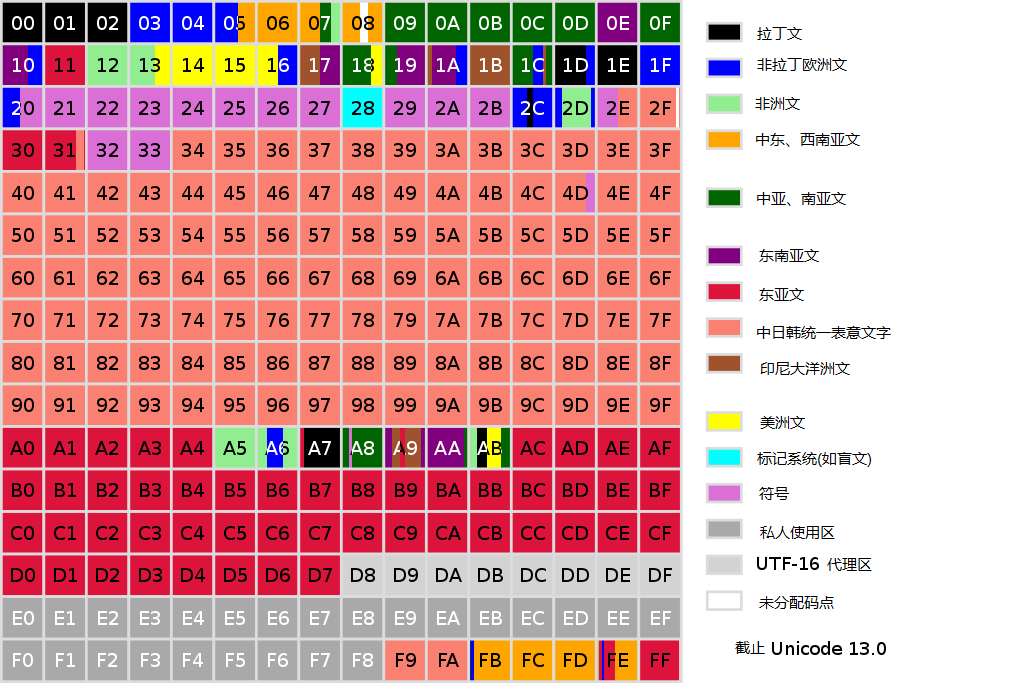
PostgreSQL本地化
本地化的概念
本地化的目的是支持不同国家、地区的语言特性、规则。比如拥有本地化支持后,可以使用支持汉语、法语、日语等等的字符集。除了字符集以外,还有字符排序规则和其他语言相关规则的支持,例如我们知道(‘a’,‘b’)该如何排序,那么(‘a’,‘A’)和(‘啊’,‘阿’)又该如何排序?
如果通过google去搜本地化、字符集、collation相关信息,可能会得到一些复杂又遥远的知识。最好的老师还是
本地化知识点总共分为3个部分:locale本地化支持、collation校验、字符集。
locale
pg的本地化由由操作系统提供,需要检查操作系统是否支持locale -a。在初始化数据库时可指定locale
initdb --locale=en_US
也可以单独设置本地化子类:字符串排序、字符归类方法、数值格式、日期格式、时间格式、货币格式等
initdb --locale=zh_CN --lc-monetary=en_US
所有本地化子类:
| 本地化子类 | 规则 |
|---|---|
| LC_COLLATE | String sort order |
| LC_CTYPE | Character classification (What is a letter? Its upper-case equivalent?) |
| LC_MESSAGES | Language of messages |
| LC_MONETARY | Formatting of currency amounts |
| LC_NUMERIC | Formatting of numbers |
| LC_TIME | Formatting of dates and times |
这些子类又可以分为两部分,其中lc_messages,lc_monetary,lc_numeric,lc_time在初始化后,可以通过参数进行调整。LC_COLLATE,LC_CTYPE属于collation,详见collation的调整。
locale设置会影响如下行为:
- Sort order in queries using
ORDER BYor the standard comparison operators on textual data - The
upper,lower, andinitcapfunctions - Pattern matching operators (
LIKE,SIMILAR TO, and POSIX-style regular expressions); locales affect both case insensitive matching and the classification of characters by character-class regular expressions - The
to_charfamily of functions - The ability to use indexes with
LIKEclauses
COLLATION
collation是字符排序的顺序和字符分类行为。一些数据库操作符依赖collation,比如order by、lower, upper、initcap 、to_char等等。
使用如下SQL查询系统表pg_collation,来获取字符集支持的LC_COLLATE和LC_CTYPE信息
select pg_encoding_to_char(collencoding) as encoding,collname,collcollate,collctype from pg_collation where collname in ('default','C','POSIX','en_US.utf8','zh_CN.utf8','zh_CN.gb2312','zh_SG.gb2312') ;encoding | collname | collcollate | collctype
----------+--------------+--------------+--------------| default | | | C | C | C| POSIX | POSIX | POSIXUTF8 | en_US.utf8 | en_US.utf8 | en_US.utf8EUC_CN | zh_CN.gb2312 | zh_CN.gb2312 | zh_CN.gb2312UTF8 | zh_CN.utf8 | zh_CN.utf8 | zh_CN.utf8EUC_CN | zh_SG.gb2312 | zh_SG.gb2312 | zh_SG.gb2312
encoding是字符集,collname为collation的名字
- encoding 为空时,表示这个 collation 支持所有的字符集
default,C,POSIX是所有平台都支持的collation,由libc提供,其他collation取决于操作系统是否支持(locale -a)- default表示使用建库时的collation,可通过\l查看
C语义上等价于POSIX,但是PG仍然认为他们是不同的collation。他们的字符都以ASCII码对比,严格按照字节序比对大小。
=> SELECT 'a' COLLATE "C" < 'b' COLLATE "POSIX" ;
ERROR: 42P21: collation mismatch between explicit collations "C" and "POSIX"
LINE 1: SELECT 'a' COLLATE "C" < 'b' COLLATE "POSIX" ;
LOCATION: merge_collation_state, parse_collate.c:834
- UTF8是最常见的字符集,我们最常见的语言环境是en_US和zh_CN
- 可以通过
CREATE COLLATION ...创建自定义的collation。不过LC_COLLATE和LC_CTYPE不同的情况非常少见
LC_COLLATE
LC_COLLATE影响字符比对(排序、字符操作等等)
collate子句可以转化表达式的collation:
expr COLLATE collation
注意这里指定的是collation,不是lc_collate。如果没有显示指定collation,数据库默认使用字段的collation,如果字段没有指定collation,使用database的默认collation。
不同的collation排序测试:
select col1 from (values ('a'), ('A'), ('啊'), ('阿'))
-> AS l(col1)
-> order by col1 collate "C";col1
------Aa啊阿select col1 from (values ('a'), ('A'), ('啊'), ('阿'))
-> AS l(col1)
-> order by col1 collate "en_US.utf8";col1
------aA啊阿select col1 from (values ('a'), ('A'), ('啊'), ('阿'))
-> AS l(col1)
-> order by col1 collate "zh_CN.utf8";col1
------aA阿啊
这3个不同的collation有不同的lc_collate,排序方法应该是不一样的,从结果来看确实是不一样的,出现了3种排序结果。
collation C为什么A<a?
collation C使用的ASCII的编码顺序,ASCII码中大写在小写前面。而en_US.utf8和zh_CN.utf8的英文字母明显不是这个顺序
中文的顺序
同样是utf8字符集,中文环境和英文环境的中文顺序不一样。不同的lc_collate对于不同本地化语言,应该都可以对应到不同的alphabets。其中,lc_collate=C的排序一定是按字节序排的,虽然ASCII没有中文,但是C也可以排序中文,(基本)每个中文都可以对应UTF8的一个编码,而C以其字节序排序。
LC_CTYPE
LC_CTYPE影响字符操作(如upper、initcap等)
如果字符串都是英文,比如是’abcD’,initcap在3种collation下都会转换为’Abcd’,这里不多展示了。
但是加入中文,结果就不一样了:
select initcap('啊aAAa阿bBBb' collate "C");initcap
--------------啊Aaaa阿Bbbbselect initcap('啊aAAa阿aAAa' collate "en_US.utf8");initcap
--------------啊aaaa阿aaaaselect initcap('啊aAAa阿aAAa' collate "zh_CN.utf8");initcap
--------------啊aaaa阿aaaa
LC_CTYPE=C时,initcap把每个非连续英文字符串的首字母大写,而en_US.utf8和zh_CN.utf8只会将首个字符大写(中文就不会变),其他英文字符小写。
initcap中文也许处于需求不明的状况,但是我们可以得出结论:不同的LC_CTYPE会导致initcap等字符敏感函数结果不一样。
另外,中文对于大小写不敏感,一些其他本地化语言同样有大小写,不同的LC_CTYPE导致的结果会更复杂。
字符集
字符集基础
PostgreSQL支持不同的字符集character sets(也叫encodings)。字符集于collation是两个概念,但是字符集必须跟LC_CTYPE,LC_COLLATE兼容。就像在pg_collation中看到的那样,C/POSIX支持所有字符集,而其他collation只支持一种字符集(linux系统中)。
PostgreSQL中文相关可用的字符集:
(*collation C由libc库提供,部分collation可以由ICU库提供,需提前编译)
| Name | Description | Language | Server端是否支持? | ICU是否支持? | Bytes/Char | Aliases |
|---|---|---|---|---|---|---|
| BIG5 | Big Five | 繁体中文 | No | No | 1–2 | WIN950, Windows950 |
| EUC_CN | Extended UNIX Code-CN | 简体中文 | Yes | Yes | 1–3 | GB2312 |
| GB18030 | National Standard | 中文 | No | No | 1–4 | |
| GBK | Extended National Standard | 简体中文 | No | No | 1–2 | WIN936, Windows936 |
| UTF8 | Unicode, 8-bit | all | Yes | Yes | 1–4 | Unicode |
繁体中文:
BIG5是最常见的繁体中文字符集标准。之前是业界标准,后来被录入为国家标准。
简体中文:
GB是国标的意思,GB2312、GB18030、GBK都是我国的国家字符集标准。由于生僻字等问题,并经过多年发展产生了一些历史版本,所以标准看上去有多个。
其中EUC_CN全称为 Extended UNIX Code-CN ,其实就是GB2312,但它也不能处理所有罕见字。类似命名的还有EUC_KR,EUC_JP,EUC_TW等等。
国际标准:
上面的字符集都是国家标准,他们除了支持英、中外不支持其他语言。而国际标准支持世界上所有语言,这就是unicode国际编码标准(甚至emoji也包含其中 👍)。(还有个著名的国际标准组织ISO也在维护字符集,他俩有交集,这里先忽略ISO)。
由于Unicode编码方案的不同又有UTF-8、UTF-16、UTF-32三种编码方式。
UTF-8编码格式:
| 字节 | 格式 | 实际编码位 | 码点范围 |
|---|---|---|---|
| 1字节 | 0xxxxxxx | 7 | 0 ~ 127 |
| 2字节 | 110xxxxx 10xxxxxx | 11 | 128 ~ 2047 |
| 3字节 | 1110xxxx 10xxxxxx 10xxxxxx | 16 | 2048 ~ 65535 |
| 4字节 | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx | 21 | 65536 ~ 2097151 |
UTF8编码是变长的。
0x00-0x7F之间的字符(1字节),UTF-8编码与ASCII(American Standard Code for Information Interchange 美国标准信息交换代码)编码完全相同,所以UTF-8是完全兼容ASCII的。
由于同源、同义、相似性,在unicode中中日韩越使用了同一编码,称为中日韩统一表意文字(或称中日韩越统一表意文字)。
中日韩统一表意文字编码范围为:3400-4DBF/4E00-9FFF/20000-3FFFF
字符集转换
server_encoding与client_encoding不一致,可发生自动转换Server查出来的字符集。设置服务端字和客户端字符集参考设置字符集一节。
中文相关字符集Server/Client可转化表:
| Server Character Set | Available Client Character Sets |
|---|---|
| BIG5 | not supported as a server encoding |
| EUC_CN(GB2312) | EUC_CN(GB2312), MULE_INTERNAL, UTF8 |
| GB18030 | not supported as a server encoding |
| GBK | not supported as a server encoding |
| UTF8 | all supported encodings |
| GB18030,GBK服务端都不支持,所以其实只有EUC_CN(GB2312)、UTF8能在Server/Client转换。 |
以上是可以转换的字符集,仍需要CONVERSATION的支持。PG内置了一些转换函数,可通过pg_conversion查看:
| Conversion Name | Source Encoding | Destination Encoding |
|---|---|---|
| big5_to_utf8 | BIG5 | UTF8 |
| euc_cn_to_utf8 | EUC_CN | UTF8 |
| gb18030_to_utf8 | GB18030 | UTF8 |
| gbk_to_utf8 | GBK | UTF8 |
| utf8_to_big5 | UTF8 | BIG5 |
