Hadoop的安装和使用,Windows使用shell命令简单操作HDFS
1,Hadoop简介
Hadoop是一个能够对大量数据进行分布式处理的软件框架,并且是以一种可靠、高效、可伸缩的方式进行处理的,它具有以下几个方面的特性。 高可靠性。 高效性。 高可扩展性。 高容错性。 成本低。 运行在Linux平台上。 支持多种编程语言。,2,分布式文件系统HDFS
2,分布式文件系统HDFS
1. HDFS简介
Hadoop分布式文件系统(Hadoop Distributed File System,HDFS)是Hadoop项目的两大核心之一,是针对谷歌文件系统(Google File System,GFS)的开源实现。 总体而言,HDFS要实现以下目标: 兼容廉价的硬件设备。 流数据读写。 大数据集。 简单的文件模型。 强大的跨平台兼容性。
2.HDFS体系结构

Hadoop包含了HDFS和MapReduce两大核心组件,本教程主要使用HDFS,没有使用MapReduce,但是,仍然要完整地安装Hadoop。这里采用的Apache Hadoop版本是3.1.3。 Hadoop包括三种安装模式:
单机模式:只在一台机器上运行,存储是采用本地文件系统,没有采用分布式文件系统HDFS;
伪分布式模式:存储采用分布式文件系统HDFS,但是,HDFS的名称节点和数据节点都在同一台机器上;
分布式模式:存储采用分布式文件系统HDFS,而且,HDFS的名称节点和数据节点位于不同机器上。
3,Hadoop的安装
这里介绍Hadoop伪分布式模式的安装方法。
到Hadoop官网(https://archive.apache.org/dist/hadoop/common/hadoop-3.1.3/)下载Hadoop3.1.3安装文件hadoop-3.1.3.tar.gz。
由于Hadoop不直接支持Windows系统,因此,需要使用工具集winutils进行支持。到github.com网站(https://github.com/s911415/apache-hadoop-3.1.3-winutils)下载与Hadoop3.1.3配套的winutils。进入下载页面后,如图2-16所示,点击“Code”按钮,然后在弹出的菜单中点击“Download ZIP”即可下载得到压缩文件apache-hadoop-3.1.3-winutils-master.zip,再将该压缩文件进行解压缩。
把Hadoop3.1.3安装文件hadoop-3.1.3.tar.gz解压缩到“C:\”(或者其他目录),使用winutils中的bin目录整个替换Hadoop中的bin目录。
在“C:\ hadoop-3.1.3”目录下新建tmp目录,再在tmp目录下新建两个子目录,分别是datanode和namenode。

