elasticsearch的数据聚合
聚合可以让我们极其方便的实现对数据的统计、分析、运算。例如:
什么品牌的手机最受欢迎?
这些手机的平均价格、最高价格、最低价格?
这些手机每月的销售情况如何?
实现这些统计功能的比数据库的sql要方便的多,而且查询速度非常快,可以实现近实时搜索效果
聚合种类
聚合常见的有三类:
-
桶(Bucket)聚合:用来对文档做分组
-
TermAggregation:按照文档字段值分组,例如按照品牌值分组、按照国家分组
-
Date Histogram:按照日期阶梯分组,例如一周为一组,或者一月为一组
-
-
度量(Metric)聚合:用以计算一些值,比如:最大值、最小值、平均值等
-
Avg:求平均值
-
Max:求最大值
-
Min:求最小值
-
Stats:同时求max、min、avg、sum等
-
-
管道(pipeline)聚合:其它聚合的结果为基础做聚合
注意:参加聚合的字段必须是keyword、日期、数值、布尔类型
DSL实现聚合
语句
GET /hotel/_search
{"size": 0,"aggs": {"brandAgg": {"terms": {"field": "brand","size": 20}}}
}- 设置size为0,结果中不包含文档,只包含聚合结果
- aggs定义聚合
- brandAgg给聚合起个名字
- terms聚合的类型,按照品牌值聚合,所以选择term
- field参与聚合的字段
- terms里面的sezi希望获取的聚合结果数量
发起请求的结果

聚合结果排序
默认情况下,Bucket聚合会统计Bucket内的文档数量,记为count,并且按照count降序排序。
我们可以指定order属性,自定义聚合的排序方式,按照_count降序排列
GET /hotel/_search
{"size": 0, "aggs": {"brandAgg": {"terms": {"field": "brand","order": {"_count": "desc" },"size": 20}}}
}发起请求的结果, 按照_count降序排列。

限定聚合范围
默认情况下,Bucket聚合是对索引库的所有文档做聚合,但真实场景下,用户会输入搜索条件,因此聚合必须是对搜索结果聚合。那么聚合必须添加限定条件。我们可以限定要聚合的文档范围,只要添加query条件即可。
只对200元以下的文档聚合
GET /hotel/_search
{"query": {"range": {"price": {"lte": 200 }}}, "size": 0, "aggs": {"brandAgg": {"terms": {"field": "brand","size": 20}}}
}聚合得到的品牌明显变少了

