.data:while probe is not None and target <= probe.data:if target == probe.dta:return Trueelse:probe = probe.prevelse:while probe is not None and target >= probe.data:if target == probe.data:return Trueelse:probe = probe.nextreturn Falsedef insert_node_into_ordered_doubly_linekd_list(value):""" 最好画个图看,链表操作很容易绕晕,注意赋值顺序"""newnode = DListNode(value)if head is None: # empty listhead = newnodetail = headelif value < head.data: # insert before headnewnode.next = headhead.prev = newnodehead = newnodeelif value > tail.data: # insert after tailnewnode.prev = tailtail.next = newnodetail = newnodeelse: # insert into middlenode = headwhile node is not None and node.data < value:node = node.nextnewnode.next = nodenewnode.prev = node.prevnode.prev.next = newnodenode.prev = newnode
循环链表
def travrseCircularList(listRef):curNode = listRefdone = listRef is Nonewhile not None:curNode = curNode.nextprint(curNode.data)done = curNode is listRef # 回到遍历起始点def searchCircularList(listRef, target):curNode = listRefdone = listRef is Nonewhile not done:curNode = curNode.nextif curNode.data == target:return Trueelse:done = curNode is listRef or curNode.data > targetreturn Falsedef add_newnode_into_ordered_circular_linked_list(listRef, value):""" 插入并维持顺序1.插入空链表;2.插入头部;3.插入尾部;4.按顺序插入中间"""newnode = ListNode(value)if listRef is None: # empty listlistRef = newnodenewnode.next = newnodeelif value < listRef.next.data: # insert in frontnewnode.next = listRef.nextlistRef.next = newnodeelif value > listRef.data: # insert in backnewnode.next = listRef.nextlistRef.next = newnodelistRef = newnodeelse: # insert in the middlepreNode = NonecurNode = listRefdone = listRef is Nonewhile not done:preNode = curNodepreNode = curNode.nextdone = curNode is listRef or curNode.data > valuenewnode.next = curNodepreNode.next = newnode
利用循环双端链表我们可以实现一个经典的缓存失效算法,lru:
# -*- coding: utf-8 -*-class Node(object):def __init__(self, prev=None, next=None, key=None, value=None):self.prev, self.next, self.key, self.value = prev, next, key, valueclass CircularDoubleLinkedList(object):def __init__(self):node = Node()node.prev, node.next = node, nodeself.rootnode = nodedef headnode(self):return self.rootnode.nextdef tailnode(self):return self.rootnode.prevdef remove(self, node):if node is self.rootnode:returnelse:node.prev.next = node.nextnode.next.prev = node.prevdef append(self, node):tailnode = self.tailnode()tailnode.next = nodenode.next = self.rootnodeself.rootnode.prev = nodeclass LRUCache(object):def __init__(self, maxsize=16):self.maxsize = maxsizeself.cache = {}self.access = CircularDoubleLinkedList()self.isfull = len(self.cache) >= self.maxsizedef __call__(self, func):def wrapper(n):cachenode = self.cache.get(n)if cachenode is not None: # hitself.access.remove(cachenode)self.access.append(cachenode)return cachenode.valueelse: # missvalue = func(n)if not self.isfull:tailnode = self.access.tailnode()newnode = Node(tailnode, self.access.rootnode, n, value)self.access.append(newnode)self.cache[n] = newnodeself.isfull = len(self.cache) >= self.maxsizereturn valueelse: # fulllru_node = self.access.headnode()del self.cache[lru_node.key]self.access.remove(lru_node)tailnode = self.access.tailnode()newnode = Node(tailnode, self.access.rootnode, n, value)self.access.append(newnode)self.cache[n] = newnodereturn valuereturn wrapper@LRUCache()
def fib(n):if n <= 2:return 1else:return fib(n - 1) + fib(n - 2)for i in range(1, 35):print(fib(i))
10章:Recursion
Recursion is a process for solving problems by subdividing a larger problem into smaller cases of the problem itself and then solving the smaller, more trivial parts.
递归函数:调用自己的函数
# 递归函数:调用自己的函数,看一个最简单的递归函数,倒序打印一个数 def printRev(n):if n > 0:print(n)printRev(n-1)printRev(3) # 从10输出到1# 稍微改一下,print放在最后就得到了正序打印的函数 def printInOrder(n):if n > 0:printInOrder(n-1)print(n) # 之所以最小的先打印是因为函数一直递归到n==1时候的最深栈,此时不再# 递归,开始执行print语句,这时候n==1,之后每跳出一层栈,打印更大的值printInOrder(3) # 正序输出
Properties of Recursion: 使用stack解决的问题都能用递归解决
- A recursive solution must contain a base case; 递归出口,代表最小子问题(n == 0退出打印)
- A recursive solution must contain a recursive case; 可以分解的子问题
- A recursive solution must make progress toward the base case. 递减n使得n像递归出口靠近
Tail Recursion: occurs when a function includes a single recursive call as the last statement of the function. In this case, a stack is not needed to store values to te used upon the return of the recursive call and thus a solution can be implemented using a iterative loop instead.