| utf8_to_euc_cn | UTF8 | EUC_CN |
| utf8_to_gb18030 | UTF8 | GB18030 |
| utf8_to_gbk | UTF8 | GBK |
可通过create conversation语句创建自定义的转换,需指定转换的function。
有些字符集间看上去可以转换,但是server端根本不支持存储这些字符集(如big5、gb18030、gbk),所以也没啥用。我们这里仅需要知道euc_cn和utf8能相互转换就可以了。
没有CONVERSATION是不能发生转换的:
--EUC_CN的database
=> \encoding EUC_KR
EUC_KR: invalid encoding name or conversion procedure not found
字符集转换测试:
需要注意客户端的字符集设置(如CRT的 “session”-“Appearance”-“Character encoding”)
至少有3个端有字符集的概念:数据库server、数据库client、UI客户端。CONVERSATION也只能控制:数据库server -> 数据库client
1.server为UTF8的转换测试:
create table zh(col1 varchar(20));
insert into zh values('>'),('阿'),('〇'); --〇 ling是一个中文
--CRT不设置为UTF8中文全是乱码,只有CRT设置UTF8来插入=> show server_encoding;server_encoding
-----------------UTF8
=> show client_encoding;client_encoding
-----------------UTF8
--完全没有转换的情况下,UTF8正常展示。此时3端字符集为:UTF8 - UTF8 - UTF8
=> select * from zh;col1
------>阿〇--切换数据库client字符集,此时3端字符集为:UTF8 - EUC_CN - UTF8
=> \encoding EUC_CN; --设置客户端字符集=> select * from zh where col1 in ('阿');
ERROR: 22021: invalid byte sequence for encoding "EUC_CN": 0xe9 0x98
LOCATION: report_invalid_encoding, mbutils.c:1597
Time: 0.112 ms
=> select * from zh where col1 in ('〇');
ERROR: 22021: invalid byte sequence for encoding "EUC_CN": 0xe3 0x80
ERROR: 22021: invalid byte sequence for encoding "EUC_CN": 0xe3 0x80
--“阿”和“〇”看上去不能转换为EUC_CN,但不是这样的=> select * from zh limit 2;col1
------><B0><A2>
(2 rows)
--第二行即是"阿",数据库server/client看上去转换了字符集,从UTF8转换为了EUC_CN
--但是可能是因为UI客户端问题没有正确显示(此时UI客户端CRT为UTF8)--然而把CRT改成GB2312还是不会正确展示
select * from zh limit 2;col1
------><B0><A2>
(2 rows)--当查询〇时,数据库直接抛出报错,说明〇不能从UTF8转换为EUC_CN
select * from zh ;
ERROR: 22P05: character with byte sequence 0xe3 0x80 0x87 in encoding "UTF8" has no equivalent in encoding "EUC_CN"
LOCATION: report_untranslatable_char, mbutils.c:1631
2.server为EUC_CN的转换测试:
=> show server_encoding; --database为EUC_CN字符集
server_encoding
-----------------
EUC_CN--在EUC_CN库下同样创建一个zh表,此时尝试插入就有问题了
=> insert into zh values('〇');
ERROR: 22P05: character with byte sequence 0xe3 0x80 0x87 in encoding "UTF8" has no equivalent in encoding "EUC_CN"
LOCATION: report_untranslatable_char, mbutils.c:1631
同样报错〇不能从UTF8转换为EUC_CN。EUC_CN(GB2312)中文编码不完全与UTF8相同,EUC_CN(GB2312)不是所有中文都包含的,特别是罕见字。
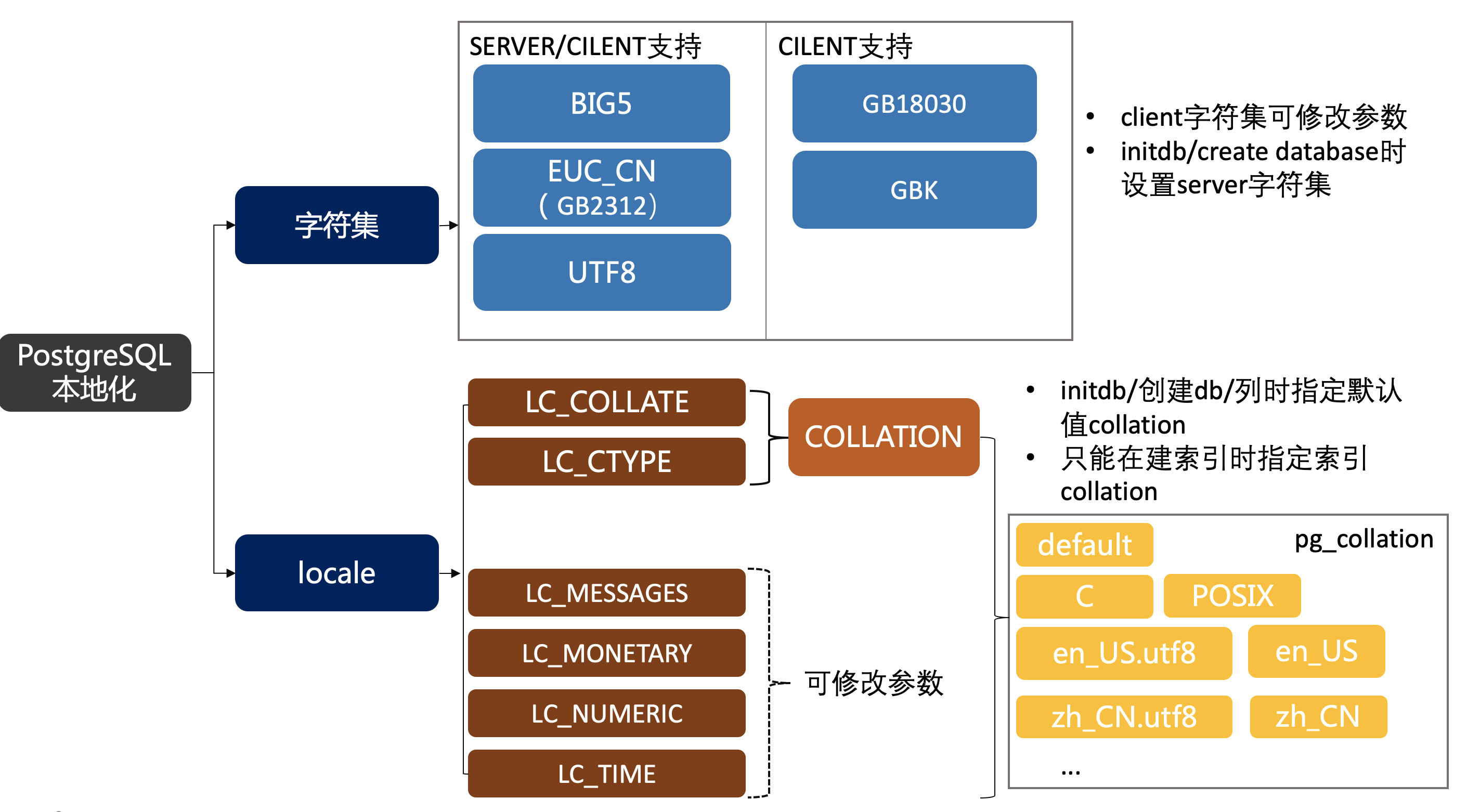
设置locale、collation和字符集
上面已经了解过本地化和字符集设置了,这里做一个汇总
database cluster的locale、collation、字符集
初始化时可设置database cluster的locale和字符集,参考:
initdb -D $DATADIR -E UTF8 --locale=en_US.UTF8
initdb -D $DATADIR -E UTF8 --locale=en_US.UTF8 --lc_collate=C --lc_ctype=C
initdb -D $DATADIR -E UTF8 --locale=en_US.UTF8 --lc_collate=C --lc_ctype=C --lc-messages=en_US.UTF8 --lc-monetary=en_US.UTF8 --lc-numeric=en_US.UTF8 --lc-time=en_US.UTF8
initdb会创建postgres,template1,和template0三个库。create database语句时默认使用template1创建库。
-
encoding设置字符集;locale设置LC_COLLATE,LC_CTYPE,LC_MESSAGES,LC_MONETARY,LC_NUMERIC,LC_TIME,除非特别指定(如–lc_collate)
-
LC_COLLATE,LC_CTYPE称为collation,还可在database、列、索引上设置。LC_MESSAGES,LC_MONETARY,LC_NUMERIC,LC_TIME为实例参数,可随时修改。
-
encoding只能在初始化、创建database时设置,一旦设置不可修改。
database的collation、字符集
创建database时可设置database的字符集、lc_collate、lc_ctype。
create database ,createdb都可以在创建database时指定字符集,一旦创建就不能修改database的字符集。两个命令都是使用template库来创建database
template又有template0和template1,官方文档有这样一句话:
Another common reason for copying
template0instead oftemplate1is that new encoding and locale settings can be specified when copyingtemplate0, whereas a copy oftemplate1must use the same settings it does. This is becausetemplate1might contain encoding-specific or locale-specific data, whiletemplate0is known not to.
template1是可写数据的模板库,可能包含本地化过的数据,而template0不能写数据,所以要创建不同的本地化库应使用template0。
而且要显示使用template0,因为不指定的话默认是template1。所以在创建database时没有指定template1且指定其他字符集会报错:
=> create database db_GB2312 ENCODING 'EUC_CN' LC_COLLATE 'zh_CN.gb2312' LC_CTYPE 'zh_CN.gb2312';
ERROR: 22023: new encoding (EUC_CN) is incompatible with the encoding of the template database (UTF8)
HINT: Use the same encoding as in the template database, or use template0 as template.
另外,不能在创建database时通过指定locale来设置字符集
=> create database db_GB2312 locale 'zh_CN.gb2312' template 'template0';
ERROR: 22023: encoding "UTF8" does not match locale "zh_CN.gb2312"
DETAIL: The chosen LC_CTYPE setting requires encoding "EUC_CN".
LOCATION: check_encoding_locale_matches, dbcommands.c:773
报错表示需要指定LC_CYTPE子选项,把collation相关子选项全部加上仍然报错:
=> create database db_GB2312 LOCALE 'EUC_CN' LC_COLLATE 'zh_CN.gb2312' LC_CTYPE 'zh_CN.gb2312';
ERROR: 42601: conflicting or redundant options
DETAIL: LOCALE cannot be specified together with LC_COLLATE or LC_CTYPE.
LOCALE又不能跟LC_CTYPE等子选项一起使用
然后把locale去掉,通过设置字符集、LC_COLLATE、LC_CTYPE 来设置,可以成功。
创建指定字符集的database的正确姿势:
- create database
create database db_GB2312 ENCODING 'EUC_CN' LC_COLLATE 'zh_CN.gb2312' LC_CTYPE 'zh_CN.gb2312' template 'template0';
- createdb
通过cli命令createdb来创建,createdb封装了create database,他俩是等价的:
createdb -E EUC_CN -T template0 --lc-collate=zh_CN.gb2312 --lc-ctype=zh_CN.gb2312 db_GB2312
查看database字符集:
-
\l -
pg_database
select datname,pg_encoding_to_char(encoding),datcollate,datctype,datlocprovider,daticulocale from pg_database;
- show参数
SERVER_ENCODING,LC_COLLATE,LC_CTYPE三个参数都是不可更改的,分别展示当前database的server端字符集、LC_COLLATE、LC_CTYPE
列的collation
collation只跟字符排序、字符函数相关,跟编码不相关。在没有索引的情况下,修改列的collation相当于只是在调整这个列的default排序输出,有索引的情况下会重建索引。不指定列的collation默认与database一致。
建表时指定collation:(注意有些字段类型是un-collatable的,比如int)
create table t1(col1 varchar(10) collate "en_US.utf8");
alter table t1 alter column col1 type varchar(10) collate "C";
注意:alter table不修改长度是不会重建表的,但是一定会重建索引
查看列的默认collation:
1. \d+ t12. information_schema.columns
select table_catalog,table_schema,table_name,column_name,collation_name from information_schema.columns where table_name='t1';3. pg_attribute
select a.attrelid::regclass,a.attname,a.attcollation,c.collname,c.collcollate,c.collctype from pg_attribute a left join pg_collation c on a.attcollation=c.oid where a.attrelid::regclass='tlzl'::regclass and a.attcollation<>0;
推荐方式3查看。\d+ ,information_schema.columns虽然能看到collname,但是collname不是唯一的。只有方式3可以看到collate,ctype
指定collate和查看pg_attribute的测试:
create table tlzl(col1 varchar(10) ,col2 varchar(10) collate "C",col3 varchar(10) collate "zh_CN",col4 varchar(10) collate "en_US.utf8"
);
--列的collation相当于给列打上默认排序的标记,也看不到具体是哪个collate和ctype
db_utf8_c=> Table "public.tlzl"Column | Type | Collation | Nullable | Default | Storage | Compression | Stats target | Description
