深度学习推荐系统(八)AFM模型及其在Criteo数据集上的应用
深度学习推荐系统(八)AFM模型及其在Criteo数据集上的应用
1 AFM模型原理及其实现
-
沿着特征工程自动化的思路,深度学习模型从 PNN ⼀路⾛来,经过了Wide&Deep、Deep&Cross、FNN、DeepFM、NFM等模型,进⾏了大量的、基于不同特征互操作思路的尝试。
-
但特征工程的思路走到这里几乎已经穷尽了可能的尝试,模型进⼀步提升的空间非常小,这也是这类模型的局限性所在。
-
从这之后,越来越多的深度学习推荐模型开始探索更多“结构”上的尝试,诸如注意力机制、序列模型、强化学习等在其他领域大放异彩的模型结构也逐渐进⼊推荐系统领域,并且在推荐模型的效果提升上成果显著。
-
从 2017年开始,推荐领域也开始尝试将注意力机制引入模型之中,由浙江大学提出的AFM和由阿里巴巴提出的DIN是典型模型。

1.1 AFM模型原理
-
AFM模型和NFM模型结构上非常相似, 算是NFM模型的一个延伸。在NFM中, 不同特征域的特征embedding向量经过特征交叉池化层的交叉,将各个交叉特征向量进行
加和, 然后后面跟了一个DNN网络。 加和池化,它相当于一视同仁地对待所有交叉特征, 没有考虑不同特征对结果的影响程度。 -
这可能会影响最后的预测效果, 因为不是所有的交互特征都能够对最后的预测起作用。 没有用的交互特征可能会产生噪声。例如:如果应用场景是预测一位男性用户是否购买一款键盘的可能性, 那么“性别=男且购买历史包含鼠标”这个交叉特征, 很可能比“性别=男且用户年龄=30”这一个交叉特征重要。
-
作者在提出NFM之后,把注意力机制引入到了里面去, 来学习不同交叉特征对于结果的不同影响程度。
-
AFM 是从改进模型结构的⾓度出发进行的⼀次有益尝试。它与具体的应用场景无关。
1.1.1 AFM模型结构
-
AFM模型是通过在
特征交叉层和最终的输出层之间加入注意力网络来引入了注意力机制 -
注意力网络的作用是为每⼀个交叉特征提供权重,也就是注意力得分
该模型的网络架构如下:

1.1.2 基于注意力机制的池化层

其中要学习的模型参数就是特征交叉层到注意力网络全连接层的权重矩阵W,偏置向量b,以及全连接层到softmax输出层的权重向量h。
注意力网络将与整个模型⼀起参与梯度反向传播的学习过程,得到最终的权重参数。
1.2 AFM模型代码复现
import torch.nn as nn
import torch.nn.functional as F
import torch
import itertoolsclass Dnn(nn.Module):"""Dnn part"""def __init__(self, hidden_units, dropout=0.):"""hidden_units: 列表, 每个元素表示每一层的神经单元个数, 比如[256, 128, 64], 两层网络, 第一层神经单元128, 第二层64, 第一个维度是输入维度dropout: 失活率"""super(Dnn, self).__init__()self.dnn_network = nn.ModuleList([nn.Linear(layer[0], layer[1]) for layer in list(zip(hidden_units[:-1], hidden_units[1:]))])self.dropout = nn.Dropout(p=dropout)def forward(self, x):for linear in self.dnn_network:x = linear(x)x = F.relu(x)x = self.dropout(x)return xclass Attention_layer(nn.Module):def __init__(self, att_units):""":param att_units: [embed_dim, att_vector]"""super(Attention_layer, self).__init__()self.att_w = nn.Linear(att_units[0], att_units[1])self.att_dense = nn.Linear(att_units[1], 1)# bi_interaction (batch_size, (field_num*(field_num-1))/2, embed_dim)def forward(self, bi_interaction):# a的shape为(batch_size, (field_num*(field_num-1))/2, att_vector)a = self.att_w(bi_interaction)a = F.relu(a)# 得到注意力分数,shape为(batch_size, (field_num*(field_num-1))/2, 1)att_scores = self.att_dense(a)# 为dim=1进行softmax转换 shape为(batch_size, (field_num*(field_num-1))/2, 1)att_weight = F.softmax(att_scores, dim=1)# 得到最终权重(广播机制) * bi_interaction,然后把dim=1压缩(行的相同位置相加、去掉dim=1)# 即(field_num*(field_num-1))/2,embed_dim)变为embed_dim# att_out的shape为(batch_size, embed_dim)att_out = torch.sum(att_weight * bi_interaction, dim=1)return att_outclass AFM(nn.Module):def __init__(self, feature_info, mode, hidden_units, embed_dim=8, att_vector=8, dropout=0.5, useDNN=False):"""AFM::param feature_info: 特征信息(数值特征, 类别特征, 类别特征embedding映射):param mode: A string, 三种模式, 'max': max pooling, 'avg': average pooling 'att', Attention:param att_vector: 注意力网络的隐藏层单元个数:param hidden_units: DNN网络的隐藏单元个数, 一个列表的形式, 列表的长度代表层数, 每个元素代表每一层神经元个数:param dropout: Dropout比率:param useDNN: 默认不使用DNN网络"""super(AFM, self).__init__()self.dense_features, self.sparse_features, self.sparse_features_map = feature_infoself.mode = modeself.useDNN = useDNN# embedding层, 这里需要一个列表的形式, 因为每个类别特征都需要embeddingself.embed_layers = nn.ModuleDict({'embed_' + str(key): nn.Embedding(num_embeddings=val, embedding_dim=embed_dim)for key, val in self.sparse_features_map.items()})# 如果是注意机制的话,这里需要加一个注意力网络if self.mode == 'att':self.attention = Attention_layer([embed_dim, att_vector])# 如果使用DNN的话, 这里需要初始化DNN网络if self.useDNN:# 注意 这里的总维度 = 数值型特征的维度 + embedding的维度self.fea_num = len(self.dense_features) + embed_dimhidden_units.insert(0, self.fea_num)self.bn = nn.BatchNorm1d(self.fea_num)self.dnn_network = Dnn(hidden_units, dropout)self.nn_final_linear = nn.Linear(hidden_units[-1], 1)else:# 注意 这里的总维度 = 数值型特征的维度 + embedding的维度self.fea_num = len(self.dense_features) + embed_dimself.nn_final_linear = nn.Linear(self.fea_num, 1)def forward(self, x):# 1、先把输入向量x分成两部分处理、因为数值型和类别型的处理方式不一样dense_inputs, sparse_inputs = x[:, :len(self.dense_features)], x[:, len(self.dense_features):]# 转换为long形sparse_inputs = sparse_inputs.long()# 2、不同的类别特征分别embeddingsparse_embeds = [self.embed_layers['embed_' + key](sparse_inputs[:, i]) for key, i inzip(self.sparse_features_map.keys(), range(sparse_inputs.shape[1]))]# 3、embedding进行堆叠 fild_num即为离散特征数sparse_embeds = torch.stack(sparse_embeds) # (离散特征数, batch_size, embed_dim)sparse_embeds = sparse_embeds.permute((1, 0, 2)) # (batch_size, 离散特征数, embed_dim)# 这里得到embedding向量之后 sparse_embeds(batch_size, 离散特征数, embed_dim)# 下面进行两两交叉, 注意这时候不能加和了,也就是NFM的那个计算公式不能用, 这里两两交叉的结果要进入Attention# 两两交叉embedding之后的结果是一个(batch_size, (field_num*field_num-1)/2, embed_dim)# 这里实现的时候采用一个技巧就是组合# 比如fild_num有3个的话,那么组合embedding就是[0,1] [0,2],[1,2]位置的embedding乘积操作first = []second = []for f, s in itertools.combinations(range(sparse_embeds.shape[1]), 2):first.append(f)second.append(s)# 取出first位置的embedding 假设field是3的话,就是[0, 0, 1]位置的embedding# p的shape为(batch_size, (field_num*(field_num-1))/2, embed_dim)p = sparse_embeds[:, first, :]# 取出second位置的embedding 假设field是3的话,就是[1, 2, 2]位置的embedding# q的shape为(batch_size, (field_num*(field_num-1))/2, embed_dim)q = sparse_embeds[:, second, :]# 最终得到bi_interaction的shape为(batch_size, (field_num*(field_num-1))/2, embed_dim)# p * q ,对应位置相乘# 假设field_num为3,即为[batch_size,(0,0,1),embed_dim] 与 [batch_size,(1,2,2),embed_dim] 对应元素相乘# 即[0,1] [0,2],[1,2]位置的embedding乘积操作bi_interaction = p * qif self.mode == 'max':att_out = torch.sum(bi_interaction, dim=1) # (batch_size, embed_dim)elif self.mode == 'avg':att_out = torch.mean(bi_interaction, dim=1) # (batch_size, embed_dim)else:# 注意力网络att_out = self.attention(bi_interaction) # (batch_size, embed_dim)# 把离散特征和连续特征进行拼接x = torch.cat([att_out, dense_inputs], dim=-1)if not self.useDNN:outputs = torch.sigmoid(self.nn_final_linear(x))else:# BatchNormalizationx = self.bn(x)# deepdnn_outputs = self.nn_final_linear(self.dnn_network(x))outputs = torch.sigmoid(dnn_outputs)return outputsif __name__ == '__main__':x = torch.rand(size=(2, 5), dtype=torch.float32)feature_info = [['I1', 'I2'], # 连续性特征['C1', 'C2', 'C3'], # 离散型特征,即field_num=3{'C1': 20,'C2': 20,'C3': 20}]# 建立模型hidden_units = [128, 64, 32]mode = "att"net = AFM(feature_info, mode, hidden_units)print(net)print(net(x))
