Spark【RDD编程(四)综合案例】
案例1-TOP N个数据的值
输入数据:
1,1768,50,155
2,1218,600,211
3,2239,788,242
4,3101,28,599
5,4899,290,129
6,3110,54,1201
7,4436,259,877
8,2369,7890,27处理代码:
def main(args: Array[String]): Unit = {//创建SparkContext对象val conf:SparkConf = new SparkConf()conf.setAppName("test1").setMaster("local")val sc: SparkContext = new SparkContext(conf)var index: Int = 0//通过加载本地文件系统的数据创建RDD对象val rdd: RDD[String] = sc.textFile("data/file1.txt")rdd.filter(line=>line.split(",").length == 4).map(line=>line.split(",")(2)).map(word=>(word.toInt,1)).sortByKey(false).map(kv=>kv._1).take(5).foreach(key=>{index += 1println(index + s"\t$key")})//关闭SparkContext对象sc.stop()}代码解析:
-
sc.textFile("data/file1.txt"):通过加载本地文件来创建RDD对象 -
rdd.filter(line=>line.split(",").length == 4):确保数据的完整性 -
map(line=>line.split(",")(2)):通过逗号将一行字符串分隔开来组成一个Array数组并取出数组中第3个严肃 -
map(word=>(word.toInt,1)):因为我们的sortByKey方法是针对键值对进行操作的,所以必须把我们上面取出来的值转为(值,x)形式的键值对。
-
sortByKey(false):设置参数为false表示降序排列。
-
map(kv=>kv._1).take(5):取出top五。
运行结果:
1 7890
2 788
3 600
4 290
5 259案例2-文件排序
要求:输入三个文件(每行一个数字),要求输出一个文件,文件内文本格式为(序号 数值)。
rdd.map(num => (num.toInt,1)).partitionBy(new HashPartitioner(1)).sortByKey().map(t=>{index += 1(index,t._1)}).foreach(println) //只有调用 行动操作语句 才会触发真正的从头到尾的计算
我们会发现,如果我们不调用 foreach 这个行动操作而是直接在转换操作中进行输出的话,这样是输出不来结果的,所以我们必须要调用行动操作。
而且,我们必须对分区进行归并,因为在分布式环境下,只有把多个分区合并成一个分区,才能使得结果整体有序。(这里尽管我们是本地测试,数据源是一个目录下的文件,但是我们也要考虑到假如是在分布式环境下的情况)
运行结果:
(1,1)
(2,4)
(3,5)
(4,12)
(5,16)
(6,25)
(7,33)
(8,37)
(9,39)
(10,40)
(11,45)案例3-二次排序
要求:对格式为(数值 数值)类型的数据进行排序,假如第一个数值相同,则比较第二个数值。
import com.study.spark.core.rdd
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}class SecondarySortKey(val first:Int,val second:Int) extends Ordered[SecondarySortKey] with Serializable {override def compare(other: SecondarySortKey): Int = {if (this.first - other.first != 0) {this.first - other.first}else{this.second-other.second}}
}
object SecondarySortKey{def main(args: Array[String]): Unit = {val conf:SparkConf = new SparkConf()conf.setAppName("test3").setMaster("local")val sc: SparkContext = new SparkContext(conf)val rdd: RDD[String] = sc.textFile("data/sort/test03.txt")val rdd2: RDD[(SecondarySortKey, String)] = rdd.map(line => (new SecondarySortKey(line.split(" ")(0).toInt, line.split(" ")(1).toInt), line))rdd2.sortByKey(false).map(t=>t._2).foreach(println)sc.stop()}
}这里我们使用了自定义的类并继承了Ordered 和 Serializable 这两个特质,为了实现自定义的排序规则。 其中,Ordered 特质的混入需要重写它的 compare 方法来实现我们的自定义比较规则,而 Serializable 的混入作用是使得我们的对象可以序列化,以便在网络中可以传输。
运行结果:
8 3
5 6
5 3
4 9
4 7
3 2
1 6案例4-平均成绩
给出三门成绩的三个文件,要求算出每位学生的平均成绩。
//读入数据val rdd: RDD[String] = sc.textFile("data/rdd/test3")rdd.map(line=>(line.split(" ")(0),line.split(" ")(1).toInt)).map(t=>(t._1,(t._2,1))).reduceByKey((t1,t2)=>(t1._1+t2._1,t1._2+t2._2)).mapValues(t=>t._1/t._2.toFloat).foreach(println)运行结果:
(小新,88.333336)
(小丽,88.666664)
(小明,89.666664)
(小红,83.666664)综合案例
输入数据格式:(姓名,课程名,成绩)
Aaron,OperatingSystem,100
Aaron,Python,50
Aaron,ComputerNetwork,30
Aaron,Software,94
Abbott,DataBase,18
Abbott,Python,82
Abbott,ComputerNetwork,76
Abel,Algorithm,30
Abel,DataStructure,38
Abel,OperatingSystem,38