# Recursive Binary Searchdef recBinarySearch(target, theSeq, first, last):# 你可以写写单元测试来验证这个函数的正确性if first > last: # 递归出口1return Falseelse:mid = (first + last) // 2if theSeq[mid] == target:return True # 递归出口2elif theSeq[mid] > target:return recBinarySearch(target, theSeq, first, mid - 1)else:return recBinarySearch(target, theSeq, mid + 1, last)
11章:Hash Tables
基于比较的搜索(线性搜索,有序数组的二分搜索)最好的时间复杂度只能达到O(logn),利用hash可以实现O(1)查找,python内置dict的实现方式就是hash,你会发现dict的key必须要是实现了 __hash__ 和 __eq__ 方法的。
Hashing: hashing is the process of mapping a search a key to a limited range of array indeices with the goal of providing direct access to the keys.
hash方法有个hash函数用来给key计算一个hash值,作为数组下标,放到该下标对应的槽中。当不同key根据hash函数计算得到的下标相同时,就出现了冲突。解决冲突有很多方式,比如让每个槽成为链表,每次冲突以后放到该槽链表的尾部,但是查询时间就会退化,不再是O(1)。还有一种探查方式,当key的槽冲突时候,就会根据一种计算方式去寻找下一个空的槽存放,探查方式有线性探查,二次方探查法等,cpython解释器使用的是二次方探查法。还有一个问题就是当python使用的槽数量大于预分配的2/3时候,会重新分配内存并拷贝以前的数据,所以有时候dict的add操作代价还是比较高的,牺牲空间但是可以始终保证O(1)的查询效率。如果有大量的数据,建议还是使用bloomfilter或者redis提供的HyperLogLog。
如果你感兴趣,可以看看这篇文章,介绍c解释器如何实现的python dict对象:Python dictionary implementation。我们使用Python来实现一个类似的hash结构。
import ctypesclass Array: # 第二章曾经定义过的ADT,这里当做HashMap的槽数组使用def __init__(self, size):assert size > 0, 'array size must be > 0'self._size = sizePyArrayType = ctypes.py_object * sizeself._elements = PyArrayType()self.clear(None)def __len__(self):return self._sizedef __getitem__(self, index):assert index >= 0 and index < len(self), 'out of range'return self._elements[index]def __setitem__(self, index, value):assert index >= 0 and index < len(self), 'out of range'self._elements[index] = valuedef clear(self, value):""" 设置每个元素为value """for i in range(len(self)):self._elements[i] = valuedef __iter__(self):return _ArrayIterator(self._elements)class _ArrayIterator:def __init__(self, items):self._items = itemsself._idx = 0def __iter__(self):return selfdef __next__(self):if self._idx < len(self._items):val = self._items[self._idx]self._idx += 1return valelse:raise StopIterationclass HashMap:""" HashMap ADT实现,类似于python内置的dict一个槽有三种状态:1.从未使用 HashMap.UNUSED。此槽没有被使用和冲突过,查找时只要找到UNUSEd就不用再继续探查了2.使用过但是remove了,此时是 HashMap.EMPTY,该探查点后边的元素扔可能是有key3.槽正在使用 _MapEntry节点"""class _MapEntry: # 槽里存储的数据def __init__(self, key, value):self.key = keyself.value = valueUNUSED = None # 没被使用过的槽,作为该类变量的一个单例,下边都是is 判断EMPTY = _MapEntry(None, None) # 使用过但是被删除的槽def __init__(self):self._table = Array(7) # 初始化7个槽self._count = 0# 超过2/3空间被使用就重新分配,load factor = 2/3self._maxCount = len(self._table) - len(self._table) // 3def __len__(self):return self._countdef __contains__(self, key):slot = self._findSlot(key, False)return slot is not Nonedef add(self, key, value):if key in self: # 覆盖原有valueslot = self._findSlot(key, False)self._table[slot].value = valuereturn Falseelse:slot = self._findSlot(key, True)self._table[slot] = HashMap._MapEntry(key, value)self._count += 1if self._count == self._maxCount: # 超过2/3使用就rehashself._rehash()return Truedef valueOf(self, key):slot = self._findSlot(key, False)assert slot is not None, 'Invalid map key'return self._table[slot].valuedef remove(self, key):""" remove操作把槽置为EMPTY"""assert key in self, 'Key error %s' % keyslot = self._findSlot(key, forInsert=False)value = self._table[slot].valueself._count -= 1self._table[slot] = HashMap.EMPTYreturn valuedef __iter__(self):return _HashMapIteraotr(self._table)def _slot_can_insert(self, slot):return (self._table[slot] is HashMap.EMPTY orself._table[slot] is HashMap.UNUSED)def _findSlot(self, key, forInsert=False):""" 注意原书有错误,代码根本不能运行,这里我自己改写的Args:forInsert (bool): if the search is for an insertionReturns:slot or None"""slot = self._hash1(key)step = self._hash2(key)_len = len(self._table)if not forInsert: # 查找是否存在keywhile self._table[slot] is not HashMap.UNUSED:# 如果一个槽是UNUSED,直接跳出if self._table[slot] is HashMap.EMPTY:slot = (slot + step) % _lencontinueelif self._table[slot].key == key:return slotslot = (slot + step) % _lenreturn Noneelse: # 为了插入keywhile not self._slot_can_insert(slot): # 循环直到找到一个可以插入的槽slot = (slot + step) % _lenreturn slotdef _rehash(self): # 当前使用槽数量大于2/3时候重新创建新的tableorigTable = self._tablenewSize = len(self._table) * 2 + 1 # 原来的2*n+1倍self._table = Array(newSize)self._count = 0self._maxCount = newSize - newSize // 3# 将原来的key value添加到新的tablefor entry in origTable:if entry is not HashMap.UNUSED and entry is not HashMap.EMPTY:slot = self._findSlot(entry.key, True)self._table[slot] = entryself._count += 1def _hash1(self, key):""" 计算key的hash值"""return abs(hash(key)) % len(self._table)def _hash2(self, key):""" key冲突时候用来计算新槽的位置"""return 1 + abs(hash(key)) % (len(self._table)-2)class _HashMapIteraotr:def __init__(self, array):self._array = arrayself._idx = 0def __iter__(self):return selfdef __next__(self):if self._idx < len(self._array):if self._array[self._idx] is not None and self._array[self._idx].key is not None:key = self._array[self._idx].keyself._idx += 1return keyelse:self._idx += 1else:raise StopIterationdef print_h(h):for idx, i in enumerate(h):print(idx, i)print('\n')def test_HashMap():""" 一些简单的单元测试,不过测试用例覆盖不是很全面 """h = HashMap()assert len(h) == 0h.add('a', 'a')assert h.valueOf('a') == 'a'assert len(h) == 1a_v = h.remove('a')assert a_v == 'a'assert len(h) == 0h.add('a', 'a')h.add('b', 'b')assert len(h) == 2assert h.valueOf('b') == 'b'b_v = h.remove('b')assert b_v == 'b'assert len(h) == 1h.remove('a')assert len(h) == 0n = 10for i in range(n):h.add(str(i), i)assert len(h) == nprint_h(h)for i in range(n):assert str(i) in hfor i in range(n):h.remove(str(i))assert len(h) == 0
12章: Advanced Sorting
第5章介绍了基本的排序算法,本章介绍高级排序算法。
归并排序(mergesort): 分治法
def merge_sorted_list(listA, listB):""" 归并两个有序数组,O(max(m, n)) ,m和n是数组长度"""print('merge left right list', listA, listB, end='')new_list = list()a = b = 0while a < len(listA) and b < len(listB):if listA[a] < listB[b]:new_list.append(listA[a])a += 1else:new_list.append(listB[b])b += 1while a < len(listA):new_list.append(listA[a])a += 1while b < len(listB):new_list.append(listB[b])b += 1print(' ->', new_list)return new_listdef mergesort(theList):""" O(nlogn),log层调用,每层n次操作mergesort: divided and conquer 分治1. 把原数组分解成越来越小的子数组2. 合并子数组来创建一个有序数组"""print(theList) # 我把关键步骤打出来了,你可以运行下看看整个过程if len(theList) <= 1: # 递归出口return theListelse:mid = len(theList) // 2# 递归分解左右两边数组left_half = mergesort(theList[:mid])right_half = mergesort(theList[mid:])# 合并两边的有序子数组newList = merge_sorted_list(left_half, right_half)return newList""" 这是我调用一次打出来的排序过程
[10, 9, 8, 7, 6, 5, 4, 3, 2, 1]
[10, 9, 8, 7, 6]
[10, 9]
[10]
[9]
merge left right list [10] [9] -> [9, 10]
[8, 7, 6]
[8]
[7, 6]
[7]
[6]
merge left right list [7] [6] -> [6, 7]
merge left right list [8] [6, 7] -> [6, 7, 8]
merge left right list [9, 10] [6, 7, 8] -> [6, 7, 8, 9, 10]
[5, 4, 3, 2, 1]
[5, 4]
[5]
[4]
merge left right list [5] [4] -> [4, 5]
[3, 2, 1]
[3]
[2, 1]
[2]
[1]
merge left right list [2] [1] -> [1, 2]
merge left right list [3] [1, 2] -> [1, 2, 3]
merge left right list [4, 5] [1, 2, 3] -> [1, 2, 3, 4, 5]
"""
快速排序
def quicksort(theSeq, first, last): # average: O(nlog(n))"""quicksort :也是分而治之,但是和归并排序不同的是,采用选定主元(pivot)而不是从中间进行数组划分1. 第一步选定pivot用来划分数组,pivot左边元素都比它小,右边元素都大于等于它2. 对划分的左右两边数组递归,直到递归出口(数组元素数目小于2)3. 对pivot和左右划分的数组合并成一个有序数组"""if first < last:pos = partitionSeq(theSeq, first, last)# 对划分的子数组递归操作quicksort(theSeq, first, pos - 1)quicksort(theSeq, pos + 1, last)def partitionSeq(theSeq, first, last):""" 快排中的划分操作,把比pivot小的挪到左边,比pivot大的挪到右边"""pivot = theSeq[first]print('before partitionSeq', theSeq)left = first + 1right = lastwhile True:# 找到第一个比pivot大的while left <= right and theSeq[left] < pivot:left += 1# 从右边开始找到比pivot小的while right >= left and theSeq[right] >= pivot:right -= 1if right < left:breakelse:theSeq[left], theSeq[right] = theSeq[right], theSeq[left]# 把pivot放到合适的位置theSeq[first], theSeq[right] = theSeq[right], theSeq[first]print('after partitionSeq {}: {}\t'.format(theSeq, pivot))return right # 返回pivot的位置def test_partitionSeq():l = [0,1,2,3,4]assert partitionSeq(l, 0, len(l)-1) == 0l = [4,3,2,1,0]assert partitionSeq(l, 0, len(l)-1) == 4l = [2,3,0,1,4]assert partitionSeq(l, 0, len(l)-1) == 2test_partitionSeq()def test_quicksort():def _is_sorted(seq):for i in range(len(seq)-1):if seq[i] > seq[i+1]:return Falsereturn Truefrom random import randintfor i in range(100):_len = randint(1, 100)to_sort = []for i in range(_len):to_sort.append(randint(0, 100))quicksort(to_sort, 0, len(to_sort)-1) # 注意这里用了原地排序,直接更改了数组print(to_sort)assert _is_sorted(to_sort)test_quicksort()
利用快排中的partitionSeq操作,我们还能实现另一个算法,nth_element,快速查找一个无序数组中的第k大元素
def nth_element(seq, beg, end, k):if beg == end:return seq[beg]pivot_index = partitionSeq(seq, beg, end)if pivot_index == k:return seq[k]elif pivot_index > k:return nth_element(seq, beg, pivot_index-1, k)else:return nth_element(seq, pivot_index+1, end, k)def test_nth_element():from random import shufflen = 10l = list(range(n))shuffle(l)print(l)for i in range(len(l)):assert nth_element(l, 0, len(l)-1, i) == itest_nth_element()
相关文章:
用python实现基本数据结构【03/4】
说明 如果需要用到这些知识却没有掌握,则会让人感到沮丧,也可能导致面试被拒。无论是花几天时间“突击”,还是利用零碎的时间持续学习,在数据结构上下点功夫都是值得的。那么Python 中有哪些数据结构呢?列表、字典、集…...

