基于keras中Lenet对于mnist的处理
文章目录
- MNIST
- 导入必要的包
- 加载数据
- 可视化数据集
- 查看数据集的分布
- 开始训练
- 画出loss图
- 画出accuracy图
- 使用数据外的图来测试
- 图片可视化
- 转化灰度图的可视化
- 可视化卷积层的特征图
- 第一层卷积 conv1 和 pool1
- 第二层卷积 conv2 和 pool2
MNIST
MNIST(Modified National Institute of Standards and Technology database)是一个经典的手写数字数据集,通常用于计算机视觉和机器学习的基准测试。以下是关于MNIST数据集的介绍:
数据集内容:
MNIST数据集包含了大约70000张28x28像素的手写数字图片。
这些图片包括了从0到9的10个不同数字,每个数字都有大约7000张图片。
用途:
MNIST数据集通常用于图像分类任务,目标是将手写数字图片分为0到9的10个类别。
它被广泛用于测试和验证各种图像处理和机器学习算法,特别是深度学习模型。
数据特点:
- 每张图片都是灰度图像,即只有一个颜色通道(黑白)。
- 图像的大小固定为28x28像素,总共784个像素。
- 每个像素的值在0到255之间,表示像素的亮度。
挑战:
MNIST数据集相对较小,对于现代深度学习模型来说,通常被认为是一个相对简单的任务。
然而,MNIST仍然具有一定的挑战性,因为手写数字的风格和字体会有很大的差异,有些数字可能写得非常潦草或难以识别。
应用领域:
MNIST数据集通常用于教育和研究,帮助初学者理解图像分类和深度学习概念。
它还可以作为一个基准测试数据集,用于验证新的机器学习算法或深度学习架构的性能。

https://classic.d2l.ai/chapter_convolutional-neural-networks/lenet.html
import tensorflow as tf
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense, Dropout
from tensorflow.keras.optimizers import Adamdef leNet_model():model = Sequential()model.add(Conv2D(30, (5, 5), input_shape=(28, 28, 1), activation='relu')) # 24*24*30model.add(MaxPooling2D(pool_size=(2, 2)))model.add(Conv2D(15, (3, 3), activation='relu')) # 15*30*3*3model.add(MaxPooling2D(pool_size=(2, 2)))model.add(Flatten())model.add(Dense(500, activation='relu'))model.add(Dropout(0.5))model.add(Dense(num_classes, activation='softmax'))# 使用Adam优化器,学习率为0.01optimizer = Adam(learning_rate=0.01)# 编译模型,使用交叉熵损失函数和准确率作为指标model.compile(optimizer=optimizer, loss='categorical_crossentropy', metrics=['accuracy'])return modelmodel = leNet_model()
print(model.summary())
_________________________________________________________________Layer (type) Output Shape Param #
=================================================================conv2d_6 (Conv2D) (None, 24, 24, 30) 780 max_pooling2d_6 (MaxPoolin (None, 12, 12, 30) 0 g2D) conv2d_7 (Conv2D) (None, 10, 10, 15) 4065 max_pooling2d_7 (MaxPoolin (None, 5, 5, 15) 0 g2D) flatten_3 (Flatten) (None, 375) 0 dense_5 (Dense) (None, 500) 188000 dropout_3 (Dropout) (None, 500) 0 dense_6 (Dense) (None, 10) 5010 =================================================================
Total params: 197855 (772.87 KB)
Trainable params: 197855 (772.87 KB)
Non-trainable params: 0 (0.00 Byte)
_________________________________________________________________
导入必要的包
!pip install Keras==2.0.6
!pip install np_utils
import numpy as np
import matplotlib.pyplot as plt
import keras
from keras.datasets import mnist
from keras.utils.np_utils import to_categorical
import random
from keras.models import Model
加载数据
# 设置随机种子,以确保结果可重复
np.random.seed(0)# 使用Keras的mnist.load_data()加载MNIST数据集,将数据集分为训练集和测试集
(X_train, y_train), (X_test, y_test) = mnist.load_data()# 打印训练集和测试集的形状(维度)
print(X_train.shape) #(60000, 28, 28)
print(X_test.shape) #(10000, 28, 28)
可视化数据集
# 创建一个空列表用于存储每个数字类别的样本数量
num_of_samples = []# 定义图形中的列数和数字类别总数
cols = 5
num_classes = 10# 创建一个图形子图,包含num_classes行和cols列
fig, axs = plt.subplots(nrows=num_classes, ncols=cols, figsize=(5, 10))
fig.tight_layout()# 遍历每列和每个数字类别
for i in range(cols):for j in range(num_classes):# 从训练集中选择特定类别的图像x_selected = X_train[y_train == j]# 随机选择一张图像并显示在子图中axs[j][i].imshow(x_selected[random.randint(0, (len(x_selected) - 1)), :, :], cmap=plt.get_cmap('gray'))axs[j][i].axis("off")if i == 2:axs[j][i].set_title(str(j)) # 在中间列添加标题num_of_samples.append(len(x_selected)) # 记录每个类别的样本数量# 打印每个数字类别的样本数量
print(num_of_samples)# 创建一个新的图形,用于显示样本数量
plt.figure(figsize=(12, 4))生成5示例和10个种类