...import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}object RDDPractice {def main(args: Array[String]): Unit = {val conf:SparkConf = new SparkConf()conf.setAppName("test-last").setMaster("local")val sc: SparkContext = new SparkContext(conf)val rdd: RDD[String] = sc.textFile("data/chapter5-data1.txt")//(1)该系共有多少名学生val nums: Long = rdd.map(line => line.split(",")(0)).distinct().count()println("该系一共 "+nums+" 名学生")//(2)该系共开设多少门课程val course_nums: Long = rdd.map(line => line.split(",")(1)).distinct().count()println("该系一共 "+course_nums+" 门课程")//(3)学生 Tom 的总成绩和平均成绩分别是多少val score: Double = rdd.filter(line => line.contains("Tom")).map(line => line.split(",")(2).toInt).sum()val avg: Double = score/rdd.filter(line => line.contains("Tom")).map(line=>line.split(",")(1)).count()println("Tom 的总成绩为 "+score+",平均成绩为 "+avg)//(4)求每名同学的选修的课程门数rdd.map(line=>(line.split(",")(0),line.split(",")(1))) //(学生名,课程名).mapValues(v => (v,1)) //(学生名,(课程名,1)).reduceByKey((k,v)=>("",k._2+v._2)) //(学生名,("",1+1+1)) 合并课程总数.mapValues(x => x._2) //(学生名,课程总数).foreach(println)//(5)该系DataBase课程共有多少人选修val l = rdd.filter(line => line.split(",")(1) == "DataBase").count()println("选修DataBase课程的人数为 "+l)//(6)各门课程的平均分是多少//(学生,课程名,成绩)=>课程总成绩/该课程的学生数val res: RDD[(String, Float)] = rdd.map(line => (line.split(",")(1), line.split(",")(2).toInt)) //(课程名,成绩).combineByKey(score => (score, 1), //(成绩,1)(acc: (Int, Int), score) => (acc._1 + score, acc._2 + 1), //(成绩1+成绩2,1+1)(acc1: (Int, Int), acc2: (Int, Int)) => (acc1._1 + acc2._1, acc1._2 + acc2._2) //(成绩+成绩,1+1)).map({case (key, value) => (key, value._1 / value._2.toFloat) //(课程名,总课程成绩/课程人数)})res.saveAsTextFile("data/rdd/practice")sc.stop()}
}
运行结果:
该系一共 265 名学生
该系一共 8 门课程
Tom 的总成绩为 154.0,平均成绩为 30.8
(Ford,3)
(Lionel,4)
(Verne,3)
(Lennon,4)
(Joshua,4)
(Marvin,3)
(Marsh,4)
(Bartholomew,5)
(Conrad,2)
(Armand,3)
(Jonathan,4)
(Broderick,3)
(Brady,5)
(Derrick,6)
(Rod,4)
(Willie,4)
(Walter,4)
(Boyce,2)
(Duncann,5)
(Elvis,2)
(Elmer,4)
(Bennett,6)
(Elton,5)
(Jo,5)
(Jim,4)
(Adonis,5)
(Abel,4)
(Peter,4)
(Alvis,6)
(Joseph,3)
(Raymondt,6)
(Kerwin,3)
(Wright,4)
(Adam,3)
(Borg,4)
(Sandy,1)
(Ben,4)
(Miles,6)
(Clyde,7)
(Francis,4)
(Dempsey,4)
(Ellis,4)
(Edward,4)
(Mick,4)
(Cleveland,4)
(Luthers,5)
(Virgil,5)
(Ivan,4)
(Alvin,5)
(Dick,3)
(Bevis,4)
(Leo,5)
(Saxon,7)
(Armstrong,2)
(Hogan,4)
(Sid,3)
(Blair,4)
(Colbert,4)
(Lucien,5)
(Kerr,4)
(Montague,3)
(Giles,7)
(Kevin,4)
(Uriah,1)
(Jeffrey,4)
(Simon,2)
(Elijah,4)
(Greg,4)
(Colin,5)
(Arlen,4)
(Maxwell,4)
(Payne,6)
(Kennedy,4)
(Spencer,5)
(Kent,4)
(Griffith,4)
(Jeremy,6)
(Alan,5)
(Andrew,4)
(Jerry,3)
(Donahue,5)
(Gilbert,3)
(Bishop,2)
(Bernard,2)
(Egbert,4)
(George,4)
(Noah,4)
(Bruce,3)
(Mike,3)
(Frank,3)
(Boris,6)
(Tony,3)
(Christ,2)
(Ken,3)
(Milo,2)
(Victor,2)
(Clare,4)
(Nigel,3)
(Christopher,4)
(Robin,4)
(Chad,6)
(Alfred,2)
(Woodrow,3)
(Rory,4)
(Dennis,4)
(Ward,4)
(Chester,6)
(Emmanuel,3)
(Stan,3)
(Jerome,3)
(Corey,4)
(Harvey,7)
(Herbert,3)
(Maurice,2)
(Merle,3)
(Les,6)
(Bing,6)
(Charles,3)
(Clement,5)
(Leopold,7)
(Brian,6)
(Horace,5)
(Sebastian,6)
(Bernie,3)
(Basil,4)
(Michael,5)
(Ernest,5)
(Tom,5)
(Vic,3)
(Eli,5)
(Duke,4)
(Alva,5)
(Lester,4)
(Hayden,3)
(Bertram,3)
(Bart,5)
(Adair,3)
(Sidney,5)
(Bowen,5)
(Roderick,4)
(Colby,4)
(Jay,6)
(Meredith,4)
(Harold,4)
(Max,3)
(Scott,3)
(Barton,1)
(Elliot,3)
(Matthew,2)
(Alexander,4)
(Todd,3)
(Wordsworth,4)
(Geoffrey,4)
(Devin,4)
(Donald,4)
(Roy,6)
(Harry,4)
(Abbott,3)
(Baron,6)
(Mark,7)
(Lewis,4)
(Rock,6)
(Eugene,1)
(Aries,2)
(Samuel,4)
(Glenn,6)
(Will,3)
(Gerald,4)
(Henry,2)
(Jesse,7)
(Bradley,2)
(Merlin,5)
(Monroe,3)
(Hobart,4)
(Ron,6)
(Archer,5)
(Nick,5)
(Louis,6)
(Len,5)
(Randolph,3)
(Benson,4)
(John,6)
(Abraham,3)
(Benedict,6)
(Marico,6)
(Berg,4)
(Aldrich,3)
(Lou,2)
