kafka 3.5 主题分区的Follower创建Fetcher线程从Leader拉取数据源码
Kakfa集群有主题,每一个主题下又有很多分区,为了保证防止丢失数据,在分区下分Leader副本和Follower副本,而kafka的某个分区的Leader和Follower数据如何同步呢?下面就是讲解的这个
首先要知道,Follower的数据是通过Fetch线程异步从Leader拉取的数据,不懂的可以看一下Kafka——副本(Replica)机制
- 一、Broker接收处理分区的Leader和Follower的API
- 二、针对分区副本的Leader和Follower的处理逻辑
- 1、如果是Follower,则准备创建Fetcher线程,好异步执行向Leader拉取数据
- 2、遍历分区Follower副本,判断是否有向目标broker现成的Fetcher,如果是则复用,否则创建
- 3、创建Fetcher线程的实现
一、Broker接收处理分区的Leader和Follower的API
在kafkaApis.scala中
//处理Leader和follower,ISR的请求case ApiKeys.LEADER_AND_ISR => handleLeaderAndIsrRequest(request)
def handleLeaderAndIsrRequest(request: RequestChannel.Request): Unit = {val zkSupport = metadataSupport.requireZkOrThrow(KafkaApis.shouldNeverReceive(request))//从请求头中获取关联ID//从请求体中获取LeaderAndIsrRequest对象。val correlationId = request.header.correlationIdval leaderAndIsrRequest = request.body[LeaderAndIsrRequest]//对请求进行集群操作的授权验证。authHelper.authorizeClusterOperation(request, CLUSTER_ACTION)//检查broker的代数是否过时。if (zkSupport.isBrokerEpochStale(leaderAndIsrRequest.brokerEpoch, leaderAndIsrRequest.isKRaftController)) {//省略代码} else {//调用replicaManager.becomeLeaderOrFollower方法处理请求,获取响应val response = replicaManager.becomeLeaderOrFollower(correlationId, leaderAndIsrRequest,RequestHandlerHelper.onLeadershipChange(groupCoordinator, txnCoordinator, _, _))requestHelper.sendResponseExemptThrottle(request, response)}}
经过一些检验后,调用becomeLeaderOrFollower获得响应结果,
二、针对分区副本的Leader和Follower的处理逻辑
def becomeLeaderOrFollower(correlationId: Int,leaderAndIsrRequest: LeaderAndIsrRequest,onLeadershipChange: (Iterable[Partition], Iterable[Partition]) => Unit): LeaderAndIsrResponse = {//首先记录了方法开始的时间戳val startMs = time.milliseconds()//副本状态改变锁replicaStateChangeLock synchronized {//从leaderAndIsrRequest中获取一些请求信息,包括controller的ID、分区状态等val controllerId = leaderAndIsrRequest.controllerIdval requestPartitionStates = leaderAndIsrRequest.partitionStates.asScalaval response = {//处理过程中,会检查请求的controller epoch是否过时if (leaderAndIsrRequest.controllerEpoch < controllerEpoch) {//省略} else {val responseMap = new mutable.HashMap[TopicPartition, Errors]controllerEpoch = leaderAndIsrRequest.controllerEpochval partitions = new mutable.HashSet[Partition]()//要成功Leader分区的集合val partitionsToBeLeader = new mutable.HashMap[Partition, LeaderAndIsrPartitionState]()//要成为Follower分区的集合val partitionsToBeFollower = new mutable.HashMap[Partition, LeaderAndIsrPartitionState]()val topicIdUpdateFollowerPartitions = new mutable.HashSet[Partition]()//遍历requestPartitionStates,其中包含了来自控制器(controller)的分区状态请求requestPartitionStates.foreach { partitionState =>val topicPartition = new TopicPartition(partitionState.topicName, partitionState.partitionIndex)//对于每个分区状态请求,首先检查分区是否存在,如果不存在,则创建一个新的分区。val partitionOpt = getPartition(topicPartition) match {case HostedPartition.Offline =>stateChangeLogger.warn(s"Ignoring LeaderAndIsr request from " +s"controller $controllerId with correlation id $correlationId " +s"epoch $controllerEpoch for partition $topicPartition as the local replica for the " +"partition is in an offline log directory")responseMap.put(topicPartition, Errors.KAFKA_STORAGE_ERROR)Nonecase HostedPartition.Online(partition) =>Some(partition)case HostedPartition.None =>val partition = Partition(topicPartition, time, this)allPartitions.putIfNotExists(topicPartition, HostedPartition.Online(partition))Some(partition)}//接下来,检查分区的主题ID和Leader的epoch(版本号)等信息。partitionOpt.foreach { partition =>val currentLeaderEpoch = partition.getLeaderEpochval requestLeaderEpoch = partitionState.leaderEpochval requestTopicId = topicIdFromRequest(topicPartition.topic)val logTopicId = partition.topicIdif (!hasConsistentTopicId(requestTopicId, logTopicId)) {//如果主题ID不一致,则记录错误并将其添加到响应映射(responseMap)中。