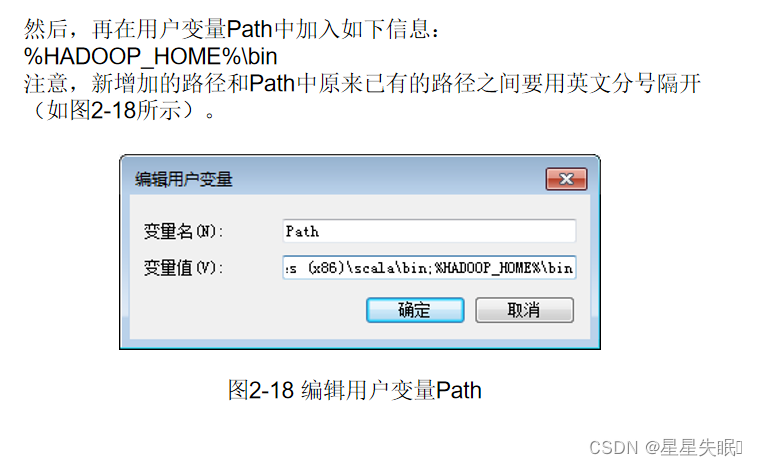
对“C:\ hadoop-3.1.3\etc\hadoop”下面的3个配置文件进行修改。
把core-site.xml文件的配置修改为如下:
<configuration><property><name>fs.default.name</name><value>hdfs://localhost:9000</value></property></configuration>
把hdfs-site.xml文件的配置修改为如下:
<configuration><property><name>dfs.replication</name><value>1</value></property><property> <name>dfs.permissions</name> <value>false</value> </property><property><name>dfs.namenode.name.dir</name><value>/C:/hadoop-3.1.3/tmp/namenode</value></property><property><name>dfs.datanode.data.dir</name><value>/C:/hadoop-3.1.3/tmp/datanode</value></property> </configuration>
修改hadoop-env.cmd文件,找到如下一行: set JAVA_HOME=%JAVA_HOME% 把%JAVA_HOME%替换成JDK的绝对路径,比如: set JAVA_HOME=C:\ Java\jdk1.8.0_111 需要注意的是,如果JDK路径中包含了空格,如果直接使用如下设置后面步骤会报错: set JAVA_HOME= C:\Program Files\Java\jdk1.8.0_111 如果采用这种带有空格的路径,后面运行“hdfs namenode -format”命令时就会报错,因为Program Files中存在空格。为了解决这个问题,可以使用下面两种方式之一进行处理:
(1)只需要用PROGRA~1 代替Program Files,即改为C:\PROGRA~1\Java\jdk1.8.0_111 (2)或是使用双引号,即改为 “C:\Program Files”\Java\jdk1.8.0_111
然后,在Windows系统中打开一个cmd窗口,执行如下命令对Hadoop系统进行格式化:
> cd c:\hadoop-3.1.3\bin
> hdfs namenode -format
上述命令执行以后,如果返回类似如下的信息则表示格式化成功:
\hadoop-3.1.3\tmp\namenode has been successfully formatted. 执行如下命令启动
> cd c:\hadoop-3.1.3\sbin
> start-dfs.cmd 执行该命令以后,会同时弹出另外2个cmd窗口,这2个新弹出的cmd窗口不要关闭,然后,在刚才执行start-dfs.cmd命令的cmd窗口内,继续执行JDK自带的命令jps查看Hadoop已经启动的进程:
> jps
需要注意的是,这里在使用jps命令的时候,没有带上绝对路径,是因为已经把JDK添加到了Path环境变量中。 执行jps命令以后,如果能够看到“DataNode”和“NameNode”这两个进程,就说明Hadoop启动成功。 需要关闭Hadoop时,可以执行如下命令:
> cd c:\hadoop-3.1.3\sbin > stop-dfs.cmd
1.使用WEB管理页面操作HDFS
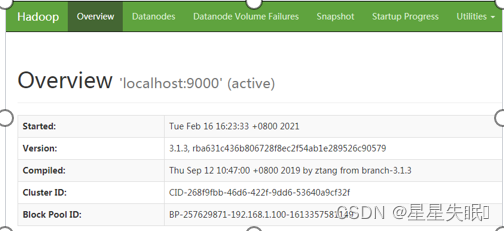
首先启动Hadoop,然后可以在浏览器中输入“http://localhost:9870”,就可以访问Hadoop的WEB管理页面
在WEB管理页面中,点击顶部右侧的菜单选项“Utilities”,在弹出的子菜单中点击“Browse the file system”,会出现如图2-20所示的HDFS文件系统操作页面,在这个页面中可以创建、查看、删除目录和文件
2.使用命令操作HDFS
除了在浏览器中通过WEB方式操作HDFS以外,还可以在cmd窗口中使用命令对HDFS进行操作。