(Brook,4)
(Ronald,3)
(Pete,3)
(Nicholas,5)
(Bill,2)
(Harlan,6)
(Tracy,3)
(Gordon,4)
(Alston,4)
(Andy,3)
(Bruno,5)
(Beck,4)
(Phil,3)
(Barry,5)
(Nelson,5)
(Antony,5)
(Rodney,3)
(Truman,3)
(Marlon,4)
(Don,2)
(Philip,2)
(Sean,6)
(Webb,7)
(Solomon,5)
(Aaron,4)
(Blake,4)
(Amos,5)
(Chapman,4)
(Jonas,4)
(Valentine,8)
(Angelo,2)
(Boyd,3)
(Benjamin,4)
(Winston,4)
(Allen,4)
(Evan,3)
(Albert,3)
(Newman,2)
(Jason,4)
(Hilary,4)
(William,6)
(Dean,7)
(Claude,2)
(Booth,6)
(Channing,4)
(Jeff,4)
(Webster,2)
(Marshall,4)
(Cliff,5)
(Dominic,4)
(Upton,5)
(Herman,3)
(Levi,2)
(Clark,6)
(Hiram,6)
(Drew,5)
(Bert,3)
(Alger,5)
(Brandon,5)
(Antonio,3)
(Elroy,5)
(Leonard,2)
(Adolph,4)
(Blithe,3)
(Kenneth,3)
(Perry,5)
(Matt,4)
(Eric,4)
(Archibald,5)
(Martin,3)
(Kim,4)
(Clarence,7)
(Vincent,5)
(Winfred,3)
(Christian,2)
(Bob,3)
(Enoch,3)
选修DataBase课程的人数为 126各门课程的平均分是多少,输出文件:
(CLanguage,50.609375)
(Software,50.909092)
(Python,57.82353)
(Algorithm,48.833332)
(DataStructure,47.572517)
(DataBase,50.539684)
(ComputerNetwork,51.90141)
(OperatingSystem,54.9403)解析
(1)该系共有多少名学生
首先使用map 转换操作从数据中提取出来所有的学生姓名,然后使用转换操作 distinct 函数去重,最后使用行动操作 count 进行统计。
//(1)该系共有多少名学生val nums: Long = rdd.map(line => line.split(",")(0)).distinct().count()
(2)该系共开设多少门课程
同(1),不同的是我们提取的是所有的课程名。
//(2)该系共开设多少门课程val course_nums: Long = rdd.map(line => line.split(",")(1)).distinct().count()
(3)学生 Tom 的总成绩和平均成绩分别是多少
对于总成绩,使用过滤函数 filter 提取出含有"Tom"的数据行,然后将一行字符串转为多个字段并取出成绩字段的值并求和。
对于平均成绩,我们计算出科目的数量然后用总成绩除以它即可。
//(3)学生 Tom 的总成绩和平均成绩分别是多少val score: Double = rdd.filter(line => line.contains("Tom")).map(line => line.split(",")(2).toInt).sum()val avg: Double = score/rdd.filter(line => line.contains("Tom")).map(line=>line.split(",")(1)).count()println("Tom 的总成绩为 "+score+",平均成绩为 "+avg)(4)求每名同学的选修的课程门数
先取出学生名和课程名,把学生名最为key,课程名通过mapValues函数转为(课程名,1)的形式,对于相同的学生,通过reduceByKey函数累加它的课程数,通过mapValues函数将键值对形式的value转为单个的值-课程总数。
//(4)求每名同学的选修的课程门数rdd.map(line=>(line.split(",")(0),line.split(",")(1))) //(学生名,课程名).mapValues(v => (v,1)) //(学生名,(课程名,1)).reduceByKey((k,v)=>("",k._2+v._2)) //(学生名,("",1+1+1)) 合并课程总数.mapValues(x => x._2) //(学生名,课程总数).foreach(println)(5)该系DataBase课程共有多少人选修
直接通过 count 函数对字段1为"DataBase"的数据行进行统计。
//(5)该系DataBase课程共有多少人选修val l = rdd.filter(line => line.split(",")(1) == "DataBase").count()(6)各门课程的平均分是多少
通过combineByKey函数通过对每个key(课程)对应的value(成绩)转为(成绩,1)的形式,
然后对相同的key(课程)的值(成绩,1)进行合并,将成绩和次数进行累加,
对于不同分区的数据也是一样,对成绩和次数都进行累加,
最后按照要求的格式输出(课程名,总成绩/总次数=课程平均成绩)
//(6)各门课程的平均分是多少//(学生,课程名,成绩)=>课程总成绩/该课程的学生数val res: RDD[(String, Float)] = rdd.map(line => (line.split(",")(1), line.split(",")(2).toInt)) //(课程名,成绩).combineByKey(score => (score, 1), //(成绩,1)(acc: (Int, Int), score) => (acc._1 + score, acc._2 + 1), //(成绩1+成绩2,1+1)(acc1: (Int, Int), acc2: (Int, Int)) => (acc1._1 + acc2._1, acc1._2 + acc2._2) //(成绩+成绩,1+1)).map({case (key, value) => (key, value._1 / value._2.toFloat) //(课程名,总课程成绩/课程人数)})除此之外,也可以用reduceByKey来进行解决,二者的原理是一样的:
rdd.map(line => (line.split(",")(1), line.split(",")(2).toInt)).map(t => (t._1, (t._2, 1))).reduceByKey((t1, t2) => (t1._1 + t2._1, t1._2 + t2._2)).map(t => (t._1, t._2._1 / t._2._2.toFloat)) //这行代码可以用mapValues()替换,因为我们本来就是只对value进行操作,key不需要改变.foreach(println)相关文章:
综合案例】)
Spark【RDD编程(四)综合案例】
案例1-TOP N个数据的值 输入数据: 1,1768,50,155 2,1218,600,211 3,2239,788,242 4,3101,28,599 5,4899,290,129 6,3110,54,1201 7,4436,259,877 8,2369,7890,27 处理代码: def main(args: Array[String]): Unit {//创建SparkContext对象val conf…...

