HashMap、LinkedHashMap、ConcurrentHashMap、ArrayList、LinkedList的底层实现。
HashMap、LinkedHashMap、ConcurrentHashMap、ArrayList、LinkedList的底层实现。
HashMap相关问题
1、你用过HashMap吗?什么是HashMap?你为什么用到它?用过,HashMap是基于哈希表的Map接口的非同步实现,
它允许null键和null值,且HashMap依托于它的数据结构的设计
,存储效率特别高,这是我用它的原因2、你知道HashMap的工作原理吗?你知道HashMap的get()方法
的工作原理吗?上面两个问题属于同一答案的问题HashMap是基于hash算法实现的,通过put(key,value)
存储对象到HashMap中,也可以通过get(key)从HashMap中获取对象。
当我们使用put的时候,首先HashMap会对key的hashCode()的值
进行hash计算,根据hash值得到这个元素在数组中的位置,
将元素存储在该位置的链表上。当我们使用get的时候,
首先HashMap会对key的hashCode()的值进行hash计算,
根据hash值得到这个元素在数组中的位置,将元素从该位置上的链表中取出3、当两个对象的hashcode相同会发生什么?hashcode相同,说明两个对象HashMap数组的同一位置上,
接着HashMap会遍历链表中的每个元素,
通过key的equals方法来判断是否为同一个key,
如果是同一个key,则新的value会覆盖旧的value,
并且返回旧的value。如果不是同一个key,
则存储在该位置上的链表的链头4、如果两个键的hashcode相同,你如何获取值对象?遍历HashMap链表中的每个元素,并对每个key进行hash计算,
最后通过get方法获取其对应的值对象5、如果HashMap的大小超过了负载因子(load factor)定义的容量,
怎么办?负载因子默认是0.75,HashMap超过了负载因子定义的容量,
也就是说超过了(HashMap的大小*负载因子)这个值,
那么HashMap将会创建为原来HashMap大小两倍的数组大小,
作为自己新的容量,这个过程叫resize或者rehash6、你了解重新调整HashMap大小存在什么问题吗?当多线程的情况下,可能产生条件竞争。当重新调整HashMap大小的时候,
确实存在条件竞争,如果两个线程都发现HashMap需要重新调整大小了,
它们会同时试着调整大小。在调整大小的过程中,
存储在链表中的元素的次序会反过来,
因为移动到新的数组位置的时候,
HashMap并不会将元素放在LinkedList的尾部,而是放在头部,
这是为了避免尾部遍历(tail traversing)。
如果条件竞争发生了,那么就死循环了7、我们可以使用自定义的对象作为键吗?可以,只要它遵守了equals()和hashCode()方法的定义规则,
并且当对象插入到Map中之后将不会再改变了。
如果这个自定义对象时不可变的,那么它已经满足了作为键的条件,
因为当它创建之后就已经不能改变了。
HashSet与HashMap区别
HashMap实现了Map接口
HashSet实现了Set接口HashMap储存键值对
HashSet仅仅存储对象HashMap使用put()方法将元素放入map中
HashSet使用add()方法将元素放入set中HashMap中使用键对象来计算hashcode值
HashSet使用成员对象来计算hashcode值HashMap比较快,因为是使用唯一的键来获取对象
HashSet较HashMap来说比较慢
HashTable与HashMap的区别
Hashtable方法是同步的
HashMap方法是非同步的Hashtable基于Dictionary类
HashMap基于AbstractMap,而AbstractMap基于Map接口的实现Hashtable中key和value都不允许为null,遇到null,
直接返回 NullPointerException
HashMap中key和value都允许为null,遇到key为null的时候,
调用putForNullKey方法进行处理,而对value没有处理Hashtable中hash数组默认大小是11,扩充方式是old*2+1
HashMap中hash数组的默认大小是16,而且一定是2的指数
LinkedHashMap的有序性
LinkedHashMap底层使用哈希表与双向链表来保存所有元素,
它维护着一个运行于所有条目的双向链表
(如果学过双向链表的同学会更好的理解它的源代码),
此链表定义了迭代顺序,该迭代顺序可以是插入顺序或者是访问顺序
1.按插入顺序的链表:在LinkedHashMap调用get方法后,
输出的顺序和输入时的相同,这就是按插入顺序的链表,
默认是按插入顺序排序2.按访问顺序的链表:在LinkedHashMap调用get方法后,
会将这次访问的元素移至链表尾部,
不断访问可以形成按访问顺序排序的链表。简单的说,
按最近最少访问的元素进行排序(类似LRU算法)
我们可以通过例子来理解我们上面所说的LinkedHashMap的插入顺序和访问顺序
public static void main(String[] args) {Map<String, String> map = new HashMap<String, String>();map.put("apple", "苹果");map.put("watermelon", "西瓜");map.put("banana", "香蕉");map.put("peach", "桃子");Iterator iter = map.entrySet().iterator();while (iter.hasNext()) {Map.Entry entry = (Map.Entry) iter.next();System.out.println(entry.getKey() + "=" + entry.getValue());}
}
上面是简单的HashMap代码,通过控制台的输出,我们可以看到HashMap是没有顺序的
banana=香蕉
apple=苹果
peach=桃子
watermelon=西瓜
我们现在将HashMap换成LinkedHashMap,其他代码不变
Map<String, String> map = new LinkedHashMap<String, String>();
看一下控制台的输出
apple=苹果
watermelon=西瓜
banana=香蕉
peach=桃子
我们可以看到,其输出顺序是完成按照插入顺序的,也就是我们上面所说的保留了插入的顺序。下面我们修改一下代码,通过访问顺序进行排序。
public static void main(String[] args) {Map<String, String> map = new LinkedHashMap<String, String>(16,0.75f,true);map.put("apple", "苹果");map.put("watermelon", "西瓜");map.put("banana", "香蕉");map.put("peach", "桃子");map.get("banana");map.get("apple");Iterator iter = map.entrySet().iterator();while (iter.hasNext()) {Map.Entry entry = (Map.Entry) iter.next();System.out.println(entry.getKey() + "=" + entry.getValue());}