4,HDFS的基本使用方法
1)启动hadoop,为当前登录的Windows用户在HDFS中创建用户目录



2)在用户名user/zhangna下创建test目录


在user/zhangna下有了test目录了
3)将windows操作系统本地的一个文件上传到hdfs的test目录中

我把文件保存到了D盘,并且用hadoop命令put把文件传到了test目录中

在cmd命令提示符中出现了乱码,在浏览器查看hadoop可以显示出内容

4)把test目录复制到windows本地文件系统某个目录下


在D盘下面我创建的zhang的文件夹下有test目录,并且有test.txt文件
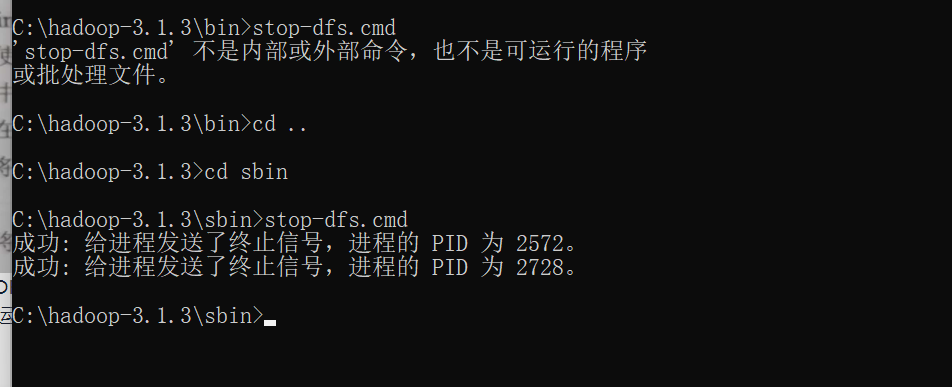
5)我把hadoop使用命令停了
相关文章:
Hadoop的安装和使用,Windows使用shell命令简单操作HDFS
1,Hadoop简介 Hadoop是一个能够对大量数据进行分布式处理的软件框架,并且是以一种可靠、高效、可伸缩的方式进行处理的,它具有以下几个方面的特性。 高可靠性。 高效性。 高可扩展性。 高容错性。 成本低。 运行在Linux平台上。 支持多种编程…...

ubuntu上ffmpeg使用framebuffer显示video
这个主题是想验证使用fbdev(Linux framebuffer device),将video直接显示到Linux framebuffer上,在FFmpeg中对应的FFOutputFormat 就是ff_fbdev_muxer。 const FFOutputFormat ff_fbdev_muxer {.p.name "fbdev",.p.long_…...
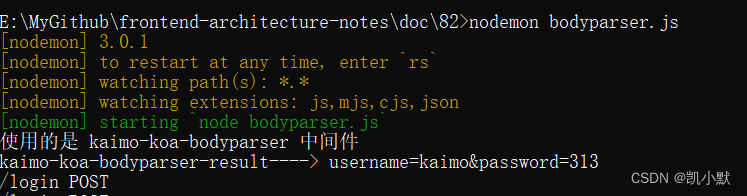
82 # koa-bodyparser 中间件的使用以及实现
准备工作 安装依赖 npm init -y npm i koakoa 文档:https://koajs.cn/# koa 中不能用回调的方式来实现,因为 async 函数执行的时候不会等待回调完成 app.use(async (ctx, next) > {console.log(ctx.path, ctx.method);if (ctx.path "/login…...

计算一串输出数字的累加和
计算一个文件内数字的累加和 awk {sum$1}END{print sum} 直接抽取数据以后的打印是这样的 cat step-iostat.1125.log |grep sda |cut -c "49-56" |awk {sum$1}END{print sum}...

python包导入原理解析
原文链接: https://www.cnblogs.com/hi3254014978/p/15317976.html 根据编程经验的不同,我们在运行程序时可能经常或者偶尔碰到下面这些问题,仔细观察后会发现这些问题无一例外都出现了一个相同的短语,很容易就可以发现࿰…...

MNIST手写数字辨识-cnn网路 (机器学习中的hello world,加油)
用PyTorch实现MNIST手写数字识别(非常详细) - 知乎 (zhihu.com) 参考来源(这篇文章非常适合入门来看,每个细节都讲解得很到位) 一、模块函数用法-查漏补缺: 1.关于torch.nn.functional.max_pool2d()的用法: 上述示例…...