Metric聚合语法
现在我们需要对桶内的酒店做运算,获取每个品牌的用户评分的min、max、avg等值
score_stats聚合是在brandAgg的聚合内部嵌套的子聚合。因为我们需要在每个桶分别计算
GET /hotel/_search
{"size": 0, "aggs": {"brandAgg": { "terms": { "field": "brand", "size": 20},"aggs": { "score_stats": { "stats": { "field": "score" }}}}}
}我们还可以给聚合结果做个排序,例如按照每个桶的酒店平均分做排序,score_stats.avg对score聚合函数的平均值进行降序排序。
GET /hotel/_search
{"size": 0, "aggs": {"brandAgg": { "terms": { "field": "brand", "size": 20,"order": {"score_stats.avg": "desc"}},"aggs": { "score_stats": { "stats": { "field": "score" }}}}}
}小结
aggs代表聚合,与query同级
聚合必须的三要素:
-
聚合名称
-
聚合类型
-
聚合字段
聚合可配置属性有:
-
size:指定聚合结果数量
-
order:指定聚合结果排序方式
-
field:指定聚合字段
java代码实现聚合
搜索页面的品牌、城市等信息不应该是在页面写死,而是通过聚合索引库中的酒店数据得来的
controller类
import cn.itcast.hotel.pojo.PageResult;
import cn.itcast.hotel.pojo.RequestParams;
import cn.itcast.hotel.service.IHotelService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;import java.util.List;
import java.util.Map;@RestController
@RequestMapping("/hotel")
public class HotelController {@Autowiredprivate IHotelService hotelService;@PostMapping("filters")public Map<String, List<String>> getFilters(@RequestBody RequestParams params){return hotelService.getFilters(params);}
}service类
import cn.itcast.hotel.mapper.HotelMapper;
import cn.itcast.hotel.pojo.Hotel;
import cn.itcast.hotel.pojo.HotelDoc;
import cn.itcast.hotel.pojo.PageResult;
import cn.itcast.hotel.pojo.RequestParams;
import cn.itcast.hotel.service.IHotelService;
import com.alibaba.fastjson.JSON;
import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.common.geo.GeoPoint;
import org.elasticsearch.common.unit.DistanceUnit;
import org.elasticsearch.index.query.BoolQueryBuilder;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.index.query.functionscore.FunctionScoreQueryBuilder;
import org.elasticsearch.index.query.functionscore.ScoreFunctionBuilders;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
import org.elasticsearch.search.aggregations.AggregationBuilders;
import org.elasticsearch.search.aggregations.Aggregations;
import org.elasticsearch.search.aggregations.bucket.terms.Terms;
import org.elasticsearch.search.sort.SortBuilders;
import org.elasticsearch.search.sort.SortOrder;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;import java.io.IOException;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;@Service
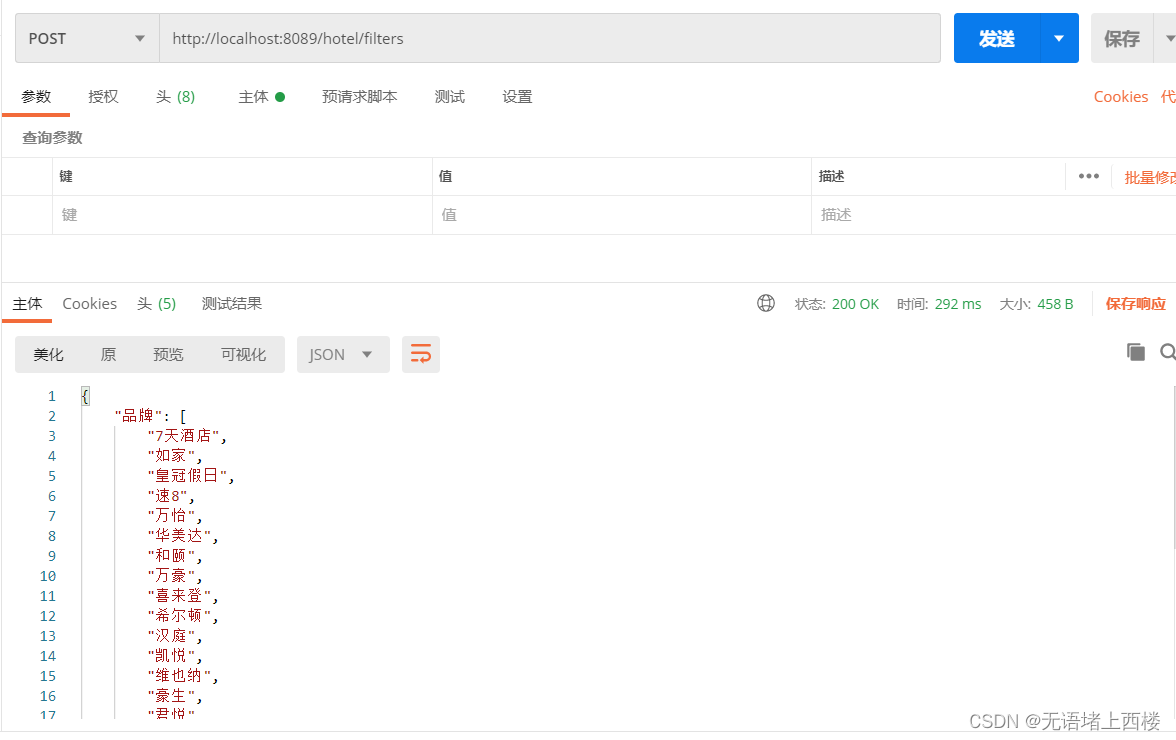
public class HotelService extends ServiceImpl<HotelMapper, Hotel> implements IHotelService {@Autowiredprivate RestHighLevelClient client;@Overridepublic Map<String, List<String>> getFilters(RequestParams params) {try {// 1.准备RequestSearchRequest request = new SearchRequest("hotel");// 2.准备DSL// 2.1.query// buildBasicQuery(params, request);// 2.2.设置sizerequest.source().size(0);// 2.3.聚合buildAggregation(request);// 3.发出请求SearchResponse response = client.search(request, RequestOptions.DEFAULT);// 4.解析结果Map<String, List<String>> result = new HashMap<>();Aggregations aggregations = response.getAggregations();// 4.1.根据品牌名称,获取品牌结果List<String> brandList = getAggByName(aggregations, "brandAgg");result.put("品牌", brandList);// 4.2.根据品牌名称,获取品牌结果List<String> cityList = getAggByName(aggregations, "cityAgg");result.put("城市", cityList);// 4.3.根据品牌名称,获取品牌结果List<String> starList = getAggByName(aggregations, "starAgg");result.put("星级", starList);return result;} catch (IOException e) {throw new RuntimeException(e);}}private void buildAggregation(SearchRequest request) {request.source().aggregation(AggregationBuilders.terms("brandAgg").field("brand").size(100));request.source().aggregation(AggregationBuilders.terms("cityAgg").field("city").size(100));request.source().aggregation(AggregationBuilders.terms("starAgg").field("starName").size(100));}private List<String> getAggByName(Aggregations aggregations, String aggName) {// 4.1.根据聚合名称获取聚合结果Terms brandTerms = aggregations.get(aggName);// 4.2.获取bucketsList<? extends Terms.Bucket> buckets = brandTerms.getBuckets();// 4.3.遍历List<String> brandList = new ArrayList<>();for (Terms.Bucket bucket : buckets) {// 4.4.获取keyString key = bucket.getKeyAsString();brandList.add(key);}return brandList;}}
发送请求,获得结果
相关文章:
elasticsearch的数据聚合
聚合可以让我们极其方便的实现对数据的统计、分析、运算。例如: 什么品牌的手机最受欢迎? 这些手机的平均价格、最高价格、最低价格? 这些手机每月的销售情况如何? 实现这些统计功能的比数据库的sql要方便的多,而且…...