Golang报错mixture of field:value and value initializers
Golang报错mixture of field:value and value initializers 这个错误跟编程习惯(模式)有关,都知道golang 语言的编程与java /python 以及其他的编程语言相似 ,一通百通,易学万卷书。 编程中同一个结构中要保持唯一模…...

【网络教程】记一次使用Docker手动搭建BT宝塔面板的全过程(包含问题解决如:宝塔面板无法开启防火墙,ssh,nginx等)
文章目录 准备安装安装宝塔面板开启ssh和修改ssh的密码导出镜像问题解决宝塔面板无法开启防火墙无法启动ssh设置密码nginx安装失败设置开机启动相关服务准备 演示的系统环境:Ubuntu 22.04.3 LTS更新安装/升级docker到最新版本升级docker相关命令如下# 更新软件包列表并自动升级…...
【大虾送书第九期】速学Linux:系统应用从入门到精通
目录 🍭写在前面 🍭为什么学习Linux系统 🍭Linux系统的应用领域 🍬1.Linux在服务器的应用 🍬2.嵌入式Linux的应用 🍬3.桌面Linux的应用 🍭Linux的版本选择 &a…...

docker相关命令
####### 帮助启动类命令 ########## 启动docker systemctl start docker 停止docker systemctl stop docker 重启docker systemctl restart docker 查看docker状态 systemctl status docker 开机启动 systemctl enable docker 查看docker概要信息 docker info 查看…...

