Hugging Face实战-系列教程3:AutoModelForSequenceClassification文本2分类
🚩🚩🚩Hugging Face 实战系列 总目录
有任何问题欢迎在下面留言
本篇文章的代码运行界面均在notebook中进行
本篇文章配套的代码资源已经上传
下篇内容:
Hugging Face实战-系列教程4:padding与attention_mask
输出我们需要几个输出呢?比如说这个cls分类,我们做一个10分类,可以吗?对每一个词做10分类可以吗?预测下一个词是什么可以吗?是不是也可以!
在我们的NLP任务中,相比图像任务有分类有回归,NLP有回归这一说吗?我们要做的所有任务都是分类,就是把分类做到哪儿而已,不管做什么都是分类。
比如我们刚刚导入的两个英语句子,是对序列做情感分析,就是一个二分类,用序列做分类,你想导什么输出头,你就导入什么东西就可以了,简不简单?好简单是不是,上代码:
from transformers import AutoModelForSequenceClassification
checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
model = AutoModelForSequenceClassification.from_pretrained(checkpoint)
outputs = model(**inputs)
print(outputs.logits.shape)
导入一个序列分类的包,还是选择checkpoint这个名字,选择分词器,导入模型,将模型打印一下:
DistilBertForSequenceClassification(
(distilbert): DistilBertModel(
(embeddings): Embeddings(
(word_embeddings): Embedding(30522, 768, padding_idx=0)
(position_embeddings): Embedding(512, 768)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(transformer): Transformer(
(layer): ModuleList(
(0): TransformerBlock(
(attention): MultiHeadSelfAttention(
(dropout): Dropout(p=0.1, inplace=False)
(q_lin): Linear(in_features=768, out_features=768, bias=True)
(k_lin): Linear(in_features=768, out_features=768, bias=True)
(v_lin): Linear(in_features=768, out_features=768, bias=True)
(out_lin): Linear(in_features=768, out_features=768, bias=True)
)
(sa_layer_norm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(ffn): FFN(
(dropout): Dropout(p=0.1, inplace=False)
(lin1): Linear(in_features=768, out_features=3072, bias=True)
(lin2): Linear(in_features=3072, out_features=768, bias=True)
)
(output_layer_norm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
)
(1): TransformerBlock(
(attention): MultiHeadSelfAttention(
(dropout): Dropout(p=0.1, inplace=False)
(q_lin): Linear(in_features=768, out_features=768, bias=True)
(k_lin): Linear(in_features=768, out_features=768, bias=True)
(v_lin): Linear(in_features=768, out_features=768, bias=True)
(out_lin): Linear(in_features=768, out_features=768, bias=True)
)
(sa_layer_norm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(ffn): FFN(
(dropout): Dropout(p=0.1, inplace=False)
(lin1): Linear(in_features=768, out_features=3072, bias=True)
(lin2): Linear(in_features=3072, out_features=768, bias=True)
)
(output_layer_norm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
)
(2): TransformerBlock(
(attention): MultiHeadSelfAttention(
(dropout): Dropout(p=0.1, inplace=False)
(q_lin): Linear(in_features=768, out_features=768, bias=True)
(k_lin): Linear(in_features=768, out_features=768, bias=True)
(v_lin): Linear(in_features=768, out_features=768, bias=True)
(out_lin): Linear(in_features=768, out_features=768, bias=True)
)
(sa_layer_norm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(ffn): FFN(
(dropout): Dropout(p=0.1, inplace=False)
(lin1): Linear(in_features=768, out_features=3072, bias=True)
(lin2): Linear(in_features=3072, out_features=768, bias=True)
)
(output_layer_norm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