【网络编程·数据链路层】MAC帧/以太网协议/ARP协议/RARP协议
需要云服务器等云产品来学习Linux的同学可以移步/-->腾讯云<--/-->阿里云<--/-->华为云<--/官网,轻量型云服务器低至112元/年,新用户首次下单享超低折扣。 目录 一、MAC帧 1、IP地址和MAC地址的区别 2、MAC帧协议 3、MTU对IP协议的…...

算法:移除数组中的val的所有元素---双指针[2]
文章来源: https://blog.csdn.net/weixin_45630258/article/details/132689237 欢迎各位大佬指点、三连 1、题目: 给你一个数组 nums和一个值 val,你需要原地移除所有数值等于 val 的元素,并返回移除后数组的新长度。 不要使用…...

Python小知识 - Python爬虫进阶:如何克服反爬虫技术
Python爬虫进阶:如何克服反爬虫技术 爬虫是一种按照一定的规则,自动抓取网页信息的程序。爬虫也叫网页蜘蛛、蚂蚁、小水滴,是一种基于特定算法的自动化程序,能够按照一定的规则自动的抓取网页中的信息。爬虫程序的主要作用就是从一…...
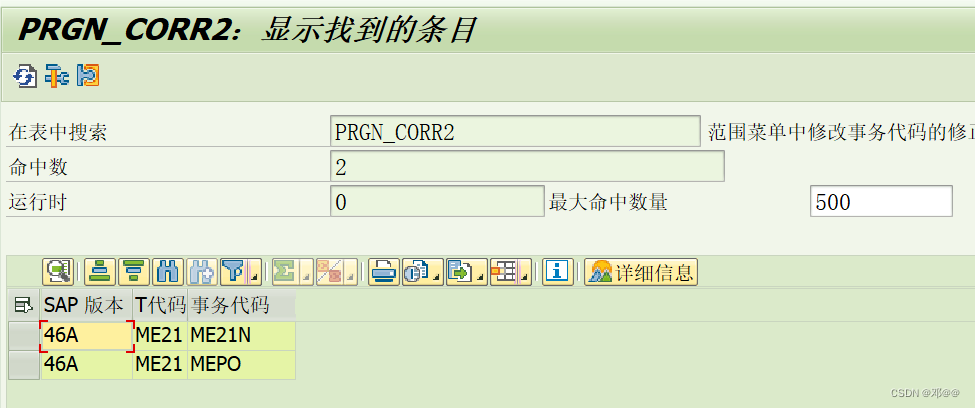
SAP中的新旧事务码
SAP中的新旧事务码 SAP随着新版本的发布,我们知道sap已经更新了很多的程序和TCODE。sap提供了很多新的TCODE来替换旧的TCODE,新TCODE有很多的新特性和新功能。在这个这种情况下,很多旧TCODE就会被废弃。我们如何查找这个替换呢? …...
day3_C++
day3_C 思维导图用C的类完成数据结构 栈的相关操作用C的类完成数据结构 循环队列的相关操作 思维导图 用C的类完成数据结构 栈的相关操作 stack.h #ifndef STACK_H #define STACK_H#include <iostream> #include <cstring>using namespace std;typedef int datat…...
,带注释)
力扣题解(73. 矩阵置零),带注释
题目描述 链接:点我 题解 //法一 使用hashset记录有0的横纵坐标即可 class Solution {public void setZeroes(int[][] matrix) {HashSet<Integer> row new HashSet<Integer>();HashSet<Integer> col new HashSet<Integer>();for(int i 0;i <…...