查看数据集的分布
# 使用Matplotlib绘制柱状图,展示训练数据集中各个类别的样本数量分布
plt.bar(range(0, num_classes), num_of_samples) # 创建柱状图,x轴为类别编号,y轴为样本数量
plt.title("Distribution of the train dataset") # 设置图表标题
plt.xlabel("Class number") # 设置x轴标签
plt.ylabel("Number of images") # 设置y轴标签
plt.show() # 显示柱状图# 重新调整图像数据的形状,以匹配卷积神经网络(CNN)的输入要求
X_train = X_train.reshape(60000, 28, 28, 1) # 将训练数据集的形状重塑为(样本数量, 28, 28, 1)
X_test = X_test.reshape(10000, 28, 28, 1) # 将测试数据集的形状重塑为(样本数量, 28, 28, 1)# 对训练和测试标签进行独热编码,以适应多类别分类任务
y_train = to_categorical(y_train, 10) # 将训练标签独热编码为(样本数量, 10)
y_test = to_categorical(y_test, 10) # 将测试标签独热编码为(样本数量, 10)# 数据归一化:将图像像素值从0到255的范围缩放到0到1的范围,有助于模型训练
X_train = X_train / 255 # 训练数据集归一化处理
X_test = X_test / 255 # 测试数据集归一化处理

开始训练
history = model.fit(X_train, y_train,\
epochs=10, validation_split = 0.1, batch_size = 400,\verbose = 1, shuffle = True)
| 参数 | 描述 |
|---|---|
| X_train | 训练数据 |
| y_train | 训练标签 |
| epochs | 训练的轮数 |
| validation_split | 将训练数据的一部分用于验证的比例 |
| batch_size | 每个小批量的样本数量 |
| verbose | 控制训练过程中的输出信息级别 |
| shuffle | 是否在每轮训练前随机打乱训练数据 |
画出loss图
# 使用Matplotlib绘制训练过程中的损失曲线
plt.plot(history.history['loss']) # 绘制训练集上的损失值曲线
plt.plot(history.history['val_loss']) # 绘制验证集上的损失值曲线
plt.legend(['loss', 'val_loss']) # 添加图例,标记曲线含义
plt.title('Loss') # 设置图表标题为"Loss"
plt.xlabel('epoch') # 设置x轴标签为"epoch",表示训练轮数画出accuracy图
# 使用Matplotlib绘制训练过程中的准确率曲线
plt.plot(history.history['accuracy']) # 绘制训练集上的准确率曲线
plt.plot(history.history['val_accuracy']) # 绘制验证集上的准确率曲线
plt.legend(['accuracy', 'val_accuracy']) # 添加图例,标记曲线含义
plt.title('Accuracy') # 设置图表标题为"Accuracy",表示准确率曲线的含义
plt.xlabel('epoch') # 设置x轴标签为"epoch",表示训练轮数使用数据外的图来测试
给图片加点noise,看看测试结果
图片可视化
import requests # 导入 requests 库,用于发送 HTTP 请求
from PIL import Image # 导入 PIL 库,用于图像处理
import numpy as np # 导入 NumPy 库,用于数组操作
import matplotlib.pyplot as plt # 导入 Matplotlib 库,用于图像显示# 指定要下载的图像的URL
url = "https://colah.github.io/posts/2014-10-Visualizing-MNIST/img/mnist_pca/MNIST-p1815-4.png"# 发送HTTP GET请求,获取图像数据,stream=True 表示以流的方式获取数据
response = requests.get(url, stream=True)# 打印HTTP响应状态码,以确认是否成功获取图像数据
print(response)# 使用PIL库打开图像,并将数据存储在img对象中
img = Image.open(response.raw)# 使用Matplotlib显示图像,指定灰度色彩映射
plt.imshow(img, cmap=plt.get_cmap('gray'))# 将图像转换为NumPy数组
img_array = np.asarray(img)# 打印图像数组的形状,以了解图像的尺寸和通道数
print(img_array.shape)