--------+-----------------------+------------+----------+---------+----------+-------------+--------------+-------------col1 | character varying(10) | | | | extended | | | col2 | character varying(10) | C | | | extended | | | col3 | character varying(10) | zh_CN | | | extended | | | col4 | character varying(10) | en_US.utf8 | | | extended | | |
--collname和collate,ctype不是一一对应的,上面的col3 zh_CN看不出来collate是哪个
db_utf8_c=> select pg_encoding_to_char(collencoding) as encoding,collname,collcollate,collctype from pg_collation where collname like 'zh_CN%';encoding | collname | collcollate | collctype
----------+--------------+--------------+--------------EUC_CN | zh_CN | zh_CN | zh_CNEUC_CN | zh_CN.gb2312 | zh_CN.gb2312 | zh_CN.gb2312UTF8 | zh_CN.utf8 | zh_CN.utf8 | zh_CN.utf8UTF8 | zh_CN | zh_CN.utf8 | zh_CN.utf8--pg_attribute展示比\d+准确
db_utf8_c=> select a.attrelid::regclass,a.attname,a.attcollation,c.collname,c.collcollate,c.collctype from pg_attribute a left join pg_collation c on a.attcollation=c.oid where a.attrelid::regclass='tlzl'::regclass and a.attcollation<>0;attrelid | attname | attcollation | collname | collcollate | collctype
----------+---------+--------------+------------+-------------+------------tlzl | col1 | 100 | default | | tlzl | col2 | 950 | C | C | Ctlzl | col4 | 12562 | en_US.utf8 | en_US.utf8 | en_US.utf8tlzl | col3 | 13200 | zh_CN | zh_CN.utf8 | zh_CN.utf8
--此时才知道,col3 zh_CN的collate是zh_CN.utf8
修改列的collate重写测试:
--给字段加索引,看看重写情况
db_utf8_c=> create index idxcol4 on tlzl(col4);
CREATE INDEXdb_utf8_c=> select pg_relation_filepath('tlzl') TableRelid, pg_relation_filepath('idxcol4') IndexRelid; tablerelid | indexrelid
------------------+------------------base/40996/41006 | base/40996/41015db_utf8_c=> alter table tlzl alter column col4 type varchar(10) collate "C";
ALTER TABLE
db_utf8_c=> select pg_relation_filepath('tlzl') TableRelid, pg_relation_filepath('idxcol4') IndexRelid; tablerelid | indexrelid
------------------+------------------base/40996/41006 | base/40996/41016
--表没有重写,索引重写了
列的collation只是标记,修改列的collation不会重写表,但是如果其上有索引,那么会重写这个索引(有时候不会见下面一节)。
索引的collation
在创建索引时,如不显示指定索引的collation,那么索引会使用列上声明的collation。
创建索引时显示使用collation:
create index idx_C on tlzl(col3 collate "C");
另外,索引还可以以text_pattern_ops,varchar_pattern_ops,bpchar_pattern_ops来创建,此时的索引不依赖collation的规则,而是一个字符一个字符的对比
The difference from the default operator classes is that the values are compared strictly character by character rather than according to the locale-specific collation rules.
CREATE INDEX test_index ON test_table (col varchar_pattern_ops);
其实这种索引跟collation不是完全无关,索引一定有一个排序规则,这种索引的排序规则看上去跟C一致。参考like不走索引一节
查看索引的collation:
\d+ --\d+会展示指定过collate的索引,如果没有的话使用的是列默认索引
db_utf8_c=> \d+ tlzlTable "public.tlzl"Column | Type | Collation | Nullable | Default | Storage | Compression | Stats target | Description
--------+-----------------------+------------+----------+---------+----------+-------------+--------------+-------------col1 | character varying(10) | | | | extended | | | col2 | character varying(10) | C | | | extended | | | col3 | character varying(10) | zh_CN | | | extended | | | col4 | character varying(10) | en_US.utf8 | | | extended | | |
Indexes:"idx_c" btree (col3 COLLATE "C")"idxcol4" btree (col4)
Access method: heap通过pg_index查看更为清晰:(pg_index的indcollation类型是oidvector的,不能直接转化为oid,查起来麻烦点)
db_utf8_c=> select indcollation,indexrelid::regclass from pg_index where indexrelid::regclass ='idx_C'::regclass;indcollation | indexrelid
--------------+------------950 | idx_cdb_utf8_c=> select oid,pg_encoding_to_char(collencoding) as encoding,collname,collcollate,collctype from pg_collation where oid=950;oid | encoding | collname | collcollate | collctype
-----+----------+----------+-------------+-----------950 | | C | C | C
另外,不能通过alter index改变索引的collation,只能删除重建
测试:指定过索引collate后,修改列的collate是否会重写索引?
db_utf8_c=> select pg_relation_filepath('tlzl') TableRelid, pg_relation_filepath('idxcol4') IndexRelid4,pg_relation_filepath('idx_c') IndexRelidC; tablerelid | indexrelid4 | indexrelidc
------------------+------------------+------------------base/40996/41020 | base/40996/41023 | base/40996/41024
(1 row)db_utf8_c=> alter table tlzl alter column col3 type varchar(10) collate "en_US.utf8";
ALTER TABLE
db_utf8_c=> select pg_relation_filepath('tlzl') TableRelid, pg_relation_filepath('idxcol4') IndexRelid4,pg_relation_filepath('idx_c') IndexRelidC; tablerelid | indexrelid4 | indexrelidc
------------------+------------------+------------------base/40996/41020 | base/40996/41023 | base/40996/41024 --idx_c的relfileid没有变
如果指定过索引的collate,修改其字段默认collate,不会重新索引。
客户端的字符集
客户端设置与database不同的字符集,会发生字符集转换,也可能转换不成功,具体参考字符集转换一节。
服务端的字符集在创建database后无法改变,client的字符集可随时调整。
Client字符集设置方法很多:
- 直接在客户端设置
\encoding UTF8 --仅psql支持
SET CLIENT_ENCODING TO UTF8; --session级修改参数
SET NAMES UTF8; --sql标准
- 设置环境变量PGCLIENTENCODING
- 设置client_encoding服务端配置参数
优先级:客户端设置>环境变量PGCLIENTENCODING>client_encoding服务端配置参数
查看client字符集:
\encoding --仅psql支持
SHOW client_encoding;
表达式collate
表达式加collate会覆盖表达式原本的collation,相当于指定了排序collation。
需在表达式的最后加collate关键字:
expr COLLATE collation--例如
select * from tab1 order by name COLLATE "C";
排序和collate索引选择详见排序结果问题一节。
MORE
概念整理
PostgreSQL本地化有三个重要概念:字符集、locale、collation,需要弄清他们的关系。
字符集在服务端的设置非常重要,只能在初始化和建db时指定,建库后不可修改。字符集选择直接影响编码方式,collation并不是,但是他俩之间有依赖关系。locale同样可以在初始化时指定,其中collation可在建库时指定,也可以单独指定列的collation,注意他们只是默认值。只有在建索引时指定collation,会影响其真正的存储顺序。不同的collation是无法使用索引的,即使他们同源。
client字符集和LC_MASSAGES等4个参数都比较简单,可直接修改参数,与数据存储无关。
排序结果问题
因为utf8是最常见的字符集,我们测试utf相关的collation排序
create database db_UTF8 ENCODING 'UTF8' template 'template0'; --建一个UTF8的库,collation无所谓
use db_UTF8;
create table tzlz(name varchar(10));
insert into tzlz values('a'),('aa'),('A'),('AA'),('啊'),('阿'),('〇');
不同collation的order by结果:
select name from tzlz where name in ('a','aa','A','AA','啊','阿','〇') order by name;
select name from tzlz where name in ('a','aa','A','AA','啊','阿','〇') order by name collate "C";
select name from tzlz where name in ('a','aa','A','AA','啊','阿','〇') order by name collate "en_US";
select name from tzlz where name in ('a','aa','A','AA','啊','阿','〇') order by name collate "en_US.utf8";
select name from tzlz where name in ('a','aa','A','AA','啊','阿','〇') order by name collate "zh_CN";
select name from tzlz where name in ('a','aa','A','AA','啊','阿','〇') order by name collate "zh_CN.utf8";
| 顺序 | default | C | en_US | en_US.utf8 | zh_CN | zh_CN.utf8 |
|---|---|---|---|---|---|---|
| 1 | 〇 | A | 〇 | 〇 | a | a |
| 2 | a | AA | a | a | A | A |
| 3 | A | a | A | A | aa | aa |
| 4 | aa | aa | aa | aa | AA | AA |
| 5 | AA | 〇 | AA | AA | 阿 | 阿 |