SpringMVC应用
文章目录 一、常用注解二、参数传递2.1 基础类型String2.2 复杂类型2.3 RequestParam2.4.路径传参 PathVariable2.4 Json数据传参 RequestBody2.5 RequestHeader 三、方法返回值3.1 void3.2 Stringmodel3.3 ModelAndView 一、常用注解 SpringMVC是一个基于Java的Web框架&#…...
百度输入法全面升级,打造首个基于大模型的输入法原生应用
基于文心一言,百度输入法宣布全面升级,打造行业首个“基于大模型的输入法原生应用”,从“输入工具”全面转型为“AI创作工具”。 近日,百度文心一言正式向公众开放。基于文心一言,百度输入法宣布全面升级,打…...

如何解决GitHub 访问不了?小白教程
GitHub 是全球最大的代码开源平台,小伙伴们平时都喜欢在那里找一些优质的开源项目来学习,以提升自己的编程技能。 但是很多小白初探GitHub 发现访问不了,不能访问 通过一下方法绕过这堵墙,成功下载 GitHub 上的项目。过程非常简单…...
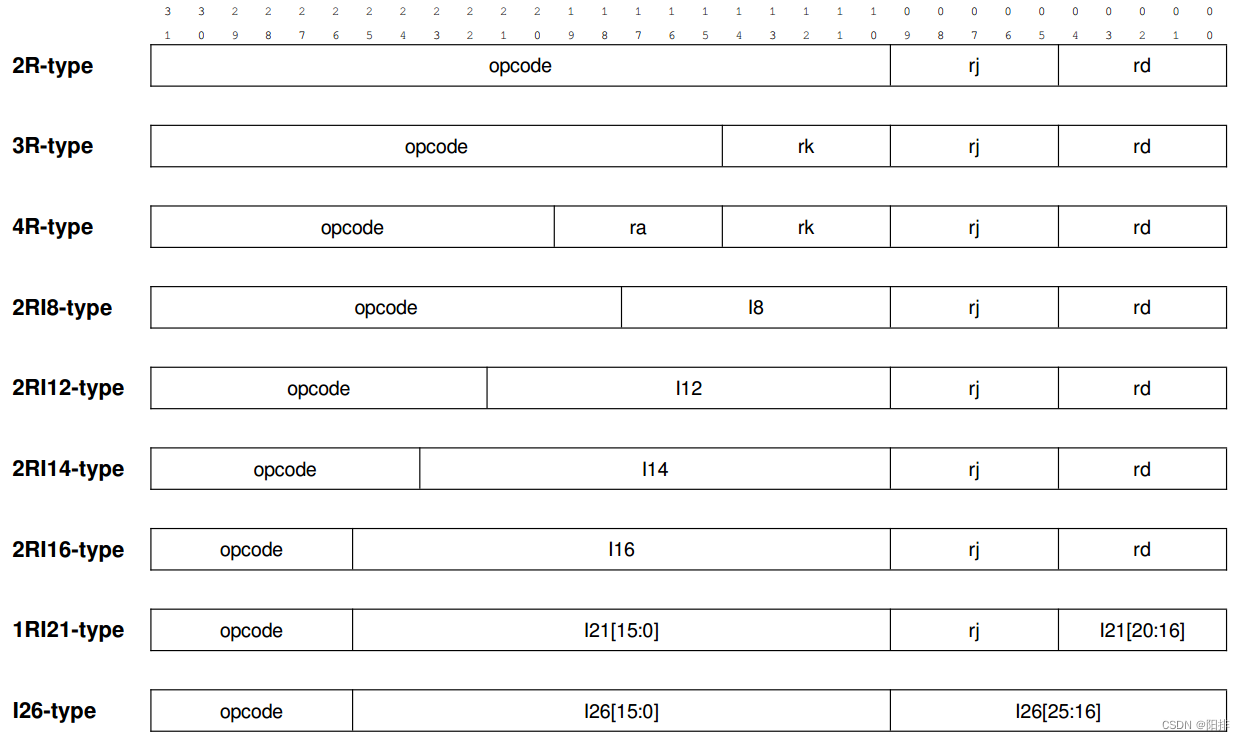
龙芯指令集LoongArch——学习笔记(1)
1 龙芯架构 PDF下载链接: https://www.loongson.cn/download/index 1.1 龙芯架构概述 龙芯架构具有 RISC 指令架构的典型特征。 它的指令长度固定且编码格式规整, 绝大多数指令只有两个源操作数和一个目的操作数, 采用 load/store 架构&…...

