web UI自动化介绍
文章目录
- 一、web UI自动化介绍
- 1.1 执行UI自动化测试前提
- 1.2 Selenium介绍以及知识点梳理
- 二、Selenium 学习
- 2.1 基础
- 2.1.1 环境安装与基础使用
- 2.1.2 web浏览器控制
- 2.1.3 常见控件的八大定位方式
- 2.1.3.1 八大定位方式介绍
- 2.1.3.2 NAME、ID定位
- 2.1.3.3 css_selector定位
- 2.1.3.4 通过XPATH定位
- 2.1.4 强制等待与隐式等待
- 2.4.1 **强制(直接)等待**
- 2.4.2 **隐式等待**
- 2.4.3 **显式等待**
- 2.4.4 总结
- 2.1.5 常见控件的交互方法
- 2.1.6 练习1-测试人论坛搜索自动化
- 2.2 进阶
- 2.2.1 css selector定位
- 2.2.1.1 css 选择器概念
- 2.2.1.2 CSS基础语法
- 调试方法
- css基础语法
- 关系定位
- css 顺序关系
- 2.2.2 XPATH定位
- 2.2.2.1 xpath 基本概念
- 2.2.2.2 XPTAH基础语法
- **调试方法**
- 基础语法
- 2.2.2.3 xpath 高级用法
- 2.2.3 显示等待的高级应用
- 原理解析
- 官方分装类 expected_conditions
- 自定义显示等待条件
- 2.2.4高级控件的交互方法
- 介绍
- ActionChains基本用法
- 键盘操作
- 鼠标操作
- 2.25 网页多窗口和Frame的处理
- 多窗口处理
- Frame的处理
- 文件上传以及弹窗处理
- 文件上传
- 弹窗处理
- 关键数据记录
- 介绍
- 示范
- 练习项目1-litemall商城管理后台
- 前置后置操作
- 登录功能
- 新增商品
- 删除商品
- 新增商品测试用例
- 2.3 高级
- 2.3.1 浏览器复用-托管
- 2.3.2 cookie复用
- 2.3.3 Page Object思想
- 2.3.4 异常记录关键信息
- 常规的记录方法
- 使用装饰器记录
- UI自动化的常见项目结构
一、web UI自动化介绍
1.1 执行UI自动化测试前提
- 业务流程不频繁改动
- UI 元素不频繁改动,界面稳定
- 需要频繁回归的场景
- 多平台运行,组合遍历型、大量重复的任务s
业界使用较多的web UI自动化工具是 Selenium
1.2 Selenium介绍以及知识点梳理
支持多语言,行业内最火最主流
-
用于web浏览器测试的工具
-
支持的浏览器包括IE,Firefox,Safari,Chrome,Edge等
-
使用简单,可使用Java,Python等多种语言编写用例脚本
-
主要由三个工具构成:WebDriver、IDE、Grid
-
能力建设——初级
Selenium 的架构:
在客户端通过各种语言调用selenium库,selenium 调用对应的浏览器驱动,通过浏览器驱动去操作浏览器进行各种操作。
| 形式 | 章节 | 描述 |
|---|---|---|
| 知识点 | Web 自动化测试价值与体系 | 价值体系 技术选型 学习路线 |
| 知识点 | 环境安装与使用 | selenium、 chromedriver、 firefox geckodriver |
| 知识点 | 自动化用例录制 | selenium IDE、录制、回放、基本使用 |
| 知识点 | 自动化测试用例结构分析 | 录制代码解析,代码结构优化 |
| 知识点 | web 浏览器控制 | 打开网页、刷新、回退、最大化、最小化 |
| 知识点 | 常见控件定位方法 | id name css xpath link 定位 |
| 知识点 | 强制等待与隐式等待 | 介绍 selenium 经典的三种等待方式 |
| 知识点 | 常见控件交互方法 | 点击,输入,清空,获取元素文本、尺寸等属性信息 |
| 实战 | 测试人论坛搜索功能自动化测试 | 用例设计、用例编写、断言 |
-
中级
形式 章节 描述 知识点 高级定位-css css 使用场景、语法 知识点 高级定位-xpath xpath 使用场景、语法 知识点 显式等待高级使用 显式等待原理与使用 知识点 高级控件交互方法 右键点击、页面滑动、表单填写等自动化动作 知识点 网页 frame 与多窗口处理 多窗口,多 frame 下的窗口识别与切换 知识点 文件上传弹框处理 文件上传的自动化与弹框处理机制 知识点 自动化关键数据记录 行为日志、截图,page source 实战 电子商务产品实战 用例设计、日志封装、测试报告 训练营 知名产品web自动化测试实战 用例设计、日志封装、测试报告 -
高级
形式 章节 描述 知识点 浏览器复用 利用远程调试技术实现自动化登录 知识点 Cookie 复用 利用 cookie 复用实现自动化登录 知识点 page object 设计模式 page object 模式的发展历史介绍、六大设计原则 知识点 异常自动截图 测试用例失败时自动截图 知识点 测试用例流程设计 测试装置的应用,套件级别的初始化与清理、用例级别的初始化与清理 实战 电子商务产品实战 page object 设计模式应用、BasePage 封装、基于 page object 模式的测试用例编写 训练营 web自动化测试进阶实战 page object 设计模式应用、BasePage 封装、基于 page object 模式的测试用例编写 -
拓展
- selenium高级用法
形式 章节 描述 知识点 selenium 多浏览器处理 chrome、firefox 等浏览器的自动化支持 知识点 执行 javascript 脚本 使用 selenium 直接在当前页面中进行 js 交互 知识点 selenium option 常用操作 selenium option 的介绍与使用 知识点 capability 配置参数解析 capability 用法 ,firefox chrome 等浏览器的专属 capability - 新一代前端测试框架
形式 章节 描述 知识点 cypress 测试框架介绍 web 自动化测试框架 cypress
二、Selenium 学习
2.1 基础
2.1.1 环境安装与基础使用
-
准备好Python环境(百度python安装教程)
-
准备好selenium依赖
pip install selenium -
driver的下载与配置(以chrome为例)
-
下载chrome的webdriver
官方链接:
https://www.selenium.dev/documentation/en/webdriver/driver_requirements/
淘宝镜像,下载更快
https://npm.taobao.org/mirrors/chromedriver/
在下载时需要 选择与浏览器对应的版本,如果找不到完全一样的,可以选取个最相近的,一般大版本相同也是可以正常使用的
-
配置环境变量
为了能够直接使用webdriver,而不是使用时去写死webdriver的地址,需要将webdriver所在的文件夹路径加到 环境变量(PATH)中
-
验证
打开一个cmd命令行,输入:
chromedriver --version,可以看到版本信息则说明chromedriver环境变量配置成功
-
-
在代码中import对应的依赖并打开百度
基本使用
from time import sleepfrom selenium import webdriver # 初始化浏览器驱动,这里选择Chrome浏览器,需要配置好webdriver的环境变量 driver = webdriver.Chrome() # 浏览器打卡百度 driver.get('http://www.baidu.com') sleep(10) # 关闭浏览器 driver.close()运行脚本能成功打开百度则说明配置成功
2.1.2 web浏览器控制
在初始化driver后可以使用以下方法对浏览器进行控制
初始化driver即:diver = webdriver.Chrome
然后使用driver调用以下方法:
| 方法 | 使用场景 | 操作 |
|---|---|---|
| get | web自动化测试第一步 | 打开浏览器 |
| refresh | 模拟浏览器刷新 | 浏览器刷新 |
| back | 模拟退回步骤 | 浏览器退回 |
| maximize_window | 模拟浏览器最大化 | 最大化浏览器 |
| minimize_window | 模拟浏览器最小化 | 最小化浏览器 |
from time import sleep
from selenium import webdriver
# 初始化浏览器驱动,这里选择Chrome浏览器,需要配置好webdriver的环境变量
driver = webdriver.Chrome()
# 浏览器打卡百度
driver.get('https://ceshiren.com/')
sleep(3)
# 刷新页面
driver.refresh()
driver.get('http://www.baidu.com')
# 浏览器返回操作
driver.back()
sleep(1)
# 最小化窗口
driver.minimize_window()
sleep(1)
driver.maximize_window()
sleep(1)
# 关闭浏览器
driver.close()
2.1.3 常见控件的八大定位方式
2.1.3.1 八大定位方式介绍
控件的定位方式很多,但常用的只有以下四种:id、name、xpath、css selector ,后续会详细介绍
| 方式 | 描述 | 使用方法 |
|---|---|---|
| id(重点) | id 属性对应的值 | driver.find_element(By.ID, “ID属性”) |
| name(重点) | name 属性对应的值 | driver.find_element(By.NAME, “Name属性对应的值”) |
| xpath(重点) | xpath表达式 | driver.find_element(By.XPATH, “xpath表达式”) |
| css selector(重点) | css 表达式 | driver.find_element(By.CSS_SELECTOR, “css表达式”) |
| link text | 查找其可见文本与搜索值匹配的锚元素 | driver.find_element(By.LINK_TEXT,“文本信息”) |
| partial link text | 查找其可见文本包含搜索值的锚元素。 如果多个元素匹配,则只会选择第一个元素。 | |
| class name | class 属性对应的值 | driver.find_element(By.CLASS_NAME,‘el-submenu__title’) |
| tag name | 标签名称 | 很少用 |
使用格式:
# 示例,两种方式作用一模一样
# 官方建议使用下面的方式
driver.find_element_by_id("su")
driver.find_element(By.ID, "su") # 推荐你使用
-
通过ID定位:
driver.find_element(By.ID, "ID属性对应的值")import time from selenium import webdriver from selenium.webdriver.common.by import By driver = webdriver.Chrome() driver.get('https://ceshiren.com/') # 强制等待3秒,等待元素加载完毕 time.sleep(3) # 点击类别 ele = driver.find_element(By.ID,'ember24').click() time.sleep(30)
2.1.3.2 NAME、ID定位
- name定位格式:
driver.find_element(By.NAME, "Name属性对应的值") - id定位格式:
driver.find_element(By.ID, "ID对应的值")
2.1.3.3 css_selector定位
- 格式:
driver.find_element(By.CSS_SELECTOR, "css表达式") - 复制绝对定位
- 编写 css selector 表达式(后面章节详细讲解)
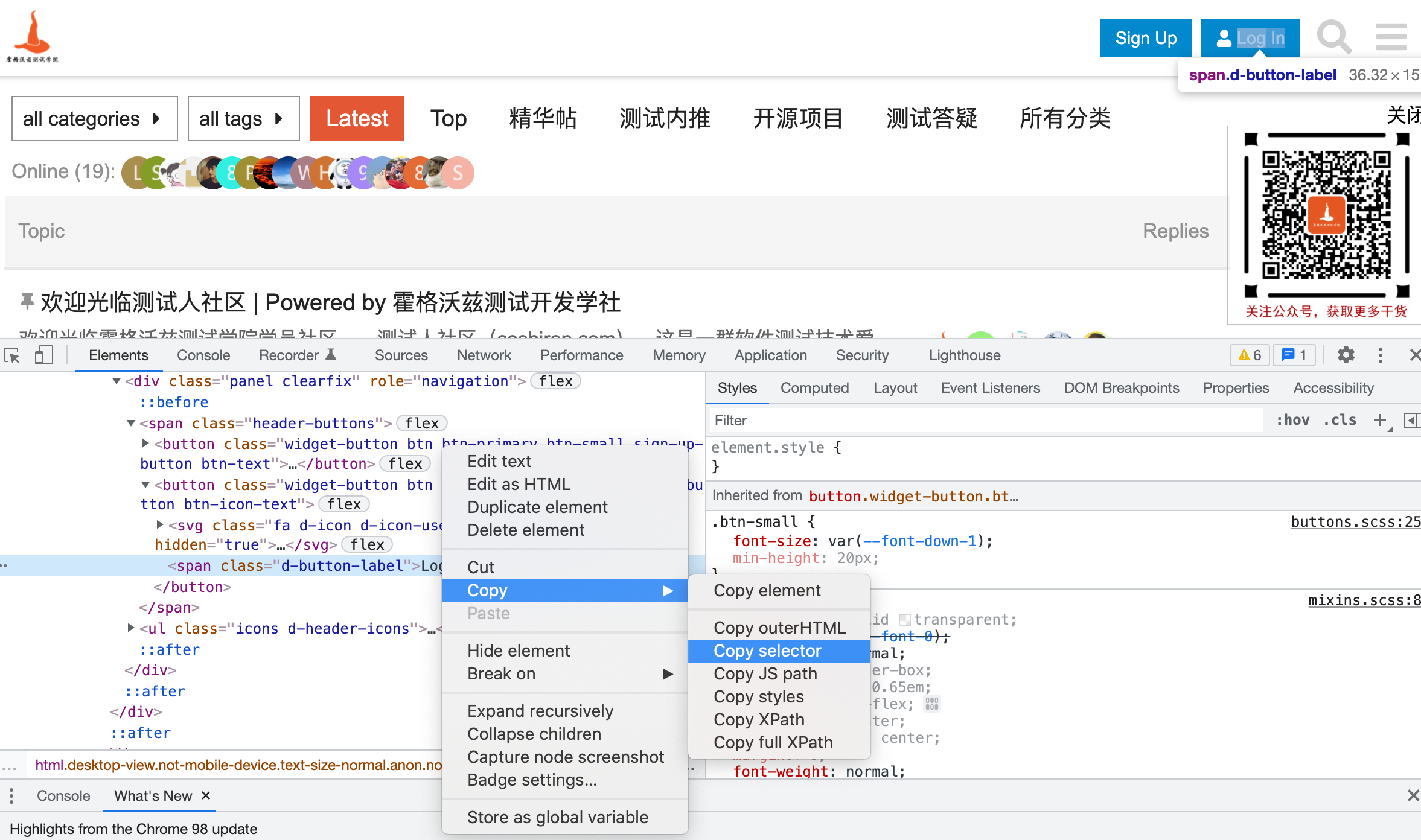
2.1.3.4 通过XPATH定位
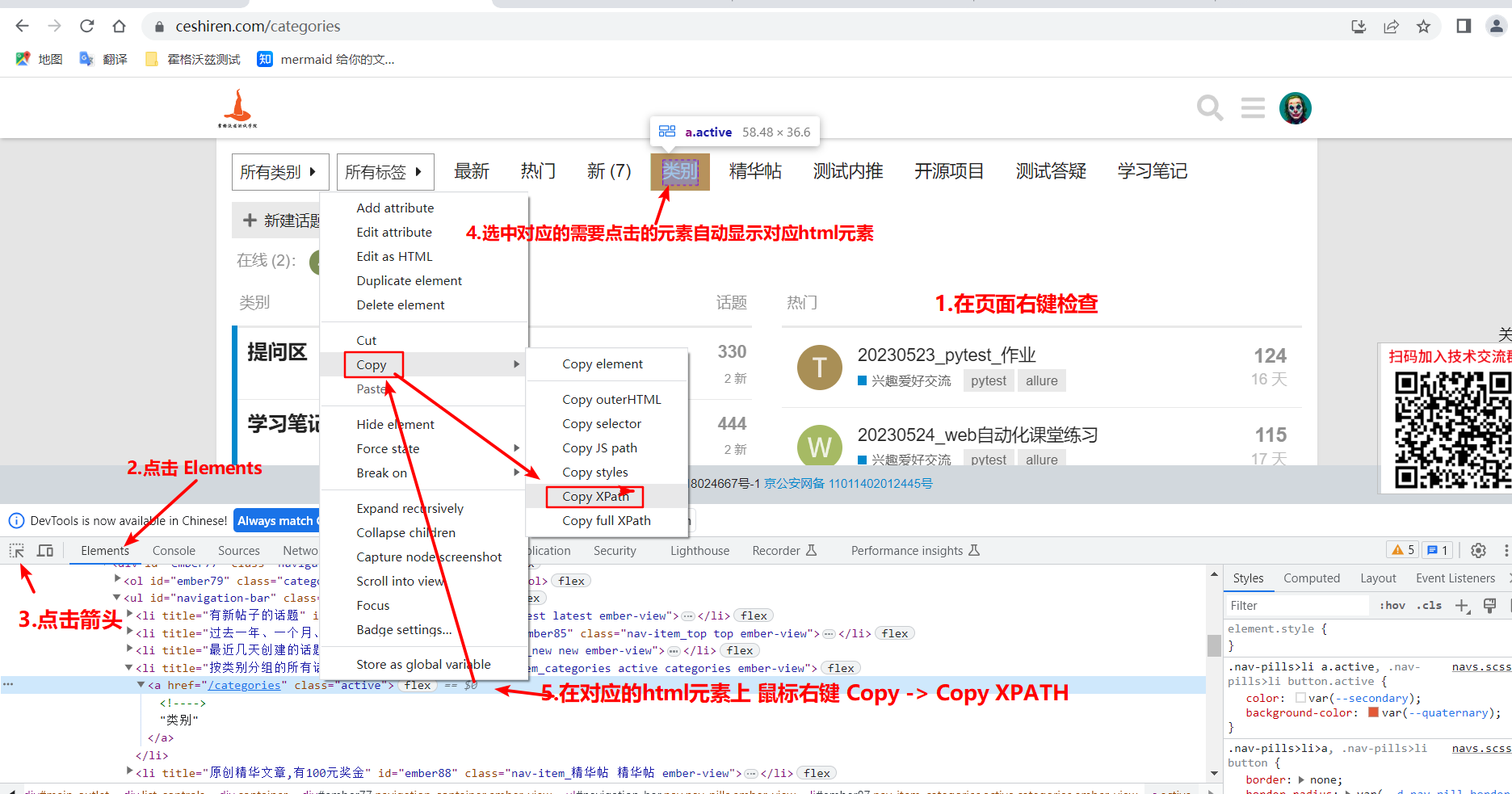
-
格式:
driver.find_element(By.XPATH, "xpath表达式") -
chrome复制绝对定位
-
编写 xpath 表达式(后面章节详细讲解)
2.1.4 强制等待与隐式等待
在chrome打开网页的时候,有时候由于网络加载、渲染等问题,无法定位到元素,需要等待元素加载渲染,否则会出现异常的报错,比如找不到元素等。
等待元素加载分为以下三种:强制等待、隐式等待、以及显示等待
2.4.1 强制(直接)等待
-
原理:直接在操作元素前添加sleep() 函数直接等待几秒,让元素加载成功
-
缺点:难以确定元素加载的具体等待时间,时间短了无法定位到元素,时间长了影响执行效率,可以通过隐式等待解决
2.4.2 隐式等待
-
原理:设置一个等待时间,轮询查找(默认0.5秒)元素是否出现,如果没出现就抛出异常
-
隐式等待相比强制等待更智能,在脚本中我们一般看不到等待语句,但是它会在每个页面加载的时候自动等待;隐式等待只需要声明一次,一般在打开浏览器后进行声明.
声明之后对整个drvier的生命周期都有效,后面不用重复声明。
driver.implicitly_wait(3)
- 缺点:
-
元素可以找到,使用点击等操作,出现报错
-
原因:
- 页面元素加载是异步加载过程,通常html会先加载完成,js、css其后,导致进行交互操作时失败
- 元素存在与否是由HTML决定,元素的交互是由css或者js决定
- 隐式等待只关注元素能不能找到,不关注元素能否点击或者进行其他的交互
-
2.4.3 显式等待
-
原理:在最长等待时间内,轮询,是否满足结束条件
-
格式:
WebDriverWait(driver实例, 最长等待时间, 轮询时间).until(结束条件)def wait_until():driver = webdriver.Chrome()driver.get("https://vip.ceshiren.com/#/ui_study")WebDriverWait(driver, 10).until(expected_conditions.element_to_be_clickable((By.CSS_SELECTOR, '#success_btn')))driver.find_element(By.CSS_SELECTOR, "#success_btn").click()
2.4.4 总结
| 类型 | 使用方式 | 原理 | 适用场景 |
|---|---|---|---|
| 直接等待 | time.sleep(等待时间)) | 强制线程等待 | 调试代码,临时性添加 |
| 隐式等待 | driver.implicitly_wait(等待时间) | 在时间范围内,轮询查找元素 | 解决找不到元素问题,无法解决交互问题 |
| 显式等待 | WebDriverWait(driver实例, 最长等待时间, 轮询时间).until(结束条件) | 设定特定的等待条件,轮询操作 | 解决特定条件下的等待问题,比如点击等交互性行为 |
2.1.5 常见控件的交互方法
-
点击
click()# 点击百度搜索框 driver.find_element(By.ID,"kw").click() -
输入
send_keys('xx')# 输入"霍格沃兹测试开发" driver.find_element(By.ID,"kw").send_keys("霍格沃兹测试开发") -
清空
clear()# 清空搜索框中信息 driver.find_element(By.ID,"kw").clear() -
获取元素属性信息
-
目的:根据这些信息进行断言或者调试
-
获取元素信息的方法
- 获取元素文本
- 获取元素的属性(html的属性值)
# 获取元素文本 driver.find_element(By.ID, "id").text # 获取这个元素的name属性的值 driver.find_element(By.ID, "id").get_attribute("name")
-
2.1.6 练习1-测试人论坛搜索自动化
测试人搜索功能测试—进入测试人论坛首页(https://ceshiren.com)
- 点击搜索按钮
- 输入搜索关键词
- 输入回车进行搜索
预期结果判断:
- 搜索成功
- 搜索结果列表包含关键字
from time import sleepfrom selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions
from selenium.webdriver.support.wait import WebDriverWaitclass TestCeshirenSearch:def setup_class(self):# 初始化driver并打开首页self.driver = webdriver.Chrome()self.driver.get('https://ceshiren.com')# 设置 隐式等待,整个测试期间只需要设置一次self.driver.implicitly_wait(5)def teardown_class(self):sleep(3)# 关闭 浏览器self.driver.close()def test_search(self):# 点击搜索 按钮self.driver.find_element(By.ID, 'search-button').click()# 在搜索输入框输入pytestself.driver.find_element(By.ID, 'search-term').send_keys('pytest')# 显示等待5秒,直到 搜索结果 按钮可点击WebDriverWait(self.driver, 5).until(expected_conditions.element_to_be_clickable(self.driver.find_element(By.CSS_SELECTOR, '.results')))# 查看搜索结果 并根据 结果中是否包含搜索的元素进行 断言el_topic_list = self.driver.find_element(By.CSS_SELECTOR, ".topic-list-body")topic_title_text = el_topic_list.textassert 'pytest' in topic_title_text
2.2 进阶
HTML中常用标签,定位方式一般选取 css定位 或者xpath 定位,需要对html中常用标签有一定的了解,以下是一些基本的标签
标题:<h1>、<h2>、<h3>、<h4>、<h5>、<h6>、<title>
段落:<p>
链接:<a>
图像:<img>
样式:<style>
列表:`无序列表<ul>、有序列表<ol>、列表项<li>`
块:`<div>、<span>`
脚本:<script>
注释:<!--注释-->
2.2.1 css selector定位
2.2.1.1 css 选择器概念
-
css selector 定位 实际就是HTML的 Css选择器 的标签定位
-
css 定位可以支持web端的产品也可支持app端的webview场景
-
css 选择器有自己的语法规则和表达式
-
css 定位通常分为绝对定位和相对定位
# 绝对定位 $("#ember63 > td.main-link.clearfix.topic-list-data > span > span > a") # 相对定位 $("#ember63 [title='新话题']")从上可以看到相对定位更加简洁优雅,此外相对定位还有以下有点不
- 可维护性更强
- 语法更加简洁
- 解决各种复杂的定位场景
2.2.1.2 CSS基础语法
使用css相对定位,需要使用的对应的基础语法,使用基础语法可以使用chrome自带的console 进行调试判断
调试方法
在浏览器(如:Chrome) 上,按F12或者鼠标右键检查 ,进入console,
输入 $("css表达式")
或者 $$("css表达式")
回车后查看是否定位到准确的结果
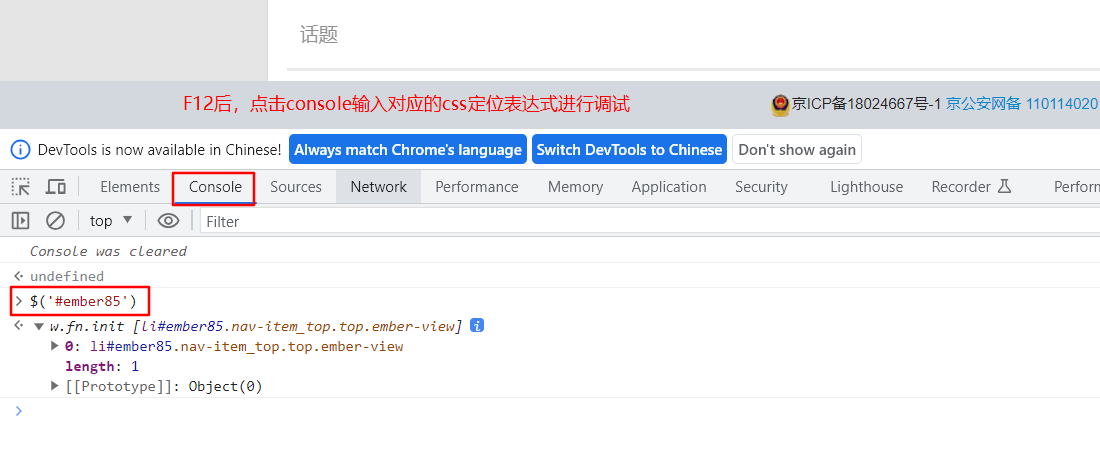
css基础语法
css 可以定位html 元素中的标签、id、类、以及其他属性进行定位,详细介绍如下
**PS注意:**对于class 属性,如果属性值有空格 ,类似这样的class="nav-item_top top ember-view"
其中的空格 并不是字符串,而是作为分隔符,表示class 有多个属性值,定位时选取一个不对导致的重复的属性值即可(其他属性对应的属性值是唯一的)
| 类型 | 表达式 | 浏览器console中的写法 | 示例 |
|---|---|---|---|
| 标签 | 标签名 | $(‘标签名’) | $(‘li’) |
| 类 | .class属性值 | $(‘.类的值’) | $(‘.nav-item_top’) |
| ID | #id属性值 | $(‘#id属性值’) | $(‘#ember85’) |
| 属性 | [属性名=‘属性值’] | ( " [ 属性名 = ′ 属性 值 ′ ] " ) 或者 < b r > ("[属性名='属性值']")或者<br> ("[属性名=′属性值′]")或者<br>(‘[属性名=“属性值”]’) | $(“[title=‘过去一年、一个月、一周或一天中最活跃的话题’]”) |
示例对应的html结构:

关系定位
| 类型 | 格式 | 说明 | 浏览器console中的写法 |
|---|---|---|---|
| 父子 | 元素>元素 | $(‘#s_kw_wrap>input’) | |
| 后代 | 元素 元素 | 节点子节点及子节点的所有子节点 | $(‘#form input’) |
| 并集(了解) | 元素,元素 | 只要有一个元素存在 就返回定位结果 | $(‘.bg,.s_ipt_wr,.new-pmd,.quickdelete-wrap’) |
| 邻近兄弟(了解即可) | 元素**+**元素 | 元素在同一个父节点下,且相邻 | $(‘.soutu-btn+input’) |
| 兄弟(了解即可) | 元素1~元素2 | 元素在同一个父节点下 | $(‘.soutubtni’) |
示例:

以下为输入chrome console的语法:
- 父子关系——定位节点1下的子节点2:
$('#ember206>#ember208') - 后代关系——定位节点1的后代节点4:
$('[id="ember206"] [title="有新帖子的话题"]')(PS: id属性也是属性的一种,因此也可使用属性的语法) - 临近兄弟——定位节点2的临近兄弟节点3:
$('#ember208+[id="navigation-bar"]') - 兄弟——定位节点4的兄弟节点6:
$('#ember213~#ember216') - 并集关系——定位节点4和节点6 :
$('#ember213,#ember216'),只要能知道到其中一个就返回结果
css 顺序关系
| 类型 | 格式 | jiei | 浏览器console中的写法 |
|---|---|---|---|
| 父子关系+顺序 | 父->子:nth-child**(n)** | $(‘#form>input:nth-child(2)’) | |
| 父子关系+标签类型+顺序 | 父->子:nth-of-type**(n)** | $(‘#form>input:nth-of-type(1)’) |
示例:
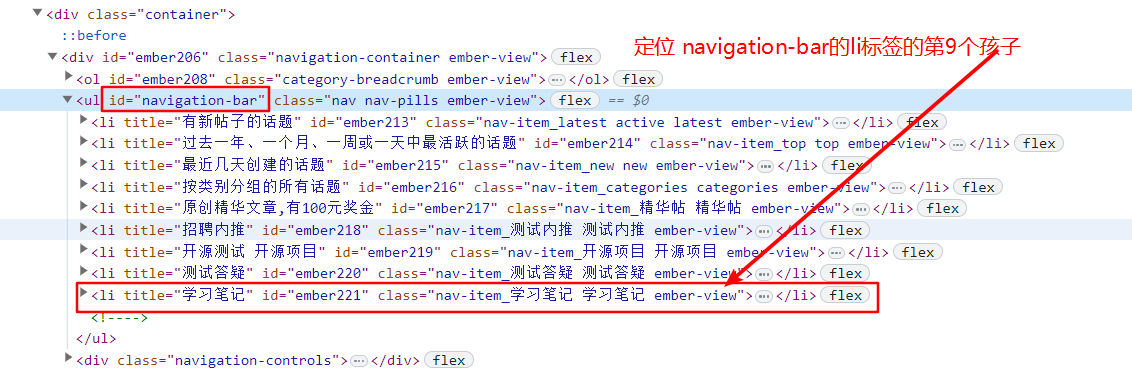
- 定位 navigation-bar的第9个孩子:
$('[id="navigation-bar"]>li:nth-child(9)')
当父节点下的子节点 类型不一样,又想找某个类型下的第几个元素时,则可使用 第二种 即:$('[id="navigation-bar"]>li:nth-child(9)') 表示 定位 navigation-bar节点下的 li标签中的第9个
2.2.2 XPATH定位
2.2.2.1 xpath 基本概念
XPath (XML Path Language) 是一门在 XML 文档中查找信息的语言,可用来在 XML 文档中对元素和属性进行遍历;可以使用路径表达式来选取 XML 文档中的节点或者节点集;也可以在web或者app自动化的测试中使用xpath 进行元素定位。
2.2.2.2 XPTAH基础语法
和css定位一样,xpath 定位也分为绝对定位和相对定位,绝对定位需要根节点开始一层一层的向下定位,因此非常的臃肿且存在一旦前端修改了中间的某一个节点的依赖,原来的表达式就会失效,因此自动化中最后 使用简洁 优雅的相对定位。
XPATH相对定位的优点:
- 可维护性更强
- 语法更加简洁
- 相比于css可以支持更多的方式
调试方法
- 浏览器-console
$x("xpath表达式")
- 浏览器-elements
- ctrl+f 输入xpath或者css
基础语法
| 表达式 | 结果 | |
|---|---|---|
| / | 从根节点的子元素选取,绝对定位的开头 | 整个页面: $x("/") |
| // | 从符合条件的元素开始,不考虑他们的位置,相对定位常用开头 | |
| * | 通配符 | |
| nodename | 选取此节点的所有子节点 | |
| … | 选取当前节点的父节点 | |
| @ | 选取属性 | $x(‘//*[@属性名=“属性值”]’) |
示例 输入Chrome console的命令:
# 页面中的所有的子元素
$x("/*")
# 整个页面中的所有元素
$x("//*")
# 查找页面上面所有的div标签节点
$x("//div")
# 查找id属性为site-logo的节点
$x('//*[@id="site-logo"]')
# 查找节点的父节点
$x('//*[@id="site-logo"]/..')
-
xpath通过索引直接获取对应元素
# 获取此节点下的所有的li元素 $x("//*[@id='ember21']//li")# 获取此节点下【所有的节点的】第一个li元素 $x("//*[@id='ember21']//li[1]")
2.2.2.3 xpath 高级用法
-
[last()]: 选取最后一个# 选取最后一个input标签 //input[last()] -
[@属性名='属性值' and @属性名='属性值']: 与关系# 选取属性name的值为passward并且属性pwd的值为123456的input标签 //input[@name='passward' and @pwd='123456'] -
[@属性名='属性值' or @属性名='属性值']: 或关系# 选取属性name的值为passward或属性pwd的值为123456的input标签 //input[@name='passward' or @pwd='123456'] -
[text()='文本信息']: 根据文本信息定位# 选取所有文本信息为'霍格沃兹测试开发'的元素 //*[text()='霍格沃兹测试开发'] -
[contains(text(),'文本信息')]: 根据文本信息包含定位# 选取所有文本信息包'霍格沃兹'的元素 //*[contains(text(),'霍格沃兹')]
2.2.3 显示等待的高级应用
原理解析
由于页面元素加载是异步加载过程,通常html会先加载完成,js、css其后,所以可能导致进行交互操作时失败,因此可以利用selenium中的**WebDriverWait** 类来实现等待,直到指定条件生效 或者 超出设定的时间。
显示等待的原理:
- 在代码中定义等待一定条件发生后再进一步执行代码(解决元素已加载但js等交互未完全加载的问题)
- 在最长等待时间内循环执行结束条件的函数
- WebDriverWait(driver 实例, 最长等待时间, 轮询时间).until(结束条件函数)
WebDriverWait类的结构:
在WebDriverWait 类中一个属性POLL_FREQUENCY,表示轮询的间隔;还有3个函数,分别是 构造函数init、直到条件成立函数until 和 直到条件不成立函数unitil_not。
在构造函数中 需要传入 webdriver的实例化对象driver、超时时间timeout、以及轮询间隔poll_frequency,默认轮询间隔为0.5秒。
其中until 方法中需要传入一个 函数对象,以及提示信息message(非必填)
其中until的源码如下(额外自己添加一点的注释):
def until(self, method, message: str = ""):screen = Nonestacktrace = None# 结束时间 = 当前的时间(单调时间的秒数) + 构造函数初始化时传入的超时时间end_time = time.monotonic() + self._timeout# 设置死循环while True:try:# 调用 传入的函数名,该函数的参数是 driver的实例化对象,并将返回值赋值给valuevalue = method(self._driver)# 当为True时 return 函数结束if value:return value# 捕获忽略传入的异常except self._ignored_exceptions as exc:screen = getattr(exc, "screen", None)stacktrace = getattr(exc, "stacktrace", None)# 等待一个轮询间隔time.sleep(self._poll)# 当超出 结束时间时 跳出循环if time.monotonic() > end_time:break# 抛出超时异常raise TimeoutException(message, screen, stacktrace)