AFM((embed_layers): ModuleDict((embed_C1): Embedding(20, 8)(embed_C2): Embedding(20, 8)(embed_C3): Embedding(20, 8))(attention): Attention_layer((att_w): Linear(in_features=8, out_features=8, bias=True)(att_dense): Linear(in_features=8, out_features=1, bias=True))(nn_final_linear): Linear(in_features=10, out_features=1, bias=True)
)
tensor([[0.5879],[0.6086]], grad_fn=<SigmoidBackward0>)
2 AFM模型在Criteo数据集上的应用
数据的预处理可以参考
深度学习推荐系统(二)Deep Crossing及其在Criteo数据集上的应用
2.1 准备训练数据
import pandas as pdimport torch
from torch.utils.data import TensorDataset, Dataset, DataLoaderimport torch.nn as nn
from sklearn.metrics import auc, roc_auc_score, roc_curveimport warnings
warnings.filterwarnings('ignore')
# 封装为函数
def prepared_data(file_path):# 读入训练集,验证集和测试集train_set = pd.read_csv(file_path + 'train_set.csv')val_set = pd.read_csv(file_path + 'val_set.csv')test_set = pd.read_csv(file_path + 'test.csv')# 这里需要把特征分成数值型和离散型# 因为后面的模型里面离散型的特征需要embedding, 而数值型的特征直接进入了stacking层, 处理方式会不一样data_df = pd.concat((train_set, val_set, test_set))# 数值型特征直接放入stacking层dense_features = ['I' + str(i) for i in range(1, 14)]# 离散型特征需要需要进行embedding处理sparse_features = ['C' + str(i) for i in range(1, 27)]# 定义一个稀疏特征的embedding映射, 字典{key: value},# key表示每个稀疏特征, value表示数据集data_df对应列的不同取值个数, 作为embedding输入维度sparse_feas_map = {}for key in sparse_features:sparse_feas_map[key] = data_df[key].nunique()feature_info = [dense_features, sparse_features, sparse_feas_map] # 这里把特征信息进行封装, 建立模型的时候作为参数传入# 把数据构建成数据管道dl_train_dataset = TensorDataset(# 特征信息torch.tensor(train_set.drop(columns='Label').values).float(),# 标签信息torch.tensor(train_set['Label'].values).float())dl_val_dataset = TensorDataset(# 特征信息torch.tensor(val_set.drop(columns='Label').values).float(),# 标签信息torch.tensor(val_set['Label'].values).float())dl_train = DataLoader(dl_train_dataset, shuffle=True, batch_size=16)dl_vaild = DataLoader(dl_val_dataset, shuffle=True, batch_size=16)return feature_info,dl_train,dl_vaild,test_set
file_path = './preprocessed_data/'feature_info,dl_train,dl_vaild,test_set = prepared_data(file_path)
2.2 建立AFM模型
from _01_afm import AFMhidden_units = [128, 64, 32]
mode = "att"
dnn_dropout = 0.0
net = AFM(feature_info, mode, hidden_units, dropout=dnn_dropout, useDNN=True)
# 测试一下模型
for feature, label in iter(dl_train):out = net(feature)print(feature.shape)print(out.shape)print(out)break
3.3 模型的训练
from AnimatorClass import Animator
from TimerClass import Timer# 模型的相关设置
def metric_func(y_pred, y_true):pred = y_pred.datay = y_true.datareturn roc_auc_score(y, pred)def try_gpu(i=0):if torch.cuda.device_count() >= i + 1:return torch.device(f'cuda:{i}')return torch.device('cpu')def train_ch(net, dl_train, dl_vaild, num_epochs, lr, device):"""⽤GPU训练模型"""print('training on', device)net.to(device)# 二值交叉熵损失loss_func = nn.BCELoss()optimizer = torch.optim.Adam(params=net.parameters(), lr=lr)animator = Animator(xlabel='epoch', xlim=[1, num_epochs],legend=['train loss', 'train auc', 'val loss', 'val auc'],figsize=(8.0, 6.0))timer, num_batches = Timer(), len(dl_train)log_step_freq = 10for epoch in range(1, num_epochs + 1):# 训练阶段net.train()loss_sum = 0.0metric_sum = 0.0for step, (features, labels) in enumerate(dl_train, 1):timer.start()# 梯度清零optimizer.zero_grad()# 正向传播predictions = net(features)loss = loss_func(predictions, labels.unsqueeze(1) )try: # 这里就是如果当前批次里面的y只有一个类别, 跳过去metric = metric_func(predictions, labels)except ValueError:pass# 反向传播求梯度loss.backward()optimizer.step()timer.stop()# 打印batch级别日志loss_sum += loss.item()metric_sum += metric.item()if step % log_step_freq == 0:animator.add(epoch + step / num_batches,(loss_sum/step, metric_sum/step, None, None))# 验证阶段net.eval()val_loss_sum = 0.0val_metric_sum = 0.0for val_step, (features, labels) in enumerate(dl_vaild, 1):with torch.no_grad():predictions = net(features)val_loss = loss_func(predictions, labels.unsqueeze(1))try:val_metric = metric_func(predictions, labels)except ValueError:passval_loss_sum += val_loss.item()val_metric_sum += val_metric.item()if val_step % log_step_freq == 0:animator.add(epoch + val_step / num_batches, (None,None,val_loss_sum / val_step , val_metric_sum / val_step))print(f'final: loss {loss_sum/len(dl_train):.3f}, auc {metric_sum/len(dl_train):.3f},'f' val loss {val_loss_sum/len(dl_vaild):.3f}, val auc {val_metric_sum/len(dl_vaild):.3f}')print(f'{num_batches * num_epochs / timer.sum():.1f} examples/sec on {str(device)}')
lr, num_epochs = 0.001, 5
train_ch(net, dl_train, dl_vaild, num_epochs, lr, try_gpu())