}
代码与之前的相比
1.替换了LinkedHashMap的构造函数,使用三个参数的构造函数,第三个参数传进true就是表明用访问顺序来排序,默认是false(即插入顺序)
2.增加了两句LinkedHashMap的get方法,来表示最近已经访问过这两个元素了
//修改的代码
Map<String, String> map = new LinkedHashMap<String, String>(16,0.75f,true);
......
map.get("banana");
map.get("apple");看一下控制台的输出结果
watermelon=西瓜
peach=桃子
banana=香蕉
apple=苹果
我们可以看到,顺序是先从最少访问的元素开始遍历(西瓜、桃子),而香蕉、苹果是因为分别调用了get方法,香蕉是最先访问的,所以它的比苹果更少用一些。这也就是我们之前提到过的,LinkedHashMap可以选择按照访问顺序进行排序
LinkedHashMap与HashMap的区别
LinkedHashMap有序的,有插入顺序和访问顺序
HashMap无序的
LinkedHashMap内部维护着一个运行于所有条目的双向链表
HashMap内部维护着一个单链表
什么是ArrayList
ArrayList可以理解为动态数组,它的容量能动态增长,该容量是指用来存储列表元素的数组的大小,随着向ArrayList中不断添加元素,其容量也自动增长
ArrayList允许包括null在内的所有元素
ArrayList是List接口的非同步实现
ArrayList是有序的
ArrayList实现了List接口、底层使用数组保存所有元素,其操作基 本上是对数组的操作ArrayList继承了AbstractList抽象类,它是一个数组队列,提供了相关的添加、删除、修改、遍历等功能ArrayList实现了RandmoAccess接口,即提供了随机访问功能,RandmoAccess是java中用来被List实现,为List提供快速访问功能的,我们可以通过元素的序号快速获取元素对象,这就是快速随机访问ArrayList实现了Cloneable接口,即覆盖了函数clone(),能被克隆
ArrayList实现了java.io.Serializable接口,意味着ArrayList支持序列化
什么是LinkedList
LinkedList基于链表的List接口的非同步实现
LinkedList允许包括null在内的所有元素
LinkedList是有序的
LinkedList是fail-fast的
LinkedList与ArrayList的区别
LinkedList底层是双向链表
ArrayList底层是可变数组
LinkedList不允许随机访问, 即查询效率低 ArrayList允许随机访问,即查询效率高
LinkedList插入和删除效率快
ArrayList插入和删除效率低
解释一下:
对于随机访问的两个方法,get和set,ArrayList优于LinkedList,因为LinkedList要移动指针
对于新增和删除两个方法,add和remove,LinedList比较占优势,因为ArrayList要移动数据
什么是ConcurrentHashMap
ConcurrentHashMap基于双数组和链表的Map接口的同步实现
ConcurrentHashMap中元素的key是唯一的、value值可重复
ConcurrentHashMap不允许使用null值和null键
ConcurrentHashMap是无序的
为什么使用ConcurrentHashMap
我们都知道HashMap是非线程安全的,当我们只有一个线程在使用HashMap的时候,自然不会有问题,但如果涉及到多个线程,并且有读有写的过程中,HashMap就会fail-fast。要解决HashMap同步的问题,我们的解决方案有
Hashtable
Collections.synchronizedMap(hashMap)
这两种方式基本都是对整个hash表结构加上同步锁,这样在锁表的期间,别的线程就需要等待了,无疑性能不高,所以我们引入ConcurrentHashMap,既能同步又能多线程访问
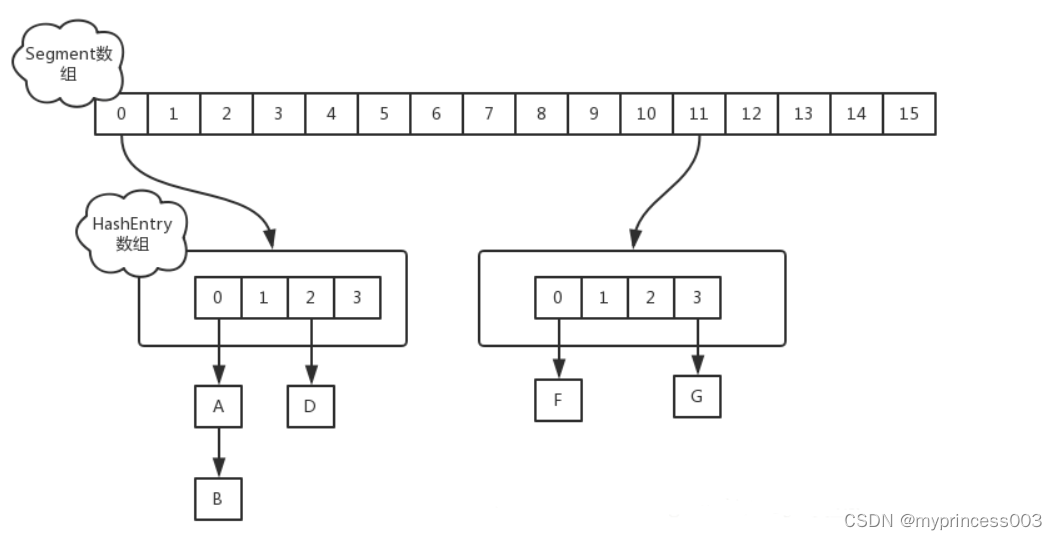
ConcurrentHashMap的数据结构
ConcurrentHashMap的数据结构为一个Segment数组,Segment的数据结构为HashEntry的数组,而HashEntry存的是我们的键值对,可以构成链表。可以简单的理解为数组里装的是HashMap
从上面的结构我们可以了解到,ConcurrentHashMap定位一个元素的过程需要进行两次Hash操作,第一次Hash定位到Segment,第二次Hash定位到元素所在的链表的头部,因此,这一种结构的带来的副作用是Hash的过程要比普通的HashMap要长,但是带来的好处是写操作的时候可以只对元素所在的Segment进行加锁即可,不会影响到其他的Segment。正是因为其内部的结构以及机制,ConcurrentHashMap在并发访问的性能上要比Hashtable和同步包装之后的HashMap的性能提高很多。在理想状态下,ConcurrentHashMap 可以支持 16 个线程执行并发写操作(如果并发级别设置为 16),及任意数量线程的读操作
什么是Vector
Vector是基于可变数组的List接口的同步实现
Vector是有序的
Vector允许null键和null值
Vector已经不建议使用了
Vector实现了List接口、底层使用数组保存所有元素,其操作基本上是对数组的操作
Vector继承了AbstractList抽象类,它是一个数组队列,提供了相关的添加、删除、修改、遍历等功能
Vector实现了RandmoAccess接口,即提供了随机访问功能,RandmoAccess是java中用来被List实现,为List提供快速访问功能的,我们可以通过元素的序号快速获取元素对象,这就是快速随机访问
Vector实现了Cloneable接口,即覆盖了函数clone(),能被克隆
Vector实现了java.io.Serializable接口,意味着ArrayList支持序列化
Vector和ArrayList的区别
Vector同步、线程安全的
ArrayList异步、线程不安全
Vector 需要额外开销来维持同步锁,性能慢
ArrayList 性能快
Vector 可以使用Iterator、foreach、Enumeration输出
ArrayList 只能使用Iterator、foreach输出
相关文章:
HashMap、LinkedHashMap、ConcurrentHashMap、ArrayList、LinkedList的底层实现。
HashMap、LinkedHashMap、ConcurrentHashMap、ArrayList、LinkedList的底层实现。 HashMap相关问题 1、你用过HashMap吗?什么是HashMap?你为什么用到它?用过,HashMap是基于哈希表的Map接口的非同步实现, 它允许null键…...