stateChangeLogger.error(s"Topic ID in memory: ${logTopicId.get} does not" +s" match the topic ID for partition $topicPartition received: " +s"${requestTopicId.get}.")responseMap.put(topicPartition, Errors.INCONSISTENT_TOPIC_ID)} //如果Leader的epoch大于当前的epoch,则记录控制器(controller)的epoch,并将分区添加到要成为Leader或Follower的集合中。 else if (requestLeaderEpoch > currentLeaderEpoch) { //分区副本确定是当前broker的,则添加到partitionsToBeLeader或者partitionsToBeFollower//如果分区副本是leader并且broker是当前broker,则加入partitionsToBeLeader//其他的放入到partitionsToBeFollower//这样保证后续操作partitionsToBeLeader或者partitionsToBeFollower只操作当前broker的if (partitionState.replicas.contains(localBrokerId)) {partitions += partitionif (partitionState.leader == localBrokerId) {partitionsToBeLeader.put(partition, partitionState)} else {partitionsToBeFollower.put(partition, partitionState)}} //省略代码.....}//创建高水位线检查点val highWatermarkCheckpoints = new LazyOffsetCheckpoints(this.highWatermarkCheckpoints)//如果partitionsToBeLeader非空,则调用makeLeaders方法将指定的分区设置为Leader,并返回这些分区的集合,否则返回空集合val partitionsBecomeLeader = if (partitionsToBeLeader.nonEmpty)//这个是处理Leader的逻辑makeLeaders(controllerId, controllerEpoch, partitionsToBeLeader, correlationId, responseMap,highWatermarkCheckpoints, topicIdFromRequest)elseSet.empty[Partition]//如果partitionsToBeFollower非空,则调用makeFollowers方法将指定的分区副本设置为Follower,并返回这些分区的集合,否则返回空集合。val partitionsBecomeFollower = if (partitionsToBeFollower.nonEmpty)//这个是处理Follower的逻辑makeFollowers(controllerId, controllerEpoch, partitionsToBeFollower, correlationId, responseMap,highWatermarkCheckpoints, topicIdFromRequest)elseSet.empty[Partition]//根据partitionsBecomeFollower集合获取Follower分区的主题集合,并更新相关指标。val followerTopicSet = partitionsBecomeFollower.map(_.topic).toSetupdateLeaderAndFollowerMetrics(followerTopicSet)//如果topicIdUpdateFollowerPartitions非空,则调用updateTopicIdForFollowers方法更新Follower分区的主题ID。if (topicIdUpdateFollowerPartitions.nonEmpty)updateTopicIdForFollowers(controllerId, controllerEpoch, topicIdUpdateFollowerPartitions, correlationId, topicIdFromRequest) //启动高水位检查点线程。startHighWatermarkCheckPointThread()//根据参数初始化日志目录获取器maybeAddLogDirFetchers(partitions, highWatermarkCheckpoints, topicIdFromRequest)//关闭空闲的副本获取器线程//todo FetcherThreadsreplicaFetcherManager.shutdownIdleFetcherThreads()replicaAlterLogDirsManager.shutdownIdleFetcherThreads()//省略代码.... }}//省略代码.... }}
因为这篇文章主要写Follower如何拉取数据,所以只需要关注上面代码中的makeFollowers就可以了
1、如果是Follower,则准备创建Fetcher线程,好异步执行向Leader拉取数据
/*1. 从领导者分区集中删除这些分区。2. 将这些 partition 标记为 follower,之后这些 partition 就不会再接收 produce 的请求了3. 停止对这些 partition 的副本同步,这样这些副本就不会再有(来自副本请求线程)的数据进行追加了4.对这些 partition 的 offset 进行 checkpoint,如果日志需要截断就进行截断操作;5. 清空 purgatory 中的 produce 和 fetch 请求6.如果代理未关闭,向这些 partition 的新 leader 启动副本同步线程* 执行这些步骤的顺序可确保转换中的副本在检查点偏移之前不会再接收任何消息,以便保证检查点之前的所有消息都刷新到磁盘*如果此函数中抛出意外错误,它将被传播到 KafkaAPIS,其中将在每个分区上设置错误消息,因为我们不知道是哪个分区导致了它。否则,返回由于此方法而成为追随者的分区集*/private def makeFollowers(controllerId: Int,controllerEpoch: Int,partitionStates: Map[Partition, LeaderAndIsrPartitionState],correlationId: Int,responseMap: mutable.Map[TopicPartition, Errors],highWatermarkCheckpoints: OffsetCheckpoints,topicIds: String => Option[Uuid]) : Set[Partition] = {val traceLoggingEnabled = stateChangeLogger.isTraceEnabled//省略代码。。。。//创建一个可变的Set[Partition]对象partitionsToMakeFollower,用于统计follower的集合val partitionsToMakeFollower: mutable.Set[Partition] = mutable.Set()try {partitionStates.forKeyValue { (partition, partitionState) =>//遍历partitionStates中的每个分区,根据分区的leader是否可用来改变分区的状态。val newLeaderBrokerId = partitionState.leadertry {if (metadataCache.hasAliveBroker(newLeaderBrokerId)) {//如果分区的leader可用,将分区设置为follower,并将其添加到partitionsToMakeFollower中。// Only change partition state when the leader is availableif (partition.makeFollower(partitionState, highWatermarkCheckpoints, topicIds(partitionState.topicName))) {partitionsToMakeFollower += partition}} else {//省略代码。。} catch {//省略代码。。。