论文笔记《3D Gaussian Splatting for Real-Time Radiance Field Rendering》
项目地址 原论文 Abstract 最近辐射场方法彻底改变了多图/视频场景捕获的新视角合成。然而取得高视觉质量仍需神经网络花费大量时间训练和渲染,同时最近较快的方法都无可避免地以质量为代价。对于无边界的完整场景(而不是孤立的对象)和 10…...

数据库管理系统,数据库,sql的基本介绍以及它们之间的关系
数据库管理系统(Database Management System,简称DBMS)是一种软件工具或系统,用于管理和维护数据库的创建、访问、更新和管理。DBMS允许用户在数据库中存储、检索和操作数据,同时提供了数据安全性、完整性和一致性的控…...
)
【Flowable】Springboot使用Flowable(一)
一、项目依赖 <dependency><groupId>org.flowable</groupId><artifactId>flowable-engine</artifactId><version>6.3.0</version></dependency><dependency><groupId>mysql</groupId><artifactId>my…...

戳泡泡小游戏
欢迎来到程序小院 戳泡泡 玩法: 鼠标点击上升的起泡泡,点击暴躁记录分数,不要让泡泡越过屏幕,共有三次复活生命,会有随机星星出现,点击即可暴躁全屏哦^^。开始游戏https://www.ormcc.com/play/gameStart/1…...

Redis缓存
1. Redis缓存相关问题 1.1 缓存穿透 缓存穿透是指查询一个数据库一定不存在的数据。 我们以前正常的使用Redis缓存的流程大致是: 1、数据查询首先进行缓存查询 2、如果数据存在则直接返回缓存数据 3、如果数据不存在,就对数据库进行查询࿰…...

mysql 插入更新数据
insert into insert into 语句进行插入时,如果插入的字段包含 主键或者唯一索引字段,那么, 1)主键或唯一索引 已存在,则插入失败 1062 - Duplicate entry 1 for key PRIMARY 2)只有主键或者唯一索 引不存…...
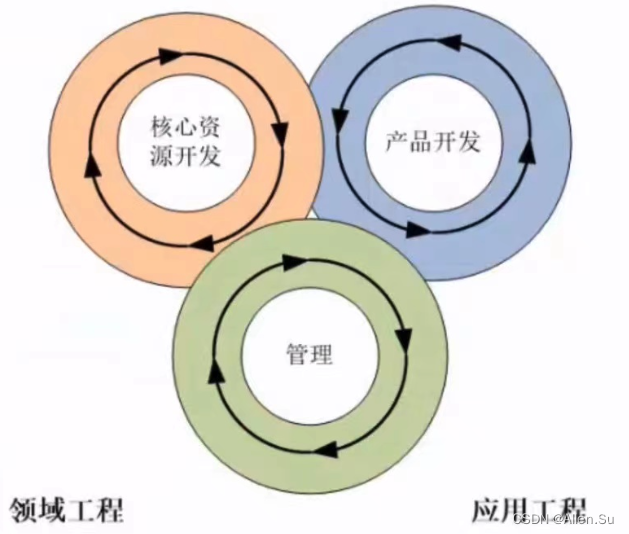
系统架构设计高级技能 · 软件产品线
现在的一切都是为将来的梦想编织翅膀,让梦想在现实中展翅高飞。 Now everything is for the future of dream weaving wings, let the dream fly in reality. 点击进入系列文章目录 系统架构设计高级技能 软件产品线 一、产品线概述二、产品线的过程模型2.1 双生命…...

C语言学习系列-->字符函数和字符串函数
文章目录 一、字符函数1、字符分类函数2、字符转换函数 二、字符串函数1、strlen概述模拟实现 2、strcpy概述模拟实现 3、strcat概述模拟实现 3、strcmp概述模拟实现 4、有限制的字符串函数strncpystrncatstrncmp 4、strstr概述模拟实现 一、字符函数 1、字符分类函数 包含头…...