flink学习之广播流与合流操作demo
广播流是什么? 将一条数据广播到所有的节点。使用 dataStream.broadCast() 广播流使用场景? 一般用于动态加载配置项。比如lol,每天不断有人再投诉举报,客服根本忙不过来,腾讯内部做了一个判断,只有vip3…...
PPT架构师架构技能图
PPT架构师架构技能图 目录概述需求: 设计思路实现思路分析1.软素质2.核心输出(office输出) 参考资料和推荐阅读 Survive by day and develop by night. talk for import biz , show your perfect code,full busy,skip hardness,ma…...

STM32微控制器的低功耗模式
STM32微控制器的低功耗模式(Low-power modes):Sleep mode、Stop mode 和 Standby mode。 1.1 Sleep Mode(睡眠模式): 把STM32微控制器当作一位劳累的工人,他在工作过程中需要短暂的休息。在Sleep模式下,微控制器会关闭一部分电路,减小功耗,但仍然保持对中央处理单…...
tensorflow QAT
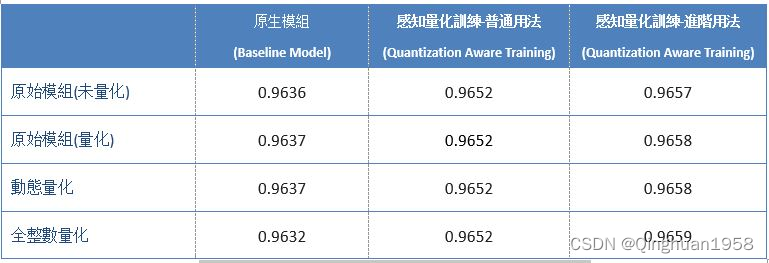
tensorflow qat https://www.wpgdadatong.com/tw/blog/detail/70672 在边缘运算的重点技术之中,除了简化复杂的模块构架,来简化参数量以提高运算速度的这项模块轻量化网络构架技术之外。另一项技术就是各家神经网络框架(TensorFlow、Pytorc…...

