【爬虫】8.1. 深度使用tesseract-OCR技术识别图形验证码
深度使用tesseract-OCR技术识别图形验证码
文章目录
- 深度使用tesseract-OCR技术识别图形验证码
- 1. OCR技术
- 2. 准备工作
- 3. 简单作用了解
- 3.1. 验证码图片爬取-screenshot_as_png
- 3.2. 识别测试-image_to_string
- 3.2.1. 正确识别
- 3.2.2. 错误识别
- 3.2.3. 灰度调节
- 3.3. 识别实战-使用image_to_string对象
- 4. pytesseract库介绍
- 5. image_to_string
- 6. image_to_boxes
- 7. image_to_data
- 8. 参考博客
前言:本片文章是基于我之前发的一篇文章《【爬虫】8.1. 使用OCR技术识别图形验证码》而写的,链接为:
【爬虫】8.1. 使用OCR技术识别图形验证码,前面这篇文章比较基础。入门了tesseract-OCR技术之后对它比较感兴趣,故继续深度学习以下。为了衔接比较好,故本篇文章前面讲到的会和前面一篇文章有一些重复。
突然发现一个问题,csdn的图片有水印…不管了,凑合看吧,但是代码运行就要自己找图片了
1. OCR技术
OCR,即Optical Character Recognition,中文叫做光学字符识别,是指使用电子设备(例如扫描仪和数码相机)检查打印再纸上的字符,通过检查暗、亮的模式确定字符形状,然后使用字符识别方法将形状转化位计算机文字。现在OCR技术已经广泛应用于生产活动中,如文档识别,证件识别,字幕识别,文档搜索等。当然用来识别本节所述的图形验证码也没有问题。
2. 准备工作
我用的库是pytesseract,有的人用的是tesserocr,其实两者感觉差别不大:
- 打开tesseract下载的网页 tesseract,下载最后一个(应该是)tesseract-ocr-w64-setup-v5.3.0.2.221214这个版本,接着就是安装,安装过程中自己记好自己安装在哪里!!!然后就是选择语言包,建议不要全选会下载很慢。
- 将你记下来的安装路径的整个文件地址给添加到环境变量中去。
- 接着python安装pytesseract,找到pytesseract.py文件,打开并找到tesseract_cmd这个变量(大约在30行左右)将里面的值修改为tesseract.exe文件的地址(这个文件在你一开始记下的文件地址里面,查找文件夹就找到了,不用进其他的文件夹,注意转义字符)。
- 搞定上述之后在cmd窗口运行tesseract --list-langs可以看到你下载的语言包。
- 重启,然后运行你的示例代码就行了,如果还不可以,那你去看其他下载教程。
以下是一篇在Ubuntu18.04安装Tesseract库的博客,需要的请跳转:
开源OCR识别库-tesseract介绍-平凡的编程者-博客园(cnblogs.com)
3. 简单作用了解
先简单了解下有啥用吧。
3.1. 验证码图片爬取-screenshot_as_png
这个网页使用JavaScript渲染出来的,我们进行爬取的时候使用selenium自动化测试工具。
from selenium import webdriver
from selenium.webdriver.common.by import By
from PIL import Image
from io import BytesIO
import timedef demo():browser = webdriver.Chrome()browser.get("https://captcha7.scrape.center")time.sleep(3)captcha = browser.find_element(By.CSS_SELECTOR,"#captcha")image = Image.open(BytesIO(captcha.screenshot_as_png))image.show()if __name__ == "__main__":demo()
这里使用了我很少见的BytesIO,这是一个类,它的功能是读取二进制数据流,而图片就是二进制数据流;还有就是captcha.screenshot_as_png这部分的功能就是将当前页面的内容捕获为一张图像,以bytes二进制数据保存;最后调用image的show方法来显式验证码的图像。
3.2. 识别测试-image_to_string
本小节的验证码案例网站为https://captcha7.scrape.center,使用的是image_to_string,当然还有其他的,等会再说。
3.2.1. 正确识别
首先我们选用两张图片来进行测试,第一张是有换行和明显空格,第二张是一张验证码。