尖端AR技术如何在美国革新外科手术实践?
AR智能眼镜已成为一种革新性的工具,在外科领域具有无穷的优势和无限的机遇。Vuzix与众多医疗创新企业建立了长期合作关系,如Pixee Medical、Medacta、Ohana One、Rods & Cones、Proximie等。这些公司一致认为Vuzix智能眼镜可有效提升手术实践&#x…...

【木板】Python实现-附ChatGPT解析
1.题目 木板 时间限制:1s 空间限制:256MB 限定语言:不限题目描述: 小明有n块木板,第i (1<=i<=n) 块木板的长度为ai.小明买了一块长度为m的木料,这块木料可以切割成任意块,拼接到已有的木板上用来加长木板。 小明想让最短的木板尽量长。 请问小明加长木板后,最短木板…...
第一章:绪论
1.1 系统架构概述 架构是体现在组件中的一个系统的基本组织、它们彼此的关系与环境的关系以及指导它的设计和发展的原则。 系统是组织起来完成某一特定功能火一组功能的组件集。系统这个术语包括了单独的应用程序、传统意义上的系统、子系统、系统之系统、产品线、整个企业及…...

C++面试知识点总结
知识点总结 <<符号表示该语句将把这个字符串发送给cout;该符号指出了信息流动的路径;cout的对象属性包括一个插入运算符(<<),它可以将其右侧的信息插入到流中,endl:重起一行。在输出流中插入en…...

从智能手机到智能机器人:小米品牌的高端化之路
原创 | 文 BFT机器人 前言 在前阵子落幕的2023世界机器人大会“合作之夜”上,北京经济技术开发区管委会完成了与世界机器人合作组织、小米机器人等16个重点项目签约,推动机器人创新链和产业链融合,其中小米的投资额达到20亿! 据了…...

深度学习推荐系统(八)AFM模型及其在Criteo数据集上的应用
深度学习推荐系统(八)AFM模型及其在Criteo数据集上的应用 1 AFM模型原理及其实现 沿着特征工程自动化的思路,深度学习模型从 PNN ⼀路⾛来,经过了Wide&Deep、Deep&Cross、FNN、DeepFM、NFM等模型,进⾏了大量的、基于不…...

TDengine 快速体验(Docker 镜像方式)
简介 TDengine 可以通过安装包、Docker 镜像 及云服务快速体验 TDengine 的功能,本节首先介绍如何通过 Docker 快速体验 TDengine,然后介绍如何在 Docker 环境下体验 TDengine 的写入和查询功能。如果你不熟悉 Docker,请使用 安装包的方式快…...

1.3 VSCode安装与环境配置
进入网址Visual Studio Code - Code Editing. Redefined下载.deb文件,然后打开终端,进入下载文件夹,键入命令 sudo dpkg -i code_1.100.3-1748872405_amd64.deb 在终端键入命令code即启动vscode 需要安装插件列表 1.Chinese简化 2.ros …...
)
是否存在路径(FIFOBB算法)
题目描述 一个具有 n 个顶点e条边的无向图,该图顶点的编号依次为0到n-1且不存在顶点与自身相连的边。请使用FIFOBB算法编写程序,确定是否存在从顶点 source到顶点 destination的路径。 输入 第一行两个整数,分别表示n 和 e 的值(1…...