软件测试面试题汇总
测试技术面试题 软件测试面试时一份好简历的重要性 1、什么是兼容性测试?兼容性测试侧重哪些方面? 5 2、我现在有个程序,发现在Windows上运行得很慢,怎么判别是程序存在问题还是软硬件系统存在问题? 5 3、测试的策略…...
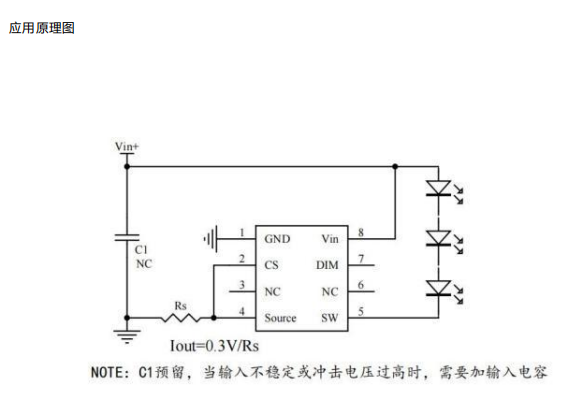
AP5101C 高压线性恒流IC 宽电压6-100V LED汽车大灯照明 台灯LED矿灯 指示灯电源驱动
产品描述 AP5101C 是一款高压线性 LED 恒流芯片 , 外围简单 、 内置功率管 , 适用于6- 100V 输入的高精度降压 LED 恒流驱动芯片。电流2.0A。AP5101C 可实现内置MOS 做 2.0A,外置 MOS 可做 3.0A 的。AP5101C 内置温度保护功能 ,温度保护点为…...
<模拟>)
【大数问题】字符串相减(大数相减)<模拟>
类似 【力扣】415. 字符串相加(大数相加),实现大数相减。 题解 模拟相减的过程,先一直使大数减小数,记录借位,最后再判断是否加负号。(中间需要删除前导0,例如10001-1000000001&am…...