相关文章:
深度学习推荐系统(八)AFM模型及其在Criteo数据集上的应用
深度学习推荐系统(八)AFM模型及其在Criteo数据集上的应用 1 AFM模型原理及其实现 沿着特征工程自动化的思路,深度学习模型从 PNN ⼀路⾛来,经过了Wide&Deep、Deep&Cross、FNN、DeepFM、NFM等模型,进⾏了大量的、基于不…...

【Spring】aop的底层原理
🎄欢迎来到边境矢梦的csdn博文🎄 🎄本文主要梳理 Spring 中的切面编程aop的底层原理和重点注意的地方 🎄 🌈我是边境矢梦,一个正在为秋招和算法竞赛做准备的学生🌈 🎆喜欢的朋友可以…...
微信小程序开发---基本组件的使用
目录 一、scroll-view (1)作用 (2)用法 二、swiper和swiper-item (1)作用 (2)用法 三、text (1)作用 (2)使用 四、rich-tex…...

SpringBoot国际化配置组件支持本地配置和数据库配置
文章目录 0. 前言i18n-spring-boot-starter1. 使用方式0.引入依赖1.配置项2.初始化国际化配置表3.如何使用 2. 核心源码实现一个拦截器I18nInterceptorI18nMessageResource 加载国际化配置 3.源码地址 0. 前言 写个了原生的SpringBoot国际化配置组件支持本地配置和数据库配置 背…...
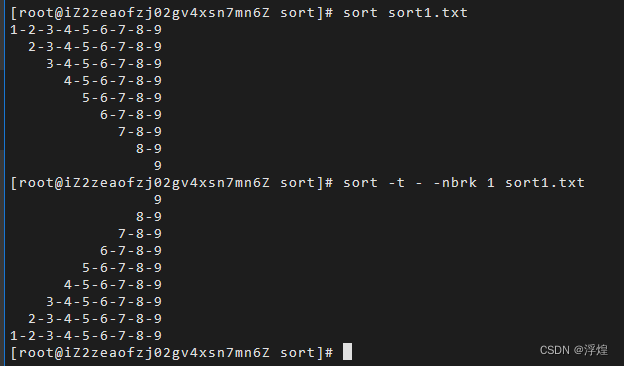
Shell编程之sort
sort 命令将文件的每一行作为比较对象,通过将不同行进行相互比较,从而得到最终结果。从首字符开始,依次按ASCII码值进行比较,最后将结果按升序输出。 基本语法 sort (选项)(参数) 常用选项 常用选项 -n根据字符串的数字比较-r…...