我们运行下面代码:
import pytesseract
from PIL import Image
image1 = Image.open("tesseract_tt1.png")
result1 = pytesseract.image_to_string(image1)
image2 = Image.open("tesseract_tt2.png")
result2 = pytesseract.image_to_string(image2)
print(result1, end= '')
print("=========")
print(result2, end= '')
Demons
Lin
Ss ZzTU
=========
2034
我们可以看到在输出SZTU这部分时候出现了SsZz这样大小写都输出的情况,这是因为pytesseract库在识别大小写字母时候很难准确识别出大小写,你可以采取其他办法来执行,这里就不列出来。
3.2.2. 错误识别
我选取到了一张图片,如下所示:

import pytesseract
from PIL import Image
image = Image.open("error.png")
result = pytesseract.image_to_string(image)
print(result, end= '')
04-8 d.
可以看到这个输出结果明显不是我们想要的,这是因为OCR识别技术是通过检查暗、亮的模式确定字符形状,不是我们想当然的用脑子来看。所以,我们需要做一些额外处理,把干扰信息去掉,我们观察发现,图片里哪些造成干扰的点,其颜色大多比文本的颜色更浅,因此可以通过颜色将干扰点去掉。首先将保存的图片转化为数组,看一下维度:
from PIL import Image
import numpy as np
image = Image.open("error.png")
print(np.array(image).shape)
print(image.mode)
(38, 112, 4)
RGBA
从结果上可以看出,这个图片其实是一个三维数组,38和112代表图片的高和宽,4则是每个像素点的表示向量,那为什么是4呢?因为最后一维是一个长度为4的数组分别表示R(红)G(绿)B(蓝)A(透明度),即一个像素点由4个数字表示。那为什么是RGBA而不是RGB或者其他的呢?因为image.mode是RGBA,即由透明通道的真彩色。
mode属性定义了图片的类型和像素的位宽,一共由9种类型:
- 1:像素用1位表示,Python中表示为True或False,即二值化。
- L:像素用8位表示,取值位0-255,表示灰度图像,数字越小,颜色越黑。
- P:像素用8位表示,即调色板数据。
- RGB:像素用3X8位表示,即真彩色。
- RGBA:像素用4X8位标识,即有透明通道的真彩色。
- CMYK:像素用4X8位表示,即印刷四色模式。
- YCbCr:像素用3X8位表示,即彩色视频格式。
- I:像素用32位整型表示。
- F:像素用32位浮点型表示。
3.2.3. 灰度调节
让识别更加准确,可以把RGBA转化位更简单的L,即把图片转化位灰度图像。往图片对象的convert方法中传入L即可,代码如下表示:
image = image.convert('L')
image.show()
我们选择把图片转化位灰度图像,然后根据阈值删除图片上的干扰点,成功识别出验证码,也可以调用image的show方法来查看图像,代码如下:
from PIL import Image
import numpy as npimage = Image.open("error.png")
image = image.convert('L')
threshold = 90
array = np.array(image)
array = np.where(array> threshold, 255, 0)
image = Image.fromarray((array.astype('uint8')))
# image.show()
result = pytesseract.image_to_string(image)
print(result)
这里先将变量threshold赋值位50.它代表灰度的阈值。接着将图片转化位Numpy数组,利用Numpy的where方法对数组进行筛选和处理,其中将灰度大于阈值的图片的像素设置为255表示白色,否则为0,表示黑色。Image.fromarray((array.astype(‘uint8’))) 是使用PIL(Python Imaging Library)库将numpy数组转换为图像。
3.3. 识别实战-使用image_to_string对象
看懂就行了,识别可能不太准确。
import time
import re
import pytesseract
from selenium import webdriver
from io import BytesIO
from PIL import Image
from retrying import retry
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import TimeoutException
from selenium.webdriver.common.by import By
import numpy as npdef preprocess(image):image = image.convert('L')array = np.array(image)array = np.where(array > 105, 255, 0)image = Image.fromarray(array.astype('uint8'))return image@retry(stop_max_attempt_number=10, retry_on_result=lambda x: x is False)
def login():browser.get('https://captcha7.scrape.center/')browser.find_element(By.CSS_SELECTOR, '.username input[type="text"]').send_keys('admin')browser.find_element(By.CSS_SELECTOR, '.password input[type="password"]').send_keys('admin')captcha = browser.find_element(By.CSS_SELECTOR,'#captcha')image = Image.open(BytesIO(captcha.screenshot_as_png))image = preprocess(image)image.show()captcha = pytesseract.image_to_string(image)print(captcha)captcha = re.sub('[^A-Za-z0-9]', '', captcha)browser.find_element(By.CSS_SELECTOR, '.captcha input[type="text"]').send_keys(captcha)browser.find_element(By.CSS_SELECTOR, '.login').click()try:WebDriverWait(browser, 10).until(EC.presence_of_element_located((By.XPATH, '//h2[contains(., "登录成功")]')))time.sleep(5)browser.close()return Trueexcept TimeoutException:return Falseif __name__ == '__main__':browser = webdriver.Chrome()login()