[杂谈]-快速了解LoRaWAN网络以及工作原理
快速了解LoRaWAN网络以及工作原理 文章目录 快速了解LoRaWAN网络以及工作原理1、LoRaWAN网络元素1.1 终端设备(End Devices)1.2 网关(Gateways)1.3 网络服务器(Net Server)1.4 应用服务器(Appli…...
MySQL--MySQL表的增删改查(基础)
排序:ORDER BY 语法: – ASC 为升序(从小到大) – DESC 为降序(从大到小) – 默认为 ASC SELECT … FROM table_name [WHERE …] ORDER BY column [ASC|DESC], […]; *** update...

Vue中启动提示polyfill缺少-webpack v5版本导致
安装 npm i node-polyfill-webpack-plugin 因为我们的项目使用webpack v5,其中polyfill Node核心模块被删除。所以,我们安装它是为了在项目中访问这些模块 vue.config.js文件 const { defineConfig } require("vue/cli-service"); const No…...

Hugging Face实战-系列教程3:AutoModelForSequenceClassification文本2分类
🚩🚩🚩Hugging Face 实战系列 总目录 有任何问题欢迎在下面留言 本篇文章的代码运行界面均在notebook中进行 本篇文章配套的代码资源已经上传 下篇内容: Hugging Face实战-系列教程4:padding与attention_mask 输出我…...

《TCP/IP网络编程》阅读笔记--Socket类型及协议设置
目录 1--协议的定义 2--Socket的创建 2-1--协议族(Protocol Family) 2-2--Socket类型(Type) 3--Linux下实现TCP Socket 3-1--服务器端 3-2--客户端 3-3--编译运行 4--Windows下实现 TCP Socket 4-1--TCP服务端 4-2--TC…...