windows docker 容器启动报错:Ports are not available
docker 启动容器报错: (HTTP code 500) server error - Ports are not available: listen tcp 0.0.0.0:6379: bind: An attempt was made to access a socket in a way forbidden by its access permissions. 问题排查 检查端口是否被其它程序占用:nets…...

300. 最长递增子序列
题目描述 给你一个整数数组 nums ,找到其中最长严格递增子序列的长度。 子序列 是由数组派生而来的序列,删除(或不删除)数组中的元素而不改变其余元素的顺序。例如,[3,6,2,7] 是数组 [0,3,1,6,2,2,7] 的子序列。 示…...
)
DNS(域名解析系统)
含义 当我们在上网要访问莫个服务器的时候,就需要知道服务器的IP地址,但IP地址是一串数字,虽然这串数字用点分十进制已经清晰不少了,但还是不利于人们记忆和传播,于是人们使用单词来代替IP地址(例如baidu&a…...

解决jsp/html界面跳转servlet出现404错误的方法
解决jsp/html界面跳转servlet出现404错误的方法 最近在学习黑马项目过程中遇到的问题 问题一: 检查页面的跳转路径和名称拼写是否正确 问题二: tomcat发布项目时所使用的路径名称与项目不同 在idea右上角点击如图圈住的按钮 在deployment中更改出现…...

catface,使用Interface定义Controller,实现基于Http协议的RPC调用
catface 前言cat-client 模块EnableCatClientCatClientCatMethodCatNoteCatResponesWrapperCatClientConfigurationCatClientProviderCatClientFactoryCatSendInterceptorCatHttpCatPayloadResolverCatObjectResolverCatLoggerProcessorCatResultProcessorCatSendProcessorAbst…...
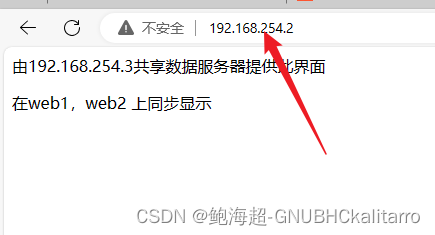
Linux:LVS (NAT群集搭建)
模拟环境 外网入口服务器 外网 192.168.8.88 内网ip 192.168.254.4 web1 服务器 ip 192.168.254.1 网关: 192.168.254.4 web2 服务器 ip 192.168.254.2 网关: 192.168.254.4 共享存储服务器 ip 192.168.254.3 介绍 访问 外网192.16…...
音乐格式转换mp3怎么转?跟着步骤操作一遍
音乐格式转换mp3怎么转?mp3,一种音频数据压缩格式,由于其极具优势的文件尺寸小和高质量音效,自诞生之日起就占据了主流音乐格式的头把交椅,并且至今仍然受到用户的青睐,稳居音乐领域的霸主地位。在我们繁忙…...