4. pytesseract库介绍
pytesseract提供了以下14个识别的api,可以满足大多数用户的需求,基本用到的有image_to_string,image_to_boxes,image_to_data,下面是它的14个api:
from pytesseract import ALTONotSupported # 用于表示ALTO XML格式不受支持的错误
from pytesseract import get_languages # 输出识别出文字的语言
from pytesseract import get_tesseract_version # 获取安装的Tesseract OCR引擎的版本信息
from pytesseract import image_to_alto_xml # 将图像识别结果输出为ALTO XML格式的文档,该格式通常用于文档数字化和文本识别
from pytesseract import image_to_boxes # 将图像中的文字识别为边界框(box),并返回它们的坐标信息
from pytesseract import image_to_data # 将图像中的文字识别并返回详细的数据,包括文本、坐标、置信度等信息
from pytesseract import image_to_osd # 识别图像中的文字方向和脚本信息,以确定文本的定位和方向
from pytesseract import image_to_pdf_or_hocr # 将图像中的文字识别并将结果输出为PDF或HOCR(HTML OCR)格式的文档
from pytesseract import image_to_string # 将图像中的文字识别为字符串,并返回识别的文本内容
from pytesseract import Output # 这是一个常量,用于指定返回识别结果的格式,例如文本、字典、数据等
from pytesseract import run_and_get_output # 执行Tesseract OCR引擎并获取其输出,可以用于高级定制和控制
from pytesseract import TesseractError # 用于表示Tesseract OCR引擎的错误
from pytesseract import TesseractNotFoundError # 用于表示未找到Tesseract OCR引擎的错误
from pytesseract import TSVNotSupported # 用于表示TSV(制表符分隔值)格式不受支持的错误__version__ = '0.3.10'
以下内容使用的图片均为上面使用过的!!!!!!
5. image_to_string
从名字上来看是将图片转化为字符串格式,先来看看它的用法,再来说说它的其他参数:
import pytesseract
from PIL import Image
image1 = Image.open("tesseract_tt1.png")
result1 = pytesseract.image_to_string(image1)
print(result1, end= '')
以下是它的其他常见的可选参数:
- lang:指定要用于识别的语言,默认为英语。
- config:允许你传递tesseract配置参数,以微调识别过程,这可以包括有关字体、分辨率以及其他识别参数的设置,配置参数通常以键值对的形式传递。
- –dpi:设置图像的分辨率(每英寸点数)。这可以用于提高对低分辨率图像的识别效果。
- –c tessedit_char_whitelist:允许您指定要识别的字符白名单。例如,–c tessedit_char_whitelist=0123456789可以限制识别的字符集为数字。
以下是使用cv2和pytesseract
import cv2
import pytesseract
img = cv2.imread('tesseract_tt1.png')
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
string = pytesseract.image_to_string(img)
print(string)
print (type(string))
6. image_to_boxes
image_to_boxes 是 pytesseract 库中的一个函数,用于将图像中的文字识别为边界框(box),并返回它们的坐标信息。每个边界框包含了单个字符的位置和大小。这对于进行文本布局分析和文本识别后的后续处理非常有用。
函数签名:
image_to_boxes(image, lang=None, config='', output_type=pytesseract.Output.STRING)
参数说明:
image:要识别的图像,通常是一个 PIL 图像对象。lang:可选参数,指定要用于识别的语言。config:可选参数,用于配置 Tesseract 的识别参数。output_type:可选参数,指定返回结果的格式,默认为字符串。
返回值:
- 如果
output_type设置为pytesseract.Output.STRING(默认值),则返回一个包含边界框信息的字符串,每行一个边界框,每行的格式为:<字符> <x坐标> <y坐标> <右边界x坐标> <下边界y坐标> <页>
模板代码:
from pytesseract import image_to_boxes
from PIL import Image
image = Image.open('tesseract_tt2.png')# 使用 image_to_boxes 函数进行文字识别并获取边界框信息
boxes = image_to_boxes(image)
# 打印边界框信息
for box in boxes.splitlines():b = box.split()char, x, y, x2, y2, page = b[0], int(b[1]), int(b[2]), int(b[3]), int(b[4]), int(b[5])print(f"字符: {char}, 位置: 左上({x},{y}), 右下({x2},{y2}), 页: {page}")
上述示例代码演示了如何使用 image_to_boxes 函数进行文字识别,并打印出识别的文本字符以及它们的位置信息。每个边界框包括字符、左上角坐标、右下角坐标和所在页。以下是输出结果:
字符: 2, 位置: 左上(13,4), 右下(34,27), 页: 0
字符: 0, 位置: 左上(45,12), 右下(55,27), 页: 0
字符: 3, 位置: 左上(64,10), 右下(78,38), 页: 0
字符: 4, 位置: 左上(90,16), 右下(102,34), 页: 0
知道这些信息我们可以做以下事情,对于这些我就没兴趣了:
-