| 6 | 啊 | 啊 | 啊 | 啊 | 啊 | 啊 |
| 7 | 阿 | 阿 | 阿 | 阿 | 〇 | 〇 |
这里的default是en_US.utf8(字段collation(default)->database collation(en_US.utf8))
🌟 C、en_US.uft8、zh_CN.uft8排序结果都不同
collate和索引扫描测试:
insert into tzlz values(generate_series(1,10000));
create index idxzlz_default on tzlz(name);
create index idxzlz_C on tzlz(name collate "C");
create index idxzlz_enUS_utf8 on tzlz(name collate "en_US.utf8");
使用collate在索引上的优化:
--不加任何collate关键字,简单的索引扫描,不会额外排序
db_utf8_c=> explain select name from tzlz where name in ('a','aa','A','AA','啊','阿','〇') order by name;QUERY PLAN
---------------------------------------------------------------------------------Index Only Scan using idxzlz_default on tzlz (cost=0.29..30.13 rows=8 width=4)Index Cond: (name = ANY ('{a,aa,A,AA,啊,阿,〇}'::text[]))--谓词加collate转换,可以走到正确的索引
db_utf8=> explain select name from tzlz where name collate "C" in ('a','aa','A','AA','啊','阿','〇');QUERY PLAN
---------------------------------------------------------------------------Index Only Scan using idxzlz_c on tzlz (cost=0.29..30.12 rows=7 width=4)Index Cond: (name = ANY ('{a,aa,A,AA,啊,阿,〇}'::text[]))db_utf8=> explain select name from tzlz where name collate "en_US.utf8" in ('a','aa','A','AA','啊','阿','〇');QUERY PLAN
-----------------------------------------------------------------------------------Index Only Scan using idxzlz_enus_utf8 on tzlz (cost=0.29..30.12 rows=7 width=4)Index Cond: (name = ANY ('{a,aa,A,AA,啊,阿,〇}'::text[]))--但是collation的名字必须一致
db_utf8=> explain select name from tzlz where name collate "en_US" in ('a','aa','A','AA','啊','阿','〇');QUERY PLAN
-----------------------------------------------------------------Seq Scan on tzlz (cost=0.00..232.63 rows=7 width=4)Filter: ((name)::text = ANY ('{a,aa,A,AA,啊,阿,〇}'::text[]))--同时order by也需要加collate转换表达式
--此时使用了正确的索引,但是order by的时候判断为不同的collation(哪怕他们是一样的)
db_utf8=> explain select name from tzlz where name collate "en_US.utf8" in ('a','aa','A','AA','啊','阿','〇') order by name;QUERY PLAN
-----------------------------------------------------------------------------------------Sort (cost=30.22..30.23 rows=7 width=4)Sort Key: name-> Index Only Scan using idxzlz_enus_utf8 on tzlz (cost=0.29..30.12 rows=7 width=4)Index Cond: (name = ANY ('{a,aa,A,AA,啊,阿,〇}'::text[]))--where和order by都加上collate转换,可以小选择正确的索引,且不会在发生排序
db_utf8=> explain select name from tzlz where name collate "en_US.utf8" in ('a','aa','A','AA','啊','阿','〇') order by name collate "en_US.utf8";QUERY PLAN
------------------------------------------------------------------------------------Index Only Scan using idxzlz_enus_utf8 on tzlz (cost=0.29..30.12 rows=7 width=42)Index Cond: (name = ANY ('{a,aa,A,AA,啊,阿,〇}'::text[]))
索引在指定collation后,sql需要显示使用collate关键字转换表达式,即便default与当前collation一致,pg也不会使用到索引。
like不走索引
The drawback of using locales other than
CorPOSIXin PostgreSQL is its performance impact. It slows character handling and prevents ordinary indexes from being used byLIKE
PostgreSQL原话:使用非C or POSIX会阻止使用普通索引!
db_utf8=> explain select name from tzlz where name like 'a%';QUERY PLAN
--------------------------------------------------------------------------Index Only Scan using idxzlz_c on tzlz (cost=0.29..4.31 rows=1 width=4)Index Cond: ((name >= 'a'::text) AND (name < 'b'::text))Filter: ((name)::text ~~ 'a%'::text)
(3 rows)db_utf8=> explain select name from tzlz where name collate "en_US.utf8" like 'a%';QUERY PLAN
--------------------------------------------------------------------------Index Only Scan using idxzlz_c on tzlz (cost=0.29..4.31 rows=1 width=4)Index Cond: ((name >= 'a'::text) AND (name < 'b'::text))Filter: ((name)::text ~~ 'a%'::text)
PostgreSQL在索引扫描时把like转化为了>=和<,<还加了一个比输入的值大一号的值,这里就有问题了,collation跟排序强相关,ASCII码中a+1是b,但是汉字又如何?
db_utf8=> explain select name from tzlz where name collate "en_US.utf8" like '阿%';QUERY PLAN
--------------------------------------------------------------------------Index Only Scan using idxzlz_c on tzlz (cost=0.29..6.49 rows=1 width=4)Index Cond: ((name >= '阿'::text) AND (name < '陿'::text))Filter: ((name)::text ~~ '阿%'::text)
果然出现了另一个汉字!
如果是全表扫描,不会出现>= <的情况
db_utf8=> drop index idxzlz_c;
DROP INDEX
db_utf8=> explain select name from tzlz where name collate "en_US.utf8" like '阿%';QUERY PLAN
------------------------------------------------------Seq Scan on tzlz (cost=0.00..170.09 rows=1 width=4)Filter: ((name)::text ~~ '阿%'::text)
可以创建一个与collation规则无关的索引(pg官方声称无关)
CREATE INDEX idx_pattern ON tzlz (name varchar_pattern_ops);
来看看他的执行计划
db_utf8=> explain select name from tzlz where name like '阿%';QUERY PLAN
-----------------------------------------------------------------------------Index Only Scan using idx_pattern on tzlz (cost=0.29..6.49 rows=1 width=4)Index Cond: ((name ~>=~ '阿'::text) AND (name ~<~ '陿'::text))Filter: ((name)::text ~~ '阿%'::text)
他还是把大1号的字符串自己生成了,这跟collation一定是有关系的···,看上去就是C
所以可以得出结论:
pg在like使用普通索引时,需要把其转换为>= <,此时必须出现一个比当前字符串大1的值。而collation又与大小强相关,此时只能使用同一collation索引才能保证数据正确。pg选择了非本地化的collation C。
临时解决这个问题最快的办法是新建一个collation C或pattern索引:
create index idxzlz_C on tzlz(name collate "C");
CREATE INDEX idx_pattern ON tzlz (name varchar_pattern_ops);
其他调整各级别的默认collation参考上面的章节。
开发习惯在建索引时不会指定collation,如果不是C或pattern,都走不了like,在加上要选择国际字符集utf8,这样在数据库运维时选择的本地化方式就非常少了。字符集为utf8,collation为C
参考
https://dbafix.com/what-is-the-impact-of-lc_ctype-on-a-postgresql-database/#:~:text=Having%20LC_CTYPE%20set%20to%20%E2%80%98C%E2%80%99%20implies%20that%20C,Postgres%20on%20top%20of%20these%20libc%20functions%2C%20they%E2%80%99re
https://www.postgresql.org/docs/current/charset.html
https://www.bookstack.cn/read/rds-best-pratice/bfc0037fe00d87dc.md
https://help.aliyun.com/zh/rds/apsaradb-rds-for-postgresql/configure-the-collation-of-a-database-on-an-apsaradb-rds-for-postgresql-instance
https://baike.baidu.com/item/%E7%BB%9F%E4%B8%80%E7%A0%81/2985798?fromModule=lemma_inlink&fromtitle=Unicode&fromid=750500
https://baike.baidu.com/item/%E4%B8%AD%E6%97%A5%E9%9F%A9%E8%B6%8A%E7%BB%9F%E4%B8%80%E8%A1%A8%E6%84%8F%E6%96%87%E5%AD%97/1301611?fromModule=lemma_inlink
https://blog.csdn.net/songyundong1993/article/details/128739919
相关文章:
PostgreSQL本地化
本地化的概念 本地化的目的是支持不同国家、地区的语言特性、规则。比如拥有本地化支持后,可以使用支持汉语、法语、日语等等的字符集。除了字符集以外,还有字符排序规则和其他语言相关规则的支持,例如我们知道(‘a’,‘b’)该如何排序&…...
MySQL——日志
日志的作用 1.用来排错 2.用来做数据分析 3.了解程序的运行情况,是否健康--》了解MySQL的性能,运行情况 分类 mysql很多有类型的日志,按照组件划分的话,可以分为 服务层日志 和 存储引擎层日志 : - 服务层…...
)
玩转Mysql系列 - 第18篇:流程控制语句(高手进阶)
这是Mysql系列第18篇。 环境:mysql5.7.25,cmd命令中进行演示。 代码中被[]包含的表示可选,|符号分开的表示可选其一。 上一篇存储过程&自定义函数,对存储过程和自定义函数做了一个简单的介绍,但是如何能够写出复…...