GitHub使用教程
GitHub使用教程 视频教程一:Github 新手够用指南 | 全程演示&个人找项目技巧放送_哔哩哔哩_bilibili 笔记: README.md编写教程:Typora官方免费版与入门教程__阿伟_的博客-CSDN博客 找开源项目的一些途径 • https://github.com/trendin…...
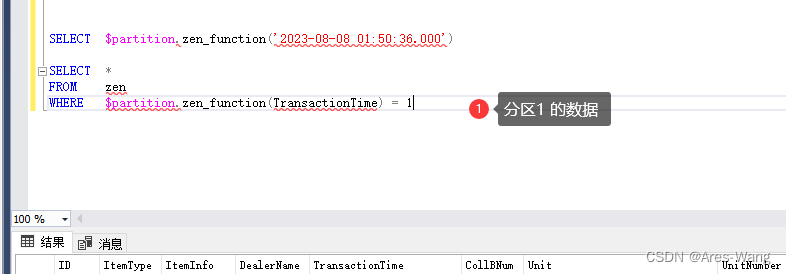
sql server 分区表
分区表 分区表是在SQL Server 2005之后的版本引入的特性,这个特性允许把逻辑上的一个表在物理上分为很多部分。换句话说,分区表从物理上看是将一个大表分成几个小表,但是从逻辑上看,还是一个大表。 步骤 创建分表区的步骤分为…...

开源许可证概述:GNU, BSD, Apache, MPL, 和 MIT
前言 开源许可证是开源软件分发的基础。它们定义了使用者如何使用,修改,分发开源软件。在这篇文章中,我们将探讨五种常见的开源许可证:GNU通用公共许可证 (GNU GPL),BSD许可证,Apache许可证,Mo…...