文本高亮或标记:您可以使用字符的左上角和右下角坐标信息来在原始图像上绘制矩形框,从而高亮或标记文本字符。这对于可视化识别结果或提供反馈非常有用。
-
文本提取:通过比较字符的所在页信息,您可以将识别的文本分成不同的页面或段落。这对于处理多页文档或大型文本文件很有帮助。
-
文本布局分析:通过分析字符的相对位置和页码信息,您可以推断文本的布局结构,例如确定标题、段落、表格或列表的位置。这有助于自动化文档处理。
-
字符级别编辑:您可以根据字符的坐标信息,进行字符级别的编辑或纠正。例如,您可以检测到字符位置偏差较大的情况,并尝试进行自动校正。
-
文本重排:如果需要将文本重新排列成特定格式,可以使用字符的坐标信息将它们按照所在页和位置进行排序和排列。
-
自动分析文本流:通过字符的相对位置和页码信息,您可以自动分析文本流,例如确定文本的阅读顺序或制定自动化文档处理规则。
7. image_to_data
以下内容是参考这一篇博文:pytesseract image_to_data检测并定位图片中的文字 - LiveZingy
image_to_data 是 pytesseract 库中的一个函数,用于将图像中的文字识别并返回详细的数据,包括文本、坐标、置信度等信息。
函数签名:
image_to_data(image, lang=None, config='', output_type=pytesseract.Output.DICT, nice=0)
参数说明:
image:要识别的图像,通常是一个 PIL 图像对象。lang:可选参数,指定要用于识别的语言。config:可选参数,用于配置 Tesseract 的识别参数。output_type:可选参数,指定返回结果的格式,默认为字典(pytesseract.Output.DICT)。nice:可选参数,设置 Tesseract 进程的优先级,默认为 0。
返回值:
- 根据
output_type参数的不同,image_to_data函数返回不同的对象。常见的output_type包括字典、字符串、或数据对象。
如果 output_type 设置为 pytesseract.Output.DICT,则返回一个包含详细信息的字典,其中包括以下参数:
'level':文本块的级别(例如,字、词、文本行等)。'page_num':文本块所在的页码。'block_num':文本块的编号。'par_num':段落编号。'line_num':文本行编号。'word_num':单词编号。'left'、'top'、'width'、'height':文本块的位置和尺寸信息。'conf':识别置信度。'text':识别的文本内容。
以下是一个示例代码,演示如何使用 image_to_data 函数并理解其返回的对象:
import pytesseract
from PIL import Image# 打开图像文件
image = Image.open('tesseract_tt2.png')# 使用 image_to_data 函数进行文字识别并获取详细信息
data = pytesseract.image_to_data(image, output_type=pytesseract.Output.DICT)print(data)
# 打印详细信息
for i, (word, left, top, width, height, conf) in enumerate(zip(data['text'], data['left'], data['top'], data['width'], data['height'], data['conf'])):if i > 0: # 第一行通常包含表头信息,可以跳过print(f"文本: {word}, 位置: 左上({left},{top}), 宽度: {width}, 高度: {height}, 置信度: {conf}")
{'level': [1, 2, 3, 4, 5], 'page_num': [1, 1, 1, 1, 1], 'block_num': [0, 1, 1, 1, 1], 'par_num': [0, 0, 1, 1, 1], 'line_num': [0, 0, 0, 1, 1], 'word_num': [0, 0, 0, 0, 1], 'left': [0, 13, 13, 13, 13], 'top': [0, 0, 0, 0, 0], 'width': [112, 89, 89, 89, 89], 'height': [38, 34, 34, 34, 34], 'conf': [-1, -1, -1, -1, 60], 'text': ['', '', '', '', '2034']}
文本: , 位置: 左上(13,0), 宽度: 89, 高度: 34, 置信度: -1
文本: , 位置: 左上(13,0), 宽度: 89, 高度: 34, 置信度: -1
文本: , 位置: 左上(13,0), 宽度: 89, 高度: 34, 置信度: -1
文本: 2034, 位置: 左上(13,0), 宽度: 89, 高度: 34, 置信度: 60
根据 image_to_data 的输出结果,以下是各个参数的知识点解释:
-
'level':文本块的级别。这表示文本的层次结构,例如,1 表示文本块级别,2 表示词级别,以此类推。 -
'page_num':文本块所在的页码。在单一图像中识别文本时,通常为 1。 -
'block_num':文本块的编号。文本块是文本的更大单元,通常表示一个文本块包含多个词或多个文本行。 -
'par_num':段落编号。这表示文本块所属的段落编号。 -
'line_num':文本行编号。表示文本块所在的文本行编号,通常在段落内。 -
'word_num':单词编号。表示文本块内的单词编号,通常在文本行内。 -
'left'、'top'、'width'、'height':文本块的位置和尺寸信息。'left'和'top'表示文本块的左上角坐标,'width'和'height'表示文本块的宽度和高度。 -
'conf':识别置信度。表示 Tesseract 对文本块的识别置信度,通常是一个分数,值越高表示置信度越高。 -
'text':识别的文本内容。这是文本块中识别出的具体文本,通常包含单词或字符的文本内容。
在这个示例中,有多个文本块级别的信息。最后一条记录中的 'text' 包含了识别的文本内容(‘2034’),而前面的记录中 'text' 为空字符串,这可能表示Tesseract对这些文本块没有成功识别。并且你也可以根据置信度选取最好的结果,当然这个结果不一定是正确的。
8. 参考博客
开源OCR识别库-tesseract介绍-平凡的编程者-博客园(cnblogs.com)
【爬虫】8.1. 使用OCR技术识别图形验证码
借助Tesseract-OCR进行文本检测(1)
借助Tesseract-OCR进行文本检测(2)
pytesseract image_to_data检测并定位图片中的文字 - LiveZingy
相关文章:
【爬虫】8.1. 深度使用tesseract-OCR技术识别图形验证码
深度使用tesseract-OCR技术识别图形验证码 文章目录 深度使用tesseract-OCR技术识别图形验证码1. OCR技术2. 准备工作3. 简单作用了解3.1. 验证码图片爬取-screenshot_as_png3.2. 识别测试-image_to_string3.2.1. 正确识别3.2.2. 错误识别3.2.3. 灰度调节 3.3. 识别实战-使用im…...