)
(3): TransformerBlock(
(attention): MultiHeadSelfAttention(
(dropout): Dropout(p=0.1, inplace=False)
(q_lin): Linear(in_features=768, out_features=768, bias=True)
(k_lin): Linear(in_features=768, out_features=768, bias=True)
(v_lin): Linear(in_features=768, out_features=768, bias=True)
(out_lin): Linear(in_features=768, out_features=768, bias=True)
)
(sa_layer_norm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(ffn): FFN(
(dropout): Dropout(p=0.1, inplace=False)
(lin1): Linear(in_features=768, out_features=3072, bias=True)
(lin2): Linear(in_features=3072, out_features=768, bias=True)
)
(output_layer_norm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
)
(4): TransformerBlock(
(attention): MultiHeadSelfAttention(
(dropout): Dropout(p=0.1, inplace=False)
(q_lin): Linear(in_features=768, out_features=768, bias=True)
(k_lin): Linear(in_features=768, out_features=768, bias=True)
(v_lin): Linear(in_features=768, out_features=768, bias=True)
(out_lin): Linear(in_features=768, out_features=768, bias=True)
)
(sa_layer_norm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(ffn): FFN(
(dropout): Dropout(p=0.1, inplace=False)
(lin1): Linear(in_features=768, out_features=3072, bias=True)
(lin2): Linear(in_features=3072, out_features=768, bias=True)
)
(output_layer_norm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
)
(5): TransformerBlock(
(attention): MultiHeadSelfAttention(
(dropout): Dropout(p=0.1, inplace=False)
(q_lin): Linear(in_features=768, out_features=768, bias=True)
(k_lin): Linear(in_features=768, out_features=768, bias=True)
(v_lin): Linear(in_features=768, out_features=768, bias=True)
(out_lin): Linear(in_features=768, out_features=768, bias=True)
)
(sa_layer_norm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(ffn): FFN(
(dropout): Dropout(p=0.1, inplace=False)
(lin1): Linear(in_features=768, out_features=3072, bias=True)
(lin2): Linear(in_features=3072, out_features=768, bias=True)
)
(output_layer_norm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
)
)
)
)
(pre_classifier): Linear(in_features=768, out_features=768, bias=True)
(classifier): Linear(in_features=768, out_features=2, bias=True)
(dropout): Dropout(p=0.2, inplace=False)
)
看看多了什么?前面我们说对每一个词生成一个768向量,最后就连了两个全连接层:
(pre_classifier): Linear(in_features=768, out_features=768, bias=True)
(classifier): Linear(in_features=768, out_features=2, bias=True)
(dropout): Dropout(p=0.2, inplace=False)
这个logits就是输出结果了:
print(outputs.logits.shape)
torch.Size([2, 2])
这个2*2表示的就是样本为2(两个英语句子),分类是2分类,但是我们需要得到最后的分类概率,再加上softmax:
import torch
predictions = torch.nn.functional.softmax(outputs.logits, dim=-1)
print(predictions)
dim=-1就是沿着最后一个维度进行计算,最后返回的就是概率值:
tensor([[1.5446e-02, 9.8455e-01], [9.9946e-01, 5.4418e-04]], grad_fn=SoftmaxBackward0)
概率知道了,类别的概率是什么呢?调一个内置的id to label配置:
model.config.id2label
{0: 'NEGATIVE', 1: 'POSITIVE'}
也就是说,第一个句子负面情感的概率为1.54%,正面的概率情感为98.46%
下篇内容:
Hugging Face实战-系列教程4:padding与attention_mask
相关文章:

Hugging Face实战-系列教程3:AutoModelForSequenceClassification文本2分类
🚩🚩🚩Hugging Face 实战系列 总目录 有任何问题欢迎在下面留言 本篇文章的代码运行界面均在notebook中进行 本篇文章配套的代码资源已经上传 下篇内容: Hugging Face实战-系列教程4:padding与attention_mask 输出我…...

《TCP/IP网络编程》阅读笔记--Socket类型及协议设置
目录 1--协议的定义 2--Socket的创建 2-1--协议族(Protocol Family) 2-2--Socket类型(Type) 3--Linux下实现TCP Socket 3-1--服务器端 3-2--客户端 3-3--编译运行 4--Windows下实现 TCP Socket 4-1--TCP服务端 4-2--TC…...

GitHub使用教程
GitHub使用教程 视频教程一:Github 新手够用指南 | 全程演示&个人找项目技巧放送_哔哩哔哩_bilibili 笔记: README.md编写教程:Typora官方免费版与入门教程__阿伟_的博客-CSDN博客 找开源项目的一些途径 • https://github.com/trendin…...
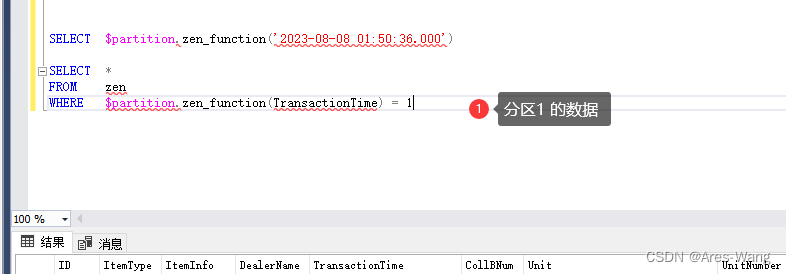
sql server 分区表
分区表 分区表是在SQL Server 2005之后的版本引入的特性,这个特性允许把逻辑上的一个表在物理上分为很多部分。换句话说,分区表从物理上看是将一个大表分成几个小表,但是从逻辑上看,还是一个大表。 步骤 创建分表区的步骤分为…...

开源许可证概述:GNU, BSD, Apache, MPL, 和 MIT
前言 开源许可证是开源软件分发的基础。它们定义了使用者如何使用,修改,分发开源软件。在这篇文章中,我们将探讨五种常见的开源许可证:GNU通用公共许可证 (GNU GPL),BSD许可证,Apache许可证,Mo…...

java中log使用总结
目录 一、概述1.1. 核心日志框架1.2 门面日志框架 二、最佳实践2.1 核心日志框架API包2.2 门面日志框架依赖2.3 集成使用2.3.1 集成jcl2.3.2 集成slf4j2.3.2.1 slf4j集成单一框架2.3.2.2 slf4j整合混合框架 三、总结3.1 所有相关包3.1.1 核心日志框架包3.1.2 门面日志框架3.1.3…...
【Java】传输层协议TCP
传输层协议TCP TCP报文格式首部长度保留位32位序列号和32位确认应答号标记ACKSYNFINRSTURGPSH 16位窗口大小16位校验和16位紧急指针选项 TCP特点可靠传输实现机制-确认应答超时重传连接管理机制三次握手四次挥手特殊情况 滑动窗口流量控制拥塞控制延迟应答捎带应答面向字节流粘…...
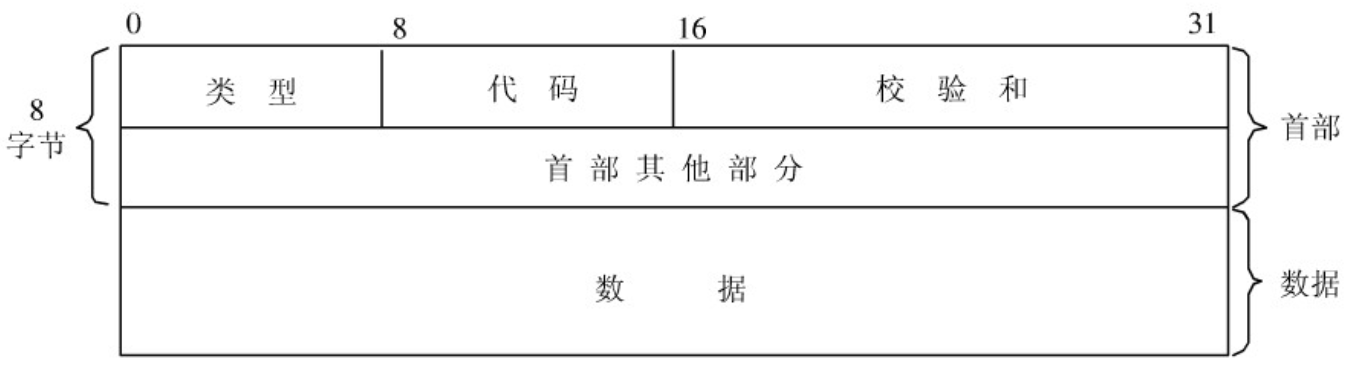
计算机网络基础知识(非常详细)
1. 网络模型 1.1 OSI 七层参考模型 七层模型,亦称 OSI(Open System Interconnection)参考模型,即开放式系统互联,是网络通信的标准模型。一般称为 OSI 参考模型或七层模型。 它是一个七层的、抽象的模型体ÿ…...