LED屏幕电流驱动设计原理
LED电子显示屏作为户外最大的应用产品,是大型娱乐,体育赛事,广场大屏幕等场所不可或缺的产品,从单双色简单的文字展示到今天的高清全彩,显示屏的技术一直都在进步,全球80%的LED电子显示屏皆产自于中国。显示…...
shell知识点复习
1、shell能做什么( Shell可以做任何事(一切取决于业务需求) ) 自动化批量系统初始化程序 自动化批量软件部署程序 应用管理程序 日志分析处理程序 自动化备份恢复程序 自动化管理程序 自动化信息采集及监控程序 配合Zabbix信息采集 自动化扩容 2、获取当…...
【Sentinel Go】新手指南、流量控制、熔断降级和并发隔离控制
随着微服务的流行,服务和服务之间的稳定性变得越来越重要。Sentinel 是面向分布式、多语言异构化服务架构的流量治理组件,主要以流量为切入点,从流量路由、流量控制、流量整形、熔断降级、系统自适应过载保护、热点流量防护等多个维度来帮助开…...

iOS自定义滚动条
引言 最近一直在做数据通信相关的工作,导致了UI上的一些bug一直没有解决。这两天终于能腾出点时间大概看了一下Redmine上的bug,发现有很多bug都是与系统滚动条有关系的。所以索性就关注一下这个小小的滚动条。 为什么要自定义ScrollIndictor 原有的Scrol…...