it监控系统可以电脑吗?有什么效果
IT业务监控已经成为公司不可或缺的一部分,以确保业务的正常运行,提高企业的竞争能力。本文将详细介绍IT业务监控的必要性、实施方法以及如何选择合适的监控工具。 IT业务监控的必要性 确保业务稳定运行 IT业务监控可以实时检测公司的工作流程&#x…...
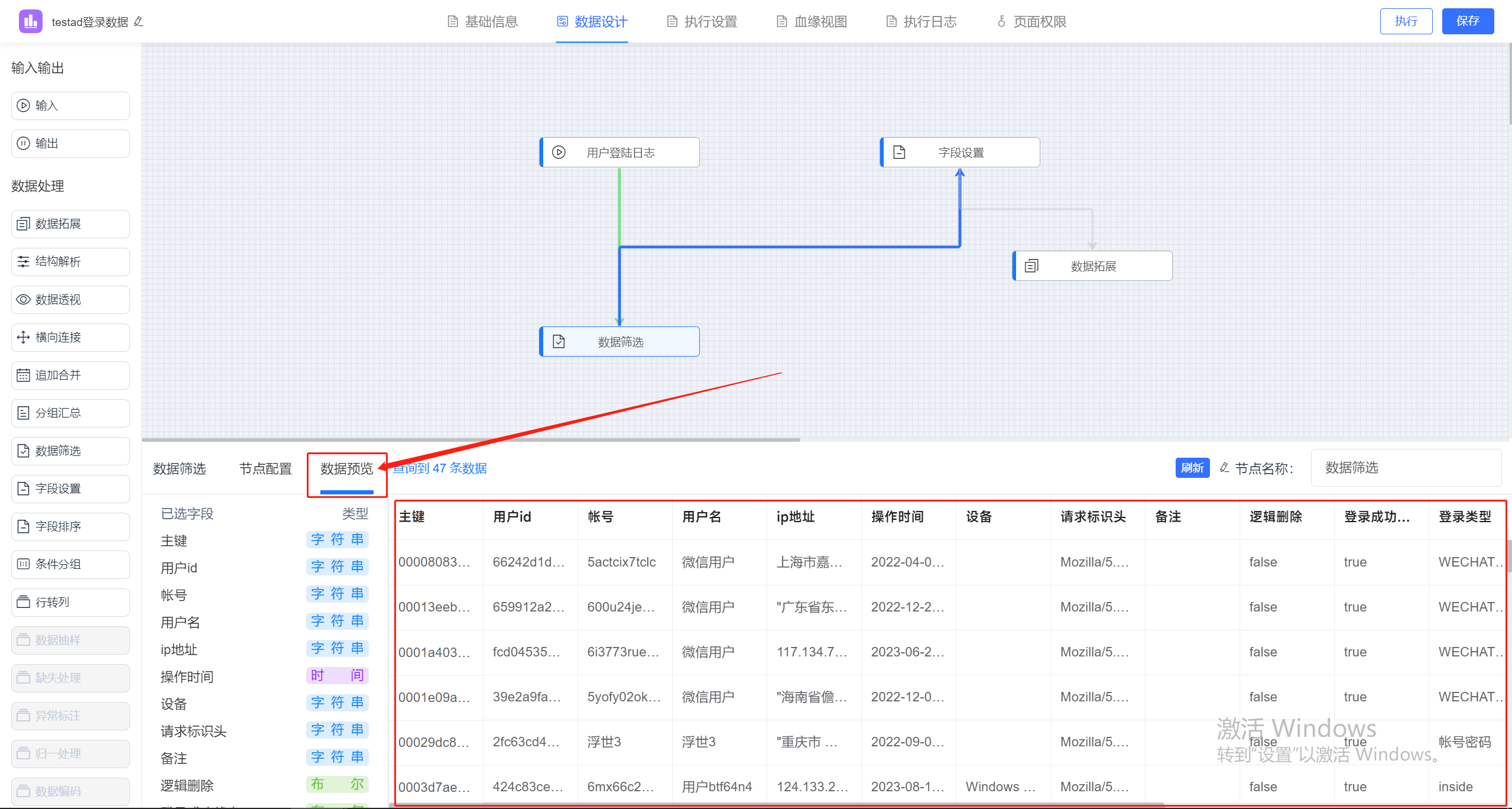
jvs-智能bi(自助式数据分析)9.1更新内容
jvs-智能bi更新功能 1.报表增加权限功能(服务、模板、数据集、数据源可进行后台权限分配) 每个报表可以独立设置权限,通过自定义分配,给不同的人员分配不同的权限。 2.报表新增执行模式 可选择首次报表加载数据为最新数据和历…...

MyBatis-Plus-扩展操作(3)
3.扩展 代码生成 逻辑删除 枚举处理器 json处理器 配置加密 分页插件 3.1 代码生成 https://blog.csdn.net/weixin_41957626/article/details/132651552 下载下面的插件 红色的是刚刚生成的。 我觉得不如官方的那个好用,唯一的好处就是勾选的选项能够看的懂得。…...