如何进行SEO优化数据分析?(掌握正确的数据分析方法,让您的网站更上一层楼!)
在互联网时代,SEO优化已经成为了每一个网站运营者必备的技能。而在SEO优化中,数据分析更是至关重要的一环。在本文中,我们将会详细介绍如何正确的进行SEO优化数据分析,让您的网站更上一层楼! 数据分析的重要性 数据分…...

Golang不同平台编译的思考
GOOS和GOARCH $GOOS可选值如下: darwin dragonfly freebsd linux netbsd openbsd plan9 solaris windows $GOARCH可选值如下 386 amd64 arm 在编译的时候我们可以根据实际需要对这两个参数进行组合。更详细的说明可以进官网看看 ## http://golang.org/cmd/go http…...

SpringSecurity学习
1.认证 密码校验用户 密码加密存储 Configuration public class SecurityConfig extends WebSecurityConfigurerAdapter {Beanpublic PasswordEncoder passwordEncoder(){return new BCryptPasswordEncoder();}} 我们没有这个配置,默认明文存储, {id}password;实现…...
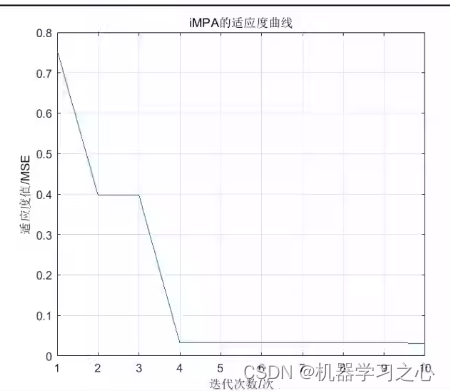
时序预测 | MATLAB实现ICEEMDAN-iMPA-BiLSTM时间序列预测
时序预测 | MATLAB实现ICEEMDAN-iMPA-BiLSTM时间序列预测 目录 时序预测 | MATLAB实现ICEEMDAN-iMPA-BiLSTM时间序列预测预测效果基本介绍程序设计参考资料 预测效果 基本介绍 ICEEMDAN-iMPA-BiLSTM功率/风速预测 基于改进的自适应经验模态分解改进海洋捕食者算法双向长短期记忆…...
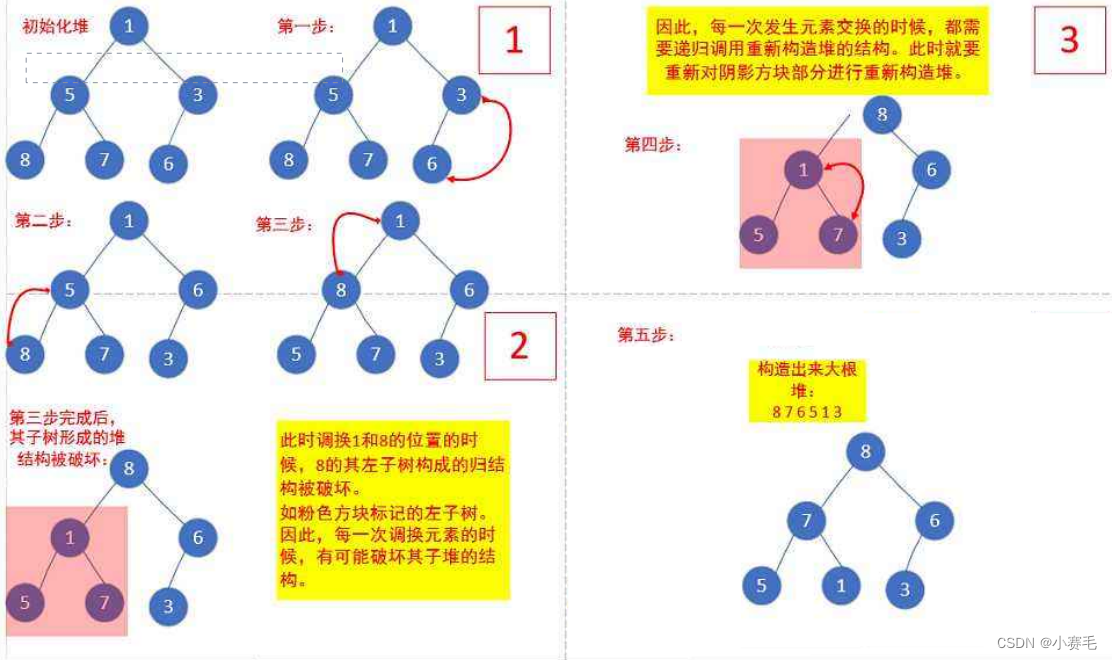
二叉树(上)
“路虽远,行则将至” ❤️主页:小赛毛 目录 1.树概念及结构 1.1树的概念 1.2 树的相关概念 1.3 树的表示(树的存储) 2.二叉树概念及结构 2.1概念 2.2现实中的二叉树 2.3 特殊的二叉树: 2.4 二叉树的性质 3.二叉树的顺…...
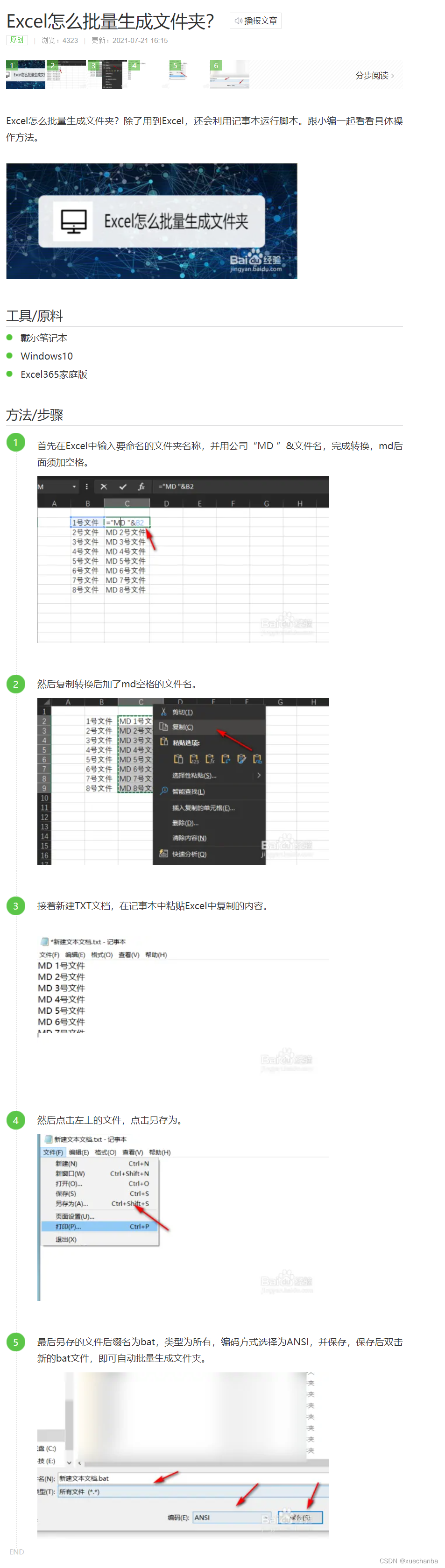
Excel怎么批量生成文件夹
Excel怎么批量生成文件夹的链接: https://jingyan.baidu.com/article/ea24bc398d9dcb9b63b3312f.html...