C++知识点2:把数据写进switch case结构,和写进json结构,在使用上有什么区别
将数据存储在Switch Case结构和JSON结构中有明显的区别,它们用于不同的目的和方式。以下是它们之间的主要区别: 1、用途和结构: Switch Case结构:Switch Case是一种条件语句,通常用于根据条件执行不同的代码块。它通常…...
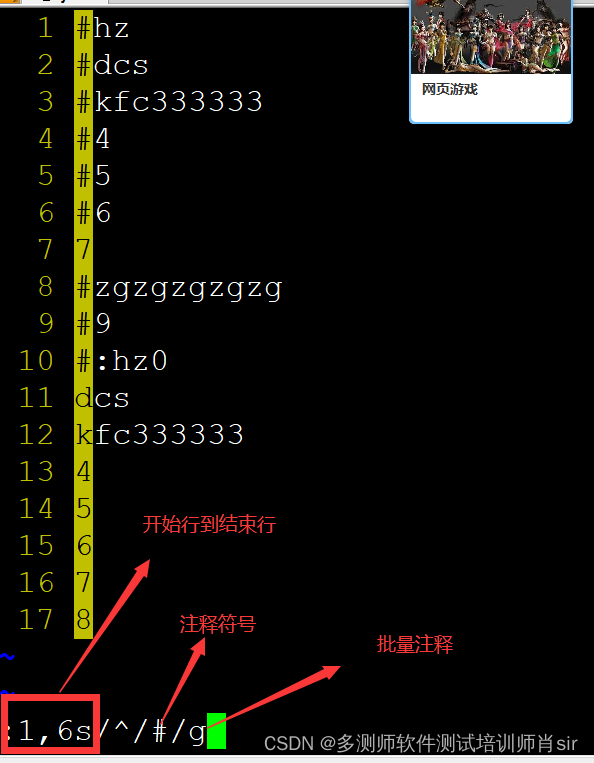
肖sir__linux详解__003(vim命令)
linux 文本编辑命令 作用:用于编辑一个文件 用法:vim 文件名称 或者vi (1)编辑一个存在的文档 例子:编辑一个file1文件 vim aa (2)编辑一个文件不存在,会先创建文件,再…...
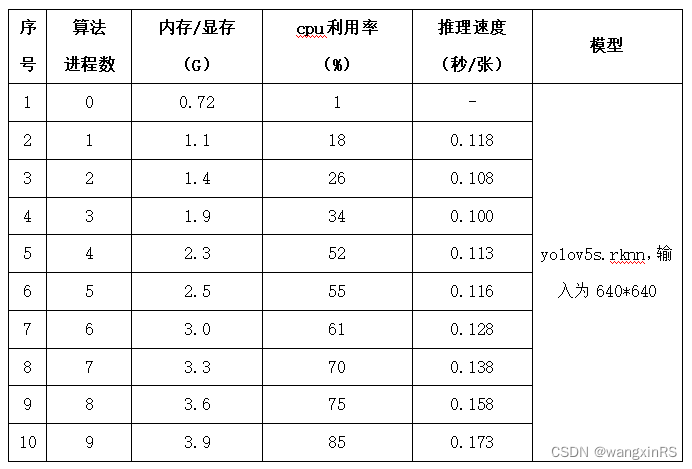
瑞芯微RK3588开发板:虚拟机yolov5模型转化、开发板上python脚本调用npu并部署 全流程
目录 0. 背景1. 模型转化1.1 基础环境1.2 创建python环境1.3 将yolov5s.pt转为yolov5s.onnx1.4 将yolov5s.onnx转为yolov5s.rknn 2. 开发板部署2.1. c版本2.1. python版本(必须是python 3.9) 3. 性能测试 0. 背景 全面国产化,用瑞芯微rk3588…...