蓝桥杯3498 01串的熵
问题描述 对于一个长度为 23333333的 01 串, 如果其信息熵为 11625907.5798, 且 0 出现次数比 1 少, 那么这个 01 串中 0 出现了多少次? #include<iostream> #include<cmath> using namespace std;int n 23333333;int main() {//枚举 0 出现的次数//因…...
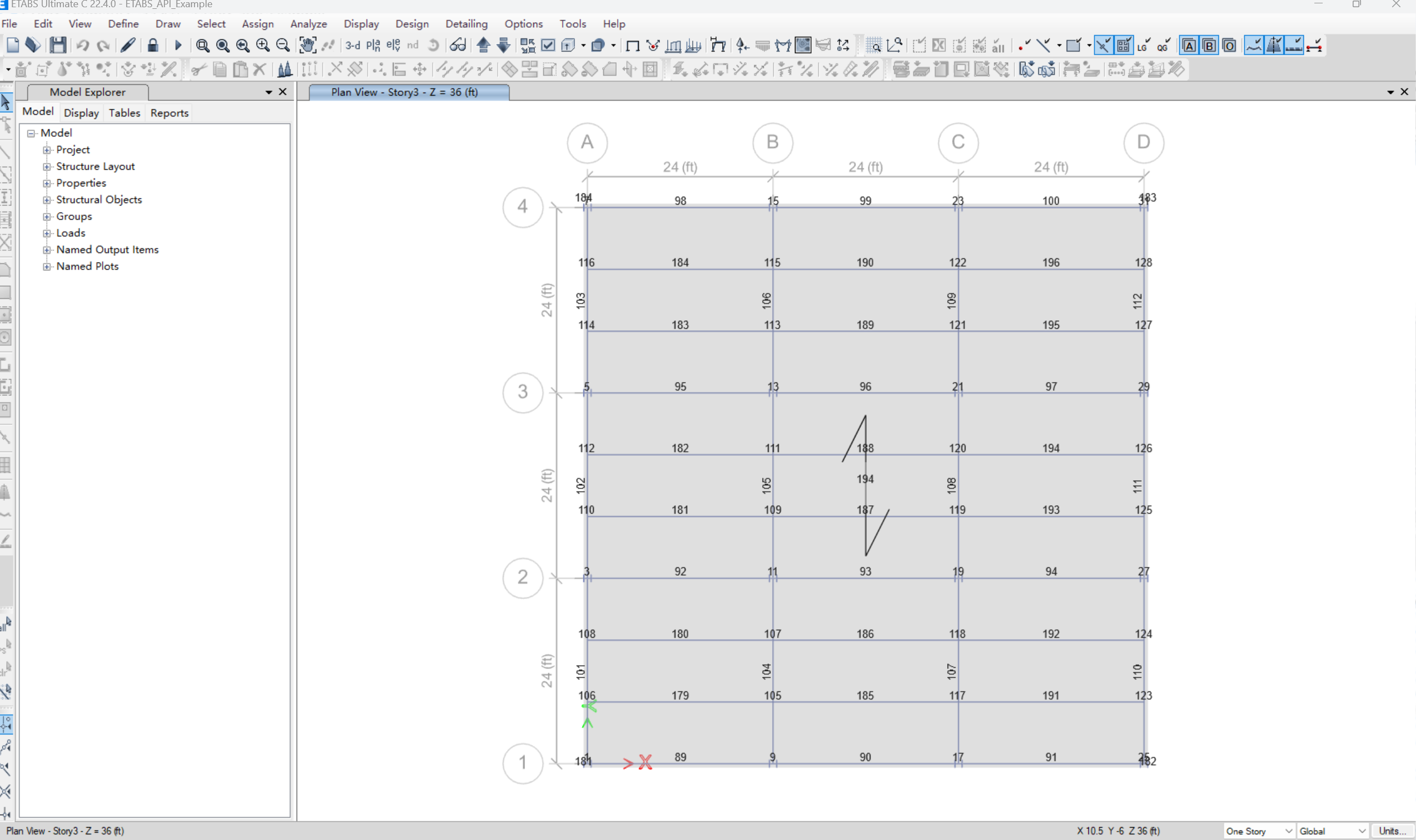
【Post-process】【VBA】ETABS VBA FrameObj.GetNameList and write to EXCEL
ETABS API实战:导出框架元素数据到Excel 在结构工程师的日常工作中,经常需要从ETABS模型中提取框架元素信息进行后续分析。手动复制粘贴不仅耗时,还容易出错。今天我们来用简单的VBA代码实现自动化导出。 🎯 我们要实现什么? 一键点击,就能将ETABS中所有框架元素的基…...