java中log使用总结
目录 一、概述1.1. 核心日志框架1.2 门面日志框架 二、最佳实践2.1 核心日志框架API包2.2 门面日志框架依赖2.3 集成使用2.3.1 集成jcl2.3.2 集成slf4j2.3.2.1 slf4j集成单一框架2.3.2.2 slf4j整合混合框架 三、总结3.1 所有相关包3.1.1 核心日志框架包3.1.2 门面日志框架3.1.3…...
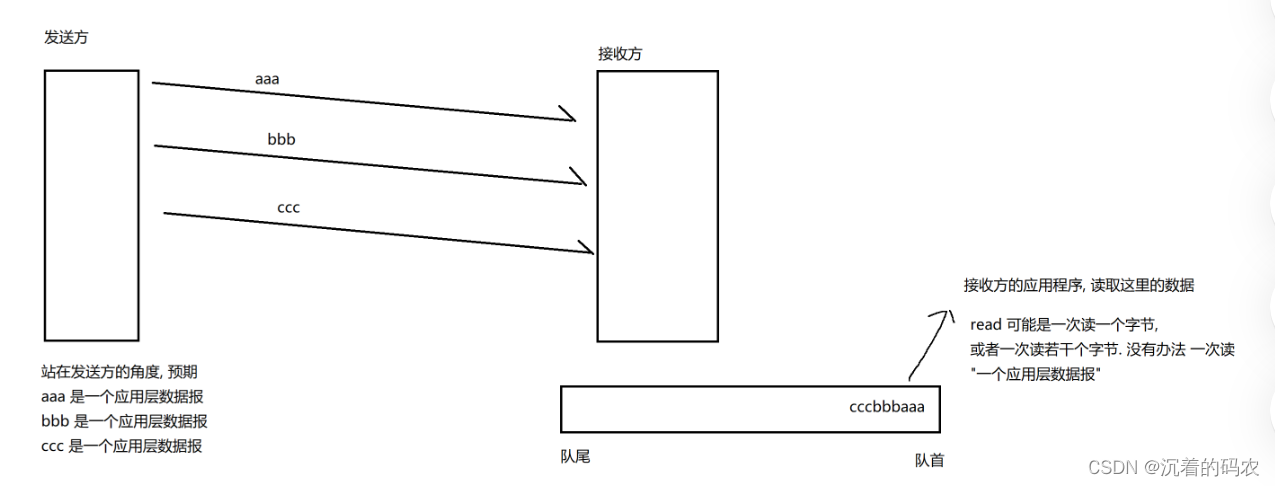
【Java】传输层协议TCP
传输层协议TCP TCP报文格式首部长度保留位32位序列号和32位确认应答号标记ACKSYNFINRSTURGPSH 16位窗口大小16位校验和16位紧急指针选项 TCP特点可靠传输实现机制-确认应答超时重传连接管理机制三次握手四次挥手特殊情况 滑动窗口流量控制拥塞控制延迟应答捎带应答面向字节流粘…...
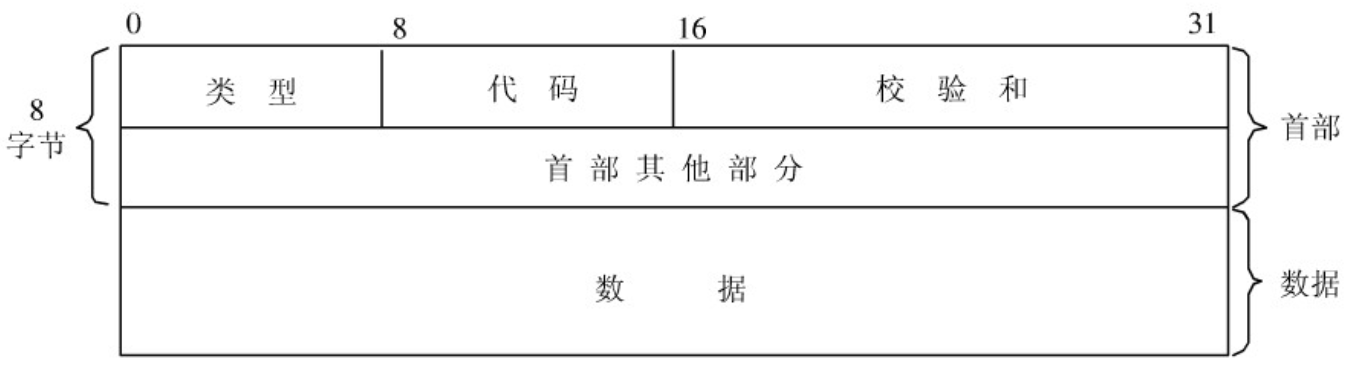
计算机网络基础知识(非常详细)
1. 网络模型 1.1 OSI 七层参考模型 七层模型,亦称 OSI(Open System Interconnection)参考模型,即开放式系统互联,是网络通信的标准模型。一般称为 OSI 参考模型或七层模型。 它是一个七层的、抽象的模型体ÿ…...

如何进行SEO优化数据分析?(掌握正确的数据分析方法,让您的网站更上一层楼!)
在互联网时代,SEO优化已经成为了每一个网站运营者必备的技能。而在SEO优化中,数据分析更是至关重要的一环。在本文中,我们将会详细介绍如何正确的进行SEO优化数据分析,让您的网站更上一层楼! 数据分析的重要性 数据分…...

Golang不同平台编译的思考
GOOS和GOARCH $GOOS可选值如下: darwin dragonfly freebsd linux netbsd openbsd plan9 solaris windows $GOARCH可选值如下 386 amd64 arm 在编译的时候我们可以根据实际需要对这两个参数进行组合。更详细的说明可以进官网看看 ## http://golang.org/cmd/go http…...

SpringSecurity学习
1.认证 密码校验用户 密码加密存储 Configuration public class SecurityConfig extends WebSecurityConfigurerAdapter {Beanpublic PasswordEncoder passwordEncoder(){return new BCryptPasswordEncoder();}} 我们没有这个配置,默认明文存储, {id}password;实现…...
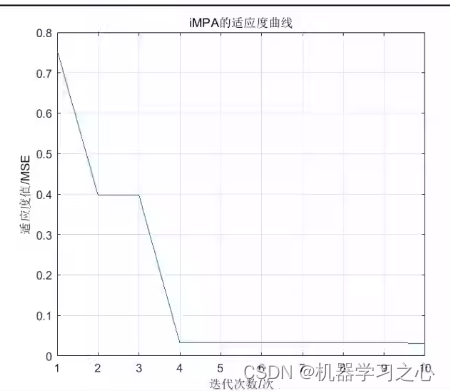
时序预测 | MATLAB实现ICEEMDAN-iMPA-BiLSTM时间序列预测
时序预测 | MATLAB实现ICEEMDAN-iMPA-BiLSTM时间序列预测 目录 时序预测 | MATLAB实现ICEEMDAN-iMPA-BiLSTM时间序列预测预测效果基本介绍程序设计参考资料 预测效果 基本介绍 ICEEMDAN-iMPA-BiLSTM功率/风速预测 基于改进的自适应经验模态分解改进海洋捕食者算法双向长短期记忆…...