react 中 antd 的 样式和 tailwind 样式冲突
问题原因:在使用 tailwindcss 时,会导入大量的 tailwindcss 默认属性,而默认样式中 button, [typebutton] 包含了 background-color: transparent; 从而导致 antd Button 按钮背景色变成透明。解决办法:禁止 tailwindcss 的默认属…...
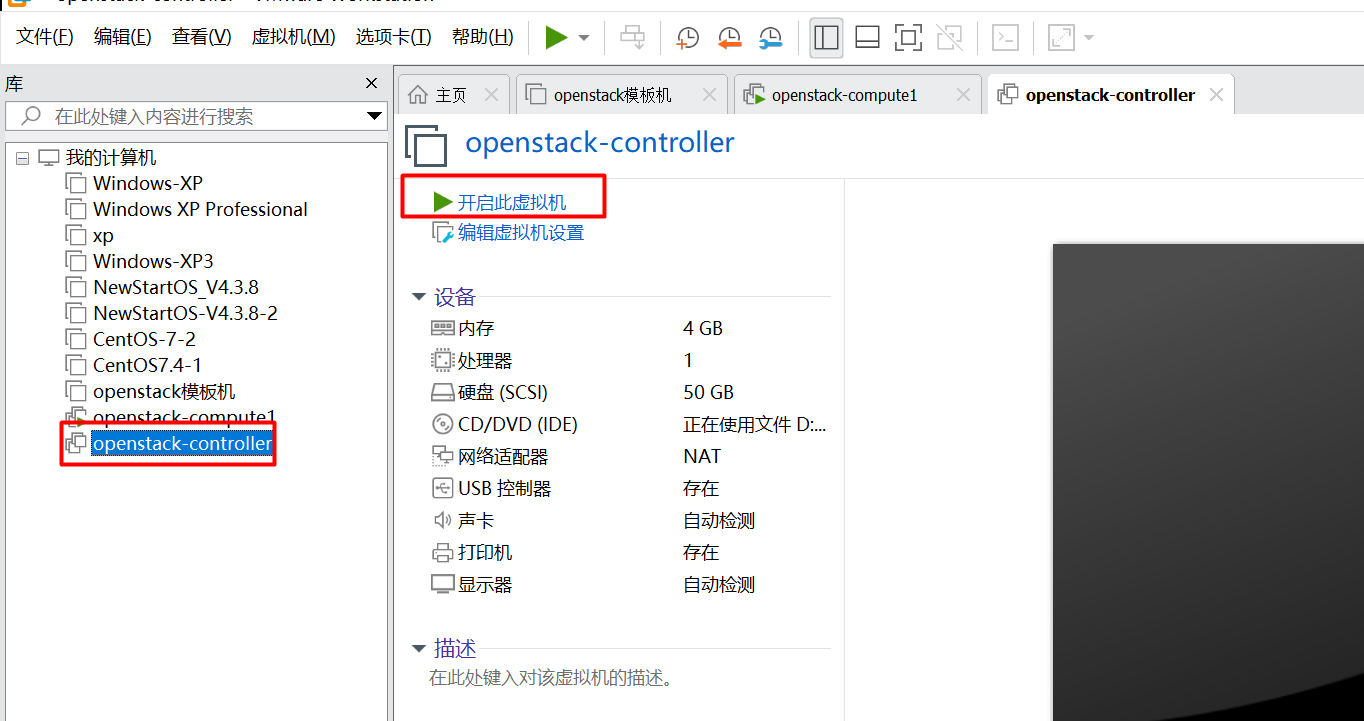
获取该虚拟机的所有权失败,主机上的某个应用程序正在使用该虚拟机
点击“openstack-controller”虚机 打开出现如下错误,点击“获取所有权” 点击“取消” 这时候不要删除虚拟机,这种错误一般是由于虚拟机没有正常关闭引起的。 找到openstack-controller的虚拟磁盘文件及配置文件存放的位置,删除openstack-…...

2024届校招-Java开发笔试题-S4卷
有三种题型:单项选择题(10道)、不定项选择题(10道)、编程题(3道) 下面是一些回忆的题目: 1.哪种设计模式将对象的创建与使用分离,通过工厂类创建对象 答:工…...
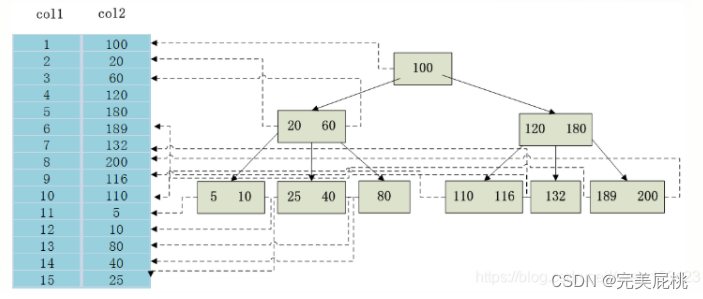
数据分析面试题(2023.09.08)
数据分析流程 总体分为四层:需求层、数据层、分析层和结论层 一、统计学问题 1、贝叶斯公式复述并解释应用场景 公式:P(A|B) P(B|A)*P(A) / P(B)应用场景:如搜索query纠错,设A为正确的词,B为输入的词,那…...