官方分装类 expected_conditions
官网说明: https://www.selenium.dev/selenium/docs/api/py/webdriver_support/selenium.webdriver.support.expected_conditions.html
官方为显示等待封装了许多的条件函数,在expected_conditions类中有以下常用的条件方法:
常见 expected_conditions
| 类型 | 示例方法 | 说明 |
|---|---|---|
| element | element_to_be_clickable() (常用)visibility_of_element_located() | 针对于元素,比如判断元素是否可以点击,或者元素是否可见 |
| url | url_contains() | 针对于url |
| title | title_is() | 针对于标题 |
| frame | frame_to_be_available_and_switch_to_it(locator) | 针对于frame |
| alert | alert_is_present() | 针对于弹窗 |
自定义显示等待条件
部分按钮处于可点击状态,但是有时候点击一次元素未生效需要多次点击元素,因此需要设计一个条件函数,在点击后返回需要的一个新的元素,当点击一次时,无法找到元素会返回为None,此时,until方法会在等待时间内,重复执行该函数。
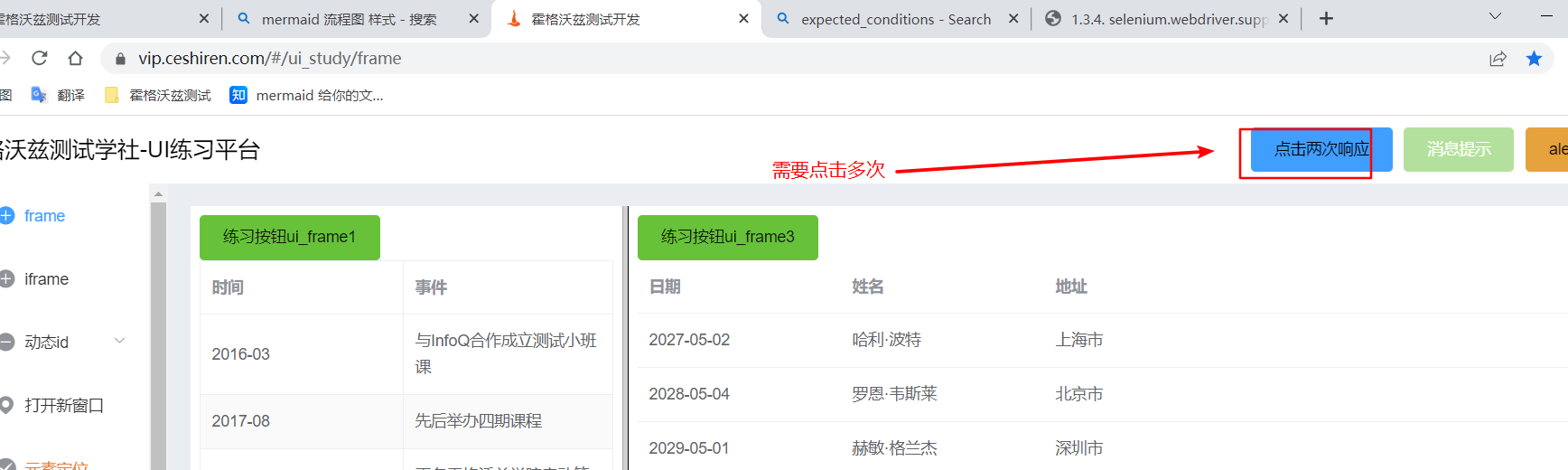
from time import sleepfrom selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.wait import WebDriverWaitdriver = webdriver.Chrome()
driver.get('https://vip.ceshiren.com/#/ui_study/frame')
driver.maximize_window()def multi_clickable(target_ele, next_ele):"""点击元素直到出现预期的新元素点击目标元素,返回点击后出现的新元素,没有则返回None:param target_ele: 需要点击的目标元素,如:(By.ID, "primary_btn"),传入的是一个元组:param next_ele: 点击目标元素的后需要返回的新元素::return:"""def _predicate(driver):# 点击目标元素driver.find_element(*target_ele).click()# 返回期待的下一个元素,不存在时返回Nonereturn driver.find_element(*next_ele)return _predicateWebDriverWait(driver, 10).until(multi_clickable((By.ID, "primary_btn"),(By.XPATH,'//*[text()="该弹框点击两次后才会弹出"]'))
)
2.2.4高级控件的交互方法
介绍
在进行selenium 操作时,有些场景需要模拟键鼠操作才可以实现,比如 复制粘贴、元素的拖拽等;selenium中提供ActionChains来实现相关的操作
| 使用场景 | 对应事件 |
|---|---|
| 复制粘贴 | 键盘事件 |
| 拖动元素到某个位置 | 鼠标事件 |
| 鼠标悬停 | 鼠标事件 |
| 滚动到某个元素 | 滚动事件 |
| 使用触控笔点击 | 触控笔事件(了解即可) |
ActionChains基本用法
在进行网页交互通常还有右击、双击、鼠标悬停、拖拽、ctrl+c复制以及粘贴,大写输入等控制,在selenium中提供了ActionChains类来实现各种键鼠操作。
当我们调用ActionChains的方法时,不会立即执行,而是会将所有的操作按顺序存放在一个队列里,当调用perform()方法时,队列中的事件才会依次执行。
使用的基本语法如下:
实例化化 ActionChains类: ActionChains(driver) ,其中driver为webdriver
# 实例化时传入webdriver,调用perform()后操作才会执行
ActionChains(self.driver).操作.perform()
键盘操作
-
按下/释放某个键位
按下shift 键
key_down(Keys.SHIFT, ele),其中ele 为定位的元素,必传释放shift建
key_up(Keys.SHIFT,el),其中ele 为定位的元素,必传 -
按键输入字符:
输入 selenium
send_keys("selenium") -
输入回车
-
直接输入回车: 元素.send_keys(Keys.ENTER)
-
使用ActionChains: key_down(Keys.ENTER)
-
-
复制、粘贴、剪切—组合键位
上诉三个设计多个案件,其中需要用到的ctr 可以通过 key_down()方法进行控制,c、v、x 可以通过send_keys()输入需要的按键,需要注意的时,需要考虑系统的兼容
- 多系统兼容
- mac 的复制按钮为 command +c
- windows 的复制按钮为 ctrl +c
示例:在输入输入字符后,全选剪切,再进行粘贴
# 复制粘贴 win 和 mac 有所不同,因此区分下 cmd_ctrl = Keys.COMMAND if sys.platform == 'darwin' else Keys.CONTROL # 1.在输入框 先输入 chrome 2.ctr+a 全选 3.ctr+x 剪切 4. ctr+v 粘贴(3次)5.释放ctrl键 ActionChains(driver).send_keys('chrome').\key_down(cmd_ctrl,el_search_input).\send_keys('axvvv').\key_up(cmd_ctrl,el_search_input).perform()源码:https://gitee.com/sailor233/seleniumDemo/blob/dev/try/keyboard2-copy-.py
- 多系统兼容
鼠标操作
官网:https://www.selenium.dev/documentation/webdriver/actions_api/mouse/
- 双击:
double_click(元素对象) - 拖动元素:
drag_and_drop(起始元素对象, 结束元素对象) - 指定位置悬浮:
move_to_element(元素对象) - 鼠标右键:
context_click(元素对象) - 鼠标滚轮滚动操作:(selenium 版本需要在 4.2 之后)
- 官网:https://www.selenium.dev/documentation/webdriver/actions_api/wheel/
- 滚动到元素:
scroll_to_element(WebElement对象) - 根据坐标滚动:
scroll_by_amount(横坐标, 纵坐标)
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2023/7/4 23:00
# @Author : sailor233
# @File : ActionChains_MouseAction.py
# @Software: PyCharm
# @Des : ActionChains的鼠标操作
import timefrom selenium import webdriver
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import Bydriver = webdriver.Chrome()
driver.implicitly_wait(5)
driver.get('https://vip.ceshiren.com/#/ui_study/mouseover')# 双击元素
ele_double = driver.find_element(By.ID,'primary_btn')
ActionChains(driver).double_click(ele_double).perform()
time.sleep(1)
# 点击确定
driver.find_element(By.CSS_SELECTOR,'.el-message-box__btns>button').click()
time.sleep(2)# 鼠标移入悬浮
moveToEle = driver.find_element(By.CSS_SELECTOR,'[id="mouseover"]>button')
ActionChains(driver).move_to_element(moveToEle).perform()
time.sleep(1)# 鼠标右键
driver.get('https://vip.ceshiren.com/#/ui_study/clicks')
right_ele = driver.find_element(By.CSS_SELECTOR,'[id="rightClick"]>button')
ActionChains(driver).context_click(right_ele).perform()
time.sleep(2)# 元素拖拽
driver.get('https://vip.ceshiren.com/#/ui_study/action_chains')
start_ele = driver.find_element(By.ID,'item1')
end_ele = driver.find_element(By.ID,'item3')
ActionChains(driver).drag_and_drop(start_ele,end_ele).perform()
time.sleep(3)
2.25 网页多窗口和Frame的处理
多窗口处理
在网页点击链接时,会打开新的窗口,如果我们想要在新的窗口进行操作,就需要先切换窗口。每个窗口都有一个句柄作为唯一标识,因此我们可以通过切换句柄来实现多个页面之前的灵活操作。
-
多窗口的处理流程
-
先获取当前窗口的窗口句柄(
dirver.current_window_handle),返回句柄标识,一个字符串如:
B351ACAA077B689431FA53199D88D0C0 -
获取所有的窗口句柄(
driver.window_handles),返回一个列表,包含所有的句柄标识如:
['B351ACAA077B689431FA53199D88D0C0', 'CB85E316C47BC4C8B3A2FE51F0C0D736'] -
判断当前窗口是否为想操作的窗口,如果是则对窗口进行操作;否则切换窗口
driver.switch_to.window(all_windows[0])
-
-
案例
- 打开百度页面
- 点击登录
- 弹框点击
立即注册输入用户名和手机号 - 返回刚才的登录页面,输入用户名、密码、点击登录
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2023/7/6 22:08
# @Author : sailor233
# @File : switch_window.py
# @Software: PyCharm
# @Des : selenium 多窗口切换操作
from time import sleepfrom selenium import webdriver
from selenium.webdriver.common.by import Bydriver = webdriver.Chrome()
driver.implicitly_wait(5)
driver.get('https://wwww.baidu.com')driver.find_element(By.LINK_TEXT,'登录').click()
# 查看当前句柄标识
print(driver.current_window_handle)
driver.find_element(By.LINK_TEXT,'立即注册').click()
# 获取所有窗口的句柄标识
all_windows = driver.window_handles
print('all_windows:%s' %all_windows)
# 切换到新的窗口
driver.switch_to.window(all_windows[-1])
# 输入用户名、手机号
driver.find_element(By.ID,'TANGRAM__PSP_4__userName').send_keys('zhangsan')
driver.find_element(By.ID,'TANGRAM__PSP_4__phone').send_keys('13594531258')# 切换会之前的窗口
driver.switch_to.window(all_windows[0])
# 输入 用户名
driver.find_element(By.ID,'TANGRAM__PSP_11__userName').send_keys('lisi')
# 输入密码
driver.find_element(By.ID,'TANGRAM__PSP_11__password').send_keys('adasda')
# 点击登录
driver.find_element(By.ID,'TANGRAM__PSP_11__submit').click()
sleep(5)
Frame的处理
- 介绍
在web页面中,html可以使用frame框架,在一个主页面中,利用frame创建不同的框架,从而实现在一个web页面呈现多个页面,每个frame框架的内容可以有自己的布局方式。因此有时定位不到元素可能就是因为元素,那么可能元素在ifrme中,可以查看元素是否被包含与frame标签中。
w3c frame框架demo:https://www.w3school.com.cn/tiy/t.asp?f=eg_html_frame_cols
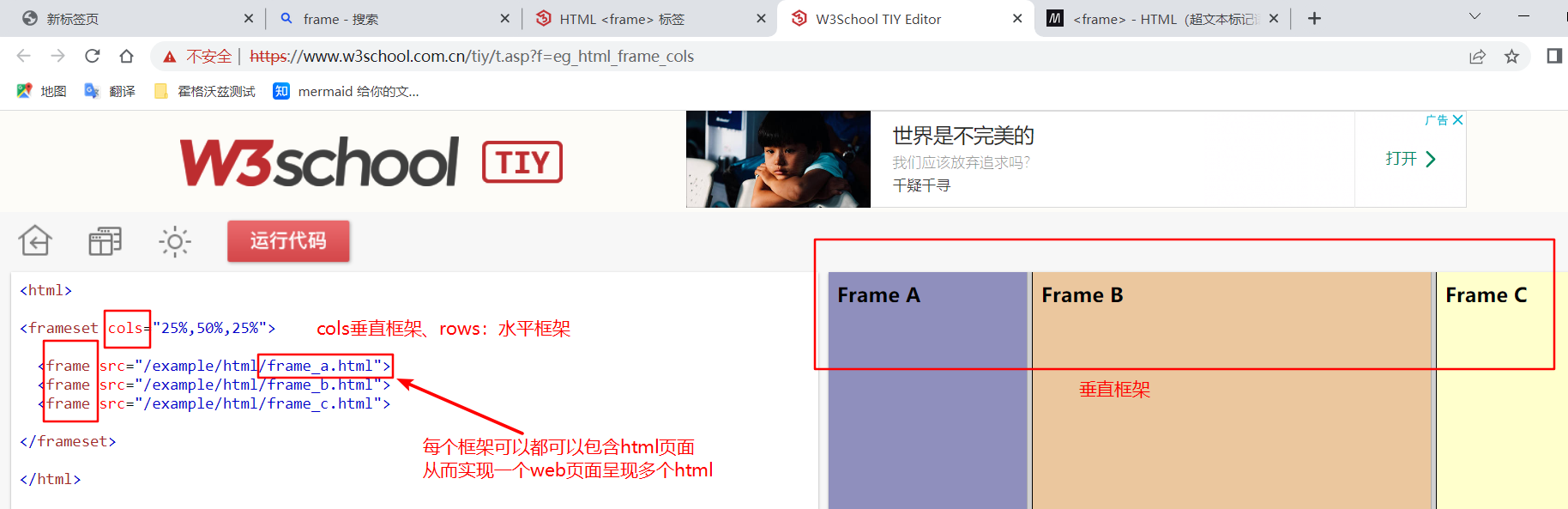
其中Frame分为3类:
- frame标签包含 frameset、frame、iframe三种
- 其中frameset与其他标签一样,可以使用id、name等selenium中任意支持的方式定位
- frame和iframe在selenium中有专门的定位方法
-
多Frame切换
- 根据frame的id或者index 切换:
driver.switch_to.frame() - 切换到默认frame:
driver.swutch_to.default_conten() - 切换到父级frame(嵌套frame的情况):
driver.swicth_to.parent_frame()
举例:拖动元素,其中两个元素在iframe中
- 根据frame的id或者index 切换:
演示环境:https://www.runoob.com/try/try.php?filename=jqueryui-api-droppable
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2023/7/10 23:28
# @Author : sailor233
# @File : frame.py
# @Software: PyCharm
# @Des : 演示地址https://www.runoob.com/try/try.php?filename=jqueryui-api-droppable
from time import sleepfrom selenium import webdriver
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import Bydriver = webdriver.Chrome()
driver.implicitly_wait(5)
driver.get('https://www.runoob.com/try/try.php?filename=jqueryui-api-droppable')
# 切换到 iframe框架内
driver.switch_to.frame('iframeResult')
ele_drag = driver.find_element(By.XPATH,'//*[text()="请拖拽我!"]')
ele_drop = driver.find_element(By.XPATH,'//*[text()="请放置到这里!"]')
ActionChains(driver).drag_and_drop(ele_drag,ele_drop).perform()
# 切换会主框架
driver.switch_to.default_content()
sleep(5)
文件上传以及弹窗处理
文件上传
如果页面使用web页面使用 input标签实现文件上传,可以直接使用send_keys(文件绝对地址)进行上传文件
步骤如下:
- 找到上传按钮:
el = driver.find_element(By.CSS_SELECTOR,'.upload-pic') - 使用上传按钮上传图片:
el.send_keys(jpg_path)
ps: 也可以直接合并为一步
举例:使用百度首页,点击图片上传功能,上传图片