【Redis】4、rsync远程同步
与inodify结合使用,实现实时同步 rsync简介 rsync(Remote Sync,远程同步)是一个开源的快速备份工具,可以在不同主机之间镜像同步整个目录树,;支持增量备份,并保持链接和权限&#…...

无服务架构--Serverless
无服务架构 无服务架构(Serverless Architecture)即无服务器架构,也被称为函数即服务(Function as a Service,FaaS),是一种云计算模型,用于构建和部署应用程序,无需关心…...

2023-09-07 LeetCode每日一题(修车的最少时间)
2023-09-07每日一题 一、题目编号 2594. 修车的最少时间二、题目链接 点击跳转到题目位置 三、题目描述 给你一个整数数组 ranks ,表示一些机械工的 能力值 。ranksi 是第 i 位机械工的能力值。能力值为 r 的机械工可以在 r * n2 分钟内修好 n 辆车。 同时给你…...
数据挖掘实验-主成分分析与类特征化
数据集&代码https://www.aliyundrive.com/s/ibeJivEcqhm 一.主成分分析 1.实验目的 了解主成分分析的目的,内容以及流程。 掌握主成分分析,能够进行编程实现。 2.实验原理 主成分分析的目的 主成分分析就是把原有的多个指标转化成少数几个代表…...
,322. 零钱兑换,279.完全平方数)
70. 爬楼梯 (进阶),322. 零钱兑换,279.完全平方数
代码随想录训练营第45天|70. 爬楼梯 (进阶,322. 零钱兑换,279.完全平方数 70.爬楼梯文章思路代码 322.零钱兑换文章思路代码 279.完全平方数文章思路代码 总结 70.爬楼梯 文章 代码随想录|0070.爬楼梯完全背包版本 思路 将楼梯长度视为背…...
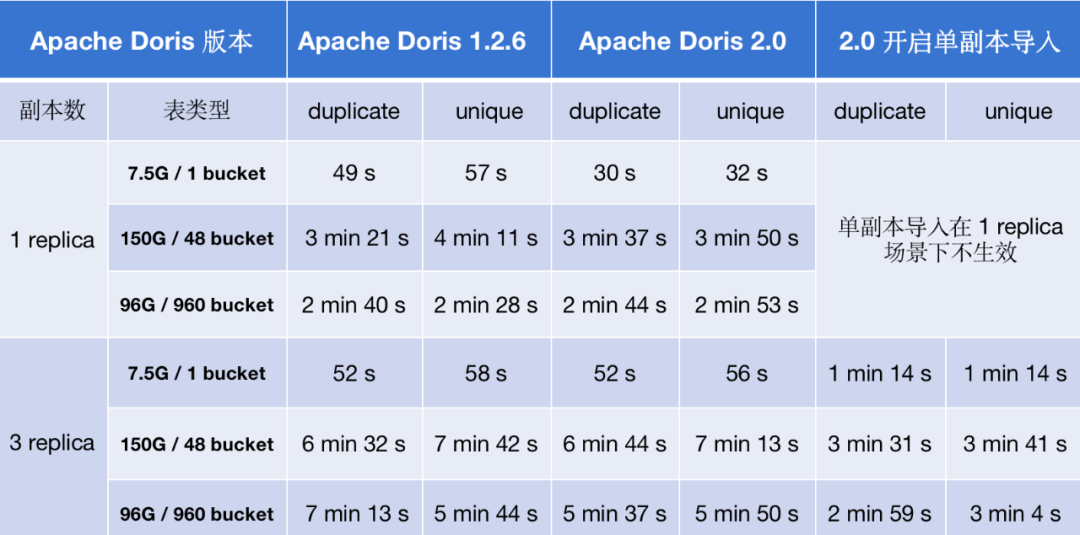
Apache Doris 2.0 如何实现导入性能提升 2-8 倍
数据导入吞吐是 OLAP 系统性能的重要衡量标准之一,高效的数据导入能力能够加速数据实时处理和分析的效率。随着 Apache Doris 用户规模的不断扩大, 越来越多用户对数据导入提出更高的要求,这也为 Apache Doris 的数据导入能力带来了更大的挑战…...