}}//删除针对partitionsToMakeFollower中 partition 的副本同步线程replicaFetcherManager.removeFetcherForPartitions(partitionsToMakeFollower.map(_.topicPartition))stateChangeLogger.info(s"Stopped fetchers as part of become-follower request from controller $controllerId " +s"epoch $controllerEpoch with correlation id $correlationId for ${partitionsToMakeFollower.size} partitions")//对于每个分区,完成延迟的抓取或生产请求。partitionsToMakeFollower.foreach { partition =>completeDelayedFetchOrProduceRequests(partition.topicPartition)}//如果正在关闭服务器,跳过添加抓取器的步骤。if (isShuttingDown.get()) {//省略代码} else {//对于每个分区,获取分区的leader和抓取偏移量,并构建partitionsToMakeFollowerWithLeaderAndOffset映射。val partitionsToMakeFollowerWithLeaderAndOffset = partitionsToMakeFollower.map { partition =>val leaderNode = partition.leaderReplicaIdOpt.flatMap(leaderId => metadataCache.getAliveBrokerNode(leaderId, config.interBrokerListenerName)).getOrElse(Node.noNode())val leader = new BrokerEndPoint(leaderNode.id(), leaderNode.host(), leaderNode.port())val log = partition.localLogOrExceptionval fetchOffset = initialFetchOffset(log)partition.topicPartition -> InitialFetchState(topicIds(partition.topic), leader, partition.getLeaderEpoch, fetchOffset)}.toMap//添加抓取器以获取partitionsToMakeFollowerWithLeaderAndOffset中的分区。replicaFetcherManager.addFetcherForPartitions(partitionsToMakeFollowerWithLeaderAndOffset)}} catch {//省略代码}//省略代码。。。}
2、遍历分区Follower副本,判断是否有向目标broker现成的Fetcher,如果是则复用,否则创建
之后执行replicaFetcherManager.addFetcherForPartitions把信息添加到指定的Fetcher线程中
// to be defined in subclass to create a specific fetcherdef createFetcherThread(fetcherId: Int, sourceBroker: BrokerEndPoint): T
//主要目的是将分区和偏移量添加到相应的Fetcher线程中def addFetcherForPartitions(partitionAndOffsets: Map[TopicPartition, InitialFetchState]): Unit = {lock synchronized {//首先对partitionAndOffsets进行分组,按照BrokerAndFetcherId来分组val partitionsPerFetcher = partitionAndOffsets.groupBy { case (topicPartition, brokerAndInitialFetchOffset) =>BrokerAndFetcherId(brokerAndInitialFetchOffset.leader, getFetcherId(topicPartition))}def addAndStartFetcherThread(brokerAndFetcherId: BrokerAndFetcherId,brokerIdAndFetcherId: BrokerIdAndFetcherId): T = {//创建Fetcher线程 val fetcherThread = createFetcherThread(brokerAndFetcherId.fetcherId, brokerAndFetcherId.broker)//把线程放入到fetcherThreadMapfetcherThreadMap.put(brokerIdAndFetcherId, fetcherThread)//线程启动fetcherThread.start()fetcherThread}for ((brokerAndFetcherId, initialFetchOffsets) <- partitionsPerFetcher) {val brokerIdAndFetcherId = BrokerIdAndFetcherId(brokerAndFetcherId.broker.id, brokerAndFetcherId.fetcherId)//将启动的FetcherThread线程添加到fetcherThreadMap中val fetcherThread = fetcherThreadMap.get(brokerIdAndFetcherId) match {// //检查是否已经存在一个与当前broker和fetcher id相匹配的Fetcher线程。case Some(currentFetcherThread) if currentFetcherThread.leader.brokerEndPoint() == brokerAndFetcherId.broker =>// reuse the fetcher thread//如果存在,则重用该线程currentFetcherThreadcase Some(f) =>//如果之前有,fetcher线程,则先关闭在创建一个新的Fetcher线程并启动f.shutdown()addAndStartFetcherThread(brokerAndFetcherId, brokerIdAndFetcherId)case None =>//创建一个新的Fetcher线程,并启动addAndStartFetcherThread(brokerAndFetcherId, brokerIdAndFetcherId)}//将分区添加到相应的Fetcher线程中// failed partitions are removed when added partitions to threadaddPartitionsToFetcherThread(fetcherThread, initialFetchOffsets)}}}
上面可能有疑问,为什么有重用fetcher线程?
答案:是broker并不一定会为每一个主题分区的Follower都启动一个 fetcher 线程,对于一个目的 broker,只会启动 num.replica.fetchers 个线程,具体这个 topic-partition 会分配到哪个 fetcher 线程上,是根据 topic 名和 partition id 进行计算得到,实现所示:
// Visibility for testingprivate[server] def getFetcherId(topicPartition: TopicPartition): Int = {lock synchronized {Utils.abs(31 * topicPartition.topic.hashCode() + topicPartition.partition) % numFetchersPerBroker}}
继续往下,其中createFetcherThread的实现是下面
3、创建Fetcher线程的实现