ubuntu 20.04 docker安装emqx 最新版本或指定版本
要在Ubuntu 20.04上使用Docker安装EMQX(EMQ X Broker)的4.4.3版本,您可以执行以下步骤: 1.更新系统包列表: sudo apt update2.安装Docker: sudo apt install docker.io3.启动Docker服务并设置其开机自启…...

软件测试/测试开发丨学会与 AI 对话,高效提升学习效率
点此获取更多相关资料 简介 ChatGPT 的主要优点之一是它能够理解和响应自然语言输入。在日常生活中,沟通本来就是很重要的一门课程,沟通的过程中表达越清晰,给到的信息越多,那么沟通就越顺畅。 和 ChatGPT 沟通也是同样的道理&…...

CEF内核和高级爬虫知识
(转)关于MFC中如何使用CEF内核(CEF初解析) Python GUI: cefpython3的简单分析和应用 cefpython3:一款强大的Python库 开始大多数抓取尝试可以从几乎一行代码开始: fun main() PulsarContexts.createSession().scrapeOutPages(&q…...
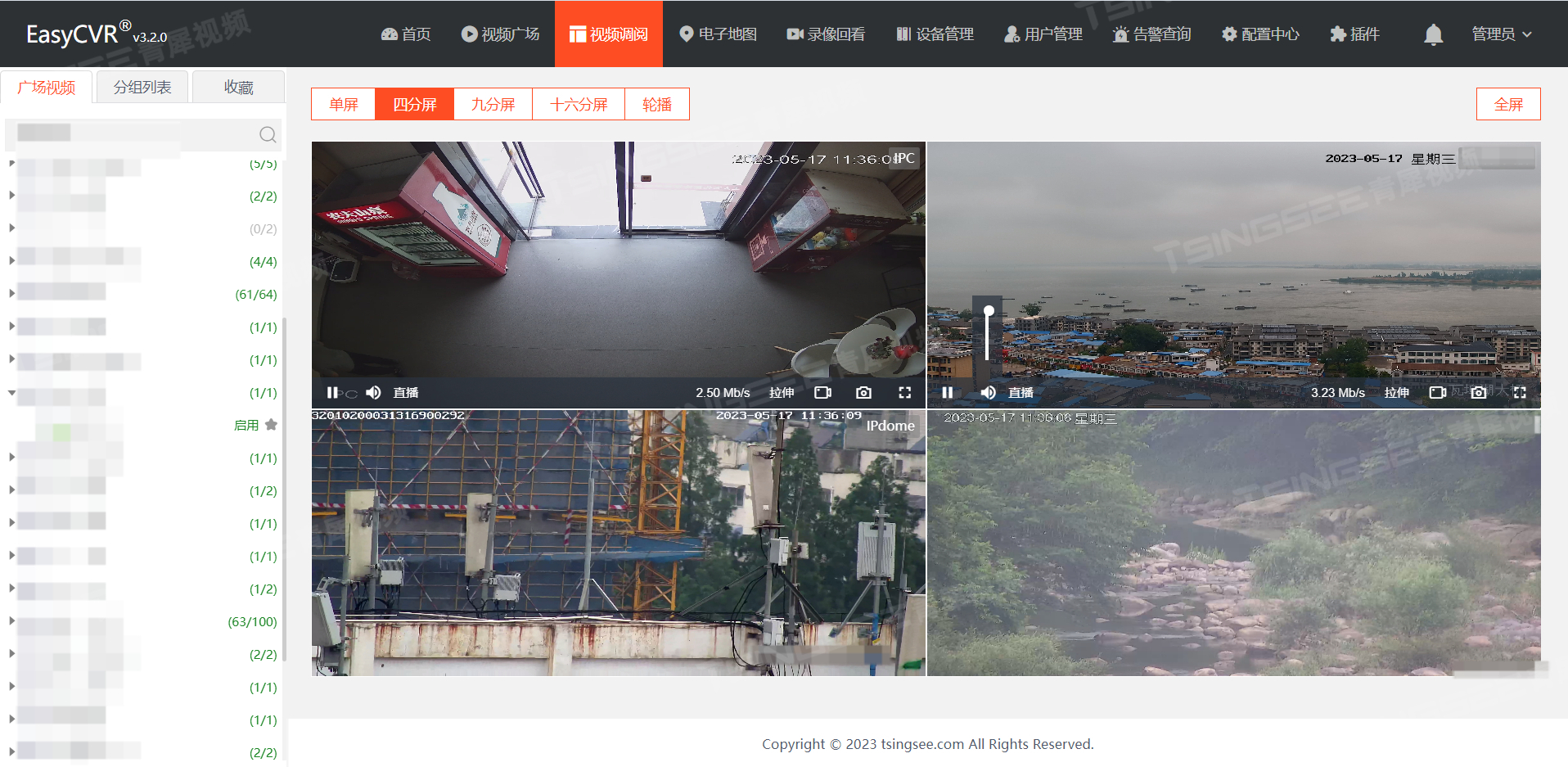
视频集中存储/云存储/磁盘阵列EasyCVR平台分组批量绑定/取消设备功能详解
安防视频监控/视频集中存储/云存储/磁盘阵列EasyCVR平台视频能力丰富灵活,可支持的主流标准协议有国标GB28181、RTSP/Onvif、RTMP等,以及支持厂家私有协议与SDK接入,包括海康Ehome、海大宇等设备的SDK等。视频汇聚融合管理平台EasyCVR既具备传…...