【PythonRS】基于GDAL修改栅格数据的DN值
遥感工作者离不开栅格数据,有时候我们可能需要修改栅格数据的值,但ENVI和ArcGIS中并没有直接修改DN值的工具,只有栅格计算器、Band math这些工具去计算整个波段的值,或者Edit Classification Image工具可以修改ENVI分类后的像元值…...

mysql课堂笔记 mac
目录 启动mac上的mysql 进入mysql mac windows 创建数据库 创建表 修改字段数据类型 修改字段名 增加字段 删除字段 启动mac上的mysql sudo /usr/local/mysql/support-files/mysql.server start 直接输入你的开机密码即可。 编辑 进入mysql mac sudo /usr/local…...

2023年数学建模国赛A 定日镜场的优化设计思路分析
构建以新能源为主体的新型电力系统,是我国实现“碳达峰”“碳中和”目标的一项重要措施。塔式太阳能光热发电是一种低碳环保的新型清洁能源技术[1]。定日镜是塔式太阳能光热发电站(以下简称塔式电站)收集太阳能的基本组件,其底座由…...

【QT】QMessageBox消息框的使用(16)
在实际项目中,弹出消息框是一个很常见的操作,包含错误信息提示、警告信息提示、关于信息提示、还包括判断信息选择等操作,那么今天通过这一节来好好了解下消息框的使用方法。 一.环境配置 1.python 3.7.8 可直接进入官网下载安装…...
XL-LightHouse 与 Flink 和 ClickHouse 流式大数据统计系统
一个Flink任务只能并行处理一个或少数几个数据流,而XL-LightHouse一个任务可以并行处理数万个、几十万个数据流; 一个Flink任务只能实现一个或少数几个数据指标,而XL-LightHouse单个任务就能支撑大批量、数以万计的数据指标。 1、XL-LightHo…...

【postgresql 基础入门】创建数据库的方法,存储位置,决定自己的数据的访问用户和范围
创建数据库 专栏内容: postgresql内核源码分析手写数据库toadb并发编程 开源贡献: toadb开源库 个人主页:我的主页 管理社区:开源数据库 座右铭:天行健,君子以自强不息;地势坤,君…...

科技云报道:AI时代,对构建云安全提出了哪些新要求?
科技云报道原创。 随着企业上云的提速,一系列云安全问题也逐渐暴露出来,云安全问题得到重视,市场不断扩大。 Gartner 发布“2022 年中国 ICT 技术成熟度曲线”显示,云安全已处于技术萌芽期高点,预期在2-5年内有望达到…...