easycode生成代码模板配置
实体: ##引入宏定义 $!define##使用宏定义设置回调(保存位置与文件后缀)$!autoImport import io.swagger.annotations.ApiModel; import io.swagger.annotations.ApiModelProperty; import lombok.Data; import lombok.NoArgsConstructor; i…...
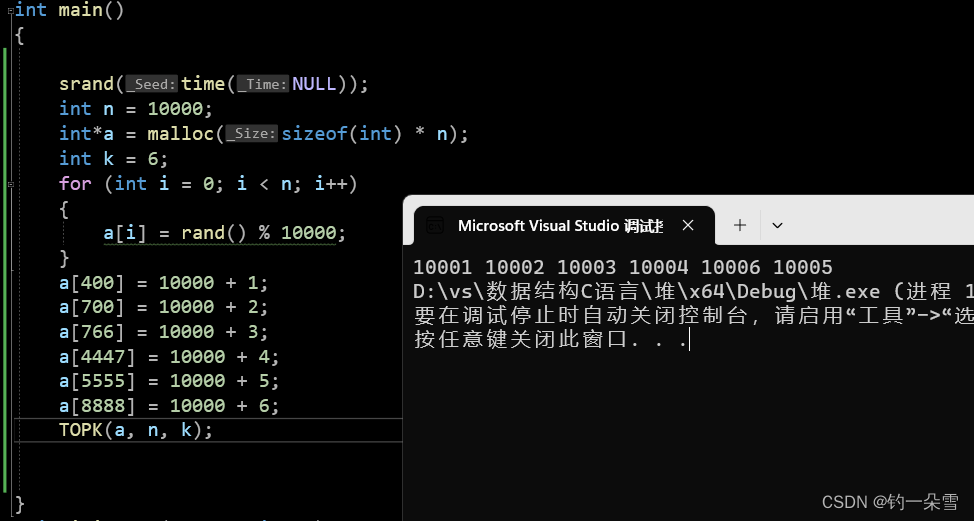
【数据结构】堆排序和Top-k问题
【数据结构】堆 堆排序 如果只是将待排数组建立一个大堆或者小堆是无法得到一个升序或者降序的数组,因为对与一个堆,我们没法知道同一层的大小关系。 但是,如果建立了一个大堆,那么堆顶元素一定是这个数组中最大的,…...