转化灰度图的可视化
import cv2
resized = cv2.resize(img_array,(28,28)) #通过opencv像素
gray_scale = cv2.cvtColor(resized,cv2.COLOR_BGR2GRAY)#取灰度值
image = cv2.bitwise_not(gray_scale)# 对灰度图像进行按位取反操作,即将图像中的白色像素变为黑色,黑色像素变为白色
plt.imshow(gray_scale,cmap=plt.get_cmap("gray")) #将图片显示位黑白

image = image/255
image = image.reshape(1,28,28,1) #让他和我们训练得时候一样
prediction = np.argmax(model.predict(image))#多类数据集得预测模型
print("预测结果: ",str(prediction))
1/1 [==============================] - 0s 18ms/step
预测结果数字: 4
#看测试结果
score = model.evaluate(X_test,y_test,verbose=0)
print(type(score))
print('Test socre', score[0])
print('Test accuracy',score[1])
可视化卷积层的特征图
# 利用 Model API 获取模型中间层的输出
# 创建两个新的模型,layer1 和 layer2,分别将输入和输出连接到模型的第一个和第三个层
layer1 = Model(inputs=model.layers[0].input, outputs=model.layers[0].output)
layer2 = Model(inputs=model.layers[0].input, outputs=model.layers[2].output)# 使用 layer1 和 layer2 对输入图像进行预测,获取中间层的输出
visual_layer1, visual_layer2 = layer1.predict(image), layer2.predict(image)# 打印中间层的输出形状
print(visual_layer1.shape)
print(visual_layer2.shape)第一层卷积 conv1 和 pool1
# 创建一个 10x6 的大图,用于显示多个特征图
plt.figure(figsize=(10, 6))# 循环遍历每个卷积核的特征图
for i in range(30):# 在大图中创建子图,6行5列,i+1 表示子图的位置plt.subplot(6, 5, i+1)# 显示特征图,使用 'jet' 色彩映射以增强可视化效果plt.imshow(visual_layer1[0, :, :, i], cmap=plt.get_cmap('jet'))# 关闭坐标轴plt.axis('off')# 显示整个图像
plt.show()
这段代码通过循环遍历第一层卷积层的每个卷积核(共30个),并将其特征图可视化显示出来。每个特征图都以不同的颜色显示,通过色彩映射(‘jet’)可以增强特征图的可视化效果。这有助于理解卷积层在图像中检测到的不同特征或模式。
通过在 plt.subplot() 中设置合适的行列数和位置,可以将多个特征图显示在同一图像中,以便一次性查看多个特征。这种可视化方法有助于深入了解神经网络的特征提取过程。