class ReplicaFetcherManager(brokerConfig: KafkaConfig,protected val replicaManager: ReplicaManager,metrics: Metrics,time: Time,threadNamePrefix: Option[String] = None,quotaManager: ReplicationQuotaManager,metadataVersionSupplier: () => MetadataVersion,brokerEpochSupplier: () => Long)extends AbstractFetcherManager[ReplicaFetcherThread](name = "ReplicaFetcherManager on broker " + brokerConfig.brokerId,clientId = "Replica",numFetchers = brokerConfig.numReplicaFetchers) {override def createFetcherThread(fetcherId: Int, sourceBroker: BrokerEndPoint): ReplicaFetcherThread = {val prefix = threadNamePrefix.map(tp => s"$tp:").getOrElse("")val threadName = s"${prefix}ReplicaFetcherThread-$fetcherId-${sourceBroker.id}"val logContext = new LogContext(s"[ReplicaFetcher replicaId=${brokerConfig.brokerId}, leaderId=${sourceBroker.id}, " +s"fetcherId=$fetcherId] ")val endpoint = new BrokerBlockingSender(sourceBroker, brokerConfig, metrics, time, fetcherId,s"broker-${brokerConfig.brokerId}-fetcher-$fetcherId", logContext)val fetchSessionHandler = new FetchSessionHandler(logContext, sourceBroker.id)val leader = new RemoteLeaderEndPoint(logContext.logPrefix, endpoint, fetchSessionHandler, brokerConfig,replicaManager, quotaManager, metadataVersionSupplier, brokerEpochSupplier)// 创建了一个ReplicaFetcherThread对象,它的构造函数接受多个参数,用于副本的获取和管理。new ReplicaFetcherThread(threadName, leader, brokerConfig, failedPartitions, replicaManager,quotaManager, logContext.logPrefix, metadataVersionSupplier)}def shutdown(): Unit = {info("shutting down")closeAllFetchers()info("shutdown completed")}
}
其中new ReplicaFetcherThread返回一个创建的线程
class ReplicaFetcherThread(name: String,leader: LeaderEndPoint,brokerConfig: KafkaConfig,failedPartitions: FailedPartitions,replicaMgr: ReplicaManager,quota: ReplicaQuota,logPrefix: String,metadataVersionSupplier: () => MetadataVersion)extends AbstractFetcherThread(name = name,clientId = name,leader = leader,failedPartitions,fetchTierStateMachine = new ReplicaFetcherTierStateMachine(leader, replicaMgr),fetchBackOffMs = brokerConfig.replicaFetchBackoffMs,isInterruptible = false,replicaMgr.brokerTopicStats) {override def doWork(): Unit = {super.doWork()completeDelayedFetchRequests()}}
而ReplicaFetcherThread继承的AbstractFetcherThread类,AbstractFetcherThread又继承自ShutdownableThread类,其中ShutdownableThread中的run方法是线程的执行函数
abstract class AbstractFetcherThread(name: String,clientId: String,val leader: LeaderEndPoint,failedPartitions: FailedPartitions,val fetchTierStateMachine: TierStateMachine,fetchBackOffMs: Int = 0,isInterruptible: Boolean = true,val brokerTopicStats: BrokerTopicStats) //BrokerTopicStats's lifecycle managed by ReplicaManagerextends ShutdownableThread(name, isInterruptible) with Logging {override def doWork(): Unit = {maybeTruncate()maybeFetch()}
}
public abstract class ShutdownableThread extends Thread {//省略代码public abstract void doWork();public void run() {isStarted = true;log.info("Starting");try {while (isRunning())doWork();} catch (FatalExitError e) {shutdownInitiated.countDown();shutdownComplete.countDown();log.info("Stopped");Exit.exit(e.statusCode());} catch (Throwable e) {if (isRunning())log.error("Error due to", e);} finally {shutdownComplete.countDown();}log.info("Stopped");}
}
ShutdownableThread中的run函数调用子类的doWork(),
而doWork中的执行顺序如下
//是否截断maybeTruncate()//抓取maybeFetch()//处理延时抓取请求completeDelayedFetchRequests()
其中 maybeFetch(),就是正常拼接fetch请求,并向目标broker发送请求,调用broker的case ApiKeys.FETCH => handleFetchRequest(request),
private def maybeFetch(): Unit = {//分区映射锁val fetchRequestOpt = inLock(partitionMapLock) {val ResultWithPartitions(fetchRequestOpt, partitionsWithError) = leader.buildFetch(partitionStates.partitionStateMap.asScala)handlePartitionsWithErrors(partitionsWithError, "maybeFetch")if (fetchRequestOpt.isEmpty) {trace(s"There are no active partitions. Back off for $fetchBackOffMs ms before sending a fetch request")partitionMapCond.await(fetchBackOffMs, TimeUnit.MILLISECONDS)}fetchRequestOpt}fetchRequestOpt.foreach { case ReplicaFetch(sessionPartitions, fetchRequest) =>processFetchRequest(sessionPartitions, fetchRequest)}}
相关文章:

kafka 3.5 主题分区的Follower创建Fetcher线程从Leader拉取数据源码
Kakfa集群有主题,每一个主题下又有很多分区,为了保证防止丢失数据,在分区下分Leader副本和Follower副本,而kafka的某个分区的Leader和Follower数据如何同步呢?下面就是讲解的这个 首先要知道,Follower的数据…...

Golang web 项目中实现自定义 recovery 中间件
为什么需要实现自定义 recovery 中间件? 在 Golang 的 Web 项目中,自定义 recovery 中间件是一种常见的做法,用于捕获并处理应用程序的运行时错误,以避免整个应用程序崩溃并返回对应格式的响应数据。 很多三方 web 框架…...
Direct3D绘制旋转立方体例程
初始化文件见Direct3D的初始化_direct3dcreate9_寂寂寂寂寂蝶丶的博客-CSDN博客 D3DPractice.cpp #include <windows.h> #include "d3dUtility.h" #include <d3dx9math.h>IDirect3DDevice9* Device NULL; IDirect3DVertexBuffer9* VB NULL; IDirect3…...

ElementUI浅尝辄止31:Tabs 标签页
选项卡组件:分隔内容上有关联但属于不同类别的数据集合。 常见于网站内容信息分类或app内容信息tab分类 1.如何使用? Tabs 组件提供了选项卡功能,默认选中第一个标签页,你也可以通过 value 属性来指定当前选中的标签页。 <temp…...