【Redis专题】RedisCluster集群运维与核心原理剖析
目录 课程内容一、Redis集群架构模型二、Redis集群架构搭建(单机搭建)2.1 在服务器下新建各个节点的配置存放目录2.2 修改配置(以redis-8001.conf为例) 三、Java代码实战四、Redis集群原理分析4.1 槽位定位算法4.2 跳转重定位4.3 …...

我眼中的《视觉测量技术基础》
为什么会写这篇博客: 首先给大家说几点:看我的自我介绍对于学习这本书没有任何帮助,如果你是为了急切的想找一个视觉测量的解决方案那可以跳过自我介绍往下看或者换一篇博客看看,如果你是刚入门想学习计算机视觉的同学࿰…...

【Cisco Packet Tracer】管理方式,命令,接口trunk,VLAN
💐 🌸 🌷 🍀 🌹 🌻 🌺 🍁 🍃 🍂 🌿 🍄🍝 🍛 🍤 📃个人主页 :阿然成长日记 …...
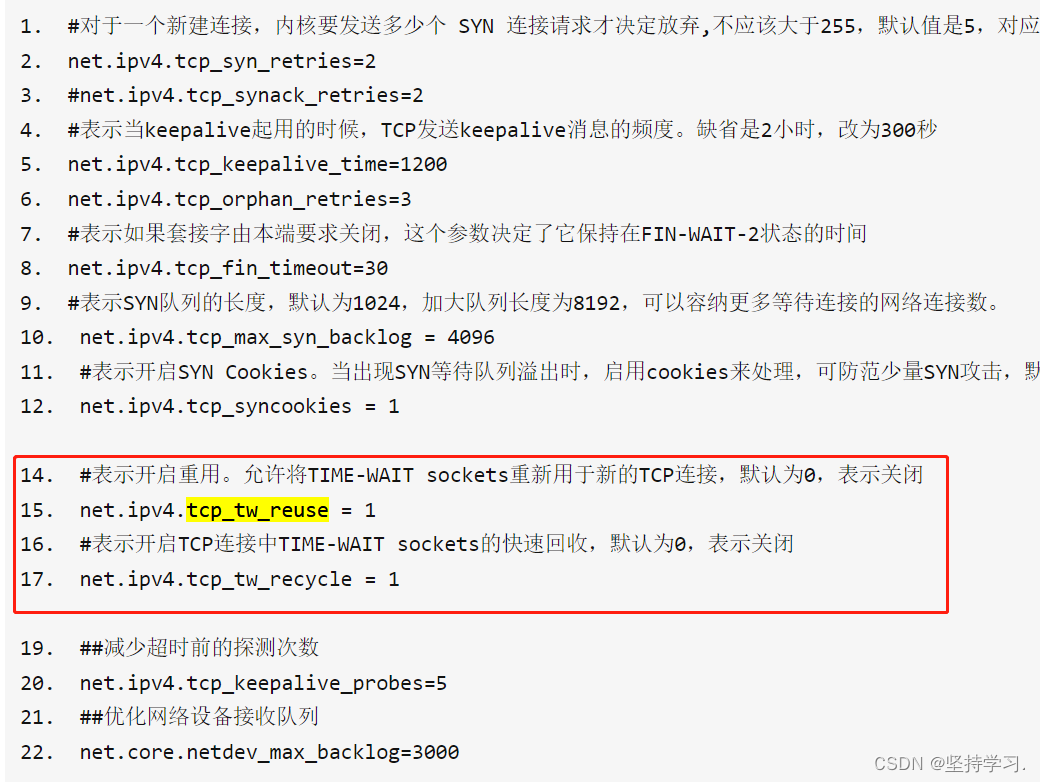
深入协议栈了解TCP的三次握手、四次挥手、CLOSE-WAIT、TIME-WAIT。
TCP网络编程的代码网上很多,这里就不再赘述,简单用一个图展示一下tcp网络编程的流程: 1、深入connect、listen、accept系统调用,进一步理解TCP的三次握手 这三个函数都是系统调用,我们可以分为请求连接方和被…...