第二层卷积 conv2 和 pool2
plt.figure(figsize=(10,6))
for i in range(15):plt.subplot(3,5,i+1)plt.imshow(visual_layer2[0,:,:,i],cmap=plt.get_cmap('jet'))plt.axis('off')

相关文章:
基于keras中Lenet对于mnist的处理
文章目录 MNIST导入必要的包加载数据可视化数据集查看数据集的分布开始训练画出loss图画出accuracy图 使用数据外的图来测试图片可视化转化灰度图的可视化可视化卷积层的特征图第一层卷积 conv1 和 pool1第二层卷积 conv2 和 pool2 MNIST MNIST(Modified National …...

Python爬虫 教程:IP池的使用
前言 嗨喽~大家好呀,这里是魔王呐 ❤ ~! python更多源码/资料/解答/教程等 点击此处跳转文末名片免费获取 一、简介 爬虫中为什么需要使用代理 一些网站会有相应的反爬虫措施,例如很多网站会检测某一段时间某个IP的访问次数,如果访问频率…...

Ansible之playbook剧本
一、playbook概述1.1 playbook 介绍1.2 playbook 组成部分 二、playbook 示例2.1 playbook 启动及检测2.2 实例一2.3 vars 定义、引用变量2.4 指定远程主机sudo切换用户2.5 when条件判断2.6 迭代2.7 Templates 模块1.先准备一个以 .j2 为后缀的 template 模板文件,设…...
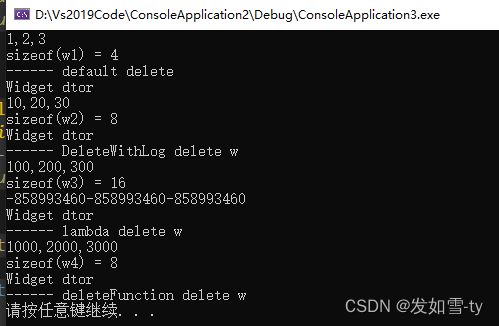
unique_ptr的大小探讨
unique_ptr大小和删除器有很大关系,具体区别看如下代码的分析。不要让unique_ptr占用的空间太大,否则不会达到裸指针同样的效果。 #include <iostream> #include <memory> using namespace std;class Widget {int m_x;int m_y;int m_z;publ…...

人工智能TensorFlow PyTorch物体分类和目标检测合集【持续更新】
1. 基于TensorFlow2.3.0的花卉识别 基于TensorFlow2.3.0的花卉识别Android APP设计_基于安卓的花卉识别_lilihewo的博客-CSDN博客 2. 基于TensorFlow2.3.0的垃圾分类 基于TensorFlow2.3.0的垃圾分类Android APP设计_def model_load(img_shape(224, 224, 3)_lilihewo的博客-CS…...

ElementPlus·面包屑导航实现
面包屑导航 使用vue3中的UI框架elementPlus的 <el-breadcrumb> 实现面包屑导航 <template><!-- 面包屑 --><div class"bread-container" ><el-breadcrumb separator">"><el-breadcrumb-item :to"{ path:/ }&quo…...

【项目管理】PM vs PMO 18点区别
导读:项目经理跟PMO主要有哪些区别?首先从定义上了解,然后根据其他维度进行对比分析,基本可以了解这二者的区别,文中罗列18点区别供各位参考。 目录 1、定义 1.1 PMO 1.2 PM 2、两者区别 2.1 ROI 2.2 项目成功率…...

13 Python使用Json
概述 在上一节,我们介绍了如何在Python中使用xml,包括:SAX、DOM、ElementTree等内容。在这一节,我们将介绍如何在Python中使用Json。Json的英文全称为JavaScript Object Notation,中文为JavaScript对象表示法ÿ…...

PDFBOX和ASPOSE.PDF
一、aspose.pdf 文档 https://docs.aspose.com/pdf/java/ 1、按段落分段 /*** docx文本按段分段*/ public static void main(String[] args) {int i 1;try {// 打开文件流FileInputStream file new FileInputStream("I:\\范文.docx");// 创建 Word 文档对象XWPFDo…...