经典的生产者和消费者模型问题
典型的生产者-消费者问题,可以使用 Java 中的 java.util.concurrent 包提供的 BlockingQueue 来实现。BlockingQueue 是一个线程安全的队列,它可以处理这种生产者-消费者的场景。以下是一个示例代码: import java.util.concurrent.ArrayBlockingQueue; import java.util.co…...

Java基础:代理
这里写目录标题 什么是代理1.静态代理(委托类、代理类):使用步骤:示例优缺点 2.动态代理(委托类、中介类)2.1 JDK动态代理使用:中介类:示例1:示例2: 2.2 CGLi…...

每日一学——防火墙2
防火墙是一种网络安全设备,用于保护计算机网络免受未经授权的访问、攻击和恶意行为的影响。以下是一些防火墙的基本概念: 防火墙规则:防火墙会根据预先设置的规则来决定允许或拒绝特定的网络流量。这些规则可以指定源 IP 地址、目标 IP 地址、…...
Web学习笔记-React(组合Components)
笔记内容转载自 AcWing 的 Web 应用课讲义,课程链接:AcWing Web 应用课。 CONTENTS 1. 创建父组件2. 从上往下传递数据3. 传递子节点4. 从下往上调用函数5. 兄弟组件间传递消息6. 无状态函数组件7. 组件的生命周期 本节内容是组件与组件之间的组合&#…...
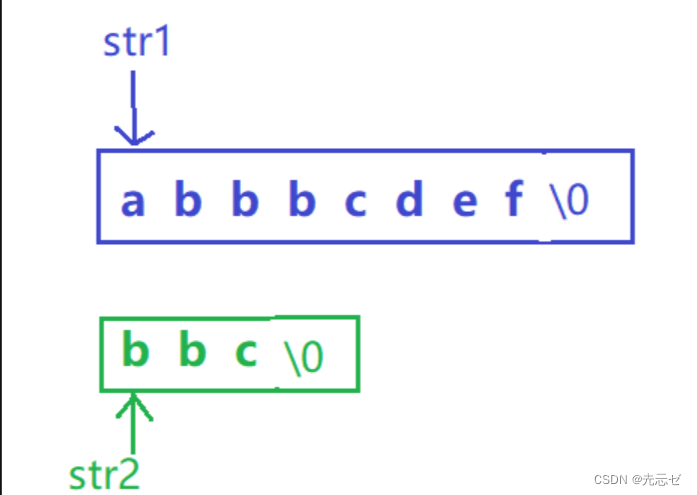
【strstr函数的介绍和模拟实现——超详细版】
strstr函数的介绍和模拟实现 strstr函数的介绍 资源来源于cplusplus网站 strstr函数声明: char *strstr( const char *str1, const char *str2 ); 它的作用其实就是: 在字符串str1中查找是否含有字符串str2,如果存在,返回str2在…...
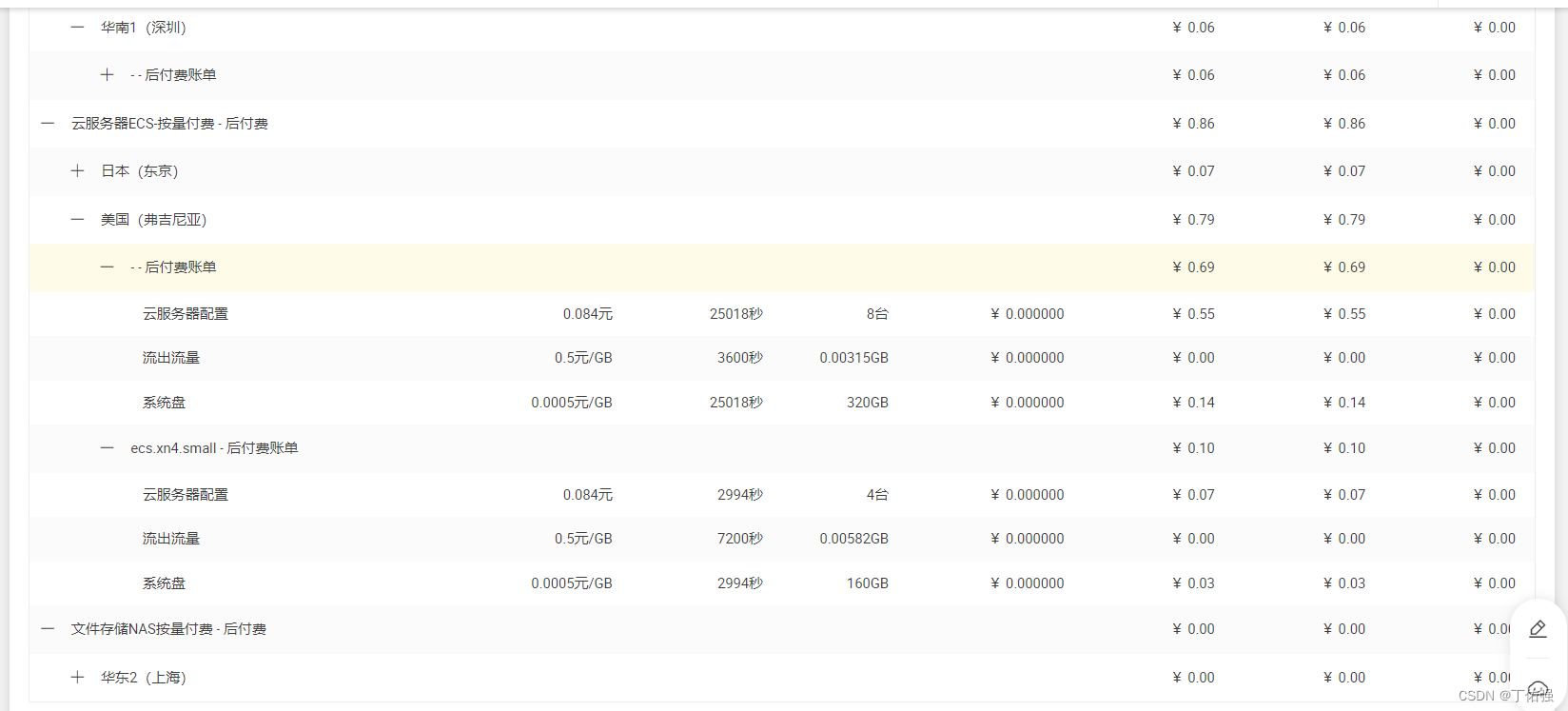
【Terraform】Terraform自动创建云服务器脚本
Terraform 是由 HashiCorp 创建的开源“基础架构即代码”工具 (IaC) 使用HCL(配置语言)描述云平台基础设施(这里教你使用低级基础设施:交换机、云服务器、VPC、带宽) Terraform提供者…...
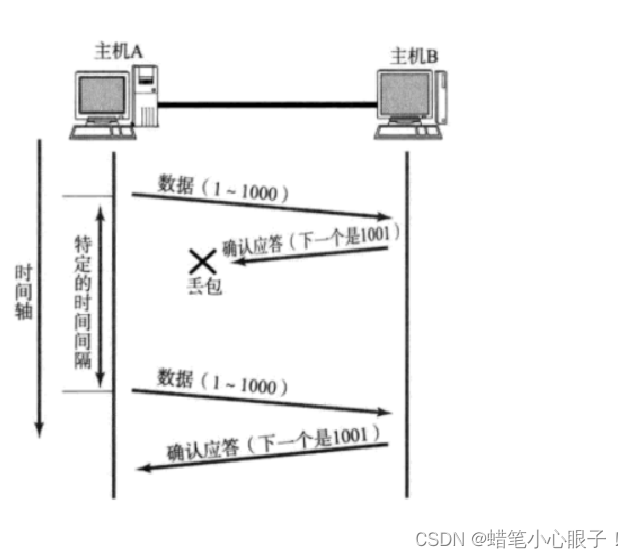
TCP机制之确认应答及超时重传
TCP因为其可靠传输的特性被广泛使用,这篇博客将详细介绍一下TCP协议是如何保证它的可靠性的呢?这得主要依赖于其确认应答及超时重传机制,同时三次握手四次挥手也起到了少部分不作用,但是主要还是由确认应答和超时重传来决定的;注意:这里的可靠传输并不是说100%能把数据发送给接…...
 过程记录)
Openharmony3.2 源码编译(ubuntu 22.04) 过程记录
OS: ubuntu 22.04 x64 1. 下载源码 1.1 安装码云repo工具 sudo apt install python3-pip git-lfsmkdir ~/bin curl https://gitee.com/oschina/repo/raw/fork_flow/repo-py3 -o ~/bin/repo chmod ax ~/bin/repo pip3 install -i https://repo.huaweicloud.com/repository/p…...