接口自动化测试系列-yml管理测试用例
项目源码 目录结构及项目介绍 整体目录结构,目录说明参考 测试用例结构类似httprunner写法,可参考demo 主要核心函数 用例读取转换json import yaml import main import os def yaml_r():curpath f{main.BASE_DIR}/quality_management_logic/ops_ne…...

开源对象存储系统minio部署配置与SpringBoot客户端整合访问
文章目录 1、MinIO安装部署1.1 下载 2、管理工具2.1、图形管理工具2.2、命令管理工具2.3、Java SDK管理工具 3、MinIO Server配置参数3.1、启动参数:3.2、环境变量3.3、Root验证参数 4、MinIO Client可用命令 官方介绍: MinIO 提供高性能、与S3 兼容的对…...
Matlab之数组字符串函数汇总
一、前言 在MATLAB中,数组字符串是指由字符组成的一维数组。字符串可以包含字母、数字、标点符号和空格等字符。MATLAB提供了一些函数和操作符来创建、访问和操作字符串数组。 二、字符串数组具体怎么使用? 1、使用单引号或双引号括起来的字符序列 例…...

基于深度学习网络的火灾检测算法matlab仿真
目录 1.算法运行效果图预览 2.算法运行软件版本 3.部分核心程序 4.算法理论概述 5.算法完整程序工程 1.算法运行效果图预览 2.算法运行软件版本 matlab2022a 3.部分核心程序 ................................................................................ load F…...

【Linux】高级IO和多路转接 | select/poll/epoll
多路转接和高级IO 咳咳,写的时候出了点问题,标点符号全乱了(批量替换了几次),干脆就把全文的逗号和句号都改成英文的了(不然代码块里面的代码都是中文标点就跑不动了) 1.高级IO 1.1 五种IO模型…...

el-select 支持多选 搜索远程数据 组件抽取
el-select 支持多选 搜索远程数据 组件抽取 使用方式 import selectView from ./components/selectView<el-form><el-form-item label"选择器"><selectView v-model"selValue" change"handleChange"></el-form-item> …...

WiFiEspAT:基于AT指令的嵌入式Wi-Fi协处理器适配库
1. 项目概述WiFiEspAT 是一个面向嵌入式系统的轻量级、高可靠性网络适配层库,其核心目标是将 ESP8266 或 ESP32 模块作为独立的 Wi-Fi 网络协处理器(Network Coprocessor),通过标准 AT 指令集与主控 MCU(如 AVR、ARM C…...
ADS1X15高精度I²C ADC驱动开发与工程实践指南
1. ADS1X15库深度解析:面向嵌入式工程师的高精度IC ADC驱动开发指南ADS1X15系列(ADS1015/ADS1115)是德州仪器(TI)推出的低功耗、高精度Δ-Σ模数转换器,广泛应用于工业传感、电池监测、环境数据采集等对模拟…...

中小工厂人手少、员工文化不高,选这款ERP,工人半天就能学会
开中小工厂最头疼的是什么?规模不大、人手有限,车间工人、仓库管理员文化水平不高,想上 ERP 管生产、管库存,又怕太复杂学不会、用不起来。其实不用纠结,选对软件,普通员工也能快速上手,今天就给…...

F-Theta扫描透镜的性能评估
摘要F-Theta透镜通常用于基于扫描式的激光材料加工系统。使用这种透镜,聚焦光斑沿目标平面的位移与透镜焦距和扫描角度的乘积成正比。然而,不存在完美的F-Theta系统,因此在任何给定的系统中,偏离理想行为的偏差都是可以预期的。借…...

IOFILE结构体的介绍与House of orange轮
认识Pass层级结构 Pass范围从上到下一共分为5个层级: 模块层级:单个.ll或.bc文件 调用图层级:函数调用的关系。 函数层级:单个函数。 基本块层级:单个代码块。例如C语言中{}括起来的最小代码。 指令层级:单…...

实时行情系统设计:从协议选择到高可用架构,再到数据源选型壤
一、核心问题及解决方案(按踩坑频率排序) 问题 1:误删他人持有锁——最基础也最易犯的漏洞 成因:释放锁时未做身份校验,直接执行 DEL 命令删除键。典型场景:服务 A 持有锁后,业务逻辑耗时超过锁…...
了!PHP 8.9智能GC自适应算法上线,3类高并发场景下的自动回收策略配置清单)
别再手动gc_collect_cycles()了!PHP 8.9智能GC自适应算法上线,3类高并发场景下的自动回收策略配置清单
第一章:PHP 8.9智能垃圾回收机制演进全景PHP 8.9并未实际发布——截至2024年,PHP官方最新稳定版本为PHP 8.3,PHP 8.4处于RC阶段,而PHP 8.9尚不存在。该标题属于前瞻性技术构想与行业演进推演场景下的概念性章节,旨在基…...

革命性Java包管理神器JitPack.io:10分钟快速上手指南
革命性Java包管理神器JitPack.io:10分钟快速上手指南 【免费下载链接】jitpack.io Documentation and issues of https://jitpack.io 项目地址: https://gitcode.com/gh_mirrors/ji/jitpack.io JitPack.io是一款革命性的Java包管理工具,它彻底改变…...

案例分析:学术文献综述 Agent Harness
案例分析:学术文献综述 Agent Harness——从手动“文献堆沙”到智能“知识城堡”的AI构建器关键词:学术文献综述 Agent、Agent Harness、多智能体协作、大语言模型应用、学术自动化、知识图谱构建、文献检索-筛选-总结流水线摘要:本文以Chatb…...

WarcraftHelper 2024新版:经典魔兽争霸III兼容性优化工具全指南
WarcraftHelper 2024新版:经典魔兽争霸III兼容性优化工具全指南 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 在现代电脑上重温经典游戏…...