jenkins 报错fatal:could not read Username for ‘XXX‘:No such device or address
#原因:机器做迁移,或者断电,遇到突发情况 #解决: 一.排查HOME和USER环境变量 可以在项目执行shell脚本的时候echo $HOME和USER 也可以在构建记录位置点击compare environment 对比两次构建的环境变量 二.查看指定节点的git凭证 查…...

Golang 面试经典题:map 的 key 可以是什么类型?哪些不可以?
Golang 面试经典题:map 的 key 可以是什么类型?哪些不可以? 在 Golang 的面试中,map 类型的使用是一个常见的考点,其中对 key 类型的合法性 是一道常被提及的基础却很容易被忽视的问题。本文将带你深入理解 Golang 中…...

JavaScript 中的 ES|QL:利用 Apache Arrow 工具
作者:来自 Elastic Jeffrey Rengifo 学习如何将 ES|QL 与 JavaScript 的 Apache Arrow 客户端工具一起使用。 想获得 Elastic 认证吗?了解下一期 Elasticsearch Engineer 培训的时间吧! Elasticsearch 拥有众多新功能,助你为自己…...

基于服务器使用 apt 安装、配置 Nginx
🧾 一、查看可安装的 Nginx 版本 首先,你可以运行以下命令查看可用版本: apt-cache madison nginx-core输出示例: nginx-core | 1.18.0-6ubuntu14.6 | http://archive.ubuntu.com/ubuntu focal-updates/main amd64 Packages ng…...

oracle与MySQL数据库之间数据同步的技术要点
Oracle与MySQL数据库之间的数据同步是一个涉及多个技术要点的复杂任务。由于Oracle和MySQL的架构差异,它们的数据同步要求既要保持数据的准确性和一致性,又要处理好性能问题。以下是一些主要的技术要点: 数据结构差异 数据类型差异ÿ…...

【单片机期末】单片机系统设计
主要内容:系统状态机,系统时基,系统需求分析,系统构建,系统状态流图 一、题目要求 二、绘制系统状态流图 题目:根据上述描述绘制系统状态流图,注明状态转移条件及方向。 三、利用定时器产生时…...

高防服务器能够抵御哪些网络攻击呢?
高防服务器作为一种有着高度防御能力的服务器,可以帮助网站应对分布式拒绝服务攻击,有效识别和清理一些恶意的网络流量,为用户提供安全且稳定的网络环境,那么,高防服务器一般都可以抵御哪些网络攻击呢?下面…...

Springboot社区养老保险系统小程序
一、前言 随着我国经济迅速发展,人们对手机的需求越来越大,各种手机软件也都在被广泛应用,但是对于手机进行数据信息管理,对于手机的各种软件也是备受用户的喜爱,社区养老保险系统小程序被用户普遍使用,为方…...

SAP学习笔记 - 开发26 - 前端Fiori开发 OData V2 和 V4 的差异 (Deepseek整理)
上一章用到了V2 的概念,其实 Fiori当中还有 V4,咱们这一章来总结一下 V2 和 V4。 SAP学习笔记 - 开发25 - 前端Fiori开发 Remote OData Service(使用远端Odata服务),代理中间件(ui5-middleware-simpleproxy)-CSDN博客…...

LangChain知识库管理后端接口:数据库操作详解—— 构建本地知识库系统的基础《二》
这段 Python 代码是一个完整的 知识库数据库操作模块,用于对本地知识库系统中的知识库进行增删改查(CRUD)操作。它基于 SQLAlchemy ORM 框架 和一个自定义的装饰器 with_session 实现数据库会话管理。 📘 一、整体功能概述 该模块…...
的使用)
Go 并发编程基础:通道(Channel)的使用
在 Go 中,Channel 是 Goroutine 之间通信的核心机制。它提供了一个线程安全的通信方式,用于在多个 Goroutine 之间传递数据,从而实现高效的并发编程。 本章将介绍 Channel 的基本概念、用法、缓冲、关闭机制以及 select 的使用。 一、Channel…...