第51节:cesium 范围查询(含源码+视频)
结果示例: 完整源码: <template><div class="viewer"><el-button-group class="top_item"><el-button type=...

YOLOv5改进算法之添加CA注意力机制模块
目录 1.CA注意力机制 2.YOLOv5添加注意力机制 送书活动 1.CA注意力机制 CA(Coordinate Attention)注意力机制是一种用于加强深度学习模型对输入数据的空间结构理解的注意力机制。CA 注意力机制的核心思想是引入坐标信息,以便模型可以更好地…...
Jmeter系列-阶梯加压线程组Stepping Thread Group详解(6)
前言 tepping Thread Group是第一个自定义线程组但,随着版本的迭代,已经有更好的线程组代替Stepping Thread Group了【Concurrency Thread Group】,所以说Stepping Thread Group已经是过去式了,但还是介绍一下 Stepping Thread …...

图像的几何变换(缩放、平移、旋转)
图像的几何变换 学习目标 掌握图像的缩放、平移、旋转等了解数字图像的仿射变换和透射变换 1 图像的缩放 缩放是对图像的大小进行调整,即 使图像放大或缩小 cv2.resize(src,dsize,fx0,fy0,interpolationcv2.INTER_LINEAR) 参数: src :输入图像dsize…...

计算机网络第四章——网络层(上)
提示:朝碧海而暮苍梧,睹青天而攀白日 文章目录 网络层是路由器的最高层次,通过网络层就可以将各个设备连接到一起,从而实现这两个主机的数据通信和资源共享,之前学的数据链路层和物理层也是将两端连接起来,但是却没有网…...

【MyBatis】一、MyBatis概述与基本使用
Mybatis概述 Mybatis是一个半自动化的框架,需要自己写sql语句,对比JDBC其有耦合性更低的SQL语句与Java代码,各司其职不相互冗杂,对比Hibernate与JPA其又有更灵活的SQL编写能力。 环境搭建 引入相关依赖并打jar包 <dependenc…...

Java事件机制简介 内含面试题
面试题分享 云数据解决事务回滚问题 点我直达 2023最新面试合集链接 2023大厂面试题PDF 面试题PDF版本 java、python面试题 项目实战:AI文本 OCR识别最佳实践 AI Gamma一键生成PPT工具直达链接 玩转cloud Studio 在线编码神器 玩转 GPU AI绘画、AI讲话、翻译,GPU点亮…...

springMVC基础技术使用
目录 1.常用注解 1.1RequestMapping 1.2.RequestParam 1.3.RequestBody 1.4.PathVariable 2.参数传递 2.1 slf4j-----日志 2.2基础类型 2.3复杂类型 2.4RequestParam 2.5PathVariable 2.6RequestBody 2.7请求方法(增删改查) 3.返回值 3.1void …...

UI设计师的发展前景是否超越了平面设计?
这是一个现代经济学的典型话题:应该跟随趋势追逐风口,还是坚守成熟的“夕阳产业” UI 设计行业发展短短不过 20 多年,但平面设计这个“夕阳产业”最早可以追溯到上世纪的二三十年代。显而易见的答案是,更新兴的 UI 设计师得到的好…...

MyBatis的基本操作
目录 一、MyBatis的增删改查1、添加2、删除3、修改4、查询一个实体类对象5、查询集合 二、MyBatis的各种查询功能1、查询一个实体类对象2、查询一个list集合3、查询单个数据4、查询一条数据为map集合5、查询多条数据为map集合 三、特殊SQL的执行1、模糊查询2、批量删除3、动态设…...

【Tomcat】在SpringBoot项目中,Tomcat是如何处理HTTP请求的
目录 首先了解一下标准的Tomcat处理HTTP请求的流程 SpringBoot项目中Tomcat处理流程 首先了解一下标准的Tomcat处理HTTP请求的流程 监听端口:Tomcat 在启动时监听指定的端口,等待客户端发送请求。 接收请求:当客户端发起一个 HTTP 请…...