#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2023/7/11 22:08
# @Author : sailor233
# @File : file_upload.py
# @Software: PyCharm
# @Des : 文件上传处理
import os
import timefrom selenium import webdriver
from selenium.webdriver.common.by import Bydriver = webdriver.Chrome()
driver.implicitly_wait(5)
driver.get('https://www.baidu.com')
# 点击 相机按钮
driver.find_element(By.CSS_SELECTOR,'.soutu-btn').click()
# 点击 选择文件 按钮
el = driver.find_element(By.CSS_SELECTOR,'.upload-pic')# 获取文件的绝对路径
jpg_path = os.path.abspath('test.jpg')
# 上传文件
el.send_keys(jpg_path)time.sleep(10)
弹窗处理
在页面操作时,有时候会出现由js生成的弹窗,如alert、confirm以及prompt;在selenium中可以使用 `switch_to.alert 进行定位。
常用方法如下:
- 切换到弹框:
switch_to.alert - 获取弹窗中的文本信息:
text - 接受现有警告框:
accept() - 解散警告框:
dismiss() - 发送文本到警告框:
send_keys()
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2023/7/11 22:55
# @Author : sailor233
# @File : alert.py
# @Software: PyCharm
# @Des :
from time import sleepfrom selenium import webdriver
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import Bydriver = webdriver.Chrome()
driver.implicitly_wait(5)
driver.get('https://www.runoob.com/try/try.php?filename=jqueryui-api-droppable')
# 切换到 iframe框架内
driver.switch_to.frame('iframeResult')
ele_drag = driver.find_element(By.XPATH,'//*[text()="请拖拽我!"]')
ele_drop = driver.find_element(By.XPATH,'//*[text()="请放置到这里!"]')
ActionChains(driver).drag_and_drop(ele_drag,ele_drop).perform()# 切换到弹窗并点击确认
driver.switch_to.alert.accept()
sleep(5)
关键数据记录
介绍
为了后续排查错误,需要将自动化执行过程中的关键数据记录下来,关键数据执行日志、执行行为的截图、页面源码,以下分别对三种数据的功能进行介绍
-
代码的执行日志
- 记录代码的执行记录,方便复现场景
- 可以作为bug依据
- 用法:在关键位置使用 logging库打印日志
-
代码执行的截图
- 断言失败或成功截图
- 异常截图达到丰富报告的作用
- 可以作为bug依据
- 用法:
driver.save_screenshot('./images/search1.png')
-
page source(页面源代码)
self.driver.page_source-
协助排查报错时元素当时是否存在页面上
-
用法:
# 在报错行前面添加保存page_source的操作 with open("record.html", "w", encoding="u8") as f:f.write(self.driver.page_source)
-
示范
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2023/7/12 22:21
# @Author : sailor233
# @File : reord.py
# @Software: PyCharm
# @Des :
# 日志与脚本结合
from selenium import webdriver
from selenium.webdriver.common.by import Byfrom logUtil import loggerclass TestDataRecord:def setup_class(self):self.driver = webdriver.Chrome()self.driver.implicitly_wait(3)def teardown_class(self):self.driver.quit()def test_log_data_record(self):# 实例化self.driversearch_content = "霍格沃兹测试开发学社"# 打开百度首页self.driver.get("https://www.sogou.com/")logger.debug("打开搜狗首页")# 输入霍格沃兹测试学院self.driver.find_element(By.CSS_SELECTOR, "#query"). \send_keys(search_content)logger.debug(f"搜索的内容为{search_content}")# 点击搜索self.driver.find_element(By.CSS_SELECTOR, "#stb").click()# 搜索结果search_res = self.driver.find_element(By.CSS_SELECTOR, "em")# 保存搜索结构截图self.driver.save_screenshot('searchResult.jpg')# 保存页面源码with open("record.html", "w", encoding="u8") as f:f.write(self.driver.page_source)logger.info(f"搜索结果为{search_res.text}")assert search_res.text == search_content
日志模块:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2023/7/12 22:20
# @Author : sailor233
# @File : logUtil.py
# @Software: PyCharm
# @Des :
# 日志配置
import logging
# 创建logger实例
logger = logging.getLogger('simple_example')
# 设置日志级别
logger.setLevel(logging.DEBUG)
# 流处理器
ch = logging.StreamHandler()
ch.setLevel(logging.DEBUG)
# 日志打印格式
formatter = logging.Formatter\
('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
# 添加格式配置
ch.setFormatter(formatter)
# 添加日志配置
logger.addHandler(ch)
练习项目1-litemall商城管理后台
在litemall管理商城后台 对商品类目进行添加 和删除
产品信息:
- 地址:http://litemall.hogwarts.ceshiren.com/#/dashboard
- 使用账户,用户名: manage 密码: manage123
实现的用例场景:
| 用例标题 | 前提条件 | 执行步骤 | 预期结果 |
|---|---|---|---|
| 添加商品 | 1. 登录并进入用户管理后台 2. 登录账号有商品管理的权限 | 1. 点击增加 2. 输入商品名称和商品编号 3. 点击 上架 | 1. 跳转商品列表 2. 新增在第一行行,新增成功 |
| 删除商品 | 1. 进入用户管理后台 2. 商品列表里面有已存在的商品(新增) | 1. 点击删除按钮 | 1. 是否有删除成功提示 2. 被删除商品不在商品类目列表展示 |
脚本编写思路:
- 编写前置后置操作,如drvier的初始化、登录平台等
- 实现基本功能
- 代码优化,将强制等待换为隐式等待
- 完善细节:日志、报告、截图
前置后置操作
前置操作setup_class中,实现浏览器的打开、隐式等待
后置操作teardown_class 中,实现浏览器的关闭
class TestLiteMall:def setup_class(self):self.driver = webdriver.Chrome() # 初始化driver,使用chrome浏览器self.driver.maximize_window() # 最大化浏览器窗口self.driver.implicitly_wait(5) # 全局设置隐式等待5sdef teardown_class(self):self.driver.quit() # 退出浏览器
实现基本功能:
基本功能分为:登录、新增商品、删除商品
登录功能
def login(self):"""实现登录功能:return:"""# 由于用户名 和 密码有原本文本,需要先清除self.driver.find_element(By.NAME, 'username').clear()self.driver.find_element(By.NAME, 'username').send_keys('manage')self.driver.find_element(By.NAME, 'password').clear()self.driver.find_element(By.NAME, 'password').send_keys('manage123')# 点击登录按钮self.driver.find_element(By.CSS_SELECTOR, 'button').click()
新增商品
def add_merchandise(self, merchandise_id, merchandise_name):"""添加商品:param merchandise_id:商品ID:param merchandise_name:商品名称:return: 无"""logger.info('点击商品管理')self.driver.find_element(By.XPATH, '//*[text()="商品管理"]').click()logger.info('点金商品列表')self.driver.find_element(By.XPATH, '//*[text()="商品列表"]').click()logger.info('点击点击按钮')self.driver.find_element(By.CSS_SELECTOR, '.filter-container>button:nth-of-type(2)').click()logger.info('输入商品编号')self.driver.find_element(By.XPATH, '//*[text()="商品编号"]/../div/div/input').send_keys(merchandise_id)logger.info('输入商品名称')self.driver.find_element(By.XPATH, '//*[text()="商品名称"]/../div/div/input').send_keys(merchandise_name)logger.info('点击上架')self.driver.find_element(By.CSS_SELECTOR, '.op-container>button:nth-child(2)').click()
删除商品
def delet_merchandise(self, merchandise_id='1439956'):"""通过商品id删除商品:param merchandise_id:商品对应的id:return:"""logger.info('点击商品管理')self.driver.find_element(By.XPATH, '//*[text()="商品管理"]').click()logger.info('点金商品列表')self.driver.find_element(By.XPATH, '//*[text()="商品列表"]').click()logger.info(f'通过商品id:{merchandise_id},定位到对应删除按钮后 点击删除')self.driver.find_element(By.XPATH, f'//*[text()="{merchandise_id}"]/../../td[last()]/div/button[2]').click()
新增商品测试用例
@pytest.mark.parametrize('merchandise_id,merchandise_name', test_add_data)
def test_add_merchandise(self, merchandise_id, merchandise_name):logger.info(f'测试添加商品:{merchandise_id},{merchandise_name}')self.add_merchandise(merchandise_id, merchandise_name)logger.info('断言出现提示信息:创建成功')WebDriverWait(self.driver, 3).until(expected_conditions.visibility_of_element_located((By.XPATH, '//p[text()="创建成功"]')))assert self.driver.find_element(By.XPATH, '//p[text()="创建成功"]').text == '创建成功'
2.3 高级
2.3.1 浏览器复用-托管
-
介绍
浏览器复用指的是 selenium代码执行调用的浏览器与我们当前使用的浏览器是一个,而不是从新打开一个由selenium控制打开的浏览器;这样实现便于自动测试过程中的人为介入,从而提高测试效率。
如果seleniu控制打开时一个新的chrome,不会携带任何cookie信息等,不利用人工介入如扫码登陆、调式等,具体场景举例:
- 当运行 selenium 自动化时,要求已经登录才能才做。这个时候我们可以提前登录,运行脚本的时候复用已经打开的浏览器。
- 当调试了某个步骤很多的测试用例,前面N-1步已经成功,只需调试第N步。如果从头开始运行脚本,耗时过多,这时我们可以直接复用浏览器手动操作第N不进行调试。
-
配置步骤
-
首先退出当前所有的谷歌浏览器,其中windows还需打开任务管理器 查看chrome进程是否关闭
-
配置环境变量,将chrome浏览器exe文件所在位置放到环境变量path中
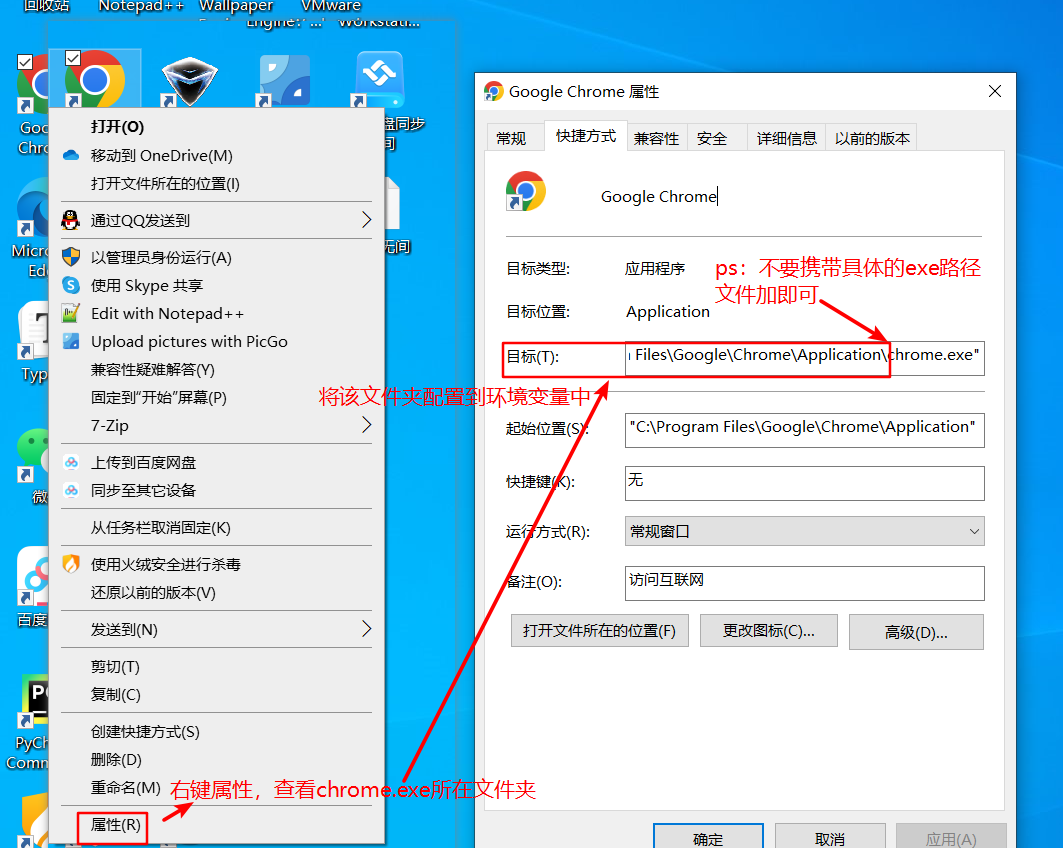
-
验证是否配置成功
-
重新打开cmd命令输入以下命令,打开浏览器
chrome --remote-debugging-port=9222 -
再打开的浏览器输入
localhost:9222会打开一个空白页面或者一个简单页面
-
-
-
代码中使用
#!/usr/bin/env python # -*- coding: utf-8 -*- # @Time : 2023/7/25 22:25 # @Author : sailor233 # @File : chrome_remote.py # @Software: PyCharm # @Des : from selenium import webdriver from selenium.webdriver.chrome.options import Optionsopt = Options() # 地址要和cmd启动的一致chrome一致 opt.debugger_address = 'localhost:9222' # 实例化driver传入 启动的chrome地址 driver = webdriver.Chrome(options=opt) # 使用已打开的chrome 打开百度,而不是重新启动一个chrome浏览器 driver.get('http://www.baidu.com')
2.3.2 cookie复用
-
cookie是什么
Cookie是保存在计算机上的一种文件。当我们使用计算机浏览网页时,服务器会生成一个证书并将其返回给我们的计算机。这个证书是cookie。一般来说,cookie是服务器写给客户端的文件,也可以称为浏览器缓存,复用已有的cookie,可以直接登录,不需要重新进行登录认证;对于部分只能扫码登录的应用,可以先登录后,保存cookie,后续直接使用cookie进行访问。
-
为什么需要复用cookie
- 复用浏览器仍然在每次用例开始都需要人为介入
- 若用例需要经常执行,复用浏览器则不是一个好的选择
- 大部分cookie的时效性都很长,扫一次可以使用多次
-
复用cookie的思路
- 打开浏览器,扫码登录
- 确保登录之后(重点!!!),获取cookies
- 检查本地文件是否已经获取成功
- 再次打开浏览器,通过cookie直接进入主页
-
代码实现
- 获取cookie:
driver.get_cookies() - 添加cookie:
driver.add_cookie(cookie)
- 获取cookie:
-
demo 企业微信登录cookie复用
#!/usr/bin/env python # -*- coding: utf-8 -*- # @Time : 2023/7/26 21:58 # @Author : sailor233 # @File : test_cookie.py # @Software: PyCharm # @Des : from time import sleepimport yaml from selenium import webdriver def test_getcookie():driver = webdriver.Chrome()driver.get('https://work.weixin.qq.com/wework_admin/loginpage_wx?from=myhome')# 获取cookie# get_cookie()add_cookies(driver)driver.refresh()sleep(5)def get_cookie(driver):# 获取cookiescookies = driver.get_cookies()# 将获取到的cookie保存到文件中with open('cookie.yaml', 'w') as f:yaml.safe_dump(cookies, f)def add_cookies(driver):cookies = yaml.safe_load(open('cookie.yaml'))for cookie in cookies:driver.add_cookie(cookie) -
常见问题
- 获取cookie的时候,即执行代码获取cookie时,一定要确保已经登录
- 植入cookie之后需要进入登录页面,刷新验证是否自动登录成功。
2.3.3 Page Object思想
传统的UI自动化是线性脚本,元素操作、断言等步骤混合在一起,当UI存在变换时改动非常麻烦,工作量很大,也无法清晰的表达出业务用例的场景。
-
PO思想简介
把一个具体的页面转换成编程语言当中的一个类,页面特性转化成对象属性,页面操作转换成对象方法。
-
PO建模原则
- 字段意义
- 不要暴露页面内的所有元素给外部
- 不需要建模UI内的所有元素,元素很多无法重复建模,选择重点元素
- 方法意义
- 用公共方法代表UI所提供的的功能
- 方法应该返回其他PageObject的或者返回用于断言的数据
- 同样的行为不同结果可以建模不同的方法
- 不要在方法内加断言
- 字段意义
以测试登录雪球测试为例:
- 之前的线性脚本:
class TestSearch:def test_search(self):# 初始化浏览器self.driver = webdriver.Chrome()self.driver.get("https://xueqiu.com/")self.driver.implicitly_wait(3)# 输入搜索关键词self.driver.find_element(By.NAME, "q").send_keys("阿里巴巴-SW")# 点击搜索按钮self.driver.find_element(By.CSS_SELECTOR, "i.search").click()# 获取搜索结果name = self.driver.find_element(By.XPATH, "//table//strong").text# 断言assert name == "阿里巴巴-SW"
-
使用PO思想设计测试脚本
-
先封装搜索页面
#!/usr/bin/env python # -*- coding: utf-8 -*- # @File : search_page.py from selenium import webdriver from selenium.webdriver.common.by import By class SearchPage:__INPUT_SEARCH = (By.NAME, "q")__BUTTON_SEARCH = (By.CSS_SELECTOR, "i.search")__SPAN_STOCK = (By.XPATH, "//table//strong")def __init__(self):self.driver = webdriver.Chrome()self.driver.implicitly_wait(3)self.driver.get("https://xueqiu.com/")def search_stock(self, stock_name: str):self.driver.find_element(*self.__INPUT_SEARCH).send_keys(stock_name)self.driver.find_element(*self.__BUTTON_SEARCH).click()name = self.driver.find_element(By.XPATH, "//table//strong").textreturn name -
测试用例
from search_page import SearchPage class TestSearch:def test_search(self):text = SearchPage().search_stock("阿里巴巴-SW")# 断言assert "阿里巴巴-SW" == text
-
2.3.4 异常记录关键信息
常规的记录方法
一般记录方式使用try,except 进行记录
import timeimport allure
from selenium import webdriver
from selenium.webdriver.common.by import By# 问题1: 异常处理会影响用例本身的结果
# 解决方案: 需要在异常处理后使用raise 再把异常抛出去# 问题2:异常处理的逻辑与业务无关,添加后显得非常冗余,需要进行解耦
# 解决方案: 使用装饰器进行异常逻辑的处理class TestBaidu:def test(self):driver = webdriver.Chrome()driver.get('http://www.baidu.com')try:# 查找一个不存在的iddriver.find_element(By.ID, 'su1')except Exception:timestamp = int(time.time())image_path = f'./images/image_{timestamp}.PNG' # 需要先创建imagse目录# 保存截图driver.save_screenshot(image_path)# 保存源码page_path = f'./page_source/page_{timestamp}.html' # 需要先创建page_source目录with open(page_path, 'w', encoding='utf-8') as f:f.write(driver.page_source)# 将截图放入allure测试报告allure.attach.file(image_path, name='picture', attachment_type=allure.attachment_type.PNG)# 将源码放入allure测试报告allure.attach.file(page_path, name='pagesoce', attachment_type=allure.attachment_type.HTML)raise Exception
使用allure命令 可以生成测试报告 并看到执行后保存的数据:
pytest --alluredir=./report
allure serve ./report