国风美学生成模型v1.0硬件指南:STM32在交互装置中触发模型生成的联动设计
国风美学生成模型v1.0硬件指南:STM32在交互装置中触发模型生成的联动设计 你有没有想过,用毛笔在砚台上轻轻一磨,就能“磨”出一幅由AI创作的国风山水画?或者,在实体竹简上刻下几笔,就能触发AI生成一首古风…...

看门狗技术原理与双模架构工程实践
1. 看门狗技术原理与工程本质看门狗(Watchdog Timer,WDT)并非字面意义上的“犬类守护者”,而是一种经过严格工程定义的硬件级故障检测与恢复机制。其核心价值不在于“看守”系统,而在于以确定性时间约束为判据…...
)
工业视觉新选择:onsemi HiSPi接口在PCB缺陷检测中的实战应用(含配置指南)
工业视觉新选择:onsemi HiSPi接口在PCB缺陷检测中的实战应用(含配置指南) 在工业4.0时代,PCB制造对缺陷检测的精度和效率要求日益严苛。传统检测系统常受限于接口带宽和稳定性,而onsemi HiSPi(High-Speed P…...

OneWireFB:面向工业级可靠性的嵌入式单总线帧缓冲驱动框架
1. OneWireFB 库概述OneWireFB(One-Wire Frame Buffer)是一个面向嵌入式系统的轻量级、无阻塞、可重入的单总线(1-Wire)设备驱动框架,专为 STM32 等 Cortex-M 微控制器平台设计。其核心目标并非简单封装 Dallas/Maxim …...

DeepSeek-R1-Distill-Llama-8B快速上手:Jupyter Notebook原生Ollama内核集成
DeepSeek-R1-Distill-Llama-8B快速上手:Jupyter Notebook原生Ollama内核集成 1. 模型介绍:推理新星登场 DeepSeek-R1-Distill-Llama-8B是DeepSeek团队推出的新一代推理模型,专门针对数学推理、代码生成和逻辑推理任务进行了深度优化。 这个…...

云容笔谈·东方红颜影像生成系统LaTeX技术文档自动插图实战
云容笔谈东方红颜影像生成系统LaTeX技术文档自动插图实战 你有没有过这样的经历?辛辛苦苦写完一份几十页的技术文档,内容详实,逻辑清晰,但最终生成的PDF却是一片“白纸黑字”,除了代码块就是公式,看起来枯…...

使用MATLAB进行生成图像的后处理与分析:以Flux.1-Dev深海幻境输出为例
使用MATLAB进行生成图像的后处理与分析:以Flux.1-Dev深海幻境输出为例 1. 引言 最近,像Flux.1-Dev这样的图像生成模型越来越火,它们能根据文字描述创造出令人惊叹的视觉作品,比如“深海幻境”这类充满想象力的场景。作为一名工程…...

Qwen3-VL:30B效果展示:飞书内上传电商主图,自动识别卖点、生成标题与营销文案
Qwen3-VL:30B效果展示:飞书内上传电商主图,自动识别卖点、生成标题与营销文案 想象一下:电商运营同学在飞书群里随手丢了一张新品主图,3秒后就能获得精准的商品卖点分析、吸引人的标题和完整的营销文案。这不是未来,而…...

差分进化算法实战:用Python和Matlab解决优化问题的5个经典案例
差分进化算法实战:用Python和Matlab解决优化问题的5个经典案例 在工程优化和科学研究中,我们常常需要寻找某个复杂问题的最优解——可能是最小化成本、最大化效率,或是找到一组最佳参数组合。传统优化方法在面对非线性、多峰或高维问题时往往…...

5大核心优势,立即掌握专业级3D点云标注工具labelCloud
5大核心优势,立即掌握专业级3D点云标注工具labelCloud 【免费下载链接】labelCloud 项目地址: https://gitcode.com/gh_mirrors/la/labelCloud labelCloud是一款专为计算机视觉工程师和研究人员设计的轻量级3D点云标注工具,能够高效生成用于3D目…...