科技成果鉴定测试报告一般包含哪些测试内容?
软件测评报告 一、科技成果评价是需要做第三方软件测评报告,一般是证明技术指标点是否完善,覆盖主要申报内容,应用软件项目科技成果鉴定测试内容: (一)是否完成合同或计划任务书要求的指标; …...
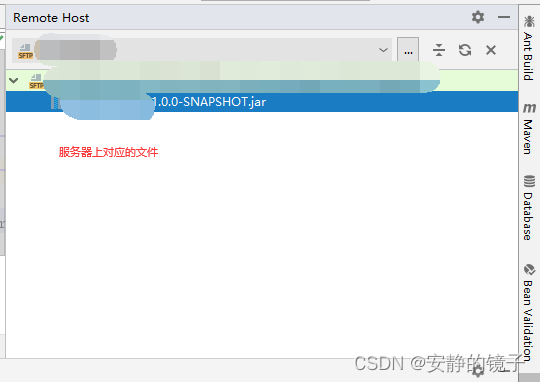
IDEA中的“Deployment“ 将项目直接部署到服务器上
ntelliJ IDEA中的"Deployment"工具栏是一个方便的工具,用于将你的项目直接部署到服务器上。这个工具栏提供了三种部署的方式: 1.Web Server在本地电脑上,并且服务器运行目录也在项目目录下。 2.Web Server在本地电脑上,…...

密室逃脱小游戏
欢迎来到程序小院 密室逃脱 玩法: 判断可生存的空间,鼠标点击屏幕进行人物左右移动,躲避闸道进行生存,每进行一次关卡都会有分数统计,赶紧去闯关吧^^。开始游戏https://www.ormcc.com/play/gameStart/176 html <c…...

【MyBatis】MyBatis项目结构的搭建
Mybatis项目的搭建 依赖 将打包方式添加为jar包 <groupId>com.qinghe.mybatis</groupId><artifactId>Mybatis_demo3</artifactId><version>1.0-SNAPSHOT</version><packaging>jar</packaging>添加如下依赖 <depen…...