-
存在的问题
-
由于添加了异常处理,影响了用例本身的执行结果,本该是执行失败的结果测试报告中显示 Passed
解决方式: 在exception后捕获了异常并处理的最后增加语句抛出异常:
raise Exeception执行结果:
pytest --alluredir=./report、allure serve ./report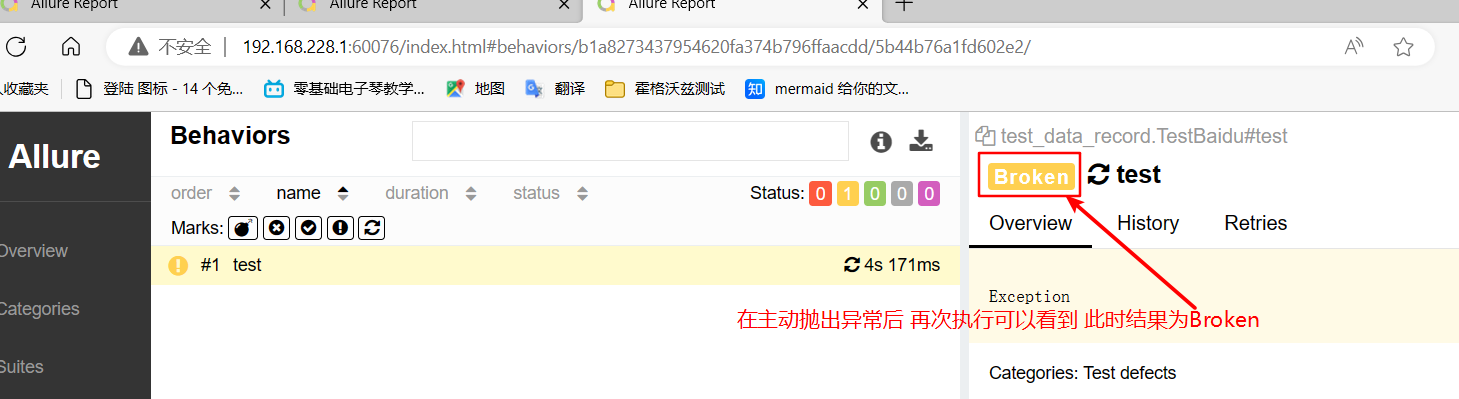
-
异常处理代码和业务无关,不能耦合否则用例
解决方法:使用装饰器,就可以不体现在源码中
-
使用装饰器记录
-
装饰器函数
# 问题3: 通driver进行截图时、获取源码时报错没有driver # 解决方案: 通过debug可以看到args[0]中存在TestBaidu的实例对象,它包含了实例属性self.driver, # 因此可以通过# args[0].driver获取drievr# 问题4:当某测试函数执行后没有返回值, # 解决方法: 执行 装饰函数时需要return def ui_exception_record(func):def wrapper(*args, **kwargs):try:# 成功后需要返回,否则无法看到返回值return func(*args, **kwargs)except Exception:# 获取被装饰方式的实例对象self# 前提条件:1.被装饰方法是一个实例方法 2.获取的变量也是实例变量即是self.driver# 根据调试 可以看到args[0]是类TestBaidu的实例对象,存在实例属性 driverdriver = args[0].driverprint('出现异常')timestamp = int(time.time())image_path = f'./images/image_{timestamp}.PNG' # 需要先创建imagse目录# 保存截图driver.save_screenshot(image_path)# 保存源码page_path = f'./page_source/page_{timestamp}.html' # 需要先创建page_source目录with open(page_path, 'w', encoding='utf-8') as f:f.write(driver.page_source)# 将截图放入allure测试报告allure.attach.file(image_path, name='picture', attachment_type=allure.attachment_type.PNG)# 将源码放入allure测试报告allure.attach.file(page_path, name='pagesoce', attachment_type=allure.attachment_type.HTML)raise Exceptionreturn wrapper- 装饰执行测试函数:
class TestBaidu:@ui_exception_recorddef test(self):self.driver = webdriver.Chrome()self.driver.get('http://www.baidu.com')self.driver.find_element(By.ID, 'su1')通过装饰器的使用,在测试函数中出现异常的处理不体现在业务逻辑中,程序变得非常优雅
UI自动化的常见项目结构
- page: 页面对象
- testcases: 测试用例
- utils: 公共工具
- log: 日志信息
相关文章:
web UI自动化介绍
文章目录 一、web UI自动化介绍1.1 执行UI自动化测试前提1.2 Selenium介绍以及知识点梳理 二、Selenium 学习2.1 基础2.1.1 环境安装与基础使用2.1.2 web浏览器控制2.1.3 常见控件的八大定位方式2.1.3.1 八大定位方式介绍2.1.3.2 NAME、ID定位2.1.3.3 css_selector定位2.1.3.4 …...