如何让 Llama2、通义千问开源大语言模型快速跑在函数计算上?
:::info 本文是“在Serverless平台上构建AIGC应用”系列文章的第一篇文章。 ::: 前言 随着ChatGPT 以及 Stable Diffusion,Midjourney 这些新生代 AIGC 应用的兴起,围绕AIGC应用的相关开发变得越来越广泛,有呈井喷之势,从长远看这波应用的爆…...
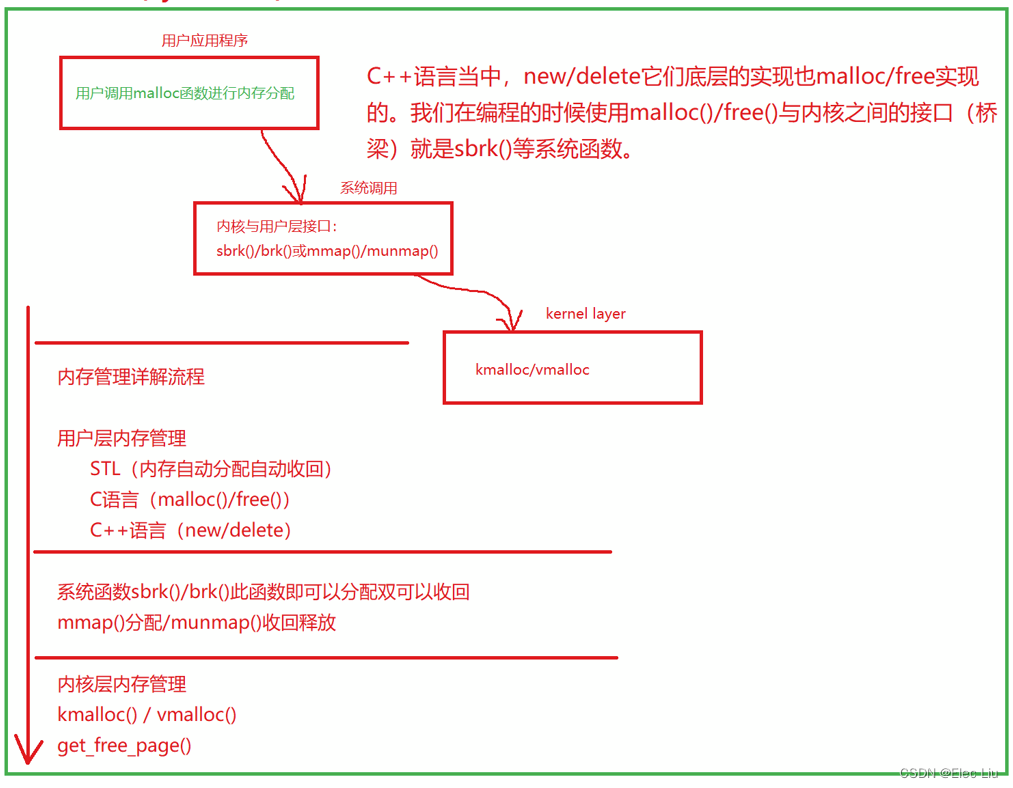
Linux内核源码分析 (B.2)虚拟地址空间布局架构
Linux内核源码分析 (B.2)虚拟地址空间布局架构 文章目录 Linux内核源码分析 (B.2)虚拟地址空间布局架构一、Linux内核整体架构及子系统二、Linux内核内存管理架构 一、Linux内核整体架构及子系统 Linux内核只是操作系统当中的一部分,对下管理系统所有硬件设备&…...
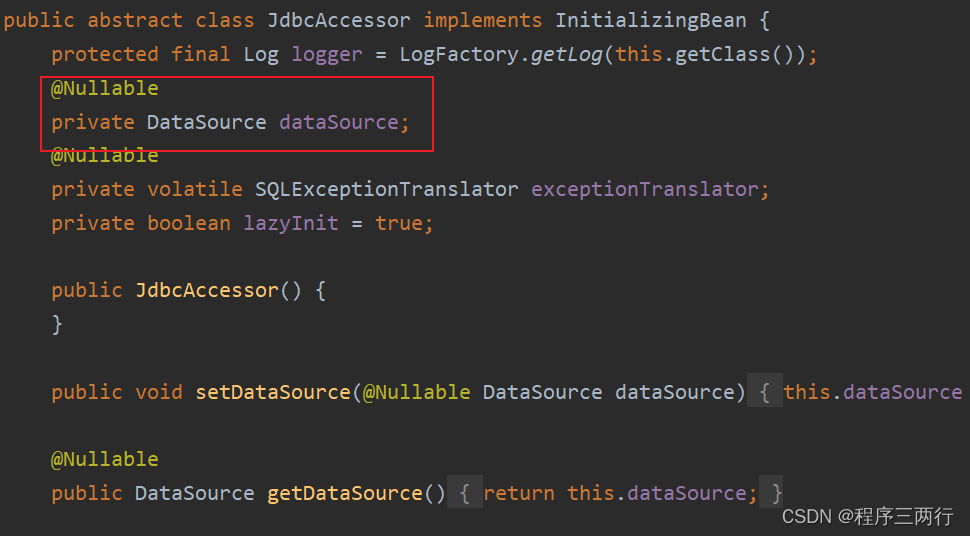
Spring系列文章:Spring使用JdbcTemplate
一、简介 JdbcTemplate是Spring提供的⼀个JDBC模板类,是对JDBC的封装,简化JDBC代码。 当然,你也可以不⽤,可以让Spring集成其它的ORM框架,例如:MyBatis、Hibernate等。 第一步:引入依赖 <d…...