将 ChatGPT 用于数据科学项目的指南
推荐:使用 NSDT场景编辑器 快速搭建3D应用场景 我们都知道 ChatGPT 的受欢迎程度以及人们如何使用它来提高生产力。但是,如果您是新手,则值得注册ChatGPT免费演示并尝试它所能做的一切。您还应该参加我们的 ChatGPT 简介课程,学习…...

06-JVM对象内存回收机制深度剖析
上一篇:05-JVM内存分配机制深度剖析 堆中几乎放着所有的对象实例,对堆垃圾回收前的第一步就是要判断哪些对象已经死亡(即不能再被任何途径使用的对象)。 1.引用计数法 给对象中添加一个引用计数器,每当有一个地方引…...

[VSCode] 替换掉/去掉空行
VSCode中使用快捷键CtrlH,出现替换功能,在上面的“查找”框中输入正则表达式: ^\s*(?\r?$)\n然后选择右侧的“使用正则表达式”;“替换”框内为空,点击右侧的“全部替换”,即可去除所有空行。 参考 [VS…...
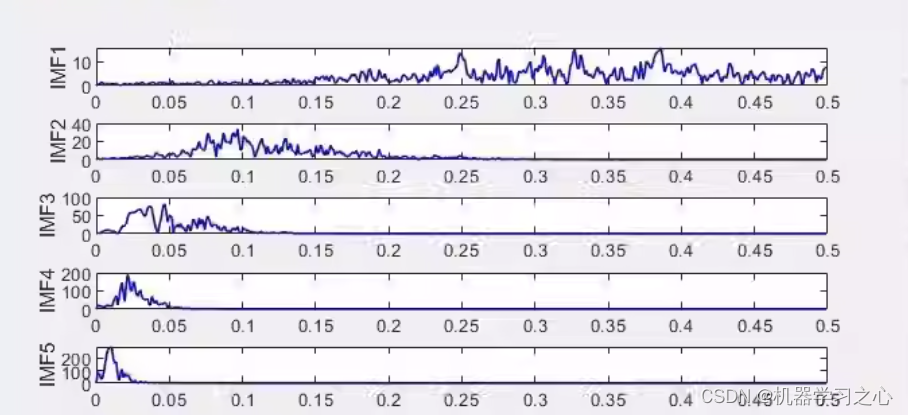
时序分解 | MATLAB实现ICEEMDAN+SE改进的自适应经验模态分解+样本熵重构分量
时序分解 | MATLAB实现ICEEMDANSE改进的自适应经验模态分解样本熵重构分量 目录 时序分解 | MATLAB实现ICEEMDANSE改进的自适应经验模态分解样本熵重构分量效果一览基本介绍程序设计参考资料 效果一览 基本介绍 ICEEMDANSE改进的自适应经验模态分解样本熵重构分量 包括频谱图 避…...

python内网环境安装第三方包【内网搭建开发环境】
文章目录 一、问题二、解决方法三、代码实现一、问题 内网安装第三方包的应用场景,一般是一些需要在没网的环境下进行开发的情况。这些环境一般仅支持本地局域网访问,所以只能在不下载任何第三方包的情况下艰难开发。 二、解决方法 将当前应用依赖的第三方包提前下载到本地…...