Ubuntu环境下离线部署Docker生态全攻略:从安装到镜像迁移
1. 为什么需要离线部署Docker?从企业内网说起 大家好,我是老张,在运维和开发这个行当里摸爬滚打了十几年,经手过不少企业级项目。今天想和大家聊聊一个非常实际,但又常常让新手头疼的场景:在完全没有外网的…...

Python射线检测实战:trimesh与python-mesh-raycast性能对比与应用选择
1. 为什么你需要关心Python射线检测? 如果你正在捣鼓3D项目,比如机器人导航、游戏开发、三维重建,或者像我之前做的一个无人机避障模拟系统,那你大概率会遇到一个经典问题:怎么判断一条射线(想象成一道激光…...

LightTools中手动构建菲涅尔透镜的折线优化技巧
1. 为什么需要手动构建菲涅尔透镜? 很多刚开始用LightTools的朋友,一听到要自己手动建菲涅尔透镜,第一反应可能是:“软件不是自带菲涅尔透镜实用程序(Fresnel Lens Utility)吗?为什么还要费这个…...

纯硬件雪花氛围灯设计:无MCU触控调光与锂电池管理
1. 项目概述雪花氛围灯是一款面向电子爱好者与嵌入式初学者设计的便携式装饰照明装置。其核心价值在于将基础模拟电路、电池管理、电容式触摸交互与结构化外壳集成于一个直径仅65mm、高度50mm的紧凑球形空间内,兼顾功能性、安全性与可制造性。整机采用纯硬件方案实现…...

开源工具如何解决鸣潮游戏性能问题?提升帧率与优化体验的完整方案
开源工具如何解决鸣潮游戏性能问题?提升帧率与优化体验的完整方案 【免费下载链接】WaveTools 🧰鸣潮工具箱 项目地址: https://gitcode.com/gh_mirrors/wa/WaveTools 你是否正在寻找一款能够有效解决鸣潮游戏卡顿、帧率不稳定问题的游戏工具&…...
)
告别“封号”与“宕机”:2026企业级Python分布式爬虫架构实战(微服务+K8s全链路解析)
前言 在2026年的今天,数据采集早已不是写个requests循环就能搞定的小事。 面对反爬机制的智能化(指纹识别、行为分析、AI验证码)、目标网站的高并发压力以及企业内部对数据时效性、合规性的严苛要求,传统的单体爬虫架构显得捉襟见…...

F3D在Windows平台的高效应用指南:从安装到性能优化
F3D在Windows平台的高效应用指南:从安装到性能优化 【免费下载链接】f3d Fast and minimalist 3D viewer. 项目地址: https://gitcode.com/GitHub_Trending/f3/f3d 解决3D查看器的性能与兼容性难题 在Windows环境下处理3D模型时,你是否经常遇到加…...

WuliArt Qwen-Image Turbo功能详解:BF16防黑图、VAE分块解码都是啥?
WuliArt Qwen-Image Turbo功能详解:BF16防黑图、VAE分块解码都是啥? 1. 为什么这款文生图工具值得关注? 你有没有遇到过这样的情况:在本地运行文生图模型时,等待几分钟后只得到一张全黑的图片?或者生成的…...

Flutter增量编译
遇到这个问题,就是缓存和文件不在同一个系统盘,我们把增量编译关闭就好,然后把系统的flutter缓存位置修改(环境变量中)// 新增:禁用 Kotlin 增量编译tasks.withType<org.jetbrains.kotlin.gradle.tasks.…...

西门子罗宾康A5E31418305
孙13665068812西门子罗宾康A5E31418305产品介绍西门子罗宾康(Robicon)A5E31418305是一款高性能工业变频器驱动模块,属于西门子旗下罗宾康品牌的中压变频器产品线。该型号广泛应用于电力、石化、冶金、矿山等工业领域,以其卓越的可…...