PostgreSQL 数据库使用 psql 导入 SQL
最近我们有一个 SQL 需要导入到 PostgreSQL ,但数据格式使用的是用: -- -- TOC entry 7877 (class 0 OID 21961) -- Dependencies: 904 -- Data for Name: upload_references; Type: TABLE DATA; Schema: public; Owner: - --COPY public.upload_refere…...
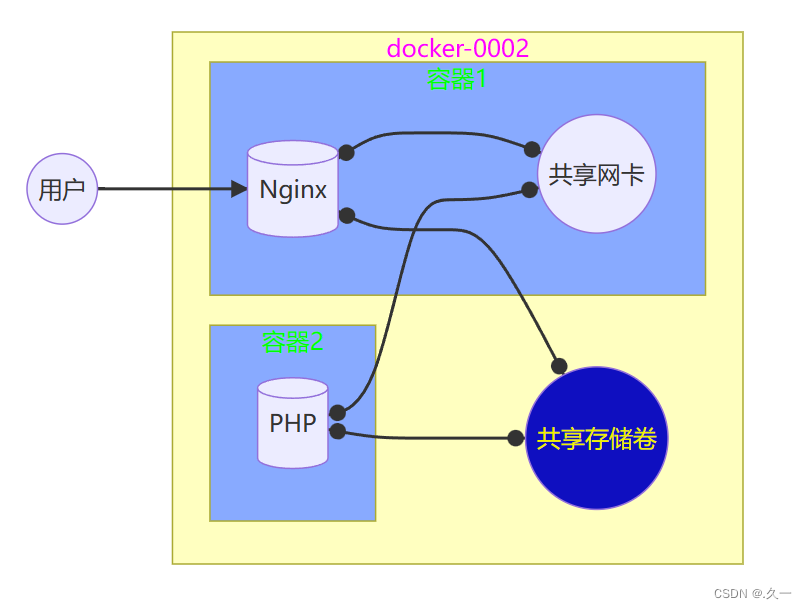
容器编排学习(三)端口映射与Harber镜像仓库介绍
一 对外发布服务(端口映射) 1 概述 新创建容器的IP 地址是随机的 容器在重启后每次 IP 都会发生变化 容器服务只有宿主机才能访问 如何才能使用容器对外提供稳定的服务? 容器端口可以与宿主机的端口进行映射绑定 从而把宿主机变成对应的服务&a…...
Day_13 > 指针进阶(2)
目录 1.函数指针数组 2.指向函数指针数组的指针 3.回调函数 qsort()函数 代码示例 void* 4.结束 今天我们在进阶指针的基础上,学习进阶指针的第二部分 1.函数指针数组 首先我们回顾一下指针数组 char* arr[5]://字符指针数组 - 数组 - 存放的是字符指针 in…...