7.13 在SpringBoot中 正确使用Validation实现参数效验
文章目录 前言引入Maven依赖一、POST/PUT RequestBody参数校验1.1 Valid或Validated注解配合constraints注解1.2 测试运行 二、GET/DELETE RequestParam参数校验2.1 Validated注解配合constraints注解2.2 测试运行 三、GET 无注解参数校验3.1 Valid或Validated注解配合constrai…...

Matlab图像处理之Lee滤波器
目录 一、前言:二、LEE滤波器2.1 LEE滤波器原理2.2 LEE滤波器实现步骤三、MATLAB代码示例一、前言: LEE滤波器是一种常用于合成孔径雷达(SAR)图像去噪的滤波器。它能增强图像的局部对比度。今天我们将通过MATLAB来实现这种滤波器。 二、LEE滤波器 2.1 LEE滤波器原理 LEE滤…...

C++系列-const修饰的常函数
const修饰的常函数 常函数常对象 常函数 成员函数后加const,称为常函数。常函数内部不可以修改成员变量。常函数内可以改变加了mutable修饰的成员变量。 code:#include <iostream>using namespace std;class Horse{public:int age 3;mutable string color …...
fail-safe 机制与 fail-fast 机制
Fail-fast 表示快速失败,在集合遍历过程中,一旦发现容器中的数据被修改了,会立刻抛出 ConcurrentModificationException 异常,从而导致遍历失败,像这种情况 定义一个 Map 集合,使用 Iterator 迭代器进行数据…...

LLM 位置编码及外推
RoPE https://zhuanlan.zhihu.com/p/629681325 PI 位置插值(POSITION INTERPOLATION)显著改善RoPE的外推能力。你只需要对PT(pretraining)模型fine-turing最多1000步就能实现。PI是通过将线性的缩小了输入位置的索引使其匹配原始上下文窗口…...

第3章_瑞萨MCU零基础入门系列教程之开发环境搭建与体验
本教程基于韦东山百问网出的 DShanMCU-RA6M5开发板 进行编写,需要的同学可以在这里获取: https://item.taobao.com/item.htm?id728461040949 配套资料获取:https://renesas-docs.100ask.net 瑞萨MCU零基础入门系列教程汇总: ht…...

AI在医疗保健领域:突破界限,救治生命
文章目录 AI在医学影像分析中的应用AI在疾病预测和早期诊断中的作用个性化治疗和药物研发医疗数据管理和隐私保护未来展望 🎉欢迎来到AIGC人工智能专栏~AI在医疗保健领域:突破界限,救治生命 ☆* o(≧▽≦)o *☆嗨~我是IT陈寒🍹✨博…...

centos7安装kubernets集群
一、准备工作 准备三台虚拟机,centos7系统 二、系统配置 1. 修改主机名 # 三台机器都需要执行 hostnamectl set-hostname k8s-master hostnamectl set-hostname k8s-node1 hostnamectl set-hostname k8s-node22. 修改hosts文件 # 三台机器都需要执行 [rootk8s-…...
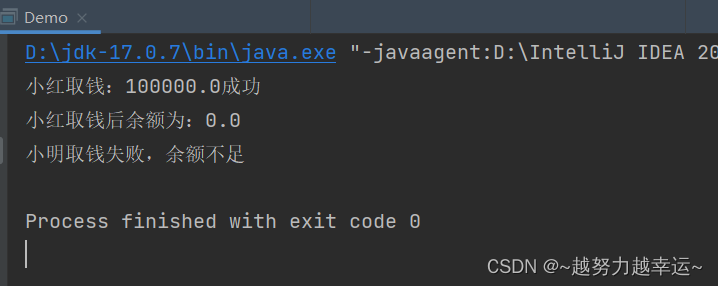
【多线程】线程安全与线程同步
线程安全与线程同步 1.什么是线程安全问题? 多个线程同时操作同一个共享资源的时候,可能会出现业务安全问题 取钱的线程安全问题场景: 两个人他们有一个共同的账户,余额是10万元,如果两个人同时来取钱,…...

指针权限,new与delete,类与对象,函数模板,类模板的用法
指针权限 用法 void Print(const char* SecretPointer) {cout << "绝密指令为:";cout << SecretPointer << endl; }void Change(int& number, int* const FixedPointer) {cout << "更换站台数字为:";c…...