[matlab]cvx安装后测试代码
测试环境: windows10 x64 matlab2023a 代码来自官方网站:CVX: Matlab Software for Disciplined Convex Programming | CVX Research, Inc. m 20; n 10; p 4; A randn(m,n); b randn(m,1); C randn(p,n); d randn(p,1); e rand; cvx_beginva…...

【css】margin:auot什么情况下失效
margin:auto只对块级元素有效果,并且在正常文档流margin:automargin:0 auto,css默认在正常文档流里面margin-top和margin-bottom是0 为什么margin: auto能实现水平居中,而垂直居中不行? 一般子…...

linux的dirty page回写磁盘过程中是否允许并发写入更新page?
概述 众所周知Linux内核write系统调用采用pagecache机制加速写入过程,避免write系统调用长时间block应用进程,用户态进程执行write调用的时候,内核只是将用户态buffer copy到内核的pagecache当中,write系统调用就返回了,完全不需要等待数据完全写入存储设备,因为存储设备…...
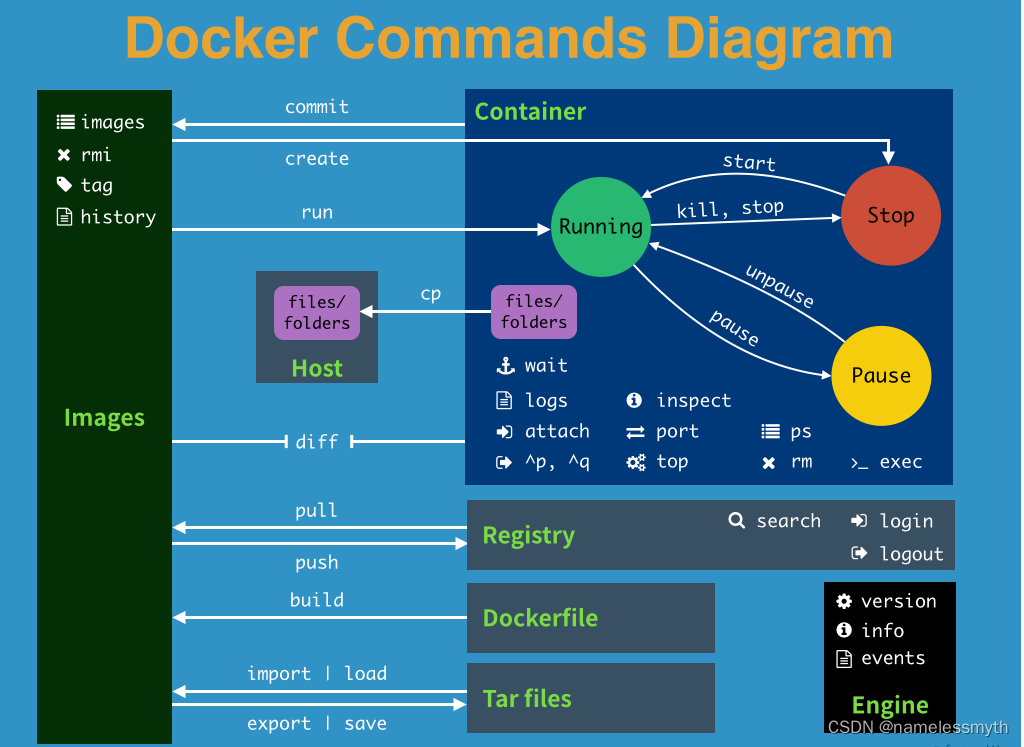
Docker-基础命令使用
文章目录 前言命令帮助命令执行示意图docker rundocker psdocker inspectdocker execdocker attachdocker stopdocker startdocker topdocker rmdocker prune参考说明 前言 本文主要介绍Docker基础命令的使用方法。 命令帮助 Docker命令获取帮助方法 # docker -h Flag shor…...

【Python 程序设计】Python 中的类型提示【06/8】
目录 一、说明 二、什么是动态类型? 2.1 为什么要使用类型提示? 2.2 局限性 三、基本类型提示 3.1 声明变量的类型 3.2 函数注释 四、Python 中的内置类型 4.1 原子类型与复合类型 五、函数注释 5.1 如何指定函数的参数类型和返回类型 5.2 在函数签名中…...
78 # koa 中间件的实现
上上节实现了上下文的,上一节使用了一下中间件,这一节来实现 koa 的中间件这个洋葱模型。 思路: 储存用户所有的 callback将用户传递的 callback 全部组合起来(redux 里的 compose)组合成一个线性结构依次执行&#…...

国产操作系统麒麟v10中遇到的一些问题
下载pycharm:直接在应用商店 目标:主机1安装了虚拟机,主机2要ping通主机1安装的虚拟机。 前提:主机1,主机2在同一局域网下,同一网段。 网络配置 因为虚拟机的网段不在局域网网段内,局域网下…...