c++ 学习之 静态成员变量和静态成员函数
文章目录 前言正文静态成员变量初始化操作如何理解共享一份数据访问权限 静态成员函数访问方式静态成员函数只能访问静态成员变量访问权限 前言 静态成员分为 1)静态成员变量 所有对象共享一份数据在编译阶段分配空间类内声明,类外初始化 2)…...

C程序需要按下回车键才能读取字符
当编写涉及从终端输入字符的C程序时,有时会遇到需要按下回车键才能读取字符的问题。这是因为默认情况下,终端通常处于行缓冲模式,需要等待用户按下回车键才会将输入的字符发送给正在运行的程序。这可能会导致一些不便,尤其是当程序…...

x86体系结构(WinDbg学习笔记)
寄存器 eaxAccumulator累加器ebxBase register基寄存器ecxCounter register计数器寄存器edxData register - can be used for I/O port access and arithmetic functions数据寄存器-可用于I/O端口访问和算术函数esiSource index register源索引寄存器ediDestination index reg…...
Hadoop的第二个核心组件:MapReduce框架第四节
Hadoop的第二个核心组件:MapReduce框架 十、MapReduce的特殊应用场景1、使用MapReduce进行join操作2、使用MapReduce的计数器3、MapReduce做数据清洗 十一、MapReduce的工作流程:详细的工作流程第一步:提交MR作业资源第二步:运行M…...

算法通关村第十九关——最少硬币数
LeetCode322.给你一个整数数组 coins,表示不同面额的硬币,以及一个整数 amount,表示总金额。计算并返回可以凑成总金额所需的最少的硬币个数。如果没有任何一种硬币组合能组成总金额,返回-1。你可以认为每种硬币的数量是无限的。 示例1&…...
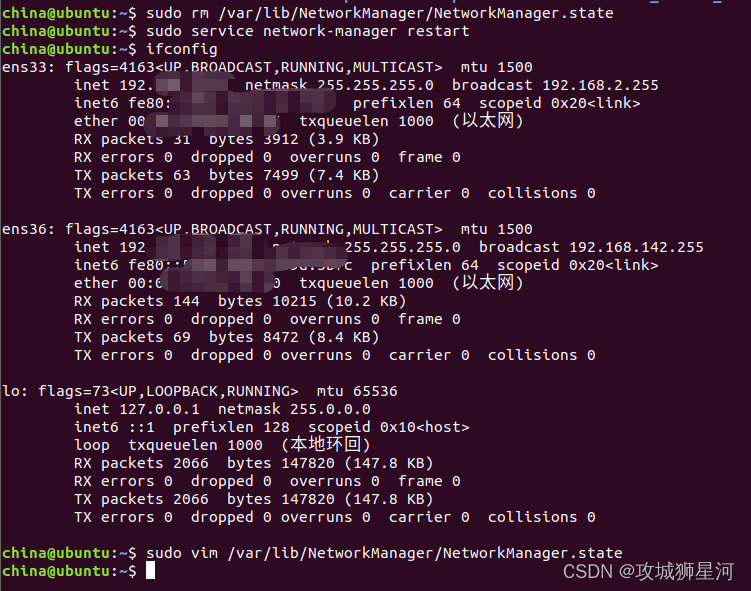
Linux ifconfig只显示 lo 网卡,没有ens网卡解决方案
项目场景: 虚拟机中linux无网络问题 问题描述 之前在调试linux的时候,由于一些不太清楚的误操作,导致ubuntu linux出现无网络问题,现象如下 ifconfig 只显示了 lo 网卡 lo 网卡:它是本地环回接口。 这意味着您的虚…...