小米13Pro/13Ultra刷面具ROOT后激活LSPosed框架微X模块详细教程
喜欢买小米手机,很多是因为小米手机的开放,支持root权限,而ROOT对普通用户来说更多的是刷入DIY模块功能,今天ROM乐园小编就教大家如何使用面具ROOT,实现大家日常情况下非常依赖的微X模块功能,体验微X模块的…...

文盘Rust -- 给程序加个日志 | 京东云技术团队
日志是应用程序的重要组成部分。无论是服务端程序还是客户端程序都需要日志做为错误输出或者业务记录。在这篇文章中,我们结合log4rs聊聊rust 程序中如何使用日志。 log4rs类似java生态中的log4j,使用方式也很相似 log4rs中的基本概念 log4rs 的功能组件也由 appe…...
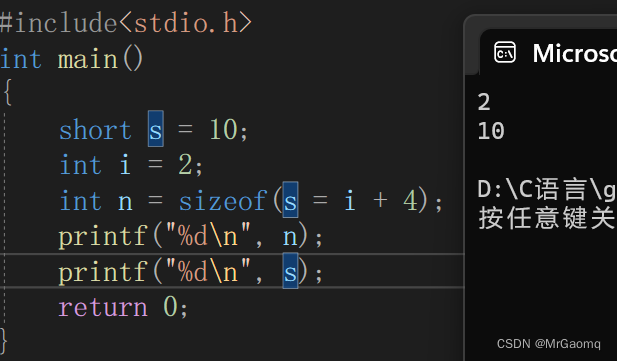
C语言深入理解指针(非常详细)(五)
目录 回调函数qsort使用举例qsort函数的模拟实现sizeof和strlen的对比sizeofstrlensizeof和strlen的对比一道关于sizeof的题 回调函数 回调函数就是一个通过函数指针调用的函数 如果你把函数的指针(地址)作为参数传递给另一个函数,当这个指…...
[docker]笔记-portainer的安装
1、portainer是一款可视化的容器管理软件,利用portainer可以轻松方便的管理和创建容器。portainer本身是一个容器,完全免费并且具有汉化版。本文介绍portainer的安装和使用。 2、安装好容器并配置好容器环境,可参照https://blog.csdn.net/bl…...
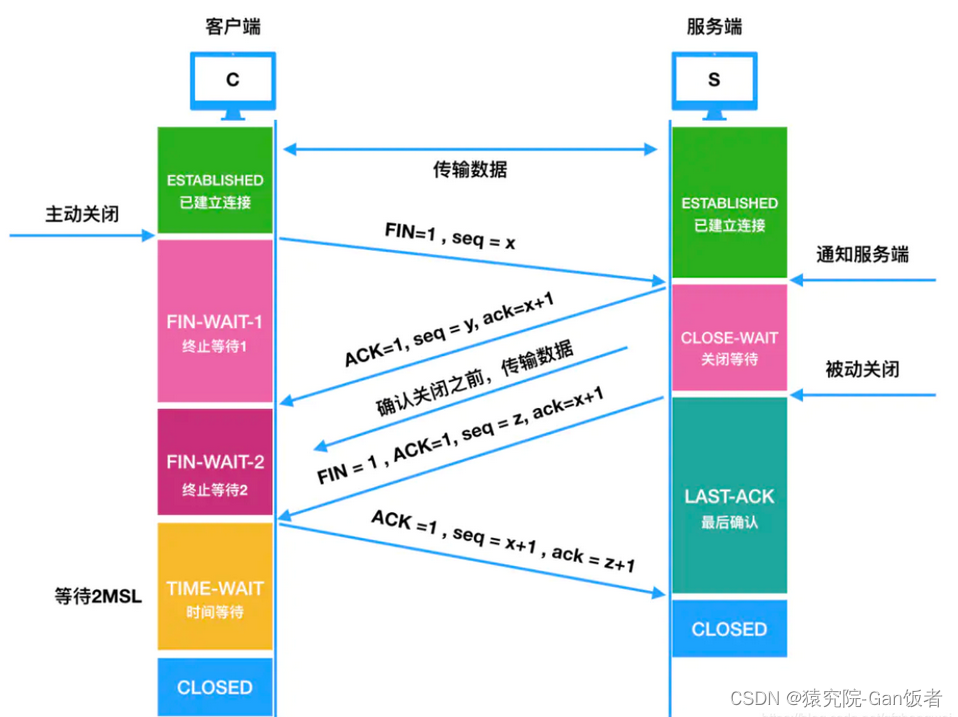
详解TCP/IP的三次握手和四次挥手
文章目录 前言一、TCP/IP协议的三次握手1.1 三次握手流程 二、TCP/IP的四次挥手2.1 四次挥手流程 三、主要字段3.1、标志位(Flags)3.2、序号(sequence number)3.3、确认号(acknowledgement number) 四、状态…...

YOLOv5算法改进(16)— 增加小目标检测层
前言:Hello大家好,我是小哥谈。小目标检测层是指在目标检测任务中用于检测小尺寸目标的特定网络层。由于小目标具有较小的尺寸和低分辨率,它们往往更加难以检测和定位。YOLOv5算法的检测速度与精度较为平衡,但是对于小目标的检测效…...
)
蓝桥杯官网练习题(图像模糊)
题目描述 小蓝有一张黑白图像,由 nm 个像素组成,其中从上到下共 n 行,每行从左到右 �m 列。每个像素由一个 0 到 255 之间的灰度值表示。 现在,小蓝准备对图像进行模糊操作,操作的方法为: 对…...