RabbitMQ: topic 结构
生产者 package com.qf.mq2302.topic;import com.qf.mq2302.utils.MQUtils; import com.rabbitmq.client.Channel; import com.rabbitmq.client.Connection;public class Pubisher {public static final String EXCHANGE_NAME"mypubilisher";public static void ma…...
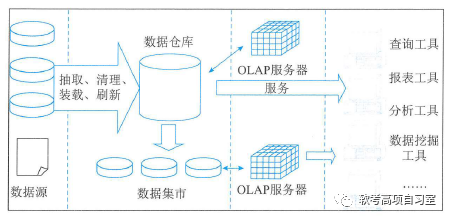
信息系统项目管理教程(第4版):第二章 信息技术及其发展
请点击↑关注、收藏,本博客免费为你获取精彩知识分享!有惊喜哟!! 第二章 信息技术及其发展 2.1信息技术及其发展 信息技术是以微电子学为基础的计算机技术和电信技术的结合而形成的,对声音的、图像的、文字的、数字…...

有哪些适合初学者的编程语言?
C语言 那为什么我还要教你C语言呢?因为我想要让你成为一个更好、更强大的程序员。如果你要变得更好,C语言是一个极佳的选择,其原因有二。首先,C语言缺乏任何现代的安全功能,这意味着你必须更为警惕,时刻了…...

uni-app动态tabBar,根据不同用户展示不同的tabBar
1.uni框架的api实现 因为我们用的是uni-app框架开发,所以在创建项目的时候直接创建uni-ui的项目即可,这个项目模板中自带了uni的一些好用的组件和api。 起初我想着这个效果不难实现,因为官方也有api可以直接使用,所以我最开始尝试…...

手写Spring:第6章-资源加载器解析文件注册对象
文章目录 一、目标:资源加载器解析文件注册对象二、设计:资源加载器解析文件注册对象三、实现:资源加载器解析文件注册对象3.1 工程结构3.2 资源加载器解析文件注册对象类图3.3 类工具类3.4 资源加载接口定义和实现3.4.1 定义资源加载接口3.4…...

Redis 7 第八讲 集群模式(cluster)架构篇
集群架构 Redis 集群架构图 集群定义 Redis 集群是一个提供在多个Redis节点间共享数据的程序集;Redis集群可以支持多个master 应用场景 Redis集群支持多个master,每个master又可以挂载多个slave读写分离支持数据的高可用支持海量数据的读写存储操作集群自带Sentinel的故障…...

【PowerQuery】导入与加载XML
在标准数据格式类型里面,有一类比较特殊的数据类型,就是层次结构数据。层次结构数据和标准的结构型数据方式完全不同,在实际应用过程中使用最为频繁的几种数据类型如下。 XML数据格式Json 数据格式Yaml 数据格式我们将在本节和大家一起分享下XML格式数据集成,下一节和大家分…...

vue 预览视频
1.预览本地文件 1.1 直接给video或者embed的src赋值本地路径 <video :src"videoUrl"></video> // 或者 使用embed标签<embed :src"videoUrl" /> 1.2 读取文件流形式 <input type"file" ref"file" /> <vi…...