Unity——脚本与序列化
在介绍序列化之前,我们先来了解一下为什么要对数据进行序列化 数据序列化有以下几个主要的应用场景和目的: 1. 持久化存储:序列化可以将对象或数据结构转换为字节序列,使得其可以被存储在磁盘上或数据库中。通过序列化ÿ…...
连接)
Springboot 实现多数据源(PostgreSQL 和 SQL Server)连接
为 HagiCode 添加 GitHub Pages 自动部署支持 本项目早期代号为 PCode,现已正式更名为 HagiCode。本文记录了如何为项目引入自动化静态站点部署能力,让内容发布像喝水一样简单。 背景/引言 在 HagiCode 的开发过程中,我们遇到了一个很现实的问…...

从智能门铃到工业质检:拆解5个嵌入式AI落地案例,看模型压缩和硬件选型怎么选
从智能门铃到工业质检:5个嵌入式AI实战案例与选型策略 智能门铃的摄像头突然捕捉到一张陌生面孔,300毫秒内完成本地人脸比对并推送到主人手机——这背后是嵌入式AI在消费电子领域的典型应用。当算法工程师面对瑞芯微RK3588和地平线旭日X3两颗芯片的选型表…...

Qt QTabWidget标签页文字方向调校实战:当标签在左侧时,如何让文字乖乖水平显示?
Qt QTabWidget标签页文字方向调校实战:当标签在左侧时,如何让文字乖乖水平显示? 在桌面应用开发中,Qt框架的QTabWidget组件因其灵活性和易用性广受开发者青睐。但当我们尝试将标签页位置调整为左侧时,一个令人头疼的问…...

边缘智能部署:AI模型在边缘节点的轻量化改造
边缘智能部署:AI模型在边缘节点的轻量化改造📚 本章学习目标:深入理解AI模型在边缘节点的轻量化改造的核心概念与实践方法,掌握关键技术要点,了解实际应用场景与最佳实践。本文属于《云原生、云边端一体化与算力基建&a…...

把openEuler当微服务跑:Docker Compose编排实战,管理Nginx+MySQL多容器应用
微服务架构下的openEuler容器化实践:NginxMySQL多容器编排指南 1. 云原生时代的轻量级操作系统选择 在容器化技术席卷全球的今天,开发者们越来越倾向于将操作系统本身也视为可编排的服务单元。openEuler作为一款专为云原生场景优化的Linux发行版…...

GLM-OCR部署避坑:CPU模式也能用,无显卡用户详细指南
GLM-OCR部署避坑:CPU模式也能用,无显卡用户详细指南 你是不是也遇到过这种情况:看到别人用AI模型轻松识别文档、提取表格,自己也想试试,结果一查部署要求——“需要NVIDIA显卡,显存8GB以上”。手头只有一台…...

让 AI 听懂业务、直接干活:销售易 NeoAgent 2.0 的三大跃迁
当软件行业仍在争论“AI是否会杀死SaaS”时,销售易已经给出了自己的答案。3月27日,在2026腾讯云城市峰会首站上海站,腾讯旗下CRM销售易正式发布新一代营销服全场景AI原生CRM——NeoAgent 2.0。这并非一次简单的产品迭代,而是销售易…...
)
保姆级教程:从WOS下载文献到Citespace出图,手把手搞定科研可视化(附避坑指南)
科研可视化实战:从WOS数据采集到Citespace图谱优化的完整指南 第一次打开Citespace时,看着满屏的英文参数和报错提示,我盯着屏幕发了十分钟呆——这大概是每个科研新手都会经历的"震撼教育"。文献计量分析本应是揭示知识脉络的利器…...

MelonLoader终极指南:Unity游戏Mod加载器从入门到精通
MelonLoader终极指南:Unity游戏Mod加载器从入门到精通 【免费下载链接】MelonLoader The Worlds First Universal Mod Loader for Unity Games compatible with both Il2Cpp and Mono 项目地址: https://gitcode.com/gh_mirrors/me/MelonLoader 还在为Unity游…...

SEO_避开这些SEO误区,优化效果事半功倍
SEO误区:避开这些误区,优化效果事半功倍 在当今竞争激烈的互联网环境中,搜索引擎优化(SEO)成为了每一个网站主的必修课。不少人在SEO实践中却犯下了一些常见的误区,这些误区不仅没有提升网站的排名&#x…...