使用鳄鱼指标和ADX开立空头的条件,3秒讲清楚
使用鳄鱼指标和ADX开立空头的条件其实很简单,anzo capital昂首资本3秒钟讲清楚。 首先,市场行情需呈水平状态。再者,均线体系开始向上发散,给出明确的信号。最后,ADX确认该信号,要求指数上涨20%以上&#…...

RabbitMQ死信队列与延迟队列
目录 死信队列 死信队列的定义 死信队列的应用场景 死信队列的作用 死信队列架构图 死信队列代码实现 延迟队列 延迟队列的定义 延迟队列的应用场景 延迟队列的作用 延迟队列架构图 延迟队列的代码实现 死信队列 死信队列的定义 死信队列(Dead Letter …...

存储管理呀
世界太吵,别听,别看,别管,别怕,向前走 一. 存储管理 初识硬盘 机械 HDD 固态 SSDSSD的优势 SSD采用电子存储介质进行数据存储和读取的一种技术,拥有极高的存储性能,被认为是存储技术发展的未来…...

学习 BeautifulSoup 库从入门到精通
可以按照以下步骤进行: 1. 安装 BeautifulSoup: 首先,确保你已经安装了 Python。然后可以使用 pip 命令来安装 BeautifulSoup 库。在命令行中输入以下命令: pip install beautifulsoup42. 导入 BeautifulSoup: 在 …...

JavaScript基础知识总结
目录 一、js代码位置 二、变量与数据类型 1、声明变量 2、基本类型(7种基本类型) 1、undefined和null 2、String ⭐ 模板字符串(Template strings) 3、number和bigint ⭐ 4、boolean ⭐ 5、symbol 3、对象类型 1、Fun…...

技术面试与HR面:两者之间的关联与区别
🌷🍁 博主猫头虎(🐅🐾)带您 Go to New World✨🍁 🦄 博客首页——🐅🐾猫头虎的博客🎐 🐳 《面试题大全专栏》 🦕 文章图文…...

【Redis】为什么要学 Redis
文章目录 前言一、Redis 为什么快二、Redis 的特性2.1 将数据储存到内存中2.2 可编程性2.3 可扩展性2.4 持久性2.5 支持集群2.6 高可用性 三、Redis 的应用场景四、不能使用 Redis 的场景 前言 关于为什么要学 Redis 这个问题,一个字就可以回答,那就是&…...
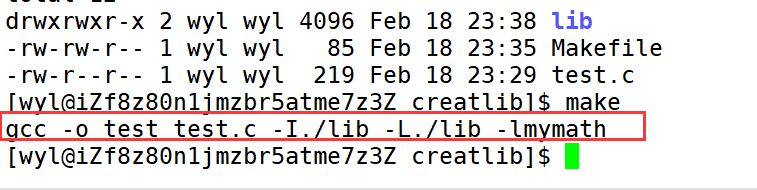
动静态库生成使用
🔥🔥 欢迎来到小林的博客!! 🛰️博客主页:✈️林 子 🛰️博客专栏:✈️ Linux 🛰️社区 :✈️ 进步学堂 🛰…...

LLVM编译安装
LLVM编译安装 #全量下载 git clone https://github.com/llvm/llvm-project.git #只下载最新commit版本 git clone --depth 1 https://github.com/llvm/llvm-project.git#配置 #!/bin/bash set -ex cmake -S llvm -B build -DCMAKE_INSTALL_PREFIX/data0/huozai/software/insta…...

表的内连接和外连接
表的连接是SQL中的一种操作,用于将两个或多个表中的数据按照某个条件进行关联。 内连接 使用内连接将两个表(Table1 和 Table2)进行连接: select * from Table1 inner join Table2 on Table1.id Table2.id;举例: -- 用普通的写法 select…...
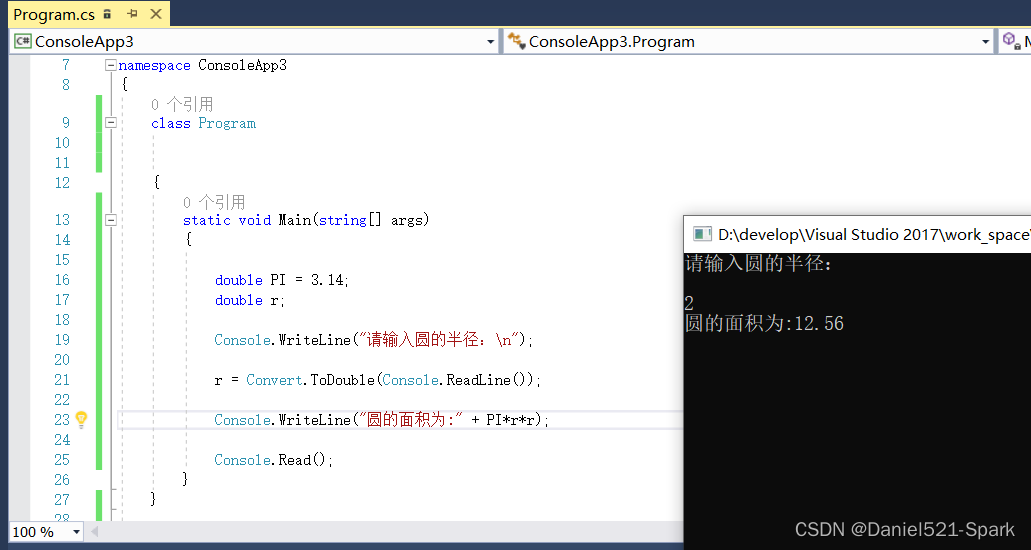
三、C#—变量,表达式,运算符(3)
🌻🌻 目录 一、变量1.1 变量1.2 使用变量的步骤1.3 变量的声明1.4 变量的命名规则1.5 变量的初始化1.6 变量初始化的三种方法1.7 变量的作用域1.8 变量使用实例1.9 变量常见错误 二、C#数据类型2.1 数据类型2.2 值类型2.2.1 值类型直接存储值2.2.2 简单类…...

纷享销客受邀出席CDIE2023数字化创新博览会 助力大中型企业增长
2023年,穿越周期,用数字化的力量重塑企业经营与增长的逻辑,再次成为企业数字化技术应用思考的主旋律,以数字经济为主线,数字技术融入产业发展与企业增长为依据,推动中国企业数字化升级。 9月5日,…...

第19节 Node.js Express 框架
Express 是一个为Node.js设计的web开发框架,它基于nodejs平台。 Express 简介 Express是一个简洁而灵活的node.js Web应用框架, 提供了一系列强大特性帮助你创建各种Web应用,和丰富的HTTP工具。 使用Express可以快速地搭建一个完整功能的网站。 Expre…...

CTF show Web 红包题第六弹
提示 1.不是SQL注入 2.需要找关键源码 思路 进入页面发现是一个登录框,很难让人不联想到SQL注入,但提示都说了不是SQL注入,所以就不往这方面想了 先查看一下网页源码,发现一段JavaScript代码,有一个关键类ctfs…...

图表类系列各种样式PPT模版分享
图标图表系列PPT模版,柱状图PPT模版,线状图PPT模版,折线图PPT模版,饼状图PPT模版,雷达图PPT模版,树状图PPT模版 图表类系列各种样式PPT模版分享:图表系列PPT模板https://pan.quark.cn/s/20d40aa…...

Fabric V2.5 通用溯源系统——增加图片上传与下载功能
fabric-trace项目在发布一年后,部署量已突破1000次,为支持更多场景,现新增支持图片信息上链,本文对图片上传、下载功能代码进行梳理,包含智能合约、后端、前端部分。 一、智能合约修改 为了增加图片信息上链溯源,需要对底层数据结构进行修改,在此对智能合约中的农产品数…...
提供了哪些便利?)
现有的 Redis 分布式锁库(如 Redisson)提供了哪些便利?
现有的 Redis 分布式锁库(如 Redisson)相比于开发者自己基于 Redis 命令(如 SETNX, EXPIRE, DEL)手动实现分布式锁,提供了巨大的便利性和健壮性。主要体现在以下几个方面: 原子性保证 (Atomicity)ÿ…...

Mysql8 忘记密码重置,以及问题解决
1.使用免密登录 找到配置MySQL文件,我的文件路径是/etc/mysql/my.cnf,有的人的是/etc/mysql/mysql.cnf 在里最后加入 skip-grant-tables重启MySQL服务 service mysql restartShutting down MySQL… SUCCESS! Starting MySQL… SUCCESS! 重启成功 2.登…...

华为OD机考-机房布局
import java.util.*;public class DemoTest5 {public static void main(String[] args) {Scanner in new Scanner(System.in);// 注意 hasNext 和 hasNextLine 的区别while (in.hasNextLine()) { // 注意 while 处理多个 caseSystem.out.println(solve(in.nextLine()));}}priv…...

解决:Android studio 编译后报错\app\src\main\cpp\CMakeLists.txt‘ to exist
现象: android studio报错: [CXX1409] D:\GitLab\xxxxx\app.cxx\Debug\3f3w4y1i\arm64-v8a\android_gradle_build.json : expected buildFiles file ‘D:\GitLab\xxxxx\app\src\main\cpp\CMakeLists.txt’ to exist 解决: 不要动CMakeLists.…...
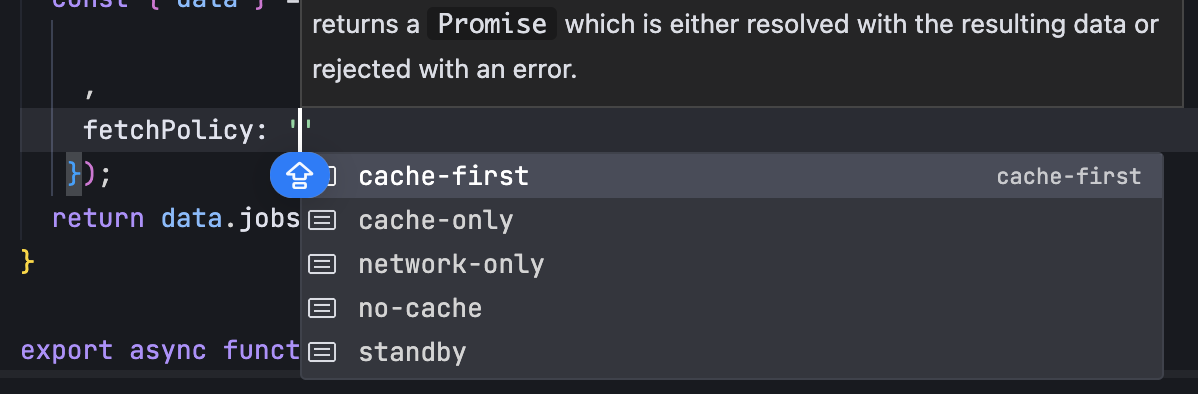
GraphQL 实战篇:Apollo Client 配置与缓存
GraphQL 实战篇:Apollo Client 配置与缓存 上一篇:GraphQL 入门篇:基础查询语法 依旧和上一篇的笔记一样,主实操,没啥过多的细节讲解,代码具体在: https://github.com/GoldenaArcher/graphql…...

[特殊字符] 手撸 Redis 互斥锁那些坑
📖 手撸 Redis 互斥锁那些坑 最近搞业务遇到高并发下同一个 key 的互斥操作,想实现分布式环境下的互斥锁。于是私下顺手手撸了个基于 Redis 的简单互斥锁,也顺便跟 Redisson 的 RLock 机制对比了下,记录一波,别踩我踩过…...