4个维度讲透ChatGPT技术原理,揭开ChatGPT神秘技术黑盒!(文末送书)
🤵♂️ 个人主页:艾派森的个人主页 ✍🏻作者简介:Python学习者 🐋 希望大家多多支持,我们一起进步!😄 如果文章对你有帮助的话, 欢迎评论 💬点赞Ǵ…...

利用ngx_stream_return_module构建简易 TCP/UDP 响应网关
一、模块概述 ngx_stream_return_module 提供了一个极简的指令: return <value>;在收到客户端连接后,立即将 <value> 写回并关闭连接。<value> 支持内嵌文本和内置变量(如 $time_iso8601、$remote_addr 等)&a…...

Debian系统简介
目录 Debian系统介绍 Debian版本介绍 Debian软件源介绍 软件包管理工具dpkg dpkg核心指令详解 安装软件包 卸载软件包 查询软件包状态 验证软件包完整性 手动处理依赖关系 dpkg vs apt Debian系统介绍 Debian 和 Ubuntu 都是基于 Debian内核 的 Linux 发行版ÿ…...

关于nvm与node.js
1 安装nvm 安装过程中手动修改 nvm的安装路径, 以及修改 通过nvm安装node后正在使用的node的存放目录【这句话可能难以理解,但接着往下看你就了然了】 2 修改nvm中settings.txt文件配置 nvm安装成功后,通常在该文件中会出现以下配置&…...

React19源码系列之 事件插件系统
事件类别 事件类型 定义 文档 Event Event 接口表示在 EventTarget 上出现的事件。 Event - Web API | MDN UIEvent UIEvent 接口表示简单的用户界面事件。 UIEvent - Web API | MDN KeyboardEvent KeyboardEvent 对象描述了用户与键盘的交互。 KeyboardEvent - Web…...

Neo4j 集群管理:原理、技术与最佳实践深度解析
Neo4j 的集群技术是其企业级高可用性、可扩展性和容错能力的核心。通过深入分析官方文档,本文将系统阐述其集群管理的核心原理、关键技术、实用技巧和行业最佳实践。 Neo4j 的 Causal Clustering 架构提供了一个强大而灵活的基石,用于构建高可用、可扩展且一致的图数据库服务…...
)
【HarmonyOS 5 开发速记】如何获取用户信息(头像/昵称/手机号)
1.获取 authorizationCode: 2.利用 authorizationCode 获取 accessToken:文档中心 3.获取手机:文档中心 4.获取昵称头像:文档中心 首先创建 request 若要获取手机号,scope必填 phone,permissions 必填 …...

CMake控制VS2022项目文件分组
我们可以通过 CMake 控制源文件的组织结构,使它们在 VS 解决方案资源管理器中以“组”(Filter)的形式进行分类展示。 🎯 目标 通过 CMake 脚本将 .cpp、.h 等源文件分组显示在 Visual Studio 2022 的解决方案资源管理器中。 ✅ 支持的方法汇总(共4种) 方法描述是否推荐…...

OPenCV CUDA模块图像处理-----对图像执行 均值漂移滤波(Mean Shift Filtering)函数meanShiftFiltering()
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 在 GPU 上对图像执行 均值漂移滤波(Mean Shift Filtering),用于图像分割或平滑处理。 该函数将输入图像中的…...
中的KV缓存压缩与动态稀疏注意力机制设计)
大语言模型(LLM)中的KV缓存压缩与动态稀疏注意力机制设计
随着大语言模型(LLM)参数规模的增长,推理阶段的内存占用和计算复杂度成为核心挑战。传统注意力机制的计算复杂度随序列长度呈二次方增长,而KV缓存的内存消耗可能高达数十GB(例如Llama2-7B处理100K token时需50GB内存&a…...

技术栈RabbitMq的介绍和使用
目录 1. 什么是消息队列?2. 消息队列的优点3. RabbitMQ 消息队列概述4. RabbitMQ 安装5. Exchange 四种类型5.1 direct 精准匹配5.2 fanout 广播5.3 topic 正则匹配 6. RabbitMQ 队列模式6.1 简单队列模式6.2 工作队列模式6.3 发布/订阅模式6.4 路由模式6.5 主题模式…...