Gridea+GitPage+Gittalk 搭建个人博客
👋通过GrideaGitPage 搭建属于自己的博客! 👻GitPage 负责提供 Web 功能! 😽Gridea 作为本地编辑器,方便 push 文章! 🏷本文讲解如何使用 GrideaGitPage 服务域名(可选&a…...

代码质量保障第2讲:单元测试 - 浅谈单元测试
代码质量保障第2讲:单元测试 - 浅谈单元测试 本文是代码质量保障第2讲,浅谈单元测试。单元测试(unit testing),是指对软件中的最小可测试单元进行检查和验证。这是基础,所以围绕着单元测试,我从…...

RISC-V CLIC中断机制实战:用中断咬尾优化你的嵌入式实时系统性能
RISC-V CLIC中断机制实战:用中断咬尾优化你的嵌入式实时系统性能 在嵌入式系统开发中,中断处理效率直接影响着实时性和系统吞吐量。传统的中断处理方式往往伴随着频繁的上下文保存与恢复,这不仅消耗宝贵的CPU周期,还增加了栈空间的…...

终极指南:如何为Amlogic电视盒子刷入Armbian系统并解决网络兼容性问题
终极指南:如何为Amlogic电视盒子刷入Armbian系统并解决网络兼容性问题 【免费下载链接】amlogic-s9xxx-armbian Supports running Armbian on Amlogic, Allwinner, and Rockchip devices. Support a311d, s922x, s905x3, s905x2, s912, s905d, s905x, s905w, s905, …...

深夜调试:一个弹窗定位问题,暴露了90%UI自动化的通病
01 深夜的屏幕共享凌晨零点四十二分,屏幕共享刚打开,一个应届生就迫不及待地展示他的毕业设计。“企微信通讯录,目前我只做了一个添加成员的模块。”他的鼠标在代码和页面之间快速切换,“但做到添加部门的时候,这里就会…...
)
告别盲猜:用Process Monitor给你的软件行为做一次“全身体检”(以Chrome/微信为例)
告别盲猜:用Process Monitor给你的软件行为做一次“全身体检”(以Chrome/微信为例) 你是否曾经好奇过,当你在电脑上双击一个软件图标时,它究竟在后台悄悄执行了哪些操作?为什么有些软件启动特别慢ÿ…...

GetQzonehistory:3步永久保存你的QQ空间青春回忆
GetQzonehistory:3步永久保存你的QQ空间青春回忆 【免费下载链接】GetQzonehistory 获取QQ空间发布的历史说说 项目地址: https://gitcode.com/GitHub_Trending/ge/GetQzonehistory 你是否还记得十年前在QQ空间写下的第一条说说?那些记录着青春、…...

GitHub 中文插件:3分钟让全球最大开发者平台说你的语言
GitHub 中文插件:3分钟让全球最大开发者平台说你的语言 【免费下载链接】github-chinese GitHub 汉化插件,GitHub 中文化界面。 (GitHub Translation To Chinese) 项目地址: https://gitcode.com/gh_mirrors/gi/github-chinese 作为一名开发者&am…...
)
两千多块搞定24G显存!我的Tesla M40深度学习主机装机全记录(附详细配置单与避坑清单)
两千元打造24G显存深度学习主机:Tesla M40实战指南 在深度学习领域,显存容量往往比核心性能更能决定模型训练的可行性。当主流消费级显卡还在8G-12G显存区间徘徊时,NVIDIA Tesla M40以24G GDDR5显存和不到500元的二手价格,为预算有…...

使用Hermes Agent时如何正确配置Taotoken作为自定义供应商
使用Hermes Agent时如何正确配置Taotoken作为自定义供应商 1. 准备工作 在开始配置之前,请确保您已经完成以下准备工作。首先,您需要拥有一个有效的Taotoken账户,并在控制台中创建了API Key。其次,您需要在模型广场查看并记录下…...
)
Python自动化办公:用华为云OBS SDK实现文件自动备份与同步(附完整代码)
Python自动化办公:用华为云OBS SDK实现文件自动备份与同步 每天下班前手动备份项目文档,在不同设备间反复传输最新版本,这些重复性工作消耗了开发者大量时间。华为云对象存储服务(OBS)配合Python SDK,能将这…...

降AI率工具5大坑:哪些功能没用却让你多花100元的避雷指南?
降AI率工具5大坑:哪些功能没用却让你多花100元的避雷指南? 降 AI 率工具市场 2026 年初已经卷到红海,新工具一周冒一批。但 70% 的工具是「看着花哨实际没用」的产品。学生买完发现降不下去 AI 率、申请退款被拒、报警无门。 我盘了一份 5 …...