Vant组件库入门知识
🙈作者简介:练习时长两年半的Java up主 🙉个人主页:程序员老茶 🙊 ps:点赞👍是免费的,却可以让写博客的作者开兴好久好久😎 📚系列专栏:Java全栈,…...

AgentScope Runtime 生产部署:Engine+Sandbox 双核架构深度拆解
AgentScope Runtime 生产部署:EngineSandbox 双核架构深度拆解 导读:AgentScope Runtime 提供了完整的生产级运行时框架,支持从本地到云端的多种部署形态。本文深入拆解 Engine 和 Sandbox 双核架构,详解 Docker/K8s/Serverless 部署方案,以及 Agent-as-…...
)
阿里云OSS直传避坑指南:Vue3中如何安全处理临时凭证(Browser.js最佳实践)
Vue3阿里云OSS直传安全实践:从临时凭证管理到防抓包设计 引言 在当今企业级应用开发中,文件上传功能几乎是标配需求。阿里云OSS作为国内领先的对象存储服务,其Browser.js直传方案能有效减轻服务器负担,但同时也带来了前端安全管理…...

【技术解读】NeuroLM:当EEG成为LLM的“第二语言”,多任务脑电分析的统一范式
1. 当脑电波遇上大语言模型:NeuroLM的技术革命 想象一下,如果你的脑电波能像外语一样被AI翻译和理解,会是怎样的场景?这正是NeuroLM带来的颠覆性突破。这个将EEG(脑电图)信号视为"第二语言"的通用…...
✅)
计算机毕业设计:Python基于Spark与协同过滤的智能图书推荐平台 Django框架 协同过滤推荐算法 书籍 可视化 数据分析 大数据 大模型(建议收藏)✅
博主介绍:✌全网粉丝10W,前互联网大厂软件研发、集结硕博英豪成立工作室。专注于计算机相关专业项目实战6年之久,选择我们就是选择放心、选择安心毕业✌ > 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与…...

从TRPO到PPO2:OpenAI如何用‘裁剪’技巧让强化学习训练更稳更快?
从TRPO到PPO2:深度强化学习的工程优化之路 在深度强化学习领域,策略优化算法的发展经历了从理论严谨到工程实用的转变。TRPO(Trust Region Policy Optimization)作为里程碑式的工作,首次系统性地解决了策略梯度算法的稳…...

百考通:AI驱动数据分析,精细化引导与全维度覆盖,让数据价值高效落地
在数字化浪潮席卷各行各业的今天,数据已成为核心生产要素,但如何从海量数据中挖掘价值、辅助决策,始终是企业与个人面临的核心难题。传统数据分析流程繁琐、技术门槛高、周期漫长,让许多非专业人士望而却步。百考通(ht…...

【深度学习】遥感影像变化检测:从模型演进到实战选型
1. 遥感影像变化检测:从“找不同”到“智能感知” 还记得小时候玩的“找不同”游戏吗?给你两张看似一样的图片,让你圈出其中的差异点。遥感影像变化检测,本质上就是给地球这个“大家伙”玩一场超级复杂的“找不同”游戏。只不过&a…...

卡尔曼滤波Simulink实例:温度测量中的优化应用
卡尔曼滤波simulink实例,卡尔曼滤波在温度测量中的应用今天咱们来聊一个在工程领域特别实用的技术——卡尔曼滤波。这玩意儿名字听着挺唬人,但说白了就是个"带脑子的数据过滤器"。就拿温度测量来说,传感器数据总带着点噪声对吧?这时…...

实战指南:在VMware虚拟化环境中构建高可用Hadoop完全分布式集群
1. 为什么选择VMware搭建Hadoop集群? 在开始动手之前,我们先聊聊为什么要在VMware虚拟化环境中搭建Hadoop集群。我见过太多初学者一上来就直接在物理机上折腾,结果遇到硬件兼容性问题时束手无策。VMware提供的虚拟化环境就像个"安全沙盒…...

永磁同步电机DPWM算法控制仿真Simulink模型探索
永磁同步电机DPWM算法控制仿真simulink模型。 邮箱发送。最近在研究永磁同步电机(PMSM)的控制算法,发现DPWM(Discontinuous Pulse Width Modulation,不连续脉宽调制)算法挺有意思,今天就来聊聊基…...