图解JavaScript原型:原型链及其分析 | JavaScript图解
忽略该图的细节(如内存地址值没有用二进制) 以下是对该图进一步的理解和总结 1. JS 对象概念的辨析 对象是什么:保存在堆中一块区域,同时在栈中有一块区域保存其在堆中的地址(也就是我们通常说的该变量指向谁&…...
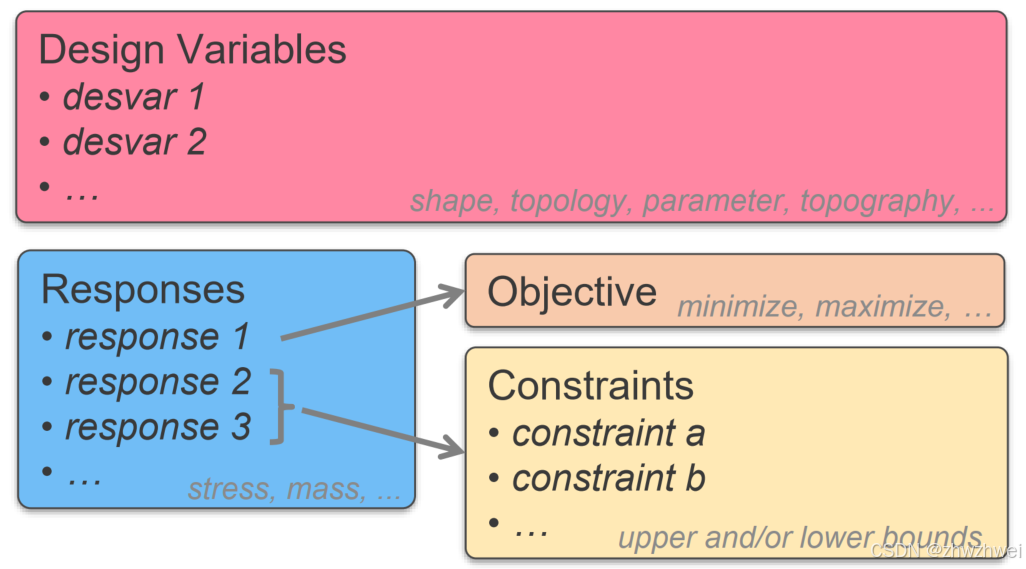
[拓扑优化] 1.概述
常见的拓扑优化方法有:均匀化法、变密度法、渐进结构优化法、水平集法、移动可变形组件法等。 常见的数值计算方法有:有限元法、有限差分法、边界元法、离散元法、无网格法、扩展有限元法、等几何分析等。 将上述数值计算方法与拓扑优化方法结合&#…...
深入解析光敏传感技术:嵌入式仿真平台如何重塑电子工程教学
一、光敏传感技术的物理本质与系统级实现挑战 光敏电阻作为经典的光电传感器件,其工作原理根植于半导体材料的光电导效应。当入射光子能量超过材料带隙宽度时,价带电子受激发跃迁至导带,形成电子-空穴对,导致材料电导率显著提升。…...

拟合问题处理
在机器学习中,核心任务通常围绕模型训练和性能提升展开,但你提到的 “优化训练数据解决过拟合” 和 “提升泛化性能解决欠拟合” 需要结合更准确的概念进行梳理。以下是对机器学习核心任务的系统复习和修正: 一、机器学习的核心任务框架 机…...
加密芯片与MCU协同工作的典型流程)
SE(Secure Element)加密芯片与MCU协同工作的典型流程
以下是SE(Secure Element)加密芯片与MCU协同工作的典型流程,综合安全认证、数据保护及防篡改机制: 一、基础认证流程(参数保护方案) 密钥预置 SE芯片与MCU分别预置相同的3DES密钥(Key1、Key2…...