对Transformer中的Attention(注意力机制)的一点点探索
摘要:本文试图对 Transformer 中的 Attention 机制进行一点点探索。并就 6 个问题深入展开。 ✅ NLP 研 1 选手的学习笔记 简介:小王,NPU,2023级,计算机技术 研究方向:文本生成、摘要生成 文章目录 一、为啥…...

车内信息安全技术-安全技术栈-软件安全
操作系统 1.隔离技术 信息安全中的隔离技术通常指的是将不同安全级别的信息或数据隔离开来,以保护敏感信息不受未授权的访问或泄露。在操作系统中,常见的隔离技术包括:虚拟化技术:通过虚拟化软件,将物理计算机分割成多个独立的虚拟计算机,每个虚拟计算机都可以运行独立的…...

Redis常见命令
命令可以查看的文档 http://doc.redisfans.com/ https://redis.io/commands/ 官方文档(英文) http://www.redis.cn/commands.html 中文 https://redis.com.cn/commands.html 个人推荐这个 https://try.redis.io/ redis命令在线测试工具 https://githubfa…...
)
腾讯CodeBuddy.ai实战:5分钟用AI生成可部署的五子棋游戏(附房间系统源码)
腾讯CodeBuddy.ai实战:5分钟用AI生成可部署的五子棋游戏(附房间系统源码) 在快节奏的数字化时代,AI辅助开发正以前所未有的速度改变着编程工作流。本文将带您体验如何借助腾讯CodeBuddy.ai平台,仅用自然语言指令快速生…...

Python点云处理实战:5种降采样方法对比与Open3D代码详解
Python点云处理实战:5种降采样方法对比与Open3D代码详解 点云数据在三维重建、自动驾驶、工业检测等领域应用广泛,但原始点云往往包含数十万甚至上百万个点,直接处理会带来巨大的计算负担。本文将深入解析5种主流的点云降采样方法,…...

DS3232M高精度RTC芯片驱动开发与工业级时间同步实践
1. DS3232M高精度实时时钟芯片技术解析与嵌入式驱动开发实践1.1 芯片定位与工程价值DS3232M是Maxim Integrated(现属Analog Devices)推出的工业级IC接口实时时钟(RTC)芯片,其核心价值在于2 ppm温度补偿精度(…...

TwinCAT3 Modbus-TCP双端通信实战:从环境配置到寄存器操作
1. TwinCAT3与Modbus-TCP通信基础 工业自动化领域最让人头疼的就是设备间的通信问题。我刚开始接触TwinCAT3时,面对各种通信协议也是一头雾水。直到掌握了Modbus-TCP这个"万能翻译官",才发现原来不同设备之间的对话可以如此简单。Modbus-TCP就…...

三星电视变身游戏主机:Moonlight for Tizen终极串流指南
三星电视变身游戏主机:Moonlight for Tizen终极串流指南 【免费下载链接】moonlight-chrome-tizen A WASM port of Moonlight for Samsung Smart TVs running Tizen OS (5.5 and up) 项目地址: https://gitcode.com/gh_mirrors/mo/moonlight-chrome-tizen 将…...

基于Qwen3-ASR-0.6B的语音质检系统:客服场景落地
基于Qwen3-ASR-0.6B的语音质检系统:客服场景落地 客服中心每天产生海量通话录音,传统人工质检只能覆盖极小样本,大量问题被遗漏。现在,借助Qwen3-ASR-0.6B语音识别模型,我们可以构建高效的智能质检系统,实现…...

从原理到应用:寄存器二分频电路在FPGA设计中的5种实际场景
从原理到应用:寄存器二分频电路在FPGA设计中的5种实际场景 在FPGA开发中,时钟管理一直是工程师们需要面对的核心挑战之一。想象一下,当你需要在同一个设计中同时处理高速数据流和低速外设通信时,如何优雅地协调不同速度的时钟域&a…...

DeerFlow完整指南:Web UI与控制台双模式使用方法
DeerFlow完整指南:Web UI与控制台双模式使用方法 1. 认识你的深度研究助理:DeerFlow 如果你经常需要从网上搜集信息、整理报告,或者对某个话题进行深度研究,那么手动搜索、阅读、总结的过程一定让你感到耗时费力。今天ÿ…...

rl-agents项目实战:如何自定义你的强化学习环境与智能体配置文件?
RL-Agents项目实战:深度定制强化学习环境与智能体配置指南 引言 当你第一次成功运行rl-agents示例代码时,那种兴奋感可能还记忆犹新。但很快,你会面临一个更实际的挑战:如何将这个框架适配到自己的研究项目中?与大多数…...

PushedDisplay:轻量嵌入式OLED显示驱动库
1. PushedDisplay 库概述PushedDisplay 是一个轻量级、模块化、可裁剪的嵌入式显示驱动库,专为资源受限的 MCU 环境设计。其核心设计理念是“按需加载”(Pushed)——仅编译和链接项目实际使用的显示组件与通信协议适配层,彻底规避…...