生成xcframework
打包 XCFramework 的方法 XCFramework 是苹果推出的一种多平台二进制分发格式,可以包含多个架构和平台的代码。打包 XCFramework 通常用于分发库或框架。 使用 Xcode 命令行工具打包 通过 xcodebuild 命令可以打包 XCFramework。确保项目已经配置好需要支持的平台…...

19c补丁后oracle属主变化,导致不能识别磁盘组
补丁后服务器重启,数据库再次无法启动 ORA01017: invalid username/password; logon denied Oracle 19c 在打上 19.23 或以上补丁版本后,存在与用户组权限相关的问题。具体表现为,Oracle 实例的运行用户(oracle)和集…...

23-Oracle 23 ai 区块链表(Blockchain Table)
小伙伴有没有在金融强合规的领域中遇见,必须要保持数据不可变,管理员都无法修改和留痕的要求。比如医疗的电子病历中,影像检查检验结果不可篡改行的,药品追溯过程中数据只可插入无法删除的特性需求;登录日志、修改日志…...

基于Uniapp开发HarmonyOS 5.0旅游应用技术实践
一、技术选型背景 1.跨平台优势 Uniapp采用Vue.js框架,支持"一次开发,多端部署",可同步生成HarmonyOS、iOS、Android等多平台应用。 2.鸿蒙特性融合 HarmonyOS 5.0的分布式能力与原子化服务,为旅游应用带来…...

新能源汽车智慧充电桩管理方案:新能源充电桩散热问题及消防安全监管方案
随着新能源汽车的快速普及,充电桩作为核心配套设施,其安全性与可靠性备受关注。然而,在高温、高负荷运行环境下,充电桩的散热问题与消防安全隐患日益凸显,成为制约行业发展的关键瓶颈。 如何通过智慧化管理手段优化散…...

学校时钟系统,标准考场时钟系统,AI亮相2025高考,赛思时钟系统为教育公平筑起“精准防线”
2025年#高考 将在近日拉开帷幕,#AI 监考一度冲上热搜。当AI深度融入高考,#时间同步 不再是辅助功能,而是决定AI监考系统成败的“生命线”。 AI亮相2025高考,40种异常行为0.5秒精准识别 2025年高考即将拉开帷幕,江西、…...

【数据分析】R版IntelliGenes用于生物标志物发现的可解释机器学习
禁止商业或二改转载,仅供自学使用,侵权必究,如需截取部分内容请后台联系作者! 文章目录 介绍流程步骤1. 输入数据2. 特征选择3. 模型训练4. I-Genes 评分计算5. 输出结果 IntelliGenesR 安装包1. 特征选择2. 模型训练和评估3. I-Genes 评分计…...

Linux C语言网络编程详细入门教程:如何一步步实现TCP服务端与客户端通信
文章目录 Linux C语言网络编程详细入门教程:如何一步步实现TCP服务端与客户端通信前言一、网络通信基础概念二、服务端与客户端的完整流程图解三、每一步的详细讲解和代码示例1. 创建Socket(服务端和客户端都要)2. 绑定本地地址和端口&#x…...

TSN交换机正在重构工业网络,PROFINET和EtherCAT会被取代吗?
在工业自动化持续演进的今天,通信网络的角色正变得愈发关键。 2025年6月6日,为期三天的华南国际工业博览会在深圳国际会展中心(宝安)圆满落幕。作为国内工业通信领域的技术型企业,光路科技(Fiberroad&…...
django blank 与 null的区别
1.blank blank控制表单验证时是否允许字段为空 2.null null控制数据库层面是否为空 但是,要注意以下几点: Django的表单验证与null无关:null参数控制的是数据库层面字段是否可以为NULL,而blank参数控制的是Django表单验证时字…...